در این مطلب، ویدئو آموزش یادگیری ماشین پایتون – 7: آموزش و آزمایش داده ها با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,089 –> 00:00:02,250
در این ویدیو ما قصد داریم
2
00:00:02,250 –> 00:00:04,920
نحوه تقسیم مجموعه داده های خود را به آموزش
3
00:00:04,920 –> 00:00:07,649
و آزمایش با استفاده از SQL در روش تقسیم تست قطار بررسی
4
00:00:07,649 –> 00:00:10,920
کنیم، معمولاً وقتی
5
00:00:10,920 –> 00:00:14,849
مجموعه داده ای مانند این دارید، گاهی اوقات
6
00:00:14,849 –> 00:00:18,060
مدل را با استفاده از کل مجموعه داده آموزش می دهیم، اما
7
00:00:18,060 –> 00:00:20,250
این خوب نیست. استراتژی استراتژی خوب
8
00:00:20,250 –> 00:00:22,859
این است که مجموعه داده ها را به
9
00:00:22,859 –> 00:00:26,070
دو قسمت تقسیم کنید که بخشی از
10
00:00:26,070 –> 00:00:28,349
نمونه را برای آموزش واقعی استفاده می کنید و از
11
00:00:28,349 –> 00:00:31,619
نمونه های باقی مانده رنی برای مزه کردن
12
00:00:31,619 –> 00:00:34,920
مدل خود استفاده می کنید و دلیل آن این است که می خواهید از
13
00:00:34,920 –> 00:00:37,770
آن نمونه ها برای چشیدن مدل
14
00:00:37,770 –> 00:00:39,660
هایی که مدل دارد استفاده کنید. قبلا دیده نشده است، به
15
00:00:39,660 –> 00:00:41,760
عنوان مثال در اینجا اگر من از هشت
16
00:00:41,760 –> 00:00:44,219
نمونه اول برای آموزش مدل استفاده کنم و سپس
17
00:00:44,219 –> 00:00:46,620
از دو نمونه باقی مانده برای آزمایش استفاده
18
00:00:46,620 –> 00:00:48,660
کنم، در این صورت ایده خوبی در مورد دقت مدل به دست خواهم آورد
19
00:00:48,660 –> 00:00:50,489
زیرا مدل
20
00:00:50,489 –> 00:00:53,430
قبل از این دو نمونه را ندیده است. مجموعه دادههایی
21
00:00:53,430 –> 00:00:55,469
که برای این تمرین استفاده میکنیم،
22
00:00:55,469 –> 00:01:02,129
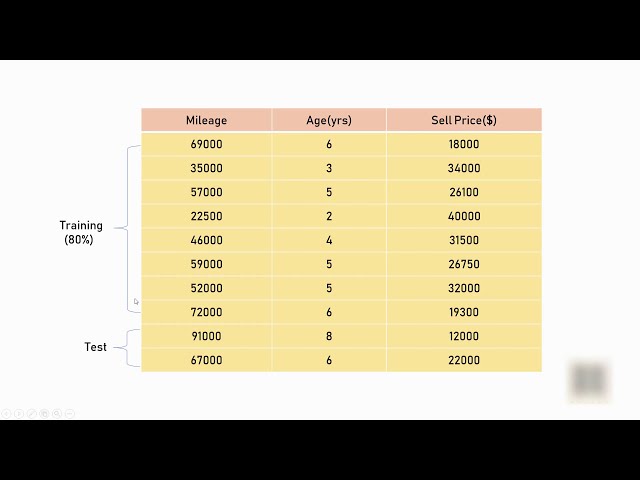
مجموعه دادههای قیمت خودرو BMW است.
