در این مطلب، ویدئو نحوه استقرار مدل های یادگیری ماشین در تولید با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:03,750 –> 00:00:10,810
[موسیقی]
2
00:00:10,810 –> 00:00:11,630
[تشویق حضار]
3
00:00:11,630 –> 00:00:14,340
[موسیقی]
4
00:00:14,340 –> 00:00:17,980
سلام به همه خوش آمدید به بحث
5
00:00:17,980 –> 00:00:19,660
نحوه استقرار مدلهای یادگیری ماشینی در
6
00:00:19,660 –> 00:00:22,210
تولید، با تشکر از توقف شما، من
7
00:00:22,210 –> 00:00:23,619
واقعاً برای صحبت در مورد این موضوع هیجانزده هستم،
8
00:00:23,619 –> 00:00:25,090
زیرا فکر میکنم بسیار
9
00:00:25,090 –> 00:00:27,880
مهم است که در مورد این موضوع صحبت کنیم.
10
00:00:27,880 –> 00:00:29,619
مرحله دوم جریان یادگیری ماشینی
11
00:00:29,619 –> 00:00:31,960
که همه میدانند که به کارگیری
12
00:00:31,960 –> 00:00:33,519
مدلهای یادگیری ماشینی برای تولید است،
13
00:00:33,519 –> 00:00:35,440
زیرا من معتقدم که این همان
14
00:00:35,440 –> 00:00:37,780
چیزی است که ارزش واقعی علم داده
15
00:00:37,780 –> 00:00:39,370
به درستی مشخص میشود، بنابراین در کل
16
00:00:39,370 –> 00:00:41,710
چرخه تا این لحظه شما
17
00:00:41,710 –> 00:00:43,570
سرمایهگذاری کردهاید و حالا به این نقطه
18
00:00:43,570 –> 00:00:45,190
رسیدهاید که یک کوچک را در جایی مستقر میکنید
19
00:00:45,190 –> 00:00:47,190
که واقعاً برای شرکت به ارمغان میآورد و به
20
00:00:47,190 –> 00:00:49,480
اندازه کافی عجیب است که بسیاری از شرکتها
21
00:00:49,480 –> 00:00:52,180
به چند دلیل در مورد آن صحبت
22
00:00:52,180 –> 00:00:54,340
نمیکنند.
23
00:00:54,340 –> 00:00:56,260
24
00:00:56,260 –> 00:00:58,090
خیلی شرم آور است زیرا آنها
25
00:00:58,090 –> 00:01:01,239
این کار را به شیوه ای بسیار بد انجام می دهند، بنابراین
26
00:01:01,239 –> 00:01:03,340
انگیزه من از این صحبت این است که به
27
00:01:03,340 –> 00:01:04,989
شما بینش و همچنین مقداری غذا برای
28
00:01:04,989 –> 00:01:07,630
فکر کردن و و برخی اگر در این مسیر هستید، فرض کنید مسیرهایی را برای
29
00:01:07,630 –> 00:01:09,549
پیگیری دنبال کنید،
30
00:01:09,549 –> 00:01:12,729
قبل از اینکه وارد جزئیات شوم، به طور خلاصه
31
00:01:12,729 –> 00:01:14,500
خود را معرفی می کنم نام من samit quill است،
32
00:01:14,500 –> 00:01:17,500
33
00:01:17,500 –> 00:01:21,040
اگر در توییتر هستید، یک مهندس نرم افزار و آزمایشگاه های تحقیق و توسعه IBM در آلمان جنوبی هستم.
34
00:01:21,040 –> 00:01:23,259
و چیزهایی
35
00:01:23,259 –> 00:01:25,000
که می توانید من را در توییتر دنبال کنید من بسیار پاسخگو هستم،
36
00:01:25,000 –> 00:01:26,530
بنابراین هر گونه سوالی دارید
37
00:01:26,530 –> 00:01:30,220
فقط در زندگی روزمره برای من بنویسید.
38
00:01:30,220 –> 00:01:32,380
39
00:01:32,380 –> 00:01:34,450
40
00:01:34,450 –> 00:01:36,430
برخی از مشارکتهای مشتری برای
41
00:01:36,430 –> 00:01:40,210
IBM دقیقاً به همین دلیل دستور
42
00:01:40,210 –> 00:01:42,520
کار صحبت است. من انگیزهها را
43
00:01:42,520 –> 00:01:44,350
توضیح میدهم تا چرا در این مورد صحبت میکنم و چرا
44
00:01:44,350 –> 00:01:46,509
فکر میکنم مهم است که یک
45
00:01:46,509 –> 00:01:49,570
مدل پایتون در واقع چگونه است، ما مدل مدل مدل را میدانیم
46
00:01:49,570 –> 00:01:51,790
اما چیست؟ چه چیزی
47
00:01:51,790 –> 00:01:54,820
وجود دارد که دقیقاً چه نوع
48
00:01:54,820 –> 00:01:56,259
محیط های تولیدی مختلف به نظر می
49
00:01:56,259 –> 00:01:59,049
رسد و سپس سعی خواهم کرد آن را در
50
00:01:59,049 –> 00:02:00,610
محیط های تولید استاندارد
51
00:02:00,610 –> 00:02:02,829
که Cloud Foundry docker cuban ets
52
00:02:02,829 –> 00:02:06,490
یا از طریق سرویس های مدیریت شده است به نمایش بگذارم، بنابراین فکر می کنم
53
00:02:06,490 –> 00:02:09,310
همه ما این کار را انجام داده ایم. این تصویر یا
54
00:02:09,310 –> 00:02:11,170
گونهای از این تصویر بارها و بارها انجام نمیشود، بنابراین
55
00:02:11,170 –> 00:02:12,840
این تصویر هیچ کاری انجام نمیدهد، اما اساساً
56
00:02:12,840 –> 00:02:15,640
یک نمای کلی از چگونگی شکلگیری یک
57
00:02:15,640 –> 00:02:17,500
جریان یادگیری یا جریان علم داده ارائه میدهد،
58
00:02:17,500 –> 00:02:18,880
بنابراین با
59
00:02:18,880 –> 00:02:21,160
درک کسبوکار اکتساب دادهها شروع میشود که در آن
60
00:02:21,160 –> 00:02:22,720
شما مشکلی را ایجاد میکنید. سعی می کنم
61
00:02:22,720 –> 00:02:24,250
با مدل یادگیری ماشینی
62
00:02:24,250 –> 00:02:26,500
شما را با درک داده ها، مدل سازی و ارزیابی آماده سازی داده ها حل کنم
63
00:02:26,500 –> 00:02:29,950
و در نهایت
64
00:02:29,950 –> 00:02:31,840
ممکن است به مرحله استقرار برسد یا نرسد،
65
00:02:31,840 –> 00:02:35,020
اما تعجب آور است که
66
00:02:35,020 –> 00:02:36,730
کار به همین جا ختم نمی شود، بنابراین اگر
67
00:02:36,730 –> 00:02:38,230
به عنوان دانشمند خوانده شوید، من واقعاً یک دانشمند خواهم بود.
