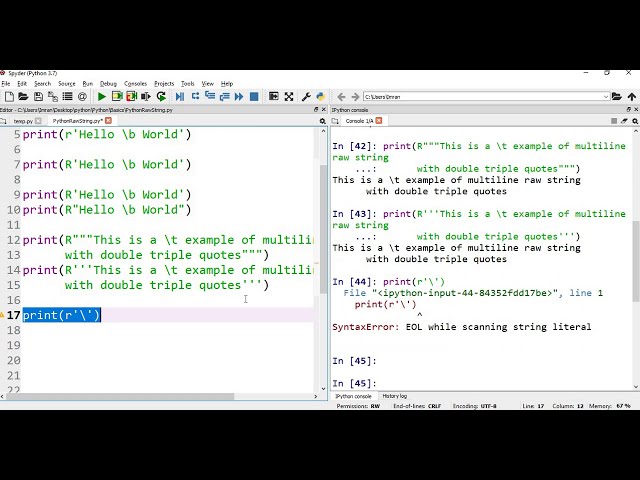
در این مطلب، ویدئو جانت ماتسن – برنامه نویسی میکروب ها با استفاده از پایتون – PyCon 2018 با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,580 –> 00:00:05,779
[تشویق حضار]
2
00:00:05,779 –> 00:00:07,740
از همه شما سپاسگزارم که امروز به سخنرانی من آمدید
3
00:00:07,740 –> 00:00:10,740
زیرا او گفت که نام من جانت است.
4
00:00:10,740 –> 00:00:13,049
5
00:00:13,049 –> 00:00:14,790
6
00:00:14,790 –> 00:00:17,460
7
00:00:17,460 –> 00:00:19,619
اسلاید میکنید یا میتوانید
8
00:00:19,619 –> 00:00:21,090
با برنامهنویسی
9
00:00:21,090 –> 00:00:25,470
میکروبها آنها را کمی به دست بگیرید، بنابراین همانطور که همه میدانید ما
10
00:00:25,470 –> 00:00:27,390
از میکروبها برای تولید
11
00:00:27,390 –> 00:00:29,730
مواد ارزشمندی مانند آبجو و شراب برای
12
00:00:29,730 –> 00:00:32,579
هزاران سال استفاده کردهایم، ممکن است شما را متعجب کنید
13
00:00:32,579 –> 00:00:34,410
که در دهههای اخیر ما یاد
14
00:00:34,410 –> 00:00:36,420
گرفتهایم که مواد بسیار زیادی تولید کنیم. تنوع گستردهتری از
15
00:00:36,420 –> 00:00:39,899
مولکولها با استفاده از این میکروبها، به
16
00:00:39,899 –> 00:00:42,329
عنوان مثال، ما میتوانیم تعدادی
17
00:00:42,329 –> 00:00:44,100
داروی مختلف از جمله انسولین مصنوعی را
18
00:00:44,100 –> 00:00:46,620
با استفاده از میکروبهایی مانند E.coli و
19
00:00:46,620 –> 00:00:50,070
مخمر تولید کنیم، ما میتوانیم طعمها و عطرهای مختلفی را تولید کنیم
20
00:00:50,070 –> 00:00:52,050
که در
21
00:00:52,050 –> 00:00:53,879
محصولاتی وجود دارد که همه ما کاملاً با آنها آشنا هستیم و به طور فزایندهای با آنها آشنا هستیم.
22
00:00:53,879 –> 00:00:56,610
ما در حال یافتن
23
00:00:56,610 –> 00:00:58,770
کاربردهایی برای مواد بیولوژیکی در
24
00:00:58,770 –> 00:01:00,660
محصولات یا در فرآیندهایی مانند
25
00:01:00,660 –> 00:01:02,969
تولید لوازم الکترونیکی هستیم که
26
00:01:02,969 –> 00:01:06,330
نسبتاً پیشرفته هستند، اینجاست که زایوژن
27
00:01:06,330 –> 00:01:09,210
وارد می شود زیرا برای الکل می توان
28
00:01:09,210 –> 00:01:11,460
میکروب هایی را دریافت کرد. به طور طبیعی آن را تولید میکنیم، اما
29
00:01:11,460 –> 00:01:13,049
بیشتر و بیشتر برای انواع مواد شیمیایی
30
00:01:13,049 –> 00:01:14,700
که میخواهیم بسازیم، مجبور به انجام این کار هستید، ما
31
00:01:14,700 –> 00:01:16,560
ارگانیسمها را تغییر میدهیم تا آنها را وادار به
32
00:01:16,560 –> 00:01:18,299
تولید ترکیبات مورد
33
00:01:18,299 –> 00:01:21,210
علاقهشان کنیم.
