در این مطلب، ویدئو Valerio Maggio – Python معنایی: تسلط بر داده های پیوندی با پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,000 –> 00:00:02,029
آه
2
00:00:09,030 –> 00:00:10,950
خیلی متشکرم که آمدید من
3
00:00:10,950 –> 00:00:13,740
واقعاً هیجان زده هستم که
4
00:00:13,740 –> 00:00:15,030
اینجا هستم سهامی که قرار است در مورد
5
00:00:15,030 –> 00:00:20,160
وب معنایی در پایتون صحبت کنم من واقعاً
6
00:00:20,160 –> 00:00:21,660
برای ساختن سهام هیجان زده هستم زیرا
7
00:00:21,660 –> 00:00:24,810
در واقع بچه هایی که
8
00:00:24,810 –> 00:00:31,290
در این زمینه درگیر هستند معمولاً که آنها قبلاً
9
00:00:31,290 –> 00:00:33,450
با جاوا دوست داشتند چیزهایی شبیه به این است
10
00:00:33,450 –> 00:00:36,030
زیرا چند سال پیش این نوع
11
00:00:36,030 –> 00:00:39,570
چیزها عمدتاً به زبان جاوا ساخته می شدند
12
00:00:39,570 –> 00:00:42,120
اما امروزه
13
00:00:42,120 –> 00:00:44,760
راه حل های زیادی وجود دارد که ممکن است برای کد پایتون خود از آنها استفاده کنید.
14
00:00:44,760 –> 00:00:48,660
15
00:00:48,660 –> 00:00:51,600
در رشته علوم کامپیوتر در
16
00:00:51,600 –> 00:00:54,390
دانشگاه ناپل در سال گذشته من یک
17
00:00:54,390 –> 00:00:56,160
محقق فوق دکتری در دانشگاه
18
00:00:56,160 –> 00:01:00,870
سالرنو هستم، بنابراین من اهل تپه هستم من عاشق
19
00:01:00,870 –> 00:01:03,510
علم داده و همه موضوعات
20
00:01:03,510 –> 00:01:05,700
مرتبط با این نوع چیزها و
21
00:01:05,700 –> 00:01:10,320
نیمی دیگر از من یک بچه بازی هستم، بنابراین ممکن است
22
00:01:10,320 –> 00:01:13,920
در مورد هر یک از چیزهای خنده دار که معمولاً دوست داریم صحبت کنیم،
23
00:01:13,920 –> 00:01:21,470
خوب چند
24
00:01:21,470 –> 00:01:24,119
کلمه کلیدی بسیار مختصر در مورد چیزهایی که به آنها علاقه مند هستم.
25
00:01:24,119 –> 00:01:29,939
26
00:01:29,939 –> 00:01:31,710
27
00:01:31,710 –> 00:01:34,979
28
00:01:34,979 –> 00:01:37,500
و وب معنایی،
29
00:01:37,500 –> 00:01:40,820
موضوع بحث امروز است و من
30
00:01:40,820 –> 00:01:43,649
معمولاً با این نوع موارد در پایتون کار میکنم،
31
00:01:43,649 –> 00:01:46,500
عمدتاً از همه این ابزارها استفاده میکردم، به
32
00:01:46,500 –> 00:01:48,630
عنوان مثال، شبکه X با دید
33
00:01:48,630 –> 00:01:50,850
زیاد میدانست تا بتوانم از استادم در زمینه رمزگذاری و یادگیری یاد بگیرم.
34
00:01:50,850 –> 00:01:56,369
Gem Tim برای مدلسازی موضوع
35
00:01:56,369 –> 00:02:01,549
و تلنگر صوتی برای دادههای معنایی، بنابراین
36
00:02:01,549 –> 00:02:04,500
در واقع این گفتگو عمدتاً مبتنی بر
37
00:02:04,500 –> 00:02:08,280
آزمایشگاه RDF ما است.
38
00:02:08,280 –> 00:02:10,229
39
00:02:10,229 –> 00:02:14,340
40
00:02:14,340 –> 00:02:16,620
41
00:02:16,620 –> 00:02:18,750
بنابراین اولین چیزی که می خواهم
42
00:02:18,750 –> 00:02:22,350
در مورد آن صحبت کنم این است که وب بسیار خوب است، نمی
43
00:02:22,350 –> 00:02:25,370
دانم بسیاری از شما قبلاً می دانید که
44
00:02:25,370 –> 00:02:27,130
محقق و
45
00:02:27,130 –> 00:02:31,020
بازیابی شکل گیری یا تجزیه و تحلیل وب
46
00:02:31,020 –> 00:02:34,030
تخمین زده اند که شکل وب
47
00:02:34,030 –> 00:02:37,150
مانند یک پاپیون است، در واقع نمودار وب است.
