در این مطلب، ویدئو علم داده در ArcGIS با استفاده از Python و R آسان شده است با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,390 –> 00:00:03,000
علم داده که با استفاده از Python در سینه های ما آسان شده است
2
00:00:03,000 –> 00:00:05,850
، دومین
3
00:00:05,850 –> 00:00:08,599
پیشنهاد جلسه مذکور است که
4
00:00:08,599 –> 00:00:11,040
قبلاً از جلسه اول پاسخ بسیار خوبی
5
00:00:11,040 –> 00:00:13,049
داشتیم، فکر می کنم جلسه آخر
6
00:00:13,049 –> 00:00:15,269
را با بیان این موضوع شروع کردیم و واقعاً به
7
00:00:15,269 –> 00:00:17,490
نوعی به ما باز می گردد که این
8
00:00:17,490 –> 00:00:18,779
حقیقت است که weeba
9
00:00:18,779 –> 00:00:21,990
گفتیم اگر در زمینه
10
00:00:21,990 –> 00:00:24,449
علم داده و تجزیه و تحلیل یا
11
00:00:24,449 –> 00:00:27,449
در پایتون بسیار باتجربه هستید یا در بازوی پایتون نیستید و
12
00:00:27,449 –> 00:00:30,420
تازه کار هستید، می توانید از
13
00:00:30,420 –> 00:00:32,940
این دوره از این جلسه بهره های زیادی
14
00:00:32,940 –> 00:00:35,040
ببرید. احساس میکنم باید
15
00:00:35,040 –> 00:00:36,329
کاملاً همه چیزهایی را که ما میخواهیم
16
00:00:36,329 –> 00:00:38,489
هزاران لینک برای شما ارائه کنیم را درک کنید که میتوانید آنها
17
00:00:38,489 –> 00:00:40,140
را یادداشت کنید و میتوانید به عقب برگردید و ما
18
00:00:40,140 –> 00:00:42,090
احساس میکنیم اسناد ما
19
00:00:42,090 –> 00:00:45,329
واقعاً به شما کمک خواهد کرد و ما نیز هستیم و
20
00:00:45,329 –> 00:00:46,800
ما داریم کارتها
21
00:00:46,800 –> 00:00:49,739
و آدرسهای ایمیل ما را بیرغبتی با ما تماس بگیرید تا
22
00:00:49,739 –> 00:00:51,739
در صورت گیرکردن در این مشکلات به شما کمک کنیم.
23
00:00:51,739 –> 00:00:53,340
24
00:00:53,340 –> 00:00:56,309
25
00:00:56,309 –> 00:00:58,500
26
00:00:58,500 –> 00:01:00,690
27
00:01:00,690 –> 00:01:03,170
قبل
28
00:01:03,170 –> 00:01:06,000
از این، یک جلسه ناهار بود و
29
00:01:06,000 –> 00:01:08,689
شاید 30 نفر در آنجا بودند و
30
00:01:08,689 –> 00:01:11,130
مردم
31
00:01:11,130 –> 00:01:13,049
از زمانی که می دانید برای مدت طولانی ما
32
00:01:13,049 –> 00:01:15,119
آن را چیزی متفاوت می نامیدیم، علم داده انجام می دهند، اما کاملاً
33
00:01:15,119 –> 00:01:17,880
واضح است که با گذشت زمان روی داده ها
34
00:01:17,880 –> 00:01:20,549
35
00:01:20,549 –> 00:01:22,530
36
00:01:22,530 –> 00:01:24,570
37
00:01:24,570 –> 00:01:27,000
به دلیل قدرت محاسباتی که
38
00:01:27,000 –> 00:01:29,460
داریم، تکنیکها سریعتر و سریعتر و بهتر و بهتر میشوند، اما چیزی که به نظر من
39
00:01:29,460 –> 00:01:32,850
جذابتر است این است که افراد بیشتر و بیشتری
40
00:01:32,850 –> 00:01:35,549
از انجام علم داده نمیترسند. به طوری
41
00:01:35,549 –> 00:01:37,229
که افراد بیشتری وارد این
42
00:01:37,229 –> 00:01:39,600
بازار میشوند که عادت کردهاند مردم
43
00:01:39,600 –> 00:01:41,520
از ریاضیات و انجام
44
00:01:41,520 –> 00:01:43,170
تجزیه و تحلیل میترسند و به نظرم میرسد
45
00:01:43,170 –> 00:01:45,119
که افراد بیشتری
46
00:01:45,119 –> 00:01:47,460
در مورد انجام تجزیه و تحلیل هیجان زده میشوند و دیدن آن
47
00:01:47,460 –> 00:01:50,009
برای من جذاب و بسیار هیجانانگیز است.
48
00:01:50,009 –> 00:01:52,079
جایی که این موضوع در طول سالها اتفاق افتاده است،
49
00:01:52,079 –> 00:01:54,210
بنابراین تکنیکها و روشها
50
00:01:54,210 –> 00:01:55,829
در طول سالها
51
00:01:55,829 –> 00:01:58,590
در طیف گستردهای از رشتهها به پیشرفت خود ادامه میدهند و
52
00:01:58,590 –> 00:02:00,600
دوباره ما اکنون در معرض یک
53
00:02:00,600 –> 00:02:04,020
رویداد دائمی هستیم. اکنون با کاهش حجم دادهها برای
54
00:02:04,020 –> 00:02:06,540
rjs برای تجزیه و تحلیل اصلی خود و مواردی
55
00:02:06,540 –> 00:02:08,910
مانند آمارهای جغرافیایی آمار فضایی و
56
00:02:08,910 –> 00:02:12,690
تحلیلگر فضایی، بر ابزارهای اصلی تمرکز
57
00:02:12,690 –> 00:02:13,530
58
00:02:13,530 –> 00:02:15,660
میکنیم که بیشترین سود را برای شما به ارمغان میآورند، اگر
59
00:02:15,660 –> 00:02:18,150
متوجه شوید که در طول سال به Q گوش میدهیم.
60
00:02:18,150 –> 00:02:20,490
کنفرانس کاربر
61
00:02:20,490 –> 00:02:22,890
و و از طریق انجمن ها و آنچه شما
62
00:02:22,890 –> 00:02:25,470
از طریق میز پشتیبانی ما دارید و ما در مورد
63
00:02:25,470 –> 00:02:27,630
تکنیک های مختلفی که باید
64
00:02:27,630 –> 00:02:29,100
در نرم افزار وجود داشته باشد می شنویم و تعداد زیادی از
65
00:02:29,100 –> 00:02:30,600
آنها وجود دارد و مردم می گویند که می دانید این
66
00:02:30,600 –> 00:02:31,739
باید در آنجا وجود داشته باشد. قادر
67
00:02:31,739 –> 00:02:33,630
به حل این روش شناسی باید باشید
68
00:02:33,630 –> 00:02:35,340
رفیق این چیزی است که شما
69
00:02:35,340 –> 00:02:37,200
باید در این زمینه باشید و کاری که ما باید
70
00:02:37,200 –> 00:02:38,790
انجام دهیم این است که باید میزان
71
00:02:38,790 –> 00:02:40,680
سرمایه انسانی و زمانی را که در اختیار داریم بسنجیم و
72
00:02:40,680 –> 00:02:42,900
باید تصمیم بگیریم که چه چیزی این است
73
00:02:42,900 –> 00:02:45,959
که بیشترین استفاده را داشته باشد چه تکنیکی
74
00:02:45,959 –> 00:02:47,850
بیشترین مشکلات را حل می کند و
75
00:02:47,850 –> 00:02:49,739
وقتی این تصمیم را می گیریم می
76
00:02:49,739 –> 00:02:51,269
خواهیم مطمئن شویم که نسخه ما
77
00:02:51,269 –> 00:02:52,709
بهترین است که در آنجا
78
00:02:52,709 –> 00:02:54,330
خواهید فهمید که سریع ترین خواهد بود و رفتن
79
00:02:54,330 –> 00:02:55,800
خوبترین سند و درک آسانترین سند باشد،
80
00:02:55,800 –> 00:02:57,750
ما به آن
81
00:02:57,750 –> 00:02:59,580
افتخار میکنیم، اما احمقانه است که
82
00:02:59,580 –> 00:03:01,380
با شما بچهها با همه
83
00:03:01,380 –> 00:03:02,640
تخصصهای متفاوتتان و همه کارهای متفاوتی
84
00:03:02,640 –> 00:03:05,220
که شما انجام میدهید فکر کنیم که بتوانیم
85
00:03:05,220 –> 00:03:07,830
همه چیز را پوشش دهیم. نمیدانی و چیزهایی
86
00:03:07,830 –> 00:03:09,780
که خیلی سریع هستند. نوع چیزها خیلی سریع در حال
87
00:03:09,780 –> 00:03:11,430
آمدن هستند تکنیکها آنقدر سریع به
88
00:03:11,430 –> 00:03:13,350
بازار میآیند که ما نمیتوانیم این کار را انجام دهیم، پس چگونه این کار را
89
00:03:13,350 –> 00:03:16,319
انجام میدهید چگونه به کاربران کمک میکنید به
90
00:03:16,319 –> 00:03:18,180
خودشان کمک کنند و این کار را از طریق یکپارچهسازی انجام میدهید.
91
00:03:18,180 –> 00:03:19,769
استراتژی، بنابراین شما این کار را
92
00:03:19,769 –> 00:03:22,980
از طریق زبان های برنامه نویسی مانند
93
00:03:22,980 –> 00:03:24,870
پایتون انجام دهید و اکنون پایتون ها
94
00:03:24,870 –> 00:03:27,209
رابط اسکریپت نویسی ما برای سال ها بوده است و ما در
95
00:03:27,209 –> 00:03:28,650
مورد استفاده از Python Arland صحبت خواهیم کرد.
96
00:03:28,650 –> 00:03:30,480
97
00:03:30,480 –> 00:03:33,630
98
00:03:33,630 –> 00:03:37,860
و پایتون دست به دست هم می دهند
99
00:03:37,860 –> 00:03:40,140
که می دانید ما در مورد مزیت های زیادی صحبت خواهیم کرد
100
00:03:40,140 –> 00:03:41,910
101
00:03:41,910 –> 00:03:44,100
و بنابراین دوباره تصمیم می گیرید که
102
00:03:44,100 –> 00:03:46,320
چه زبانی
103
00:03:46,320 –> 00:03:48,299
برای شما در بسیاری از موارد منطقی است.