34
00:01:21,210 –> 00:01:23,280
35
00:01:23,280 –> 00:01:25,710
کار می کند اما بعداً تصویری را به شما نشان خواهم داد که
36
00:01:25,710 –> 00:01:30,240
کمی واقعی تر است، بنابراین
37
00:01:30,240 –> 00:01:31,710
تقاضا برای مواد شیمیایی که به
38
00:01:31,710 –> 00:01:34,770
شما نشان دادم فروش بسیار بالایی دارد حدود
39
00:01:34,770 –> 00:01:37,500
80 میلیارد دلار در سال و بنابراین برای
40
00:01:37,500 –> 00:01:39,390
همگام شدن با این تقاضا، ما این
41
00:01:39,390 –> 00:01:42,060
میکروب ها را در مخازن واقعا بزرگی که می
42
00:01:42,060 –> 00:01:45,990
توانند چندین طبقه ارتفاع داشته باشند و تا
43
00:01:45,990 –> 00:01:48,060
صدها هزار لیتر
44
00:01:48,060 –> 00:01:51,780
مایع را در آنها مصرف کنند، البته سیمونتون نمی
45
00:01:51,780 –> 00:01:53,909
تواند آزمایش هایی در این مقیاس انجام دهد، بنابراین در عوض
46
00:01:53,909 –> 00:01:56,009
ما آزمایش های خود را کاهش می دهیم و سعی
47
00:01:56,009 –> 00:02:00,060
می کنیم آنها را به سرعت انجام دهیم. ممکن است
48
00:02:00,060 –> 00:02:02,189
آزمایش توان بالای ما چیزی
49
00:02:02,189 –> 00:02:02,850
شبیه به این باشد،
50
00:02:02,850 –> 00:02:06,299
ابتدا باید انواعی از
51
00:02:06,299 –> 00:02:08,729
میکروب ها را بسازیم که در آن هر میکروب
52
00:02:08,729 –> 00:02:11,400
برنامه ژنتیکی متفاوتی را اجرا
53
00:02:11,400 –> 00:02:14,540
54
00:02:14,540 –> 00:02:17,370
می کند و بعد از رشد، همه ترکیبات ژنتیکی متفاوتی دارند. و این ارگانیسم ها را به
55
00:02:17,370 –> 00:02:19,739
صورت موازی با استفاده از حجم های کوچکی که ما
56
00:02:19,739 –> 00:02:22,620
با چشم های موازی داریم آزمایش کنیم، مانند داشتن صفحات 96 چاهی
57
00:02:22,620 –> 00:02:26,489
مانند این، می توانیم از آنها برای
58
00:02:26,489 –> 00:02:28,170
اندازه گیری عملکرد استفاده کنیم و بفهمیم
59
00:02:28,170 –> 00:02:30,510
کدام سویه ها نسبت
60
00:02:30,510 –> 00:02:31,920
به سویه های مادری که آنها را از آنها ساخته ایم بهبود یافته اند
61
00:02:31,920 –> 00:02:34,890
و سپس چه زمانی. ما نامزدهایی را پیدا
62
00:02:34,890 –> 00:02:37,799
میکنیم که امیدوارند میتوانیم آنها
63
00:02:37,799 –> 00:02:40,799
را در آزمایشهای راکتور رومیزی در مقیاس بزرگتر ارائه
64
00:02:40,799 –> 00:02:42,150
کنیم، جایی که محیط کنترلشدهتری داریم
65
00:02:42,150 –> 00:02:44,010
و
66
00:02:44,010 –> 00:02:47,549
هر چند وقت یکبار با دقت بیشتری آزمایش میکنیم که این میکروبها چقدر خوب عمل
67
00:02:47,549 –> 00:02:49,470
میکنند، وقتی یک برنده واقعی پیدا میکنیم،
68
00:02:49,470 –> 00:02:51,900
میتوانیم آنها را به بزرگ بفرستیم. مخازن و
69
00:02:51,900 –> 00:02:53,459
آزمایش چند میلیون دلاری را
70
00:02:53,459 –> 00:02:59,420
اجرا کنید تا ببینید واقعاً چگونه در مقیاس
71
00:02:59,420 –> 00:03:01,500
محاسباتی و
72
00:03:01,500 –> 00:03:03,720
73
00:03:03,720 –> 00:03:05,760
چالشهای ما عمل میکنند.