68
00:02:38,230 –> 00:02:40,450
واقعاً ناراحت کننده است که اگر من هر
69
00:02:40,450 –> 00:02:44,080
روز به مدت دو ماه برای مدل سازی به دفتری بیایم، یک
70
00:02:44,080 –> 00:02:46,290
بهینه سازی پارامتر دارم که مجموعه پارامترهای نهایی را دارم
71
00:02:46,290 –> 00:02:48,370
که نتایج عالی را انجام می
72
00:02:48,370 –> 00:02:51,160
دهد، اما فقط آنجا از بین می رود زیرا
73
00:02:51,160 –> 00:02:52,840
هیچ کس این را اجرا نکرده است بنابراین آنها
74
00:02:52,840 –> 00:02:55,420
برای من و من واقعاً ناراحت خواهند شد. فکر کنید اینجاست
75
00:02:55,420 –> 00:02:57,160
که بخش عملیاتی یادگیری ماشینی
76
00:02:57,160 –> 00:02:59,470
وارد می شود که می توانم بگویم حتی یک
77
00:02:59,470 –> 00:03:01,000
زمینه نسبتاً جدیدتر و
78
00:03:01,000 –> 00:03:03,850
خود یادگیری ماشینی است، بنابراین من واقعاً دوست دارم
79
00:03:03,850 –> 00:03:05,200
فکر کنید که بقیه آن بهعنوان
80
00:03:05,200 –> 00:03:07,930
توسعه و بخش عملیات در
81
00:03:07,930 –> 00:03:11,200
هنگام استقرار به میان میآید، بنابراین
82
00:03:11,200 –> 00:03:15,400
همانطور که گفتم من نیز اغلب با
83
00:03:15,400 –> 00:03:18,640
مشتریان IBM صحبت میکنم و الگویی
84
00:03:18,640 –> 00:03:20,350
که ما میبینیم آنها از آن
85
00:03:20,350 –> 00:03:22,720
استفاده کردهاند. این است که یک دانشمند داده وجود دارد
86
00:03:22,720 –> 00:03:24,070
87
00:03:24,070 –> 00:03:26,829
که مثلاً یک مدل پایتون کار کرده است، او
88
00:03:26,829 –> 00:03:28,420
چند کار را برای هفته ها یا ماه ها
89
00:03:28,420 –> 00:03:30,549
انجام داده است، او فکر می کند
90
00:03:30,549 –> 00:03:32,709
که یک مدل به اندازه کافی خوب دارد و سپس
91
00:03:32,709 –> 00:03:34,180
آن را روی دیوار می اندازد.
92
00:03:34,180 –> 00:03:35,709
تیم توسعه برنامه، بخش فناوری اطلاعات
93
00:03:35,709 –> 00:03:37,600
هر چه باشد، و سپس کار آنها این
94
00:03:37,600 –> 00:03:40,570
است که اکنون یک برنامه کاربردی با برنامه ای توسعه دهند
95
00:03:40,570 –> 00:03:43,360
که می توان از آن استفاده کرد،
96
00:03:43,360 –> 00:03:46,299
اگر برای شرکت ها کار کند خوب است، اما من در
97
00:03:46,299 –> 00:03:48,720
این تکنیک نقص هایی می بینم
98
00:03:48,720 –> 00:03:51,220
که منظورم این است که شکاف یا موانع زیادی وجود دارد.
