در این مطلب، ویدئو دستهبندی رقم دستنویس در پایتون با استفاده از یادگیری scikit با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:02,929 –> 00:00:05,819
در این ویدیو به نحوه
2
00:00:05,819 –> 00:00:08,630
استفاده از الگوریتم چاقوی ساده برای
3
00:00:08,630 –> 00:00:14,639
طبقهبندی رقم دستنویس با استفاده از
4
00:00:14,639 –> 00:00:18,420
مجموعه دادهای به نام فهرست M نگاه میکنیم، بنابراین از
5
00:00:18,420 –> 00:00:23,760
scikit-learn برای این منظور استفاده میکنیم و بله،
6
00:00:23,760 –> 00:00:27,980
بیایید شروع کنیم، بنابراین ابتدا باید
7
00:00:27,980 –> 00:00:32,430
مقداری را وارد کنیم. از کتابخانههایی که به آنها
8
00:00:32,430 –> 00:00:36,329
نیاز داریم، بنابراین اول از همه باید matplotlib را وارد کنیم،
9
00:00:36,329 –> 00:00:41,399
سپس scikit-learn و numpy
10
00:00:41,399 –> 00:00:51,600
این سه چیز هستند، سپس
11
00:00:51,600 –> 00:00:59,760
numpy را وارد کنیم، بگوییم p، سپس باید
12
00:00:59,760 –> 00:01:04,890
مجموعه دادهها را وارد کنیم، بنابراین از مجموعه دادههای اسکاتلند، دادهها را
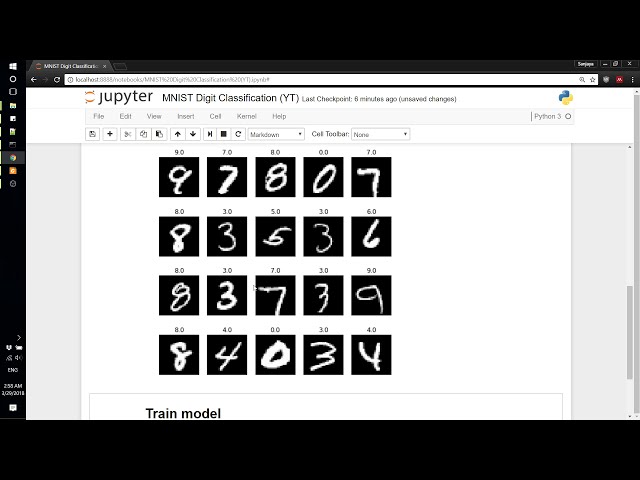
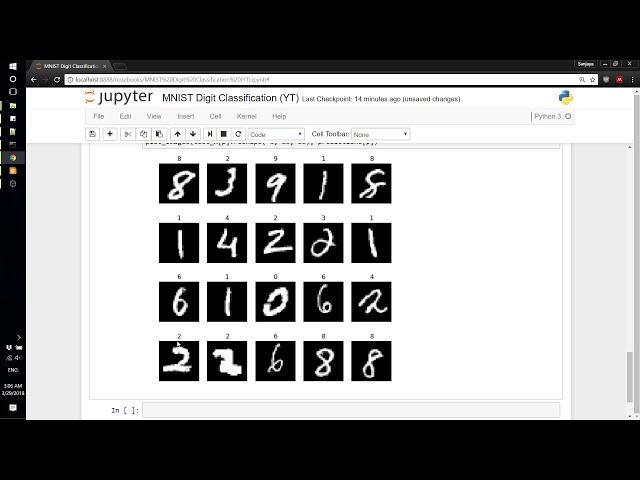
13
00:01:04,890 –> 00:01:18,060
وارد میکنیم، سپس ما. فقط باید از این
14
00:01:18,060 –> 00:01:21,030
دستور کتاب استفاده کنید تا نمودارهای ایجاد
15
00:01:21,030 –> 00:01:24,810
شده توسط نقشه در خود دفترچه قابل مشاهده نباشند،
16
00:01:24,810 –> 00:01:34,860
بنابراین اکنون میتوانیم
17
00:01:34,860 –> 00:01:40,049
مجموعه دادههای Emily و آشیانه برابر
18
00:01:40,049 –> 00:01:46,049
با دادههای ml را دانلود کنیم تا پارامتر اصلی
19
00:01:46,049 –> 00:01:53,420
داده شخصی باشد و
20
00:01:54,869 –> 00:01:58,900
اگر ببینیم چه چیزی است. برگردانده شده است این
21
00:01:58,900 –> 00:02:01,990
عفو فرهنگ لغت ما با این چهار کلید ما
22
00:02:01,990 –> 00:02:04,840
ند یقه است که شامل ستون ها
23
00:02:04,840 –> 00:02:07,600
رح نام ستون ها است سپس هدف داده ها، بنابراین ای
24
00:02:07,600 –> 00:02:10,479
دو مورد عل
25
00:02:10,479 –> 00:02:17,730
قه مند بودند، بنابراین بیایید X را به عنوان M د
26
00:02:17,730 –> 00:02:28,269
ده آشیانه و Y را به عنوان M هدف تعریف کن
27
00:02:28,269 –> 00:02:38,140
م. بیایید انواع داده ها را به صورت یکسان چاپ کنیم
28
00:02:38,140 –> 00:02:48,250
