در این مطلب، ویدئو تحلیل بیزی در پایتون: کیت شروع با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
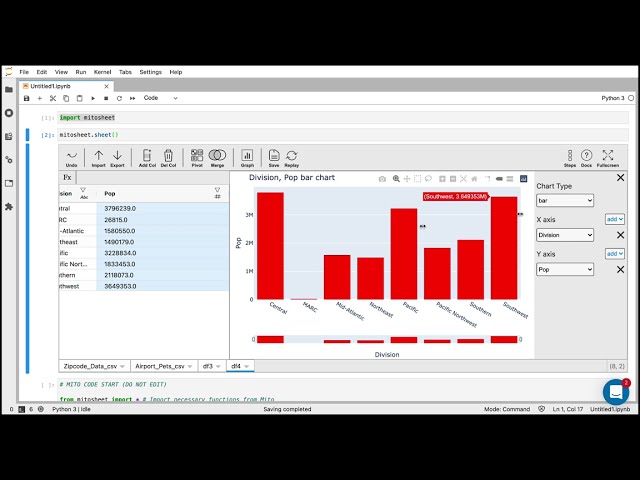
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,530 –> 00:00:04,470
واقعیت واقعاً پیچیده است
2
00:00:04,470 –> 00:00:09,320
و وظیفه ما بهعنوان تحلیلگران و
3
00:00:09,320 –> 00:00:13,410
دانشمندان این است که مدلهایی بسازیم که به ما در
4
00:00:13,410 –> 00:00:17,539
درک واقعیت و توضیح آن کمک کند،
5
00:00:17,539 –> 00:00:21,300
و من امروز یک کلمه بسیار ملایم
6
00:00:21,300 –> 00:00:23,189
و ملایم
7
00:00:23,189 –> 00:00:26,609
مقدمهای برای تحلیل بیزی
8
00:00:26,609 –> 00:00:28,859
و دفترچههای یادداشتی ارائه خواهم کرد. به اشتراک گذاشتن
9
00:00:28,859 –> 00:00:30,240
با شما اساساً چیزهایی هستند که
10
00:00:30,240 –> 00:00:32,668
من در زمانی که این
11
00:00:32,668 –> 00:00:36,360
چیزها را برای خودم کشف می کردم مونتاژ کردم،
12
00:00:36,360 –> 00:00:40,700
بنابراین از آنجایی که چیزی که می خواهم در مورد آن صحبت کنم
13
00:00:40,700 –> 00:00:45,180
تا حد زیادی حول مدل های ساختمان می چرخد،
14
00:00:45,180 –> 00:00:47,280
برای من عاقلانه به نظر می رسد که
15
00:00:47,280 –> 00:00:49,079
ابتدا بفهمم چگونه من ماوس کار می
16
00:00:49,079 –> 00:00:53,640
کند بله، اوه-هه،
17
00:00:53,640 –> 00:00:58,410
خوب، پیشرفت اشکالی ندارد، بنابراین از آنجایی
18
00:00:58,410 –> 00:00:59,760
که می خواهم در مورد مدل ها صحبت کنم،
19
00:00:59,760 –> 00:01:01,620
به نظر عاقلانه است که فقط یک
20
00:01:01,620 –> 00:01:03,570
قدم به عقب برگردیم و دقیقاً در مورد اینکه یک
21
00:01:03,570 –> 00:01:06,270
مدل واقعاً چیست صحبت کنیم و یک
22
00:01:06,270 –> 00:01:09,210
نقل قول بسیار معروف وجود دارد. توسط این آماردان برجسته بریتانیایی
23
00:01:09,210 –> 00:01:11,580
جورج باکس و همانطور که او می گوید
24
00:01:11,580 –> 00:01:14,460
همه مدل ها اشتباه هستند، اما برخی از آنها مفید هستند،
25
00:01:14,460 –> 00:01:19,979
بنابراین اگر چه مدل هایی اشتباه هستند، چرا
26
00:01:19,979 –> 00:01:21,450
ما علاقه مند هستیم چرا
27
00:01:21,450 –> 00:01:23,009
مدل های ساختمان را به خوبی در نظر بگیریم.
28
00:01:23,009 –> 00:01:25,170
چند دلیل برای آن وجود دارد که اولی به
29
00:01:25,170 –> 00:01:27,210
دست آوردن درک من برای
30
00:01:27,210 –> 00:01:30,150
بازجویی از یک سیستم است، دیگری این است
31
00:01:30,150 –> 00:01:33,780
که مفروضات و فرضیات خود را آزمایش کنیم و
32
00:01:33,780 –> 00:01:37,280
در نهایت برخی از پیشبینیها را انجام دهیم،
33
00:01:37,280 –> 00:01:41,549
بنابراین یک مدل درست است، این
34
00:01:41,549 –> 00:01:44,189
یک نوع است. تقریب به یک
35
00:01:44,189 –> 00:01:48,750
سیستم و به طور کلی مجموعه ای
36
00:01:48,750 –> 00:01:51,450
از مفروضات را در بر می گیرد که این مفروضات ممکن
37
00:01:51,450 –> 00:01:55,049
است دقیق باشند یا نباشند و معمولاً
38
00:01:55,049 –> 00:01:56,460
در نوعی چارچوب ریاضی فرموله می شود
39
00:01:56,460 –> 00:01:58,770
و آن
40
00:01:58,770 –> 00:02:02,040
چارچوب دارای برخی پارامترها است و این
41
00:02:02,040 –> 00:02:04,229
نقش به عنوان یک تحلیلگر است که این
42
00:02:04,229 –> 00:02:06,329
مدل را انتخاب کند. به دست آوردن مناسب ترین
43
00:02:06,329 –> 00:02:09,030
مقادیر برای آن پارامترها، این
44
00:02:09,030 –> 00:02:11,430
پارامترها همچنین به این معنی هستند که یک مدل واحد را
45
00:02:11,430 –> 00:02:13,319
می توان برای
46
00:02:13,319 –> 00:02:15,030
سیستم های مختلف اعمال کرد، به عنوان مثال یک
47
00:02:15,030 –> 00:02:17,489
توزیع دوجمله ای، یک مدل آماری بسیار استاندارد را
48
00:02:17,489 –> 00:02:19,739
می توان برای
49
00:02:19,739 –> 00:02:21,510
انداختن یک تاس یا چرخاندن یک
50
00:02:21,510 –> 00:02:23,930
سکه و به طور مشابه اعمال کرد. یک چاه توزیع نرمال
51
00:02:23,930 –> 00:02:25,889
می تواند برای
52
00:02:25,889 –> 00:02:28,709
اندازه گیری ارتفاع و جرم نیز اعمال شود،
53
00:02:28,709 –> 00:02:30,659
فقط یک سوال انتخاب پارامتر مناسب است.
54
00:02:30,659 –> 00:02:35,189
برای مدل خوب است، پس چگونه
55
00:02:35,189 –> 00:02:37,230
میتوانیم
56
00:02:37,230 –> 00:02:39,419
مقادیر صحیح یا مناسب را برای این
57
00:02:39,419 –> 00:02:41,099
پارامترها هدایت کنیم، اکنون آنها دو نوع
58
00:02:41,099 –> 00:02:43,499
مدرسه رقیب هستند برای اینکه چگونه
59
00:02:43,499 –> 00:02:46,230
میتوان به این موضوع رفت.