99
00:03:51,220 –> 00:03:53,260
اگر چنین حصار بزرگی
100
00:03:53,260 –> 00:03:55,019
بین تیم علم داده و
101
00:03:55,019 –> 00:03:57,489
تیم توسعه وجود داشته باشد، زیرا برای
102
00:03:57,489 –> 00:03:59,470
مثال فرض کنید پس از یک هفته کار، مایک
103
00:03:59,470 –> 00:04:01,600
تصمیم می گیرد که اکنون یک
104
00:04:01,600 –> 00:04:04,360
ویژگی شگفت انگیز جدید برای مدل یادگیری ماشین خود پیدا
105
00:04:04,360 –> 00:04:07,269
کرده است. عملکرد را بهبود می بخشد
106
00:04:07,269 –> 00:04:10,209
اما دب همچنان به مجموعه داده های
107
00:04:10,209 –> 00:04:12,280
قدیمی یا اطلاعات قدیمی خود تکیه می کند که بسیار
108
00:04:12,280 –> 00:04:14,350
خوب من برای آموزش کوچک به پارامترهای زیادی نیاز دارم،
109
00:04:14,350 –> 00:04:16,720
بله، نکته من در اینجا این است
110
00:04:16,720 –> 00:04:19,180
که بهتر است به آرامی
111
00:04:19,180 –> 00:04:21,060
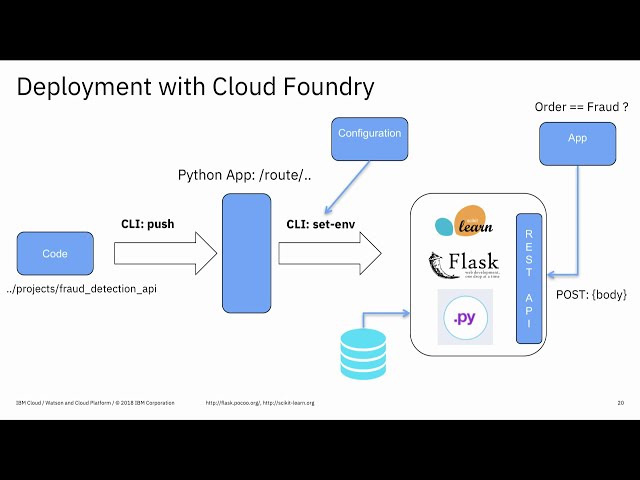
به سمت دوم حرکت کنید. مدلی که
112
00:04:21,060 –> 00:04:23,950
دانشمند داده من است و Deb توسعهدهنده
113
00:04:23,950 –> 00:04:25,479
آنها به صورت هماهنگ کار میکنند، بنابراین مایک
114
00:04:25,479 –> 00:04:28,040
یک مدل را در پایتون یا چه چیزی توسعه میدهد
115
00:04:28,040 –> 00:04:30,500
و سپس از نزدیک
116
00:04:30,500 –> 00:04:34,010
با خود توسعهدهنده دانشمند داده کار میکند تا
117
00:04:34,010 –> 00:04:36,020
آن را ترکیب کند و آن را در
118
00:04:36,020 –> 00:04:37,880
تولید جایی که شما بکار ببرید. قرار است
119
00:04:37,880 –> 00:04:39,170
ارزش مدل یادگیری ماشینی را به ارمغان بیاورد،
120
00:04:39,170 –> 00:04:41,620
121
00:04:42,110 –> 00:04:44,600
بنابراین من فقط در این مرحله
122
00:04:44,600 –> 00:04:46,850
برای ارائه انجام میدهم که
123
00:04:46,850 –> 00:04:48,350
روی محیطهای تولید در فضای ابری تمرکز میکنم،
124
00:04:48,350 –> 00:04:51,010
زیرا این همان کاری است که همه بچههای باحال انجام میدهند
125
00:04:51,010 –> 00:04:53,720
پایتون یک زبان برنامهنویسی اصلی
126
00:04:53,720 –> 00:04:55,940
در اینجا میکرو است. -معماریهای مبتنی بر خدمات
127
00:04:55,940 –> 00:04:58,610
ساختارهای یکپارچه نیستند
128
00:04:58,610 –> 00:05:00,020
الگوریتمهای یادگیری ماشین سنتی بدون
129
00:05:00,020 –> 00:05:01,160
یادگیری عمیق که فقط به این
130
00:05:01,160 –> 00:05:02,390
دلیل است که به کارگیری سنت آسانتر
131
00:05:02,390 –> 00:05:04,190
است. الگوریتم های یادگیری ماشین آل
132
00:05:04,190 –> 00:05:05,780
به دلیل اینکه معمولاً از نظر اندازه کوچکتر هستند
133
00:05:05,780 –> 00:05:08,150
و تیم علم داده و تیم توسعه نرم افزار
134
00:05:08,150 –> 00:05:10,840
به طور هماهنگ کار می کنند
135
00:05:10,840 –> 00:05:13,490
قبل از اینکه وارد جزئیات شوم، من فقط به
136
00:05:13,490 –> 00:05:19,160
شما یک لولای سریع و سریع از موارد استفاده را ارائه می
137
00:05:19,160 –> 00:05:20,450
دهم که ما از آن استفاده خواهیم کرد، بنابراین
138
00:05:20,450 –> 00:05:22,790
در واقع مجموعه دادههای واقعی موردی دادهها
139
00:05:22,790 –> 00:05:25,150
از شرکت شناسایی کلاهبرداری کارت اعتباری
140
00:05:25,150 –> 00:05:27,590
این است که آنها نزدیک به دویست هزار
141
00:05:27,590 –> 00:05:28,730
142
00:05:28,730 –> 00:05:30,950
تراکنش با کارت اعتباری انجام دادند.
