در این مطلب، ویدئو آموزش Scikit-Learn | یادگیری ماشینی با Scikit-Learn | Sklearn | آموزش پایتون | Simplile Learn با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:44:38
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:02,029 –> 00:00:04,799
سلام و خوش آمدید به
2
00:00:04,799 –> 00:00:07,200
بخش اول آموزش اسکیکت-یادگیری نام من ریچارد
3
00:00:07,200 –> 00:00:08,760
کرشنر است با تیمی
4
00:00:08,760 –> 00:00:11,759
که به سادگی آموخته شده است و به سادگی یاد گرفته
5
00:00:11,759 –> 00:00:13,830
شده است، گواهینامه دریافت کنید. اکنون ما
6
00:00:13,830 –> 00:00:15,960
آموزش آموزش اسکیتی را پوشش می دهیم که
7
00:00:15,960 –> 00:00:17,940
دارای بسیاری از ویژگی ها و انواع مختلف است.
8
00:00:17,940 –> 00:00:20,970
api در آن برای کاوش دادهها و انجام
9
00:00:20,970 –> 00:00:22,650
علم دادههای خود با افکتها، احتمالاً
10
00:00:22,650 –> 00:00:25,380
یکی از برترین بستههای علم داده موجود
11
00:00:25,380 –> 00:00:27,960
است، بنابراین آنچه که سایت نمیتواند یاد
12
00:00:27,960 –> 00:00:30,330
بگیرد، ابزاری ساده و کارآمد برای
13
00:00:30,330 –> 00:00:32,969
دادهکاوی و تجزیه و تحلیل داده است که بر روی Numpy Side Pie ساخته شده است.
14
00:00:32,969 –> 00:00:35,940
و کتابخانه mat plot بنابراین
15
00:00:35,940 –> 00:00:37,410
بسیار خوب با این ماژولهای دیگر ارتباط برقرار میکند
16
00:00:37,410 –> 00:00:39,239
و یک منبع باز است و
17
00:00:39,239 –> 00:00:43,350
مجوز تجاری bsd قابل استفاده است.
18
00:00:43,350 –> 00:00:44,879
19
00:00:44,879 –> 00:00:47,370
20
00:00:47,370 –> 00:00:48,840
21
00:00:48,840 –> 00:00:50,940
22
00:00:50,940 –> 00:00:52,350
دلیل دیگری برای اینکه واقعاً
23
00:00:52,350 –> 00:00:54,660
راه اندازی Sicit-Learn را دوست داشته باشید، بنابراین مجبور نیستید
24
00:00:54,660 –> 00:00:56,219
هزینه آن را به عنوان مجوز تجاری
25
00:00:56,219 –> 00:00:58,469
در مقابل بسیاری از پلتفرم های دارای حق چاپ دیگر در
26
00:00:58,469 –> 00:00:59,940
آنجا بپردازید.
27
00:00:59,940 –> 00:01:02,219
در scikit-learn ما از کلاس دو
28
00:01:02,219 –> 00:01:03,989
چیز اصلی یا طبقهبندی
29
00:01:03,989 –> 00:01:06,210
مدلهای طبقهبندی و رگرسیون استفاده میکنیم
30
00:01:06,210 –> 00:01:08,159
که مشخص میکند کدام دسته و شی
31
00:01:08,159 –> 00:01:10,619
متعلق به یک برنامه کاربردی است
32
00:01:10,619 –> 00:01:13,080
که بسیار مورد استفاده قرار میگیرد، تشخیص هرزنامه است، بنابراین
33
00:01:13,080 –> 00:01:15,750
آیا هرزنامه است یا هرزنامه نیست بله/خیر در
34
00:01:15,750 –> 00:01:17,640
بانکداری شما ممکن است این یک وام خوب
35
00:01:17,640 –> 00:01:19,770
وام بد است امروز ما به بررسی
36
00:01:19,770 –> 00:01:21,930
شراب خواهیم پرداخت آیا شراب خوب است یا شراب بد
37
00:01:21,930 –> 00:01:23,909
و رگرسیون پیش بینی یک
38
00:01:23,909 –> 00:01:26,070
ویژگی مرتبط با یک شی است،
39
00:01:26,070 –> 00:01:28,439
یک مثال پیش بینی قیمت حوضچه است
40
00:01:28,439 –> 00:01:30,390
که چه چیزی خواهد بود ارزش بعدی اگر این
41
00:01:30,390 –> 00:01:33,119
حوض امروز به ازای هر سهم بیست و سه دلار
42
00:01:33,119 –> 00:01:35,430
و پنج سنت فروخته شود، فکر
43
00:01:35,430 –> 00:01:36,810
میکنید برای فردا و فردا
44
00:01:36,810 –> 00:01:38,220
و روز بعد چه چیزی بفروشد
45
00:01:38,220 –> 00:01:39,390
تا یک مدل رگرسیونی
46
00:01:39,390 –> 00:01:41,159
باشد با
47
00:01:41,159 –> 00:01:43,020
پیشبینی آبوهوای هر یک از اینها.
48
00:01:43,020 –> 00:01:44,810
مدلهای رگرسیون ما در حال بررسی یک پیشبینی خاص هستیم
49
00:01:44,810 –> 00:01:47,040
که میخواهم امروز به آن ادای احترام
50
00:01:47,040 –> 00:01:48,869
کنم، طبقهبندی را انجام میدهیم، همانطور که گفتم،
51
00:01:48,869 –> 00:01:50,070
ما به دنبال خوب یا بد بودن یک شراب هستیم
52
00:01:50,070 –> 00:01:51,509
، اما
53
00:01:51,509 –> 00:01:53,670
مطمئناً مدل gression که در بسیاری از موارد
54
00:01:53,670 –> 00:01:55,680
مفیدتر است، زیرا شما به دنبال
55
00:01:55,680 –> 00:01:57,930
یک مقدار واقعی هستید، گاهی اوقات دنبال کردن آن نیز کمی سخت تر است،
56
00:01:57,930 –> 00:02:00,030
بنابراین طبقه بندی
57
00:02:00,030 –> 00:02:02,040
مکان واقعاً خوبی برای شروع است، ما همچنین می
58
00:02:02,040 –> 00:02:04,469
توانیم خوشه بندی انجام دهیم و
59
00:02:04,469 –> 00:02:07,560
خوشه بندی انتخاب مدل، گروه بندی خودکار را انجام می دهد
60
00:02:07,560 –> 00:02:09,419
. اشیاء مشابه در مجموعهها
61
00:02:09,419 –> 00:02:12,239
تقسیمبندی مشتری نمونهای است، بنابراین
62
00:02:12,239 –> 00:02:13,680
ما این مشتریان را داریم که
63
00:02:13,680 –> 00:02:16,170
اینگونه هستند، آنها احتمالاً این را نیز دوست خواهند داشت یا
64
00:02:16,170 –> 00:02:18,599
اگر از این نوع
65
00:02:18,599 –> 00:02:20,519
ویژگیهای خاص روی اشیاء خود خوشتان میآید، ممکن است
66
00:02:20,519 –> 00:02:22,680
این اشیاء دیگر را دوست داشته باشید، بنابراین
67
00:02:22,680 –> 00:02:24,420
یک ارجاع خوب است به خصوص در amazon.com
68
00:02:24,420 –> 00:02:26,549
یا هر یک از شبکههای خرید شما
69
00:02:26,549 –> 00:02:28,890
انتخاب مدل با مقایسه اعتبارسنجی و
70
00:02:28,890 –> 00:02:31,319
انتخاب پارامترها و مدلها در حال حاضر این
71
00:02:31,319 –> 00:02:32,819
در واقع کمی عمیقتر است تا
72
00:02:32,819 –> 00:02:34,590
جایی که کیت سایت آموخته است، ما در حال بررسی
73
00:02:34,590 –> 00:02:36,239
مدلهای مختلف برای پیشبینی
74
00:02:36,239 –> 00:02:38,430
دوره مناسب یا بهترین دوره هستیم.
