در این مطلب، ویدئو استفاده از پایتون برای تخمین توابع چگالی احتمال با نمونه گیری با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,680 –> 00:00:02,550
بابت تکمیل آخرین
2
00:00:02,550 –> 00:00:05,190
تمرینها در مورد تولید
3
00:00:05,190 –> 00:00:08,069
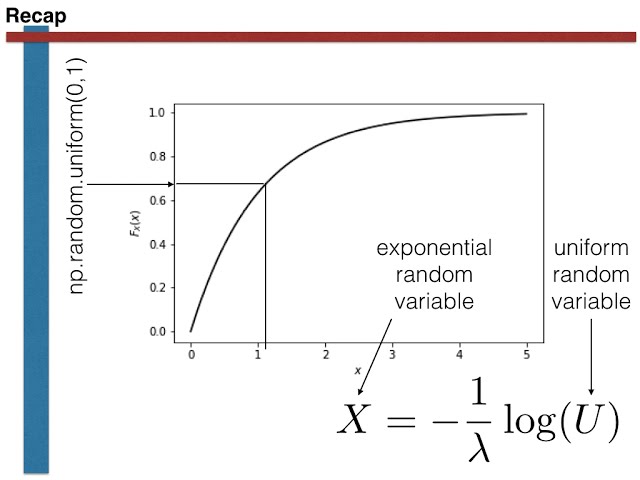
متغیرهای تصادفی نمایی تبریک میگویم، اکنون فقط یک
4
00:00:08,069 –> 00:00:09,870
کار دیگر برای تکمیل کردن دارید و سپس
5
00:00:09,870 –> 00:00:11,880
آماده خواهید بود که اولین
6
00:00:11,880 –> 00:00:14,639
تکلیف ماژول را قبل از اینکه وارد آن شویم، انجام
7
00:00:14,639 –> 00:00:17,279
دهید، اما اجازه دهید ابتدا به طور خلاصه کارهایی را
8
00:00:17,279 –> 00:00:18,900
که به ترتیب انجام دادهاید مرور کنیم. برای تکمیل آخرین
9
00:00:18,900 –> 00:00:22,529
کار در آخرین کار که یاد گرفتید چگونه
10
00:00:22,529 –> 00:00:24,750
متغیرهای تصادفی نمایی تولید
11
00:00:24,750 –> 00:00:27,330
کنید، الگوریتمی که برای تکمیل
12
00:00:27,330 –> 00:00:29,880
این کار نوشتید با تولید یک
13
00:00:29,880 –> 00:00:32,040
متغیر تصادفی یکنواخت با استفاده از
14
00:00:32,040 –> 00:00:35,610
ابزارهای آشنا از غیر p کار می کند، سپس ادعا می کنیم که
15
00:00:35,610 –> 00:00:38,160
مقدار متغیر تصادفی یکنواخت
16
00:00:38,160 –> 00:00:40,649
یک مقدار از تابع
17
00:00:40,649 –> 00:00:42,420
توزیع احتمال تجمعی برای
18
00:00:42,420 –> 00:00:44,670
مقدار خاص متغیر تصادفی نمایی شما
19
00:00:44,670 –> 00:00:47,820
به دست میآید، بنابراین میتوانیم به
20
00:00:47,820 –> 00:00:49,469
سادگی مقدار متغیر تصادفی نمایی را
21
00:00:49,469 –> 00:00:52,140
با استفاده از تابع معکوس گرفته
22
00:00:52,140 –> 00:00:54,210
برای آن تابع توزیع احتمال تجمعی Remini بخوانیم.
