در این مطلب، ویدئو تست واحد پایتون با Pytest 4 – فیکسچرهای پایتون + روشهای راهاندازی/تجزیه با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:14:42
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,060 –> 00:00:02,340
سلام بچه ها به ویدیوی بعدی در مورد
2
00:00:02,340 –> 00:00:03,750
آزمایش واحد پایتون خوش آمدید برای
3
00:00:03,750 –> 00:00:06,660
مبتدیان که از تست PI استفاده می کنند در این
4
00:00:06,660 –> 00:00:08,189
ویدیو به شما نشان می دهم که چگونه از
5
00:00:08,189 –> 00:00:11,460
فیکسچرها با تست PI استفاده کنید، بنابراین بیایید
6
00:00:11,460 –> 00:00:14,070
شروع کنیم تا از
7
00:00:14,070 –> 00:00:17,400
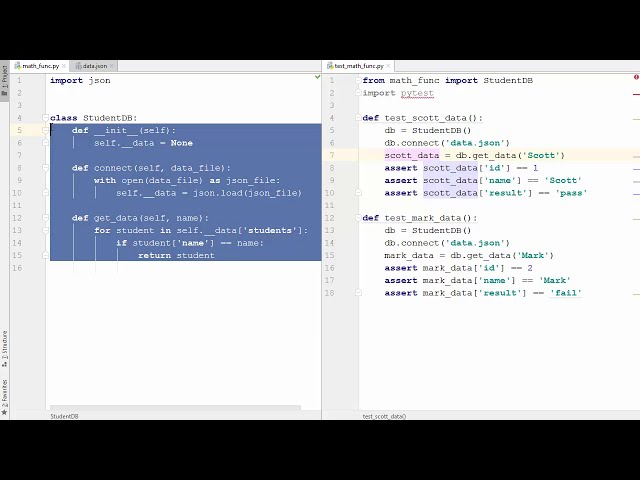
سمت چپ شروع کنیم. این کلاس DB دانشجویی
8
00:00:17,400 –> 00:00:19,529
در حال حاضر همانطور که در اینجا می بینید در
9
00:00:19,529 –> 00:00:22,439
متد init من فقط یک متغیر عضو را مقداردهی اولیه می کنم
10
00:00:22,439 –> 00:00:25,170
که داده برابر با هیچ است
11
00:00:25,170 –> 00:00:28,380
و سپس دو روش دارد یکی
12
00:00:28,380 –> 00:00:31,710
متد اتصال و دیگری متد دریافت داده
13
00:00:31,710 –> 00:00:34,649
اکنون این متد اتصال یکی را می گیرد.
14
00:00:34,649 –> 00:00:37,739
آرگومان که فایل داده است حالا اگر می
15
00:00:37,739 –> 00:00:40,230
توانید در سمت راست ببینید
16
00:00:40,230 –> 00:00:44,460
من دو تست برای این دانش آموز DB نوشته
17
00:00:44,460 –> 00:00:48,539
ام و اول از همه این کلاس را وارد کرده ام
18
00:00:48,539 –> 00:00:51,239
و سپس این
19
00:00:51,239 –> 00:00:54,180
کلاس DB دانش آموز را مقداردهی اولیه کرده ام و سپس اتصال را فراخوانی می کنم.
20
00:00:54,180 –> 00:00:57,090
متد اکنون در اینجا در
21
00:00:57,090 –> 00:00:59,730
آرگومان متد اتصال، من این
22
00:00:59,730 –> 00:01:04,589
نقطه داده JSON را به عنوان آرگومان میدهم، بنابراین اجازه دهید به
23
00:01:04,589 –> 00:01:07,409
شما نشان دهم که این داده نقطهای جیسون شامل چه چیزی است،
24
00:01:07,409 –> 00:01:10,920
بنابراین این نقطهی دادهای jason
25
00:01:10,920 –> 00:01:14,369
حاوی دادههای دانشآموز است، بنابراین
26
00:01:14,369 –> 00:01:17,820
عنصری به نام دانشآموز دارد که حاوی آن است. ns
27
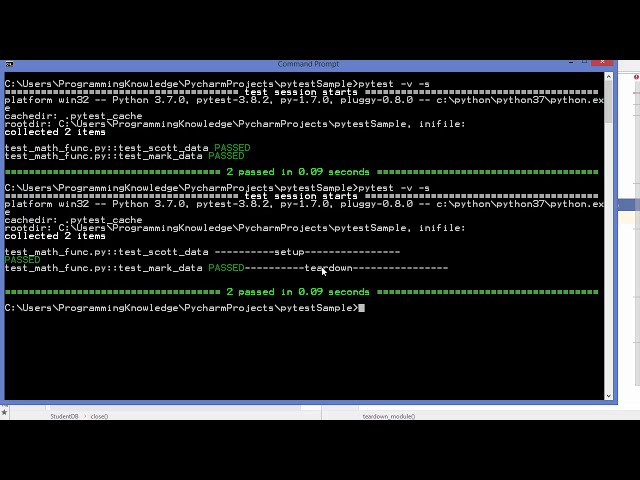
00:01:17,820 –> 00:01:21,540
این آرایه که حاوی دادههای مختلفی
28
00:01:21,540 –> 00:01:24,390
در مورد دانشآموزان مختلف است، بنابراین در حال حاضر
29
00:01:24,390 –> 00:01:29,640
من دو داده دانشآموز در اینجا دارم، یکی ID یکی
30
00:01:29,640 –> 00:01:33,780
Scott Pass و دیگری ID برای علامتگذاری و
31
00:01:33,780 –> 00:01:34,650
شکست است،
32
00:01:34,650 –> 00:01:36,990
بنابراین با استفاده از این روش اتصال، من فقط
33
00:01:36,990 –> 00:01:41,460
فایل JSON نقطه داده را باز میکنم و سپس
34
00:01:41,460 –> 00:01:46,619
من فقط این فایل JSON را به عنوان فرهنگ لغت بارگذاری می کنم،
35
00:01:46,619 –> 00:01:49,200
بنابراین همانطور که در اینجا می بینید، من