48
00:02:37,150 –> 00:02:40,180
توسط یک هسته تشکیل شده است
49
00:02:40,180 –> 00:02:43,510
که بخش اصلی است که به عنوان این
50
00:02:43,510 –> 00:02:46,300
مؤلفه قوی متصل نیز شناخته می شود که
51
00:02:46,300 –> 00:02:48,970
هسته وب است که در آن همه صفحات به
52
00:02:48,970 –> 00:02:52,420
خوبی به یکدیگر پیوند می دهند و سپس چهار منطقه
53
00:02:52,420 –> 00:02:54,520
در سمت چپ منطقه مبدا وجود دارد که
54
00:02:54,520 –> 00:02:57,550
همکاری می کنند. صفحات و منابع موجود
55
00:02:57,550 –> 00:03:00,820
در وب را که به هسته دو
56
00:03:00,820 –> 00:03:02,710
صفحه در هسته پیوند می دهند و منطقه پایانی
57
00:03:02,710 –> 00:03:05,260
که حاوی صفحاتی است که
58
00:03:05,260 –> 00:03:10,270
به صفحات پیوند داده شده توسط صفحات در هسته به صفحات پیوند داده شده اند، پیوند داده شده اند
59
00:03:10,270 –> 00:03:14,640
تا تخمین بسیار کمی
60
00:03:14,640 –> 00:03:17,680
از اندازه انجام شود. از این قسمت ها،
61
00:03:17,680 –> 00:03:20,320
هسته تقریباً 30 درصد وب
62
00:03:20,320 –> 00:03:24,910
را شامل می شود، مناطق آلفا شامل تمام قسمت های باز
63
00:03:24,910 –> 00:03:28,150
تقریباً 25 درصد کل وب است
64
00:03:28,150 –> 00:03:31,840
و سه مورد در 22 درصد
65
00:03:31,840 –> 00:03:34,060
این صفحه متصل وجود دارد که البته این یک
66
00:03:34,060 –> 00:03:37,950
تخمین برای مثال است. آیا می توانید
67
00:03:37,950 –> 00:03:43,510
به منطقه مبدأ دسترسی پیدا کنید اگر هیچ پیوند صفحه ای
68
00:03:43,510 –> 00:03:46,230
به آنها وجود ندارد، این فقط یک تخمین است
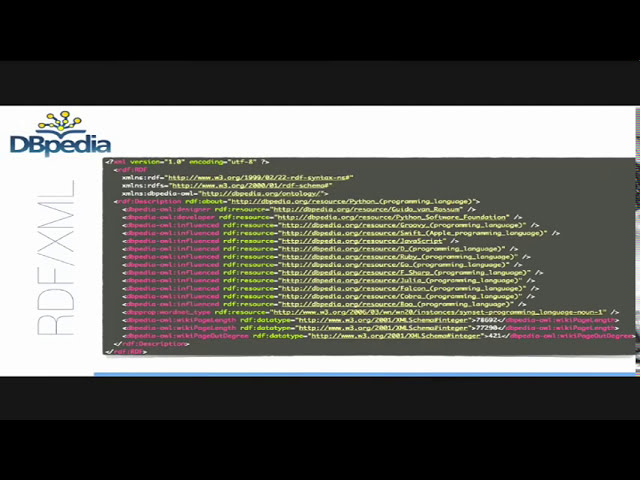
69
00:03:46,230 –> 00:03:49,450
به هر حال از دیدگاه مدیریت
70
00:03:49,450 –> 00:03:52,660
دانش www. بنابراین وب جهانی
71
00:03:52,660 –> 00:03:55,030
پر از داده است و در واقع داده ها
72
00:03:55,030 –> 00:03:57,280
معمولاً در قالب های مختلف منتشر
73
00:03:57,280 –> 00:03:59,890
می شوند. موجود در PDF و th و
74
00:03:59,890 –> 00:04:03,750
دندان ها برای تصاویر یا فایل های متنی و
75
00:04:03,750 –> 00:04:06,730
همه این صفحات همه این منابع را
76
00:04:06,730 –> 00:04:09,910
می توان به صفحات HTML یا
77
00:04:09,910 –> 00:04:13,540
به طور کلی به اسناد دیگر پیوند داد، بنابراین این
78
00:04:13,540 –> 00:04:15,370
نوع منابع از داده های شما می توان
79
00:04:15,370 –> 00:04:17,798
به صفحه وب در نمودار وب پیوند داد،
80
00:04:17,798 –> 00:04:22,300
خوب است، اما این نوع رویکرد
81
00:04:22,300 –> 00:04:25,240
محدودیت هایی دارد اول از همه، قالب داده
82
00:04:25,240 –> 00:04:27,270
ها برای مصرف انسانی است که عمدتاً
83
00:04:27,270 –> 00:04:30,270
برای مصرف انسانی و
84
00:04:30,270 –> 00:04:33,430
قالب های مختلف موجود
85
00:04:33,430 –> 00:04:35,340
در منابع موجود در وب است. نیاز به
86
00:04:35,340 –> 00:04:37,900
الگوریتمها و ابزارهای تخصصی برای
87
00:04:37,900 –> 00:04:40,030
دسترسی به جستجوی منابع برای
88
00:04:40,030 –> 00:04:40,510
ذخایر
89
00:04:40,510 –> 00:04:44,140
داریم و ما از دادهها استفاده میکنیم، بنابراین این زمانی است
90
00:04:44,140 –> 00:04:47,290
که دادههای لینکلن وارد
91
00:04:47,290 –> 00:04:49,300
92
00:04:49,300 –> 00:04:51,640
عمل میشوند.
93
00:04:51,640 –> 00:04:54,130
94
00:04:54,130 –> 00:04:57,010
و تمام اصول
95
00:04:57,010 –> 00:05:00,640
و بهترین شیوهها
96
00:05:00,640 –> 00:05:06,040
عمدتاً توسط استانداردها و توصیههای w3c هدایت میشوند،
97
00:05:06,040 –> 00:05:10,330
در واقع مدل داده پیوند
98
00:05:10,330 –> 00:05:15,490
اساساً بر
99
00:05:15,490 –> 00:05:19,380
این اساس استوار است که بر اساس مدل منبع www،
100
00:05:19,380 –> 00:05:25,690
هر منبع بهطور منحصربهفرد توسط یک URI شناسایی میشود
101
00:05:25,690 –> 00:05:28,690
که مخفف
102
00:05:28,690 –> 00:05:32,110
شناسه منبع جهانی است و
103
00:05:32,110 –> 00:05:34,120
تمام منابع در این نمودار وجود دارد
104
00:05:34,120 –> 00:05:37,300
که با پیوندهای دیگر به هم مرتبط شده اند، بنابراین
105
00:05:37,300 –> 00:05:40,120
این مدل اولیه th است. منابع موجود
106
00:05:40,120 –> 00:05:44,560
در دادههای پیونددهنده است و بهاصطلاح
107
00:05:44,560 –> 00:05:47,890
اصول پنج ستاره وجود
108
00:05:47,890 –> 00:05:55,210
دارد تا بفهمید دادههایی که در
109
00:05:55,210 –> 00:05:57,990
وب منتشر میکنید، دادههای پیوندی هستند
110
00:05:57,990 –> 00:06:00,580
یا خیر، اگر دادهها در وب در دسترس باشند، یک ستاره دریافت میکنید.
