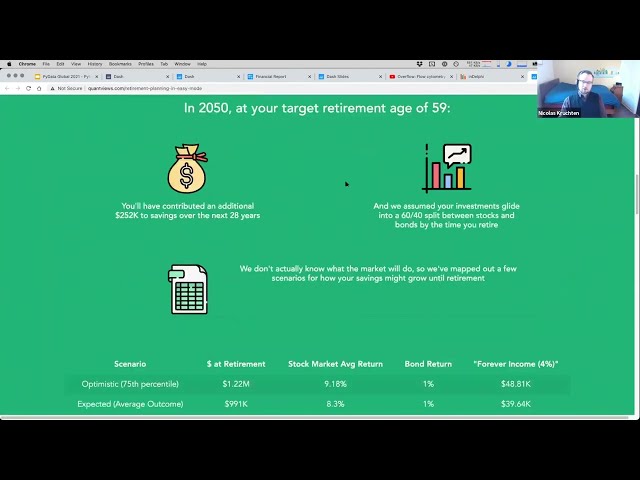
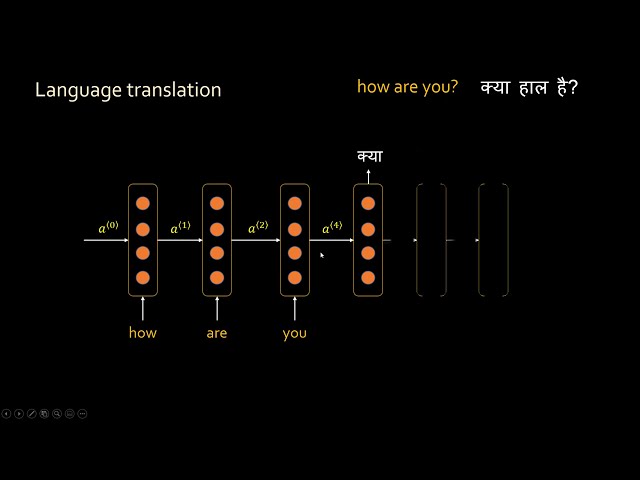
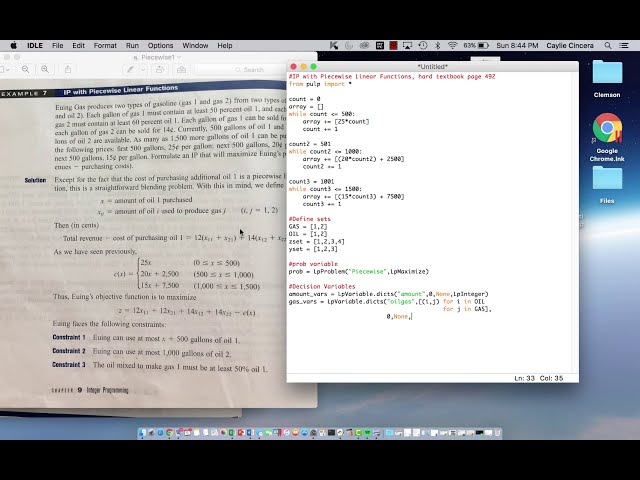
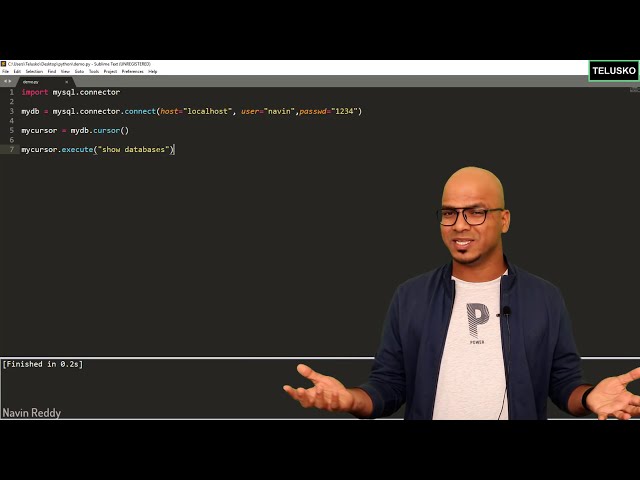
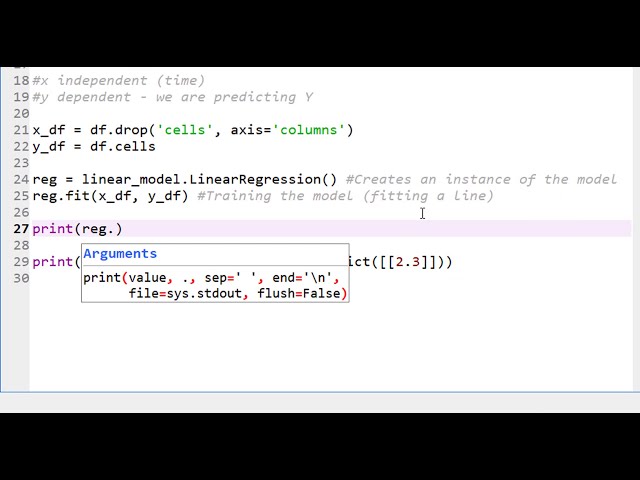
در این مطلب، ویدئو نحوه انتخاب بهترین مدل با استفاده از اعتبارسنجی متقابل در پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:01,829
بحث در مورد انتخاب مدل و
2
00:00:01,829 –> 00:00:04,920
اعتبارسنجی متقابل در ویدئوهای قبلی،
3
00:00:04,920 –> 00:00:06,569
ما شاهد مشکلات مختلف رگرسیون و
4
00:00:06,569 –> 00:00:08,820
طبقهبندی بودیم، برخی از
5
00:00:08,820 –> 00:00:10,590
مشکلات تنظیمی که در مورد آن بحث کردیم،
6
00:00:10,590 –> 00:00:12,780
چند جملهای رگرسیون خطی ساده
7
00:00:12,780 –> 00:00:14,969
در یک رگرسیون بود، بهطور مشابه، مشکلات
8
00:00:14,969 –> 00:00:16,680
طبقهبندی چندگانه مانند درخت تصمیم رگرسیون لجستیک را نیز مورد بحث قرار داده بودیم.
9
00:00:16,680 –> 00:00:19,619
10
00:00:19,619 –> 00:00:21,689
رگرسیون جنگل تصادفی
11
00:00:21,689 –> 00:00:23,760
اگر آن ویدیوها را
12
00:00:23,760 –> 00:00:26,340
ندیدهاید، میتوانید آن را از طریق لیست پخش من تماشا کنید، اما
13
00:00:26,340 –> 00:00:27,630
مطمئن شوید که
14
00:00:27,630 –> 00:00:29,460
قبل از اعمال
15
00:00:29,460 –> 00:00:31,320
انتخاب مدل، برخی از ویدیوهای طبقهبندی را تماشا کردهاید و روشهایی که
16
00:00:31,320 –> 00:00:32,910
میتوانید انواع مدلها
17
00:00:32,910 –> 00:00:35,280
یا الگوریتم این انتخاب را انتخاب کنید.
18
00:00:35,280 –> 00:00:37,500
بر اساس سطح دقت و ما تلاش خواهیم کرد تا بفهمیم
19
00:00:37,500 –> 00:00:39,000
20
00:00:39,000 –> 00:00:40,649
بهترین الگوریتم یادگیری ماشینی که
21
00:00:40,649 –> 00:00:42,629
می توانیم برای یک مشکل مجموعه داده خاص اعمال کنیم کدام
22
00:00:42,629 –> 00:00:45,059
است، سپس در مورد
23
00:00:45,059 –> 00:00:47,100
اعتبار سنجی متقاطع نیز خواهیم دید که کتابخانه ای است
24
00:00:47,100 –> 00:00:48,780
که خواهد بود. قبل از رفتن به گو، مجموعه داده های آموزشی و آزمایشی خود را به
25
00:00:48,780 –> 00:00:50,579