75
00:02:38,430 –> 00:02:40,200
یا بهترین راه حل امروز چیست، مثلاً من
76
00:02:40,200 –> 00:02:41,579
می گویم ما در حال بررسی شراب ها هستیم، این است که
77
00:02:41,579 –> 00:02:43,139
چگونه می توانید بهترین شراب را از این طریق بدست آورید
78
00:02:43,139 –> 00:02:45,180
تا بتوانیم تفاوت ها را با هم مقایسه کنیم. مدلهای nt و
79
00:02:45,180 –> 00:02:46,349
ما کمی به آن نگاه میکنیم و
80
00:02:46,349 –> 00:02:48,030
دقت مدلها را از طریق
81
00:02:48,030 –> 00:02:50,459
پارامترهای مختلف و تنظیم دقیق بهبود میبخشیم، اکنون
82
00:02:50,459 –> 00:02:51,989
این تنها بخش اول است، بنابراین ما
83
00:02:51,989 –> 00:02:53,669
نمیخواهیم زیاد روی مدلهایی که در نظر داریم تنظیم کنیم
84
00:02:53,669 –> 00:02:55,139
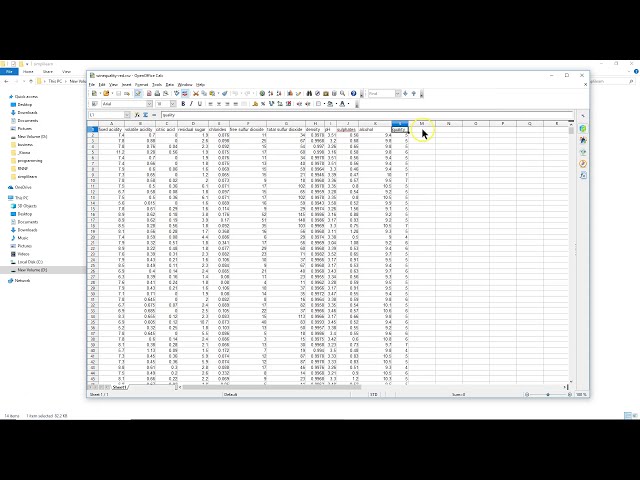
، اما من همانطور که
85
00:02:55,139 –> 00:02:57,750
به دیگر ویژگیها میرویم
86
00:02:57,750 –> 00:02:59,959
حفاظت از
87
00:02:59,959 –> 00:03:02,040
ابعاد و کاهش ابعاد پیش از پردازش، به آنها اشاره میکنیم، این است که ما
88
00:03:02,040 –> 00:03:03,959
تعداد متغیرهای تصادفی را کاهش میدهیم
89
00:03:03,959 –> 00:03:05,819
تا در نظر بگیریم که این کارایی مدل
90
00:03:05,819 –> 00:03:07,439
را افزایش میدهد، ما در آموزش امروز به آن دست نخواهیم داد
91
00:03:07,439 –> 00:03:09,930
، اما اگر شما را دارید آگاه باشید.
92
00:03:09,930 –> 00:03:12,209
بدانید که هزاران ستون
93
00:03:12,209 –> 00:03:14,129
داده وارد می شود، اما هزاران ویژگی که
94
00:03:14,129 –> 00:03:16,049
برخی از آنها تکرار می شوند
95
00:03:16,049 –> 00:03:18,419
یا می توانید برخی از آنها را با هم ترکیب کنید تا
96
00:03:18,419 –> 00:03:20,669
یک ستون جدید تشکیل دهید و با کاهش همه آن
97
00:03:20,669 –> 00:03:22,169
ویژگی های مختلف به مقدار کمتری،
98
00:03:22,169 –> 00:03:24,120
می توانید یک ویژگی را افزایش دهید.
99
00:03:24,120 –> 00:03:25,919
کارایی مدل شما میتواند
100
00:03:25,919 –> 00:03:28,319
سریعتر پردازش شود و در برخی موارد شما کمتر سوگیری خواهید داشت،
101
00:03:28,319 –> 00:03:30,060
زیرا اگر بارها و بارها آن را روی همان ویژگی وزن کنید،
102
00:03:30,060 –> 00:03:31,439
103
00:03:31,439 –> 00:03:33,150
به آن ویژگی و پیشپرداخت تعصب خواهد داشت.
104
00:03:33,150 –> 00:03:34,799
اساساً اینها هر دو
105
00:03:34,799 –> 00:03:36,810
پیش پردازش هستند، اما پیش پردازش
106
00:03:36,810 –> 00:03:38,939
استخراج ویژگی و عادی سازی است، بنابراین
107
00:03:38,939 –> 00:03:40,650
ما قرار است داده های ورودی
108
00:03:40,650 –> 00:03:42,479
مانند استفاده مجدد متن را با الگوریتم های یادگیری ماشین تبدیل
109
00:03:42,479 –> 00:03:44,340
کنیم، در این مورد یک مقیاس ساده
110
00:03:44,340 –> 00:03:45,840
برای
111
00:03:45,840 –> 00:03:47,579
پیش پردازش خود انجام خواهیم داد و
112
00:03:47,579 –> 00:03:49,319
وقتی به آن رسیدیم و میتوانیم در مورد پیشپردازش در آن نقطه بحث کنیم، به آن اشاره میکنم،
113
00:03:49,319 –> 00:03:51,180
114
00:03:51,180 –> 00:03:52,620
بیایید جلو برویم و آستینها را بالا
115
00:03:52,620 –> 00:03:55,259
بزنیم و شیرجه بزنیم و ببینیم چه چیزی به اینجا رسیدهایم،
116
00:03:55,259 –> 00:03:58,199
من دوست دارم از دفترچه یادداشت مشتری استفاده کنم و من
117
00:03:58,199 –> 00:04:01,019
از آن خارج از ناوبر Anaconda استفاده کنید، بنابراین
118
00:04:01,019 –> 00:04:03,239
اگر ناوبر Anaconda را به
119
00:04:03,239 –> 00:04:04,979
طور پیش فرض نصب کنید، همراه با نوت بوک مشتری خواهد بود
120
00:04:04,979 –> 00:04:06,659
یا می توانید
121
00:04:06,659 –> 00:04:08,879
نوت بوک مشتری را به تنهایی نصب کنید، این کد
122
00:04:08,879 –> 00:04:12,359
در هر یک از تنظیمات پایتون شما کار می کند، من فکر می
123
00:04:12,359 –> 00:04:14,090
کنم که من در حال اجرای یک محیط هستم. از
124
00:04:14,090 –> 00:04:15,989
تنظیمات سه نقطهای هفت در آنجا،
125
00:04:15,989 –> 00:04:17,459
باید به محیطهای اینجا بروم و
126
00:04:17,459 –> 00:04:19,380
آن را برای تنظیم پایتون جستجو کنم، اما این یکی
127
00:04:19,380 –> 00:04:21,238
از سه x است و ما ادامه میدهیم و
128
00:04:21,238 –> 00:04:22,889
این را راهاندازی میکنیم و این آن را در
129
00:04:22,889 –> 00:04:24,659
یک مرورگر وب باز میکند. بنابراین آن را به نوعی نیک است و
130
00:04:24,659 –> 00:04:25,800
همه چیز را جدا نگه می دارد
131
00:04:25,800 –> 00:04:28,020
و در این آناکوندا در واقع می توانید
132
00:04:28,020 –> 00:04:29,970
محیط های مختلف
133
00:04:29,970 –> 00:04:32,069
نسخه های مختلف ماژول های مختلف پایتون را
134
00:04:32,069 –> 00:04:33,599
در هر محیط نصب کنید، بنابراین
135
00:04:33,599 –> 00:04:35,280
اگر توسعه زیادی انجام می دهید ابزار بسیار قدرتمندی است
136
00:04:35,280 –> 00:04:36,960
و نوت بوک Jupiter
137
00:04:36,960 –> 00:04:38,639
فقط یک صفحه نمایش بصری فوق العاده است
138
00:04:38,639 –> 00:04:40,500
مطمئنا میتوانید از
139
00:04:40,500 –> 00:04:42,150
یکی دیگر میدانم که با آناکوندا نصب شده است
140
00:04:42,150 –> 00:04:44,669
استفاده کنید. من در واقع از یک دفترچه یادداشت ساده
141
00:04:44,669 –> 00:04:46,740
به اضافه پلاس استفاده میکنم وقتی که برخی از
142
00:04:46,740 –> 00:04:49,680
اسکریپتهای پایتون را انجام میدهم، هر یک از شناسههای شما به خوبی کار
143
00:04:49,680 –> 00:04:52,080
144
00:04:52,080 –> 00:04:54,270
میکند.
145
00:04:54,270 –> 00:04:55,530
خوب است که از این
146
00:04:55,530 –> 00:04:58,139
ابزارهای مختلف آگاه باشید و وقتی
147
00:04:58,139 –> 00:05:00,150
نوت بوک ژوپیتر را راه اندازی می کنم باز می شود همانطور
148
00:05:00,150 –> 00:05:02,310
که یک صفحه وب در اینجا گفتم و ما به
149
00:05:02,310 –> 00:05:04,259
اینجا می رویم و یک پایتون جدید ایجاد می کنیم که من
150
00:05:04,259 –> 00:05:05,819
همانطور که گفتم تنظیم شده ام. من معتقدم که این
151
00:05:05,819 –> 00:05:08,759
پایتون 3 7 است، اما هر سه نسخه دیگر که
152
00:05:08,759 –> 00:05:11,580
Sicit-Learn با هر یک از سه
153
00:05:11,580 –> 00:05:13,830
x کار می کند، حتی دو نسخه هفت نسخه وجود دارد،
154
00:05:13,830 –> 00:05:15,419
بنابراین مدت زیادی از آن استفاده شده است، بنابراین در حال توسعه
155
00:05:15,419 –> 00:05:17,130
بسیار بزرگ است. طرف
156
00:05:17,130 –> 00:05:20,370
pment و سپس بچههای پشتی، بچهها و دخترها
157
00:05:20,370 –> 00:05:21,900
پیشرفت کردند و این
158
00:05:21,900 –> 00:05:23,610
را برای من کنار هم گذاشتند و بیایید جلو برویم و
159
00:05:23,610 –> 00:05:26,250
بستههای مختلف خود را وارد کنیم،
160
00:05:26,250 –> 00:05:27,240
اگر برخی از آموزشهای دیگر ما
161
00:05:27,240 –> 00:05:30,360
را خواندهاید، پانداها را بهعنوان p تشخیص میدهید.