111
00:06:00,580 –> 00:06:02,350
112
00:06:02,350 –> 00:06:04,840
اگر دادهها در وب در دسترس هستند، ممکن است دو ستاره داشته باشید،
113
00:06:04,840 –> 00:06:08,050
اما در قالبهای
114
00:06:08,050 –> 00:06:11,110
قابل خواندن و ساختار یافته با ماشین،
115
00:06:11,110 –> 00:06:13,480
اگر دادهها بدون فرمت اختصاصی در دسترس باشند، سه ستاره دریافت میکنید.
116
00:06:13,480 –> 00:06:16,500
117
00:06:16,500 –> 00:06:20,250
118
00:06:20,250 –> 00:06:23,770
استانداردها و در نهایت
119
00:06:23,770 –> 00:06:26,320
شما بهترین هستید، بنابراین
120
00:06:26,320 –> 00:06:30,250
اگر همه ستارههای بالا اعمال شوند، به اضافه
121
00:06:30,250 –> 00:06:33,180
پیوندهایی به دادههای دیگر در قالبهای مشابه، پنج ستاره خواهید داشت، البته
122
00:06:33,180 –> 00:06:37,270
دسترسی بسیار کوتاهی به
123
00:06:37,270 –> 00:06:40,570
مثالهای ساده، دکمه لایک در فیسبوک
124
00:06:40,570 –> 00:06:44,550
در واقع و این در زیر هود یک
125
00:06:44,550 –> 00:06:47,800
پیوند است. برخی از داده های وب معنایی
126
00:06:47,800 –> 00:06:51,370
در قالبی که rdfa نامیده می شود،
127
00:06:51,370 –> 00:06:54,249
در اسلایدهای بعدی به طور خلاصه در مورد آن صحبت خواهیم کرد
128
00:06:54,249 –> 00:06:56,679
یا به عنوان مثال پروژه بسیار
129
00:06:56,679 –> 00:06:58,599
معروفی به نام dbpedia
130
00:06:58,599 –> 00:07:03,909
که نوعی تبدیل
131
00:07:03,909 –> 00:07:05,889
داده های متنی است. از متنی از
132
00:07:05,889 –> 00:07:11,129
ویکیپدیا در قالب دادههای پیوندی میآید،
133
00:07:12,149 –> 00:07:16,029
فقط برای مثالی که
134
00:07:16,029 –> 00:07:19,509
من واقعاً از این نوع چیزها در عمل استفاده کردم،
135
00:07:19,509 –> 00:07:22,869
اگر صفحه ویکیپدیا در مورد
136
00:07:22,869 –> 00:07:27,089
پایتون را در این مورد در نظر بگیرید، زیرا حیوان
137
00:07:27,239 –> 00:07:31,029
این صفحه به استاندارد dbpedia تبدیل شده است،
138
00:07:31,029 –> 00:07:35,889
خوب است. خوب ذخیره سازی DPP
139
00:07:35,889 –> 00:07:38,860
بنابراین فرمت این صفحه به نوعی ساختار یافته است،
140
00:07:38,860 –> 00:07:42,999
من وارد جزئیات نمی شوم،
141
00:07:42,999 –> 00:07:45,669
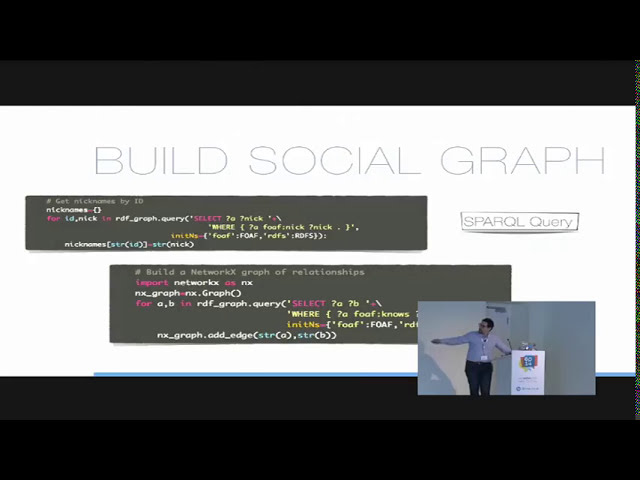
بنابراین این پیوند با
142
00:07:45,669 –> 00:07:49,110
این پیوند در dbpedia مطابقت دارد، بسیار خوب و
143
00:07:49,110 –> 00:07:52,559
سپس dbpedia در اینجا حاوی
144
00:07:52,559 –> 00:07:55,239
اطلاعات معنایی در مورد
145
00:07:55,239 –> 00:07:58,509
محتوای این صفحه و بخش طبیعت
146
00:07:58,509 –> 00:08:00,699
بیبیسی در واقع از این نوع
147
00:08:00,699 –> 00:08:04,059
اطلاعات برای دستهبندی
148
00:08:04,059 –> 00:08:06,779
صفحات مربوط به حیوانات
149
00:08:06,779 –> 00:08:11,259
در این وبسایت استفاده میکنند.