104
00:03:48,299 –> 00:03:51,359
کیس من استفاده میکنم بنابراین جامعه
105
00:03:51,359 –> 00:03:53,940
از
106
00:03:53,940 –> 00:03:55,920
تکنیک های بسیار گسترده تا تکنیک های بسیار خاص گسترده است،
107
00:03:55,920 –> 00:03:58,579
چه در حال مطالعه باشید، چه
108
00:03:58,579 –> 00:04:01,650
می دانید توزیع گونه های جلبک
109
00:04:01,650 –> 00:04:04,890
روی سنگ ها و MLA است یا چیزی
110
00:04:04,890 –> 00:04:08,760
در مقابل رشد اقتصادی و در
111
00:04:08,760 –> 00:04:12,030
آمریکای مرکزی این تکنیک ها به قدری سریع
112
00:04:12,030 –> 00:04:13,920
هستیم که باید راهی داشته باشیم
113
00:04:13,920 –> 00:04:16,168
تا به شما توانایی انجام آن
114
00:04:16,168 –> 00:04:18,779
تحلیل را در سینه خود بدهیم
115
00:04:18,779 –> 00:04:21,418
تا کسی از دانشگاه
116
00:04:21,418 –> 00:04:24,870
مینیاپولیس یا از هاروارد
117
00:04:24,870 –> 00:04:25,979
عبور کند و تکنیکی را که در حال
118
00:04:25,979 –> 00:04:26,550
انجام آن است بیابد. برای
119
00:04:26,550 –> 00:04:28,530
نوشتن آن در پایتون، آنها می خواهند آن را در زبان ما بنویسند،
120
00:04:28,530 –> 00:04:30,000
باید آن را دریافت کنید، باید
121
00:04:30,000 –> 00:04:31,680
بتوانید آن تکنیک را دریافت کنید و آن را در ArcGIS اجرا کنید
122
00:04:31,680 –> 00:04:33,810
و تا زمانی که از
123
00:04:33,810 –> 00:04:35,610
این دو زبان استفاده می کنند، می توانید انجام
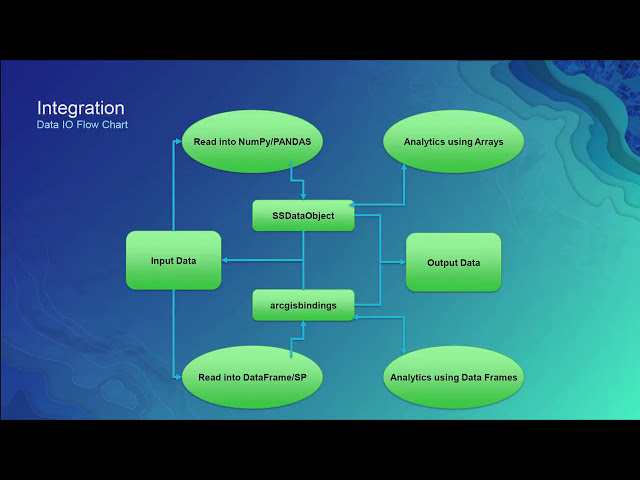
124
00:04:35,610 –> 00:04:38,550
دهید. جامعه علم داده
125
00:04:38,550 –> 00:04:39,750
در پایتون به
126
00:04:39,750 –> 00:04:42,780
نظر می رسد بسیار زیبا است، بسیار بالغ
127
00:04:42,780 –> 00:04:44,699
است، مدت زیادی است که وجود داشته است،
128
00:04:44,699 –> 00:04:47,159
ماژول های زیادی به اندازه یک واقعیت افزوده وجود ندارد، اما
129
00:04:47,159 –> 00:04:49,199
ماژول های بسیار بالغی وجود دارد که ماژول ها و
130
00:04:49,199 –> 00:04:51,479
پایتون در اینجا تمایل زیادی به داشتن تعداد زیادی ماژول دارند.
131
00:04:51,479 –> 00:04:52,860
تکنیکهایی که در آنجا وجود دارد،
132
00:04:52,860 –> 00:04:56,280
بهعنوان مثال scikit-learn دارای
133
00:04:56,280 –> 00:04:58,620
هفت دسته مختلف
134
00:04:58,620 –> 00:05:02,069
یادگیری ماشینی است و هر کدام دارای 12 مدل
135
00:05:02,069 –> 00:05:04,229
در خود هستند، بنابراین دارای تعداد
136
00:05:04,229 –> 00:05:05,940
زیادی چیزهای مختلف است، در حالی که در ما گاهی اوقات
137
00:05:05,940 –> 00:05:09,150
برخی از ماژولها را دریافت میکنید که فقط 5
138
00:05:09,150 –> 00:05:12,599
یا 6 مورد دارند. تکنیکها اما با توجه به اینکه
139
00:05:12,599 –> 00:05:16,050
R آنقدر تکنیکهای مختلف دارد که
140
00:05:16,050 –> 00:05:17,940
شما فقط باید ماژولهای مختلفی را انتخاب
141
00:05:17,940 –> 00:05:20,250
کنید که به پایتون نیاز دارید.
142
00:05:20,250 –> 00:05:21,840
143
00:05:21,840 –> 00:05:24,840
144
00:05:24,840 –> 00:05:27,000
145
00:05:27,000 –> 00:05:29,729
بنابراین اگر
146
00:05:29,729 –> 00:05:31,680
کد دیگری پیدا کردید که از
147
00:05:31,680 –> 00:05:33,900
جاوا یا کد دیگری
148
00:05:33,900 –> 00:05:37,620
استفاده میکند که از c++ استفاده میکند، میتوانید از پایتون برای تعامل
149
00:05:37,620 –> 00:05:39,120
با آن استفاده کنید و چون میتوانید این کار را انجام دهید
150
00:05:39,120 –> 00:05:40,889
زیرا پایتون با سینه
151
00:05:40,889 –> 00:05:43,229
ما تعامل دارد، میتوانید با آن تعامل داشته باشید. زبان، بنابراین
152
00:05:43,229 –> 00:05:44,550
اگر چیزی داشته باشم که به
153
00:05:44,550 –> 00:05:47,099
جاوا زنگ بزند، شعر اسکریپت را می نویسم پایتون،
154
00:05:47,099 –> 00:05:49,169
ماژول پایتون، جاوا را صدا می کند،
155
00:05:49,169 –> 00:05:50,909
هر کاری را که باید انجام دهد، برمی گردد و
156
00:05:50,909 –> 00:05:53,909
پایتون به GP fin کمک می کند. کار خوب است، بنابراین
157
00:05:53,909 –> 00:05:55,860
این چیزی است که در مورد پایتون عالی است،
158
00:05:55,860 –> 00:05:57,930
این واقعاً یک زبان چسب طاقتفرسا محسوب میشود،
159
00:05:57,930 –> 00:06:01,500
اکنون نصب همه این ماژولها، این 60
160
00:06:01,500 –> 00:06:04,080
ماژول تابستانی، اکنون برای شما بسیار آسان است
161
00:06:04,080 –> 00:06:07,650
و نصب آن حرفهای است، زیرا ما Conda را اضافه کردهایم
162
00:06:07,650 –> 00:06:09,840
، اساساً یا در برنامهای است
163
00:06:09,840 –> 00:06:11,190
که میروید. به نقطه و روی
164
00:06:11,190 –> 00:06:13,919
روش شناسی کلیک کنید تا بگید من یک بسته B
165
00:06:13,919 –> 00:06:16,469
و C می خواهم یا در خط فرمانی که
166
00:06:16,469 –> 00:06:19,500
انجام می دهید Conda install scikit-learn Conda
167
00:06:19,500 –> 00:06:23,550
نصب هر چیزی خوب است برای
168
00:06:23,550 –> 00:06:26,940
کاربران دسکتاپ شما خیلی ساده نیست
169
00:06:26,940 –> 00:06:29,279
و این به همین دلیل است ما به
170
00:06:29,279 –> 00:06:32,190
Conda رفتیم این یک نقطه دردناک بزرگ در
171
00:06:32,190 –> 00:06:35,039
ماژول های خاصی است که به کامپایلر C یا Fortran نیاز ندارند،
172
00:06:35,039 –> 00:06:37,000
173
00:06:37,000 –> 00:06:39,520
می توانید آن ها را فقط
174
00:06:39,520 –> 00:06:43,140
از طریق یک مسیر از طریق دریافت SVN یا pip نصب کنید،
175
00:06:43,140 –> 00:06:46,150
اما مواردی که به کامپایلر C نیاز دارند،
176
00:06:46,150 –> 00:06:49,810
به شما بستگی دارد. برای حل و فصل و
177
00:06:49,810 –> 00:06:51,580
بسیاری از اوقات مردم نمی توانند این کار را انجام دهند و
178
00:06:51,580 –> 00:06:53,560
بسیاری از اوقات
179
00:06:53,560 –> 00:06:56,050
با نسخه پایتون شما سازگار نیست و بنابراین بسیاری
180
00:06:56,050 –> 00:06:58,180
از اوقات مردم به این
181
00:06:58,180 –> 00:07:02,530
نسخه های ساخته شده از پیش کامپایل ماژول های پایتون و
182
00:07:02,530 –> 00:07:04,960
کریستوفر مراجعه می کنند. gall cat UC Irvine به اندازه کافی خوب بوده است که آن ها
183
00:07:04,960 –> 00:07:07,240
را ایجاد کرده و آنها را حفظ کند،
184
00:07:07,240 –> 00:07:11,080
بنابراین اگر بسته ای پیدا کردید که
185
00:07:11,080 –> 00:07:12,730
به قدرت سکوم نیاز دارد و
186
00:07:12,730 –> 00:07:14,830
با نسخه دسکتاپ شما کار نمی کند، به
187
00:07:14,830 –> 00:07:18,460
آن وب سایت اینجا در UC Irvine بروید و او
188
00:07:18,460 –> 00:07:20,470
احتمالاً نسخه ای خواهد داشت که او
189
00:07:20,470 –> 00:07:23,770
برای شما ساخته و کامپایل شده است، بنابراین جامعه علم داده روزانه
190
00:07:23,770 –> 00:07:26,050
و ما بیش از
191
00:07:26,050 –> 00:07:28,780
6000 بسته دارد، بنابراین فکر کنید که
192
00:07:28,780 –> 00:07:32,500
پایتون 60 یا 70 ماژول بالغ دارد که می دانید
193
00:07:32,500 –> 00:07:36,100
ماژول های بسیار قابل توجهی دارد و ما 6 ماژول
194
00:07:36,100 –> 00:07:38,310
بیش از شش هزار مورد در Cran فهرست شده است،
195
00:07:38,310 –> 00:07:41,080
اکنون این همان است
196
00:07:41,080 –> 00:07:44,590
پرکاربردترین نرمافزار آماری موجود در جهان
197
00:07:44,590 –> 00:07:47,650
و همچنین هنوز هم سریعترین رشد را
198
00:07:47,650 –> 00:07:51,430
دارد، بنابراین R قانونی است و
199
00:07:51,430 –> 00:07:54,700
در سراسر دولت مورد استفاده قرار میگیرد، زمانی که ما افرادی را داریم که همیشه
200
00:07:54,700 –> 00:07:56,620
به هر دانشگاه
201
00:07:56,620 –> 00:07:59,460
میآیند و همیشه از دانشگاههای ما و دانشگاههای ما استفاده
202
00:07:59,460 –> 00:08:01,750
میکنند. دولت در
203
00:08:01,750 –> 00:08:04,960
صنعت بزرگ و آنها در حال مطالعه همه چیز هستند،
204
00:08:04,960 –> 00:08:07,960
از امور مالی گرفته تا آمار و
205
00:08:07,960 –> 00:08:11,890
علوم زیستی، صنعت گسترده گسترده
206
00:08:11,890 –> 00:08:14,970
و همچنین همه این
207
00:08:14,970 –> 00:08:20,770
موارد خاص خیلی
208
00:08:20,770 –> 00:08:23,710
تاثیرگذار است و بنابراین اگر
209
00:08:23,710 –> 00:08:27,460
میخواهید من را پیدا کنید، محیط
210
00:08:27,460 –> 00:08:30,419
یک درخت و تأثیر آن را میدانید،
211
00:08:30,419 –> 00:08:34,419
توزیع لاماها را میدانید و در پرو،
212
00:08:34,419 –> 00:08:36,190
ممکن است بتوانید چیزی را پیدا کنید که این
213
00:08:36,190 –> 00:08:38,380
کار را انجام میدهد و این کار را انجام میدهد. ماژول های زیادی دارد،
214
00:08:38,380 –> 00:08:41,429
بنابراین خریدار آن مراقب باشد، اما
215
00:08:41,429 –> 00:08:44,350
در حالی که شما برخی از بهترین ذهن ها را
216
00:08:44,350 –> 00:08:47,130
در جهان دارید با
217
00:08:47,130 –> 00:08:50,140
روش های باورنکردنی آمار آمار GL
218
00:08:50,140 –> 00:08:52,000
به شما نشان می دهد که چگونه
219
00:08:52,000 –> 00:08:54,730
همه چیز را در زیر نور خورشید اندازه گیری کنید، این به شما بستگی
220
00:08:54,730 –> 00:08:56,710
دارد که مطمئن شوید که آیا چنین است. در
221
00:08:56,710 –> 00:08:59,200
پایتون یا R که میسنجید چه کسی
222
00:08:59,200 –> 00:09:01,780
آن کد را نوشته است و میدانید
223
00:09:01,780 –> 00:09:03,610
که شاید آنها
224
00:09:03,610 –> 00:09:04,990
علم دارند که از آن پشتیبانی
225
00:09:04,990 –> 00:09:06,880
میکنند، اما منتشر کردهاند، زیرا با دریافت آن
226
00:09:06,880 –> 00:09:08,470
، شهرت خود را به خطر میاندازید.