74
00:03:05,760 –> 00:03:08,099
75
00:03:08,099 –> 00:03:09,569
76
00:03:09,569 –> 00:03:13,769
ما همچنین نیاز به
77
00:03:13,769 –> 00:03:15,750
خودکارسازی مجموعه داده ها و
78
00:03:15,750 –> 00:03:17,639
توانایی پیوند سطوح مختلف عملکرد
79
00:03:17,639 –> 00:03:19,230
با ترکیبات ژنتیکی داریم از
80
00:03:19,230 –> 00:03:22,010
آن سویه ها و ما نیاز به شناسایی
81
00:03:22,010 –> 00:03:24,720
پیشرفت های آماری قابل توجهی داریم
82
00:03:24,720 –> 00:03:26,940
که می تواند با
83
00:03:26,940 –> 00:03:30,660
داده
84
00:03:30,660 –> 00:03:32,430
85
00:03:32,430 –> 00:03:34,440
های تجربی
86
00:03:34,440 –> 00:03:38,129
87
00:03:38,129 –> 00:03:39,930
88
00:03:39,930 –> 00:03:41,730
دشوار باشد. در رباتها و
89
00:03:41,730 –> 00:03:43,919
اتوماسیون و این فیلم
90
00:03:43,919 –> 00:03:45,540
برخی از کارهایی را که ما با رباتها انجام میدهیم به شما میدهد،
91
00:03:45,540 –> 00:03:48,690
بنابراین یکی در بالا سمت چپ
92
00:03:48,690 –> 00:03:50,910
رباتی است که مایعات را از
93
00:03:50,910 –> 00:03:52,590
چاههای یک صفحه جمع میکند و آنها را به
94
00:03:52,590 –> 00:03:55,560
دیگری میبرد که در وسط است.
95
00:03:55,560 –> 00:03:56,940
برداشتن انواع مختلف ژنتیکی از یک
96
00:03:56,940 –> 00:03:58,530
صفحه که ممکن است بخواهید آن را آزمایش کنید و
97
00:03:58,530 –> 00:04:00,810
صفحه سمت راست در حال قرار دادن یک
98
00:04:00,810 –> 00:04:02,280
صفحه در دستگاهی برای اندازه گیری
99
00:04:02,280 –> 00:04:06,720
عملکرد سویه های انتخاب شده است، اکنون
100
00:04:06,720 –> 00:04:08,099
متوجه شدم که این یک
101
00:04:08,099 –> 00:04:09,959
کنفرانس مهندسی ژنتیک نیست و بنابراین می
102
00:04:09,959 –> 00:04:12,060
خواستم مکث کنید و آنچه را که انجام می دهیم با
103
00:04:12,060 –> 00:04:13,889
عباراتی که برای این دسته از جمعیت آشناتر است توضیح دهید.
104
00:04:13,889 –> 00:04:17,488
105
00:04:17,488 –> 00:04:19,798
106
00:04:19,798 –> 00:04:22,048
سعی کنیم ژن X را مختل کنیم زیرا
107
00:04:22,048 –> 00:04:23,969
آن ژن برای
108
00:04:23,969 –> 00:04:26,520
تولید یک ماده شیمیایی مهم است که ما به آن علاقه
109
00:04:26,520 –> 00:04:29,140
مندیم اولین کاری که باید انجام دهیم این است
110
00:04:29,140 –> 00:04:31,240
که آن ایده قابل تفسیر انسانی را در
111
00:04:31,240 –> 00:04:33,880
زبان سطح پایین DNA جمع آوری کنیم و این کار را انجام می دهیم.