150
00:08:11,259 –> 00:08:14,079
151
00:08:14,079 –> 00:08:16,959
152
00:08:16,959 –> 00:08:20,729
وبسایت طبیعت بیبیسی
153
00:08:20,729 –> 00:08:24,099
از مطالب dbpedia سوء استفاده میکند تا بداند
154
00:08:24,099 –> 00:08:27,489
که Python a Python یک خزنده خوب است
155
00:08:27,489 –> 00:08:29,709
و این در واقع مطابق با این
156
00:08:29,709 –> 00:08:34,208
نوع از این است که schema s نامیده میشود. طرحواره عاطفی
157
00:08:34,208 –> 00:08:37,659
که در آن مجموعه ای از
158
00:08:37,659 –> 00:08:41,169
اصطلاحات مختلف دارید که ممکن است به آنها نگاه کنید و در این
159
00:08:41,169 –> 00:08:43,328
مورد کلاس این حیوان با خزنده مطابقت دارد
160
00:08:43,328 –> 00:08:45,850
خوب این فقط یک
161
00:08:45,850 –> 00:08:49,750
مثال بسیار ساده از داده های پیوند دهنده در وب است
162
00:08:49,750 –> 00:08:53,319
در واقع در سال 2007 این تقریباً این بود
163
00:08:53,319 –> 00:08:55,300
وضعیت داده های پیوند دهنده
164
00:08:55,300 –> 00:08:59,860
در سال 2008 این نمودار است عکس
165
00:08:59,860 –> 00:09:01,809
فوری داده های پیوند دهنده موجود در
166
00:09:01,809 –> 00:09:05,500
وب در سال 2009 است و این یک عکس
167
00:09:05,500 –> 00:09:07,720
فوری از داده های پیوند دهنده در
168
00:09:07,720 –> 00:09:13,060
سال 2011 است، بنابراین هر روز قالب های جدید می آیند
169
00:09:13,060 –> 00:09:15,670
و یک روز پیوند جدید می آیند. در
170
00:09:15,670 –> 00:09:17,860
مخزن این در واقع
171
00:09:17,860 –> 00:09:20,529
ایده اصلی داده های پیوند دهنده است، یک نمودار بسیار بزرگ
172
00:09:20,529 –> 00:09:22,810
از منابع که به یکدیگر متصل هستند،
173
00:09:22,810 –> 00:09:27,610
بسیار خوب، بنابراین در اینجا به این
174
00:09:27,610 –> 00:09:32,980
بخش معنایی می رویم که وب معنایی بسیار
175
00:09:32,980 –> 00:09:36,610
معروف است، حدس می زنم بر اساس برخی از
176
00:09:36,610 –> 00:09:39,610
اصول این به گفته تیم
177
00:09:39,610 –> 00:09:41,470
برنرز است. لی که در اینجا
178
00:09:41,470 –> 00:09:45,449
خالق وب جهانی و یکی از اولین
179
00:09:45,810 –> 00:09:48,160
حامیان این نوع تکنیک هاست
180
00:09:48,160 –> 00:09:50,379
، وب معنایی سیستمی است که
181
00:09:50,379 –> 00:09:52,569
ماشین را قادر می
182
00:09:52,569 –> 00:09:55,930
سازد تا درخواست های پیچیده انسانی را بر اساس آن درک کند و به آنها پاسخ دهد.
183
00:09:55,930 –> 00:09:58,000
معنی آنها به همین دلیل
184
00:09:58,000 –> 00:10:02,050
پارک معنایی است و از
185
00:10:02,050 –> 00:10:04,750
نقطه نظر عملی وب معنایی بر اساس
186
00:10:04,750 –> 00:10:08,019
مجموعه ای از استانداردها و بهترین روش ها ساخته شده است. به
187
00:10:08,019 –> 00:10:10,720
اصطلاح پشته استاندارد توسط URI که ساختار پایه است توسط زیر هود تشکیل شده است.
188
00:10:10,720 –> 00:10:13,569
189
00:10:13,569 –> 00:10:18,519
که روی آن
190
00:10:18,519 –> 00:10:20,709
تک تک منابع میتوان بهطور منحصربهفرد
191
00:10:20,709 –> 00:10:24,040
در بالای آن شناسایی کرد، RDF
192
00:10:24,040 –> 00:10:28,420
و سپس بقیه سطوح دیگر
193
00:10:28,420 –> 00:10:31,029
وجود دارد، هر چند لایههای دیگر این پشته
194
00:10:31,029 –> 00:10:35,730
تا اثبات و اعتماد قرار
195
00:10:35,730 –> 00:10:40,389
میگیرند، در واقع اینها برخی از جزئیات
196
00:10:40,389 –> 00:10:43,629
URI و URI هستند. یونیکد در پایه
197
00:10:43,629 –> 00:10:47,079
این پشته قرار دارد و سپس ما دستور XML را
198
00:10:47,079 –> 00:10:50,670
به طور کلی داریم RDF که
199
00:10:50,670 –> 00:10:53,079
چارچوب توصیف منبع است که
200
00:10:53,079 –> 00:10:55,329
در اسلاید بعدی در مورد آن با جزئیات صحبت خواهیم کرد
201
00:10:55,329 –> 00:10:57,879
و سپس همه
202
00:10:57,879 –> 00:11:02,769
چیزهایی که از این نوع سوء استفاده می کنند.
203
00:11:02,769 –> 00:11:05,829
مدل داده برای نمایش داده های معنایی
204
00:11:05,829 –> 00:11:08,350
و این هدف نهایی است، بنابراین برای داشتن
205
00:11:08,350 –> 00:11:14,519
نوعی تعامل ماشینی تراکنش های ماشینی
206
00:11:14,579 –> 00:11:17,829
شما از این نوع داده ها بهره برداری می کنید،
207
00:11:17,829 –> 00:11:20,500
بنابراین یک الگوریتم با این نوع
208
00:11:20,500 –> 00:11:23,529
داده ها باید ب می تواند بطور خودکار
209
00:11:23,529 –> 00:11:26,410
معنی را بفهمد و بنابراین
210
00:11:26,410 –> 00:11:30,459
تصمیم گیری در مورد آنها خوب است صدا F
211
00:11:30,459 –> 00:11:31,959
مخفف چارچوب توصیف سس شما
212
00:11:31,959 –> 00:11:34,420
است در واقع فرمت داده نیست
213
00:11:34,420 –> 00:11:37,360
RDF یک مدل داده برای بیان
214
00:11:37,360 –> 00:11:41,110
روابط بین عناصر داده دلخواه
215
00:11:41,110 –> 00:11:43,929
فایل های RDF است که می تواند در چندین مورد استفاده شود.
216
00:11:43,929 –> 00:11:46,870
فرمت کل بر روی سه یا
217
00:11:46,870 –> 00:11:50,230
RDF XML و این فایل ها را می توان در
218
00:11:50,230 –> 00:11:53,829
این نسخه متمدن RDF
219
00:11:53,829 –> 00:11:56,380
ذخیره کرد.