162
00:05:30,360 –> 00:05:32,940
d- کتابخانههای پانداها بهطور گسترده
163
00:05:32,940 –> 00:05:35,069
بهعنوان تنظیم قاب داده استفاده میشوند، بنابراین درست مانند
164
00:05:35,069 –> 00:05:37,680
ستونها و ردیفها و صفحهگستردهای
165
00:05:37,680 –> 00:05:39,180
با بسیاری از ویژگیهای مختلف برای جستجوی
166
00:05:39,180 –> 00:05:41,849
چیزها در Seabourn است که در بالای
167
00:05:41,849 –> 00:05:44,130
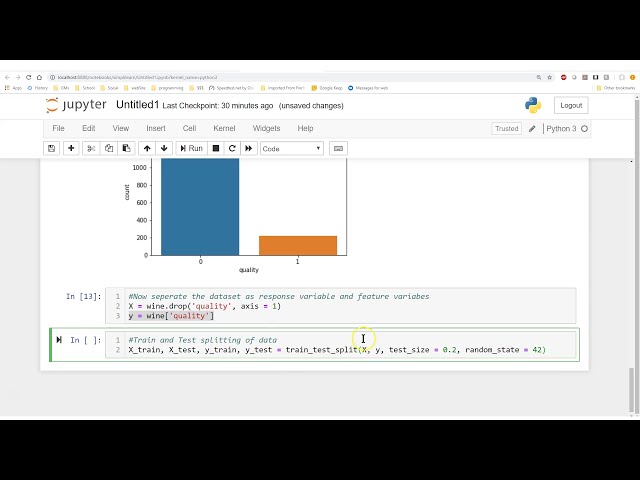
کتابخانههای طرح مات قرار میگیرد.
168
00:05:44,130 –> 00:05:46,289
چقدر سریع است که یک
169
00:05:46,289 –> 00:05:48,630
نمودار برای نمایش در
170
00:05:48,630 –> 00:05:50,370
نوت بوک مشتری برای نمایش و نشان دادن
171
00:05:50,370 –> 00:05:52,139
آنچه در حال وقوع است و سپس از
172
00:05:52,139 –> 00:05:56,610
جنگل تصادفی SVC یا
173
00:05:56,610 –> 00:06:00,029
طبقهبندی کننده بردار پشتیبانی و همچنین شبکه عصبی
174
00:06:00,029 –> 00:06:01,380
استفاده میکنیم. برای بررسی این موضوع،
175
00:06:01,380 –> 00:06:02,699
در واقع به
176
00:06:02,699 –> 00:06:04,770
بررسی سه طبقهبندیکننده مختلف میپردازیم
177
00:06:04,770 –> 00:06:06,300
که رایجترین
178
00:06:06,300 –> 00:06:08,580
طبقهبندیکنندهها هستند، اجازه دهید نشان دهیم که این دستهبندیکنندهها چگونه در
179
00:06:08,580 –> 00:06:11,159
تنظیمات یادگیری scikit کار میکنند و چگونه
180
00:06:11,159 –> 00:06:13,110
متفاوت هستند و سپس اگر شما میخواهید
181
00:06:13,110 –> 00:06:15,000
تنظیمات خود را در
182
00:06:15,000 –> 00:06:16,349
اینجا انجام دهید، میخواهید ادامه دهید و برخی از
183
00:06:16,349 –> 00:06:18,960
معیارها را وارد کنید تا SK معیارها را در
184
00:06:18,960 –> 00:06:20,940
اینجا یاد بگیرد و ما از معیارهای سردرگمی
185
00:06:20,940 –> 00:06:22,469
و گزارش طبقهبندی خارج از
186
00:06:22,469 –> 00:06:24,210
آن استفاده میکنیم و سپس از
187
00:06:24,210 –> 00:06:26,789
SK یادگیری پیش پردازش
188
00:06:26,789 –> 00:06:29,279
مقیاسکننده استاندارد و مقیاسکننده استاندارد رمزگذار برچسب
189
00:06:29,279 –> 00:06:30,830
احتمالاً متداولترین پیشپردازش مورد استفاده است،
190
00:06:30,830 –> 00:06:32,699
191
00:06:32,699 –> 00:06:34,740
بستههای پیشپردازشی مختلفی در
192
00:06:34,740 –> 00:06:37,110
یادگیری SK وجود دارد و سپس انتخاب مدل برای
193
00:06:37,110 –> 00:06:39,060
تقسیم دادههایمان یکی
194
00:06:39,060 –> 00:06:40,620
از راههای بسیاری است که ما انجام میدهیم. میتواند دادهها را به
195
00:06:40,620 –> 00:06:42,690
بخشهای مختلف تقسیم کند و آخرین خط
196
00:06:42,690 –> 00:06:45,840
در اینجا، درصد کتابخانه نمودار مات
197
00:06:45,840 –> 00:06:46,770
در خط است،
198
00:06:46,770 –> 00:06:48,600
برخی از کتابخانه طرحهای Seaboard و mat
199
00:06:48,600 –> 00:06:50,010
پیش میروند و
200
00:06:50,010 –> 00:06:51,990
کاملاً در یک راستا بدون این نمایش داده میشوند و برخی
201
00:06:51,990 –> 00:06:52,620
نیز
202
00:06:52,620 –> 00:06:54,000
خوب نیست که همیشه این را درج
203
00:06:54,000 –> 00:06:55,440
کنید. ‘re in the jupiter notebook است، این دفترچه یادداشت jupiter است،
204
00:06:55,440 –> 00:06:57,540
بنابراین اگر در ite
205
00:06:57,540 –> 00:06:59,520
هستید هنگام اجرای این، در واقع
206
00:06:59,520 –> 00:07:01,830
یک پنجره جدید باز می شود و گرافیک ها را به این ترتیب نمایش می دهد،
207
00:07:01,830 –> 00:07:04,200
بنابراین فقط اگر
208
00:07:04,200 –> 00:07:06,450
آن را به صورت ویرایشی اجرا می کنید به آن نیاز دارید.
209
00:07:06,450 –> 00:07:08,130
210
00:07:08,130 –> 00:07:09,990
من حتی با ویرایشگرهای دیگری
211
00:07:09,990 –> 00:07:11,250
که اینگونه هستند آشنا نیستم، اما مطمئن هستم که آنها در دسترس
212
00:07:11,250 –> 00:07:12,990
هستند، مطمئنم که نسخه فایرفاکس
213
00:07:12,990 –> 00:07:13,889
یا چیزی که در
214
00:07:13,889 –> 00:07:15,630
Jupiter notebook
215
00:07:15,630 –> 00:07:18,060
بیشتر است وجود دارد. به طور گسترده ای در آنجا استفاده می شود و ما می توانیم
216
00:07:18,060 –> 00:07:20,190
جلو برویم و دکمه Run را فشار دهیم و این
217
00:07:20,190 –> 00:07:22,530
اکنون همه اینها را در زیر بسته ها ذخیره کرده است
218
00:07:22,530 –> 00:07:24,450
بنابراین بسته های من اکنون همه
219
00:07:24,450 –> 00:07:26,100
بارگذاری شده اند.
220
00:07:26,100 –> 00:07:27,930
221
00:07:27,930 –> 00:07:29,550
بستهها در بالا هستند، بنابراین ما اکنون
222
00:07:29,550 –> 00:07:32,250
همه آنها را برای پروژهای
223
00:07:32,250 –> 00:07:33,780
که روی آن کار میکنیم در دسترس داریم و من فقط میخواهم
224
00:07:33,780 –> 00:07:35,729
یک یادداشت جانبی کوچک در مورد آن داشته باشم وقتی
225
00:07:35,729 –> 00:07:38,040
که با اینها بازی میکنید و
226
00:07:38,040 –> 00:07:40,020
چیزی را حذف میکنید و چیزی اضافه میکنید. حتی
227
00:07:40,020 –> 00:07:42,180
اگر به عقب برگردم و این سلول را حذف کردم و
228
00:07:42,180 –> 00:07:44,130
فقط قیچی را در اینجا
229
00:07:44,130 –> 00:07:46,380
بزنم، اینها همچنان در این هسته بارگذاری شده اند، بنابراین تا زمانی که
230
00:07:46,380 –> 00:07:49,169
به زیر هسته و راه اندازی مجدد یا راه اندازی مجدد
231
00:07:49,169 –> 00:07:51,120
و پاک کردن یا راه اندازی مجدد و اجرای همه چیز
232
00:07:51,120 –> 00:07:53,820
باز هم به پانداهای مهم دسترسی خواهم داشت.
