در این مطلب، ویدئو علم داده در پایتون: پانداس، دریازادگان، scikit-learn با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:00,589 –> 00:00:03,179
به مجموعه ویدیوهای من در مورد
2
00:00:03,179 –> 00:00:06,509
یادگیری ماشینی در Sicit-Learn خوش آمدید، در
3
00:00:06,509 –> 00:00:08,490
ویدیوی قبلی یاد گرفتیم که چگونه
4
00:00:08,490 –> 00:00:11,460
یک مدل را با استفاده از
5
00:00:11,460 –> 00:00:14,340
روش تقسیم تست Train به درستی ارزیابی کنیم
6
00:00:14,340 –> 00:00:16,890
که روی مدلهای طبقهبندی تمرکز
7
00:00:16,890 –> 00:00:19,890
کردیم و معیار ارزیابی ما دقت طبقهبندی بود.
8
00:00:19,890 –> 00:00:23,580
9
00:00:23,580 –> 00:00:27,570
چگونه می توانم از کتابخانه پانداس
10
00:00:27,570 –> 00:00:31,500
برای خواندن داده ها در پایتون
11
00:00:31,500 –> 00:00:34,230
استفاده کنم چگونه از کتابخانه Seabourn برای تجسم
12
00:00:34,230 –> 00:00:38,190
داده ها استفاده کنم که رگرسیون خطی چیست و چگونه
13
00:00:38,190 –> 00:00:39,050
کار می کند
14
00:00:39,050 –> 00:00:42,239
چگونه یک مدل رگرسیون خطی را در scikit-learn چه آموزش و تفسیر کنم.
15
00:00:42,239 –> 00:00:45,840
16
00:00:45,840 –> 00:00:48,030
برخی از معیارهای ارزیابی برای
17
00:00:48,030 –> 00:00:51,629
مشکلات رگرسیون هستند و چگونه می توانم انتخاب کنم
18
00:00:51,629 –> 00:00:56,309
که کدام ویژگی ها را در مدل خود لحاظ کنم تا
19
00:00:56,309 –> 00:00:59,030
کنون در این مجموعه بر طبقه بندی تمرکز کرده ایم که
20
00:00:59,030 –> 00:01:01,590
در آن هدف
21
00:01:01,590 –> 00:01:04,819
پیش بینی یک پاسخ طبقه بندی شده است در
22
00:01:04,819 –> 00:01:08,040
مقابل رگرسیون نوعی
23
00:01:08,040 –> 00:01:10,890
یادگیری نظارت شده است که در آن هدف این است
24
00:01:10,890 –> 00:01:13,970
که پیشبینی پاسخ مستمر
25
00:01:13,970 –> 00:01:16,890
مشکلات رگرسیون تمرکز
26
00:01:16,890 –> 00:01:19,610
ویدیوی امروز
27
00:01:24,820 –> 00:01:27,439
قبل از شروع صحبت در مورد
28
00:01:27,439 –> 00:01:29,869
رگرسیون است. برای انتخاب یک مجموعه داده و
29
00:01:29,869 –> 00:01:33,340
خواندن آن به پایتون با استفاده از پانداس، یک
30
00:01:33,340 –> 00:01:36,049
کتابخانه بسیار محبوب برای
31
00:01:36,049 –> 00:01:40,149
دستکاری و تجزیه و تحلیل اکتشاف داده، اگر
32
00:01:40,149 –> 00:01:43,280
از توزیع Anaconda
33
00:01:43,280 –> 00:01:46,640
پاندای پایتون استفاده میکنید و وابستگیهای
34
00:01:46,640 –> 00:01:49,880
آن قبلاً نصب شدهاند، در غیر این صورت من
35
00:01:49,880 –> 00:01:53,200
به دستورالعملهای نصب پیوند دادهام
36
00:01:53,200 –> 00:01:56,450
. با وارد کردن پانداس به روش متعارف شروع
37
00:01:56,450 –> 00:01:59,090
38
00:01:59,090 –> 00:02:06,950
میکنم، یعنی وارد کردن پانداس بهعنوان PD، مجموعه دادهای را
39
00:02:06,950 –> 00:02:09,139
برای درس امروز از کتاب انتخاب کردهام و
40
00:02:09,139 –> 00:02:12,650
مقدمهای برای یادگیری
41
00:02:12,650 –> 00:02:15,769
آماری مجموعه دادهها به صورت آنلاین بهعنوان یک فایل CSV
42
00:02:15,769 –> 00:02:19,900
که مخفف مقادیر جدا شده با کاما است، پست شده است.