143
00:05:30,950 –> 00:05:32,510
144
00:05:32,510 –> 00:05:34,760
145
00:05:34,760 –> 00:05:37,610
اینها مانند
146
00:05:37,610 –> 00:05:40,130
جنبه های مختلف
147
00:05:40,130 –> 00:05:42,260
معامله با کارت اعتباری هستند، اخطارهای بانکی در
148
00:05:42,260 –> 00:05:44,600
سیستم آنها وجود دارد، بنابراین داده ها را ناشناس می کنند،
149
00:05:44,600 –> 00:05:46,400
بنابراین ما نمی دانیم این ستون ها چه معنایی دارند،
150
00:05:46,400 –> 00:05:48,350
اما مانند دو یا سه مورد از آنها
151
00:05:48,350 –> 00:05:50,240
ملموس هستند که زمان
152
00:05:50,240 –> 00:05:53,030
تراکنش چقدر است. در
153
00:05:53,030 –> 00:05:54,680
این تراکنش و کلاس وجود داشت، بنابراین
154
00:05:54,680 –> 00:05:56,450
اگر صفر باشد، تراکنش در مورد کلاهبرداری است،
155
00:05:56,450 –> 00:06:00,970
اگر یک تراکنش تقلبی است،
156
00:06:00,970 –> 00:06:03,620
مشکلی ندارد، بنابراین این همان چیزی است که خواننده مجموعه داده
157
00:06:03,620 –> 00:06:06,350
علمی entist مجبور شد پایتون را به
158
00:06:06,350 –> 00:06:08,330
زبان انتخابی خود انتخاب کند، بنابراین شروع به کار کرد،
159
00:06:08,330 –> 00:06:10,250
به عنوان مثال در این مورد، او از یک
160
00:06:10,250 –> 00:06:12,650
طبقهبندیکننده جنگل تصادفی استفاده میکند، بنابراین
161
00:06:12,650 –> 00:06:14,480
گردش کار استاندارد دریافت
162
00:06:14,480 –> 00:06:16,670
دادهها را انجام داد و دادهها را تمیز کرد و در نهایت
163
00:06:16,670 –> 00:06:18,740
آن را با استفاده از طبقهبندیکننده جنگل تصادفی مدلسازی کرد.
164
00:06:18,740 –> 00:06:21,190
165
00:06:21,190 –> 00:06:23,330
مسیر توسعه برای علم
166
00:06:23,330 –> 00:06:24,680
داده است، جایی که محیط تولید من
167
00:06:24,680 –> 00:06:27,140
وارد می شود و جایی است که اجازه دهید بگوییم
168
00:06:27,140 –> 00:06:28,670
هدف نهایی من جایی است که می خواهم این
169
00:06:28,670 –> 00:06:31,310
مدل را بکار ببرم اکنون چگونه می توانم به آنجا برسم.
170
00:06:31,310 –> 00:06:32,000
چندین
171
00:06:32,000 –> 00:06:34,490
راه وجود دارد که متأسفانه اولین مورد رایج ترین
172
00:06:34,490 –> 00:06:36,320
است که ما تاکنون دیدهایم
173
00:06:36,320 –> 00:06:38,390
که شبیه برخی از مدلهای دادههای دانشمند داده است
174
00:06:38,390 –> 00:06:41,000
و از آنجایی که به
175
00:06:41,000 –> 00:06:41,780
تولید
176
00:06:41,780 –> 00:06:43,430
فکر میکنید به برنامههای کاربردی جاوا میاندیشید که برنامههای نود
177
00:06:43,430 –> 00:06:46,130
C ++ C برنامههای کاربردی، بنابراین چگونه
178
00:06:46,130 –> 00:06:48,170
آنها با یکدیگر ارتباط برقرار میکنند.
179
00:06:48,170 –> 00:06:50,480
180
00:06:50,480 –> 00:06:52,580
آن مدل ها را به
181
00:06:52,580 –> 00:06:55,720
پایتون به C ++ C ترجمه کنید و سپس آنها را مجدداً مستقر کنید
182
00:06:55,720 –> 00:06:59,600
که برای بردارهای عملکرد مشکلی
183
00:06:59,600 –> 00:07:01,910
ندارد اما برای تیم واقعاً بد است. e
184
00:07:01,910 –> 00:07:04,669
به بازار یا زمان مناسب برای هدف گیری،
185
00:07:04,669 –> 00:07:06,650
بنابراین اگر مجبورید
186
00:07:06,650 –> 00:07:08,030
همه چیز را بازنویسی کنید، حداقل یک یا دو
187
00:07:08,030 –> 00:07:10,520
هفته قبل از آن فاصله دارید و ممکن است در
188
00:07:10,520 –> 00:07:12,470
دنیای پرشتاب که مدل شما
189
00:07:12,470 –> 00:07:16,010
ارزش B را از دست داده باشد، PMML وجود دارد، بنابراین می
190
00:07:16,010 –> 00:07:17,780
توانید ترجمه کنید.
191
00:07:17,780 –> 00:07:20,090
نوع مدل هستند اما قرار نیست
192
00:07:20,090 –> 00:07:22,790
توپ سوم خیلی پایدار باشند.
193
00:07:22,790 –> 00:07:24,530
سومین راه که من خیلی دوست دارم این
194
00:07:24,530 –> 00:07:26,750
است که شما فقط مدل پایتون خود را بگیرید که می
195
00:07:26,750 –> 00:07:28,400
بینید از آن استفاده می کنید و آن را به عنوان یک
196
00:07:28,400 –> 00:07:30,850
برنامه پایتون در خدمت استفاده می کنید. REST API
197
00:07:30,850 –> 00:07:33,830
چرا REST API زیرا اگر
198
00:07:33,830 –> 00:07:36,200
برنامه شما می تواند HTTP صحبت کند می تواند در
199
00:07:36,200 –> 00:07:40,190
مورد آن صحبت کند می تواند با درخواست صحبت کند، بنابراین این جنبه
200
00:07:40,190 –> 00:07:42,290
201
00:07:42,290 –> 00:07:44,300
مدل یادگیری ماشین پایتون بود که یک محیط تولید چگونه
202
00:07:44,300 –> 00:07:47,840
ممکن است به نظر برسد، بنابراین من می دانم که
203
00:07:47,840 –> 00:07:49,250
هر محیط تولید
204
00:07:49,250 –> 00:07:50,600
متفاوت است. اما این یکی از
205
00:07:50,600 –> 00:07:54,110
مزه های این یکی است که چرا ما اینجا هستیم
206
00:07:54,110 –> 00:07:56,479
با شی سریالی پایتون من
207
00:07:56,479 –> 00:07:58,010
که مدل الگوی من است، من به
208
00:07:58,010 –> 00:07:59,750
جزئیات این موضوع می پردازم که دقیقاً چیست پس
209
00:07:59,750 –> 00:08:01,039
اساساً هیچ چیز نیست.