112
00:04:33,880 –> 00:04:35,920
با استفاده از برنامهای که هم در
113
00:04:35,920 –> 00:04:39,430
پایتون در پایتون حضور خواهیم داشت که به آن هلیکس مارپیچ میگویند، همچنین
114
00:04:39,430 –> 00:04:41,380
به ما کمک میکند دستورالعملهایی را برای
115
00:04:41,380 –> 00:04:43,240
ساخت حلقهای از DNA ایجاد کنیم و بررسی کنیم
116
00:04:43,240 –> 00:04:47,050
که درست و ساخته شده است، سپس
117
00:04:47,050 –> 00:04:48,520
باید این DNA را در یک ارگانیسم جدید اعمال کنیم.
118
00:04:48,520 –> 00:04:50,380
این در واقع بسیار
119
00:04:50,380 –> 00:04:52,660
شبیه به پچ git است که در آن ناحیه
120
00:04:52,660 –> 00:04:54,970
ای از شباهت دنباله ای قبل و بعد از
121
00:04:54,970 –> 00:04:56,920
تغییری که ما کدگذاری می کنیم وجود دارد که مشخص می کند
122
00:04:56,920 –> 00:05:00,730
در کجا یکپارچه می شود،
123
00:05:00,730 –> 00:05:02,770
این موجودات اصلاح شده را می گیریم و آنها را
124
00:05:02,770 –> 00:05:05,170
در این صفحات قرار می دهیم که می توانیم آنها را در نظر بگیریم.
125
00:05:05,170 –> 00:05:07,300
مانند تستهای واحد، زیرا
126
00:05:07,300 –> 00:05:09,400
آنها کوچکترین و سریعترین تستهایی هستند که میتوانیم انجام دهیم و
127
00:05:09,400 –> 00:05:11,650
به شما نشان میدهند که چگونه
128
00:05:11,650 –> 00:05:13,960
یک واحد کار میکند، اما مشخص است
129
00:05:13,960 –> 00:05:15,820
که نشان نمیدهد که واقعاً چگونه از آن به عنوان مقیاس استفاده میشود.
130
00:05:15,820 –> 00:05:21,970
هر چند
131
00:05:21,970 –> 00:05:23,980
وقت یکبار تست ادغام فشرده تر را
132
00:05:23,980 –> 00:05:26,200
انجام دهید و اینها آزمایشاتی
133
00:05:26,200 –> 00:05:28,810
طراحی شده اند که بسیار بیشتر منعکس کننده
134
00:05:28,810 –> 00:05:30,670
نحوه عملکرد کد یا
135
00:05:30,670 –> 00:05:34,360
ارگانیسم در مقیاس هستند و درست
136
00:05:34,360 –> 00:05:36,340
مانند کدی که دریافت می کنیم ارگانیسم فیزیکی را
137
00:05:36,340 –> 00:05:38,290
به فریزرهای خود متعهد می کنیم. و این
138
00:05:38,290 –> 00:05:40,960
ترکیب ژنتیکی است و این بدان معناست که
139
00:05:40,960 –> 00:05:42,610
بعداً میتوانیم آن موجودات را
140
00:05:42,610 –> 00:05:44,770
از فریزر برای آزمایشهای بیشتر
141
00:05:44,770 –> 00:05:46,510
بررسی کنیم یا ترکیبات ژنتیکی آنها را بررسی کنیم تا
142
00:05:46,510 –> 00:05:49,780
تجزیه و تحلیل دادهها را به طور مشابه انجام دهیم، میتوانیم
143
00:05:49,780 –> 00:05:51,460
دو ترکیب ژنتیکی را انتخاب کنیم و
144
00:05:51,460 –> 00:05:53,260
کاری شبیه به git diff انجام دهیم تا بفهمیم
145
00:05:53,260 –> 00:05:55,060
کدام ژنتیکی است. ویرایشها باعث ایجاد
146
00:05:55,060 –> 00:06:00,070
تغییر جالبی در عملکرد شد، بنابراین
147
00:06:00,070 –> 00:06:01,840
زیموژن گربه ما دارای چالشهایی است که
148
00:06:01,840 –> 00:06:03,730
در شرکتهای فناوری معمولی معمول نیست
149
00:06:03,730 –> 00:06:05,410
و من میخواستم برخی
150
00:06:05,410 –> 00:06:08,920
از آن موضوعات را برجسته کنم، اول اینکه
151
00:06:08,920 –> 00:06:11,470
فضای جستجوی DNA که ما در آن بهینهسازی میکنیم
152
00:06:11,470 –> 00:06:12,220
153
00:06:12,220 –> 00:06:14,920
، متوسط است. ژنوم میکروبی حاوی
154
00:06:14,920 –> 00:06:18,100
حدود چهار هزار یا چهار میلیون
155
00:06:18,100 –> 00:06:21,430
کاراکتر DNA است و میتوان آنها
156
00:06:21,430 –> 00:06:23,050
را در چند هزار ژن مختلف سازماندهی کرد.
