

در این مقاله، اولین بازی یادگیری تقویتی (RL) خود را با استفاده از Python و محیط OpenAI Gym ساخته و اجرا می کنیم. کتابخانه OpenAI Gym دارای تعداد زیادی محیط بازی است – متنی مبتنی بر محیطهای پیچیده زمان واقعی. جزئیات بیشتر را می توان در وب سایت آنها یافت . برای نصب کتابخانه بدنسازی ساده است، فقط این دستور را تایپ کنید:
pip install gym
ما از کتابخانه باشگاه برای ساخت و اجرای یک بازی متنی به نام FrozenLake-v0 استفاده خواهیم کرد. توضیحات زیر همانطور که از سایت Gym درباره این بازی انتخاب شده است:
"زمستان اینجاست. شما و دوستانتان در حال دور زدن یک فریزبی در پارک بودید که یک پرتاب وحشیانه انجام دادید که باعث شد فریزبی در وسط دریاچه بیرون بیاید. آب بیشتر یخ زده است، اما چند سوراخ وجود دارد که یخ در آنجا آب شده است. اگر وارد یکی از آن سوراخ ها شوید، در آب یخ زده می افتید. در این زمان، کمبود فریزبی بین المللی وجود دارد، بنابراین کاملاً ضروری است که در سراسر دریاچه حرکت کنید و دیسک را بازیابی کنید. با این حال، یخ لغزنده است، بنابراین شما همیشه در جهتی که قصد دارید حرکت نخواهید کرد.
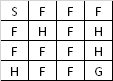
سطح با استفاده از یک شبکه مانند زیر توضیح داده شده است. بازی زمانی به پایان می رسد که به هدف برسید یا در سوراخی بیفتید. اگر به هدف برسید 1 جایزه دریافت می کنید و در غیر این صورت صفر.
SFFF
FHFH
FFFH
HFFG
جایی که S: نقطه شروع، امن، F: سطح یخ زده، ایمن، H: سوراخ، سقوط به سوی عذاب، G: هدف، جایی که فریزبی در آن قرار دارد.
در تکنیک یادگیری تقویتی یادگیری Q،
- هدف یادگیری خط مشی است که به نماینده می گوید در چه شرایطی چه اقدامی انجام دهد.
- برای هر فرآیند تصمیمگیری محدود مارکوف (FMDP)، یادگیری Q سیاستی را پیدا میکند که بهینه است به این معنا که ارزش مورد انتظار کل پاداش را در تمام مراحل متوالی، با شروع از وضعیت فعلی، حداکثر میکند.
- یادگیری Q می تواند یک خط مشی انتخاب عمل بهینه را برای هر FMDP مشخص، با توجه به زمان اکتشاف نامحدود و یک خط مشی نیمه تصادفی شناسایی کند.
- "Q" تابع Q(s,a) را نام میبرد که میتوان گفت به معنای "کیفیت" یک عمل انجام شده در یک حالت s است.
در این محیط دریاچه یخ زده 16 حالت وجود دارد - هر نقطه شبکه یک حالت است. 4 عمل امکان پذیر است - چپ، راست، بالا و پایین برای هر ایالت.
برای شروع برنامه ما - کتابخانه های زیر را در نوت بوک خود وارد کنید
- import numpy as np
- import gym
- import random
- import time
- from IPython.display import clear_output
حال، ما محیط را ایجاد می کنیم
- env = gym.make("FrozenLake-v0")
پس از این، q_matrix خود را ایجاد می کنیم که به 0 مقداردهی اولیه می شود.
- action_size = env.action_space.n
- state_size = env.observation_space.n
- q_matrix = np.zeros((state_size, action_size))
- q_matrix

حالا میخواهیم عامل خود را طوری آموزش دهیم که بعد از آموزش، این q_matrix را با حداکثر امتیاز برای آن جفت اکشن حالت بهروزرسانی کنیم و سپس عامل بتواند از آن برای اجرای بازی استفاده کند. پس از تکرارهای زیاد یک Q-table خوب آماده است.
از نظر ریاضی، موارد فوق در معادله زیر نشان داده شده است، که در آن آلفا نرخ یادگیری و گاما عامل تخفیف است.
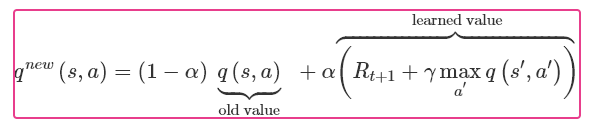
همچنین باید نرخ یادگیری را که معمولاً بین 0.001 و 0.5 است، تعیین کنیم. سرعت اکتشاف از 1 شروع می شود و به آرامی کاهش می یابد. اکتشاف پدیده ای است که در آن عامل در یک مسیر گیر نکرده و به کاوش در محیط ادامه می دهد تا مسیرهای مختلفی را پیدا کند که ممکن است به حداکثر بازده منجر شود. نرخ تنزیل عامل گاما برای پاداشهای آتی است که ارزش آن معمولاً بین 0.9 تا 0.999 است.
- num_episodes = 10000
- max_steps = 100
- learning_rate = 0.1
- discount_rate = 0.99
- exploration_rate = 1
- max_exploration_rate = 1
- min_exploration_rate = 0.05
- exploration_decay_rate = 0.0001
- cumulative_rewards_all_episodes = []
از آنجایی که کد بزرگ است، کد را به همراه این مقاله پیوست کردم. q_matrix به روز شده زیر را مشاهده خواهید کرد که پس از پایان 10000 بازی توسط نماینده یاد می شود.

اکنون، با این دانش، نماینده اکنون می تواند بازی را انجام دهد.
- # Watch our agent play Frozen Lake by playing the best action
- # from each state according to the Q-matrix
- for episode in range(3):
- # initialize new episode params
- state = env.reset()
- done = False
- print("*****EPISODE ", episode+1, "*****nnnn")
- time.sleep(1)
- for step in range(max_steps):
- # Show current state of environment on screen
- # Choose action with highest Q-value for current state
- # Take new action
- clear_output(wait=True)
- env.render()
- time.sleep(0.3)
- action = np.argmax(q_matrix[state,:])
- new_state, reward, done, info = env.step(action)
- if done:
- clear_output(wait=True)
- env.render()
- if reward == 1:
- # Agent reached the goal and won episode
- print("****You reached the goal!****")
- time.sleep(3)
- else:
- # Agent stepped in a hole and lost episode
- print("****You fell through a hole!****")
- time.sleep(3)
- clear_output(wait=True)
- break
- # Set new state
- state = new_state
- env.close()
کد بالا محیط را در حالی که عامل بازی می کند، نمایش می دهد.
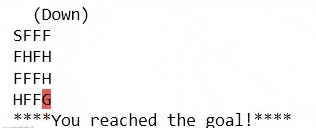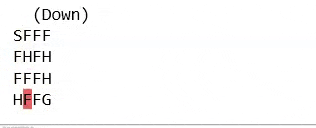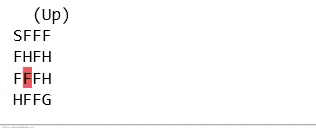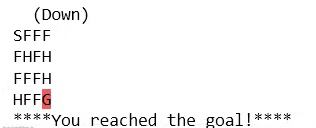
کد مطلب: