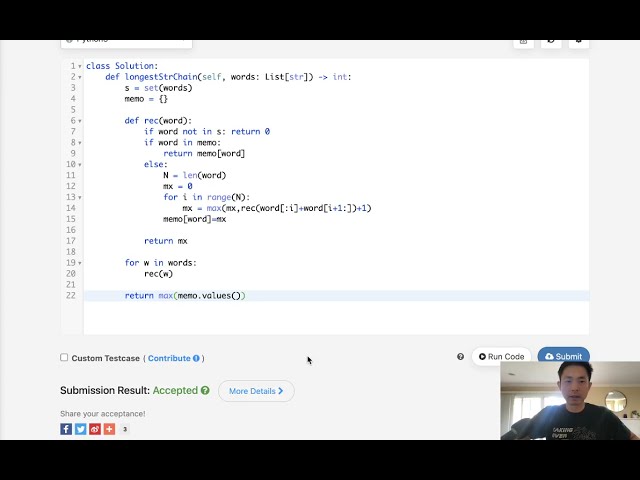
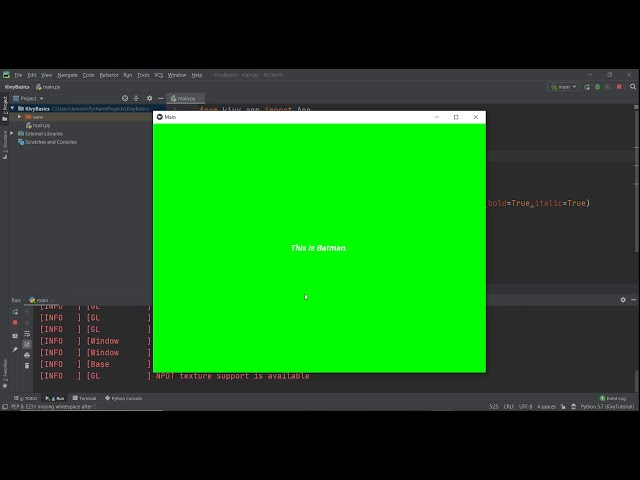
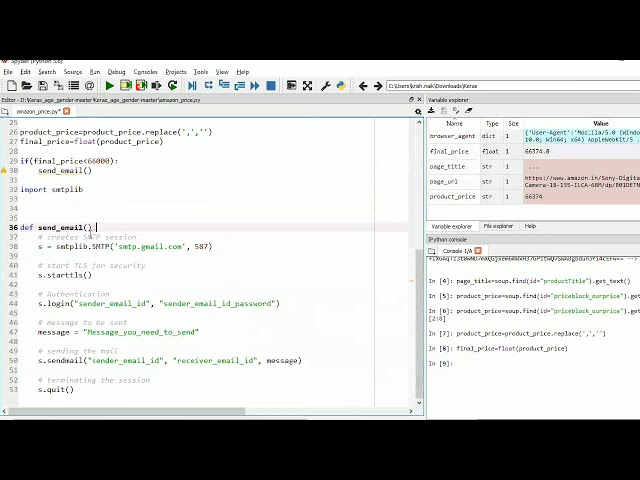
در این مطلب، ویدئو پیاده سازی شبکه های عصبی کانولوشن (CNN) با Keras – Python با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,625 –> 00:00:01,685
2
00:00:02,295 –> 00:00:03,295
3
00:00:05,960 –> 00:00:08,975
هی همه ! به نقطه ویرگول خوش آمدید
4
00:00:08,980 –> 00:00:11,760
در این آموزش، ما یک شبکه عصبی کانولوشن را
5
00:00:11,760 –> 00:00:14,785
با استفاده از keras با Tensorflow به عنوان پشتیبان پیاده سازی
6
00:00:14,785 –> 00:00:17,480
خواهیم کرد، اگر نمی دانید شبکه عصبی کانولوشن چیست یا ندارید، از مجموعه داده رقمی دستی MNIST
7
00:00:17,620 –> 00:00:20,120
برای ساختن یک طبقه بندی کننده رقمی استفاده
8
00:00:20,120 –> 00:00:22,995
می
9
00:00:22,995 –> 00:00:25,805
کنیم. سوالات مربوط به عملکرد
10
00:00:25,805 –> 00:00:29,145
یک CNN، ویدئویی در
11
00:00:29,305 –> 00:00:32,255
مورد عملکرد شبکه عصبی کانولوشنال را تماشا کنید و باید یک ایده اولیه از شبکه عصبی کانولوشنال را به شما ارائه دهد
12
00:00:32,255 –> 00:00:35,295
13
00:00:35,295 –> 00:00:38,325
و سپس می توانیم شروع کنیم.