233
00:07:53,820 –> 00:07:55,320
بدانم چون قبلا این کار را انجام داده ام من
234
00:07:55,320 –> 00:07:57,390
شاید یک ماژول را در اینجا
235
00:07:57,390 –> 00:07:59,010
بارگذاری نکردهام، اما کد خودم را بارگذاری کردهام و سپس
236
00:07:59,010 –> 00:08:00,539
نظرم را تغییر دادهام و به این فکر میکنم که چرا او
237
00:08:00,539 –> 00:08:02,039
همچنان خروجی اشتباه را ارائه میکند و
238
00:08:02,039 –> 00:08:03,390
بعد متوجه میشوم که هنوز در هسته بارگذاری شده است،
239
00:08:03,390 –> 00:08:04,890
شما باید آن را دوباره راهاندازی کنید. هسته
240
00:08:04,890 –> 00:08:06,539
فقط یک یادداشت جانبی سریع برای کار با
241
00:08:06,539 –> 00:08:08,010
یک نوت بوک مشتری و یکی از
242
00:08:08,010 –> 00:08:09,419
موارد عیب یابی که پیش می آید،
243
00:08:09,419 –> 00:08:11,340
ما می رویم و مجموعه داده های خود را بارگذاری می کنیم،
244
00:08:11,340 –> 00:08:13,440
ما از پانداها استفاده می کنیم، بنابراین اگر هنوز نرفته
245
00:08:13,440 –> 00:08:15,210
اید به پانداهای ما نگاه کنید. آموزش
246
00:08:15,210 –> 00:08:17,880
ساده خواندن csv با جداسازی
247
00:08:17,880 –> 00:08:19,380
در اینجا، بنابراین اجازه دهید من ادامه دهم و آن را اجرا
248
00:08:19,380 –> 00:08:21,930
کنم و اکنون در شراب متغیر بارگذاری شده
249
00:08:21,930 –> 00:08:24,330
است و اجازه دهید نگاهی گذرا به
250
00:08:24,330 –> 00:08:26,160
فایل واقعی بیندازیم من همیشه دوست دارم به
251
00:08:26,160 –> 00:08:28,020
داده های واقعی که دارم کار می کنم نگاه کنم. در این
252
00:08:28,020 –> 00:08:30,240
مورد، ما کیفیت شراب را داریم – قرمز، من
253
00:08:30,240 –> 00:08:31,919
فقط آن را باز میکنم، من در
254
00:08:31,919 –> 00:08:34,950
تنظیمات OpenOffice خود با نقطه ویرگول جدا نشدهام
255
00:08:34,950 –> 00:08:38,099
که توجه به آن مهم است و ما آن را باز
256
00:08:38,099 –> 00:08:40,830
میکنیم، میبینید که
257
00:08:40,830 –> 00:08:43,529
ما تا آخر اینجا رفتهایم. مانند 1600 خط داده به نظر می رسد
258
00:08:43,529 –> 00:08:47,700
– اولین آن 15 1599 خط
259
00:08:47,700 –> 00:08:50,040
یک d ما تعدادی ویژگی داریم که
260
00:08:50,040 –> 00:08:52,740
در مورد آخرین مورد کیفیت است و
261
00:08:52,740 –> 00:08:55,500
باید شرط ببندیم که کیفیت را
262
00:08:55,500 –> 00:08:57,630
با اعداد متفاوت در پنج شش هفت مشاهده
263
00:08:57,630 –> 00:09:00,330
می کنیم، واقعاً مطمئن نیستم که
264
00:09:00,330 –> 00:09:01,740
سطح آن چقدر بالا می رود اما من چیزی
265
00:09:01,740 –> 00:09:03,510
بیش از هفت را نمی بینم، بنابراین به نوعی پنج
266
00:09:03,510 –> 00:09:05,550
تا هفت است، همان چیزی است که من در اینجا می بینم پنج
267
00:09:05,550 –> 00:09:07,860
شش و هفت چهار یا پنج شش و هفت
268
00:09:07,860 –> 00:09:09,029
به دنبال اینکه ببینم آیا
269
00:09:09,029 –> 00:09:11,459
مقادیر دیگری در آنجا وجود دارد که از طریق نسخه نمایشی نگاه می کنم
270
00:09:11,459 –> 00:09:12,870
یا برای شروع، من این کار را نکردم. متوجه
271
00:09:12,870 –> 00:09:14,880
تنظیمات این دستگاه شوید ببینید
272
00:09:14,880 –> 00:09:17,220
سولفات های الکلی دارای مقادیر متفاوتی با کیفیت
273
00:09:17,220 –> 00:09:20,520
pH کل دی اکسید گوگرد
274
00:09:20,520 –> 00:09:22,380
و غیره هستند و اینها ویژگی های دیگری هستند که
275
00:09:22,380 –> 00:09:24,990
ما به آنها نگاه خواهیم کرد و از آنجایی که این
276
00:09:24,990 –> 00:09:28,470
یک پاندا است، ما فقط سر شراب و
277
00:09:28,470 –> 00:09:30,870
که پنج نقش اول ردیف های داده ما را چاپ می
278
00:09:30,870 –> 00:09:33,510
کند که البته فرمان pandas است و
279
00:09:33,510 –> 00:09:35,310
می توانیم ببینیم که بسیار شبیه به آنچه
280
00:09:35,310 –> 00:09:36,690
قبل از اینکه
281
00:09:36,690 –> 00:09:37,830
همه چیز را در اینجا داشته باشیم به آن نگاه می کردیم، به
282
00:09:37,830 –> 00:09:40,170
طور خودکار یک فهرست در سمت چپ اختصاص داده می شود، این
283
00:09:40,170 –> 00:09:40,680
284
00:09:40,680 –> 00:09:41,940
همان کاری است که پانداها انجام می دهند، اگر شما این کار را نکنید.
285
00:09:41,940 –> 00:09:43,920
به آن شاخص بدهید و برای نام ستون
286
00:09:43,920 –> 00:09:47,100
ها، ردیف اول را اختصاص داده است، بنابراین
287
00:09:47,100 –> 00:09:48,810
ما باید ردیف اول داده های خود را
288
00:09:48,810 –> 00:09:51,540
از فایل متغیر جدا شده با کاما در
289
00:09:51,540 –> 00:09:54,390
این مورد، نقطه ویرگول جدا کرده و
290
00:09:54,390 –> 00:09:55,440
ویژگی های مختلف را نشان می دهد
291
00:09:55,440 –> 00:09:59,160
و ما چه چیزی را داریم 1 2 3 4 5 6 7 8
292
00:09:59,160 –> 00:10:02,520
9 10 11 ویژگی های 12 شامل کیفیت،
293
00:10:02,520 –> 00:10:04,140
اما این همان چیزی است که ما می خواهیم روی آن کار
294
00:10:04,140 –> 00:10:06,660
کنیم و آن را درک کنیم و سپس به دلیل اینکه در
295
00:10:06,660 –> 00:10:09,240
چارچوب داده پاندا هستیم، می توانیم اطلاعات Wyandotte را نیز انجام دهیم
296
00:10:09,240 –> 00:10:11,279
و بیایید ادامه دهیم و
297
00:10:11,279 –> 00:10:13,410
اجرا کنیم که این به ما چیزهای زیادی در مورد متغیرهای ما می گوید.
298
00:10:13,410 –> 00:10:15,149
ما در حال کار با شما هستیم،
299
00:10:15,149 –> 00:10:19,020
در اینجا خواهید دید که 1599 وجود دارد که همان چیزی است که
300
00:10:19,020 –> 00:10:20,610
من از صفحه گسترده گفتم، بنابراین درست به نظر می رسد
301
00:10:20,610 –> 00:10:24,870
float64 غیر تهی، این
302
00:10:24,870 –> 00:10:26,820
اطلاعات بسیار مهمی است، به خصوص غیر
303
00:10:26,820 –> 00:10:29,550
تهی، هیچ مقدار تهی در اینجا وجود ندارد که
304
00:10:29,550 –> 00:10:31,649
واقعاً می تواند ما را به خطر بیندازد. در پیش پردازش
305
00:10:31,649 –> 00:10:33,329
و تعدادی روش برای پردازش
306
00:10:33,329 –> 00:10:36,000
مقادیر غیر پوچ وجود دارد، یکی این است
307
00:10:36,000 –> 00:10:37,500
که داده ها را از آنجا حذف کنید، بنابراین اگر
308
00:10:37,500 –> 00:10:39,149
داده های کافی در آنجا دارید، ممکن است فقط
309
00:10:39,149 –> 00:10:40,980
مقادیر غیر پوچ خود را حذف کنید، روش
310
00:10:40,980 –> 00:10:43,680
دیگر پر کردن آن اطلاعات است.