210
00:08:01,039 –> 00:08:04,669
فقط چند بایت آن یک لکه است و
211
00:08:04,669 –> 00:08:06,380
اگر می خواهید و می خواهید آن
212
00:08:06,380 –> 00:08:08,390
را در یک پایگاه داده ذخیره کنید چرا یک
213
00:08:08,390 –> 00:08:10,700
مدل را در پایگاه داده ذخیره می کنید زیرا می خواهید
214
00:08:10,700 –> 00:08:13,220
خط و نسب خود را حفظ کنید که چه مدلی در
215
00:08:13,220 –> 00:08:15,260
محیط تولید من در چه ساعتی مستقر شده است،
216
00:08:15,260 –> 00:08:17,450
برای مثال بیایید بگوییم 28 ژوئن مدل
217
00:08:17,450 –> 00:08:20,510
من یک پیش بینی انجام داد، اگر بخواهم
218
00:08:20,510 –> 00:08:22,280
در یک هفته به آن نگاه کنم، می خواهم بدانم
219
00:08:22,280 –> 00:08:24,650
کدام مدل از کدام نسخه از مدل
220
00:08:24,650 –> 00:08:26,530
او استفاده شده است و چرا آن چیزی را پیش بینی کرده است که
221
00:08:26,530 –> 00:08:28,970
من نمی خواهم یک لپه از داده ها را ذخیره کنم.
222
00:08:28,970 –> 00:08:31,280
مانند ارتقاء
223
00:08:31,280 –> 00:08:32,960
این اطلاعات را با نسخه
224
00:08:32,960 –> 00:08:34,940
مدل، نام چارچوب یادگیری ماشین مدلی
225
00:08:34,940 –> 00:08:36,559
که برای آن استفاده میکنم و
226
00:08:36,559 –> 00:08:39,830
عملکرد مدل
227
00:08:39,830 –> 00:08:41,839
من چگونه بود، تقویت کنید، بنابراین من آن مدل را ذخیره کردم و اکنون
228
00:08:41,839 –> 00:08:43,880
برنامه یادگیری ماشین من چگونه به
229
00:08:43,880 –> 00:08:46,220
نظر میرسد. درست است پس می گوید این
230
00:08:46,220 –> 00:08:48,830
برنامه من است بلوک پایینی می گوید
231
00:08:48,830 –> 00:08:51,320
منطق من مدل من است من آن را دریافت می کنم به یک
232
00:08:51,320 –> 00:08:53,680
پایگاه داده متصل می شوم و مدل خود را در آنجا دانلود می کنم
233
00:08:53,680 –> 00:08:55,720
بسته به اینکه از PI استفاده می
234
00:08:55,720 –> 00:08:59,200
کنم Scala PI spark هر چه دانلود
235
00:08:59,200 –> 00:09:01,090
کنم قاب کار، بیایید محفظه داکر را
236
00:09:01,090 –> 00:09:03,730
در آنجا تصور کنیم، زیرا من آن را
237
00:09:03,730 –> 00:09:07,030
به عنوان یک استراحت ران و نقطه پایانی API استراحت
238
00:09:07,030 –> 00:09:08,920
میکنم، به نوعی وب سرور نیاز دارم، ممکن
239
00:09:08,920 –> 00:09:10,780
است فلاسک باشد، ممکن است هر چیزی
240
00:09:10,780 –> 00:09:13,270
را به انتخاب شما گردباد کند، میدانید که
241
00:09:13,270 –> 00:09:15,490
مدل یادگیری ماشین یک مسیر ایجاد میکند برای
242
00:09:15,490 –> 00:09:16,990
برنامه شما که مانند Okay Predict است،
243
00:09:16,990 –> 00:09:19,990
به عنوان مثال، داده های خود را آماده می کنید که وارد
244
00:09:19,990 –> 00:09:22,960
شوند، بنابراین در مرحله مدل سازی
245
00:09:22,960 –> 00:09:25,450
از تمام آن 300 تراکنش استفاده
246
00:09:25,450 –> 00:09:27,640
کردید که باید مدل خود را بسازید، اکنون در
247
00:09:27,640 –> 00:09:29,890
مرحله پیش بینی چه اتفاقی می افتد، یک
248
00:09:29,890 –> 00:09:31,870
درخواست جدید از آن وارد می شود. به عنوان مثال
249
00:09:31,870 –> 00:09:33,610
درگاه بانکی شما که می گوید یک
250
00:09:33,610 –> 00:09:35,890
تراکنش کارت اعتباری جدید با ویژگی های بسیار زیاد وجود
251
00:09:35,890 –> 00:09:38,050
دارد، می توانید به من بگویید که آیا این یک تقلب است
252
00:09:38,050 –> 00:09:41,290
یا نه، بنابراین این مرحله آماده سازی شماست
253
00:09:41,290 –> 00:09:42,430
، پیش بینی را اجرا کنید و
254
00:09:42,430 –> 00:09:44,020
پس از پردازش انجام دهید و نتیجه را به
255
00:09:44,020 –> 00:09:47,290
این API بقیه برگردانید. نقطه پایانی، بنابراین بیایید برخی
256
00:09:47,290 –> 00:09:50,290
از زمینه های واقعی زندگی را در آن قرار دهیم که تصور کنید هر
257
00:09:50,290 –> 00:09:52,630
شرکت تجارت الکترونیکی به انتخاب شماست.