14
00:00:38,325 –> 00:00:41,255
بنابراین، این کانال همچنین ویدیوهای زیادی در مورد یادگیری ماشینی دارد
15
00:00:41,255 –> 00:00:44,245
و ممکن است بخواهید برای آن مشترک شوید
16
00:00:44,245 –> 00:00:45,805
زیرا من ویدیوهای جدیدی در راه است،
17
00:00:46,560 –> 00:00:49,260
بنابراین بیایید با پیاده سازی شروع
18
00:00:49,260 –> 00:00:51,120
کنیم، ما الگوریتم جنگل های تصادفی را
19
00:00:51,260 –> 00:00:52,560
روی همان مجموعه داده اجرا
20
00:00:52,565 –> 00:00:55,395
کرده بودیم و حدود 96 به ما رسید. % دقت
21
00:00:55,400 –> 00:00:58,440
بنابراین بیایید ببینیم شبکههای عصبی کانولوشن در اینجا چه چیزی را به
22
00:00:58,440 –> 00:00:59,540
ما پیشنهاد
23
00:01:00,280 –> 00:01:03,340
میکنند، من Libararies، Sequential را
24
00:01:03,340 –> 00:01:06,400
از keras.model وارد میکنم، همچنین باید
25
00:01:06,400 –> 00:01:09,460
Dense، Dropout، Activation و
26
00:01:09,465 –> 00:01:12,115
Flatten را از keras.layers وارد کنیم،
27
00:01:12,115 –> 00:01:14,845
به شما توضیح میدهم که معنی هر کدام از آنها چیست ما از آنها
28
00:01:15,335 –> 00:01:19,000
برای لایه کانولوشن استفاده می کنیم، اجازه دهید Convolution2D را نیز وارد کنیم
29
00:01:19,125 –> 00:01:21,755
و برای لایه Max Pooling اجازه دهید MaxPooling2D را انجام
30
00:01:21,755 –> 00:01:24,575
دهیم،
31
00:01:26,015 –> 00:01:28,585
بنابراین برای اعتبارسنجی مدل خود، به
32
00:01:28,585 –> 00:01:31,595
تقسیم تست قطار نیاز داریم، بنابراین،
33
00:01:31,595 –> 00:01:34,615
من از یکی از scikit Learn استفاده خواهم کرد، زیرا من هستم خیلی راحت باهاش
34
00:01:34,615 –> 00:01:36,455
35
00:01:36,455 –> 00:01:39,275
در غیر این صورت Keras یک ابزار برای انجام همان عملکرد دارد.
36
00:01:39,540 –> 00:01:42,560
ما باید pandas
37
00:01:42,580 –> 00:01:45,080
38
00:01:45,080 –> 00:01:48,140
و numpy را نیز وارد کنیم. بنابراین،
39
00:01:48,145 –> 00:01:51,015
این دادههای ما است، این همان چیزی است که به نظر میرسد
40
00:01:51,015 –> 00:01:53,965
باید کمی تغییر دهیم تا بتوانیم آنها را
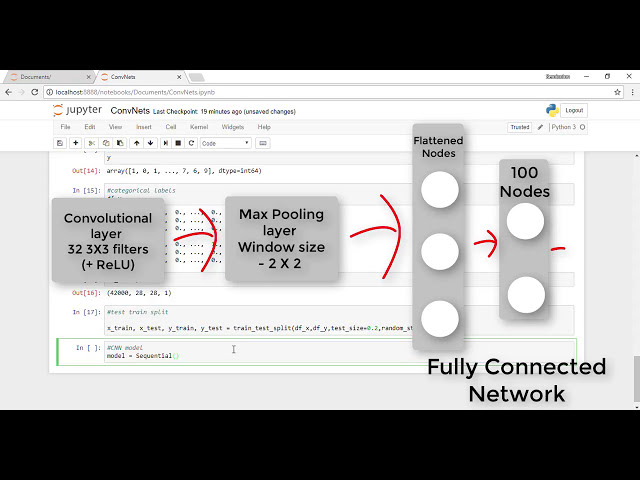
41
00:01:53,965 –> 00:01:56,765
به شبکههای ارتباطی خود وارد کنیم
42
00:01:56,765 –> 00:01:59,600