روش های مختلف تغییر دهید
26
00:00:50,579 –> 00:00:51,320
27
00:00:51,320 –> 00:00:53,789
بله لطفا
28
00:00:53,789 –> 00:00:55,860
کانال را مشترک کنید زیرا هر هفته
29
00:00:55,860 –> 00:00:57,809
سعی می کنم دو تا سه ویدیو بسازم که برخی از
30
00:00:57,809 –> 00:01:00,000
آنها یک یادگیری ماشینی و برخی دیگر
31
00:01:00,000 –> 00:01:03,690
عمیق است، بنابراین اجازه دهید قبل از شروع
32
00:01:03,690 –> 00:01:05,489
33
00:01:05,489 –> 00:01:07,770
شروع کنیم. استفاده کنید بنابراین
34
00:01:07,770 –> 00:01:09,360
این مجموعه داده ای است که من استفاده می کنم
35
00:01:09,360 –> 00:01:10,770
که چیزی نیست جز
36
00:01:10,770 –> 00:01:12,990
مجموعه داده های زیرخط خریداری شده در این
37
00:01:12,990 –> 00:01:15,659
مجموعه داده خاص، آنها انواع مختلفی از
38
00:01:15,659 –> 00:01:17,610
ستون ها هستند مانند شناسه کاربری جنسیت سن
39
00:01:17,610 –> 00:01:20,759
تخمینی حقوق و ایوان ها و بر
40
00:01:20,759 –> 00:01:22,770
اساس سن و حقوق تخمینی که می
41
00:01:22,770 –> 00:01:25,320
رویم. برای پیشبینی اینکه آیا
42
00:01:25,320 –> 00:01:27,600
شخص خرید میکند یا خیر، این نیز
43
00:01:27,600 –> 00:01:28,680
نوع دیگری از
44
00:01:28,680 –> 00:01:31,229
مشکلات طبقهبندی است، کاری که ما انجام خواهیم داد این است که
45
00:01:31,229 –> 00:01:32,640
سعی میکنیم از دو نوع
46
00:01:32,640 –> 00:01:34,860
مشکل طبقهبندی مختلف استفاده کنیم و سپس
47
00:01:34,860 –> 00:01:36,360
از اعتبارسنجی متقاطع برای
48
00:01:36,360 –> 00:01:38,790
تعیین اینکه کدام یک استفاده میکنیم.
49
00:01:38,790 –> 00:01:40,470
مشکل طبقهبندی برای این
50
00:01:40,470 –> 00:01:42,689
تکنیک خاص یادگیری ماشین و این مجموعه داده خاص بهترین است،
51
00:01:42,689 –> 00:01:45,600
بنابراین میتوانید ببینید کجا
52
00:01:45,600 –> 00:01:47,640
ویژگیهای مختلفی مانند حقوق تخمینی سن
53
00:01:47,640 –> 00:01:50,189
و شکارچیان داریم. من همچنین میتوانم
54
00:01:50,189 –> 00:01:52,500
جنسیت را بهعنوان ویژگی مستقل خود بررسی کنم،
55
00:01:52,500 –> 00:01:54,180
اما نمیخواهم فعلاً متغیر سوم
56