258
00:09:52,630 –> 00:09:55,600
259
00:09:55,600 –> 00:09:57,130
260
00:09:57,130 –> 00:10:00,280
شما مشتریان ما هستید، بیایید
261
00:10:00,280 –> 00:10:02,200
تصور کنیم که این مشکل با خدمات خرد حل می شود،
262
00:10:02,200 –> 00:10:04,480
بنابراین یک سرویس میکرو خدمت به رابط کاربری است،
263
00:10:04,480 –> 00:10:07,660
یکی در حال رسیدگی به هزینه سبد خرید
264
00:10:07,660 –> 00:10:09,100
است.
265
00:10:09,100 –> 00:10:11,890
266
00:10:11,890 –> 00:10:16,120
267
00:10:16,120 –> 00:10:18,160
میخواهد بداند که آیا این سفارش کلاهبرداری است یا این
268
00:10:18,160 –> 00:10:20,620
تراکنش، تقلب است یا نه.
269
00:10:20,620 –> 00:10:23,650
270
00:10:23,650 –> 00:10:26,170
271
00:10:26,170 –> 00:10:28,630
272
00:10:28,630 –> 00:10:30,820
سؤالات جدی در مورد
273
00:10:30,820 –> 00:10:32,770
کل این تجارت درست است، بنابراین از آنجایی که اکنون
274
00:10:32,770 –> 00:10:35,200
مدل ماشین شما
275
00:10:35,200 –> 00:10:37,060
بخش محکمی از سیستم شما است،
276
00:10:37,060 –> 00:10:39,610
باید برخی از الزامات را برای این
277
00:10:39,610 –> 00:10:41,650
مدل یادگیری ماشینی اعمال کنید، بنابراین دیگر یک مورد استفاده از اسباب بازی
278
00:10:41,650 –> 00:10:43,780
نیست، بنابراین باید بگویید خوب
279
00:10:43,780 –> 00:10:45,520
چیست حداکثر زمان پاسخ شما،
280
00:10:45,520 –> 00:10:46,690
اگر تراکنش با کارت اعتباری باشد،
281
00:10:46,690 –> 00:10:48,040
نمیتوانید بگویید مدل یادگیری ماشینی
282
00:10:48,040 –> 00:10:50,020
چیزی را در عرض 5 دقیقه به من بدهید
283
00:10:50,020 –> 00:10:51,150
که
284
00:10:51,150 –> 00:10:53,770
بسته به در
285
00:10:53,770 –> 00:10:56,230
دسترس بودن نیاز شما، آنچنان میلیثانیه کار نمیکند.
286
00:10:56,230 –> 00:10:57,850
همیشه در دسترس است، بنابراین اگر
287
00:10:57,850 –> 00:10:59,650
پلتفرم شما 24 ساعته است، مدل شما باید
288
00:10:59,650 –> 00:11:02,980
24 ساعته و همچنین کیفیت
289
00:11:02,980 –> 00:11:04,330
پیش بینی اطمینان داشته باشد، بنابراین اگر مدل یادگیری ماشین شما
290
00:11:04,330 –> 00:11:06,940
بگوید من 40٪ مطمئن هستم که این یک تقلب نیست،
291
00:11:06,940 –> 00:11:09,050
292
00:11:09,050 –> 00:11:11,480
چه چیزی از آن یاد میگیرم. درست است 40
293
00:11:11,480 –> 00:11:13,430
درصد مطمئن هستم که تقلب نیست، من بهتر می توانم
294
00:11:13,430 –> 00:11:15,470
یک سکه را 50٪ برگردانم، بنابراین بهتر می دانم،
295
00:11:15,470 –> 00:11:17,269
بنابراین فقط چیزی به من بدهید
296
00:11:17,269 –> 00:11:20,690
که بیش از
297
00:11:20,690 –> 00:11:22,570
دانش بیهوده است، حداکثر بازده شما چقدر است، بنابراین
298
00:11:22,570 –> 00:11:24,769
اگر به یاد داشته باشید مدل سازی یک فرآیند بازگشتی است.
299
00:11:24,769 –> 00:11:27,470
اسلاید از قبل
300
00:11:27,470 –> 00:11:29,630
از مدلی که امروز مرتبط است
301
00:11:29,630 –> 00:11:31,640
ممکن است فردا مناسب نباشد، بنابراین
302
00:11:31,640 –> 00:11:34,810
حداکثر زمان آموزش مجدد از مدل شما چقدر است و
303
00:11:34,810 –> 00:11:38,209
آیا این به معنای زمان خالی است، بنابراین اگر
304
00:11:38,209 –> 00:11:39,500
من مدل را دوباره آموزش میدهم به این معنی است
305
00:11:39,500 –> 00:11:41,269
که دیگر نمیتوانم از پلتفرم خود استفاده
306
00:11:41,269 –> 00:11:43,279
کنم مانند آن، پس آن نوع
307
00:11:43,279 –> 00:11:48,260
الزامات استقرار با ابر را برای
308
00:11:48,260 –> 00:11:50,060
من تحمیل کنید، بنابراین چند نفر از شما از Cloud
309
00:11:50,060 –> 00:11:54,079
Foundry در حال حاضر یک توده خوب آگاه هستید، بنابراین
310
00:11:54,079 –> 00:11:55,940
برای افرادی که از cloud 4 آگاه نیستند،
311
00:11:55,940 –> 00:11:57,140
این یک ریخته گری ماشین یک پلت فرم استاندارد است.