43
00:02:19,900 –> 00:02:23,569
فایلهای CSV روشی بسیار رایج برای ذخیره
44
00:02:23,569 –> 00:02:26,810
دادهها هستند که در آن هر مشاهده
45
00:02:26,810 –> 00:02:29,989
یک خط در فایل است و فیلدها
46
00:02:29,989 –> 00:02:32,890
با کاما از هم جدا میشوند.
47
00:02:32,890 –> 00:02:36,440
48
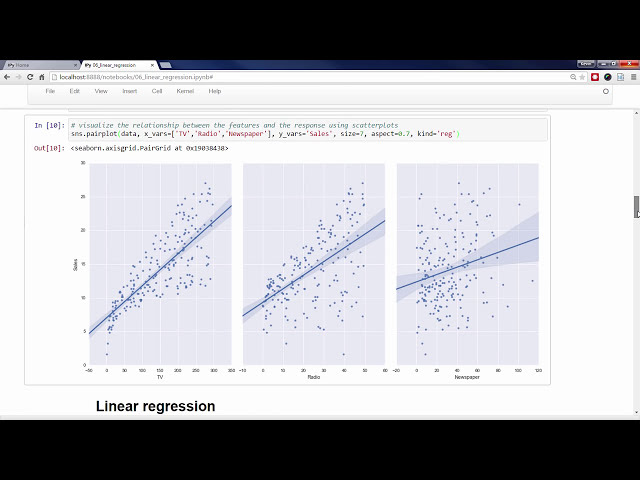
00:02:36,440 –> 00:02:40,609
49
00:02:40,609 –> 00:02:43,970
می
50
00:02:43,970 –> 00:02:46,160
توانید فایل ها را از رایانه محلی خود بخوانید یا
51
00:02:46,160 –> 00:02:49,220
واقعاً می توانید فایل ها را مستقیماً
52
00:02:49,220 –> 00:02:52,280
از یک URL بخوانید که این همان کاری است که من در اینجا
53
00:02:52,280 –> 00:02:55,280
انجام می دهم و نتایج را به عنوان یک
54
00:02:55,280 –> 00:02:58,310
شی ذخیره می کنم t داده را فراخوانی کرده و سپس متد head را
55
00:02:58,310 –> 00:03:01,220
روی آن شی اجرا کنید تا
56
00:03:01,220 –> 00:03:07,700
پنج ردیف اول داده را مشاهده کنید و نتایج به
57
00:03:07,700 –> 00:03:10,120
نوعی مانند یک صفحه گسترده نمایش
58
00:03:10,120 –> 00:03:12,859
59
00:03:12,859 –> 00:03:16,069
60
00:03:16,069 –> 00:03:20,630
داده می شود. به
61
00:03:20,630 –> 00:03:25,459
عنوان یک سری پانداس شناخته می شود، به هر حال پانداس
62
00:03:25,459 –> 00:03:27,859
متوجه شده اند که ردیف اول در
63
00:03:27,859 –> 00:03:31,269
فایل CSV شامل سرصفحه های ستون
64
00:03:31,269 –> 00:03:37,580
یعنی رادیو تلویزیون و غیره است، اما
65
00:03:37,580 –> 00:03:39,650
به نظر می رسد ستونی بدون نام وجود دارد
66
00:03:39,650 –> 00:03:41,810
که حاوی اعداد متوالی است
67
00:03:41,810 –> 00:03:47,540
که از یک شروع می شوند، بنابراین آنها احتمالاً
68
00:03:47,540 –> 00:03:49,820
فقط عبارتند از: شمارههای شناسه برای آن
69
00:03:49,820 –> 00:03:52,670
مشاهدات، من آن اعداد را میگیرم
70
00:03:52,670 –> 00:03:56,000
و از آنها بهعنوان نمایه استفاده میکنم، به
71
00:03:56,000 –> 00:04:00,020
این ترتیب پانداس ردیفها را شناسایی میکنند.