227
00:09:08,470 –> 00:09:10,300
ماژول و بگویید که این
228
00:09:10,300 –> 00:09:12,280
پاسخ درست است، بنابراین مطمئن شوید که تحقیقات خود را انجام دهید
229
00:09:12,280 –> 00:09:16,990
تا بهترین نبرد
230
00:09:16,990 –> 00:09:18,190
بین گروهها کدام
231
00:09:18,190 –> 00:09:20,290
232
00:09:20,290 –> 00:09:23,320
است. همه چیز
233
00:09:23,320 –> 00:09:25,750
در مورد R و جامعه داده های بزرگ و
234
00:09:25,750 –> 00:09:27,700
در جامعه علم داده اخیراً
235
00:09:27,700 –> 00:09:29,890
پایتون شروع به پشت سر گذاشتن دوباره
236
00:09:29,890 –> 00:09:32,050
پایتون کرده است.
237
00:09:32,050 –> 00:09:34,000
238
00:09:34,000 –> 00:09:35,290
239
00:09:35,290 –> 00:09:38,680
240
00:09:38,680 –> 00:09:41,020
دلایل دیگر را در درجه اول میتوانم
241
00:09:41,020 –> 00:09:43,110
بخش زبان چسب را نیز بگویم، اما
242
00:09:43,110 –> 00:09:45,820
مزایا و معایبی وجود دارد که
243
00:09:45,820 –> 00:09:47,170
اگر به این وبسایت بروید نمیتوانم همه آنها را انتخاب
244
00:09:47,170 –> 00:09:48,730
کنم، فکر میکنم بسیار آموزشی است
245
00:09:48,730 –> 00:09:51,280
و ارزش دیدن را دارد که نکات
246
00:09:51,280 –> 00:09:53,230
مثبت زیادی دارند و در مورد اینکه کدام یک
247
00:09:53,230 –> 00:09:55,900
را میخواهید انتخاب کنید، بنابراین R مجموعه گستردهتری
248
00:09:55,900 –> 00:09:58,750
از متدولوژیها را در مجموعه وسیعتری
249
00:09:58,750 –> 00:10:02,860
از رشتههای خاص دارد، پایتون یک
250
00:10:02,860 –> 00:10:05,350
251
00:10:05,350 –> 00:10:06,880
زبان برنامهنویسی با عملکرد کاملتر است، بنابراین اگر با
252
00:10:06,880 –> 00:10:10,980
مواردی مانند رابطهای رابط کاربری گرافیکی یا رشتههایی سر و
253
00:10:10,980 –> 00:10:13,270
کار دارید، مانند اینکه میخواهید با رشته ها در
254
00:10:13,270 –> 00:10:15,550
متن
255
00:10:15,550 –> 00:10:17,710
برخورد کنید، اگر با آمار و ریاضیات خالص سر و کار دارید، پایتون بهتر از R است
256
00:10:17,710 –> 00:10:19,690
و خیلی اوقات
257
00:10:19,690 –> 00:10:22,720
R بهتر می شود، بنابراین باید در
258
00:10:22,720 –> 00:10:24,870
نظر بگیرید که من فقط یک fe را لیست کردم. در اینجا،
259
00:10:24,870 –> 00:10:27,490
اما در هر کدام که انتخاب می کنید
260
00:10:27,490 –> 00:10:29,830
، مهم است که توجه داشته باشید که قوس s را
261
00:10:29,830 –> 00:10:31,930
پوشش داده اید، می توانید یکی را انتخاب کنید یا
262
00:10:31,930 –> 00:10:34,930
می توانید هر دو را انتخاب کنید، بنابراین در اینجا چند
263
00:10:34,930 –> 00:10:38,170
نمونه از pycelle یک
264
00:10:38,170 –> 00:10:43,030
کتابخانه تجزیه و تحلیل فضایی پایتون وجود دارد که برای مدتی در ASU
265
00:10:43,030 –> 00:10:45,520
بوده است. به دو
266
00:10:45,520 –> 00:10:47,380
مرتع مختلف رفتند، اما لوک آنسل و
267
00:10:47,380 –> 00:10:49,810
سرجیو ری و دیگران این
268
00:10:49,810 –> 00:10:51,970
تکنیک های تحلیل آماری پیشرفته را ایجاد کرده اند
269
00:10:51,970 –> 00:10:54,310
و مجوز BSD این نرم افزار منبع باز است
270
00:10:54,310 –> 00:10:56,470
و ما با آنها کار می
271
00:10:56,470 –> 00:10:59,320
کنیم تا در جعبه ابزار متن باز ایجاد کنیم که
272
00:10:59,320 –> 00:11:01,720
اقتصاد سنجی فضایی آنها
273
00:11:01,720 –> 00:11:03,220
را پیشرفته می نامد. ما به نوعی معیارهای سنجش را انجام
274
00:11:03,220 –> 00:11:04,060
275
00:11:04,060 –> 00:11:05,890
میدهیم و شما 40 سال است که این کار را انجام میدهید
276
00:11:05,890 –> 00:11:08,230
چرا یک زوری چرخ را دوباره اختراع میکند،
277
00:11:08,230 –> 00:11:10,960
او در حال حاضر بهترین یا یکی
278
00:11:10,960 –> 00:11:12,670
از پدرخواندهها در این زمینه است، پس
279
00:11:12,670 –> 00:11:15,640
چرا از کارهایی که قبلاً انجام میدهد به درستی استفاده
280
00:11:15,640 –> 00:11:18,100
نمیکند. یک گروه GIS و
281
00:11:18,100 –> 00:11:21,100
بنابراین با تلاقی با ما،
282
00:11:21,100 –> 00:11:23,770
آنها یک موتور GIS برای فراخوانی
283
00:11:23,770 –> 00:11:25,180
متدولوژی های خود دریافت می کنند، آنها یک
284
00:11:25,180 –> 00:11:27,640
رابط کاربری گرافیکی با کاربری آسان و چند
285
00:11:27,640 –> 00:11:29,650
چیز دیگر را دریافت می کنند. و سپس چیزی که به دست می آوریم تکنیک
286
00:11:29,650 –> 00:11:31,180
های پیشرفته اقتصاد سنجی هستند
287
00:11:31,180 –> 00:11:33,010
و من فکر می کنم این یک مثال بسیار خوب است
288
00:11:33,010 –> 00:11:36,030
از اینکه چگونه نرم افزارهای سودآور و
289
00:11:36,030 –> 00:11:38,620
منبع باز می توانند
290
00:11:38,620 –> 00:11:41,860
ارزش افزوده ای را برای هر دو گروه ارائه دهند.
291
00:11:41,860 –> 00:11:44,020
جعبه ابزار نمونه ما نمونه ای از جایی است که ما
292
00:11:44,020 –> 00:11:46,930
بیرون رفتیم. و ما کنستانتین کتابی
293
00:11:46,930 –> 00:11:49,420
در مورد آمار فضایی داشتیم و او
294
00:11:49,420 –> 00:11:50,860
روشهایی داشت که فکر میکردیم
295
00:11:50,860 –> 00:11:52,990
مهم هستند و کاری که ما انجام دادیم این است که
296
00:11:52,990 –> 00:11:55,330
راهش این است که میتوانید
297
00:11:55,330 –> 00:11:57,370
با ما تماس بگیرید تا
298
00:11:57,370 –> 00:12:00,790
تجزیه و تحلیل آماری پیشرفته انجام دهیم و آنها را با رابط کاربری گرافیکی آسان انجام دهیم.
299
00:12:00,790 –> 00:12:04,000
ابزارهای اسکریپت بنابراین کاری که آن جعبه ابزار نمونه
300
00:12:04,000 –> 00:12:06,850
انجام می دهد این است که طرحی را که شما
301
00:12:06,850 –> 00:12:08,650
آن را انتخاب می کنید به شما می دهد و می گویید نگاه کنید آنها
302
00:12:08,650 –> 00:12:10,720
این کار را انجام دادند و ممکن است بسیار پیشرفته
303
00:12:10,720 –> 00:12:12,970
باشد، شاید گزینه شما فقط چند گزینه یا
304
00:12:12,970 –> 00:12:14,380
هر چیز دیگری حتی پیشرفته تر باشد،
305
00:12:14,380 –> 00:12:16,360
اما صرف نظر از آن
306
00:12:16,360 –> 00:12:18,280
طرح اولیه را به شما می دهد و به شما اسکلتی
307
00:12:18,280 –> 00:12:20,350
می دهد که چگونه کار خود را انجام می دهید، اوه آنها
308
00:12:20,350 –> 00:12:23,830
از شما ورودی های B C و D یا یک دو
309
00:12:23,830 –> 00:12:26,020
سه و چهار و من یکی دو
310
00:12:26,020 –> 00:12:28,120
سه و چهار خود را دارم و سپس آنها این کار را انجام دادند تا
311
00:12:28,120 –> 00:12:29,590
متوجه شوند. دادهها را انجام دادند و سپس آنها تجزیه و تحلیل خود را انجام دادند
312
00:12:29,590 –> 00:12:31,630
و سپس آنها را به درستی نشان دادند،
313
00:12:31,630 –> 00:12:34,150
بنابراین شما از آن جعبه ابزار نمونه برای کمک به
314
00:12:34,150 –> 00:12:37,420
طراحی جعبه ابزار خود استفاده کنید.