220
00:11:56,380 –> 00:12:00,040
221
00:12:00,040 –> 00:12:05,139
222
00:12:05,139 –> 00:12:07,329
اساساً یک مدل مبتنی بر نمودار
223
00:12:07,329 –> 00:12:10,360
است، بنابراین ما مجموعه ای از سه گانه
224
00:12:10,360 –> 00:12:13,870
داریم که در آن یک گزاره موضوعی و یک
225
00:12:13,870 –> 00:12:15,910
مفعول داریم و در نهایت با تمام داده های نمایش داده شده
226
00:12:15,910 –> 00:12:18,399
با مجموعه ای از
227
00:12:18,399 –> 00:12:22,449
قبیله های مختلف به طور کلی تمام
228
00:12:22,449 –> 00:12:24,300
عناصر موجود در قبیله ها را امتحان می کنیم. به عنوان منابع نامیده میشود،
229
00:12:24,300 –> 00:12:29,129
بنابراین
230
00:12:29,129 –> 00:12:33,309
وقتی با دادههای RDF خود سروکار داریم، در مورد منابع صحبت میکنیم و
231
00:12:33,309 –> 00:12:35,829
همه منابع با
232
00:12:35,829 –> 00:12:41,220
ارجاعات I منحصر به فرد شما که
233
00:12:41,220 –> 00:12:46,809
معمولاً در i-raths شما ارجاع میشوند شناسایی میشوند. تفاوت اصلی
234
00:12:46,809 –> 00:12:50,769
بین URI و URL ها در
235
00:12:50,769 –> 00:12:55,750
این است که URL ها تنها راهی برای پیوند دادن
236
00:12:55,750 –> 00:12:59,439
و ارجاع به برخی از داده ها یا پیوند دادن به
237
00:12:59,439 –> 00:13:03,610
برخی از داده ها هستند در عوض راهی برای
238
00:13:03,610 –> 00:13:06,129
شناسایی منحصر به فرد یک منبع واحد
239
00:13:06,129 –> 00:13:10,660
در وب، مدل RDF نیز می باشد. اجازه می دهد تا
240
00:13:10,660 –> 00:13:13,300
برای یادداشت های خالی در مورد، که همچنین
241
00:13:13,300 –> 00:13:15,490
به عنوان یادداشت های ناشناس یادداشت های ناشناس شناخته می شود،
242
00:13:15,490 –> 00:13:18,160
در صورتی که شما URI
243
00:13:18,160 –> 00:13:20,649
مواردی را که می خواهید به آنها ارجاع دهید، نمی دانید، اجازه دهید
244
00:13:20,649 –> 00:13:23,140
در واقع این اتفاق بیفتد، بنابراین ما
245
00:13:23,140 –> 00:13:25,540
به عنوان مثال به این نوع نمودار می رسیم.
246
00:13:25,540 –> 00:13:28,149
یک یادداشت خالی در اینجا با این
247
00:13:28,149 –> 00:13:32,649
مجموعه متفاوت از ویژگی ها و پیوندها، بنابراین ما
248
00:13:32,649 –> 00:13:36,370
در این مورد یک یادداشت خالی داریم که
249
00:13:36,370 –> 00:13:39,339
نام اول جان نام دوم را در این
250
00:13:39,339 –> 00:13:42,450
وبلاگ دارد و سپس این یادداشت خالی
251
00:13:42,450 –> 00:13:44,950
این افراد دیگر را در اینجا می شناسد که یک
252
00:13:44,950 –> 00:13:48,640
یادداشت خالی دیگر است که دارد. استیون تیلور به
253
00:13:48,640 –> 00:13:51,850
عنوان نام اصلی به عنوان ایمیل به این TBA در medCom
254
00:13:51,850 –> 00:13:54,519
خوب است، فقط برای مثال آیه برابر 1 است
255
00:13:54,519 –> 00:13:57,760
و در نهایت مدل داده نیز
256
00:13:57,760 –> 00:14:00,700
مقادیر تحت اللفظی تحت اللفظی را مجاز میکند، برخی از
257
00:14:00,700 –> 00:14:03,820
نمونهها این هستند و
258
00:14:03,820 –> 00:14:06,000
تعادل زباله نیز ممکن است و ممکن است به صورت اختیاری h
259
00:14:06,000 –> 00:14:08,950
260
00:14:08,950 –> 00:14:12,600
برای مثال اگر
261
00:14:12,600 –> 00:14:15,760
در مورد یک وبلاگ یا یک صفحه ویکیپدیا صحبت
262
00:14:15,760 –> 00:14:17,620
میکنید، بدون مرجع زبان یا مرجع نوع، ممکن است همان صفحه را به
263
00:14:17,620 –> 00:14:21,040
زبانهای مختلف داشته باشید و این در صورتی است
264
00:14:21,040 –> 00:14:23,579
که ویژگی زبان در
265
00:14:23,579 –> 00:14:27,640
ورودی آمده باشد، کلمات بسیار کمی در مورد آن وجود دارد.
266
00:14:27,640 –> 00:14:29,980
فرمت های سریال سازی rdf به
267
00:14:29,980 –> 00:14:32,230
فرمت های تمدن بسیار متفاوتی اجازه می دهد، آنها
268
00:14:32,230 –> 00:14:35,829
برای استفاده مجدد از داده ها بسیار مفید
269
00:14:35,829 –> 00:14:38,680
هستند، آنها عبارتند از نظرسنجی های ورودی،
270
00:14:38,680 –> 00:14:42,339
سه RDF XML rdfa و RDF jason
271
00:14:42,339 –> 00:14:46,029
فقط برای ذکر موارد بسیار معروف،
272
00:14:46,029 –> 00:14:48,160
اولین مورد نظرسنجی های entrar است.