72
00:04:00,020 –> 00:04:02,990
شاخص پیشفرض اعداد متوالی است
73
00:04:02,990 –> 00:04:05,720
که از صفر شروع میشوند که در سمت چپ
74
00:04:05,720 –> 00:04:12,140
به صورت پررنگ نشان داده شده است تا نحوه تنظیم آن شناسه را بفهمم.
75
00:04:12,140 –> 00:04:15,020
اعداد به عنوان شاخص، بیایید
76
00:04:15,020 –> 00:04:19,519
به کمک برای خواندن CSV نگاه کنیم،
77
00:04:19,519 –> 00:04:22,280
داخل پرانتز کلیک می کنم و سپس دوبار روی زبانه shift روی صفحه کلیدم ضربه می
78
00:04:22,280 –> 00:04:26,140
زنم،
79
00:04:30,259 –> 00:04:34,289
می توانید ببینید که خواندن CSV دارای تعداد زیادی
80
00:04:34,289 –> 00:04:37,169
پارامتر است که به شما این امکان را می دهد که
81
00:04:37,169 –> 00:04:40,549
فرآیند خواندن CSV را با جزئیات زیاد کنترل کنید، در
82
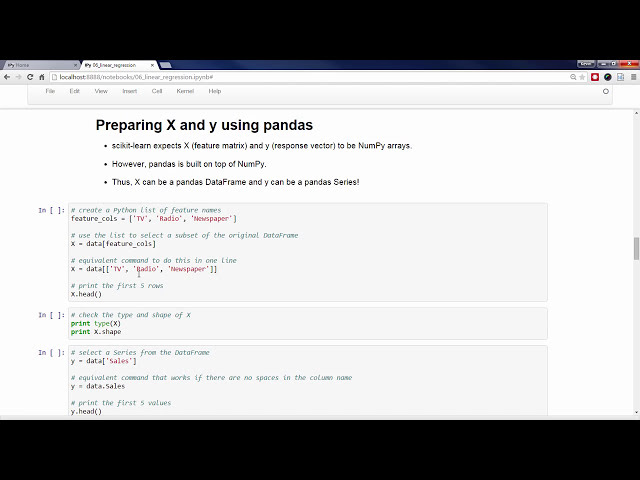
00:04:40,549 –> 00:04:44,729
مورد ما باید از پارامتر فراخوانی شاخص
83
00:04:44,729 –> 00:04:47,719
استفاده کنیم
84
00:04:54,180 –> 00:04:57,520
که به ما امکان می دهد یک ستون خاص را
85
00:04:57,520 –> 00:05:02,290
به عنوان شاخص تنظیم کنیم، بنابراین فراخوانی فهرست را
86
00:05:02,290 –> 00:05:16,090
برابر با صفر تایپ می کنیم و سپس این سلول را دوباره اجرا
87
00:05:16,090 –> 00:05:18,670
می کنیم. که اکنون ستون بدون نام
88
00:05:18,670 –> 00:05:28,300
تنظیم شده است زیرا فریم های داده شاخص نیز
89
00:05:28,300 –> 00:05:30,850
دارای یک روش دم هستند که پنج ردیف آخر را به شما نشان می دهد
90
00:05:30,850 –> 00:05:38,770
زیرا بالاترین
91
00:05:38,770 –> 00:05:41,740
عدد شاخص 200 است، فرض می کنیم که
92
00:05:41,740 –> 00:05:44,620
قاب داده 200 ردیف دارد اما می توانیم
93
00:05:44,620 –> 00:05:47,260
این را با چاپ کردن تأیید کنیم. ویژگی شکل آن
94
00:05:47,260 –> 00:05:55,030
خروجی به ما می گوید که
95
00:05:55,030 –> 00:06:04,600
اکنون که در داده ها خوانده ایم 200 ردیف در چهار ستون وجود دارد،
96
00:06:04,600 –> 00:06:07,120
بیایید در
97
00:06:07,120 –> 00:06:09,220
مورد داده ها و نحوه ساختار آن به عنوان یک
98
00:06:09,220 –> 00:06:12,610
کار یادگیری نظارت شده صحبت کنیم. ستون اول
99
00:06:12,610 –> 00:06:16,300
تلویزیون مقدار پول را به
100
00:06:16,300 –> 00:06:20,800
هزاران نشان می دهد. از دلاری که برای تبلیغات تلویزیونی برای
101
00:06:20,800 –> 00:06:23,560
تبلیغ یک محصول در یک
102
00:06:23,560 –> 00:06:27,940
بازار یا شهر خاص هزینه شده است، به عنوان مثال در بازار
103
00:06:27,940 –> 00:06:30,820
200 حدود دویست و سی و دو
104
00:06:30,820 –> 00:06:34,860
هزار دلار برای تبلیغات تلویزیونی
105
00:06:34,860 –> 00:06:37,720
به طور مشابه هشت هزار و ششصد
106
00:06:37,720 –> 00:06:39,970
دلار هزینه شده است. در بازار دویست
107
00:06:39,970 –> 00:06:43,000
برای تبلیغات رادیویی هزینه شده است و هشت هزار و
108
00:06:43,000 –> 00:06:45,130
هفتصد دلار در بازار دویست دلار برای تبلیغات روزنامه خرج شده است
109
00:06:45,130 –> 00:06:49,090
110
00:06:49,090 –> 00:06:51,670
ستون فروش نشان دهنده فروش
111
00:06:51,670 –> 00:06:54,220
کالای در حال تبلیغ در آن بازار
112
00:06:54,220 –> 00:06:58,270
در هزاران قلم است بنابراین در بازار
113
00:06:58,270 –> 00:07:01,540
دویست مقدار 13 هزار و
114
00:07:01,540 –> 00:07:04,550
400 فروخته شد
115
00:07:04,550 –> 00:07:06,979
در این مورد بیایید سعی کنیم
116
00:07:06,979 –> 00:07:10,810
فروش را بر اساس دلار تبلیغات پیش بینی
117
00:07:10,810 –> 00:07:15,560
کنیم بنابراین از رادیو تلویزیون و روزنامه به عنوان
118
00:07:15,560 –> 00:07:18,680
ویژگی استفاده می کنیم و از فروش به عنوان
119
00:07:18,680 –> 00:07:24,740
پاسخ استفاده می کنیم زیرا متغیر پاسخ ما
120
00:07:24,740 –> 00:07:27,919
پیوسته است و این یک
121
00:07:27,919 –> 00:07:31,849
مشکل رگرسیونی است. و برای اینکه واضح باشد مجموعه داده ما
122
00:07:31,849 –> 00:07:34,669
دارای 200 مشاهده است و هر
123
00:07:34,669 –> 00:07:39,789
مشاهده نشان دهنده یک بازار واحد است
124
00:07:42,069 –> 00:07:44,389
قبل از شروع کار در
125
00:07:44,389 –> 00:07:47,000
فرآیند یادگیری ماشین، بیایید
126
00:07:47,000 –> 00:07:49,990
داده های خود را تجسم کنیم تا احساس بهتری نسبت به آن داشته باشیم.
127
00:07:49,990 –> 00:07:52,990
من از کتابخانه Seabourn یک
128
00:07:52,990 –> 00:07:56,020
کتابخانه پایتون برای تجسم داده های آماری
129
00:07:56,020 –> 00:07:58,849
که در بالای matplotlib ساخته شده است،
130
00:07:58,849 –> 00:08:03,409
اگر از آناکوندا استفاده می کنید،
131
00:08:03,409 –> 00:08:06,800
می توانید kondeh install Seabourn را از
132
00:08:06,800 –> 00:08:10,639
خط فرمان اجرا کنید. برای نصب آسان آن برای
133
00:08:10,639 –> 00:08:12,889
سایر کاربران پایتون که به دستورالعملهای نصب پیوند دادهام،
134
00:08:12,889 –> 00:08:16,909
بیایید پیش برویم
135
00:08:16,909 –> 00:08:21,199
و Seabourn را به عنوان SNS وارد کنیم و همچنین
136
00:08:21,199 –> 00:08:24,650
matplotlib را در خطی که به عنوان یک فرمان جادویی شناخته میشود اجرا کنیم
137
00:08:24,650 –> 00:08:28,159
تا به نمودارها اجازه میدهد
138
00:08:28,159 –> 00:08:36,349
اغلب در اولین
139
00:08:36,349 –> 00:08:38,599
رابطهای که میخواهید در نوت بوک ظاهر شوند.
140
00:08:38,599 –> 00:08:40,700
visualize رابطه بین هر یک از
141
00:08:40,700 –> 00:08:44,329
ویژگی ها و متغیر پاسخ است که
142
00:08:44,329 –> 00:08:47,300
به راحتی می توان با استفاده از تابع نمودار جفت Seaborn انجام داد
143
00:08:47,300 –> 00:08:50,540
که جفت
144
00:08:50,540 –> 00:08:53,959
نمودارهای پراکندگی برای هر متغیر x و y تولید می کند
145
00:08:53,959 –> 00:09:02,000
که شما مشخص می کنید این نمودارها کمی
146
00:09:02,000 –> 00:09:04,579
کوچک هستند و بنابراین من می گویم. برای تغییر
147
00:09:04,579 –> 00:09:07,730
اندازه و نسبت ابعاد به طوری که بتوانم
148
00:09:07,730 –> 00:09:10,540
دادهها را راحتتر
149
00:09:28,660 –> 00:09:31,550
ببینم، میتوانید ببینید که تا حدودی یک
150
00:09:31,550 –> 00:09:37,240
رابطه خطی بین تلویزیون و فروش وجود دارد،
151
00:09:39,310 –> 00:09:42,850
به این معنی که تبلیغات تلویزیونی
152
00:09:42,850 –> 00:09:45,950
فروش را تا حدودی خطی افزایش میدهد.
153
00:09:45,950 –> 00:09:49,430
154
00:09:49,430 –> 00:09:51,860
رابطه قوی بین
155
00:09:51,860 –> 00:09:55,640
تبلیغات رادیویی و فروش و یک
156
00:09:55,640 –> 00:09:57,740
رابطه ضعیف بین
157
00:09:57,740 –> 00:10:02,450
تبلیغات روزنامه و فروش، در واقع میتوانیم
158
00:10:02,450 –> 00:10:05,540
از Seaborn بخواهیم تا نقشه را ترسیم کند. روابط se
159
00:10:05,540 –> 00:10:10,480
با افزودن یک آرگومان دیگر به طرح جفتی
160
00:10:19,470 –> 00:10:22,810
Seabourn خطی از بهترین برازش
161
00:10:22,810 –> 00:10:27,970
و همچنین باند اطمینان 95% را اضافه کرده است زیرا
162
00:10:27,970 –> 00:10:29,320
به نظر می رسد یک
163
00:10:29,320 –> 00:10:31,570
رابطه خطی بین ویژگی ها
164
00:10:31,570 –> 00:10:34,300
و پاسخ وجود دارد که این یک کاندید عالی
165
00:10:34,300 –> 00:10:41,950
برای روش رگرسیون خطی است.