315
00:12:37,420 –> 00:12:39,310
316
00:12:39,310 –> 00:12:42,070
317
00:12:42,070 –> 00:12:44,560
318
00:12:44,560 –> 00:12:46,960
اما من فکر کردم که آن را در آنجا
319
00:12:46,960 –> 00:12:48,700
در جلسه عمومی قرار دادهام و امیدواریم که
320
00:12:48,700 –> 00:12:50,830
ظاهر شود،
321
00:12:50,830 –> 00:12:53,410
این نمونهای است از جایی که VM علم داده
322
00:12:53,410 –> 00:12:56,740
یک ماشین مجازی دارای Conda است و نسخههای R یا
323
00:12:56,740 –> 00:12:59,260
مایکروسافت سرور و سرور ما را دارد.
324
00:12:59,260 –> 00:13:03,100
R را در آن باز کنید و ما
325
00:13:03,100 –> 00:13:05,260
آن را با آنها قادر کردیم و اکنون ما یک
326
00:13:05,260 –> 00:13:07,540
ماشین مجازی علوم داده مایکروسافت با قابلیت جغرافیایی فعال داشتیم که در آن
327
00:13:07,540 –> 00:13:10,360
از همان Conda استفاده می کنیم و از همان R استفاده می
328
00:13:10,360 –> 00:13:12,430
کنیم و همه اینها به طور هماهنگ کار می کند و
329
00:13:12,430 –> 00:13:14,710
امیدوارم مواردی مانند این پروژه ها
330
00:13:14,710 –> 00:13:17,800
ادامه پیدا کند. در طول زمان تکامل پیدا
331
00:13:17,800 –> 00:13:20,949
کنید، بنابراین ادغام بسیار آسان می شود بدون
332
00:13:20,949 –> 00:13:23,860
توجه به زبانی که برای
333
00:13:23,860 –> 00:13:25,300
کسانی از شما که سال ها با
334
00:13:25,300 –> 00:13:27,369
پایتون کار می کنند، می دانید که چقدر آسان است
335
00:13:27,369 –> 00:13:29,829
که یک ابزار اسکریپت ایجاد کنید، یک رابط رابط کاربری گرافیکی
336
00:13:29,829 –> 00:13:31,660
برای انجام آن وجود دارد، بنابراین شما انتخاب می کنید.
337
00:13:31,660 –> 00:13:33,850
پارامترها و سپس فایل PI را منبع می
338
00:13:33,850 –> 00:13:35,199
کنید که می خواهید ادامه دهید
339
00:13:35,199 –> 00:13:38,410
و در آن قرار دهید خوب و R همان است که
340
00:13:38,410 –> 00:13:41,170
دقیقاً همان کارها را انجام می دهید اما به جای
341
00:13:41,170 –> 00:13:43,329
منبعیابی یک فایل PI، یک فایل نقطه
342
00:13:43,329 –> 00:13:47,589
R را منبع می کنید، بنابراین هیچ فایلی وجود ندارد. بنابراین
343
00:13:47,589 –> 00:13:51,129
نحوه ایجاد آن ابزار اسکریپت
344
00:13:51,129 –> 00:13:53,439
کمی تفاوت در کد دارد
345
00:13:53,439 –> 00:13:55,899
زیرا ones و ones Python هستند، اما برای
346
00:13:55,899 –> 00:13:57,670
ایجاد آن ابزار برای دریافت
347
00:13:57,670 –> 00:14:01,259
پارامترها، پارامترها یکسان است،
348
00:14:01,259 –> 00:14:04,600
بنابراین ایجاد یک اسکریپت بسیار آسان
349
00:14:04,600 –> 00:14:06,429
است. ابزار و دقیقاً مشابه
350
00:14:06,429 –> 00:14:09,759
پایتون هستند، اکنون این واقعاً مهم است، این
351
00:14:09,759 –> 00:14:11,889
است که اگر یک چیز وجود دارد که از اینجا خارج میشوید،
352
00:14:11,889 –> 00:14:14,079
اگر میخواهید
353
00:14:14,079 –> 00:14:15,879
در پایتون برنامهنویسی کنید یا هنر
354
00:14:15,879 –> 00:14:16,869
دارید، باید از اینجا بیرون بروید و بدانید
355
00:14:16,869 –> 00:14:21,759
که این است. برای وارد کردن و خروج دادهها از
356
00:14:21,759 –> 00:14:24,369
پایتون یا R تقریباً
357
00:14:24,369 –> 00:14:27,610
همان متدولوژیهایی هستند که
358
00:14:27,610 –> 00:14:29,559
نحو کمی متفاوت دارند، اما این همان
359
00:14:29,559 –> 00:14:33,730
مفهومی است که شما پایتون دارید، یک
360
00:14:33,730 –> 00:14:37,629
شی داده SS دارید که اساساً کلاسی است
361
00:14:37,629 –> 00:14:40,779
که اطراف مکاننماهای دسترسی به دادهها
362
00:14:40,779 –> 00:14:43,299
و و چیزهای دیگر و سپس شما یک R
363
00:14:43,299 –> 00:14:45,339
شما اتصالات قفسه سینه ما را دارید و کاری که
364
00:14:45,339 –> 00:14:47,799
انجام می دهید این است که یک نمونه در اطراف یک کلاس آینده ایجاد می کنید
365
00:14:47,799 –> 00:14:49,809
و اساساً آن
366
00:14:49,809 –> 00:14:52,179
نمونه می گوید که چه چیزهایی در داخل
367
00:14:52,179 –> 00:14:53,350
آن وجود دارد و اساساً یک بسته بندی در اطراف است
368
00:14:53,350 –> 00:14:55,869
و می گوید شما فیلدهای B و C را می شناسید.
369
00:14:55,869 –> 00:14:57,759
این طرح آن است که
370
00:14:57,759 –> 00:14:59,290
مجموعه ای از انتخاب است که از این قبیل چیزها است و
371
00:14:59,290 –> 00:15:01,209
سپس وقتی می جوید وقتی می خواهید
372
00:15:01,209 –> 00:15:03,490
انتخاب کنید کدام زمینه را می خواهید انتخاب کنید،
373
00:15:03,490 –> 00:15:07,299
من می خواهم یا در R انتخاب کنم یا می خواهید
374
00:15:07,299 –> 00:15:09,610
داده ها و شی داده و
375
00:15:09,610 –> 00:15:11,319
آنچه را که هستید به دست آورید. gonna get یک عکس فوری
376
00:15:11,319 –> 00:15:15,399
از دادهها در پایتون یا یک R راست است، بنابراین
377
00:15:15,399 –> 00:15:17,049
بهجای اینکه مجبور باشیم با حلقهها
378
00:15:17,049 –> 00:15:20,439
و مکاننماها برای برداشتن دادهها سروکار داشته باشیم، به همین
379
00:15:20,439 –> 00:15:22,869
سادگی ارتباط برقرار
380
00:15:22,869 –> 00:15:24,610
میکنیم و دادهها را دریافت میکنیم و اینها فیلدهایی هستند که
381
00:15:24,610 –> 00:15:27,339
در پایتون میخواهید دریافت کنید. چیزهای موجود در
382
00:15:27,339 –> 00:15:29,079
آرایههای numpy یا آنها را در فریمهای داده پانداس دریافت میکنید
383
00:15:29,079 –> 00:15:30,819
و آیا شما
384
00:15:30,819 –> 00:15:32,769
چیزهایی در چارچوب دادهها هستید آنچه مهم است
385
00:15:32,769 –> 00:15:34,839
توجه داشته باشید این است که همه توابع تحلیلی
386
00:15:34,839 –> 00:15:37,569
در پایتون از آرایههای numpy مانند همه
387
00:15:37,569 –> 00:15:39,579
توابع تحلیلی استفاده میکنند و زیبا هستند.
388
00:15:39,579 –> 00:15:42,189
از فریم های داده بسیار استفاده می شود و بنابراین ایده
389
00:15:42,189 –> 00:15:44,169
اینجا این است که شما مجبور نیستید یک
390
00:15:44,169 –> 00:15:46,059
دسته کد بنویسید تا همه این حلقه ها را
391
00:15:46,059 –> 00:15:47,829
روی مکان نما بنویسید و نیازی نیست که
392
00:15:47,829 –> 00:15:49,989
آرایه های خالی یا لیست های خالی را
393
00:15:49,989 –> 00:15:51,789
ایجاد کنید که مقادیر را بسته بندی می کنید. برای هر ردیف
394
00:15:51,789 –> 00:15:53,439
در شما مجبور نیستید بگویید مو، آنها میشوند،
395
00:15:53,439 –> 00:15:55,149
رکوردهای بدی را در اینجا ثبت کنید که چه اتفاقی میافتد
396
00:15:55,149 –> 00:15:56,919
اگر یک راهبه یا چه چیزی باشد – شما اجازه میدهید
397
00:15:56,919 –> 00:15:59,019
شی داده یا بسته صحافی کار را
398
00:15:59,019 –> 00:16:02,019
انجام دهد تا آرایههای ناتوان را دریافت کنید یا
399
00:16:02,019 –> 00:16:04,359
فریم های داده مستقیماً
400
00:16:04,359 –> 00:16:06,639
تجزیه و تحلیل خود را انجام می دهید و اکنون یک
401
00:16:06,639 –> 00:16:08,949
آرایه numpy جدید دارید یا اکنون یک فیلد جدید
402
00:16:08,949 –> 00:16:11,559
برای اضافه کردن قاب داده خود دارید و سپس
403
00:16:11,559 –> 00:16:13,629
به شی داده یا هنرمندان binding اجازه می دهید
404
00:16:13,629 –> 00:16:15,669
کلاس ویژگی خروجی جدید را برای
405
00:16:15,669 –> 00:16:17,319
مکان نماهای خود بنویسند. برای شما در آنجا
406
00:16:17,319 –> 00:16:20,109
یا به ماژول ها اجازه می دهید کار را برای
407
00:16:20,109 –> 00:16:21,279
شما انجام
408
00:16:21,279 –> 00:16:23,589
دهند، بنابراین داده های i/o تبدیل به خطوط بسیار کمی
409
00:16:23,589 –> 00:16:25,539
از کد مانند دو سه خط کد در
410
00:16:25,539 –> 00:16:27,579
جلو و چند خط کد بیرون می شوند و
411
00:16:27,579 –> 00:16:31,059
سپس نگران وسط آن هستید.