23
00:00:54,210 –> 00:00:57,680
برای
24
00:00:57,680 –> 00:01:00,539
حالت خاص یک
25
00:01:00,539 –> 00:01:02,489
متغیر تصادفی نمایی معکوس خاص
26
00:01:02,489 –> 00:01:04,140
تابعی که استفاده کردید با
27
00:01:04,140 –> 00:01:05,880
عبارت نشان داده شده در پایین
28
00:01:05,880 –> 00:01:09,450
اسلاید در این عبارت داده می شود U
29
00:01:09,450 –> 00:01:11,189
متغیر تصادفی یکنواختی است که
30
00:01:11,189 –> 00:01:14,430
با استفاده از numpy ایجاد می کنید و X
31
00:01:14,430 –> 00:01:16,049
مقدار نهایی متغیر تصادفی نمایی شما
32
00:01:16,049 –> 00:01:24,119
در این ویدیوی نهایی است که می خواهیم
33
00:01:24,119 –> 00:01:25,979
روی آن تمرکز کنیم. نوع نهایی
34
00:01:25,979 –> 00:01:27,780
متغیر تصادفی که ممکن است به
35
00:01:27,780 –> 00:01:31,110
یک متغیر تصادفی معمولی علاقه مند باشیم، می توانید
36
00:01:31,110 –> 00:01:33,180
با
37
00:01:33,180 –> 00:01:35,100
استفاده از الگوریتمی که مشابه
38
00:01:35,100 –> 00:01:37,170
آنچه که برای متغیر تصادفی نمایی توضیح دادم، متغیرهای تصادفی معمولی تولید کنید و
39
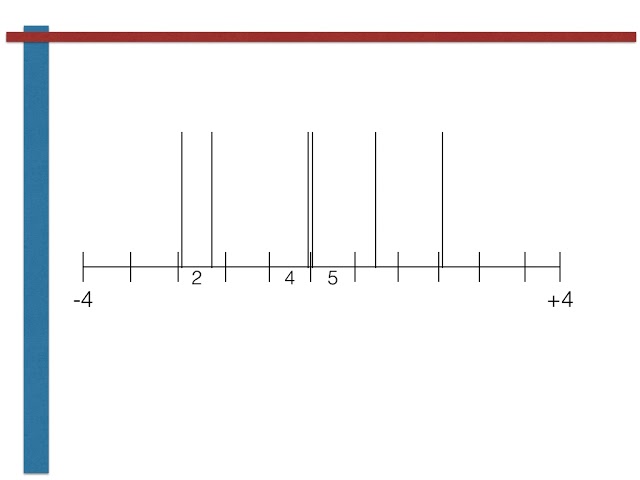
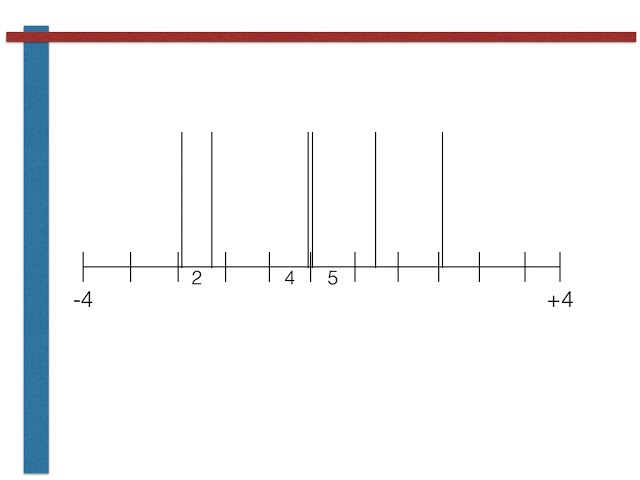
00:01:37,170 –> 00:01:39,570
با تولید چند
40
00:01:39,570 –> 00:01:41,340
متغیر تصادفی یکنواخت و سپس
41
00:01:41,340 –> 00:01:42,810
تبدیل آنها به برای بدست آوردن یک
42
00:01:42,810 –> 00:01:46,020
توزیع نرمال، این الگوریتم
43
00:01:46,020 –> 00:01:47,729
برخلاف الگوریتمهایی که برای تولید
44
00:01:47,729 –> 00:01:49,290
انواع متغیرهای تصادفی دیگر دیدهایم،
45
00:01:49,290 –> 00:01:51,869
از ریاضیات استفاده میکند که واقعاً
46
00:01:51,869 –> 00:01:53,850
با موضوع این ماژول مماس است و بنابراین
47
00:01:53,850 –> 00:01:56,909
من نمیخواهم آن را در اینجا آموزش دهم و
48
00:01:56,909 –> 00:01:58,619
بنابراین پیشنهاد میکنم. که از
49
00:01:58,619 –> 00:02:01,140
تابع ذاتی دیگری از numpy برای
50
00:02:01,140 –> 00:02:02,579
تولید متغیرهای تصادفی معمولی استاندارد خود
51
00:02:02,579 –> 00:02:06,180
استفاده می کنید، این تابع با استفاده از کد نامیده می شود.