166
00:10:41,950 –> 00:10:44,920
رگرسیون خطی یک موضوع کاملاً عمیق است، اما من
167
00:10:44,920 –> 00:10:46,480
فقط قصد دارم
168
00:10:46,480 –> 00:10:49,120
قبل از اینکه آن را در
169
00:10:49,120 –> 00:10:53,019
scikit-learn پیاده سازی کنیم برای شروع یک مقدمه کوتاه
170
00:10:53,019 –> 00:10:55,810
171
00:10:55,810 –> 00:11:00,160
172
00:11:00,160 –> 00:11:02,800
به شما ارائه می کنم. یک
173
00:11:02,800 –> 00:11:05,560
نوع مسئله یادگیری نظارت شده
174
00:11:05,560 –> 00:11:09,820
که در آن پاسخ رگرسیون خطی پیوسته
175
00:11:09,820 –> 00:11:12,700
است، یک
176
00:11:12,700 –> 00:11:15,579
مدل خاص یادگیری ماشینی است که می تواند برای
177
00:11:15,579 –> 00:11:18,640
مسائل رگرسیون استفاده شود و
178
00:11:18,640 –> 00:11:22,500
اتفاقاً کلمه رگرسیون در نام آن وجود دارد،
179
00:11:22,500 –> 00:11:25,779
به هر حال رگرسیون خطی یک
180
00:11:25,779 –> 00:11:28,449
تکنیک مدل سازی بسیار محبوب برای چهار است.
181
00:11:28,449 –> 00:11:33,160
دلایل اصلی اولاً سریع اجرا می شود که
182
00:11:33,160 –> 00:11:35,620
اهمیت فزاینده ای پیدا می کند زیرا
183
00:11:35,620 –> 00:11:39,670
اندازه مجموعه داده های شما در مرحله دوم افزایش می یابد
184
00:11:39,670 –> 00:11:43,180
نیازی به تنظیم نیست، همانطور
185
00:11:43,180 –> 00:11:46,209
که ما مجبور شدیم مقدار K را برای K
186
00:11:46,209 –> 00:11:49,920
و n تنظیم کنیم که شروع را آسان می کند.
187
00:11:49,920 –> 00:11:53,250
188
00:11:53,250 –> 00:11:55,930
189
00:11:55,930 –> 00:11:57,699
190
00:11:57,699 –> 00:12:01,810
191
00:12:01,810 –> 00:12:03,880
سالها مورد مطالعه قرار گرفته و به خوبی
192
00:12:03,880 –> 00:12:06,279
درک شده است و بنابراین حجم وسیعی
193
00:12:06,279 –> 00:12:09,100
از ادبیات در مورد
194
00:12:09,100 –> 00:12:11,730
چگونگی استفاده صحیح از رگرسیون خطی
195
00:12:11,730 –> 00:12:15,670
از نظر اشکالات وجود دارد. اشکال اصلی
196
00:12:15,670 –> 00:12:18,070
رگرسیون خطی این است که
197
00:12:18,070 –> 00:12:20,529
بعید است بهترین دقت پیشبینی
198
00:12:20,529 –> 00:12:24,040
را در مقایسه با مدلهای دیگر به این
199
00:12:24,040 –> 00:12:26,680
دلیل است که رگرسیون خطی یک
200
00:12:26,680 –> 00:12:29,140
رابطه خطی بین ویژگیها
201
00:12:29,140 –> 00:12:32,560
و پاسخ را فرض میکند، در صورتی که رابطه
202
00:12:32,560 –> 00:12:35,560
بسیار غیرخطی باشد، همانطور که در بسیاری
203
00:12:35,560 –> 00:12:38,560
از سناریوهای دنیای واقعی اتفاق میافتد، رگرسیون خطی
204
00:12:38,560 –> 00:12:41,890
قادر به مدلسازی مؤثر
205
00:12:41,890 –> 00:12:44,860
رابطه نخواهد بود و بنابراین پیشبینیهای
206
00:12:44,860 –> 00:12:49,210
آن چندان دقیق نخواهد بود. بیایید
207
00:12:49,210 –> 00:12:51,610
نگاهی به شکل عملکردی رگرسیون خطی بیندازیم
208
00:12:51,610 –> 00:12:53,620
تا
209
00:12:53,620 –> 00:12:56,980
درکی از نحوه عملکرد آن به دست آوریم.