تا مجموعه
29
00:02:48,250 –> 00:02:52,739
داده شامل داده های آموزشی شامل 70 هزار
30
00:02:52,739 –> 00:02:57,519
تصویر از وکتور تک بعدی به
31
00:02:57,519 –> 00:03:03,130
اندازه 784 در مجموعه داده های M زیبا باشد.
32
00:03:03,130 –> 00:03:06,970
33
00:03:06,970 –> 00:03:11,019
مسطح هستند و
34
00:03:11,019 –> 00:03:16,690
همچنین 7 784 از زمانی می آید که ما 28
35
00:03:16,690 –> 00:03:21,190
ضربدر 28 784 آن را انجام می دهیم، بنابراین تصویر
36
00:03:21,190 –> 00:03:23,049
از دو بعدی به یک
37
00:03:23,049 –> 00:03:26,769
بعد مسطح می شود، به همین دلیل است که 784 بله به
38
00:03:26,769 –> 00:03:31,209
ما امکان می دهد برخی از نمونه های آموزشی را برای این کار تجسم کنیم،
39
00:03:31,209 –> 00:03:34,470
40
00:03:37,290 –> 00:03:40,980
شما می دانید فقط یک تابع راحت را ترسیم کنید.
41
00:03:40,980 –> 00:03:45,960
که من تعریف کرده ام، بیایید 20 بیماری را ترسیم کنیم،
42
00:03:45,960 –> 00:03:51,960
43
00:03:56,970 –> 00:04:05,400
بنابراین آرایه ای به اندازه
44
00:04:05,400 –> 00:04:08,770
70000 با اعداد تصادفی در بین
45
00:04:08,770 –> 00:04:11,710
آنها ایجاد می کند، نه در یک ترتیب، اما ترتیب
46
00:04:11,710 –> 00:04:15,370
متفاوت است، بنابراین ما از این استفاده می کنیم و از
47
00:04:15,370 –> 00:04:17,079
اینجا فقط اولین مورد را استخراج می کنیم.
48
00:04:17,079 –> 00:04:21,550
بیست و یک و سپس ما می خواهیم تصاویر را رسم کنیم،
49
00:04:21,550 –> 00:04:24,580
بنابراین این تصاویر طرح من فقط
50
00:04:24,580 –> 00:04:28,690
این را برای ترسیم تصاویر در یک شبکه تعریف کرده ام، بنابراین
51
00:04:28,690 –> 00:04:30,910
شما این تصاویر و سطوحی را
52
00:04:30,910 –> 00:04:35,820
که باید آنها را از X P عبور دهیم و سپس
53
00:04:35,820 –> 00:04:40,960
از آنجایی که این من هستم، چنین است. یکی که t باعث می
54
00:04:40,960 –> 00:04:44,760
شود که نمودار به هم ریخته شود، انتظار می رود
55
00:04:44,760 –> 00:04:47,650
تصویر به عنوان یک آرایه دو بعدی به
56
00:04:47,650 –> 00:04:50,650
جای یک بعد مانند ما باشد، بنابراین
57
00:04:50,650 –> 00:04:56,680
باید این را در بیست و
58
00:04:56,680 –> 00:05:02,350
هشت و بیست و هشت و سپس چهار سطح دریافت کنیم که
59
00:05:02,350 –> 00:05:08,250
فقط برای عکس گرفتن از مقادیر از سیم استفاده می کنیم.