412
00:16:31,059 –> 00:16:33,339
تجزیه و تحلیل را درست روی آرایه ها یا
413
00:16:33,339 –> 00:16:36,579
فریم های داده انجام دهید، پس این چه چیزی است k مانند
414
00:16:36,579 –> 00:16:40,359
تصویر بالا پایتون است که از
415
00:16:40,359 –> 00:16:43,419
آمار فضایی یا شی داده SS استفاده می کند و تصویر
416
00:16:43,419 –> 00:16:45,669
پایینی از اتصالات RJ استفاده می کند و
417
00:16:45,669 –> 00:16:47,139
آنها دوباره همان کار را انجام می دهند به
418
00:16:47,139 –> 00:16:48,850
همین دلیل متن را در آنجا قرار دادم
419
00:16:48,850 –> 00:16:51,819
و مجموعه داده را بارگذاری کردم و پایتون
420
00:16:51,819 –> 00:16:54,729
مقداردهی اولیه می شود و اشیاء داده SS برای آن
421
00:16:54,729 –> 00:16:57,459
کلاس ویژگی، سپس کاری که من می خواهم انجام
422
00:16:57,459 –> 00:16:59,679
دهم این است که داده هایی را به دست می آورم که
423
00:16:59,679 –> 00:17:01,779
ارتباط برقرار می کند و
424
00:17:01,779 –> 00:17:05,019
عکس فوری داده ها را می گیرم، اکنون شناسه
425
00:17:05,019 –> 00:17:07,898
من فیلد شناسه منحصر به فردی است که نمی خواهم. میخواهید
426
00:17:07,898 –> 00:17:12,579
بیش از حد وارد آن شوید، اما مکاننماها میتوانند
427
00:17:12,579 –> 00:17:14,319
ترتیب خواندن
428
00:17:14,319 –> 00:17:15,669
را با هم ترکیب کنند، بهخصوص اگر پایگاه جغرافیایی یا فایل شکل فایل نباشد،
429
00:17:15,669 –> 00:17:17,859
بنابراین شما به یک
430
00:17:17,859 –> 00:17:21,369
فیلد شناسه منحصربهفرد نیاز دارید تا بتوانید
431
00:17:21,369 –> 00:17:23,589
ترتیب و آرایهها را در مقابل شکل نگه
432
00:17:23,589 –> 00:17:26,980
دارید. از نام OID نیز استفاده کنید و
433
00:17:26,980 –> 00:17:30,190
کار خواهد کرد، بنابراین در این مورد من از
434
00:17:30,190 –> 00:17:32,860
رشته خودم به نام شناسه من استفاده می کنم و می خواهم رشد
435
00:17:32,860 –> 00:17:35,740
سرانه درآمد در سال 1970
436
00:17:35,740 –> 00:17:38,169
تراکم جمعیت در سال 1970 و درصد
437
00:17:38,169 –> 00:17:40,059
جمعیت بدون تحصیلات دبیرستانی در
438
00:17:40,059 –> 00:17:43,190
کالیفرنیا و غیره داشته باشم. من آن داده ها را به دست آوردم
439
00:17:43,190 –> 00:17:44,570
و سپس می خواهم من میخواهم
440
00:17:44,570 –> 00:17:46,640
یک قاب داده پاندا بسازم و
441
00:17:46,640 –> 00:17:48,890
پنج رکورد اول را در قفسه
442
00:17:48,890 –> 00:17:51,020
سینهمان چاپ کنم، همین کار را انجام میدهم اما از
443
00:17:51,020 –> 00:17:53,510
دستور open استفاده میکنم که
444
00:17:53,510 –> 00:17:54,770
ارتباط را برقرار میکند
445
00:17:54,770 –> 00:17:56,330
و کمی در مورد هزینههای آینده به من میگوید:
446
00:17:56,330 –> 00:17:58,370
فیلدهایی را مشخص می کند که چه طرحی دارید،
447
00:17:58,370 –> 00:18:00,680
اما من در واقع تا زمانی که انتخاب نکنم، داده را ندارم،
448
00:18:00,680 –> 00:18:04,160
بنابراین در این مورد
449
00:18:04,160 –> 00:18:07,190
، همان فیلدهای رشد شناسه را انتخاب می کنم و سپس
450
00:18:07,190 –> 00:18:11,510
سر قاب داده را چاپ
451
00:18:11,510 –> 00:18:13,910
می کنم حالا فرض کنید آن آرایه ها را بگیرم یا آن فریمهای داده را
452
00:18:13,910 –> 00:18:16,190
بیرون میآورم و Swisher
453
00:18:16,190 –> 00:18:18,770
Econometrics را اجرا میکنم یا چیز سادهای را اجرا میکنم
454
00:18:18,770 –> 00:18:21,380
مانند ایجاد چند اعداد تصادفی یا به
455
00:18:21,380 –> 00:18:23,960
من بگویید که چه مقادیری بالای ده هستند و
456
00:18:23,960 –> 00:18:26,120
یک آرایه بولی به من برمیگردانم و
457
00:18:26,120 –> 00:18:27,740
هر چیزی میتواند
458
00:18:27,740 –> 00:18:29,090
چیزی بسیار پیشرفته باشد.
459
00:18:29,090 –> 00:18:31,730
have یک آرایه جدید است و آن
460
00:18:31,730 –> 00:18:34,160
آرایه جدید به اندازه
461
00:18:34,160 –> 00:18:36,470
کلاس ویژگی ورودی شما است، زیرا
462
00:18:36,470 –> 00:18:38,560
برای هر شکل یک نتیجه
463
00:18:38,560 –> 00:18:42,500
دارید، بنابراین
464
00:18:42,500 –> 00:18:44,900
اگر از مکان نما استفاده می کنید، اکنون یک آرایه جدید خواهید داشت. e
465
00:18:44,900 –> 00:18:46,820
برای برقراری اتصال،
466
00:18:46,820 –> 00:18:49,670
فیلد را درست اضافه کنید و سپس اگر میخواهید
467
00:18:49,670 –> 00:18:51,140
مواردی را
468
00:18:51,140 –> 00:18:53,330
469
00:18:53,330 –> 00:18:55,040
470
00:18:55,040 –> 00:18:57,200
در حافظه خود وارد کنید و اگر از یک دوره درج استفاده میکنید، باید هر کدام را با یک مکاننما بهروزرسانی یا یک مکاننما درج کنید.
471
00:18:57,200 –> 00:18:58,220
شما باید همه
472
00:18:58,220 –> 00:18:59,870
فیلدها را دوباره اضافه کنید و باید
473
00:18:59,870 –> 00:19:01,550
همه چیز را وارد کنید و مطمئن شوید
474
00:19:01,550 –> 00:19:02,990
که ترتیب درست و همه
475
00:19:02,990 –> 00:19:05,870
چیزها را برخلاف این متدولوژی دارید، بنابراین
476
00:19:05,870 –> 00:19:08,030
برای شی داده باید یک فیلد کاندید ایجاد کنم.
477
00:19:08,030 –> 00:19:09,080
478
00:19:09,080 –> 00:19:11,450
آن را استاندارد معمولی می نامند، یک نوع
479
00:19:11,450 –> 00:19:14,330
آرایه دوگانه است و مقدار آن یک
480
00:19:14,330 –> 00:19:17,780
آرایه ناقص از نرمال های تصادفی است و من به
481
00:19:17,780 –> 00:19:20,180
آن یک میخ به نام عادی معمولی می
482
00:19:20,180 –> 00:19:22,010
دهم، آن را به یک فرهنگ لغت اضافه کنید و من این
483
00:19:22,010 –> 00:19:24,110
خروجی را به کلاس ویژگی جدید و آنچه
484
00:19:24,110 –> 00:19:26,420
که اشیاء داده می خواهند فراخوانی کنم. انجام این کار این
485
00:19:26,420 –> 00:19:29,240
است که اشکال را از ورودی هر
486
00:19:29,240 –> 00:19:32,450
فیلد دیگری که در فایلهای ضمیمه درخواست کردهام میگیرد،
487
00:19:32,450 –> 00:19:34,610
در این مورد رشد درآمد
488
00:19:34,610 –> 00:19:36,740
سرانه و نام جدید، اکنون متوجه یک
489
00:19:36,740 –> 00:19:38,540
نام جدید میشوید که وقتی من آن را خواندم، نام جدیدی را در
490
00:19:38,540 –> 00:19:40,670
حافظه نخواندم. داده ها در پس چیست
491
00:19:40,670 –> 00:19:42,650
درست این است که میتوانید هنگام ایجاد خروجی درست، فیلدهایی را
492
00:19:42,650 –> 00:19:44,060
از ورودی بگیرید که حتی در
493
00:19:44,060 –> 00:19:45,830
حافظه
494
00:19:45,830 –> 00:19:48,830
نبودند، به طوری که میتوانید حافظه را ذخیره کنید، بنابراین
495
00:19:48,830 –> 00:19:50,600
اساساً هر فیلدی را که
496
00:19:50,600 –> 00:19:52,490
میخواهم از ورودی بهعلاوه اشکال و
497
00:19:52,490 –> 00:19:54,500
هر فیلد جدید میگیرد. که میخواهم به آن اضافه کنم
498
00:19:54,500 –> 00:19:56,660
در این مورد به آن هنجار استاندارد
499
00:19:56,660 –> 00:19:58,760
میگویند و هیچ حلقه یا چیز دیگری
500
00:19:58,760 –> 00:20:00,800
وجود ندارد، همه کارها را برای شما در
501
00:20:00,800 –> 00:20:02,420
تنظیمات غیر یا تمام تنظیمات محیطی انجام میدهد، بنابراین فقط
502
00:20:02,420 –> 00:20:04,280
چهار خط کد در اینجا برای ایجاد یک
503
00:20:04,280 –> 00:20:06,440
کاملا جدید کلاس ویژگی که همه
504
00:20:06,440 –> 00:20:08,420
آن فیلدها را در خود دارد و مطمئن شوید
505
00:20:08,420 –> 00:20:11,240
که مقدار آرایه با
506
00:20:11,240 –> 00:20:13,730
شکل صحیح در R مطابقت دارد، حتی سادهتر است ببینید
507
00:20:13,730 –> 00:20:15,710
که آن API چقدر آسان است، من
508
00:20:15,710 –> 00:20:18,740
قبلاً یک قاب داده در R دارم و واقعاً یک
509
00:20:18,740 –> 00:20:20,330
قاب داده پیشرفته است. این یک
510
00:20:20,330 –> 00:20:22,340
قاب داده یا قاب داده معمولی ما است که
511
00:20:22,340 –> 00:20:24,380
برخی اطلاعات شکل به آن متصل است، بنابراین
512
00:20:24,380 –> 00:20:26,570
وقتی آن را می نویسید
513
00:20:26,570 –> 00:20:28,190
، شکل های قاب داده شما را می گیرد
514
00:20:28,190 –> 00:20:29,960
و اگر جلوتر رفتید و
515
00:20:29,960 –> 00:20:32,030
ستون های جدیدی به آن قاب داده اضافه
516
00:20:32,030 –> 00:20:33,650
کردید، می نویسد. آن ستونهای جدید را بیرون
517
00:20:33,650 –> 00:20:35,750
بیاورم، بنابراین تنها کاری که باید انجام میدادم این است که یک
518
00:20:35,750 –> 00:20:39,200
فیلد معمولی استاندارد جدید در چارچوب دادهام ایجاد کنم
519
00:20:39,200 –> 00:20:41,840
و بردار را که
520
00:20:41,840 –> 00:20:45,370
دادهها را میخواستم بستهبندی کنم و سپس نقطه قوسی را درست انجام
521
00:20:45,370 –> 00:20:49,400
دهم، بسیار ساده است، بنابراین دوباره
522
00:20:49,400 –> 00:20:51,260
میخواهیم این را واقعاً واضح کنیم.