311
00:10:43,680 –> 00:10:46,170
مانند میانگین یا رایجترین مقادیر یا
312
00:10:46,170 –> 00:10:48,089
دیگر ابزارهای مشابه، اما
313
00:10:48,089 –> 00:10:49,680
لازم نیست نگران آن باشیم، اما به
314
00:10:49,680 –> 00:10:51,360
شکل دیگری به آن نگاه میکنیم، زیرا میتوانیم
315
00:10:51,360 –> 00:10:54,930
شراب را نیز تهی کنیم و آن را خلاصه کنیم و این نتیجه
316
00:10:54,930 –> 00:10:56,850
میدهد مشابه ما به ما نمی گوید که
317
00:10:56,850 –> 00:10:58,950
اینها مقادیر شناور هستند، اما به
318
00:10:58,950 –> 00:11:00,930
ما یک جمع بندی می دهد. متاسفم، اجازه دهید اجرا کنم
319
00:11:00,930 –> 00:11:03,270
که او در اینجا به ما جمع بندی می کند
320
00:11:03,270 –> 00:11:05,670
که در هر کدام چند مقدار تهی به ما می دهد، بنابراین
321
00:11:05,670 –> 00:11:07,170
او از شما خواسته است. بدانید که از اینجا
322
00:11:07,170 –> 00:11:08,640
میتوانید بگویید خوب این یک مقدار تهی
323
00:11:08,640 –> 00:11:10,380
است، اما او به شما نمیگوید که چند
324
00:11:10,380 –> 00:11:12,840
مقدار تهی
325
00:11:12,840 –> 00:11:14,700
326
00:11:14,700 –> 00:11:17,100
327
00:11:17,100 –> 00:11:18,930
است. فقط هفت مقدار تهی داشت
328
00:11:18,930 –> 00:11:20,880
و تمام آن تاریخگذاریهای متفاوت
329
00:11:20,880 –> 00:11:22,770
احتمالاً فقط آنها را حذف میکند، جایی که اگر
330
00:11:22,770 –> 00:11:25,200
نود درصد دادهها فاقد مقادیر بودند،
331
00:11:25,200 –> 00:11:26,940
میتوانید در
332
00:11:26,940 –> 00:11:30,120
تنظیم مجموعه دادههای متفاوت تجدیدنظر کنید یا
333
00:11:30,120 –> 00:11:31,320
راهی متفاوت برای مقابله با مقادیر پوچ
334
00:11:31,320 –> 00:11:32,850
که در مورد آن صحبت خواهیم کرد پیدا کنید. که فقط
335
00:11:32,850 –> 00:11:34,800
کمی در مدل ها بیش از حد به دلیل
336
00:11:34,800 –> 00:11:37,140
وزارت دفاع خود els دارای برخی
337
00:11:37,140 –> 00:11:39,240
ویژگیهای داخلی هستند به خصوص مدل جنگل
338
00:11:39,240 –> 00:11:41,490
که در این
339
00:11:41,490 –> 00:11:43,680
مرحله به بررسی آن
340
00:11:43,680 –> 00:11:45,180
341
00:11:45,180 –> 00:11:47,160
342
00:11:47,160 –> 00:11:50,430
میپردازیم. چند سطل و سطل ایجاد کنید که ما
343
00:11:50,430 –> 00:11:53,070
انجام می دهیم این است که 2 کاما 6 نقطه 5 کاما 8
344
00:11:53,070 –> 00:11:56,640
به این معنی است که
345
00:11:56,640 –> 00:11:58,470
اگر به یاد داشته باشید این
346
00:11:58,470 –> 00:11:59,970
مقادیر را می گیریم.
347
00:11:59,970 –> 00:12:01,590
348
00:12:01,590 –> 00:12:04,620
اساساً بین 2 و 8 یا 1 و 8 می آید
349
00:12:04,620 –> 00:12:06,750
، ما 5 5 5 6 داریم که می توانید
350
00:12:06,750 –> 00:12:08,910
فقط در 5 خط اول تنوع
351
00:12:08,910 –> 00:12:11,130
و کیفیت را ببینید، ما آن
352
00:12:11,130 –> 00:12:14,040
را فقط در دو سطل با کیفیت جدا می کنیم و بنابراین
353
00:12:14,040 –> 00:12:16,530
ما تصمیم گرفتیم دو سطل بسازیم و
354
00:12:16,530 –> 00:12:17,850
ما بد و خوب داریم، این است که
355
00:12:17,850 –> 00:12:19,860
برچسبهای روی آن دو سطل میشوند. ما دارای
356
00:12:19,860 –> 00:12:23,160
اسپرد 6.5 هستیم و شاخص دقیق ate
357
00:12:23,160 –> 00:12:25,500
شاخص دقیق به این دلیل است که ما 0
358
00:12:25,500 –> 00:12:29,220
تا 8 را روی آن 6.5 میتوانیم انجام میدهیم.
359
00:12:29,220 –> 00:12:30,810
ما واقعاً میتوانیم این را کوچکتر یا
360
00:12:30,810 –> 00:12:32,100
بزرگتر کنیم، اما ما فقط به دنبال چیزی هستیم که
361
00:12:32,100 –> 00:12:33,930
واقعاً خوب نیستیم به
362
00:12:33,930 –> 00:12:38,070
دنبال 0 1 2 3 4 5 6 ما به دنبال
363
00:12:38,070 –> 00:12:40,860
شراب هایی با 7 یا 8 با کیفیت بسیار بالا هستیم
364
00:12:40,860 –> 00:12:42,420
که می دانید این چیزی است که من می خواهم
365
00:12:42,420 –> 00:12:45,390
شب ها روی میز شام خود بگذارم. می خواهم
366
00:12:45,390 –> 00:12:47,550
شراب خوب را بچشم نه نیمه خوب شراب یا
367
00:12:47,550 –> 00:12:50,220
شراب متوسط و سپس این یک پاندا است بن
368
00:12:50,220 –> 00:12:52,320
براین عضو PD مخفف pandas pandas cut
369
00:12:52,320 –> 00:12:54,360
ه این معنی است که کیفیت شراب را کاهش می ده
370
00:12:54,360 –> 00:12:56,460
م و آن را جایگزین می کنیم و سپس سط
371
00:12:56,460 –> 00:12:58,680
هایمان برابر با سطل ها است که دس
372
00:12:58,680 –> 00:13:00,570
ور bins فرمان واقعی اس
373
00:13:00,570 –> 00:13:02,940
و سپس سطلهای متغیر ما به 6.58 میآیند،
374
00:13:02,940 –> 00:13:05,220
بنابراین دو سطل مختلف و برچسبهای ما بد
375
00:13:05,220 –> 00:13:08,070
و خوب و ما نیز میتوانیم انجام دهیم، به من اجازه دهید
376
00:13:08,070 –> 00:13:10,770
این کار را با کیفیت شراب انجام دهم، زیرا این همان
377
00:13:10,770 –> 00:13:12,600
چیزی است که ما روی آن کار میکنیم و بیایید
378
00:13:12,600 –> 00:13:15,030
به فرمان پانداهای منحصر به فرد دیگری نگاه کنیم و ما
379
00:13:15,030 –> 00:13:17,610
این را اجرا می کنم و من این خطای دوست داشتنی
380
00:13:17,610 –> 00:13:18,870
را دریافت می کنم چرا خطای خوبی دریافت کردم
381
00:13:18,870 –> 00:13:21,839
زیرا کیفیت شراب را جایگزین
382
00:13:21,839 –> 00:13:24,089
کردم و این برش را در اینجا انجام دادم که همه چیز
383
00:13:24,089 –> 00:13:26,130
را تغییر
384
00:13:26,130 –> 00:13:27,540
385
00:13:27,540 –> 00:13:29,100
می دهد. به اینجا میرویم تا هسته را
386
00:13:29,100 –> 00:13:30,990
مجدداً راهاندازی کنیم و همه چیزهایی که از آن شروع میشود را اجرا میکنیم
387
00:13:30,990 –> 00:13:32,970
در همان ابتدا و ما میتوانیم اینجا
388
00:13:32,970 –> 00:13:34,680
ببینیم که هوا را درست میکند، زیرا من
389
00:13:34,680 –> 00:13:36,089
چیزی را که قبلاً قطع شده است
390
00:13:36,089 –> 00:13:38,310
برش نمیدهم، ما کیفیت شراب خود را منحصربهفرد داریم
391
00:13:38,310 –> 00:13:40,800
و کیفیت شراب منحصربهفرد یک بد یا خوب است،
392
00:13:40,800 –> 00:13:43,110
بنابراین ما دو کیفیت داریم شیء بد
393
00:13:43,110 –> 00:13:45,180
کمتر از به معنای خوب، بد
394
00:13:45,180 –> 00:13:47,760
صفر خواهد بود و کالاها یک می شوند و برای
395
00:13:47,760 –> 00:13:49,830
تحقق
396
00:13:49,830 –> 00:13:52,650
این امر باید آن را رمزگذاری کنیم، بنابراین از کیفیت
397
00:13:52,650 –> 00:13:55,080
برچسب برابر با رمزگذار برچسب استفاده می کنیم و رمزگذار برچسب
398
00:13:55,080 –> 00:13:56,640
به من اجازه دهید
399
00:13:56,640 –> 00:13:58,470
به عنوان بخشی از SK متوجه شد که یکی
400
00:13:58,470 –> 00:14:00,180
از چیزهایی است که ما وارد می کنیم، یک رمزگذار برچسب است،
401
00:14:00,180 –> 00:14:01,890
می توانید آن را در اینجا
402
00:14:01,890 –> 00:14:04,710
از مقیاس کننده استاندارد واردات پردازش یادگیری SK مشاهده کنید که
403
00:14:04,710 –> 00:14:06,000
در یک
404
00:14:06,000 –> 00:14:08,370
دقیقه و رمزگذار برچسب استفاده می کنیم و این چیزی است که
405
00:14:08,370 –> 00:14:10,680
به آن می گوید که از آن استفاده کند. برابر با صفر و
406
00:14:10,680 –> 00:14:12,420
خوب برابر با یک است و ما ادامه می دهیم و آن را
407
00:14:12,420 –> 00:14:14,040
اجرا می کنیم و سپس باید آن را
408
00:14:14,040 –> 00:14:16,140
روی داده ها اعمال کنیم و وقتی این کار را انجام دادیم
409
00:14:16,140 –> 00:14:18,480
کیفیت شراب خود را که قبلا
410
00:14:18,480 –> 00:14:20,370
داشتیم می گیریم و آن را برابر با کیفیت برچسب تنظیم می کنیم.