157
00:06:23,050 –> 00:06:26,320
بازنمایی را مشخص کنید، اما
158
00:06:26,320 –> 00:06:28,840
علیرغم پیشرفتهای بزرگ در زیستشناسی، ما
159
00:06:28,840 –> 00:06:30,730
هنوز فقط
160
00:06:30,730 –> 00:06:33,160
درباره نیمی از این ژنها درک خوبی
161
00:06:33,160 –> 00:06:35,320
از عملکرد آنها داریم و بنابراین واقعاً
162
00:06:35,320 –> 00:06:36,940
مانند این است که در حال بهینهسازی یک پایه کد هستیم که در آن
163
00:06:36,940 –> 00:06:38,830
درک مبهمی
164
00:06:38,830 –> 00:06:41,430
از همه چیز داریم. عملکردهایی
165
00:06:41,430 –> 00:06:43,870
که به شما ایده می دهد
166
00:06:43,870 –> 00:06:45,330
کاوش تجربی این
167
00:06:45,330 –> 00:06:48,460
تصور که شما می خواهید هر ژنی را
168
00:06:48,460 –> 00:06:50,559
در یک ژنوم برای ژنومی با 4000
169
00:06:50,559 –> 00:06:53,409
ژن مختل کنید، اگر فقط می خواهید به
170
00:06:53,409 –> 00:06:55,719
تک تک اختلالات دو ژن نگاه کنید، آنگاه
171
00:06:55,719 –> 00:06:58,089
فقط باید 4000 ژن بسازید. فشار می دهد
172
00:06:58,089 –> 00:07:00,460
و 4000 آزمایش انجام می دهد و این برای zymogen آسان است،
173
00:07:00,460 –> 00:07:04,870
اما zymogen اغلب
174
00:07:04,870 –> 00:07:06,879
می خواهد سویه هایی را با تغییرات بسیار بسیار
175
00:07:06,879 –> 00:07:08,409
بیشتر در آنها بسازد و
176
00:07:08,409 –> 00:07:09,879
ترکیبات این فضا که در آن
177
00:07:09,879 –> 00:07:12,819
کاوش می شود به سرعت از
178
00:07:12,819 –> 00:07:15,370
آنچه ما می توانیم به صورت تجربی انجام دهیم رشد می کند، بنابراین اگر می خواهید
179
00:07:15,370 –> 00:07:18,099
امتحان کنید. ترکیبی از شش
180
00:07:18,099 –> 00:07:19,539
ویرایش ژن و شما می خواستید آن
181
00:07:19,539 –> 00:07:22,149
فضا را به طور کامل کاوش کنید، باید 4000 را بسازید،
182
00:07:22,149 –> 00:07:25,059
شش گونه را انتخاب کنید و
183
00:07:25,059 –> 00:07:27,129
این شما را به 10 سویه می رساند. هفدهمین آزمایش های مختلف را
184
00:07:27,129 –> 00:07:30,069
می خواهید اجرا کنید و حالا حتی
185
00:07:30,069 –> 00:07:32,080
اگر بتوانیم آزمایش ها را با سرعت
186
00:07:32,080 –> 00:07:34,719
1 در ثانیه انجام دهیم، باز هم بیش
187
00:07:34,719 –> 00:07:37,809
از 10 تا 10 سال طول می کشد تا آن فضا را کشف کنیم
188
00:07:37,809 –> 00:07:40,330
و این سن جهان است،
189
00:07:40,330 –> 00:07:42,819
بنابراین باید انجام دهیم. چیزی هوشمندتر و
190
00:07:42,819 –> 00:07:44,499
این انگیزه می دهد که چرا ما
191
00:07:44,499 –> 00:07:46,149
در یادگیری ماشینی سرمایه گذاری زیادی برای
192
00:07:46,149 –> 00:07:50,830
طراحی سویه های خود انجام می دهیم جنبه دیگری از آنچه
193
00:07:50,830 –> 00:07:52,629
بهینه سازی ژنوم را سخت می کند این است که ما
194
00:07:52,629 –> 00:07:55,449