523
00:20:51,260 –> 00:20:54,080
دریافت دادهها در سه چهار خط
524
00:20:54,080 –> 00:20:56,570
کد واقعاً آسان است، شما چیزهایی در آرایهها یا
525
00:20:56,570 –> 00:20:58,460
فریمهای دادهای دارید که انجام میدهید، هر چند که با
526
00:20:58,460 –> 00:21:00,770
تجزیه و تحلیل خود به شهر میروید، آرایههای جدیدی
527
00:21:00,770 –> 00:21:03,110
دارید که میخواهید برای دریافت دادهها در خروجی چند
528
00:21:03,110 –> 00:21:04,730
خط کد قرار دهید. در برنامه
529
00:21:04,730 –> 00:21:09,050
برای خارج کردن دادهها خوب است، بنابراین بیایید
530
00:21:09,050 –> 00:21:12,340
به چند نمونه از پایتون نگاهی بیندازیم و
531
00:21:12,340 –> 00:21:17,200
این از مبتدی به پیشرفته تبدیل میشود،
532
00:21:18,670 –> 00:21:21,590
بنابراین این سادهترین مورد است این
533
00:21:21,590 –> 00:21:24,730
ویژگی IO است و این فقط به
534
00:21:24,730 –> 00:21:26,900
قرار دادن این در ذهن شما برمیگردد که
535
00:21:26,900 –> 00:21:30,200
انجام این کار بسیار ساده است وقتی
536
00:21:30,200 –> 00:21:32,720
دوباره از شی داده استفاده می کنید، دلیل
537
00:21:32,720 –> 00:21:35,150
استفاده از numpy دو برابر است همه
538
00:21:35,150 –> 00:21:39,740
متدولوژی ها در Syfy و scikit-learn
539
00:21:39,740 –> 00:21:42,440
و پانداس همه آنها واقعاً به این
540
00:21:42,440 –> 00:21:44,300
ساختار داده به نام آرایه numpy تکیه می کنند
541
00:21:44,300 –> 00:21:46,100
و مقدار B کافی است. آرایه آن است یک
542
00:21:46,100 –> 00:21:47,930
آرایه پیوسته دریا، بنابراین وقتی
543
00:21:47,930 –> 00:21:50,360
با اینها ریاضیات انجام می دهید، یا
544
00:21:50,360 –> 00:21:53,390
از تکنیک های C++ یا فرترن استفاده می کنید و
545
00:21:53,390 –> 00:21:55,010
چیزی که در نهایت به دست می آورید سرعت
546
00:21:55,010 –> 00:21:57,680
قابل مقایسه با C++ و Fortran است،
547
00:21:57,680 –> 00:21:59,810
زیرا C++ و Fortran است و این به این
548
00:21:59,810 –> 00:22:01,670
معنی است که حتی اگر تکنیک خود را
549
00:22:01,670 –> 00:22:03,200
در C++ نوشته
550
00:22:03,200 –> 00:22:05,150
باشید به این سرعت نخواهد بود یا
551
00:22:05,150 –> 00:22:07,130
از نسخه ای که می خواهید
552
00:22:07,130 –> 00:22:09,350
در numpy دریافت کنید سریع تر نخواهد بود،
553
00:22:09,350 –> 00:22:10,820
شکست دادن برنامه نویسان numpy بسیار دشوار است
554
00:22:10,820 –> 00:22:12,799
زیرا آنها در آن بسیار خوب هستند.
555
00:22:12,799 –> 00:22:15,679
کاری که آنها انجام میدهند در حال حاضر در C است، بنابراین تا
556
00:22:15,679 –> 00:22:17,360
زمانی که میتوانید از آرایه numpy استفاده کنید و
557
00:22:17,360 –> 00:22:20,750
با حافظه پایتون به سرعت C خواهید رسید،
558
00:22:20,750 –> 00:22:23,690
بنابراین num P مخرج مشترکی برای همه
559
00:22:23,690 –> 00:22:25,789
این روشهای مختلف است، خوب است و
560
00:22:25,789 –> 00:22:27,169
نگران دریافت همه این موارد نباشید.
561
00:22:27,169 –> 00:22:29,270
تمام این نوتبوکهای مشتری در
562
00:22:29,270 –> 00:22:31,640
دسترس شما خواهند بود، بنابراین دوباره یکی از
563
00:22:31,640 –> 00:22:33,710
کاربران اینجا در مورد نوتبوکهای مشتری از من میپرسد.
564
00:22:33,710 –> 00:22:36,020
565
00:22:36,020 –> 00:22:39,980
566
00:22:39,980 –> 00:22:42,169
567
00:22:42,169 –> 00:22:44,330
و من می توانم Pyth را اجرا کنم در
568
00:22:44,330 –> 00:22:48,260
صورت تمایل، روی کدهای داخل یک ارائه HTML
569
00:22:48,260 –> 00:22:49,970
، بنابراین من در اینجا علامت گذاری کرده ام
570
00:22:49,970 –> 00:22:52,100
که کمی در مورد کاری که
571
00:22:52,100 –> 00:22:54,559
انجام می
572
00:22:54,559 –> 00:22:56,990
دهم به شما بگویم و سپس پیوندهایی به چیزهای دیگر دارم و سپس به شما می گویم که در حال انجام چه کاری هستم.
573
00:22:56,990 –> 00:22:58,730
بنابراین این یک نوع
574
00:22:58,730 –> 00:23:01,130
ارائه است، بنابراین کاری که من می خواهم انجام دهم این است
575
00:23:01,130 –> 00:23:02,720
که من یک کار اساسی انجام می دهم، فقط می
576
00:23:02,720 –> 00:23:05,270
خواهم داده ها را در آن بخوانم،
577
00:23:05,270 –> 00:23:07,039
یک فیلد خروجی جدید ایجاد می کنم
578
00:23:07,039 –> 00:23:08,539
و داده ها را می نویسم و ما خواهیم دید که چقدر
579
00:23:08,539 –> 00:23:09,289
ساده است،
580
00:23:09,289 –> 00:23:12,620
بنابراین من چند خط را وارد می کنم، arc PI
581
00:23:12,620 –> 00:23:15,470
numpy را در شی داده وارد می کنم، اکنون باید
582
00:23:15,470 –> 00:23:18,650
فیلدها را مقداردهی اولیه کنم و بارگذاری کنم، بنابراین دوباره
583
00:23:18,650 –> 00:23:22,610
نشان می دهیم که اکنون کاری که من انجام می دهم چقدر آسان است این
584
00:23:22,610 –> 00:23:24,860
است که به یک عکس فوری می رسم. از دادهها و من
585
00:23:24,860 –> 00:23:26,450
پنج رکورد اول را چاپ کردم.
586
00:23:26,450 –> 00:23:28,940
آنچه واقعاً در مورد قاب داده پانداس خوب
587
00:23:28,940 –> 00:23:31,429
است این است که بسیار زیبا به
588
00:23:31,429 –> 00:23:33,559
نظر میرسد
589
00:23:33,559 –> 00:23:36,140
که وقتی یک
590
00:23:36,140 –> 00:23:38,059
جدول ویژگی را در حرفهای باز میکنید یا یک نقشه قوسی
591
00:23:38,059 –> 00:23:40,820
را باز میکنید دقیقاً مانند جدول ویژگی به نظر میرسد. پاک کنید و متوجه خواهید شد که
592
00:23:40,820 –> 00:23:44,900
شناسه من بر اساس 0 یا 1 نیست، بلکه از
593
00:23:44,900 –> 00:23:48,799
158 شروع می شود و به ایندکس o تبدیل می شود. f my
594
00:23:48,799 –> 00:23:51,080
pandas dataframe بنابراین فیلد ID منحصربفرد من
595
00:23:51,080 –> 00:23:53,299
به نمایه قاب داده من تبدیل می شود
596
00:23:53,299 –> 00:23:55,250
که می دانید خیلی خوب است که اکنون
597
00:23:55,250 –> 00:23:57,650
داده های خام شبیه آرایه numpy هسته هستند
598
00:23:57,650 –> 00:24:00,020
آیا شما معمولاً
599
00:24:00,020 –> 00:24:01,549
ریاضیات را در آنجا انجام می دهید اما آنقدر
600
00:24:01,549 –> 00:24:03,860
زیبا نیست اینها پنج رکورد اول
601
00:24:03,860 –> 00:24:08,419
برای یک جمعیت در سال 1969 هستند، بنابراین من
602
00:24:08,419 –> 00:24:10,100
فکر می کنم تفاوت زیادی بین
603
00:24:10,100 –> 00:24:13,429
آن خروجی در آن خروجی وجود دارد، شما می دانید که
604
00:24:13,429 –> 00:24:15,799
مردم تمایل دارند آن خروجی را دوست داشته باشند،
605
00:24:15,799 –> 00:24:17,270
اکنون چند کار اضافی وجود دارد که
606
00:24:17,270 –> 00:24:19,190
شی داده به شما اجازه می دهد درست مانند آنچه
607
00:24:19,190 –> 00:24:22,040
که هستند انجام دهید. انتخاب به شما اجازه می دهد تا چند کار
608
00:24:22,040 –> 00:24:23,040
اضافی مانند
609
00:24:23,040 –> 00:24:25,260
BIRT دو شی مختلف انجام دهید، شی داده
610
00:24:25,260 –> 00:24:27,050
به شما اجازه می دهد در حال حاضر چند کار را انجام دهید،
611
00:24:27,050 –> 00:24:30,630
اگر به طور خاص آن را نخواهید
612
00:24:30,630 –> 00:24:33,150
، اشیاء داده فقط
613
00:24:33,150 –> 00:24:35,280
آکوردهای X&Y را برای شکل شما به شما می
614
00:24:35,280 –> 00:24:36,660
دهند، بنابراین اگر شما چند ضلعی دارید،
615
00:24:36,660 –> 00:24:38,130
فقط می خواهید مرکز را بگیرید، بنابراین
616
00:24:38,130 –> 00:24:40,050
خطوطی را دارید که می خواهید مرکز را بگیرید،
617
00:24:40,050 –> 00:24:42,360
باید صریحاً شکل ها را بخواهید اگر
618
00:24:42,360 –> 00:24:44,850
می خواهید خوب باشند، می خواهید آکوردهای XY را دریافت
619
00:24:44,850 –> 00:24:46,830
کنید، حتی آکورد z را دریافت خواهید کرد.