411
00:14:20,370 –> 00:14:22,500
که رمزگذار ما است و اجازه دهید
412
00:14:22,500 –> 00:14:24,420
در اینجا به این خط نگاه کنید، ما
413
00:14:24,420 –> 00:14:27,240
تبدیل نقطه تناسب را داریم و این را در پیش پردازش خواهید دید که
414
00:14:27,240 –> 00:14:29,459
اینها رایج ترین موارد
415
00:14:29,459 –> 00:14:32,850
مورد استفاده تبدیل مناسب و تبدیل مناسب هستند،
416
00:14:32,850 –> 00:14:34,260
زیرا آنها به قدری زیاد هستند که شما همچنین در حال
417
00:14:34,260 –> 00:14:35,910
تبدیل داده ها هستید.
418
00:14:35,910 –> 00:14:37,320
آنها را در یک دستور ترکیب کردند
419
00:14:37,320 –> 00:14:39,180
و اگر میخواهیم
420
00:14:39,180 –> 00:14:41,550
کیفیت شراب را ببریم، آن را دوباره به آنجا برگردانیم
421
00:14:41,550 –> 00:14:43,589
و آن را در تنظیمات کیفیت شراب خود قرار دهیم
422
00:14:43,589 –> 00:14:46,920
و آن را اجرا کنیم و حالا شراب
423
00:14:46,920 –> 00:14:49,500
و سر اولی را چه میکنیم. پنج مقدار
424
00:14:49,500 –> 00:14:51,720
و ما ادامه میدهیم و این را اجرا میکنیم، میتوانید
425
00:14:51,720 –> 00:14:53,790
اینجا را ببینید، زیر کیفیت صفر صفر،
426
00:14:53,790 –> 00:14:55,890
باید کمی پایینتر بروید تا به
427
00:14:55,890 –> 00:14:58,290
شرابهای بهتر نگاه
428
00:14:58,290 –> 00:14:59,850
429
00:14:59,850 –> 00:15:01,529
کنید. بیایید به
430
00:15:01,529 –> 00:15:02,790
ده مورد از آنها نگاه کنیم، می توانید تمام راه
431
00:15:02,790 –> 00:15:05,520
را تا صفر یا یک ببینید که کیفیت ماست
432
00:15:05,520 –> 00:15:06,600
و دوباره به کیفیت بالا
433
00:15:06,600 –> 00:15:08,279
نگاه می کنیم، ما به هفت و هشت
434
00:15:08,279 –> 00:15:11,310
یا شش نقطه پنج به بالا نگاه می کنیم و بیایید ادامه دهیم
435
00:15:11,310 –> 00:15:13,589
و ما را بگیریم یا اینجا بودیم
436
00:15:13,589 –> 00:15:16,170
کیفیت شراب را بگیریم نگاهی به
437
00:15:16,170 –> 00:15:17,850
اطلاعات بیشتری در مورد کیفیت شراب بیندازید که
438
00:15:17,850 –> 00:15:20,790
می توانیم انجام دهیم. پانداهای ساده،
439
00:15:20,790 –> 00:15:24,060
مقدار آن را به درستی تایپ می کنم
440
00:15:24,060 –> 00:15:26,400
و می بینیم که ما
441
00:15:26,400 –> 00:15:29,280
فقط دویست و هفده
442
00:15:29,280 –> 00:15:30,720
شراب داریم که بالاتر خواهد بود.
443
00:15:30,720 –> 00:15:32,670
کیفیت بنابراین دویست هفده
444
00:15:32,670 –> 00:15:35,010
و بقیه آنها در
445
00:15:35,010 –> 00:15:39,210
سطل بد و صفر قرار می گیرند که 1382 است، بنابراین
446
00:15:39,210 –> 00:15:40,350
ما دوباره به دنبال
447
00:15:40,350 –> 00:15:42,360
درصد بالایی از اینها هستیم، چه چیزی است
448
00:15:42,360 –> 00:15:44,340
که احتمالاً در آنجا کمی زیر 20 درصد است.
449
00:15:44,340 –> 00:15:46,530
ما به دنبال شراب های برتر خود
450
00:15:46,530 –> 00:15:49,380
هستیم که هفت و هشت هستند و اجازه دهید
451
00:15:49,380 –> 00:15:51,480
از اجازه دهید این را بر روی یک نمودار ترسیم
452
00:15:51,480 –> 00:15:53,940
کنیم، بنابراین اگر به درستی به یاد داشته باشید به این و SNS نگاهی بیندازیم، این
453
00:15:53,940 –> 00:15:55,770
است که من
454
00:15:55,770 –> 00:15:56,730
فقط به بالای صفحه برگشتم
455
00:15:56,730 –> 00:15:59,040
که Seaborn Seaborn ما است. در
456
00:15:59,040 –> 00:16:00,960
بالای کتابخانه طرح حصیر قرار می گیرد، دارای بسیاری از
457
00:16:00,960 –> 00:16:02,820
ویژگی های اضافه شده به علاوه تمام ویژگی های
458
00:16:02,820 –> 00:16:04,710
کتابخانه طرح حصیری است و همچنین باعث می شود
459
00:16:04,710 –> 00:16:06,510
نمودار را سریع و آسان نشان دهید،
460
00:16:06,510 –> 00:16:08,700
ما یک نمودار میله ای ساده انجام می دهیم و
461
00:16:08,700 –> 00:16:10,890
در واقع آن را count می نامند. طرح و سپس ما
462
00:16:10,890 –> 00:16:13,200
می خواهیم فقط انجام حساب کیفیت شراب را ترسیم کنید
463
00:16:13,200 –> 00:16:15,540
فقط کیفیت شراب خود را در
464
00:16:15,540 –> 00:16:17,070
آنجا قرار دهید، بیایید ادامه دهیم و این را اجرا کنیم و
465
00:16:17,070 –> 00:16:18,840
ببینیم که چگونه به نظر می رسد و در
466
00:16:18,840 –> 00:16:20,580
اعضای ردیف خوب است که چرا ما این خط را انجام دادیم، بنابراین
467
00:16:20,580 –> 00:16:22,110
مطمئن شوید که در اینجا ظاهر می شود و می
468
00:16:22,110 –> 00:16:24,380
توانید فضای آبی را ببینید یا فضای اول
469
00:16:24,380 –> 00:16:27,630
نشاندهنده شراب با کیفیت پایین است و
470
00:16:27,630 –> 00:16:29,430
نوار دوم ما خط تولید با کیفیت بالا است و
471
00:16:29,430 –> 00:16:30,810
میتوانید ببینید که آنها فقط به
472
00:16:30,810 –> 00:16:33,600
شراب با کیفیت بالا نگاه میکنند، بیشتر شرابی
473
00:16:33,600 –> 00:16:34,650
که ما میخواهیم آن را به
474
00:16:34,650 –> 00:16:36,570
همسایهها بدهیم و شاید اگر این کار را نکنید. مثل
475
00:16:36,570 –> 00:16:38,130
همسایههای شما ممکن است
476
00:16:38,130 –> 00:16:39,540
شراب با کیفیت خوب شوند و من
477
00:16:39,540 –> 00:16:40,620
نمیدانم با شراب با کیفیت بستر چه میکنید،
478
00:16:40,620 –> 00:16:42,420
حدس میزنم از آن برای پخت و پز استفاده کنید،
479
00:16:42,420 –> 00:16:43,530
اما میتوانید اینجا را ببینید که یک
480
00:16:43,530 –> 00:16:45,630
نمودار کوچک زیبا برای ما با Seabourn در
481
00:16:45,630 –> 00:16:47,160
آنجا تشکیل میدهد. و میتوانید تنظیمات ما را روی آن ببینید،