00:01:54,180 –> 00:01:57,000
را وارد کنم، اگر میخواهید آن را وارد
57
00:01:57,000 –> 00:01:58,680
کنید، مطمئن شوید که این زن و
58
00:01:58,680 –> 00:02:00,780
مرد را به متغیرهای طبقهبندی مانند
59
00:02:00,780 –> 00:02:02,360
صفر و یک تبدیل کردهاید،
60
00:02:02,360 –> 00:02:04,770
نگران این نباشید. مجموعه داده های خاصی
61
00:02:04,770 –> 00:02:07,680
را در لینک github خود آپلود خواهم کرد
62
00:02:07,680 –> 00:02:09,660
و توضیحات را
63
00:02:09,660 –> 00:02:11,610
در توضیحات خاص ویدیوی YouTube خود ارائه خواهم کرد،
64
00:02:11,610 –> 00:02:13,410
بنابراین اجازه دهید من ادامه دهم
65
00:02:13,410 –> 00:02:15,840
و کدنویسی را شروع کنم و از
66
00:02:15,840 –> 00:02:17,580
این مجموعه داده خاص برای حل
67
00:02:17,580 –> 00:02:20,220
مشکل طبقه بندی استفاده کنم، بنابراین برای شروع
68
00:02:20,220 –> 00:02:22,500
من هستم قصد وارد کردن دو کتابخانه
69
00:02:22,500 –> 00:02:25,320
که به عنوان numpy و panda نامیده می شوند، می
70
00:02:25,320 –> 00:02:28,050
خواهم از CSV مجدد دیسکو برای خواندن این
71
00:02:28,050 –> 00:02:30,570
فایل CSV استفاده کنم، سپس کاری که می خواهم انجام دهم این است که
72
00:02:30,570 –> 00:02:32,670
73
00:02:32,670 –> 00:02:35,730
ستون حقوق قدیمی و تخمینی را اجرا می کنم و من. m قرار است
74
00:02:35,730 –> 00:02:37,680
آن را در ویژگی مستقل من
75
00:02:37,680 –> 00:02:40,890
که X است وارد کنم، به طور مشابه ستون خریداری شده من
76
00:02:40,890 –> 00:02:43,490
در ویژگی وابسته خواهد بود، به همین دلیل است که
77
00:02:43,490 –> 00:02:47,520
این x و y بعداً
78
00:02:47,520 –> 00:02:49,680
به قطار و تست تقسیم می شوند و سپس ما می خواهیم
79
00:02:49,680 –> 00:02:51,860
مدل ba خود را آموزش دهیم. روی دادههای قطار
80
00:02:51,860 –> 00:02:55,320
و مدلی که من اعمال خواهم کرد برای
81
00:02:55,320 –> 00:02:58,910
یافتن دقت از دادههای آزمایشی استفاده
82
00:02:58,910 –> 00:03:01,500
میکنم، بنابراین اینجاست که میخواهم
83
00:03:01,500 –> 00:03:02,730
صفحه آزمایشی Train را برای انتخاب مدل
84
00:03:02,730 –> 00:03:04,830
وارد کنم.