620
00:24:46,830 –> 00:24:48,540
اگر Z فعال
621
00:24:48,540 –> 00:24:50,250
باشد، هر چه باشد، آنها را دریافت خواهید کرد، اما اگر شکلها را
622
00:24:50,250 –> 00:24:52,440
میخواهید، باید آنها را بخواهید، بنابراین در اینجا
623
00:24:52,440 –> 00:24:54,270
یک قاب داده وجود دارد که دارای همان فیلدهایی است
624
00:24:54,270 –> 00:24:56,370
که من داشتم، اما آکوردهای XY را نیز دارد،
625
00:24:56,370 –> 00:24:57,780
اما بسیار خوب است. easy و من تمام
626
00:24:57,780 –> 00:24:59,970
اطلاعاتم را اینجا دارم اما اگر
627
00:24:59,970 –> 00:25:02,490
هندسههایی را بخواهم که میخواهم کارهایی مانند کلیپ
628
00:25:02,490 –> 00:25:05,250
در یا عملیات هندسه را انجام دهم و
629
00:25:05,250 –> 00:25:06,960
آنها را میخواهم، تفاوت را در اینجا متوجه خواهید شد این
630
00:25:06,960 –> 00:25:09,420
است که من هندسه مورد نیاز خود را برابر true تنظیم میکنم،
631
00:25:09,420 –> 00:25:10,020
632
00:25:10,020 –> 00:25:13,590
بنابراین ببینید در اینجا گفتم همان داده های قبلی را بدست آورید
633
00:25:13,590 –> 00:25:15,960
اما می خواهم به هندسه نیاز داشته
634
00:25:15,960 –> 00:25:18,960
باشم سپس وقتی فریم داده خود را دریافت کردم یک
635
00:25:18,960 –> 00:25:21,960
آرایه numpy جدید ایجاد می کنم که در SSD
636
00:25:21,960 –> 00:25:25,200
روی مقداری از اشکال ارسال می کنم
637
00:25:25,200 –> 00:25:27,630
و شی نوع D آن را صدا می زنم و سپس یک عدد اضافه می کنم. ستون جدیدی در
638
00:25:27,630 –> 00:25:29,910
قاب دادهام به نام شکلها است و من
639
00:25:29,910 –> 00:25:32,280
پنج رکورد اول را چاپ میکنم، بنابراین
640
00:25:32,280 –> 00:25:33,960
اکنون همان قاب دادهای را دارم که قبلاً داشتم،
641
00:25:33,960 –> 00:25:36,060
اما در واقع هندسه پای قوس را
642
00:25:36,060 –> 00:25:38,910
دقیقاً در داخل قاب داده پانداس دارم و
643
00:25:38,910 –> 00:25:44,130
اکنون ArcGIS Python API
644
00:25:44,130 –> 00:25:46,110
چند نفر است. از API جدید پایتون
645
00:25:46,110 –> 00:25:48,930
فقط pyt آگاه هستند hon api یک web api است
646
00:25:48,930 –> 00:25:52,890
که واقعاً خوب است و به
647
00:25:52,890 –> 00:25:54,540
نظر می رسد که بخشی از هسته و نسخه بعدی
648
00:25:54,540 –> 00:25:56,550
حرفه ای خواهد بود و ما به دنبال راه هایی
649
00:25:56,550 –> 00:25:58,650
برای ادغام آن با arc PI هستیم و یکی
650
00:25:58,650 –> 00:26:00,330
از راه ها این است که آنها این داده های مکانی را داشته باشند.
651
00:26:00,330 –> 00:26:02,250
فریم هایی که واقعاً مرتب هستند من خودم مدتی را
652
00:26:02,250 –> 00:26:04,080
صرف کار با پرینت داده های مکانی
653
00:26:04,080 –> 00:26:07,200
کردم و بسیار خوب است که
654
00:26:07,200 –> 00:26:09,750
یک روش کاملاً کاربردی برای
655
00:26:09,750 –> 00:26:12,540
خواندن اشکال و هندسه ها در این
656
00:26:12,540 –> 00:26:14,360
قاب های داده داشته باشیم و سپس
657
00:26:14,360 –> 00:26:17,760
عملیات هندسه را روی مواردی مانند
658
00:26:17,760 –> 00:26:20,250
لمس کردن بریده یا متقاطع انجام دهیم. چیزی که به دست
659
00:26:20,250 –> 00:26:22,470
میآورید فریمهای دادههای مکانی جدید هستند که دارای
660
00:26:22,470 –> 00:26:25,440
آن چیزها هستند، پانداسی جغرافیایی به
661
00:26:25,440 –> 00:26:26,700
عنوان راهی وجود دارد
662
00:26:26,700 –> 00:26:28,260
که منبع باز است، اما ما میخواهیم
663
00:26:28,260 –> 00:26:30,630
نسخه PI قوس خودمان را داشته باشیم که
664
00:26:30,630 –> 00:26:33,030
تمام عملیات هندسی ما را انجام میدهد و این
665
00:26:33,030 –> 00:26:36,510
اساساً راهی است که می توانید آن را انجام دهید،
666
00:26:36,510 –> 00:26:40,169
بنابراین به زودی ارائه می شود و اکنون من
667
00:26:40,169 –> 00:26:42,870
ادامه دادم و باید یک کلاس ویژگی خروجی جدید ایجاد کنم
668
00:26:42,870 –> 00:26:44,820
و این تنها کاری است که باید
669
00:26:44,820 –> 00:26:47,850
انجام دهم.
670
00:26:47,850 –> 00:26:50,549
تابع تصادفی numpy
671
00:26:50,549 –> 00:26:52,590
من یک استاندارد جدید معمولی می خواهم میانگین 0
672
00:26:52,590 –> 00:26:56,010
واریانس یکی از همان اندازه SSTO بدون
673
00:26:56,010 –> 00:26:57,690
mobs که چند ویژگی دارم
674
00:26:57,690 –> 00:27:00,450
یک فیلد کاندید ایجاد می کنم و سپس
675
00:27:00,450 –> 00:27:02,580
یک کلاس ویژگی خروجی جدید ایجاد می کنم
676
00:27:02,580 –> 00:27:04,110
و فیلدهایی را که می خواهم اضافه می کنم دوباره کپی کنید
677
00:27:04,110 –> 00:27:07,500
و وقتی این کار را انجام میدهم
678
00:27:07,500 –> 00:27:09,690
کلاس ویژگی خروجی ایجاد میکند، بنابراین دوباره هیچ حلقهای
679
00:27:09,690 –> 00:27:11,580
ایجاد نمیکنم، یک کلاس ویژگی خروجی جدید ایجاد کردم که
680
00:27:11,580 –> 00:27:13,350
شکل برای کپی کردن روی هر فیلدی که
681
00:27:13,350 –> 00:27:15,299
میخواهم روی آن کپی میشود و من تمام کردم، بنابراین
682
00:27:15,299 –> 00:27:17,910
این مثال ساده است اما یک نمایش
683
00:27:17,910 –> 00:27:19,710
امیدوارم به شما نشان دهد که دریافت دادهها چقدر ساده است،
684
00:27:19,710 –> 00:27:22,140
سپس
685
00:27:22,140 –> 00:27:24,720
هر کاری را که میخواهید با numpy panda
686
00:27:24,720 –> 00:27:26,730
scikit
687
00:27:26,730 –> 00:27:29,160
انجام دهید.
688
00:27:29,160 –> 00:27:31,260
689
00:27:31,260 –> 00:27:32,610
روش جدید کلاس ویژگی برای ایجاد
690
00:27:32,610 –> 00:27:35,309
ویژگیهای خروجی حالا بیایید
691
00:27:35,309 –> 00:27:37,530
کمی پیشرفتهتر شویم که چند نفر
692
00:27:37,530 –> 00:27:40,130
باید با همسایههای
693
00:27:40,130 –> 00:27:42,210
فضایی جستجوی محله سر و کار داشته باشند، بسیاری از
694
00:27:42,210 –> 00:27:44,010
تکنیکهای فضایی به جستجوی همسایگی نیاز دارند،
695
00:27:44,010 –> 00:27:48,510
بنابراین من یک دفترچه یادداشت مشتری دیگر دارم.
696
00:27:48,510 –> 00:27:51,000
در اینجا که به شما می گوید چگونه جستجوی همسایگی را انجام دهید،
697
00:27:51,000 –> 00:27:53,400
بنابراین یکی از راه های انجام
698
00:27:53,400 –> 00:27:56,130
آن استفاده از ماتریس های انتظار فضایی است
699
00:27:56,130 –> 00:27:58,950
که فایل باینری داخلی خود ما است.
700
00:27:58,950 –> 00:28:01,410
701
00:28:01,410 –> 00:28:04,950
702
00:28:04,950 –> 00:28:09,090
و وزن ها ممکن
703
00:28:09,090 –> 00:28:12,630
است 0.2 0.2 0.2 یا 1 1 1 یا هر چیز دیگری باشد و
704
00:28:12,630 –> 00:28:16,350
آن فایل های شنا به عنوان ورودی برای
705
00:28:16,350 –> 00:28:18,630
بسیاری از تکنیک های آمار فضایی ما استفاده
706
00:28:18,630 –> 00:28:21,090
می شود و می توان آنها را به تلویزیون گالن
707
00:28:21,090 –> 00:28:23,700
با فرمت های GWT و مواردی مانند سبک پای
708
00:28:23,700 –> 00:28:27,240
و و ok ما تبدیل کرد. و بنابراین، من
709
00:28:27,240 –> 00:28:30,390
فقط راهی برای ساختن مجموعه ای از این
710
00:28:30,390 –> 00:28:32,429
چیزها دارم، بنابراین می خواهم
711
00:28:32,429 –> 00:28:34,590
دوباره اطلاعاتی را از
712
00:28:34,590 –> 00:28:36,720
چند ضلعی های کالیفرنیا بخوانم و بتوانم یک
713
00:28:36,720 –> 00:28:39,059
نسخه با فاصله ثابت ایجاد کنم.
714
00:28:39,059 –> 00:28:41,850
715
00:28:41,850 –> 00:28:43,909
در این حالت مترها هر کس در
716
00:28:43,909 –> 00:28:45,840
250000 متر
717
00:28:45,840 –> 00:28:48,240
همسایه من خواهد بود من می خواهم فاصله معکوس
718
00:28:48,240 –> 00:28:49,710
همه را در فاصله 250
719
00:28:49,710 –> 00:28:51,870
هزار متری انجام دهم اما من می خواهم
720
00:28:51,870 –> 00:28:54,179
فاصله معکوس مربع شود بنابراین توان 2.0 من
721
00:28:54,179 –> 00:28:56,669
یک فایل شنا ایجاد می کند که این کار را انجام می دهد. n
722
00:28:56,669 –> 00:28:58,200
انجام K نزدیکترین همسایه
723
00:28:58,200 –> 00:28:59,880
من می خواهم به هشت نزدیکترین همسایه در
724
00:28:59,880 –> 00:29:02,460
این مورد اکنون همه این فایل های شنا را می
725
00:29:02,460 –> 00:29:05,279
توان در تجزیه و تحلیل استفاده
726
00:29:05,279 –> 00:29:07,919
727
00:29:07,919 –> 00:29:10,980
728
00:29:10,980 –> 00:29:14,659
729
00:29:14,659 –> 00:29:17,100
کرد. لمس کردن ملکه آن یک
730
00:29:17,100 –> 00:29:20,130
چند ضلعی است که هر رأسی را لمس می کند خوب است و
731
00:29:20,130 –> 00:29:22,020
بنابراین من می توانم آن را اجرا کنم و یک
732
00:29:22,020 –> 00:29:24,360
ماتریس وزن های ویژه جدید بر اساس آن
733
00:29:24,360 –> 00:29:27,120
ایجاد کنم، می توانم یک ترکیب ترکیبی ایجاد کنم، می توانم بگویم هی، من
734
00:29:27,120 –> 00:29:29,880
همسایه های چند ضلعی می خواهم، اما اگر من چند ضلعی یا همسایه آیوان هستم.