، بنابراین، در حال حاضر همه پیکسلها
43
00:01:59,600 –> 00:02:04,880
بهصورت ردیفی مرتب شدهاند و ما نیاز به یک تصویر داریم که به صورت نمایش داده شود. ماتریس برای
44
00:02:04,880 –> 00:02:08,320
کار روی آن، بنابراین بیایید
45
00:02:08,535 –> 00:02:11,335
با استفاده از تابع reshape، تصویر، آرایه
46
00:02:11,335 –> 00:02:14,165
را تغییر شکل دهیم، بنابراین آن را به
47
00:02:14,165 –> 00:02:17,215
28 X 28 X 1
48
00:02:17,220 –> 00:02:22,120
28 – ارتفاع، 28 – عرض، 1 – کانال
49
00:02:22,260 –> 00:02:26,160
در تصاویر RGB، میتوانیم 28 X داشته باشیم. 28 X 3
50
00:02:26,300 –> 00:02:29,800
اینجا تصاویر سیاه و سفید است، بنابراین ما 28 X 28 X 1 داریم،
51
00:02:30,115 –> 00:02:32,895
بنابراین من 2 لیست ایجاد می کنم، یکی برای
52
00:02:32,900 –> 00:02:35,900
ذخیره تصاویر و دیگری برای ذخیره برچسب ها است
53
00:02:35,900 –> 00:02:38,020
که بگوییم آیا اولین
54
00:02:38,020 –> 00:02:41,055
عنصر df_x حاوی آرایه پیکسلی است
55
00:02:41,055 –> 00:02:43,605
برای تصویری
56
00:02:43,605 –> 00:02:46,305
که نشاندهنده «4»
57
00:02:46,305 –> 00:02:48,285
است، اولین عنصر y حاوی 4
58
00:02:48,285 –> 00:02:51,295
است، به همین دلیل است که ما 2 لیست داریم، یکی برای ذخیره آرایههای پیکسل و دیگری
59
00:02:51,295 –> 00:02:54,125
برای ذخیره برچسبهای آنها،
60
00:02:54,125 –> 00:02:57,345
بنابراین حالا، اجازه دهید جلوتر بروم و همه پیکسلها
61
00:02:57,345 –> 00:03:00,355
را در فهرست قرار دهیم. لیستی که آنها را به آرایه ها تبدیل می کند
62
00:03:00,375 –> 00:03:03,185
و اجازه می دهد برچسب ها را نیز ذخیره
63
00:03:03,345 –> 00:03:06,235
کنیم، مشکلی که در اینجا به دنبال آن هستیم
64
00:03:06,235 –> 00:03:08,955
مشکل طبقه بندی است، زیرا
65
00:03:08,955 –> 00:03:11,925
ما ارقام را داریم و t را داریم. o آنها را به 10 کلاس
66
00:03:11,925 –> 00:03:13,715
1 تا 10
67
00:03:14,345 –> 00:03:17,205
0 تا 9 طبقه بندی کنید، بنابراین ما نیاز داریم که برچسب ها
68
00:03:17,205 –> 00:03:20,385
یا نتایج ما دسته بندی شوند
69
00:03:20,865 –> 00:03:23,045
در حال حاضر آنها به صورت
70
00:03:23,045 –> 00:03:25,925
0,1,2,3 …..,9 نمایش داده می شوند و این برای ما مشکل است.