273
00:14:48,160 –> 00:14:50,829
فرمت بسیار ساده و بسیار خوانا برای
274
00:14:50,829 –> 00:14:55,480
انسان قابل خواندن n3 نیز ساده است اما
275
00:14:55,480 –> 00:14:58,660
فشرده تر
276
00:14:58,660 –> 00:15:00,850
277
00:15:00,850 –> 00:15:03,699
278
00:15:03,699 –> 00:15:06,579
279
00:15:06,579 –> 00:15:09,790
است. یکپارچه
280
00:15:09,790 –> 00:15:13,810
با فرمت های دیگر مانند صفحات X HTML
281
00:15:13,810 –> 00:15:18,310
و در نهایت فرمت RDF JSON که
282
00:15:18,310 –> 00:15:22,360
در مورد api آرام مفید است، بنابراین نگاه کنید
283
00:15:22,360 –> 00:15:26,980
بیایید چند مثال بزنیم در این مورد ما
284
00:15:26,980 –> 00:15:31,010
dbpe را دریافت می کنیم. صفحه dia نمایش dbpedia
285
00:15:31,010 –> 00:15:33,410
286
00:15:33,410 –> 00:15:36,380
صفحه زبان برنامه نویس پایتون در ویکی پدیا Okay Libby
287
00:15:36,380 –> 00:15:39,500
PDM مجموعه ای از
288
00:15:39,500 –> 00:15:41,720
اطلاعات ساختاریافته در مورد زبان برنامه نویسی پایتون را به شما نشان می دهد
289
00:15:41,720 –> 00:15:44,960
در این مورد ما dbpedia l
290
00:15:44,960 –> 00:15:48,470
WL را داریم که پیشوند آن است که فقط یک
291
00:15:48,470 –> 00:15:52,460
طراح پیشوند است که ما هستیم. توسعهدهنده رزومه باز
292
00:15:52,460 –> 00:15:55,060
بنیاد نرمافزار پایتون
293
00:15:55,060 –> 00:15:57,560
بر زبان برنامهنویسی بو زبان برنامهنویسی کبرا تأثیر میگذارد
294
00:15:57,560 –> 00:16:00,530
295
00:16:00,530 –> 00:16:03,620
و به همین ترتیب،
296
00:16:03,620 –> 00:16:06,740
مهمترین نکته در اینجا این است که
297
00:16:06,740 –> 00:16:11,000
هر مقدار موجود در این صفحه در
298
00:16:11,000 –> 00:16:13,850
واقع یک مرجع به هر دو
299
00:16:13,850 –> 00:16:14,840
منبع دیگر است،
300
00:16:14,840 –> 00:16:17,840
خوب این چیزی است که منظورم این بود که وقتی با
301
00:16:17,840 –> 00:16:23,470
آنها صحبت میکنم، در مورد پیوند و داده صحبت کردیم خوب است، بنابراین
302
00:16:23,470 –> 00:16:28,970
این دادهها با فرمت n-triples،
303
00:16:28,970 –> 00:16:34,790
متأسفم، اشکالی ندارد، این یک زنجیره است.
304
00:16:34,790 –> 00:16:37,640
305
00:16:37,640 –> 00:16:39,680
306
00:16:39,680 –> 00:16:43,280
307
00:16:43,280 –> 00:16:46,640
فاعل را مفعول داشته باشیم که پرادا
308
00:16:46,640 –> 00:16:49,340
در اینجا دارای خاصیت و مفعول است و
309
00:16:49,340 –> 00:16:53,900
ما معمولاً به تمام قبیله های مختلف
310
00:16:53,900 –> 00:16:57,920
در مجموعه داده های خود می رسیم.
311
00:16:57,920 –> 00:17:01,580
فقط در شما یک پیشوند داشته باشید تا
312
00:17:01,580 –> 00:17:05,510
به معنای متفاوت از
313
00:17:05,510 –> 00:17:09,349
مرجع مختلف اشاره شود و بس و بس،
314
00:17:09,349 –> 00:17:11,780
بنابراین بسیار ساده است که هر قبیله ای با
315
00:17:11,780 –> 00:17:14,170
یک علامت با . پس همین است که
316
00:17:14,170 –> 00:17:17,960
نمایش n3 نمایش فشرده تری
317
00:17:17,960 –> 00:17:18,800
318
00:17:18,800 –> 00:17:22,520
است، اساساً از تکرارها اجتناب می کند و از تکرارها
319
00:17:22,520 –> 00:17:23,390
320
00:17:23,390 –> 00:17:25,970
کاملاً یکسان است، جدای از
321
00:17:25,970 –> 00:17:29,140
اینکه از هر تکرار اجتناب می شود و
322
00:17:29,140 –> 00:17:33,440
با یک کاما جایگزین می شود، بنابراین فهرستی
323
00:17:33,440 –> 00:17:35,660
از عناصری که دارای پیشوند یکسان هستند
324
00:17:35,660 –> 00:17:39,830
یا همان ویژگی و در نهایت RDF
325
00:17:39,830 –> 00:17:40,559
اعمال و
326
00:17:40,559 –> 00:17:43,210
نمایش یک نمایش XML
327
00:17:43,210 –> 00:17:46,929
از داده ها است، بنابراین ممکن است داده ها را
328
00:17:46,929 –> 00:17:51,039
به عنوان یک منبع XML ساختار دهیم و سپس
329
00:17:51,039 –> 00:17:57,820
در یک نمایش ساختاریافته تر افعال بیشتری
330
00:17:57,820 –> 00:18:03,600
داشته باشیم که باید بیشتر برای
331
00:18:03,600 –> 00:18:06,039
الگوریتم ها و برای پردازش در نظر گرفته شود نه برای
332
00:18:06,039 –> 00:18:08,230
خواندن خوب. منظور من برای خواندن انسان است
333
00:18:08,230 –> 00:18:12,129
و در نهایت آخرین چیز مهمی که باید
334
00:18:12,129 –> 00:18:14,649
گفت این است که RDF با واژگان متفاوتی همراه است،
335
00:18:14,649 –> 00:18:17,499
اما واژگان یک
336
00:18:17,499 –> 00:18:19,899
ایده با مجموعه محدودی از محمولات روبرو است،
337
00:18:19,899 –> 00:18:25,119
بنابراین وقتی می خواهید بدانید که محمولاتی که می خواهید بگویید چگونه هستند.