60
00:02:46,230 –> 00:02:47,909
“رویکرد عادی
61
00:02:47,909 –> 00:02:51,000
است و بله، این یک دو
62
00:02:51,000 –> 00:02:52,769
ویژگی است اساساً اگر
63
00:02:52,769 –> 00:02:54,419
میتوانید رویکرد مکرر را
64
00:02:54,419 –> 00:02:57,510
برای تطبیق یک مدل اتخاذ کنید،
65
00:02:57,510 –> 00:02:58,829
اساساً با انتخاب نوعی
66
00:02:58,829 –> 00:03:01,040
آزمون فرضیه از این
67
00:03:01,040 –> 00:03:03,989
جنگل عظیم پیچیده از آزمایشهای ممکن شروع میکنید و
68
00:03:03,989 –> 00:03:06,989
این نقطه اولیه ای که می
69
00:03:06,989 –> 00:03:09,030
توانید با کمی چسبندگی مواجه شوید زیرا مگر
70
00:03:09,030 –> 00:03:11,159
اینکه دکترای آمار داشته باشید یا
71
00:03:11,159 –> 00:03:12,540
مشکلی که روی آن کار می کنید بسیار
72
00:03:12,540 –> 00:03:15,359
ساده باشد، انتخاب آزمون مناسب
73
00:03:15,359 –> 00:03:17,780
رئیس ما می تواند یک چالش واقعی باشد،
74
00:03:17,780 –> 00:03:20,819
پس این آزمون فرضیه نیز به طور کلی
75
00:03:20,819 –> 00:03:22,319
باعث ایجاد یک مشکل می شود. مجموعه کاملی از مفروضات و
76
00:03:22,319 –> 00:03:24,659
یکی از آنها این است که آنها به طور کلی
77
00:03:24,659 –> 00:03:27,060
فقط در حد مجانبی معتبر هستند و این
78
00:03:27,060 –> 00:03:28,919
بدان معنا نیست که شما به حجم زیادی از داده ها نیاز دارید
79
00:03:28,919 –> 00:03:31,409
تا آنها عمل کنند. واقعاً خوب کار میکند
80
00:03:31,409 –> 00:03:34,470
و وقتی واقعاً
81
00:03:34,470 –> 00:03:36,629
آزمایش فرآیندها را اعمال میکنید، به این نتیجه
82
00:03:36,629 –> 00:03:38,549
میرسید که عموماً به مقدار p خلاصه میشود
83
00:03:38,549 –> 00:03:41,250
و این مقدار p به خوبی
84
00:03:41,250 –> 00:03:43,439
منشأ رسواییهای علمی متعددی بوده است
85
00:03:43,439 –> 00:03:45,540
، چرا که
86
00:03:45,540 –> 00:03:48,419
تفسیر p -value بسیار مشکل است و توضیح آن
87
00:03:48,419 –> 00:03:50,790
واقعاً دشوار است و
88
00:03:50,790 –> 00:03:52,889
علاوه بر همه اینها،
89
00:03:52,889 –> 00:03:54,329
شما این نوع
90
00:03:54,329 –> 00:03:56,489
آستانه های دلخواه پنج درصد یک درصد را دارید و
91
00:03:56,489 –> 00:03:58,680
اگر مقدار p شما کمتر از یک یا
92
00:03:58,680 –> 00:04:00,569
دیگری باشد، می توانید نتایج را بپذیرید یا
93
00:04:00,569 –> 00:04:02,370
آنها را رد کنید، این همه چیز است،
94
00:04:02,370 –> 00:04:04,259
تعریف بسیار پیچیده است و
95
00:04:04,259 –> 00:04:07,259
کمی پرخاشگر است، خوب است، من قصد
96
00:04:07,259 –> 00:04:09,689
ندارم رویکرد مکرر را زیر پا بگذارم،
97
00:04:09,689 –> 00:04:11,129
فقط میخواهم به این نکته اشاره کنم که چالشهای بزرگی وجود دارد، اما در
98
00:04:11,129 –> 00:04:13,319
99
00:04:13,319 –> 00:04:15,269
طرف مقابل شما تکنیکهای بیزی
100
00:04:15,269 –> 00:04:17,430
را داشته باشید که به همان اندازه پیچیده
101
00:04:17,430 –> 00:04:19,199
هستند، اما شاید
102
00:04:19,199 –> 00:04:21,779
برای شروع کمی انعطافپذیرتر باشند، میتوانید با خیال راحت
103
00:04:21,779 –> 00:04:23,550
تکنیکهای بیزی خود را در یک نمونه کوچک به کار ببرید،
104
00:04:23,550 –> 00:04:26,840
آنها بسیار انعطافپذیر هستند.
105
00:04:26,840 –> 00:04:29,060
و نتایجی که از
106
00:04:29,060 –> 00:04:31,130
تجزیه و تحلیل بیزی انیمه به دست میآورید آسانتر
107
00:04:31,130 –> 00:04:33,110
توضیح داده میشوند، مثل اینکه میدانید
108
00:04:33,110 –> 00:04:35,650
با چیزی که مردم
109
00:04:35,650 –> 00:04:41,750
تصور میکنند آمار به معنای خوب است، سازگارتر است، بنابراین
110
00:04:41,750 –> 00:04:42,919
برای لحظهای تصور میکنیم که ما به آن
111
00:04:42,919 –> 00:04:44,510
پشت میکنیم. رویکرد مکرر گرا
112
00:04:44,510 –> 00:04:47,900
و شروع به انجام تحلیل بیزی از کجا
113
00:04:47,900 –> 00:04:49,790
همه اینها به خوبی شروع می شود، به نوعی
114
00:04:49,790 –> 00:04:51,979
کار پشت همه اینها
115
00:04:51,979 –> 00:04:55,220
قاعده یا قانون یا قضیه بیز است و این
116
00:04:55,220 –> 00:04:57,860
چیزی است که به نظر می رسد و من فقط
117
00:04:57,860 –> 00:04:59,389
به طور خلاصه در مورد اجزای مختلف بحث می کنم
118
00:04:59,389 –> 00:05:02,210
. قضیه بیز در
119
00:05:02,210 –> 00:05:04,030
سمت راست ما دو مؤلفه داریم
120
00:05:04,030 –> 00:05:06,260
که از سمت راست شروع می کنم
121
00:05:06,260 –> 00:05:08,780
ویزای PF این همان چیزی است که به عنوان قبلی شناخته می شود
122
00:05:08,780 –> 00:05:12,010
و اساساً
123
00:05:12,010 –> 00:05:14,210
تابع چگالی احتمال است که
124
00:05:14,210 –> 00:05:17,960
آنچه را در مورد مدل می دانیم را نشان می دهد.