52
00:02:06,180 –> 00:02:09,119
e در اینجا نشان داده شده است، این
53
00:02:09,119 –> 00:02:10,800
کد یک متغیر تصادفی معمولی استاندارد را
54
00:02:10,800 –> 00:02:13,020
از توزیعی
55
00:02:13,020 –> 00:02:13,819
که در این اسلاید جدول نشان داده شده است،
56
00:02:13,819 –> 00:02:16,760
برای شما ایجاد می کند، یعنی یک
57
00:02:16,760 –> 00:02:18,409
متغیر تصادفی معمولی از
58
00:02:18,409 –> 00:02:20,480
توزیعی که انتظار
59
00:02:20,480 –> 00:02:24,799
0 و واریانس 1 را دارد، اگر برعکس شما تولید کند
60
00:02:24,799 –> 00:02:26,269
می خواهید یک متغیر تصادفی از یک
61
00:02:26,269 –> 00:02:28,069
توزیع نرمال با
62
00:02:28,069 –> 00:02:30,620
انتظار mu و واریانس مجذور سیگما داشته
63
00:02:30,620 –> 00:02:32,689
باشید، به سادگی یک متغیر تصادفی معمولی استاندارد را
64
00:02:32,689 –> 00:02:34,609
که با استفاده
65
00:02:34,609 –> 00:02:36,950
از کد بالا تولید می شود، قرار داده و آن را همانطور که
66
00:02:36,950 –> 00:02:45,859
در پایین این اسلاید با استفاده از تصادفی NP نشان داده شده است، تبدیل کنید.
67
00:02:45,859 –> 00:02:47,840
تابع نرمال نسبتاً
68
00:02:47,840 –> 00:02:50,060
آسان است، بنابراین هیچ وظیفه ای وجود ندارد که به سادگی
69
00:02:50,060 –> 00:02:51,340
آزمایش کند که می توانید از این تابع استفاده کنید،
70
00:02:51,340 –> 00:02:54,879
چنین وظیفه ای در حال حاضر زیر نظر شما خواهد بود، در
71
00:02:54,879 –> 00:02:58,159
عوض از شما می خواهد
72
00:02:58,159 –> 00:02:59,629
که تخمینی از تابع چگالی احتمال را
73
00:02:59,629 –> 00:03:02,000
برای یک
74
00:03:02,000 –> 00:03:04,189
متغیر تصادفی معمولی استاندارد محاسبه کنید. گرفتن تعداد
75
00:03:04,189 –> 00:03:06,430
زیادی نمونه و تخمین هیستوگرام
76
00:03:06,430 –> 00:03:09,230
این کار مشابه دو کار اول
77
00:03:09,230 –> 00:03:11,510
در این تمرین است اما
78
00:03:11,510 –> 00:03:14,180
چند کار ظریف وجود دارد. در اینجا به مشکلاتی می پردازیم، اما
79
00:03:14,180 –> 00:03:15,620
در ادامه این
80
00:03:15,620 –> 00:03:17,810
ویدیو به آنها خواهیم پرداخت، زیرا اکنون می خوانیم
81
00:03:17,810 –> 00:03:19,159
که با یک متغیر تصادفی پیوسته سر و کار
82
00:03:19,159 –> 00:03:23,780
داریم، اولین مورد از این مسائل این است
83
00:03:23,780 –> 00:03:25,759
که توزیع نرمال استاندارد
84
00:03:25,759 –> 00:03:28,189
پشتیبانی بی نهایت دارد، به این معنا که
85
00:03:28,189 –> 00:03:30,229
متغیر تصادفی می تواند طول بکشد. هر مقدار در
86
00:03:30,229 –> 00:03:32,569
محور واقعی بین منهای بینهایت و
87
00:03:32,569 –> 00:03:36,139
بعلاوه بینهایت حل کردن این مشکل آسان است،
88
00:03:36,139 –> 00:03:38,090
اما وقتی به یاد بیاوریم که
89
00:03:38,090 –> 00:03:39,620
شکل حالت تابع چگالی احتمالی
90
00:03:39,620 –> 00:03:41,569
که از آن نمونهبرداری میکنیم،
91
00:03:41,569 –> 00:03:43,659
چیزی شبیه به این خواهد بود.
