در این مطلب، ویدئو پردازش رشته در پایتون: آناگرام است با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:02,399
بسیار خوب، پس در این ویدیو ما قصد داریم
2
00:00:02,399 –> 00:00:04,080
تابعی را در پایتون بنویسیم که
3
00:00:04,080 –> 00:00:06,180
به ما امکان می دهد تشخیص دهیم که آیا دو
4
00:00:06,180 –> 00:00:07,890
رشته ای که آناگرام ما از یکدیگر داده شده است یا نه،
5
00:00:07,890 –> 00:00:10,080
بنابراین اگر
6
00:00:10,080 –> 00:00:13,110
آشنایی ندارید، یک آناگرام یک کلمه یا عبارت است. با
7
00:00:13,110 –> 00:00:14,910
مرتب کردن مجدد حروف یک
8
00:00:14,910 –> 00:00:17,220
کلمه یا عبارت متفاوت معمولاً با استفاده از تمام
9
00:00:17,220 –> 00:00:19,380
حروف اصلی دقیقاً یک بار،
10
00:00:19,380 –> 00:00:22,619
بنابراین
11
00:00:22,619 –> 00:00:24,840
12
00:00:24,840 –> 00:00:26,519
اگر
13
00:00:26,519 –> 00:00:28,740
اطلاعات بیشتری در مورد آناگرام میخواهید و من در اینجا دارم، به توضیح آنگرام تعریف ویکیپدیا در توضیح زیر اشاره کردهام
14
00:00:28,740 –> 00:00:31,800
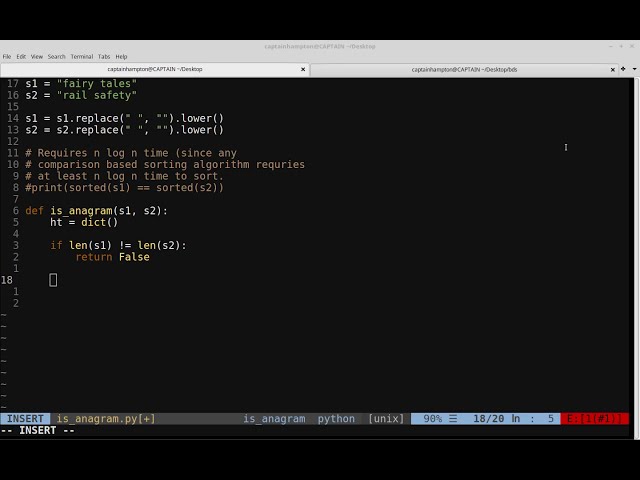
. دو متغیر s 1 – 2 که
15
00:00:31,800 –> 00:00:34,860
شبیه یکدیگر هستند بنابراین s 1 عبارت
16
00:00:34,860 –> 00:00:37,230
Fay-tales را می توان حروف را مجدداً مرتب کرد
17
00:00:37,230 –> 00:00:39,180
و این را می توان به گونه ای تنظیم
18
00:00:39,180 –> 00:00:42,030
کرد که عبارت ایمنی واقعی را تشکیل دهند بنابراین
19
00:00:42,030 –> 00:00:44,250
من چیزی از آن اضافه یا حذف نمی کنم
20
00:00:44,250 –> 00:00:46,890
. اول s 1 در اینجا من فقط
21
00:00:46,890 –> 00:00:49,379
آنها را دوباره مرتب می کنم به طوری که آنها s 2 را تشکیل می دهند
22
00:00:49,379 –> 00:00:51,870
بنابراین اگر این کار می تواند انجام شود s 1 یک آناگرام
23
00:00:51,870 –> 00:00:54,690
از s 2 است و بالعکس بنابراین کاری که می خواهیم
24
00:00:54,690 –> 00:00:55,829
انجام دهیم این است که می خواهیم تابعی را در
25
00:00:55,829 –> 00:00:57,120
پایتون بنویسیم که به ما این امکان را می دهد که w را تعیین کنیم
26
00:00:57,120 –> 00:00:59,219
خواه یا نه دو رشته
27
00:00:59,219 –> 00:01:00,899
آناگرام یکدیگر هستند و
28
00:01:00,899 –> 00:01:02,190
ما دو راه متفاوت برای حل
29
00:01:02,190 –> 00:01:04,290
این مشکل را بررسی خواهیم کرد که نوشتن یکی از آنها
30
00:01:04,290 –> 00:01:07,950
آسان است به عبارت دیگر
31
00:01:07,950 –> 00:01:10,229
نوشتن یکی دیگر بسیار مختصر خواهد
32
00:01:10,229 –> 00:01:11,880
بود. قرار است کمی پرمخاطب تر باشد،
33
00:01:11,880 –> 00:01:13,049
اما کمی
34
00:01:13,049 –> 00:01:15,570
کارآمدتر خواهد بود، بنابراین بیایید
35
00:01:15,570 –> 00:01:16,590
به نوعی روش