125
00:05:17,960 –> 00:05:20,360
پارامترها قبل از اینکه ما واقعاً
126
00:05:20,360 –> 00:05:23,180
داده های خود را تجزیه و تحلیل کنیم، این از ایده های از پیش ساخته ما است
127
00:05:23,180 –> 00:05:26,000
یا شاید حتی بر اساس مطالعات قبلی در
128
00:05:26,000 –> 00:05:28,160
مورد توزیع
129
00:05:28,160 –> 00:05:30,470
پارامتر ما و سپس در کنار آن
130
00:05:30,470 –> 00:05:33,139
ما این احتمال را داریم که به احتمال زیاد به
131
00:05:33,139 –> 00:05:36,560
شما میگوید که احتمال دادههای شما چقدر است،
132
00:05:36,560 –> 00:05:39,560
بنابراین مشاهدات جدید شما با توجه
133
00:05:39,560 –> 00:05:42,430
به مقدار خاصی از پارامتر و
134
00:05:42,430 –> 00:05:45,020
سپس در سمت چپ،
135
00:05:45,020 –> 00:05:47,210
ما قسمت عقبی را دریافت میکنیم و در نهایت
136
00:05:47,210 –> 00:05:49,280
هدف شما این است که این را بدست آورید.
137
00:05:49,280 –> 00:05:51,410
توزیع پارامترها زمانی
138
00:05:51,410 –> 00:05:54,520
که دادهها را دریافت کردید و
139
00:05:54,520 –> 00:05:56,810
سپس مخرجی وجود دارد که
140
00:05:56,810 –> 00:05:59,060
به عنوان مدرک شناخته میشود و از
141
00:05:59,060 –> 00:06:01,639
همه این مؤلفهها و
142
00:06:01,639 –> 00:06:04,250
قضیه بیز است
143
00:06:04,250 –> 00:06:06,620
.
144
00:06:06,620 –> 00:06:09,590
برای امکان پذیر ساختن این تحلیل بیزی،
145
00:06:09,590 –> 00:06:11,360
باید
146
00:06:11,360 –> 00:06:13,820
راهی حیله گر برای دور زدن
147
00:06:13,820 –> 00:06:19,570
ارزیابی شواهد پیدا کنیم، بنابراین
148
00:06:19,570 –> 00:06:22,150
من به طور خلاصه در مورد گفته قبلی صحبت
149
00:06:22,150 –> 00:06:24,860
کردم که این همان چیزی است که ما در
150
00:06:24,860 –> 00:06:27,110
مورد مقدمات قبل از شروع به طور کلی می دانیم.
151
00:06:27,110 –> 00:06:28,340
قرار است بسته بندی شود و در
152
00:06:28,340 –> 00:06:30,500
نوعی توزیع آماری باشد
153
00:06:30,500 –> 00:06:32,300
و شما معمولاً یکی
154
00:06:32,300 –> 00:06:33,800
از توزیع های استاندارد مانند یک
155
00:06:33,800 –> 00:06:36,349
نرمال یا یک کوبنده یا یک لباس را انتخاب می کنید.
156
00:06:36,349 –> 00:06:39,409
157
00:06:39,409 –> 00:06:43,159
چیزی شبیه به یکی از این توزیعهای احتمالی داشته باشید
158
00:06:43,159 –> 00:06:45,709
و اینها اساساً میگویند
159
00:06:45,709 –> 00:06:48,709
160
00:06:48,709 –> 00:06:52,580
قبل از شروع خوب، به شما میگویند در مورد پارامتر شما چه چیزهایی میدانید، بنابراین ما
161
00:06:52,580 –> 00:06:55,879
فقط نگاهی اجمالی به نحوه
162
00:06:55,879 –> 00:06:59,029
استفاده از قضیه بیز
163
00:06:59,029 –> 00:07:02,239
برای یک مسئله بسیار ساده میاندازیم. من فکر می کنم
164
00:07:02,239 –> 00:07:03,949
چیزی که همه ما می توانیم با آن شناسایی کنیم
165
00:07:03,949 –> 00:07:05,989
و آن چرخاندن یک سکه هر نوع
166
00:07:05,989 –> 00:07:09,499
نتیجه ای است که یک نتیجه باینری دارد و
167
00:07:09,499 –> 00:07:11,360
داده های چرخاندن سکه ما باید از
168
00:07:11,360 –> 00:07:15,679
صفر و یک تشکیل شده باشد و
169
00:07:15,679 –> 00:07:18,589
صفرها نشان دهنده دنباله یا نتیجه منفی هستند
170
00:07:18,589 –> 00:07:20,479
و یکی نشان می دهد که شما می دانید
171
00:07:20,479 –> 00:07:23,419
نتیجه مثبت است و هدف ما در اینجا
172
00:07:23,419 –> 00:07:26,779
این است که بتوانیم مدل های فرآیند برنولی را امتحان کنیم و
173
00:07:26,779 –> 00:07:28,879
این مدل های برنولی
174
00:07:28,879 –> 00:07:31,069
بسیار ساده است و دو
175
00:07:31,069 –> 00:07:33,800
نتیجه ممکن دارد 0 1 و یک پارامتر
176
00:07:33,800 –> 00:07:36,529
تتا و اینکه تتا چقدر است
177
00:07:36,529 –> 00:07:39,739
احتمال شماست
178
00:07:39,739 –> 00:07:42,949
اگر بخواهیم با این دادهها رویکرد مکررگرایانه را در پیش بگیریم، در حال حاضر یک یا هد دریافت
179
00:07:42,949 –> 00:07:44,659
میکنیم،
180
00:07:44,659 –> 00:07:46,249
فقط میگوییم خوب است، فقط
181
00:07:46,249 –> 00:07:49,219
میانگین آن صفرها و
182
00:07:49,219 –> 00:07:52,610
یکها را محاسبه میکنم. به 0.75 بازگشت، بنابراین بلافاصله
183
00:07:52,610 –> 00:07:56,240
بر اساس این بر روی این 20 چرخش سکه
184
00:07:56,240 –> 00:07:59,300
، می گویم وای این سکه کمی بد به نظر می رسد،
185
00:07:59,300 –> 00:08:01,099
درست است که انتظار دارم
186
00:08:01,099 –> 00:08:05,179
به 0.5 نزدیک تر باشد، اما ما فقط 20
187
00:08:05,179 –> 00:08:07,490
نمونه داریم، بنابراین باید درجاتی از عدم قطعیت وجود داشته باشد.