312
00:11:57,140 –> 00:11:58,190
-سرویس
313
00:11:58,190 –> 00:12:00,230
این نوعی پشته نرم افزاری است که می
314
00:12:00,230 –> 00:12:03,440
توانید در مرکز داده خود مستقر کنید. در
315
00:12:03,440 –> 00:12:05,630
ابتدا توسط VMware توسعه داده شده است و من
316
00:12:05,630 –> 00:12:07,519
فکر می کنم اکنون متعلق به نرم افزار محوری است.
317
00:12:07,519 –> 00:12:10,190
318
00:12:10,190 –> 00:12:12,649
319
00:12:12,649 –> 00:12:14,810
320
00:12:14,810 –> 00:12:16,550
از
321
00:12:16,550 –> 00:12:18,380
مدیریت چرخه عمر برنامه مراقبت
322
00:12:18,380 –> 00:12:20,420
می کند اگر مشکلی پیش بیاید چند نمونه را می خواهید، می
323
00:12:20,420 –> 00:12:22,700
گوید خوب است، یکی از برنامه ها از بین رفته است، می
324
00:12:22,700 –> 00:12:25,490
خواهم یک برنامه جدید را راه اندازی کنم و از
325
00:12:25,490 –> 00:12:27,440
نظارت بر روی مسیریابی مواردی مانند
326
00:12:27,440 –> 00:12:30,529
آن مراقبت می کند، بنابراین در زمینه برنامه Cloud Foundry
327
00:12:30,529 –> 00:12:32,240
چگونه آیا به نظر می رسد که
328
00:12:32,240 –> 00:12:34,130
Cloud Foundry مفهوم build
329
00:12:34,130 –> 00:12:35,839
pack را دارد، بنابراین تصور کنید این مانند یک
330
00:12:35,839 –> 00:12:38,600
تصویر داکر کانتینر در بسته ساخت
331
00:12:38,600 –> 00:12:41,029
من است، می گویم به پایگاه داده خود متصل شوید،
332
00:12:41,029 –> 00:12:43,070
مدل من را بارگیری کنید و همین کار را انجام دهید، بنابراین
333
00:12:43,070 –> 00:12:46,399
از مثالی که استفاده می کنم یک
334
00:12:46,399 –> 00:12:48,410
مورد استفاده از یادگیری ماشین پایتون است که یک Sikit-Learn است،
335
00:12:48,410 –> 00:12:51,079
بنابراین من بسته کیت Sai را در
336
00:12:51,079 –> 00:12:55,070
برنامه خود وارد می کنم، فلاسک را وارد می کنم تا
337
00:12:55,070 –> 00:12:56,750
فلاسک مانند یک وب سرور باشد، بنابراین وب سرویس استاندارد
338
00:12:56,750 –> 00:13:00,110
r شما مسیری را ایجاد میکنید
339
00:13:00,110 –> 00:13:01,820
که پیشبینی اجرای دادههای امتیازدهی را آماده میکنید و آن را
340
00:13:01,820 –> 00:13:05,269
به عنوان استراحت و API ارائه میدهید، اکنون سؤالاتی
341
00:13:05,269 –> 00:13:06,980
که برای محیط تولید بسیار خاص
342
00:13:06,980 –> 00:13:08,570
هستند در اینجا با استفاده از نحوه
343
00:13:08,570 –> 00:13:09,980
پیکربندی برنامه خود که نمیخواهید
344
00:13:09,980 –> 00:13:11,029
اعتبار شما را در برنامه ذخیره کنید.
345
00:13:11,029 –> 00:13:13,399
شما با github repo تماس
346
00:13:13,399 –> 00:13:15,110
می گیرید تا اعتبارنامه اتصال به
347
00:13:15,110 –> 00:13:18,290
Cloudant را به پایگاه داده انتخابی خود دریافت کنید،
348
00:13:18,290 –> 00:13:20,779
بنابراین Cloud
349
00:13:20,779 –> 00:13:21,980
Foundry همچنین مراقب تعادل بار است،
350
00:13:21,980 –> 00:13:22,820
351
00:13:22,820 –> 00:13:25,610
اگر برنامه شما مانند نرخ اول مانند
352
00:13:25,610 –> 00:13:27,950
پنج درخواست در ثانیه بود، 8000
353
00:13:27,950 –> 00:13:29,780
درخواست در ثانیه بعد. میتوانید آن را در
354
00:13:29,780 –> 00:13:32,380
مقیاسی مانند تعداد مواردی
355
00:13:32,380 –> 00:13:34,700
که میخواهید پیادهسازیهای کمدور صفر میخواهید تنظیم
356
00:13:34,700 –> 00:13:36,100
کنید.
357
00:13:36,100 –> 00:13:38,510
358
00:13:38,510 –> 00:13:41,030
359
00:13:41,030 –> 00:13:42,200
360
00:13:42,200 –> 00:13:45,320
361
00:13:45,320 –> 00:13:47,300
در مورد بسته ساخت، بنابراین فقط
362
00:13:47,300 –> 00:13:50,150
این را مانند انواع مختلفی از تصاویر داکر از پیش ساخته شده
363
00:13:50,150 –> 00:13:52,370
برای مثال کوبایی دهه هشتاد تصور
364
00:13:52,370 –> 00:13:54,470
کنید، زیرا یک P بود.