36
00:01:16,590 –> 00:01:20,130
حل این مشکل را مرور کنیم، بنابراین هر دو روشی که در آن
37
00:01:20,130 –> 00:01:20,880
این مشکل را حل می کنیم
38
00:01:20,880 –> 00:01:23,549
شامل عادی سازی رشته هایی که به
39
00:01:23,549 –> 00:01:25,380
ما داده می شود، یعنی می خواهیم
40
00:01:25,380 –> 00:01:27,990
هر حروف بزرگ را حذف کنیم و
41
00:01:27,990 –> 00:01:29,369
با حروف کوچک عادی سازی کنیم، بنابراین می خواهیم
42
00:01:29,369 –> 00:01:31,799
تمام حروف این دو رشته را به
43
00:01:31,799 –> 00:01:33,930
حروف کوچک عادی سازیم، همچنین می خواهیم
44
00:01:33,930 –> 00:01:36,270
فاصله های موجود را نیز حذف کنیم، بنابراین می
45
00:01:36,270 –> 00:01:38,369
خواهیم با فرض اینکه رشته هایی که به
46
00:01:38,369 –> 00:01:40,439
ما داده می شود فقط از
47
00:01:40,439 –> 00:01:43,350
نویسه ها یا فاصله های الفبایی تشکیل شده است و کاری که می
48
00:01:43,350 –> 00:01:44,579
خواهیم انجام دهیم این است که
49
00:01:44,579 –> 00:01:47,430
آن فاصله ها را حذف می کنیم و اگر حاوی
50
00:01:47,430 –> 00:01:49,200
حروف بزرگ هستند،
51
00:01:49,200 –> 00:01:51,030
این حروف کوچک را تبدیل می کنیم. ما به راحتی می توانیم مقایسه کنیم،
52
00:01:51,030 –> 00:01:52,860
بنابراین کاری که می خواهیم انجام دهیم این است که
53
00:01:52,860 –> 00:01:54,869
s 1 و s 2 را تبدیل می کنیم، آنها را
54
00:01:54,869 –> 00:01:57,000
عادی می کنیم، بنابراین می خواهیم بگوییم s
55
00:01:57,000 –> 00:02:00,299
1 برابر است با s 1 نقطه، بنابراین هر نقطه را جایگزین کنید.
56
00:02:00,299 –> 00:02:01,860
فضاهایی که در
57
00:02:01,860 –> 00:02:04,590
رشته s 1 وجود دارند بدون هیچ فاصله ای، بنابراین
58
00:02:04,590 –> 00:02:06,479
همه کاراکترها را
59
00:02:06,479 –> 00:02:08,729
با هم در یک رشته بزرگ قرار ندهید و سپس
60
00:02:08,729 –> 00:02:10,229
همه
61
00:02:10,229 –> 00:02:12,629
کاراکترهای رشته s 1 را به
62
00:02:12,629 –> 00:02:13,830
حروف کوچک تبدیل می کنیم. بنابراین،
63
00:02:13,830 –> 00:02:15,990
این دو مثال در اینجا هیچ
64
00:02:15,990 –> 00:02:17,400
کاراکتر بزرگی ندارند، اما اگر این کاراکترها را داشته باشند،
65
00:02:17,400 –> 00:02:19,740
به حروف کوچک تبدیل میشوند، بنابراین
66
00:02:19,740 –> 00:02:20,820
میخواهیم همان
67
00:02:20,820 –> 00:02:22,590
روال عادیسازی را برای رشته
68
00:02:22,590 –> 00:02:24,690
s2 انجام دهیم، بنابراین میخواهیم تمام
69
00:02:24,690 –> 00:02:27,000
فاصلههای موجود در s2 یا را حذف کنیم. تمام
70
00:02:27,000 –> 00:02:29,370
کاراکترهای حروف الفبا را به حروف کوچک تبدیل
71
00:02:29,370 –> 00:02:31,980
می کنیم و سپس کاری که می توانیم انجام دهیم این است که می توانیم خیلی
72