338
00:18:25,119 –> 00:18:27,519
339
00:18:27,519 –> 00:18:30,220
استفاده کردن برای توصیف منابع خود
340
00:18:30,220 –> 00:18:33,309
از واژگان چیزهایی است که می
341
00:18:33,309 –> 00:18:36,399
خواهید استفاده کنید زیرا واژگان
342
00:18:36,399 –> 00:18:39,190
مجموعه ای از واژگان مناسب را تعریف می کنند. پیوندهایی که ممکن
343
00:18:39,190 –> 00:18:42,249
است برای پیوند دادن موضوعات و اشیاء
344
00:18:42,249 –> 00:18:44,919
در دادههای خود استفاده کنید، واژگان بسیار متفاوتی وجود دارد که
345
00:18:44,919 –> 00:18:47,320
برخی از آنها عبارتند از c ox
346
00:18:47,320 –> 00:18:49,690
که مخفف پیوند معنایی
347
00:18:49,690 –> 00:18:51,519
در جوامع آنلاین است، بنابراین این
348
00:18:51,519 –> 00:18:54,070
واژگانی برای جوامع آنلاین است،
349
00:18:54,070 –> 00:18:56,379
واژگان چهارم که مخفف
350
00:18:56,379 –> 00:18:58,779
دوست یک دوست یا کلم در واقع
351
00:18:58,779 –> 00:19:02,769
این طرحواره این واژگان توسط
352
00:19:02,769 –> 00:19:06,009
فیس بوک خوب است و این واژگان علت
353
00:19:06,009 –> 00:19:07,239
که مخفف
354
00:19:07,239 –> 00:19:10,440
طرحواره سازمان دانش ساده است این فقط دو واژگان
355
00:19:10,440 –> 00:19:14,200
بسیار کمی هستند که بسیاری از آنها
356
00:19:14,200 –> 00:19:16,299
در واقع در ضرب المثل پیوند وجود دارد که در آن آنها
357
00:19:16,299 –> 00:19:19,600
بسیار هستند مجموعه عظیمی وجود دارد. از این
358
00:19:19,600 –> 00:19:22,529
واژگان متمایز شده بر اساس
359
00:19:22,529 –> 00:19:25,029
استفاده مورد نظر و دامنه ای که
360
00:19:25,029 –> 00:19:31,720
به Okay اشاره دارد به ویژه شوک و
361
00:19:31,720 –> 00:19:34,690
امتیازات به هم مرتبط هستند، بنابراین این یک
362
00:19:34,690 –> 00:19:39,070
مثال بسیار درخشان از
363
00:19:39,070 –> 00:19:41,919
داده های به هم پیوسته و داده های پیوند دهنده است در واقع ما در
364
00:19:41,919 –> 00:19:44,559
اینجا یک نفر چهارم داریم که مربوط
365
00:19:44,559 –> 00:19:48,299
به یک کاربر است. در شوک موجود در
366
00:19:48,299 –> 00:19:53,980
طرحواره SIOC و به عنوان مثال کاربر
367
00:19:53,980 –> 00:19:54,580
368
00:19:54,580 –> 00:19:56,740
پست های وبلاگی را ایجاد می کند که به مفهوم مرتبط هستند.
369
00:19:56,740 –> 00:19:59,410
s و این مفاهیم
370
00:19:59,410 –> 00:20:02,740
در یک طرحواره scause توضیح داده شده اند، خوب
371
00:20:02,740 –> 00:20:05,790
این فقط یک مثال بسیار ساده از
372
00:20:05,790 –> 00:20:08,500
373
00:20:08,500 –> 00:20:14,230
فرمت های داده به هم پیوسته داده های به هم پیوسته است، خوب ما
374
00:20:14,230 –> 00:20:17,110
در چند اسلاید با کد پایتون به این مثال ها
375
00:20:17,110 –> 00:20:26,260
خواهیم پرداخت، بنابراین چگونه داده های
376
00:20:26,260 –> 00:20:29,500
ارائه شده در RDF را پرس و جو کنیم. از زبانی
377
00:20:29,500 –> 00:20:31,540
به نام SPARQL استفاده کنید که مخفف
378
00:20:31,540 –> 00:20:34,030
پروتکل ساده و زبان کریول RDF است
379
00:20:34,030 –> 00:20:36,370
و زبان پرس و جوی استاندارد برای
380
00:20:36,370 –> 00:20:37,710
نمودارهای ایده است.
381
00:20:37,710 –> 00:20:40,360
382
00:20:40,360 –> 00:20:43,630
383
00:20:43,630 –> 00:20:45,580
384
00:20:45,580 –> 00:20:48,400
راه حل فقط برای
385
00:20:48,400 –> 00:20:51,040
ایجاد چند مثال در مثال رسمی،
386
00:20:51,040 –> 00:20:53,410
ما تمام محمول ها و
387
00:20:53,410 –> 00:20:56,370
اشیاء حاصل از
388
00:20:56,370 –> 00:20:59,950
منابع dbpedia با اشاره به زبان برنامه نویسی Python Python را انتخاب می کنیم.
389
00:20:59,950 –> 00:21:01,990
در
390
00:21:01,990 –> 00:21:05,290
مثال دوم می خواهیم
391
00:21:05,290 –> 00:21:07,810
چکیده پایتون را از dbpedia دریافت
392
00:21:07,810 –> 00:21:10,570
کنیم که فقط موارد را فیلتر می کند. زبانی که
393
00:21:10,570 –> 00:21:12,970
در این مورد انگلیسی است و آخرین
394
00:21:12,970 –> 00:21:15,310
نمونه هایی را که در آخرین مثال
395
00:21:15,310 –> 00:21:19,060
می خواهیم تمام لیستی را که می خواهیم بدست آوریم پیدا کنیم. اتحادیه
396
00:21:19,060 –> 00:21:21,070
اینجاست من نمیدانم میتوانید این را بخوانید یا نه،
397
00:21:21,070 –> 00:21:25,320
ما با عملگر Union در زبان SPARQL تماس
398
00:21:25,320 –> 00:21:28,810
میگیریم و لیستی از
399
00:21:28,810 –> 00:21:32,710
تمام زبانهایی که پایتون بر آنها تأثیر میگذارد
400
00:21:32,710 –> 00:21:35,050
و همه زبانهایی که پایتون به
401
00:21:35,050 –> 00:21:38,470
آنها علاقه داشته است را دریافت میکنیم. همه این
402
00:21:38,470 –> 00:21:40,870
داده ها صادقانه به زبان SQL بسیار ساده
403
00:21:40,870 –> 00:21:43,170
است، اما تفاوت این است که
404
00:21:43,170 –> 00:21:46,780
SPARQL می تواند پرس و جوهایی را روی داده های
405
00:21:46,780 –> 00:21:50,580
ارائه شده در قالب RDF ایجاد کند،
406
00:21:50,580 –> 00:21:54,490
بنابراین در نهایت به آخرین
407
00:21:54,490 –> 00:21:56,770
بخش ارائه می پردازیم که در مورد
408
00:21:56,770 –> 00:21:59,770
تسلط بر داده های پیوند دهنده است. با پایتون، بنابراین
409
00:21:59,770 –> 00:22:03,520
حدس میزنم این باید خندهدارترین
410
00:22:03,520 –> 00:22:07,210
بخش این بحث باشد.
