در این مطلب، ویدئو اکسل و SPSS: تجزیه و تحلیل داده ها با مقیاس LIKERT با استفاده از رگرسیون در Excel و SPSS با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید. اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:29:10
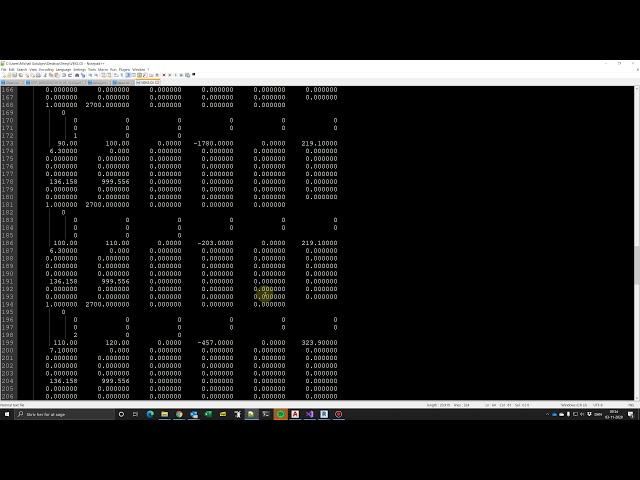
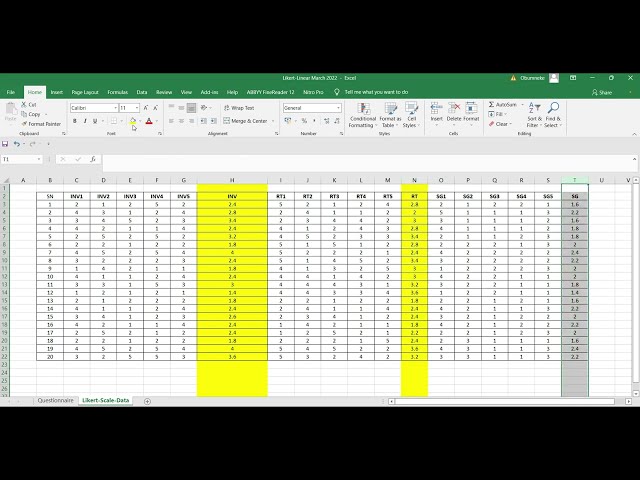
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
01 =>02
سلام متشکرم که یک بار
2
02 =>04
دیگر در آموزش امروز در آکادمی basip به من ملحق شدید،
3
04 =>06
من به شما نشان خواهم داد که چگونه
4
06 =>08
تجزیه و تحلیل رگرسیون داده های مهارتی محلی را
5
08 =>11
با استفاده از اکسل و spss
6
11 =>13
7
13 =>15
تجزیه و تحلیل
8
15 =>18
کنید.
9
18 =>20
پرسشنامه مقیاس مورد نیاز خاص در
10
20 =>22
اینجا برای استفاده برای این تجزیه و تحلیل در اینجا
11
22 =>24
ما متغیرهایی را داریم که شامل
12
24 =>28
نوآوری inv خطر پوسیدگی اس ام اس
13
28 =>31
رشد sg است و به کدهای هر یک
14
31 =>33
از این متغیرهای خاص در اینجا
15
33 =>35
inv یک تا پنج برای نوآوری rt
16
35 =>38
یک تا پنج برای ریسک نگاه کنید. اثبات sg یک دو
17
38 =>39
پنج چهار
18
39 =>42
اس ام اس را بگیرید و به مواردی که
19
42 =>44
در زیر هر یک از نقل قول ها آورده شده است نگاه کنید، همانطور که می توانید اینجا ببینید
20
44 =>45
21
45 =>47
اکنون مقیاس توافق در اینجا کاملاً
22
47 =>50
تصمیم گرفته شده است مخالفم یکی مخالفم تا
23
50 =>53
بلاتکلیف سه موافق برای کاملاً
24
53 =>54
موافقم 5
25
54 =>56
همانطور که می توانید اینجا نوشته شده است. اینجا را ببینید
26
56 =>58
که به طور منظم اینجا گرفته شده است، حالا فرض
27
58 =>01:00
کنیم این همان مدلی است که من می خواهم
28
01:00 =>01:02
در اینجا تخمین بزنم متغیر وابسته
29
01:02 =>01:05
در اینجا sg است. که گروه sms است و
30
01:05 =>01:07
دو متغیر مستقل در اینجا
31
01:07 =>01:09
نوآوری است که inv و ریسک
32
01:09 =>01:11
پذیری است، همانطور که اکنون می توانید ببینید
33
01:11 =>01:13
اگر داده هایی که ما در اینجا استفاده می کنیم
34
01:13 =>01:14
به طور معمول توزیع
35
01:14 =>01:16
شده است تست نرمال بودن را انجام نداده باشد، می خواهیم
36
01:16 =>01:18
از یک رگرسیون خطی استفاده کنیم و
37
01:18 =>01:20
اما اگر برنامه مشروبات الکلی ما
38
01:20 =>01:22
به طور معمول توزیع نشده
39
01:22 =>01:25
باشد، از رگرسیون ترتیبی و
40
01:25 =>01:27
همبستگی رتبه نعناع استفاده خواهیم کرد، همانطور که می
41
01:27 =>01:29
بینید خوب است، بنابراین این پرسشنامه ای است که ما
42
01:29 =>01:30
برای این تصویر خاص استفاده خواهیم کرد،
43
01:30 =>01:32
حالا فرض کنیم این
44
01:32 =>01:34
سوال توزیع شده است و نگاه کنیم.
45
01:34 =>01:36
در پاسخهای ایجاد شده و این
46
01:36 =>01:38
پرسشنامه به 20 پاسخدهنده برگردانده شد،
47
01:38 =>01:41
همانطور که میتوانید اینجا ببینید و
48
01:41 =>01:42
دوباره به کدهای هر یک از آن
49
01:42 =>01:46
متغیرهای خاص که inv 1 تا 5
50
01:46 =>01:50
rt1 تا 5 و sd 1 2 5 ضبط شدهاند نگاه
51
01:50 =>01:52
کنید، همانطور که اکنون میتوانید اینجا ببینید میخواهیم انجام دهیم این است
52
01:52 =>01:53
که ما میخواهیم این
53
01:53 =>01:55
متغیرهای خاص را با در نظر گرفتن
54
01:55 =>01:57
مقادیر میانگین هر یک از متغیرها تغییر دهیم، همانطور که
55
01:57 =>01:59
در اینج