92
00:03:43,659 –> 00:03:46,250
این شکل تضمین میکند که احتمال کمی وجود دارد یا
93
00:03:46,250 –> 00:03:47,599
اصلا با توجه به
94
00:03:47,599 –> 00:03:49,099
اینکه مقداری در انتهای
95
00:03:49,099 –> 00:03:52,459
توزیع به دست میآید، میتوانیم
96
00:03:52,459 –> 00:03:53,900
محدوده مقادیری را که متغیر تصادفی
97
00:03:53,900 –> 00:03:56,930
ممکن است بین منهای 4 و به علاوه 4 بگیرد، کوتاه کنیم، همانطور
98
00:03:56,930 –> 00:04:02,479
که در اینجا نشان داده شده است، هنوز مشکل وجود دارد،
99
00:04:02,479 –> 00:04:04,639
اما از آنجایی که متغیر تصادفی میتواند هر چیزی را بگیرد.
100
00:04:04,639 –> 00:04:07,519
مقدار واقعی در این محدوده و به
101
00:04:07,519 –> 00:04:09,049
این دلیل که تعداد نامتناهی اعداد واقعی
102
00:04:09,049 –> 00:04:12,289
در این محدوده وجود دارد، در نتیجه اگر
103
00:04:12,289 –> 00:04:14,030
بخواهیم تعداد دفعات هر تصادف را بشماریم.
104
00:04:14,030 –> 00:04:16,070
زمانی که ما در حال
105
00:04:16,070 –> 00:04:17,358
محاسبه هیستوگرامها برای
106
00:04:17,358 –> 00:04:19,339
توزیعهای برنولی و چندجملهای
107
00:04:19,339 –> 00:04:21,680
بودیم، متغیر ظاهر شد، در نهایت به توزیعی رسیدیم که
108
00:04:21,680 –> 00:04:23,990
دارای توابع دلتا متمرکز بر روی هر یک از
109
00:04:23,990 –> 00:04:26,990
مقادیر نمونه ما بود، چیزی شبیه به
110
00:04:26,990 –> 00:04:30,000
این که هیچ عدد واقعی را بیشتر از آن نمیبینیم.
111
00:04:30,000 –> 00:04:32,490
یک بار و بدتر از آن،
112
00:04:32,490 –> 00:04:34,590
113
00:04:34,590 –> 00:04:36,480
برای شمارش تعداد دفعاتی که هر یک از
114
00:04:36,480 –> 00:04:38,280
اعداد حقیقی بی نهایت در نمونه های ما ظاهر شده اند، باید یک لیست بی نهایت طولانی داشته باشیم،
115
00:04:38,280 –> 00:04:42,180
بدیهی است که ما این کار را انجام نمی
116
00:04:42,180 –> 00:04:44,580
دهیم، در عوض، محدوده خود
117
00:04:44,580 –> 00:04:46,710
را به تعداد گسسته ای از بازه ها تقسیم می کنیم. برای مثالی که در اینجا نشان داده شده است
118
00:04:46,710 –> 00:04:48,960
، شمارش می کنم که
119
00:04:48,960 –> 00:04:51,690
در هر یک از این محدوده ها چند نمونه
120
00:04:51,690 –> 00:04:52,440
وجود دارد،
121
00:04:52,440 –> 00:04:54,870
بنابراین ما دو نمونه در این محدوده دوم داریم
122
00:04:54,870 –> 00:04:57,990
یا یک نمونه در سطل چهارم،
123
00:04:57,990 –> 00:05:00,480
یک نمونه در سطل پنجم، یک بار
124
00:05:00,480 –> 00:05:02,670
برزنت در سطل ششم و یک نمونه داریم.
125
00:05:02,670 –> 00:05:07,080
در سطل هشتم این به اندازه کافی آسان به نظر می رسد،
126
00:05:07,080 –> 00:05:09,060
اما بیایید ببینیم یک
127
00:05:09,060 –> 00:05:11,160
برنامه کامپیوتری مقایسه ای این کار را انجام می دهد که
128
00:05:11,160 –> 00:05:13,050
این نوع محاسبات را انجام می دهد و
129
00:05:13,050 –> 00:05:19,500
تمرین اینجا کد کامل محاسبه است.
130
00:05:19,500 –> 00:05:21,270
یک هیستوگرام را با
131
00:05:21,270 –> 00:05:23,270
نمونه برداری از یک متغیر تصادفی معمولی
132
00:05:23,27