23
00:01:02,129 –> 00:01:05,040
24
00:01:05,040 –> 00:01:07,439
25
00:01:07,439 –> 00:01:10,380
26
00:01:10,380 –> 00:01:12,330
ge و قیمت فروش و
27
00:01:12,330 –> 00:01:15,330
در اینجا مسافت پیموده شده و سن متغیرهای مستقل
28
00:01:15,330 –> 00:01:17,909
هستند و قیمت فروش
29
00:01:17,909 –> 00:01:19,979
متغیر وابسته در
30
00:01:19,979 –> 00:01:22,950
نوت بوک Jupiter من است. من این فایل CSV را
31
00:01:22,950 –> 00:01:25,020
در یک قاب داده بارگذاری کرده ام که شبیه به این است
32
00:01:25,020 –> 00:01:28,460
و سپس از تجسم matplotlib استفاده می کنم
33
00:01:28,460 –> 00:01:30,750
تا بفهمم
34
00:01:30,750 –> 00:01:32,700
رابطه بین متغیر وابسته و
35
00:01:32,700 –> 00:01:35,490
مستقل من، بنابراین در اینجا من یک
36
00:01:35,490 –> 00:01:37,860
نمودار مسافت پیموده شده در مقابل قیمت فروش دارم
37
00:01:37,860 –> 00:01:41,040
و می توانید یک رابطه خطی واضح
38
00:01:41,040 –> 00:01:43,799
را در اینجا مشاهده کنید، می توانیم خطی را رسم کنیم
39
00:01:43,799 –> 00:01:45,840
که از تمام این نقاط داده
40
00:01:45,840 –> 00:01:48,960
به طور مشابه برای سن خودرو و قیمت فروش که ترسیم کرده ام عبور می کند.
41
00:01:48,960 –> 00:01:51,210
نمودار پراکندگی دیگری و
42
00:01:51,210 –> 00:01:55,020
در اینجا نیز می توانید به نوعی یک رابطه خطی اعمال کنید،
43
00:01:55,020 –> 00:01:57,869
بنابراین ما می خواهیم از یک
44
00:01:57,869 –> 00:02:00,240
مدل رگرسیون خطی بر اساس
45
00:02:00,240 –> 00:02:03,270
46
00:02:03,270 –> 00:02:07,320
47
00:02:07,320 –> 00:02:12,030
این تجسم استفاده کنیم.
48
00:02:12,030 –> 00:02:12,630
در اینجا این کار این
49
00:02:12,630 –> 00:02:17,940
است که از روش تقسیم طعم آموزشدیده از
50
00:02:17,940 –> 00:02:22,320
انتخاب مدل نقطهای SK استفاده کنید،
51
00:02:22,320 –> 00:02:25,970
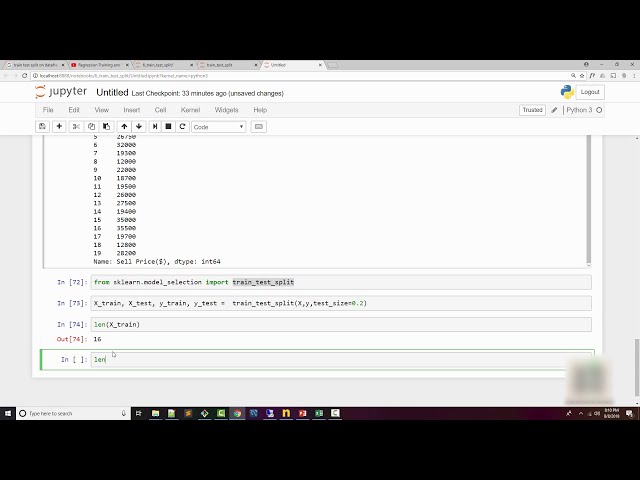
روش تقسیم طعم آموزشدیده را وارد میکنیم و
52
00:02:25,970 –> 00:02:31,980
سپس از این روش استفاده میکنیم که x و y را بهعنوان
53
00:02:31,980 –> 00:02:35,360
یک مورد استفاده میکنیم. قرار دهید و همچنین باید
54
00:02:35,360 –> 00:02:39,600
نسبتی را که با آن پخش می کنید ارائه کنید، بنابراین در اینجا
55
00:02:39,600 –> 00:02:43,110
من می خواهم اندازه مجموعه داده های سلیقه من 20٪
56
00:02:43,110 –> 00:02:45,930
و اندازه مجموعه داده های آموزشی من 80٪ باشد،
57
00:02:45,930 –> 00:02:50,370
بنابراین به این صورت مشخص می کنید که در
58
00:02:50,370 –> 00:02:54,720
نتیجه چه چیزی به دست می آورید. یک مجموعه داده قطار X است
59
00:02:54,720 –> 00:03:00,030
، سپس مجموعه دادههای X طعم، y train و y
60
00:03:00,030 –> 00:03:03,090
طعم، چهار پارامتر را دریافت میکنید، بسیار خوب
61
00:03:03,090 –> 00:03:06,890
و اگر به طول
62
00:03:06,890 –> 00:03:10,800
هر چیزی که دریافت کردهاید نگاه کنید، میبینید که
63
00:03:10,800 –> 00:03:13,560
80 درصد اندازه کل داده شما است، اندازه کل
64
00:03:13,560 –> 00:03:16,920
داده