365
00:13:54,470 –> 00:13:56,330
برنامه ython من بسته ساخت پایتون را انتخاب
366
00:13:56,330 –> 00:14:00,110
خواهم کرد و در نسخه ی نمایشی به جزئیات آن خواهم پرداخت،
367
00:14:00,110 –> 00:14:03,320
اما فقط این را در
368
00:14:03,320 –> 00:14:05,480
ذهن خود نگه دارید که به عنوان مثال من
369
00:14:05,480 –> 00:14:07,400
این ریخته گری ابری را مستقر کردم من این
370
00:14:07,400 –> 00:14:09,740
برنامه ریخته گری ابری را توسعه دادم که در پروژه من
371
00:14:09,740 –> 00:14:12,260
به نام شناسایی است. API از CLI من
372
00:14:12,260 –> 00:14:14,510
فشار CF را انجام میدهم که اساساً به معنای فشار دادن
373
00:14:14,510 –> 00:14:16,760
برنامه من است. من فکر میکنم در شبکه کوبا
374
00:14:16,760 –> 00:14:18,890
به خوبی نصب کنترل Cube یا
375
00:14:18,890 –> 00:14:21,620
چیزی شبیه به آن بسته به جایی که
376
00:14:21,620 –> 00:14:23,360
پیکربندی من وارد میشود،
377
00:14:23,360 –> 00:14:25,010
متغیرهای محیطی را برای اعتبارنامههایم تنظیم میکنم،
378
00:14:25,010 –> 00:14:28,010
مواردی از این قبیل. و اینکه چه
379
00:14:28,010 –> 00:14:30,680
دادههای C را در جایی بارگیری میکند که در آن پایگاه دادههای چندگانه اکنون
380
00:14:30,680 –> 00:14:32,360
برنامه من راهاندازی و اجرا شده است و
381
00:14:32,360 –> 00:14:34,760
برنامه هر برنامه کاربردی
382
00:14:34,760 –> 00:14:36,890
در دنیا، اگر من یک
383
00:14:36,890 –> 00:14:38,600
تأیید هویت امن یا مطمئن نداشته باشم، میتواند
384
00:14:38,600 –> 00:14:42,800
یک درخواست پست ایجاد کند و نتیجه را
385
00:14:42,800 –> 00:14:47,240
برگرداند، حالا اجازه دهید من بروم. به سرعت به برنامه برگردید،
386
00:14:47,240 –> 00:14:50,090
بنابراین بهتر متوجه شوید که
387
00:14:50,090 –> 00:14:52,690
من در مورد چه چیزی صحبت می کنم،
388
00:14:54,250 –> 00:14:57,640
بنابراین این در واقع یک
389
00:14:57,640 –> 00:14:59,960
برنامه بسیار ناب است، من فکر می کنم
390
00:14:59,960 –> 00:15:02,120
بیشتر از hu نیست. چند خط کد
391
00:15:02,120 –> 00:15:12,970
که نمی بینید خوب
392
00:15:20,430 –> 00:15:25,769
بزرگتر می شود کمی بزرگتر می کند، خیلی بزرگ است،
393
00:15:25,769 –> 00:15:30,399
بنابراین همه می توانند آن را کامل بخوانند،
394
00:15:30,399 –> 00:15:31,959
در واقع خیلی اتفاق نمی
395
00:15:31,959 –> 00:15:34,089
افتد، فقط یک اسکریپت پایتون به
396
00:15:34,089 –> 00:15:36,100
نام hello dot py بسیار خلاقانه است و
397
00:15:36,100 –> 00:15:42,220
می گوید import از Cloudant فقط
398
00:15:42,220 –> 00:15:43,810
یک ثانیه سریع به من بدهید در واقع من تازه
399
00:15:43,810 –> 00:15:45,940
متوجه شدم که باید زمینه بیشتری
400
00:15:45,940 –> 00:15:50,220
را در مورد موارد استفاده
401
00:15:59,620 –> 00:16:02,260
به شما ارائه دهم، بله فقط برای اینکه بینش بیشتری در
402
00:16:02,260 –> 00:16:04,390
مورد موارد استفاده کشف تقلب من به شما بدهم،
403
00:16:04,390 –> 00:16:07,210
این خطوط فقط برای
404
00:16:07,210 –> 00:16:09,450
ارائه ایده به شما مهم نیستند. این یک
405
00:16:09,450 –> 00:16:12,010
تراکنش واقعی از آن کارت اعتباری است که
406
00:16:12,010 –> 00:16:13,570
میگوید در این زمان
407
00:16:13,570 –> 00:16:16,570
ویژگیهای زیادی وجود داشت، یک چهل و نه امتیاز
408
00:16:16,570 –> 00:16:18,850
شش دو دلار یورو بود، و
409
00:16:18,850 –> 00:16:21,490
کلاس صفر بود، این یک غیر پروتئاز است،
410
00:16:21,490 –> 00:16:23,410
سپس مورد آمادهسازی
411
00:16:23,410 –> 00:16:25,990
دادههایی است که شما تقسیم میکنید.
412
00:16:25,990 –> 00:16:29,470
در این مورد ما
413
00:16:29,470 –> 00:16:32,440
فقط یک جنگل تصادفی بسیار ساده را انجام
414
00:16:32,440 –> 00:16:35,830
415
00:16:35,830 –> 00:16:38,680
416
00:16:38,680 –> 00:16:41,200
می دهیم.
417
00:16:41,200 –> 00:16:43,540
پیشبینیها نشان میدهد که
418
00:16:43,540 –> 00:16:45,700
اگر



![فیلم آموزشی: فلاسک پایتون از ابتدا - [قسمت 1] - شروع به کار با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/zRwy8gtgJ1Aimage2.jpg)
![فیلم آموزشی: 12. ماژول ها [آموزش برنامه نویسی پایتون 3] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/DdGVBZv46PIimage2.jpg)