نمی توانیم فقط شبیه سازی کنیم، بنابراین اگر
195
00:07:55,449 –> 00:07:57,039
اخبار و
196
00:07:57,039 –> 00:07:58,599
هوش مصنوعی سال گذشته را دنبال کرده اید
197
00:07:58,599 –> 00:08:01,889
با این ایده آشنا هستم که میتوانیم از
198
00:08:01,889 –> 00:08:04,419
الگوریتمهایی استفاده کنیم که میتوانند خودشان را در
199
00:08:04,419 –> 00:08:07,209
بازیهایی مانند go بازی کنند و این میتواند به
200
00:08:07,209 –> 00:08:09,249
آموزش الگوریتمی کمک کند تا حتی قهرمانان بزرگ سازمانهای غیر دولتی شود
201
00:08:09,249 –> 00:08:12,520
، البته این شبیهسازیها
202
00:08:12,520 –> 00:08:15,789
به یک استراتژی بسیار زمینی نیاز دارند. این استراتژی
203
00:08:15,789 –> 00:08:18,009
نیاز به شبیهسازیهای بسیار دقیق
204
00:08:18,009 –> 00:08:19,749
شما دارد محیطی که برای این می
205
00:08:19,749 –> 00:08:22,089
تواند بازی رفتن باشد و بنابراین ممکن است فکر کنید که ما
206
00:08:22,089 –> 00:08:24,490
می توانیم این را برای میکروب ها اعمال کنیم، اما
207
00:08:24,490 –> 00:08:26,889
میکروب ها با وجود اندازه کوچکشان در
208
00:08:26,889 –> 00:08:29,020
واقع بسیار پیچیده تر هستند و
209
00:08:29,020 –> 00:08:32,969
چنین شبیه سازی وجود نداشت که بتوانیم از
210
00:08:33,089 –> 00:08:35,799
جنبه دیگری استفاده کنیم این پدیده ای به نام
211
00:08:35,799 –> 00:08:39,549
اپیستاز است که این واقعیت است که
212
00:08:39,549 –> 00:08:41,409
ترکیبی از ویرایش های ژنتیکی می تواند
213
00:08:41,409 –> 00:08:44,529
اثرات غیرقابل پیش بینی داشته باشد بنابراین ممکن است فکر کنید
214
00:08:44,529 –> 00:08:47,019
که اگر جالب هستند ژن X
215
00:08:47,019 –> 00:08:48,699
برای تولید ماده
216
00:08:48,699 –> 00:08:50,620
شیمیایی مهم است. علاقه مندم که افزایش
217
00:08:50,620 –> 00:08:52,900
سطح بیان ممکن است به تولید مواد شیمیایی بیشتر کمک کند،
218
00:08:52,900 –> 00:08:57,300
اما اتفاقات بدی ممکن است رخ دهد،
219
00:08:57,300 –> 00:08:59,980
من در واقع طرفدار گوشت قرمز نیستم، اما
220
00:08:59,980 –> 00:09:01,900
تصور کنید که در یک کارخانه تولید همبرگر
221
00:09:01,900 –> 00:09:03,970
هستید و وظیفه شما بهینه سازی
222
00:09:03,970 –> 00:09:07,210
فرآیند است و متوجه می شوید که وجود دارد.
223
00:09:07,210 –> 00:09:09,340
مرحله کلیدی شالیکاری که در آن مردم
224
00:09:09,340 –> 00:09:10,810
این پتها را با دست کنار هم میچینند
225
00:09:10,810 –> 00:09:15,760
و شما با این دستگاه جدید شگفتانگیز آشنا میشوید
226
00:09:15,760 –> 00:09:17,470
که
227
00:09:17,470 –> 00:09:19,240
سرعت تشکیل شالیکاری شما را هزار برابر افزایش میدهد
228
00:09:19,240 –> 00:09:20,950
و بنابراین فکر میکنید این عالی است
229
00:09:20,950 –> 00:09:22,690
که ما این دستگاه را دریافت میکنیم.