188
00:08:07,490 –> 00:08:11,089
این تخمین و شما
189
00:08:11,089 –> 00:08:13,819
مطمئناً از منظر
190
00:08:13,819 –> 00:08:15,860
مکررگرایانه می توانید آن عدم قطعیت را کمی کنید، اما همانطور
191
00:08:15,860 –> 00:08:17,479
که در یک لحظه می خواهیم ببینیم که
192
00:08:17,479 –> 00:08:18,739
رویکرد بیزی به شما ایده بسیار
193
00:08:18,739 –> 00:08:21,079
خوبی از ظاهر این عدم قطعیت می
194
00:08:21,079 –> 00:08:23,529
دهد و ما با
195
00:08:23,529 –> 00:08:25,519
با استفاده از چیزی که به عنوان تقریب شبکه شناخته می شود،
196
00:08:25,519 –> 00:08:26,419
197
00:08:26,419 –> 00:08:30,110
بنابراین کاری که ما انجام می دهیم این است که طیفی از
198
00:08:30,110 –> 00:08:32,389
مقادیر ممکن را برای تتا به وضوح بین 0 تا
199
00:08:32,389 –> 00:08:34,099
1 در نظر بگیریم و آن را به یک
200
00:08:34,099 –> 00:08:36,229
شبکه بسیار ظریف تقسیم کنیم و سپس
201
00:08:36,229 –> 00:08:36,979
202
00:08:36,979 –> 00:08:39,948
مقادیر Bayes را ارزیابی کنیم. قضیه در هر نقطه از آن
203
00:08:39,948 –> 00:08:42,979
شبکه و ما می دانیم که قبلی چیست، می
204
00:08:42,979 –> 00:08:44,600
توانیم احتمال آن را ارزیابی کنیم و در
205
00:08:44,600 –> 00:08:46,129
نتیجه می توانیم بعد از آن شبکه را بدست آوریم،
206
00:08:46,129 –> 00:08:48,889
اما از آنجایی که اکنون
207
00:08:48,889 –> 00:08:50,540
در مورد تقریب خوب صحبت می
208
00:08:50,540 –> 00:08:52,939
کنیم، شاید فکری باشد. اب ببینید چگونه
209
00:08:52,939 –> 00:08:53,190
210
00:08:53,190 –> 00:08:55,470
تقریب با مقیاس به مدلی که
211
00:08:55,470 –> 00:08:58,650
چندین پارامتر دارد شما باید دو
212
00:08:58,650 –> 00:09:01,530
سه چهار پنج پارامتر داشته باشید سپس ناگهان
213
00:09:01,530 –> 00:09:03,990
فضای پارامترهای شما یک دسته کامل
214
00:09:03,990 –> 00:09:06,720
از محورها دارد و بنابراین تعداد نقاط
215
00:09:06,720 –> 00:09:09,870
شبکه شما به عنوان
216
00:09:09,870 –> 00:09:11,910
توان تعداد بنابراین ناگهان
217
00:09:11,910 –> 00:09:14,070
شبکه خطی ساده شما به این
218
00:09:14,070 –> 00:09:15,660
هیولای چند بعدی تبدیل می شود که به
219
00:09:15,660 –> 00:09:18,480
طور بالقوه نقاط زیادی در
220
00:09:18,480 –> 00:09:20,630
آن وجود دارد و کل وضعیت از نظر
221
00:09:20,630 –> 00:09:22,800
محاسباتی غیرقابل حل می شود زیرا اکنون
222
00:09:22,800 –> 00:09:24,330
به جای ارزیابی چند
223
00:09:24,330 –> 00:09:28,650
صد مورد با قضیه او، بنابراین
224
00:09:28,650 –> 00:09:30,540
اکنون برای بسیاری این کار را انجام می دهید. بسیار
225
00:09:30,540 –> 00:09:33,030
خوب است، بنابراین در دراز مدت برای
226
00:09:33,030 –> 00:09:34,380
مدل های پیچیده تر، تقریب عالی
227
00:09:34,380 –> 00:09:35,910
کار نمی کند، اما
228
00:09:35,910 –> 00:09:37,740
به عنوان یک نقطه شروع برای به دست آوردن
229
00:09:37,740 –> 00:09:39,570
درک بسیار خوب است، بنابراین ما می خواهیم انجام دهیم این است که
230
00:09:39,570 –> 00:09:41,970
فقط یک درجه از مقادیر برای تتا ایجاد کنیم
231
00:09:41,970 –> 00:09:46,260
و سپس یک پیشین تنظیم کنید و اینکه
232
00:09:46,260 –> 00:09:47,730
پیشین در این مورد
233
00:09:47,730 –> 00:09:49,740
کاملاً یکنواخت است، بنابراین
234
00:09:49,740 –> 00:09:52,170
فرض می کنیم که هر مقدار تتا در
235
00:09:52,170 –> 00:09:55,500
حال حاضر احتمال برابری دارد. من فکر میکنم اگر
236
00:09:55,500 –> 00:09:57,450
برای لحظهای به این موضوع فکر کنید،
237
00:09:57,450 –> 00:10:00,150
این یک کار کاملاً پوچ است که باید
238
00:10:00,150 –> 00:10:04,470
درست انجام دهید، منظورم این است که هر چقدر هم که سکه شما مغرضانه
239
00:10:04,470 –> 00:10:07,410
باشد، هیچ راهی وجود ندارد
240
00:10:07,410 –> 00:10:11,400
که اینها برای
241
00:10:11,400 –> 00:10:12,840
همه مقادیر ممکن دقیقاً یکسان باشند، فقط
242
00:10:12,840 –> 00:10:15,690
همین است دیوانه است، اما اینجاست که
243
00:10:15,690 –> 00:10:18,420
رویکرد مکرر شروع می شود، بنابراین
244
00:10:18,420 –> 00:10:19,890
رویکرد مکرر با این
245
00:10:19,890 –> 00:10:21,690
مانند لوح خالی شروع می
246
00:10:21,690 –> 00:10:23,580
247
00:10:23,580 –> 00:10:25,020
248
00:10:25,020 –> 00:10:26,790
249
00:10:26,790 –> 00:10:29,780
250
00:10:29,780 –> 00:10:32,700
شود. قضیه بیز را ارزیابی می کند بنابراین
251
00:10:32,700 –> 00:10:35,190
طول می کشد و بردار قبلی ما
252
00:10:35,190 –> 00:10:38,339
از مقادیر تتا و K را مصرف می کند که
253
00:10:38,339 –> 00:10:40,530
فقط 0 یا 1 است بسته به نتیجه
254
00:10:40,530 –> 00:10:43,770
برای یک تکان دادن یک سکه، بنابراین آن را اجرا می
255
00:10:43,770 –> 00:10:45,810
کنیم و اکنون کاری که من می خواهم انجام دهم این است.
256
00:10:45,810 –> 00:10:48,780
تعدادی تکرار از اعمال
257
00:10:48,780 –> 00:10:50,820
258
00:10:50,820 –> 00:10:53,339
بهروزرسانیهای بیزی قضیه بیز را اجرا کنید، بنابراین از قبل شروع کنید،
259
00:10:53,339 –> 00:10:56,310
تکهای از دادهها را محاسبه میکنید.
260
00:10:56,310 –> 00:10:58,620
261
00:10:58,620 –> 00:11:01,020
262
00:11:01,020 –> 00:11:04,230
آن را به عنوان تکرار بعدی وارد کنید
263
00:11:04,230 –> 00:11:06,220
و هر بار
264
00:11:06,220 –> 00:11:08,380
که این کار را انجام میدهید، دادههای جدیدی مصرف
265
00:11:08,380 –> 00:11:11,260
میکنید و نسخه جدید شما باید
266
00:11:11,260 –> 00:11:13,530
به نتیجه نهایی نزدیکتر و نزدیکتر شود،
267
00:11:13,530 –> 00:11:16,090
بنابراین کاری که انجام میدهد این است که فقط
268
00:11:16,090 –> 00:11:18,400
مدل بولین ما برنولی را اعمال میکند.