210
00:12:56,980 –> 00:13:01,360
به صورت زیر نشان داده شود y برابر است با
211
00:13:01,360 –> 00:13:06,910
هیچ بتا به علاوه بتا 1 X 1 به علاوه بتا 2 X
212
00:13:06,910 –> 00:13:12,490
2 تا بتای n X n که در آن
213
00:13:12,490 –> 00:13:15,790
n تعداد ویژگی ها است، اجازه دهید به طور خلاصه
214
00:13:15,790 –> 00:13:20,080
در مورد هر یک از عبارت های مدل بحث کنیم Y به
215
00:13:20,080 –> 00:13:23,500
سادگی مقدار پاسخ هر یک از
216
00:13:23,500 –> 00:13:25,660
ویژگی ها با یک متغیر X نشان داده می شود
217
00:13:25,660 –> 00:13:29,430
و هر ویژگی دارای یک ضریب است در
218
00:13:29,430 –> 00:13:34,029
این حالت ما سه ویژگی تلویزیون
219
00:13:34,029 –> 00:13:37,300
و رادیو و روزنامه داریم و هر ویژگی دارای
220
00:13:37,300 –> 00:13:40,780
مقدار بتا بتا 1 و بتا 2 و بتا
221
00:13:40,780 –> 00:13:46,570
3 در نهایت بتا هیچ یا بتای 0
222
00:13:46,570 –> 00:13:49,780
رهگیری نامیده می شود. که
223
00:13:49,780 –> 00:13:54,900
مقدار y زمانی است که تمام مقادیر X 0 باشند،
224
00:13:54,900 –> 00:13:58,000
این مقادیر بتا و همچنین
225
00:13:58,000 –> 00:14:01,089
وقفه در طول
226
00:14:01,089 –> 00:14:03,820
فرآیند برازش مدل با استفاده از آنچه که
227
00:14:03,820 –> 00:14:08,530
معیار حداقل مربعات نامیده میشود، آموخته میشود که اساساً
228
00:14:08,530 –> 00:14:11,470
رگرسیون خطی به دنبال یافتن خطی است که به
229
00:14:11,470 –> 00:14:17,110
بهترین وجه مطابقت دارد. داده های مشاهده شده همانطور که
230
00:14:17,110 –> 00:14:22,150
در اینجا می بینیم بهترین خط را به عنوان خطی تعریف می
231
00:14:22,150 –> 00:14:24,550
کند که مجموع مربعات
232
00:14:24,550 –> 00:14:27,520
خطا را به حداقل می رساند که در واقع فقط
233
00:14:27,520 –> 00:14:32,490
مجموع مجذور فواصل عمودی
234
00:14:36,260 –> 00:14:40,560
بین هر نقطه و خط یک بار
235
00:14:40,560 –> 00:14:43,230
این خط بهترین است. برازش آموخته شده است
236
00:14:43,230 –> 00:14:46,140
که میتوان از آن برای پیشبینی
237
00:14:46,140 –> 00:14:51,470
فروش با توجه به مجموعهای از مقادیر ویژگی استفاده کرد،
238
00:14:56,810 –> 00:14:59,700
قبل از شروع فرآیند مدلسازی
239
00:14:59,700 –> 00:15:02,220
با scikit-learn، ابتدا باید
240
00:15:02,220 –> 00:15:05,279
ماتریس ویژگی X و بردار پاسخ Y را تعریف کنیم به
241
00:15:05,279 –> 00:15:08,760
یاد داشته باشید که
242
00:15:08,760 –> 00:15:11,820
scikit-learn مورد انتظار است. x و y
243
00:15:11,820 –> 00:15:16,620