85
00:03:04,830 –> 00:03:06,630
86
00:03:06,630 –> 00:03:08,010
الگوریتمی که در
87
00:03:08,010 –> 00:03:10,620
حال حاضر برای مسئله طبقهبندی استفاده میکنم، پس از
88
00:03:10,620 –> 00:03:12,870
آن میخواهم از معیارها نیز استفاده
89
00:03:12,870 –> 00:03:14,670
کنم. اجازه دهید یک مختصر مختصر در مورد
90
00:03:14,670 –> 00:03:17,580
طبقهبندی همسایگان que
91
00:03:17,580 –> 00:03:19,350
92
00:03:19,350 –> 00:03:22,980
ارائه دهم.
93
00:03:22,980 –> 00:03:24,690
94
00:03:24,690 –> 00:03:26,760
فاصله اقلیدسی باطن به شما کمک می کند
95
00:03:26,760 –> 00:03:29,780
فاصله بین دو نقطه بعدی را بیابید
96
00:03:29,780 –> 00:03:32,250
اساساً یک فرمول جرمی برای
97
00:03:32,250 –> 00:03:34,470
آن وجود دارد که می تواند به عنوان ریشه x2
98
00:03:34,470 –> 00:03:37,080
منهای x1 به اضافه y2 منهای y1 مربع کامل تنظیم شود
99
00:03:37,080 –> 00:03:37,950
متأسفانه
100
00:03:37,950 –> 00:03:40,080
این نیز X 2 منهای X 1 مربع کامل
101
00:03:40,080 –> 00:03:43,200
به علاوه است. y2 منهای y1 مربع کامل اگر
102
00:03:43,200 –> 00:03:44,790
می خواهید فاصله بین دو
103
00:03:44,790 –> 00:03:47,190
نقطه بعدی را به طور مشابه با توجه
104
00:03:47,190 –> 00:03:49,110
به سه بعدی پیدا کنید، فرمول تغییر می کند،
105
00:03:49,110 –> 00:03:51,630
بنابراین در مرحله بعدی من می خواهم m را تقسیم کنم
106
00:03:51,630 –> 00:03:54,480
. مجموعه دادههای y در آموزش و آزمایش من
107
00:03:54,480 –> 00:03:56,670
از کتابخانه کرنش و صفحه آزمایشی استفاده
108
00:03:56,670 –> 00:03:59,070
میکنم که X و 1 و
109
00:03:59,070 –> 00:04:02,550
حالت تصادفی را به عنوان فایل میدهم، لطفاً
110
00:04:02,550 –> 00:04:04,530
این مقدار حالت تصادفی را یادداشت کنید زیرا میخواهم در
111
00:04:04,530 –> 00:04:06,300
مورد این و نحوه آن توضیح دهم.