00:02:31,980 –> 00:02:33,930
سریع بررسی کنیم که آیا آنگرام های دیگری
73
00:02:33,930 –> 00:02:35,430
از یکدیگر با انجام کارهای زیر
74
00:02:35,430 –> 00:02:37,830
می توانیم بپرسیم که آیا می توانیم
75
00:02:37,830 –> 00:02:41,490
چاپ کنیم که آیا s 1 مرتب شده است یا نه
76
00:02:41,490 –> 00:02:45,390
. برابر s 2 مرتب شده است، بنابراین اساساً
77
00:02:45,390 –> 00:02:47,430
کاری که ما در اینجا انجام می دهیم w است داریم
78
00:02:47,430 –> 00:02:50,160
کاراکترهای s 1 را
79
00:02:50,160 –> 00:02:52,230
مرتب میکنیم و کاراکترهای s 2 را مرتب میکنیم و میپرسیم آیا
80
00:02:52,230 –> 00:02:53,640
آن دو چیز با یکدیگر برابر هستند یا نه
81
00:02:53,640 –> 00:02:55,410
یا نتیجه را چاپ میکنیم
82
00:02:55,410 –> 00:02:57,590
تا نتیجه درست یا نادرست باشد،
83
00:02:57,590 –> 00:03:00,750
بنابراین این یک راه آسان برای تعیین
84
00:03:00,750 –> 00:03:02,340
اینکه آیا دو رشته
85
00:03:02,340 –> 00:03:05,130
آناگرام یکدیگر هستند یا نه، مختصر است،
86
00:03:05,130 –> 00:03:07,280
اما البته هر رویکرد مرتبسازی مبتنی بر مقایسه
87
00:03:07,280 –> 00:03:09,780
حداقل به n
88
00:03:09,780 –> 00:03:12,570
ورود زمان نیاز دارد، بنابراین من میخواهم
89
00:03:12,570 –> 00:03:19,620
نظری را در اینجا بنویسم. n
90
00:03:19,620 –> 00:03:26,310
در زمان وارد شوید زیرا هر
91
00:03:26,310 –> 00:03:31,200
الگوریتم مرتب سازی مبتنی بر مقایسه به حداقل n
92
00:03:31,200 –> 00:03:38,850
ورود به سیستم برای مرتب سازی نیاز دارد، بنابراین ما می توانیم
93
00:03:38,850 –> 00:03:40,560
کمی بهتر از این انجام دهیم، بنابراین من فقط می
94
00:03:40,560 –> 00:03:41,790
خواهم در این مورد نظر بدهم، اما
95
00:03:41,790 –> 00:03:44,300
در صورتی که این مورد را اینجا بگذارم. شما
96
00:03:44,300 –> 00:03:46,769
میخواهید یک راهحل بسیار مختصر برای این
97
00:03:46,769 –> 00:03:48,600
مشکل ببینید، کاری که ما میخواهیم انجام
98
00:03:48,600 –> 00:03:49,890
دهیم این است که میخواهیم کاری مشابه انجام دهیم،
99
00:03:49,890 –> 00:03:52,050
به این معنا که ما
100
00:03:52,050 –> 00:03:53,820
هنوز از قبل پردازش میکنیم که این رشتهها
101
00:03:53,820 –> 00:03:55,560
هر یک از فاصلهها را حذف میکنند. و
102
00:03:55,560 –> 00:03:57,720
نیز عادی سازی موارد اما چه ما قصد داریم این
103
00:03:57,720 –> 00:03:59,640
کار را انجام دهیم این است که
104
00:03:59,640 –> 00:04:02,400
از یک فرهنگ لغت یا جدول هش استفاده می کنیم، بنابراین
105
00:04:02,400 –> 00:04:04,320
حروفی را که
106
00:04:04,320 –> 00:04:06,150
با آنها روبرو شده ایم، پس از اینکه
107
00:04:06,150 –> 00:04:08,220
این رشته ها را از قبل پردازش کردیم و می خواهیم پیگیری کنیم.