269
00:11:18,400 –> 00:11:22,020
و سپس یک سری نمودار تولید می کند و
270
00:11:22,020 –> 00:11:24,880
این همان چیزی است که به نظر می رسد، بنابراین در
271
00:11:24,880 –> 00:11:26,710
پانل سمت چپ بالای صفحه، در اینجا
272
00:11:26,710 –> 00:11:29,080
خط آبی افقی چین دار که قبل
273
00:11:29,080 –> 00:11:30,580
از لباس قبلی است که با آن شروع کردیم،
274
00:11:30,580 –> 00:11:32,800
و سپس اولین
275
00:11:32,800 –> 00:11:35,170
نقطه داده خود را داریم که اگر ما به
276
00:11:35,170 –> 00:11:38,590
دادههایمان برگردیم، یک عدد 1 بود به این معنی که اولین
277
00:11:38,590 –> 00:11:40,600
باری که سکه را برگرداندیم، اکنون بلافاصله سر به دست آوردیم،
278
00:11:40,600 –> 00:11:43,960
این به ما میگوید که
279
00:11:43,960 –> 00:11:46,240
سکه ما کاملاً مغرضانه نیست یا
280
00:11:46,240 –> 00:11:49,540
دو طرف آن دم ندارد و
281
00:11:49,540 –> 00:11:53,320
میدانیم که تتا برابر است. 0
282
00:11:53,320 –> 00:11:54,010
غیرممکن است،
283
00:11:54,010 –> 00:11:59,170
بنابراین اولین بهروزرسانی قبلی ما به این شکل به
284
00:11:59,170 –> 00:12:02,410
نظر میرسد، 0 برای t t برابر است با 0،
285
00:12:02,410 –> 00:12:04,180
زیرا ما قبلاً
286
00:12:04,180 –> 00:12:05,440
بر اساس این واقعیت که
287
00:12:05,440 –> 00:12:09,790
یک سر را مشاهده کردهایم و خطی است و
288
00:12:09,790 –> 00:12:11,890
اساساً میگوید ok است، آن را رد کردهایم. حرفه ای با
289
00:12:11,890 –> 00:12:14,290
افزایش تتا، توانایی تتا افزایش مییابد،
290
00:12:14,290 –> 00:12:16,930
بیایید نمونه دوم خود را مصرف کنیم که
291
00:12:16,930 –> 00:12:20,470
در حال حاضر دم است و اکنون
292
00:12:20,470 –> 00:12:22,510
این احتمال را که
293
00:12:22,510 –> 00:12:24,850
سکه ما دو سر داشته باشد را از بین بردهایم
294
00:12:24,850 –> 00:12:26,920
295
00:12:26,920 –> 00:12:29,560
. و ما آن را ورق می زنیم، به این معنی که واضح است که
296
00:12:29,560 –> 00:12:32,470
اگر تتا هم یکی نباشد، پس از
297
00:12:32,470 –> 00:12:36,030
این به یک پسین بسیار خاص می رسیم
298
00:12:36,030 –> 00:12:38,530
که من آن را مک دونالد
299
00:12:38,530 –> 00:12:42,040
پسینر می نامم و سپس
300
00:12:42,040 –> 00:12:43,930
شما هر بار که آماده مصرف یک عدد هستید، به تکرار ادامه می دهید.
301
00:12:43,930 –> 00:12:46,710
دادههای جدید و
302
00:12:46,710 –> 00:12:49,750
شما دادههای پسین را از تکرار قبلی میگیرید،
303
00:12:49,750 –> 00:12:51,550
برای تکرار بعدی
304
00:12:51,550 –> 00:12:53,890
دادههای مصرفی مقدم میشود، شما یک
305
00:12:53,890 –> 00:12:56,830
پسین جدید میگیرید و آنقدر تکرار میکنید تا زمانی
306
00:12:56,830 –> 00:12:59,320
که اکنون به نتیجه نهایی خود
307
00:12:59,320 –> 00:13:01,900
برسید که تابع چگالی احتمال
308
00:13:01,900 –> 00:13:06,400
تتا را بر اساس شما میدهد. داده ها
309
00:13:06,400 –> 00:13:08,260
و اگر این را به دقت بررسی
310
00:13:08,260 –> 00:13:10,240
کنید، خواهید دید که اوج در این
311
00:13:10,240 –> 00:13:14,710
توزیع بالای 0.75 است که به
312
00:13:14,710 –> 00:13:17,080
نوعی با آنچه ما از
313
00:13:17,080 –> 00:13:18,570
برنامه مستقیم و مکرر دریافت کردیم
314
00:13:18,570 –> 00:13:22,410
مطابقت دارد. حالا نکته خوب در مورد این
315
00:13:22,410 –> 00:13:24,870
رویکرد برای مدل سازی این است که
316
00:13:24,870 –> 00:13:28,260
تعویض یک مدل بسیار آسان است و
317
00:13:28,260 –> 00:13:30,360
در مدلی دیگر
318
00:13:30,360 –> 00:13:33,600
جایگزین می شود و یک جایگزین عالی برای مدل برنولی وجود دارد و
319
00:13:33,600 –> 00:13:36,150
آن مدل دو جمله ای است، بنابراین به جای در
320
00:13:36,150 –> 00:13:37,800
نظر گرفتن هر یک از چرخش های سکه
321
00:13:37,800 –> 00:13:40,050
به طور جداگانه همه آنها را با هم گروه می کنیم
322
00:13:40,050 –> 00:13:41,430
و می گوییم خوب، ما
323
00:13:41,430 –> 00:13:44,910
یک آزمایش واحد خواهیم داشت که در آن 20
324
00:13:44,910 –> 00:13:48,120
آزمایش داریم که 15 آزمایش موفقیت آمیز بود و
325
00:13:48,120 –> 00:13:51,090
آن را به عنوان یک توده در نظر می گیریم و بنابراین اکنون
326
00:13:51,090 –> 00:13:53,340
من یک عملکرد جدید در اینجا دارم که انجام می دهد.
327
00:13:53,340 –> 00:13:55,140
دقیقاً به همین دلیل است که ما یک
328
00:13:55,140 –> 00:13:58,080
احتمال جدید داریم که اکنون بر اساس
329
00:13:58,080 –> 00:14:00,060
مدل دوجملهای است، اما
330
00:14:00,060 –> 00:14:02,640
ما یک قبلی کمی پیچیدهتر نیز خواهیم داشت،
331
00:14:02,640 –> 00:14:04,770
در این مورد باید از توزیع بتا
332
00:14:04,770 –> 00:14:07,080
به عنوان قبلی استفاده کنیم و توزیع بتا
333
00:14:07,080 –> 00:14:09,660
مناسبترین است. در
334
00:14:09,660 –> 00:14:12,030
این شرایط به دلیل اینکه
335
00:14:12,030 –> 00:14:14,550
در محدوده 0 تا 1 پشتیبانی دارد و
336
00:14:14,550 –> 00:14:17,790
خارج از آن محدوده تعریف نشده است، دارای دو
337
00:14:17,790 –> 00:14:21,300
پارامتر آلفا و بتا است و
338
00:14:21,300 –> 00:14:23,250
انتخاب آن پارامترها شکل bea را تعیین می کند.