735
00:29:29,880 –> 00:29:32,130
یک چند ضلعی که
736
00:29:32,130 –> 00:29:34,110
حداقل چهار همسایه ندارد،
737
00:29:34,110 –> 00:29:35,789
بیرون میروند و چهار همسایه را در
738
00:29:35,789 –> 00:29:38,520
فضای مرکزی به من وارد میکنند تا مطمئن شوم که چهار همسایه دارم،
739
00:29:38,520 –> 00:29:40,320
زیرا بسیاری از آمارهای فضایی
740
00:29:40,320 –> 00:29:42,510
مستلزم این است که همه حداقل یک
741
00:29:42,510 –> 00:29:44,490
همسایه داشته باشند، بنابراین ما روشهایی برای
742
00:29:44,490 –> 00:29:46,529
کمک به شما داریم موارد مشابه گذشته، بنابراین
743
00:29:46,529 –> 00:29:48,120
همه این فایلهای شنا را میتوان در
744
00:29:48,120 –> 00:29:50,309
بسیاری از تکنیکهایی که ما استفاده میکنیم و
745
00:29:50,309 –> 00:29:52,230
بسیاری از تکنیکها در پایتون و بسیاری از
746
00:29:52,230 –> 00:29:54,600
تکنیکها در R در حال حاضر استفاده کرد، اما
747
00:29:54,600 –> 00:29:56,159
در حال پرواز چه میشود، بنابراین گاهی اوقات میگویید ما این
748
00:29:56,159 –> 00:29:58,590
فرمت شماست Janek می دانید من نمی
749
00:29:58,590 –> 00:29:59,970
دانم چگونه از کلاس شما استفاده کنم
750
00:29:59,970 –> 00:30:02,700
که به خوبی می خواند شما می توانید این کارها را
751
00:30:02,700 –> 00:30:04,620
با استفاده از جدول GA انجام دهید و بسیار
752
00:30:04,620 –> 00:30:07,440
ساده است و بسیار شبیه به روشی است که
753
00:30:07,440 –> 00:30:09,450
داده ها را در ابتدا می خوانید. شما فقط
754
00:30:09,450 –> 00:30:11,580
یک تفاوت جزئی با به دست
755
00:30:11,580 –> 00:30:13,679
آوردن دادههایی که میگویید من میخواهم
756
00:30:13,679 –> 00:30:16,860
تنظیم جستجو را روی true انجام دهم انجام میدهید و چیزی که قرار است
757
00:30:16,860 –> 00:30:18,990
برگرداند این است که هنوز هم دادههای شما خوانده میشود،
758
00:30:18,990 –> 00:30:21,210
همچنان آنها را در آرایههای ناتوان قرار میدهید، هنوز
759
00:30:21,210 –> 00:30:23,159
هم میتوانید فریمهای داده را از آنها بسازید، اما
760
00:30:23,159 –> 00:30:25,260
اکنون شما یک چهار درخت خواهید داشت که با آن
761
00:30:25,260 –> 00:30:27,750
جستجو می کنید و می گویید من همه را در فاصله
762
00:30:27,750 –> 00:30:30,360
250 هزار متری می خواهم یا هشت
763
00:30:30,360 –> 00:30:32,039
همسایه نزدیکم را می خواهم ببینیم چه
764
00:30:32,039 –> 00:30:32,730
شکلی است
765
00:30:32,730 –> 00:30:35,669
بنابراین این بار خواندم داده ها را
766
00:30:35,669 –> 00:30:37,980
به همان روش به دست آوردم اما به مجموعه جستجو نیاز دارم.
767
00:30:37,980 –> 00:30:40,770
درست است و کاری که من انجام میدهم این است که میگویم
768
00:30:40,770 –> 00:30:42,870
میخواهم این جستجوی همسایه جدید را در اینجا تنظیم کنم و
769
00:30:42,870 –> 00:30:45,690
میخواهم در فاصله صفر دور جستجو کنم، اما
770
00:30:45,690 –> 00:30:48,059
من چهار همسایه نزدیکتر را میخواهم و
771
00:30:48,059 –> 00:30:50,010
میخواهم این جستجوی همسایه را انجام دهم، بنابراین
772
00:30:50,010 –> 00:30:51,809
این جستجوی همسایه را انجام دادم و برای هر
773
00:30:51,809 –> 00:30:54,600
مقدار و n همسایهها را جستجو میکنم اگر کمتر
774
00:30:54,600 –> 00:30:57,059
از پنج سال دارم، میخواهم پرینت بگیرم که همسایههای من چه کسانی
775
00:30:57,059 –> 00:31:02,790
هستند، بنابراین شناسه صفر را
776
00:31:02,790 –> 00:31:04,980
در آرایه numpy مرتب کنید اولین مقدار در
777
00:31:04,980 –> 00:31:07,860
آرایه nubby، همسایگان آن سفارش
778
00:31:07,860 –> 00:31:11,550
ID 23 27 1 & 2 هستند، بنابراین اگر به همسایگانش نیاز داشتم
779
00:31:11,550 –> 00:31:14,340
مقادیر من می روم و
780
00:31:14,340 –> 00:31:17,850
مقادیر 23 27 1 و 2 را برای شماره 1
781
00:31:17,850 –> 00:31:20,750
782
00:31:20,750 –> 00:31:24,810
می گیرم همسایگان آن 2 0 27 و 23 و شماره 2 1 27 0 و 38 هستند، بنابراین این
783
00:31:24,810 –> 00:31:26,610
همسایه های من هستند چهار نزدیکترین همسایه من
784
00:31:26,610 –> 00:31:30,480
همان خواندن همان داده های به دست آمده فقط
785
00:31:30,480 –> 00:31:32,100
با استفاده از نیاز به جستجو و سپس باید
786
00:31:32,100 –> 00:31:34,080
چند کار را در اینجا انجام دهید تا جستجوی چهاردرختی ایجاد شود،
787
00:31:34,080 –> 00:31:37,620
اکنون میتوانم
788
00:31:37,620 –> 00:31:39,360
ادامه دهم اگر لازم بود تمام
789
00:31:39,360 –> 00:31:41,460
مسافتهایی را که دیروز در
790
00:31:41,460 –> 00:31:43,230
جزیره روی آن کار کردم با کسی انجام دهم و
791
00:31:43,230 –> 00:31:44,490
گفتم میدانید چه
792
00:31:44,490 –> 00:31:46,140
فاصلههایی خوب است که مطمئن شویم داریم، بنابراین این
793
00:31:46,140 –> 00:31:48,210
مورد را مرور میکنم، یک جستجوی همسایه انجام
794
00:31:48,210 –> 00:31:50,160
795
00:31:50,160 –> 00:31:52,050
میدهم و سپس فاصلهها را برای همه همسایگانم محاسبه میکنم و آنها را چاپ
796
00:31:52,050 –> 00:31:55,170
میکنم تا ID 0 دارای سه
797
00:31:55,170 –> 00:31:57,510
همسایه باشد، آنها 3 1 هستند. و 4
798
00:31:57,510 –> 00:32:02,220
مسافت 200 200 و 282 هستند پس این فقط همین است
799
00:32:02,220 –> 00:32:03,960
این فقط یک نمونه از کارهایی است که شما بچه ها
800
00:32:03,960 –> 00:32:06,480
می توانید با استفاده از این جستجوهای
801
00:32:06,480 –> 00:32:09,240
همسایه انجام دهید و سپس این یکی
802
00:32:09,240 –> 00:32:11,520
دوباره وزنه های همسایه را انجام می
803
00:32:11,520 –> 00:32:13,050
804
00:32:13,050 –> 00:32:14,760
805
00:32:14,760 –> 00:32:16,230
دهد.
806
00:32:16,230 –> 00:32:17,910
به شما می گوید که وزن آنها چقدر است
807
00:32:17,910 –> 00:32:19,410
دوباره نگران گرفتن همه این
808
00:32:19,410 –> 00:32:21,630
چیزها نباشید، فقط می توانید بالا بروید و این را
809
00:32:21,630 –> 00:32:24,840
از UM از وب سایت بگیرید
810
00:32:24,840 –> 00:32:26,010
اگر مایل به انجام جستجوی محله هستید
811
00:32:26,010 –> 00:32:34,710
اگر این کاهش پیدا کند و سپس
812
00:32:34,710 –> 00:32:37,380
یک روش وجود دارد که ما وجود دارد با
813
00:32:37,380 –> 00:32:41,130
PI کار کردم دیدم چند نفر از pycelle استفاده
814
00:32:41,130 –> 00:32:45,330
کردهاند یا از pycelle آگاه هستند، خوب من
815
00:32:45,330 –> 00:32:46,920
مدتی است که روی این کار کار میکنم و
816
00:32:46,920 –> 00:32:48,660
امیدوار بودم آتش بیشتری بگیرد، اما
817
00:32:48,660 –> 00:32:51,750
PI saw این است که تکنیکهای بسیار خوبی دارد
818
00:32:51,750 –> 00:32:54,450
و یکی از آنها
819
00:32:54,450 –> 00:32:56,430
پروژهها یا ماژولهای قهرمان واقعی آن
820
00:32:56,430 –> 00:32:59,070
روشهای اقتصاد سنجی فضایی هستند که بسیار خوب است و
821
00:32:59,070 –> 00:33:00,600
نوع فضایی معیارهای بسیاری از مواقعی
822
00:33:00,600 –> 00:33:02,730
که شما در حال انجام یک رگرسیون در فضا هستید، همان چیزی که
823
00:33:02,730 –> 00:33:04,230
دارید، همبستگی خودکار باقیمانده است،
824
00:33:04,230 –> 00:33:05,880
شما با کمی مشکل مواجه هستید. h رگرسیون خود را
825
00:33:05,880 –> 00:33:07,290
به این دلیل وجود دارد که
826
00:33:07,290 –> 00:33:09,540
وابستگی مکانی در باقیمانده های شما وجود دارد، به این دلیل
827
00:33:09,540 –> 00:33:11,730
که شما نمی توانید به نتایج
828
00:33:11,730 –> 00:33:13,800
رگرسیون حداقل مربعات معمولی خود اعتماد کنید
829
00:33:13,800 –> 00:33:15,510
و بنابراین
830
00:33:15,510 –> 00:33:16,620
831
00:33:16,620 –> 00:33:18,210
Meek های اقتصادی ویژه پیشرفته فضایی وجود دارند که برای انجام آنها به آنها
832
00:33:18,210 –> 00:33:20,130
نیاز دارید. به
833
00:33:20,130 –> 00:33:22,020
استنباطهایی که از اتصال خود میکشید اعتماد کنید،
834
00:33:22,020 –> 00:33:24,660
بنابراین در اینجا مثالی از نحوه انجام برخی
835
00:33:24,660 –> 00:33:28,440
تحلیلهای بسیار پیشرفته بسیار شبیه به
836
00:33:28,440 –> 00:33:31,350
درستی آورده شده است.
837
00:33:31,350 –> 00:33:34,350
838
00:33:34,350 –> 00:33:37,590
839
00:33:37,590 –> 00:33:39,510
بارها و بارها
840
00:33:39,510 –> 00:33:41,550
یک شروع را میبینید در پایان یکسان، زیرا
841
00:33:41,55