112
00:04:06,300 –> 00:04:08,370
در واقع به
113
00:04:08,370 –> 00:04:10,459
ما کمک میکند تا انتخاب مدل را انجام دهیم،
114
00:04:10,459 –> 00:04:14,100
سپس من میخواهم کانیا خود را بر اساس
115
00:04:14,100 –> 00:04:16,560
و cainy فراخوانی کنم، میخواهم
116
00:04:16,560 –> 00:04:18,779
یک شی بسازم و در آن منافذ
117
00:04:18,779 –> 00:04:19,380
118
00:04:19,380 –> 00:04:21,390
و خط همسایه را برابر با
119
00:04:21,390 –> 00:04:23,789
4 در نظر بگیرم. به جای 4 می خواهم یک
120
00:04:23,789 –> 00:04:26,160
عدد فرد بدهم زیرا اگر در آن زمان به نزدیکترین
121
00:04:26,160 –> 00:04:28,169
همسایه از همان نوع برسم،
122
00:04:28,169 –> 00:04:29,820
123
00:04:29,820 –> 00:04:31,470
پیش بینی اینکه مدل باید از کدام سمت برود
124
00:04:31,470 –> 00:04:34,650
پس از آن بسیار دشوار خواهد بود و من از K استفاده می کنم. و K و
125
00:04:34,650 –> 00:04:37,080
K و n لباس طبقه بندی شده و من
126
00:04:37,080 –> 00:04:38,970
می خواهم قطار xn و چیز سفید را
127
00:04:38,970 –> 00:04:41,160
پس از آن پیش بینی کنم و
128
00:04:41,160 –> 00:04:43,650
این مقدار پیش بینی شده من خواهد بود بعد از
129
00:04:43,650 –> 00:04:45,570
آن کاری که می خواهم انجام دهم این است که می
130
00:04:45,570 –> 00:04:47,039
خواهم نمره دقت را
131
00:04:47,039 –> 00:04:50,160
بر اساس داده های آزمون پیدا کنید و I
132
00:04:50,160 –> 00:04:52,350
با دادههای پیشبینیشده Y مقایسه میشود، بنابراین
133
00:04:52,350 –> 00:04:53,940
اجازه دهید هر دو این
134
00:04:53,940 –> 00:04:57,660
خط خاص را در اینجا اجرا کنم، این است که من
135
00:04:57,660 –> 00:05:01,110
حدود 75 درصد دقت را با عصا بدست میآورم و
136
00:05:01,110 –> 00:05:04,010
همسایه زیرخط برابر با 5 است، حالا
137
00:05:04,010 –> 00:05:06,450
به یاد داشته باشید که آنچه در مورد
138
00:05:06,450 –> 00:05:08,340
حالت تصادفی تصادفی در این مورد گفتم وضعیت
139
00:05:08,340 –> 00:05:10,560
اکنون من می خواهم این
140
00:05:10,560 –> 00:05:11,850
کد را کپی کنم و آن را در
141
00:05:11,850 –> 00:05:15,240
اینجا جای گذاری می کنم به یاد داشته باشید که من K را ساخته ام و یک
142
00:05:15,240 –> 00:05:17,160
همسایه زیرخط خوب است، اجازه
143
00:05:17,160 –> 00:05:19,200
دهید مقادیر حالت تصادفی را به 3 تغییر
144
00:05:19,200 –> 00:05:20,700
دهم و ببینیم پیمایش چگونه خواهد بود.
145
00:05:20,700 –> 00:05:22,860
می توانید ببینید دقتی که من
146
00:05:22,860 –> 00:05:24,690
دریافت می کنم اساساً 81٪ است،
147
00:05:24,690 –> 00:05:28,430
به طور مشابه، اجازه دهید آن را از 1 در یک
148
00:05:28,430 –> 00:05:30,570
حالت تصادفی تغییر دهیم، زمانی که ما در حال انتخاب
149
00:05:30,570 –> 00:05:32,450
هستیم، دقت 74٪ را
150
00:05:32,450 –> 00:05:34,950
به طور مشابه برای 2 دریافت می کنیم، بیایید ببینیم آیا
151
00:05:34,950 –> 00:05:36,960
مکان نما تغییر می کند یا خیر. حالا
152
00:05:36,960 –> 00:05:40,680
به 78% تغییر می کنم، اجازه دهید فقط
153
00:05:40,680 –> 00:05:42,419
با مقدار بیشتری بازی کنم مانند حالت تصادفی
154
00:05:42,419 –> 00:05:44,640
برابر با 7 است، اکنون می توانید ببینید که
155
00:05:44,640 –> 00:05:47,630
مقدار 0.77 است که 77% دقت است
156
00:05:47,630 –> 00:05:49,979
، مطمئن شوید که هر زمان که
157
00:05:49,979 –> 00:05:52,919
این مرحله تصادفی خاص را انتخاب می کنیم، باران بعدی است.