339
00:14:23,250 –> 00:14:25,410
توزیع ch و
340
00:14:25,410 –> 00:14:28,200
ارتقاء قبلی، بنابراین بیایید آن را ارزیابی کنیم
341
00:14:28,200 –> 00:14:35,940
و اکنون این را برای دادهها امتحان کنیم و
342
00:14:35,940 –> 00:14:41,100
این کار را به خوبی انجام میدهیم، بنابراین
343
00:14:41,100 –> 00:14:43,590
از همان دادههای قبلی استفاده نمیکنیم، در حال حاضر ده
344
00:14:43,590 –> 00:14:46,650
آزمایش هفت موفقیتآمیز،
345
00:14:46,650 –> 00:14:49,740
خط آبی افقی یکدست را داریم که یکنواخت
346
00:14:49,740 –> 00:14:52,050
قبل از آن متوجه می شویم که با استفاده از
347
00:14:52,050 –> 00:14:54,240
توزیع پیتزا با آلفا برابر با یک و B
348
00:14:54,240 –> 00:14:56,010
T برابر با یک، بنابراین این به همان اندازه
349
00:14:56,010 –> 00:14:57,480
آموزنده است که از جایی که قبلا شروع کردیم
350
00:14:57,480 –> 00:15:00,510
و می توانید ببینید که در این مورد ما
351
00:15:00,510 –> 00:15:02,160
به توزیعی می
352
00:15:02,160 –> 00:15:04,320
رسیم که بیشتر یادآور چیزی است که ما دریافت کردیم. زمانی
353
00:15:04,320 –> 00:15:06,750
که دوجملهای هر
354
00:15:06,750 –> 00:15:08,700
توزیع برنولی و یکنواخت
355
00:15:08,700 –> 00:15:11,880
قبلی را تعیین کرده بودیم، اما اکنون اگر به وضعیت فکر کنیم
356
00:15:11,880 –> 00:15:14,160
و بگوییم خوب این یکنواخت
357
00:15:14,160 –> 00:15:16,830
قبلی کاملاً پوچ است، میتوانیم
358
00:15:16,830 –> 00:15:18,570
خیلی بهتر از آن انجام دهیم، بیایید برای چیزی تلاش
359
00:15:18,570 –> 00:15:20,400
کنیم که اطلاعات ضعیفی دارد، بنابراین
360
00:15:20,400 –> 00:15:23,190
قبل از آن صفر در دو انتها
361
00:15:23,190 –> 00:15:25,050
و به نوعی در وسط به اوج رسیده است و
362
00:15:25,050 –> 00:15:27,710
می توانیم دریافت کنیم که با توزیع بتا
363
00:15:27,710 –> 00:15:32,300
آلفا برابر با T برابر با دو
364
00:15:32,860 –> 00:15:36,740
خوب است و اکنون یک بار دیگر – خط آبی مقدم است.
365
00:15:36,740 –> 00:15:39,110
رنگ سبز احتمال ماست
366
00:15:39,110 –> 00:15:41,269
و خط نارنجی قسمت عقب است و
367
00:15:41,269 –> 00:15:43,399
چیزی که می توانید ببینید این است که به جای اینکه خط
368
00:15:43,399 –> 00:15:47,569
خلفی بیش از 70% ردیف شود در
369
00:15:47,569 –> 00:15:50,089
این مورد
370
00:15:50,089 –> 00:15:53,240
کمی به سمت چپ تغییر کرده است، بنابراین آنچه در اینجا داریم این است
371
00:15:53,240 –> 00:15:56,809
که خط قبلی ما دانش در مورد تتا در
372
00:15:56,809 –> 00:16:00,769
واقع تأثیر مشاهدات ما را تعدیل کرده است
373
00:16:00,769 –> 00:16:03,740
، اما حتی این هم
374
00:16:03,740 –> 00:16:06,740
خیلی خوب نیست، زیرا من تقریباً مطمئن
375
00:16:06,740 –> 00:16:09,139
هستم که دانش من در مورد نحوه عملکرد
376
00:16:09,139 –> 00:16:11,779
سکه ها چندان مبهم نیست،
377
00:16:11,779 –> 00:16:14,119
احساس بسیار قوی دارم که تتا
378
00:16:14,119 –> 00:16:17,179
واقعاً باید تقریباً نزدیک به 1/2 باشید،
379
00:16:17,179 –> 00:16:21,410
بنابراین ممکن است یک پیشینی مانند یکی که
380
00:16:21,410 –> 00:16:23,869
با یک جن توزیع پیتزا می گیرید برابر با 20
381
00:16:23,869 –> 00:16:27,050
ضرب برابر با 20 بهتر عمل کند
382
00:16:27,050 –> 00:16:28,939
و در این مورد خط آبی تیره
383
00:16:28,939 –> 00:16:30,800
قبلی ما اکنون می توانید ببینید که به نوعی
384
00:16:30,800 –> 00:16:33,829
محدود به محدوده بین 0.4 0.6 است
385
00:16:33,829 –> 00:16:35,779
که من فکر می کنم برای
386
00:16:35,779 –> 00:16:38,029
هر ملکه ای کاملاً منطقی است حتی اگر یک سکه مغرضانه باشد،
387
00:16:38,029 –> 00:16:39,199
شما نمی خواهید از
388
00:16:39,199 –> 00:16:41,929
چیزی خارج از آن محدوده خلاص شوید، و
389
00:16:41,929 –> 00:16:43,249
سپس ما این احتمال را داریم که خط سبز
390
00:16:43,249 –> 00:16:45,589
a و پس از ما خط نارنجی
391
00:16:45,589 –> 00:16:48,799
و در اینجا می توانید ببینید که دانش موجود ما
392
00:16:48,799 –> 00:16:50,299
در مورد سکه
393
00:16:50,299 –> 00:16:53,600
واقعاً تأثیر زیادی بر نتیجه نهایی داشته است
394
00:16:53,600 –> 00:16:56,240
و اگر فقط برای یک لحظه به این موضوع فکر کنید،
395
00:16:56,240 –> 00:16:59,720
کاملاً منطقی به نظر می رسد.