71
00:03:25,925 –> 00:03:27,845
و چرا مشکل دارد؟
72
00:03:28,085 –> 00:03:31,135
زیرا ابتدا، برچسبهای 1،2،3،…
73
00:03:31,135 –> 00:03:33,375
نشاندهنده رابطه
74
00:03:33,685 –> 00:03:36,815
2 * (1) = 2 است
75
00:03:36,955 –> 00:03:39,355
که چیزی نیست که ما بخواهیم مدل ما آن را استنباط کند،
76
00:03:39,355 –> 00:03:40,855
77
00:03:41,555 –> 00:03:44,055
ما فقط به شناسایی
78
00:03:44,055 –> 00:03:47,085
ارقام در این مشکل علاقهمندیم
79
00:03:47,085 –> 00:03:49,335
و نه فقط میتوانیم از شکل آن تشخیص داده شود
80
00:03:49,335 –> 00:03:52,225
بنابراین شکل 1 که نشان دهنده مقدار 1
81
00:03:52,225 –> 00:03:54,915
است مستقل از شکل 2 است که نشان دهنده مقدار 2
82
00:03:54,915 –> 00:03:55,915
83
00:03:56,225 –> 00:03:58,645
است، به همین دلیل است که ما نیازی
84
00:03:58,645 –> 00:04:02,135
به رابطه بین برچسب ها نداریم و به همین دلیل است که باید آن را
85
00:04:02,375 –> 00:04:04,875
دسته بندی کنیم. و چگونه طبقه بندی
86
00:04:04,875 –> 00:04:07,335
کردن آن مشکل را حل می کند، بنابراین
87
00:04:07,385 –> 00:04:10,375
وقتی آن را طبقه بندی می کنیم،
88
00:04:10,375 –> 00:04:12,625
برای هر رقم ستون های مختلفی می سازیم
89
00:04:12,960 –> 00:04:14,740
و
90
00:04:14,900 –> 00:04:17,995
سپس رقمی که برچسب است
91
00:04:17,995 –> 00:04:20,334
دارای مقدار 1 و تمام ارقام دیگر دارای ارزش 0 خواهند بود
92
00:04:20,334 –> 00:04:22,955
، برای مثال
93
00:04:22,960 –> 00:04:27,420
0 خواهد بود. بردار 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0
94
00:04:27,420 –> 00:04:30,880
1 بردار 0, 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 را خواهد داشت
95
00:04:30,880 –> 00:04:32,255
پس به این ترتیب،
96
00:04:32,255 –> 00:04:34,975
این بردارها متعامد هستند
97
00:04:34,975 –> 00:04:37,075
و هیچ رابطه ای با یکدیگر ندارند
98
00:04:37,385 –> 00:04:40,505
، بنابراین، keras یک تابع to_categorical دارد
99
00:04:40,505 –> 00:04:43,560
که برچسب ها و تعداد کلاس های ما را می گیرد
100
00:04:43,580 –> 00:04:47,200
و آن را به برچسب های طبقه بندی می کند
101
00:04:47,880 –> 00:04:50,680
و پس از اتمام، بیایید همه چیز را
102
00:04:50,685 –> 00:04:54,105
به آرایه های numpy تبدیل کنیم و بررسی کنیم شکل
103
00:04:54,505 –> 00:04:56,685
و اشکال خوب هستند،
104
00:04:57,315 –> 00:05:00,125
سپس دادهها را به آزمایش تقسیم میکنیم و آموزش میدهیم و با
105
00:05:00,125 –> 00:05:01,675
پیشپردازش دادههایمان
106
00:05:01,675 –> 00:05:04,755
برای تغذیه آنها به CNN یا شبکه عصبی کانولوشنال
107
00:05:04,755 –> 00:05:08,245
کار میکنیم. حالا اجازه دهید اجرای بخش اصلی
108
00:05:08,805 –> 00:05:10,905
را شروع کنیم.
109
00:05:10,905 –> 00:05:13,425
110
00:05:13,595 –> 00:05:16,155
ما به یک مدل متوالی نیاز داریم،
111
00:05:16,160 –> 00:05:17,695
بنابراین a را شروع می کنیم مدل متوالی
112
00:05:17,700 –> 00:05:20,860
با تایپ کردن model = sequential()
و قبل از اینکه هر لایه ای را اضافه
113
00:05:20,860 –> 00:05:23,935
کنیم، ابتدا معماری خود را تعریف می
114
00:05:23,935 –> 00:05:26,025
کنیم، سپس باید آن را آزمایش کرده و تغییراتی
115
00:05:26,025 –> 00:05:28,605
در آن ایجاد کنیم تا در دقت بهبود پیدا کند،
116
00:05:28,975 –> 00:05:31,445
بنابراین ما به یک لایه کانولوشنال نیاز داریم
117
00:05:31,445 –> 00:05:34,535
که 28 x طول می کشد. 28 تصویر به عنوان ورودی
118
00:05:34,535 –> 00:05:37,225
و اجازه دهید لایه کانولوشن
119
00:05:37,225 –> 00:05:40,205
دارای 32 فیلتر باشد، هر کدام در اندازه 3X3
120
00:05:40,285 –> 00:05:43,295
و اجازه دهید فعال سازی را به عنوان ReLU در
121
00:05:43,295 –> 00:05:46,685
نظر بگیریم تا مجبور نباشیم لایه عادی سازی را جداگانه اضافه کنیم.
122
00:05:47,035 –> 00:05:50,085
و اجازه دهید حداکثر لایه ادغام با اندازه 2X2 را اضافه کرده
123
00:05:50,085