158
00:05:52,919 –> 00:05:54,390
و هفتم e white rain
159
00:05:54,390 –> 00:05:58,320
که از مجموعه داده ای انتخاب می شود که x و
160
00:05:58,320 –> 00:06:01,320
y به صورت تصادفی انتخاب می شود، ما
161
00:06:01,320 –> 00:06:03,270
فقط سعی می کنیم آن داده ها را تکرار
162
00:06:03,270 –> 00:06:05,370
کنیم و داده های قطار x و
163
00:06:05,370 –> 00:06:07,740
داده های باران سفید را با هم انتخاب کنیم و هر
164
00:06:07,740 –> 00:06:09,960
بار که این را تغییر می دهیم. مقدار حالت تصادفی
165
00:06:09,960 –> 00:06:11,789
ما یک حالت افراطی متفاوت دریافت خواهیم کرد
166
00:06:11,789 –> 00:06:15,930
و XY متاسفم x خط تیره دریافت می کنیم، بنابراین برای دیدن
167
00:06:15,930 –> 00:06:17,849
آن داده خاص، اجازه دهید ببینیم که
168
00:06:17,849 –> 00:06:20,550
آزمایش X قطار و X شما چگونه به نظر می رسد خوب است، بنابراین
169
00:06:20,550 –> 00:06:23,669
اول از همه اجازه دهید من فقط این را اجرا کنم تا
170
00:06:23,669 –> 00:06:25,440
بتوانید در حال حاضر ببینید حالت تصادفی من
171
00:06:25,440 –> 00:06:28,080
5 است حالا اجازه دهید
172
00:06:28,080 –> 00:06:29,490
مقدار اضافی در مقدار خورنده را به
173
00:06:29,490 –> 00:06:32,340
محض اجرای مقدار افراطی نمایش دهم، می توانید
174
00:06:32,340 –> 00:06:35,400
ببینید که مقادیر بسیار زیادی وجود دارد، بنابراین اجازه
175
00:06:35,400 –> 00:06:37,650
دهید فقط سر نقطه را بنویسم تا
176
00:06:37,650 –> 00:06:38,190
عدالت
177
00:06:38,190 –> 00:06:41,490
در پنج ردیف بالا وجود داشته باشد، بنابراین اینجاست. اینها
178
00:06:41,490 –> 00:06:43,530
پنج ردیف برتر من هستند، ببینید نمایهها
179
00:06:43,530 –> 00:06:45,930
از این مجموعه داده پایگاه داده
180
00:06:45,930 –> 00:06:47,430
شاخصهای مختلف انتخاب شدهاند و در
181
00:06:47,430 –> 00:06:49,740
مجموعه داده Train ترکیب میشوند،
182
00:06:49,740 –> 00:06:53,070
اکنون کاری که من میخواهم انجام دهم این است
183
00:06:53,070 –> 00:06:55,500
که ردیف اول را جذب کند، فرض کنید
184
00:06:55,500 –> 00:06:58,440
ردیف اول در اینجا سن 46 سال تخمین زده میشود.
185
00:06:58,440 –> 00:07:01,610
حقوق به صورت سنتی 20 حدود 23000
186
00:07:01,610 –> 00:07:04,890
23000 سپس کاری که ما می خواهیم انجام دهیم این است
187
00:07:04,890 –> 00:07:07,050
که همان کد
188
00:07:07,050 –> 00:07:09,210
را کپی کرده و در اینجا قرار می
189
00:07:09,210 –> 00:07:12,330
دهیم، وضعیت تصادفی را به 7 تغییر می دهم بسیار خوب، بنابراین اجازه دهید
190
00:07:12,330 –> 00:07:14,820
من فقط آن را اجرا کنم و آنچه را که می خواهم انجام دهم. m قرار است
191
00:07:14,820 –> 00:07:17,520
انجام دهم این است که
192
00:07:17,520 –> 00:07:20,880
اکنون دوباره مقدار x را می بینم، از X dot head استفاده می کنم تا فقط
193
00:07:20,880 –> 00:07:23,400
پنج ردیف بالا را ببینم، اکنون اجازه دهید
194
00:07:23,400 –> 00:07:25,140
ببینیم اولین مقدار در
195
00:07:25,140 –> 00:07:28,640
نهایت بالا چه بوده و مال من چیست.
196
00:07:28,640 –> 00:07:32,610
من X نوشته بودم که در عوض
197
00:07:32,610 –> 00:07:35,910
آن را به عنوان اضافی اضافه کنم، بنابراین اینجا شدید است،
198
00:07:35,910 –> 00:07:38,580
اکنون مشاهده کنید که سن ارزش اول 44
199
00:07:38,580 –> 00:07:40,890
سال است و ما یک 39000
200
00:07:40,890 –> 00:07:43,260
حقوق تخمین زده شده داریم که اگر اول
201
00:07:43,260 –> 00:07:46,740
به ردیف اول بروم، اساساً سن من 46 س