482
00:16:47,160 –> 00:16:49,740
بنابراین اکنون نگاه کردهایم که برخی از
483
00:16:49,740 –> 00:16:51,990
پیشپردازشها را انجام دادهایم،
484
00:16:51,990 –> 00:16:53,820
دادههایمان را کمی توضیح دادهایم، تصویری داریم
485
00:16:53,820 –> 00:16:55,530
از مقدار شرابی که انتظار داریم
486
00:16:55,530 –> 00:16:57,810
کیفیت بالا داشته باشد، پایین باشد. کیفیت این واقعیت را بررسی کرد
487
00:16:57,810 –> 00:16:59,580
که هیچ چیزی وجود ندارد که ما هیچ
488
00:16:59,580 –> 00:17:01,770
عددی نداریم l مقادیری برای مقابله یا هر
489
00:17:01,770 –> 00:17:03,240
مقدار عجیبی برخی از موارد دیگری که
490
00:17:03,240 –> 00:17:05,520
گاهی اوقات به آنها نگاه می کنید این است که اگر
491
00:17:05,520 –> 00:17:07,260
مقادیری مانند مقادیری دارید که خیلی
492
00:17:07,260 –> 00:17:09,000
از نمودار فاصله دارند، بنابراین ممکن است اندازه گیری
493
00:17:09,000 –> 00:17:11,069
خاموش باشد یا ترس از تجهیزات کالیبره شده را در
494
00:17:11,069 –> 00:17:13,500
زمینه علمی از دست بدهید. قدم بعدی که
495
00:17:13,500 –> 00:17:14,940
میخواهیم جلو برویم و انجام میدهیم این است که میخواهیم
496
00:17:14,940 –> 00:17:16,859
جلو برویم و مجموعه دادههایمان را جدا کنیم یا
497
00:17:16,859 –> 00:17:18,780
مجموعه دادههایمان را دوباره قالببندی کنیم و معمولاً از
498
00:17:18,780 –> 00:17:21,569
X بزرگ استفاده میکنیم و این نشاندهنده ویژگیهایی است
499
00:17:21,569 –> 00:17:23,099
که با آن کار میکنیم و معمولاً از
500
00:17:23,099 –> 00:17:26,040
Y کوچک که نشاندهنده آن است استفاده میکنیم. در این
501
00:17:26,040 –> 00:17:27,900
مورد کیفیت چیزی که ما به دنبال آن هستیم و
502
00:17:27,900 –> 00:17:29,970
میتوانیم آن را بگیریم، میتوانیم شراب را مصرف
503
00:17:29,970 –> 00:17:32,250
504
00:17:32,250 –> 00:17:33,960
505
00:17:33,960 –> 00:17:36,510
506
00:17:36,510 –> 00:17:38,760
کنیم. اگر محورهای ما
507
00:17:38,760 –> 00:17:40,680
برابر با 1 باشد، اگر آن را کنار گذاشته باشید،
508
00:17:40,680 –> 00:17:42,600
باز هم به درستی ظاهر میشود، فقط به
509
00:17:42,600 –> 00:17:45,390
دلیل روشی که در پیشفرضها پردازش میکند و
510
00:17:45,390 –> 00:17:46,300
پس
511
00:17:46,300 –> 00:17:49,210
چرا اگر میخواهیم کیفیت را
512
00:17:49,210 –> 00:17:52,030
برای X خود حذف کنیم، شراب خواهد بود و
513
00:17:52,030 –> 00:17:53,650
فقط کیفیتی که ما به آن نگاه می کنیم ng at
514
00:17:53,650 –> 00:17:56,020
برای Y بنابراین ما آن را در آنجا قرار می دهیم و ادامه می دهیم
515
00:17:56,020 –> 00:17:57,640
و این را اجرا می کنیم، بنابراین اکنون
516
00:17:57,640 –> 00:17:59,710
ویژگی هایی را که می خواهیم
517
00:17:59,710 –> 00:18:01,420
برای پیش بینی کیفیت شراب
518
00:18:01,420 –> 00:18:04,420
و خود کیفیت استفاده کنیم را از هم جدا
519
00:18:04,420 –> 00:18:06,970
کرده ایم. برای ایجاد یک مجموعه داده در
520
00:18:06,970 –> 00:18:08,320
یک مدل، ما میدانیم که مدل ما چقدر خوب
521
00:18:08,320 –> 00:18:10,030
است، بنابراین میخواهیم
522
00:18:10,030 –> 00:18:12,220
قطار داده را تقسیم کنیم و دادههای تقسیم را آزمایش کنیم و
523
00:18:12,220 –> 00:18:13,990
این یکی از بستههایی است که ما
524
00:18:13,990 –> 00:18:16,540
از SK Learn وارد کردیم و بسته واقعی بود.
525
00:18:16,540 –> 00:18:20,050
تقسیم تست آموزشدیده و ما میخواهیم
526
00:18:20,050 –> 00:18:23,200
اندازه تست XY نقطه دو حالت تصادفی 42 را انجام دهیم و
527
00:18:23,200 –> 00:18:25,420
این چهار متغیر را برمیگرداند و
528
00:18:25,420 –> 00:18:28,450
متداولترینی که میبینید قطار سرمایه X است، بنابراین
529
00:18:28,450 –> 00:18:30,430
ما مجموعه خود را با تست بزرگ X آموزش میدهیم
530
00:18:30,430 –> 00:18:32,230
که دادههای ما است.
531
00:18:32,230 –> 00:18:35,050
میخواهم آن را امتحان کنم چرا قطار چرا
532
00:18:35,050 –> 00:18:36,910
به خاطر میآورم مخفف کیفیت یا
533
00:18:36,910 –> 00:18:38,260
پاسخی است که ما به دنبال آن هستیم،
534
00:18:38,260 –> 00:18:40,210
بنابراین وقتی آن را آموزش میدهیم از قطار X
535
00:18:40,210 –> 00:18:42,820
و چرا قطار استفاده میکنیم و سپس Y را تست میکنیم تا
536
00:18:42,820 –> 00:18:45,100
ببینیم چقدر خوب است. تست X ما انجام میشود و
537
00:18:45,100 –> 00:18:47,230
تقسیم تست قطار به من اجازه
538
00:18:47,230 –> 00:18:49,480
میدهد به بالای صفحه که بخشی از SK
539
00:18:49,480 –> 00:18:53,350
Learn mo بود برگردم. del Selection Import Train Test
540
00:18:53,350 –> 00:18:56,830
Split راههای زیادی برای تقسیم دادهها وجود دارد،
541
00:18:56,830 –> 00:18:59,260
این اولین شروع شماست که اولین مدل خود را انجام
542
00:18:59,260 –> 00:19:00,790
میدهید، احتمالاً با
543
00:19:00,790 –> 00:19:02,950
اصول اولیه شروع میکنید، شما یک تست برای
544
00:19:02,950 –> 00:19:05,290
آموزش دارید، یکی برای تست اندازه آزمون ما
545
00:19:05,290 –> 00:19:08,650
0.2 یا 20 است. ٪ و مرحله تصادفی فقط به این معنی است
546
00:19:08,650 –> 00:19:10,180
که ما فقط با یک عدد شروع می کنیم مانند یک عدد دانه تصادفی،
547
00:19:10,180 –> 00:19:12,070
بنابراین خیلی مهم نیست
548
00:19:12,070 –> 00:19:12,670
در
549
00:19:12,670 –> 00:19:14,080
آنجا به طور تصادفی انتخاب می
550
00:19:14,080 –> 00:19:16,150
کنیم که کدام یک را استفاده کنیم زیرا این
551
00:19:16,150 –> 00:19:18,040
رایج ترین روش است.