60
00:05:09,330 –> 00:05:13,480
بنابراین در اینجا ما فقط می توانیم تصاویر را ببینیم، بنابراین
61
00:05:13,480 –> 00:05:20,770
اینها مجموعه داده های قدیمی ما هستند و
62
00:05:20,770 –> 00:05:25,050
به نظر می رسد که چرا برچسب ها
63
00:05:25,050 –> 00:05:30,330
در طول 64 شناور هستند، اجازه دهید کمی
64
00:05:30,380 –> 00:05:37,350
پیش پردازش انجام دهیم، بنابراین ما فقط
65
00:05:37,350 –> 00:05:42,720
y را به عنوان نوع در 32 تبدیل می کنیم، زیرا آنها فقط
66
00:05:42,720 –> 00:05:44,970
اعدادی هستند از 0 تا 9 ما به آن به
67
00:05:44,970 –> 00:05:54,750
عنوان یک شناور و همچنین X نیاز نداریم، بنابراین کاری که ما در
68
00:05:54,750 –> 00:05:59,250
اینجا انجام می دهیم تقسیم هر عدد بر
69
00:05:59,250 –> 00:06:04,200
255 است به طوری که مقادیر بین 0 و
70
00:06:04,200 –> 00:06:10,340
1 قرار می گیرند، بنابراین اگر به سرعت بررسی کنیم به جز min،
71
00:06:10,340 –> 00:06:14,940
حداکثر را به درستی استخراج کنیم. اکنون مقادیر
72
00:06:14,940 –> 00:06:17,220
بین 0 و 255 قرار دارند،
73
00:06:17,220 –> 00:06:19,610
اما در یادگیری ماشینی معمولاً
74
00:06:19,610 –> 00:06:23,340
به خصوص شبکه های عصبی
75
00:06:23,340 –> 00:06:28,350
اعداد بین 0 و 1 را دوست دارند، بنابراین
76
00:06:28,350 –> 00:06:29,430
تمرین خوبی است که این کار را انجام دهید،
77
00:06:29,430 –> 00:06:32,820
بنابراین ما فقط بر 255 تقسیم می کنیم تا
78
00:06:32,820 –> 00:06:36,390
مقادیر ما از 0 و 1 متغیر باشد. پس حالا اگر
79
00:06:36,390 –> 00:06:40,160
بررسی کنیم مقادیر ما بین نرمال شده اند
80
00:06:40,160 –> 00:06:47,520
0 و 1 اکنون قبل از اینکه بتوانیم مدل را
81
00:06:47,520 –> 00:06:52,020
بسازیم، باید مجموعه داده خود را به
82
00:06:52,020 –> 00:06:54,210
آموزش و آزمایش تقسیم کنیم، بنابراین scikit-learn
83
00:06:54,210 –> 00:06:56,880
از قبل یک عملکرد مناسب برای
84
00:06:56,880 –> 00:07:01,850
این کار دارد، بنابراین از انتخاب مدل یادگیری SK،
85
00:07:01,850 –> 00:07:05,490
شما یک تقسیم را آموزش دهید تا این تابع
86
00:07:05,490 –> 00:07:08,310
کل داده های ما را تقسیم کند. در
87
00:07:08,310 –> 00:07:11,840
مرکز آموزش و تست قرار دهید
88
00:07:12,520 –> 00:07:20,390
– یک X just X قطار چرا این – من
89
00:07:20,390 –> 00:07:26,000
این تقسیم را نیز آموزش می دهم و باید x
90
00:07:26,000 –> 00:07:31,970
و y را پاس کنیم بنابراین به طور پیش فرض 70٪
91
00:07:31,970 –> 00:07:34,130
از کل مجموعه داده را به مجموعه آموزشی اختصاص می
92
00:07:34,130 –> 00:07:39,220
دهد و 30٪ باقی مانده را به مجموعه آموزشی اختصاص می دهد. در
93
00:07:39,220 –> 00:07:42,470
DISA از مجموعه آموزشی برای آموزش
94
00:07:42,470 –> 00:07:44,690
مدل و از مجموعه تست برای ارزیاب