در این مطلب، ویدئو مدل های رگرسیون لجستیک در SPSS و PSPP با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید. اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:19:52
تصاویر این ویدئو:

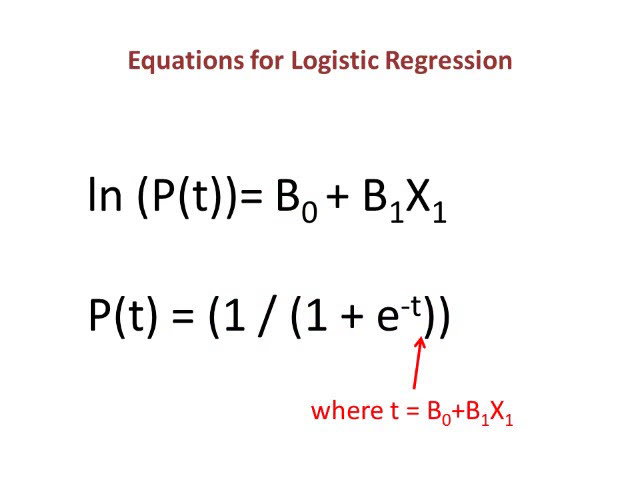


قسمتی از زیرنویس این فیلم:
00 =>03
این پروفسور راجرز است در این
2
03 =>05
ارائه ما به استفاده از
3
05 =>07
متغیرهای وابسته طبقهبندی با استفاده از
4
07 =>11
مدلهای لجستیک نگاه میکنیم. مثال
5
11 =>13
مشکل از نظرسنجی ملی مصرف مواد
6
13 =>15
مخدر و
7
15 =>17
8
17 =>20
سلامت ناشی میشود.
9
20 =>24
یک پاسخ دوگانه 0 برای خیر و 1
10
24 =>27
برای بله، متغیرهای مستقل نیز
11
27 =>29
دوقطبی اندازه گیری می کنند که آیا یک
12
29 =>31
فرد در سطح فقر یا زیر سطح فقر
13
31 =>33
زندگی می کند و اینکه آیا فرد در یک منطقه غیر کلان شهر زندگی می کند یا خیر،
14
33 =>38
راه حل قدیمی برای
15
38 =>40
این مشکل استفاده از
16
40 =>42
رگرسیون حداقل مربعات معمولی بود. این مدل
17
42 =>44
مقدار پیشبینیشده برای هر مشاهده
18
44 =>47
به احتمال اینکه فرد
19
47 =>50
دارای یک بیماری روانی شدید است تبدیل میشود، در اینجا
20
50 =>51
مدلی را میبینیم که نشان میدهد فقر از نظر
21
51 =>54
آماری معنیدار است و غیر
22
54 =>57
ساکنان مترو مدلی نیست که تنها
23
57 =>01:02
0.4 درصد از واریانس تواناییهای
24
01:02 =>01:05
بین صفر را توضیح میدهد. و یک صفر اگر رویداد رخ نداده باشد و یک صفر اگر
25
01:05 =>01:07
26
01:07 =>01:10
هر بار که مشکل با آن رویداد اتفاق می افتد
27
01:10 =>01:12
رویکرد رگرسیون به این صورت است که
28
01:12 =>01:14
مقادیر پیشبینیشده میتوانند کمتر از صفر و بزرگتر
29
01:14 =>01:17
از یک باشند که در این مثال معنایی ندارد،
30
01:17 =>01:19
میبینید که مقدار حداقل
31
01:19 =>01:21
کمتر از صفر است.
32
01:21 =>01:24
33
01:24 =>01:26
34
01:26 =>01:28
35
01:28 =>01:31
به این دلیل نامگذاری شده است که
36
01:31 =>01:32
خمهای منحنی شبیه
37
01:32 =>01:35
خم شدن حرف S در این مثال است،
38
01:35 =>01:37
ما سعی میکنیم پیشبینی کنیم که آیا یک فرد
39
01:37 =>01:40
امتحانی را با ساعت مطالعه قبول میکند یا خیر.
40
01:40 =>01:42
نقطههای بالا و پایین
41
01:42 =>01:45
محور y را ببینید. مقادیر
42
01:45 =>01:48
واقعی نتیجه 1 در صورت قبولی فرد و 0 در
43
01:48 =>01:51
صورت عدم موفقیت زمانی
44
01:51 =>01:53
که احتمال قبولی را بر اساس
45
01:53 =>01:55
ساعات مطالعه محاسبه می کنیم، منحنی s شکلی
46
01:55 =>02:00
از احتمالات را می گیریم که در اینجا
47
02:00 =>02:02
با صفر در پایین و یک در قسمت پایین محدود شده است. در بالا،
48
02:02 =>02:04
این توزیع مقادیر مورد انتظار
49
02:04 =>02:07
مطابق با انتظارات ما از آنچه که
50
02:07 =>02:11
داده ها واقعاً شبیه هستند،
51
02:11 =>02:12
مطابقت دارد.
52
02:12 =>02:14
53
02:14 =>02:16
متغیر mists را به نسبت شانس ورود به سیستم
54
02:16 =>02:20
، متغیر وابسته را
55
02:20 =>02:24
به صورت PT نشان می دهیم که احتمال رویداد
56
02:24 =>02:27
T است. ما به آن نسبت شانس logit یا log می گوییم.
57
02:27 =>02:31
58
02:31 =>02:33
59
02:33 =>02:36
60
02:36






![فیلم آموزشی: Revit را در 5 دقیقه یاد بگیرید: Rhino و Revit [صادرات\\وارد کردن به Revit][Grasshopper] با زیرنویس فارسی](http://pezhvak24.ir/dl/wood/vmxvSbuIlXYimage2.jpg)