552
00:19:18,040 –> 00:19:20,590
استفاده از امروز وجود دارد و هنوز حتی یک
553
00:19:20,590 –> 00:19:22,480
مقیاسکننده و بسته نیست، بنابراین کسی
554
00:19:22,480 –> 00:19:24,220
هنوز آن را در آنجا قرار میدهد یکی از کارهای جدیدی
555
00:19:24,220 –> 00:19:26,410
که انجام میدهند این است که دادهها
556
00:19:26,410 –> 00:19:28,660
را به یک سوم تقسیم میکنند و سپس
557
00:19:28,660 –> 00:19:31,120
مدل را روی هر یک از آنها اجرا میکنند.
558
00:19:31,120 –> 00:19:33,820
این یک سوم به دو سوم برای
559
00:19:33,820 –> 00:19:36,160
آموزش و یک سوم برای آزمایش و بنابراین شما
560
00:19:36,160 –> 00:19:37,870
در واقع تمام داده ها را مرور می کنید
561
00:19:37,870 –> 00:19:39,340
و به سه نتیجه آزمایش مختلف
562
00:19:39,340 –> 00:19:41,080
از آن می رسید که بسیار جالب است
563
00:19:41,080 –> 00:19:42,640
که روش بسیار جالبی برای انجام آن است که
564
00:19:42,640 –> 00:19:44,170
در واقع می توانید این کار را با این انجام دهید. فقط توسط
565
00:19:44,170 –> 00:19:47,530
اگر این را به یک سوم تقسیم کنید و سپس
566
00:19:47,530 –> 00:19:49,480
یک قسمت تست یک مجموعه تست
567
00:19:49,480 –> 00:19:51,040
سوم خواهید داشت و سپس مجموعه آموزشی را
568
00:19:51,040 –> 00:19:52,990
نیز به یک سوم تقسیم کنید و همچنین این کار را انجام دهید
569
00:19:52,990 –> 00:19:54,640
و سه مجموعه داده مختلف دریافت کنید که
570
00:19:54,640 –> 00:19:56,800
برای اکثر پروژه ها به خوبی کار می کند، به خصوص زمانی
571
00:19:56,800 –> 00:19:58,720
که در حال شروع هستید. عالی کار می کند، بنابراین
572
00:19:58,720 –> 00:19:59,240
573
00:19:59,240 –> 00:20:01,460
ما در تست Y خود قطار X یا تست X یا قطار سفید خود را داریم
574
00:20:01,460 –> 00:20:04,610
و سپس باید پیش برویم و مقیاس کننده را
575
00:20:04,610 –> 00:20:06,650
انجام دهیم و بیایید در مورد این صحبت کنیم
576
00:20:06,650 –> 00:20:08,540
زیرا این واقعا مهم است که
577
00:20:08,540 –> 00:20:11,750
برخی از مدل ها نیازی به مقیاس بندی ندارند.
578
00:20:11,750 –> 00:20:14,809
اکثر مدلها این کار را انجام میدهند و بنابراین ما
579
00:20:14,809 –> 00:20:16,580
متغیر اسکالر خود را ایجاد میکنیم، آن را
580
00:20:16,580 –> 00:20:19,340
مقیاسکننده استاندارد SC مینامیم و اگر درست میگویید،
581
00:20:19,340 –> 00:20:21,500
در اینجا با
582
00:20:21,500 –> 00:20:24,200
رمزگذار برچسب، تنظیم مقیاسکننده استاندارد اشتباه وارد کردهایم،
583
00:20:24,200 –> 00:20:26,690
بنابراین اسکالر ما وجود دارد و این
584
00:20:26,690 –> 00:20:28,760
مقادیر را بهجای تبدیل میکند. با داشتن
585
00:20:28,760 –> 00:20:31,040
مقادیری که از صفر میروند، اگر
586
00:20:31,040 –> 00:20:32,929
به یاد داشته باشید در اینجا مقادیری
587
00:20:32,929 –> 00:20:36,470
پنجاه و چهار شصت و چهل و پنجاه 902 داشتیم، بنابراین
588
00:20:36,470 –> 00:20:38,720
کل دی اکسید گوگرد ما این
589
00:20:38,720 –> 00:20:41,330
مقادیر عظیم را به مدل ما خواهد داشت و
590
00:20:41,330 –> 00:20:42,679
برخی از مدلها به آن نگاه میکنند.
591
00:20:42,679 –> 00:20:44,420
آنها نسبت به دی اکسید گوگرد بسیار متمایل می شوند
592
00:20:44,420 –> 00:20:46,550
و بیشترین تأثیر را دارند و
593
00:20:46,550 –> 00:20:49,640
سپس مقداری که نقطه اوه هفت شش
594
00:20:49,640 –> 00:20:51,770
نقطه صفر نه هشت یا کلرید داشته
595
00:20:51,770 –> 00:20:53,660
باشد تأثیر بسیار کمی خواهد داشت زیرا این
596
00:20:53,660 –> 00:20:55,580
عدد بسیار کوچک است بنابراین
597
00:20:55,580 –> 00:20:57,350
ما اسکالر را که به نوعی زمین بازی را همسطح کنید
598
00:20:57,350 –> 00:20:59,570
و بسته به مقیاسکننده ما
599
00:20:59,570 –> 00:21:02,059
آن را بین صفر و یک تنظیم میکند، خیلی
600
00:21:02,059 –> 00:21:03,800
وقتها کاری که انجام میدهد، بیایید جلو برویم و
601
00:21:03,800 –> 00:21:05,360
نگاهی به آن بیندازیم و ما جلوتر میرویم
602
00:21:05,360 –> 00:21:08,059
و با قطار X و قطار X خود شروع میکنیم.
603
00:21:08,059 –> 00:21:11,750
برابر با تبدیل فیت SC
604
00:21:11,750 –> 00:21:13,460
که قبلاً در مورد آن صحبت کردیم، این یک راهاندازی یادگیری SK
605
00:21:13,460 –> 00:21:15,700
است که هم متناسب است و هم
606
00:21:15,700 –> 00:21:19,220
قطار X ما را به متغیر X train ما تبدیل میکند
607
00:21:19,220 –> 00:21:21,650
و اگر فشار گردن داریم،
608
00:21:21,650 –> 00:21:24,260
باید این کار را برای آزمایش خود انجام دهیم و
609
00:21:24,260 –> 00:21:26,809
این مهم است. زیرا باید
610
00:21:26,809 –> 00:21:28,670
توجه داشته باشید که نمیخواهید
611
00:21:28,670 –> 00:21:30,650
دادههایی را که میخواهیم از همان تناسبی که
612
00:21:30,650 –> 00:21:32,179
در آموزش استفاده کردهایم در تست استفاده کنیم، در
613
00:21:32,179 –> 00:21:34,010
غیر این صورت نتایج متفاوتی دریافت میکنید و
614
00:21:34,010 –> 00:21:37,490
بنابراین ما فقط امیدواریم که تغییر مناسبی نداشته
615
00:21:37,490 –> 00:21:39,650
باشیم. فقط
616
00:21:39,650 –> 00:21:41,990
سمت آزمون را تغییر می دهد دادهها، بنابراین این تست X ما است
617
00:21:41,990 –> 00:21:44,030
که میخواهیم آن را تبدیل کنیم و بیایید ادامه دهیم
618
00:21:44,030 –> 00:21:46,340
و آن را اجرا کنیم و فقط برای این که ایدهای داشته باشیم،
619
00:21:46,340 –> 00:21:48,290
بیایید ادامه دهیم و
620
00:21:48,290 –> 00:21:52,010
قطار X خود را چاپ کنیم، بیایید
621
00:21:52,010 –> 00:21:54,260
ده متغیر اول را بسیار شبیه به روش شما
622
00:21:54,260 –> 00:21:56,630
انجام دهیم در
623
00:21:56,630 –> 00:21:59,540
اینجا میتوانید ببینید که متغیرهای ما اکنون بسیار
624
00:21:59,540 –> 00:22:01,670
یکنواختتر هستند و آنها را در یک مقیاس کوچک کردهاند،
625
00:22:01,670 –> 00:22:03,740
بنابراین بین اعداد خاصی قرار میگیرند
626
00:22:03,740 –> 00:22:06,260
و با مقیاسکننده اصلی
627
00:22:06,260 –> 00:22:08,450
میتوانید آن را دقیق تنظیم کنید.
628
00:22:08,450 –> 00:22:10,460
پیشفرض در این مورد است و این برای
629
00:22:10,460 –> 00:22:11,170
کاری که ما انجام میدهیم خوب است
630
00:22:11,170 –> 00:22:12,670
در بیشتر موارد، واقعاً
631
00:22:12,670 –> 00:22:14,350
نیازی نیست که زیاد با آن سر و کار داشته باشید، به نظر نمیرسد
632
00:22:14,350 –> 00:22:17,980
بین – احتمالا – 2
633
00:22:17,980 –> 00:22:20,620
– 2 یا چیزی شبیه به آن که فق




![فیلم آموزشی: آدم برفی [4.3.6 یا 2.13.6] [Python] [CodeHS] [توضیح داده شده] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/VaFUhziXVZkimage2.jpg)