230
00:09:22,690 –> 00:09:24,070
231
00:09:24,070 –> 00:09:27,280
و اگر عملیات پایین دستی شما
232
00:09:27,280 –> 00:09:29,080
برای این نرخ افزایش یافته تشکیل شالی که می توانید تنظیم نشده باشد، عملیات خود را تسریع خواهیم کرد که به خوبی انجام شد.
233
00:09:29,080 –> 00:09:31,930
234
00:09:31,930 –> 00:09:33,730
به سرعت کف کارخانه خود را
235
00:09:33,730 –> 00:09:36,130
با انبوهی از گوشت خام غرق کنید و هیچ کس نمی
236
00:09:36,130 –> 00:09:38,070
خواهد که
237
00:09:38,070 –> 00:09:40,150
به طور عجیبی این یک قیاس بسیار خوب
238
00:09:40,150 –> 00:09:41,860
برای برخی از اصول
239
00:09:41,860 –> 00:09:44,560
میکروب های مهندسی است زیرا
240
00:09:44,560 –> 00:09:47,920
گوشت همبرگر مشابه خوبی برای یک
241
00:09:47,920 –> 00:09:50,530
ماده شیمیایی در سلولی است که ممکن است به میزان بالایی از آن نیاز داشته باشید.
242
00:09:50,530 –> 00:09:52,540
واکنش از طریق
243
00:09:52,540 –> 00:09:54,940
مجموعهای از واکنشها انجام میشود، اما
244
00:09:54,940 –> 00:09:56,890
اگر واکنش پاییندستی را برای
245
00:09:56,890 –> 00:09:58,330
کنترل افزایش عرضه یک
246
00:09:58,330 –> 00:10:01,000
ماده شیمیایی مهم تنظیم نکردهاید، میتوانید
247
00:10:01,000 –> 00:10:02,500
آن ماده شیمیایی را انباشته کنید و در واقع میتواند
248
00:10:02,500 –> 00:10:05,890
سلول را بکشد، بنابراین این فقط یک طعم
249
00:10:05,890 –> 00:10:07,450
اپیستازی است و وجود دارد. بسیاری از انواع در
250
00:10:07,450 –> 00:10:08,740
زیست شناسی که بهینه سازی
251
00:10:08,740 –> 00:10:10,540
ما را به
252
00:10:10,540 –> 00:10:14,680
چالش می کشد قلب چالش بهینه
253
00:10:14,680 –> 00:10:16,930
254
00:10:16,930 –> 00:10:20,080
سازی
255
00:10:20,080 –> 00:10:21,790
ما را سخت
256
00:10:21,790 –> 00:10:23,470
می کند.
257
00:10:23,470 –> 00:10:26,020
مخازن می توانند رشد کنند و تقسیم شوند و
258
00:10:26,020 –> 00:10:29,140
حجم زیادی را پر کنند، اما از طرف دیگر
259
00:10:29,140 –> 00:10:30,910
ما به سلول هایی نیاز داریم که بتوانند
260
00:10:30,910 –> 00:10:32,560
مواد شیمیایی زیادی تولید کنند. و در نهایت
261
00:10:32,560 –> 00:10:35,860
به همین دلیل است که ما آنها را رشد می دهیم و برای
262
00:10:35,860 –> 00:10:37,540
ارائه زمینه ای در مورد اینکه چقدر
263
00:10:37,540 –> 00:10:40,330
این تعادل را به سختی فشار می دهیم، اغلب می توانیم میکروب
264
00:10:40,330 –> 00:10:42,100
هایی بسازیم که می توانند 90٪ حداکثر تئوری خود را تولید کنند
265
00:10:42,100 –> 00:10:45,040
که بازگشت
266
00:10:45,040 –> 00:10:47,350
به قیاس گاو مانند غذا دادن به یک
267
00:10:47,350 –> 00:10:49,180
گاو با وزن 100 پوند است. دانه و گرفتن
268
00:10:49,180 –> 00:10:51,760
90 پوند کره، بنابراین این تعادل
269
00:10:51,760 –> 00:10:53,380
مهم است و ما میخواهیم آن را واقعاً
270
00:10:53,380 –> 00:10:58,690
سخت کنیم، این برای تشبیهات گاو است.