411
00:22:07,210 –> 00:22:10,570
راهحل پایتون برای رام کردن
412
00:22:10,570 –> 00:22:13,840
وب معنایی عمدتاً مبتنی بر ایده در تلنگر RDF است.
413
00:22:13,840 –> 00:22:14,290
414
00:22:14,290 –> 00:22:16,300
415
00:22:16,300 –> 00:22:21,010
416
00:22:21,010 –> 00:22:24,450
417
00:22:24,450 –> 00:22:28,390
اگر می خواهید آن را وارد کنید، عملکرد آن را گسترش دهید، می نویسید
418
00:22:28,390 –> 00:22:32,200
ایده واردات تلنگر صوتی
419
00:22:32,200 –> 00:22:35,190
یک شی داخلی دارد که به
420
00:22:35,190 –> 00:22:38,230
421
00:22:38,230 –> 00:22:41,080
آن گراف می گویند.
422
00:22:41,080 –> 00:22:45,940
من فقط در مورد آن جزئیات میدهم،
423
00:22:45,940 –> 00:22:49,750
بنابراین یک نمودار را در اینجا ایجاد میکنیم، سپس
424
00:22:49,750 –> 00:22:53,980
بخشها را به یک منبع واحد تبدیل میکنیم که
425
00:22:53,980 –> 00:22:57,130
در فرمت end tribals نشان داده شده است، بنابراین در روش گذشته
426
00:22:57,130 –> 00:22:58,870
نمودارها یک
427
00:22:58,870 –> 00:23:00,730
پارامتر اضافی را اجازه میدهد که به
428
00:23:00,730 –> 00:23:02,560
تلنگر صوتی میگوید که فرمت ما کدام است.
429
00:23:02,560 –> 00:23:15,820
defib بله، متاسفم که
430
00:23:15,820 –> 00:23:26,790
پسر شما را نگرفتم شاید بله بله، حدس میزنم بله
431
00:23:26,790 –> 00:23:30,330
بله متشکرم
432
00:23:31,540 –> 00:23:35,500
، پس روش پست
433
00:23:35,500 –> 00:23:40,510
این فایلهای RDF را در حافظه دریافت
434
00:23:40,510 –> 00:23:43,900
میکنیم و سپس نمودار RDF را افزایش میدهیم و
435
00:23:43,900 –> 00:23:46,390
سپس ما میتوانم – دقیقاً روی قبیلههای
436
00:23:46,390 –> 00:23:48,820
این نمودار با با در تکها برای
437
00:23:48,820 –> 00:23:52,030
آموزش، سپس میتوانیم تمام
438
00:23:52,030 –> 00:23:57,030
قبیلههایی را که مطابقت دارند فهرست کنیم، به عنوان مثال
439
00:23:57,360 –> 00:24:02,830
پرس و جوی بسیار ساده در نمودار،
440
00:24:02,830 –> 00:24:05,170
همه قبیلهها را دریافت میکنیم و این نوع
441
00:24:05,170 –> 00:24:07,420
پرسوجو را منطبق میکنیم، بنابراین همه موارد را دریافت میکنیم. منابعی که
442
00:24:07,420 –> 00:24:12,670
دارای RDF در مورد خصوصیات هستند، مهم
443
00:24:12,670 –> 00:24:17,160
نیست که موضوع یا شیء کدام است،
444
00:24:17,160 –> 00:24:20,500
ما همچنین میتوانیم نمودار را دستکاری کنیم، بنابراین
445
00:24:20,500 –> 00:24:21,010
446
00:24:21,010 –> 00:24:23,620
میتوانیم یادداشتها و نکات
447
00:24:23,620 –> 00:24:25,840
جزئی را به ویژه به آن اضافه کنیم، بنابراین دو یادداشت داریم
448
00:24:25,840 –> 00:24:28,600
و بین آنها به نمودار
449
00:24:28,600 –> 00:24:31,660
و در نهایت ممکن است گراف حاصل را به صورت متنی ارسال کرده یا ذخیره
450
00:24:31,660 –> 00:24:34,450
کنیم،
451
00:24:34,450 –> 00:24:36,370
در این مورد میبینیم که
452
00:24:36,370 –> 00:24:38,260
از نمودار در یک نسخه XML بسیار خوب استفاده میکنیم،
453
00:24:38,260 –> 00:24:39,760
454
00:24:39,760 –> 00:24:43,170
و به همین دلیل است که ODF بسیار ساده
455
00:24:43,170 –> 00:24:46,090
را میتوان با پشتیبانی مداوم گسترش داد،
456
00:24:46,090 –> 00:24:49,390
در واقع پروژههای زیادی وجود دارند که از این نسخه پشتیبانی میکنند.
457
00:24:49,390 –> 00:24:52,180
پایدار بنابراین یک
458
00:24:52,180 –> 00:24:54,520
چراغ DF Lib CQ برای یک نور CQ وجود دارد.
459
00:24:54,520 –> 00:24:58,600
PostgreSQL بنابراین DB برای
460
00:24:58,600 –> 00:25:02,170
پایگاههای داده صابون