396
00:16:59,720 –> 00:17:02,089
397
00:17:02,089 –> 00:17:03,619
قبل از اینکه اساساً
398
00:17:03,619 –> 00:17:07,069
بگویید من چیزی در مورد کوئینز
399
00:17:07,069 –> 00:17:09,980
نمیدانم و به این 20 مشاهدات اعتماد میکنم تا
400
00:17:09,980 –> 00:17:14,059
401
00:17:14,059 –> 00:17:15,859
402
00:17:15,859 –> 00:17:17,449
403
00:17:17,449 –> 00:17:20,929
نتیجهام را اعلام کنم. زمان آن است که من
404
00:17:20,929 –> 00:17:22,549
به چیز متفاوتی حرکت کنم
405
00:17:22,549 –> 00:17:26,000
اوه در واقع اینطور نیست قبل از انجام آن فقط
406
00:17:26,000 –> 00:17:28,940
به ذکر است که برای انجام
407
00:17:28,940 –> 00:17:30,799
آنالیز بیزی در پایتون مجموعه ای از
408
00:17:30,799 –> 00:17:32,360
بسته های مختلف وجود دارد، بنابراین این
409
00:17:32,360 –> 00:17:34,880
پنج بسته اول هستند که همگی در پایتون پیاده سازی می شوند
410
00:17:34,880 –> 00:17:37,039
و سپس در آنجا پیاده سازی می شوند. آیا این دو مورد آخر
411
00:17:37,039 –> 00:17:39,110
، PI jags و پاکستان و اینها
412
00:17:39,110 –> 00:17:41,210
در واقع در اطراف سیستمهای دیگر قرار میگیرند،
413
00:17:41,210 –> 00:17:42,799
و من
414
00:17:42,799 –> 00:17:44,390
دقیقاً در پایان این بحث روی
415
00:17:44,390 –> 00:17:51,740
پسترن تمرکز خواهم کرد، بنابراین من به آن اشاره کردم. در این
416
00:17:51,740 –> 00:17:54,049
تقریب عالی وقتی
417
00:17:54,049 –> 00:17:57,049
مشکل خود را مقیاس بندی می کنید کار نمی کند، بنابراین چگونه می
418
00:17:57,049 –> 00:17:58,580
توانید بهتر انجام دهید چگونه با یک
419
00:17:58,580 –> 00:17:59,900
مشکل چند بعدی به
420
00:17:59,900 –> 00:18:03,650
خوبی برخورد می کنید و من حدس می زنم در
421
00:18:03,650 –> 00:18:05,000
روزهای جنگ جهانی دوم آنها در آنجا
422
00:18:05,000 –> 00:18:08,150
کارهایی انجام می دادند. کار بسیار فشرده روی
423
00:18:08,150 –> 00:18:09,559
پروژه منهتن و یکی از
424
00:18:09,559 –> 00:18:11,330
کارهایی که آنها باید انجام می دادند این بود که
425
00:18:11,330 –> 00:18:13,130
این انتگرال های چند بعدی عظیم را ارزیابی کردند
426
00:18:13,130 –> 00:18:15,470
و بنابراین یک
427
00:18:15,470 –> 00:18:17,809
فرآیند بسیار حیله گر به نام فرآیند مونت کارلو اختراع کردند
428
00:18:17,809 –> 00:18:21,020
و در ابتدا
429
00:18:21,020 –> 00:18:23,960
ارزیابی انتگرال ها بود و
430
00:18:23,960 –> 00:18:25,970
بیشتر شامل آن می شد. به جای اینکه سعی کنید این
431
00:18:25,970 –> 00:18:27,679
انتگرال ها را در شبکه ای از نقاط ارزیابی کنید
432
00:18:27,679 –> 00:18:30,710
که اساساً نمونه های تصادفی از
433
00:18:30,710 –> 00:18:32,900
آن انتگرال گرفته می شود و یک نتیجه تقریبی بدست می آید،
434
00:18:32,900 –> 00:18:34,880
اما حداقل دریافت نتایج هوا
435
00:18:34,880 –> 00:18:37,700
در مدت زمان معقول
436
00:18:37,700 –> 00:18:39,620
اکنون تنها چیزی است که
437
00:18:39,620 –> 00:18:42,230
برای اعمال باید بتوانید انجام دهید. روش مونت کارلو
438
00:18:42,230 –> 00:18:43,700
این است که بتوانید تابع چگالی خود را بگیرید
439
00:18:43,700 –> 00:18:46,160
و آن را معکوس کنید تا
440
00:18:46,160 –> 00:18:48,110
اساساً آن را به سمت بیرون بچرخانید و
441
00:18:48,110 –> 00:18:50,330
سپس به شما امکان می دهد نمونه هایی از آن تولید کنید.
442
00:18:50,330 –> 00:18:52,669
توزیع الکترونیکی از آنجایی که ما نمی
443
00:18:52,669 –> 00:18:56,059
دانیم قسمت عقبی ما چگونه به نظر می رسد، نمی توانیم آن را به
444
00:18:56,059 –> 00:18:58,669
درستی معکوس کنیم، به طوری که قبلاً
445
00:18:58,669 –> 00:19:00,559
از پنجره بیرون آمده است، اما خوشبختانه
446
00:19:00,559 –> 00:19:02,419
چیز دیگری وجود دارد که در اینجا مطرح می شود
447
00:19:02,419 –> 00:19:04,000
و آن این است که ایده زنجیره
448
00:19:04,000 –> 00:19:06,770
مارکوف زنجیره مارکوف است. فرآیندی که در آن
449
00:19:06,770 –> 00:19:10,480
مرحله بعدی فقط به شرایط فعلی بستگی دارد،
450
00:19:10,480 –> 00:19:13,160
بنابراین و مانند یک مورد واقعا ساده
451
00:19:13,160 –> 00:19:16,070
و ایده آل مانند آب و هوای
452
00:19:16,070 –> 00:19:17,840
فردا، بسیار شبیه به
453
00:19:17,840 –> 00:19:19,160
روش امروز خواهد بود و فرقی نمی کند
454
00:19:19,160 –> 00:19:20,419
که هوای دیروز یا روز
455
00:19:20,419 –> 00:19:22,820
قبل چگونه بوده است. مثل شرایط امروزی
456
00:19:22,820 –> 00:19:24,200
تنها چیزهایی هستند که بر نحوه
457
00:19:24,200 –> 00:19:27,049
ایدهآلسازی بیشتر تأثیر میگذارند، این دو
458
00:19:27,049 –> 00:19:29,440
چیز با هم به ما اجازه میدهند
459
00:19:29,440 –> 00:19:32,540
تا یک مشکل چند بعدی را حل کنیم،
460
00:19:32,540 –> 00:19:35,000
پس بیایید این کار را انجام
461
00:19:35,000 –> 00:19:37,370
دهیم و دقیقاً به مجموعه دادههای مشابهی نگاه میکنیم.
