

مقدمه
این مقاله به شما کمک می کند تا نیاز به یک محیط محاسباتی توزیع شده را درک کنید، نقش Hadoop در راه اندازی محاسبات توزیع شده و فناوری های اصلی را که با Hadoop کار می کند، درک کنید.
به عنوان یک شروع، اجازه دهید در میان مجموعه دادههایی که غولهایی مانند فیسبوک، گوگل و NSA دارند حرکت کنیم.
توجه
همه داده های مشخص شده در زیر از Google گرفته شده است.
فیس بوک
| داده هایی که فیس بوک در اختیار دارد | 300 پتابایت |
| داده های پردازش شده توسط فیس بوک در یک روز | 600 ترابایت |
| کاربران در یک ماه در فیس بوک | 1 میلیارد |
| لایک ها در یک روز در فیس بوک | 3 میلیارد |
| عکس های آپلود شده در یک روز در فیس بوک | 300 میلیون |
NSA
| داده های ذخیره شده در NSA | 5 اگزابایت |
| پردازش در روز | 30 پتابایت |
همانطور که می دانیم NSA روزانه 1.6 درصد از ترافیک اینترنت را تحت تأثیر قرار می دهد، NSA جستجوهای وب، وب سایت های بازدید شده، تماس های تلفنی، تراکنش های مالی، اطلاعات بهداشتی و غیره را نظارت می کند.
گوگل
اوپس!! گوگل در مقایسه با دو غول دیگر از میزان تراکنش داده ها شکست می زند!!
| داده هایی که گوگل دارد | 15 اگزابایت |
| پردازش داده ها در یک روز | 100 پتابایت |
| تعداد صفحات ایندکس شده | 60 تریلیون |
| جستجوهای منحصر به فرد در ماه | 1 میلیارد به علاوه |
| جستجو در ثانیه | 2.3 میلیون |
بنابراین، داشتن یک مجموعه داده عظیم مانند یک ماشین، هر چقدر هم که قدرتمند باشد، نمی تواند همه این داده ها را در چنین مقیاس عظیمی محاسبه کند. از این رو، ما به سمت یک سیستم کلان داده حرکت می کنیم.
ذخیرهسازی نیازمندیهای سیستم دادههای بزرگ
- دادههای خام
باید بتواند حجم عظیمی از دادهها را ذخیره کند، زیرا دادههای خام همیشه عظیم هستند.
فرآیند
ما باید بتوانیم اطلاعات مفید را به تنهایی از آن به موقع استخراج کنیم. در نهایت، ما به یک زیرساخت مقیاسپذیر نیاز داریم که بتواند با دادهها هماهنگی داشته باشد، که مدام در حال رشد است. این باید به ما کمک کند تا داده ها را با افزایش حجم ذخیره کنیم و همچنین می تواند همان را پردازش کند.
توجه - ذخیره سازی و پردازش بدون داشتن زیرساخت مقیاس پذیر که بتواند نیازهایی را که با داده ها در حال افزایش هستند را برآورده کند بی فایده است.
بنابراین، برای کار با چنین محیطی که دارای بینش های مختلف است، به یک چارچوب محاسباتی توزیع شده نیاز داریم و Hadoop به آنجا می رود.
Build System for Computation
هر سیستمی که بتواند برای ما محاسبات بسازد به دو صورت ساخته می شود.
- سیستم یکپارچه
همه چیز در یک ماشین واحد، که یک کامپیوتر فوق العاده است و تمام دستورالعمل های داده را پردازش می کند. - سیستم توزیع شده
چندین ماشین و چندین پردازنده وجود خواهد داشت. مجموعهای از گرهها به نام خوشه را در خود نگه میدارد، جایی که هیچ گرهای یک سوپر کامپیوتر نیست که به عنوان یک موجودیت واحد عمل میکند. این سیستم می تواند به صورت خطی مقیاس شود و اگر تعداد گره ها را در سیستم خود دو برابر کنید، فضای ذخیره سازی را دو برابر خواهید کرد. همچنین سرعت دستگاه را به دو برابر افزایش می دهد.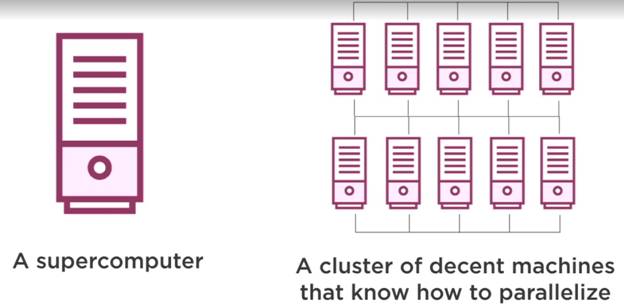
این سیستم توزیع شده جایی است که شرکت هایی مانند فیس بوک، گوگل، آمازون و غیره با مجموعه ماشین هایی با محیط های سرور گسترده زنده می مانند و این مکانی است که پردازش واقعی داده ها در آن انجام می شود.
اکنون، همه این ماشینهای محیط توزیع شده و نه سرورها نیاز به هماهنگی با یک نرمافزار دارند. این نرم افزار به نیازهای سیستم توزیع شده مانند پارتیشن بندی داده ها در چندین گره - تکرار داده ها در گره و هماهنگ کردن وظایف محاسباتی که روی ماشین های موازی اجرا می شوند، رسیدگی می کند. این نرم افزار همچنین تحمل خطا و بازیابی مانند خرابی دیسک و خرابی گره را مدیریت می کند. این نرم افزار همچنین باید فرآیند را تخصیص دهد، همانطور که ظرفیت گره از نظر حافظه و فضای هارد دیسک مدیریت می شود.
مقالات آینده من همه چیز درباره Big Data – Hadoop خواهد بود. بنابراین، به گشت و گذار برای مقالات من ادامه دهید.