آرایه های numpy هستند، اما ما خوش شانس هستیم که
244
00:15:16,620 –> 00:15:20,790
پانداس بر روی numpy ساخته شده اند به این معنی
245
00:15:20,790 –> 00:15:23,510
که یک آرایه numpy وجود دارد که در واقع
246
00:15:23,510 –> 00:15:27,510
داده های چارچوب داده را ذخیره می کند، بنابراین
247
00:15:27,510 –> 00:15:31,110
X ما می تواند فریم داده پاندا باشد و
248
00:15:31,110 –> 00:15:35,000
Y ما می تواند یک پاندا باشد. سری و
249
00:15:35,000 –> 00:15:37,920
scikit-learn نحوه
250
00:15:37,920 –> 00:15:43,890
دسترسی به آرایههای numpy زیرین را میفهمد، بیایید
251
00:15:43,890 –> 00:15:47,910
با X شروع کنیم، آنچه باید ایجاد کنیم یک
252
00:15:47,910 –> 00:15:51,060
قاب داده است که فقط شامل سه
253
00:15:51,060 –> 00:15:54,870
ستون ویژگی ما باشد، بنابراین ابتدا بیایید یک
254
00:15:54,870 –> 00:16:00,360
لیست پایتون به نام تماسهای ویژگی ایجاد کنیم که
255
00:16:00,360 –> 00:16:02,190
حاوی نامهای ما باشد.
256
00:16:02,190 –> 00:16:07,110
ستونهای ویژگی در رشتهها ذخیره میشوند، سپس میتوان گفت
257
00:16:07,110 –> 00:16:11,279
ویژگی براکت باز داده، براکت بسته را فرا میخواند
258
00:16:11,279 –> 00:16:16,140
که به پانداس میگوید
259
00:16:16,140 –> 00:16:18,480
زیرمجموعهای از ستونهای قاب داده اصلی را انتخاب کنند
260
00:16:18,480 –> 00:16:21,990
، اغلب این دو
261
00:16:21,990 –> 00:16:25,019
مرحله را مشاهده خواهید کرد. e در یک خط، همانطور که در اینجا نشان داده شده
262
00:16:25,019 –> 00:16:30,209
است، این دو براکت ها می توانند
263
00:16:30,209 –> 00:16:32,880
گیج کننده باشند، بنابراین فقط به یاد داشته باشید که
264
00:16:32,880 –> 00:16:35,640
براکت بیرونی این است که چگونه به پانداس
265
00:16:35,640 –> 00:16:38,399
می گویید که می خواهید زیرمجموعه ای از ستون های قاب داده را انتخاب کنید
266
00:16:38,399 –> 00:16:41,760
و براکت داخلی
267
00:16:41,760 –> 00:16:45,070
نحوه تعریف لیست پایتون است،
268
00:16:45,070 –> 00:16:49,490
در نهایت اجازه دهید روش head را روی X اجرا کنید
269
00:16:49,490 –> 00:16:57,440
تا تأیید کنید که عملیات کار کرده است،
270
00:16:57,440 –> 00:16:59,870
میتوانید ببینید که هنوز یک قاب داده است اما
271
00:16:59,870 –> 00:17:02,540
اکنون فقط شامل سه
272
00:17:02,540 –> 00:17:11,630
ستون ویژگی ما است، میتوانیم از تابع نوع pythons
273
00:17:11,630 –> 00:17:14,900
برای تأیید اینکه یک قاب داده است استفاده کنیم و
274
00:17:14,900 –> 00:17:17,660
میتوانیم ویژگی shape را در آن چاپ کنیم. تأیید کنید
275
00:17:17,660 –> 0