462
00:19:37,370 –> 00:19:38,990
قبل از
463
00:19:38,990 –> 00:19:41,510
اعمال یک مدل برنولی، به فرکانسها نگاه کنید،
464
00:19:41,510 –> 00:19:43,760
دقیقاً
465
00:19:43,760 –> 00:19:47,660
همان میانگین قبلی را داریم، بنابراین 75٪ میتوانیم
466
00:19:47,660 –> 00:19:50,179
فاصله اطمینان یا بر اساس آن را محاسبه کنیم و
467
00:19:50,179 –> 00:19:52,940
این مانند ماکی است. برخی از مفروضات بسیار مبهم را در نظر بگیرید،
468
00:19:52,940 –> 00:19:55,309
اما بیایید از آن
469
00:19:55,309 –> 00:19:57,149
بگذریم و در مورد حداکثر احتمال صحبت کنیم
470
00:19:57,149 –> 00:19:58,409
و این چیزی
471
00:19:58,409 –> 00:19:59,969
است که در
472
00:19:59,969 –> 00:20:02,219
رژیم مکرر نیز وجود دارد، اما به این احتمال کمی مربوط می شود
473
00:20:02,219 –> 00:20:04,799
که شاید
474
00:20:04,799 –> 00:20:07,710
ارزش آن را داشته باشد که برگردیم به این که
475
00:20:07,710 –> 00:20:09,359
احتمال چقدر است. قبلاً اشاره کردم این است
476
00:20:09,359 –> 00:20:11,700
که احتمال دادههای شما
477
00:20:11,700 –> 00:20:14,580
به مقدار خاصی از پارامتر ما داده میشود، بنابراین
478
00:20:14,580 –> 00:20:15,629
کاری که شما انجام میدهید این است که به
479
00:20:15,629 –> 00:20:17,940
هر مشاهدات فردی نگاه میکنید، بنابراین هر ورق
480
00:20:17,940 –> 00:20:20,219
سکه و میگویید خوب یک ویژگی
481
00:20:20,219 –> 00:20:22,529
0.5 است که چقدر احتمال دارد که من سر می گیرم
482
00:20:22,529 –> 00:20:24,210
و چقدر خوش شانس است که من دنباله
483
00:20:24,210 –> 00:20:26,249
می کنم و شما این کار را برای هر مشاهده فردی انجام می دهید
484
00:20:26,249 –> 00:20:28,349
و در نهایت با یک
485
00:20:28,349 –> 00:20:29,369
احتمال مواجه می شوید و ما می دانیم که
486
00:20:29,369 –> 00:20:31,109
احتمالات بین 0 و 1
487
00:20:31,109 –> 00:20:34,349
قرار می گیرند و احتمال مشترک همه آن مشاهدات را بدست می آوریم.
488
00:20:34,349 –> 00:20:36,059
در کل
489
00:20:36,059 –> 00:20:38,249
آزمایش شما باید همه
490
00:20:38,249 –> 00:20:40,440
این احتمالات را با هم ضرب کنید و می
491
00:20:40,440 –> 00:20:42,330
دانید که اگر علوم کامپیوتر انجام
492
00:20:42,330 –> 00:20:44,129
داده اید، می دانید که تمام آن
493
00:20:44,129 –> 00:20:45,929
اعداد کوچک را می گیرید و آنها را ضرب می کنید. با هم
494
00:20:45,929 –> 00:20:47,339
و در نهایت به عدد بسیار
495
00:20:47,339 –> 00:20:49,589
کمی می رسید که احتمالاً
496
00:20:49,589 –> 00:20:51,839
منجر به یک جریان محاسباتی می شود، بنابراین
497
00:20:51,839 –> 00:20:53,669
از منظر محاسباتی، این
498
00:20:53,669 –> 00:20:55,769
احتمال ساختی است که مملو از آن است، بنابراین
499
00:20:55,769 –> 00:20:57,509
آنچه که معمولاً انجام می شود به جای
500
00:20:57,509 –> 00:20:59,249
کار کردن با احتمال احتمالی است که شما آن را انجام
501
00:20:59,249 –> 00:21:00,899
می دهید.
502
00:21:00,899 –> 00:21:03,419
لگاریتم هر یک از این احتمالات را بگیرید و
503
00:21:03,419 –> 00:21:04,679
به جای اینکه چگونه شما را به جای
504
00:21:04,679 –> 00:21:05,879
ضرب با هم جمع کنید، آنها را
505
00:21:05,879 –> 00:21:07,710
با هم جمع کنید بنابراین من در اینجا توابعی
506
00:21:07,710 –> 00:21:09,570
برای احتمال و
507
00:21:09,570 –> 00:21:11,909
احتمال گزارش دارم و آنها را
508
00:21:11,909 –> 00:21:14,759
برای آن مجموعه داده و شما قرار می دهم. در سمت چپ اینجا می توانید ببینید
509
00:21:14,759 –> 00:21:17,039
که احتمال یک اوج بسیار خوب
510
00:21:17,039 –> 00:21:20,580
بالای 0.75 دارد، بنابراین
511
00:21:20,580 –> 00:21:22,440
دقیقاً همان نتایجی را به ما می دهد که فقط از محاسبه میانگین میانگین به دست آوردیم،
512
00:21:22,440 –> 00:21:24,629
513
00:21:24,629 –> 00:21:26,969
حداکثر احتمال را پیدا کنید و تشخیص آن کمی
514
00:21:26,969 –> 00:21:28,859
دشوارتر است اما
515
00:21:28,859 –> 00:21:30,960
حداکثر در احتمال ورود به سیستم
516
00:21:30,960 –> 00:21:33,509
دقیقاً در همان نقطه است در این مورد شما
517
00:21:33,509 –> 00:21:34,919
حساب و جریان را دریافت نمی کنید
518
00:21:34,919 –> 00:21:36,839
زیرا ما فقط 20 نمونه داریم اما
519
00:21:36,839 –> 00:21:38,580
اگر صد نمونه دارید هزاران نمونه
520
00:21:38,580 –> 00:21:42,839
قطعاً کار نمی کند،
521
00:21:42,839 –> 00:21:45,809
بنابراین گام بعدی زنجیره مارکوف
522
00:21:45,809 –> 00:21:48,479
و مونت کارلو را بردارید و آنها را
523
00:21:48,479 –> 00:21:50,820
با هم له کنید تا راهی برای انجام
524
00:21:50,820 –> 00:21:53,009
این تحلیل بیزی داشته باشیم و این
525
00:21:53,009 –> 00:21:55,440
اساساً یک
526
00:21:55,440 –> 00:21:57,960
الگوریتم تکراری بسیار ساده برای نحوه انجام این کار وجود دارد.
527
00:21:57,960 –> 00:22:01,080
بنابراین شما با یک نمونه برای تتا مرتب می کنید
528
00:22:01,080 –> 00:22:03,539
و نمونه می تواند
529
00:22:03,539 –> 00:22:05,219
کاملاً تصادفی گرفته شود یا می تواند
530
00:22:05,219 –> 00:22:07,379
از قبلی شما استخراج شود و سپس کاری که انجام می دهید این است
531
00:22:07,379 –> 00:22:09,479
که در مجاورت آن نمونه شما
532
00:22:09,479 –> 00:22:10,530
اکنون
533
00:22:10,530 –> 00:22:13,110
یک مقدار جدید است و این به عنوان شناخته می شود.
534
00:22:13,110 –> 00:22:15,570
پروپوزال و این یک روش بسیار
535
00:22:15,570 –> 00:22:17,400
متعارف برای انجام این کار است، شما فقط
536
00:22:17,400 –> 00:22:19,200
کمی از توزیع نرمال در اطراف
537
00:22:19,200 –> 00:22:21,240
مکا