108
00:04:08,220 –> 00:04:10,019
مطمئن شوید که اگر با یک F در رشته 1 مواجه شده ایم، فرض کنید
109
00:04:10,019 –> 00:04:13,230
یک F در رشته 2 نیز وجود دارد، به
110
00:04:13,230 –> 00:04:15,299
طوری که
111
00:04:15,299 –> 00:04:17,970
اگر یک A و s 1 ببینیم،
112
00:04:17,970 –> 00:04:19,890
باید یک a و s 2 دیگر نیز وجود داشته باشد، اگر
113
00:04:19,890 –> 00:04:21,750
یک وجود داشته باشد. I در s 1 همچنین باید
114
00:04:21,750 –> 00:04:23,280
یک I in s 2 u و غیره وجود
115
00:04:23,280 –> 00:04:25,590
داشته باشد، بنابراین اگر بتوانیم اساساً یک
116
00:04:25,590 –> 00:04:27,630
فرهنگ لغت جدول هش هیستوگرام ایجاد کنیم
117
00:04:27,630 –> 00:04:28,950
که میخواهید به آن فکر کنید، اگر
118
00:04:28,950 –> 00:04:30,780
بتوانیم یک ساختار داده ایجاد کنیم که
119
00:04:30,780 –> 00:04:32,460
بتوانیم ردیابی وقوع چنین
120
00:04:32,460 –> 00:04:34,920
چیزهایی، پس از آن که از ساختار داده عبور
121
00:04:34,920 –> 00:04:37,080
کنیم، پس از پیگیری هر
122
00:04:37,080 –> 00:04:38,760
دوی وقوع کاراکترها در
123
00:04:38,760 –> 00:04:40,410
هر دو رشته، باید
124
00:04:40,410 –> 00:04:42,180
وقوع صفر را در سراسر صفحه دریافت کنیم،
125
00:04:42,180 –> 00:04:44,610
زیرا اگر وقوع F را در
126
00:04:44,610 –> 00:04:46,350
رشته مشاهده کنیم. یکی از آنها باید
127
00:04:46,350 –> 00:04:48,150
در رشته دو اتفاقی از F داشته باشیم و
128
00:04:48,150 –> 00:04:49,890
اگر t را لغو کنیم اینها
129
00:04:49,890 –> 00:04:51,450
آناگرام های یکدیگر نبودند
130
00:04:51,450 –> 00:04:54,450
، پس ما این ویژگی لغو را نداشتیم، بنابراین بیایید در
131
00:04:54,450 –> 00:04:56,070
واقع برویم و این را کدگذاری کنیم و
132
00:04:56,070 –> 00:04:57,600
امیدواریم
133
00:04:57,600 –> 00:04:59,640
با کدگذاری آن کمی واضح تر شود، بنابراین
134
00:04:59,640 –> 00:05:01,830
تابعی به نام anagram می نویسیم و
135
00:05:01,830 –> 00:05:04,890
دو رشته s1 و s2 طول می کشد و کاری که
136
00:05:04,890 –> 00:05:05,700
ما می خواهیم انجام دهیم این است که
137
00:05:05,700 –> 00:05:07,710
فرهنگ لغت یا جدول هش خود را تعریف می کنیم و
138
00:05:07,710 –> 00:05:10,080
آن را HT می نامیم، این فقط
139
00:05:10,080 –> 00:05:12,750
با یک شی دیکشنری و سپس
140
00:05:12,750 –> 00:05:14,670
یکی بسیار سریع تنظیم می شود. کاری که میتوانیم فوراً انجام دهیم تا
141
00:05:14,670 –> 00:05:17,340
هر چیزی را از
142
00:05:17,340 –> 00:05:19,890
آناگرام بودن یکدیگر رد کنیم این است که
143
00:05:19,890 –> 00:05:22,080
طول s 1 و s 2 برابر نباشند، پس
144
00:05:22,080 –> 00:05:24,180
وقتی جلوتر رفتیم و
145
00:05:24,180 –> 00:05:26,820
هر دو s 1 و s 2 را به این روش از قبل پردازش کردیم. اگر
146
00:05:26,820 –> 00:05:28,980
طول این چیزها مساوی نباشد، می
147
00:05:28,980 –> 00:05:30,450
دانیم که نمی توانند آناگرام باشند، زیرا
148
00:05:30,450 –> 00:05:33,450
دوباره به یاد داشته باشید که یک آناگرام فقط یک
149
00:05:33,450 –> 00:05:35,040
آناگرام است اگر بتوانیم
150
00:05:35,040 –> 00:05:36,810
کاراکترهای موجود در یک رشته را در رشته
151
00:05:36,810 –> 00:05:39,410
دیگر مرتب کنیم، مستلزم حذف یا
152
00:05:39,410 –> 00:05:42,150
قرار دادن کاراکترهای جدید نیست. به
153
00:05:42,150 –> 00:05:44,280
هر یک از رشته ها، به عنوان مثال اگر
154
00:05:44,280 –> 00:05:46,950
قرار بود l را وارد کنم مثلاً میگوییم رشته X در اینجا
155
00:05:46,950 —