271
00:10:58,690 –> 00:11:01,660
272
00:11:01,660 –> 00:11:03,460
273
00:11:03,460 –> 00:11:05,590
274
00:11:05,590 –> 00:11:06,350
275
00:11:06,350 –> 00:11:08,900
تیم های علمی، بنابراین اگر شما یک
276
00:11:08,900 –> 00:11:11,060
شرکت فناوری سنتی تر مانند یک
277
00:11:11,060 –> 00:11:13,430
شرکت تجزیه و تحلیل وب هستید، آزمایش شما می
278
00:11:13,430 –> 00:11:15,470
تواند به سادگی نشان دادن دو
279
00:11:15,470 –> 00:11:18,200
نسخه مختلف از یک وب سایت باشد و ممکن است
280
00:11:18,200 –> 00:11:20,090
آن آزمایش را راه اندازی کنید و در عرض یک روز
281
00:11:20,090 –> 00:11:21,680
می توانید میلیون ها
282
00:11:21,680 –> 00:11:23,780
مشاهده مستقل در مورد آن داشته باشید. کدام گزینه
283
00:11:23,780 –> 00:11:27,500
در zymogen بهتر کار می کند، از طرف دیگر برای
284
00:11:27,500 –> 00:11:29,450
هر ایده ای که می خواهیم آزمایش کنیم، باید
285
00:11:29,450 –> 00:11:31,010
یک موجود زنده بسازیم
286
00:11:31,010 –> 00:11:33,560
و مقدار che را اندازه گیری کنیم. مایکال
287
00:11:33,560 –> 00:11:36,200
می تواند تولید کند و در نتیجه فرآیند ما
288
00:11:36,200 –> 00:11:38,270
289
00:11:38,270 –> 00:11:40,160
زمان و هزینه بیشتری می گیرد و این بر برخی از
290
00:11:40,160 –> 00:11:44,420
استراتژی های ما نیز تأثیر می گذارد، بنابراین برای جمع بندی
291
00:11:44,420 –> 00:11:48,020
چالش این است که ما این ژنوم بزرگ را
292
00:11:48,020 –> 00:11:49,730
داریم که سعی می کنیم آن را بهینه کنیم و
293
00:11:49,730 –> 00:11:51,470
فقط داریم در واقع درک مبهم
294
00:11:51,470 –> 00:11:54,290
از نحوه کار همه قطعات ما
295
00:11:54,290 –> 00:11:56,630
به شبیهسازیهای دقیق دسترسی نداریم و بنابراین
296
00:11:56,630 –> 00:11:58,160
نمیتوانیم فقط به برخی از روندهای یادگیری تقویتی بپریم، بلکه در
297
00:11:58,160 –> 00:12:01,310
حال
298
00:12:01,310 –> 00:12:03,620
متعادل کردن چندین تابع هدف
299
00:12:03,620 –> 00:12:05,360
هستیم که همگی در تضاد هستند، زیرا همه آنها متضاد هستند.
300
00:12:05,360 –> 00:12:06,860
نیاز به منابع بسیار زیادی برای سلولها
301
00:12:06,860 –> 00:12:09,800
داریم و ما این
302
00:12:09,800 –> 00:12:14,090
آزمایشهای گرانقیمت و زمانبر را داریم که به
303
00:12:14,090 –> 00:12:15,710
این معنی نیست که zymogen راهحلهایی ندارد
304
00:12:15,710 –> 00:12:17,090
و این جمعیت خوشحال خواهند شد که بشنوند
305
00:12:17,090 –> 00:12:18,920
که بسیاری از راهحلهای ما به شدت به پایتون تکیه دارند و
306
00:12:18,920 –> 00:12:24,230
بهویژه ما را پیشبینی میکنند.
307
00:12:24,230 –> 00:12:26,120
در حال تلاش برای گردآوری
308
00:12:26,120 –> 00:12:28,610
اطلاعات بیولوژیکی با نتایج تجربی در مورد
309
00:12:28,610 –> 00:12:30,530
نحوه عملکرد سویههای ما برای
310
00:12:30,530 –> 00:12:33,290
پیشبینی این است که کدام ویرایشهای ژنتیکی




![فیلم آموزشی: تجزیه و تحلیل سری زمانی در پایتون | پروژه پیش بینی سری زمانی [تکمیل] | علم داده پایتون با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/MmC4b7gPY0Qimage2.jpg)