36
00:01:49,200 –> 00:01:51,119
از ماژول JSON استفاده می کنم که
37
00:01:51,119 –> 00:01:54,030
در بالا وارد کرده ام و هر زمان که
38
00:01:54,030 –> 00:01:56,549
Jason dot load را صدا می زنم،
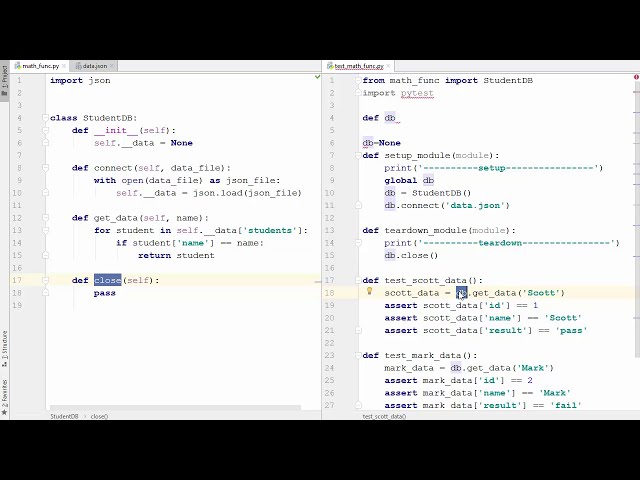
39
00:01:56,549 –> 00:01:59,670
این فایل نقطه JSON را به دیکشنری تبدیل می کند
40
00:01:59,670 –> 00:02:02,670
و سپس من این روش به نام get
41
00:02:02,670 –> 00:02:04,950
data را دارم که یک آرگومان می گیرد
42
00:02:04,950 –> 00:02:08,310
که نام دانش آموز است، حالا این نام
43
00:02:08,310 –> 00:02:10,739
را در فرهنگ لغتی
44
00:02:10,739 –> 00:02:13,770
که با استفاده از connect math سوم به دست آوردم جستجو می کنم
45
00:02:13,770 –> 00:02:16,650
و اگر این نام که به
46
00:02:16,650 –> 00:02:20,100
عنوان آرگومان ارائه شده است در
47
00:02:20,100 –> 00:02:22,830
دادههای دانشجویی موجود است، پس من
48
00:02:22,830 –> 00:02:26,550
فقط این فرهنگ لغت دانشجویی را برمیگردانم، بنابراین یک بار
49
00:02:26,550 –> 00:02:28,200
دیگر همانطور که در اینجا میبینید، فقط
50
00:02:28,200 –> 00:02:31,920
کلاس دانشآموز dot DB را وارد
51
00:02:31,920 –> 00:02:33,990
میکنم و سپس فقط DB دانشجویی را مقداردهی اولیه
52
00:02:33,990 –> 00:02:37,590
میکنم و سپس فقط فراخوانی متد
53
00:02:37,590 –> 00:02:39,720
c alled connect و در متد connect
54
00:02:39,720 –> 00:02:42,900
من نقطه داده JSON را به عنوان آرگومان می دهم
55
00:02:42,900 –> 00:02:44,760
که این فایل
56
00:02:44,760 –> 00:02:47,040
حاوی داده های دانشجویی است و در
57
00:02:47,040 –> 00:02:50,270
مرحله بعد فقط متد get data را
58
00:02:50,270 –> 00:02:54,060
از کلاس دانش آموز DB فراخوانی می کنم.
59
00:02:54,060 –> 00:02:57,510
نام دانشآموزان را در اینجا
60
00:02:57,510 –> 00:02:59,910
میدهید تا ببینید نام دانشآموز
61
00:02:59,910 –> 00:03:02,340
گیر افتاده است، به همین دلیل است که من اسکات را در اینجا میگذارم
62
00:03:02,340 –> 00:03:04,530
و در آزمون بعدی
63
00:03:04,530 –> 00:03:06,960
نام علامت را میگذارم که نام دوم است در اینجا
64
00:03:06,960 –> 00:03:09,960
و سپس با استفاده از این عبارت اظهار نظر من
65
00:03:09,960 –> 00:03:13,560
هستم. فقط بررسی کنید که آیا این شناسه ای که
66
00:03:13,560 –> 00:03:18,240
با استفاده از داده های اسکات به دست آوردم با
67
00:03:18,240 –> 00:03:21,330
شناسه ای که در فایل JSON وجود دارد برابر است یا
68
00:03:21,330 –> 00:03:23,880
نه همان ادعایی که برای
69
00:03:23,880 –> 00:03:26,730
نام دانش آموز نوشته ام و نتیجه دانش آموزان
70
00:03:26,730 –> 00:03:30,630
و آزمون مشابهی که برای نام دوم نوشته ام
71
00:03:30,630 –> 00:03:34,350
یا نه. دانش آموز دوم که
72
00:03:34,350 –> 00:03:37,590
اکنون همانطور که قبلاً دیده اید علامت بزنید
73
00:03:37,590 –> 00:03:40,770
تا کارها ساده تر شود، من به تازگی از
74
00:03:40,770 –> 00:03:45,180
این فایل JSON به عنوان فایل پایگاه داده استفاده کرده ام، اما
75
00:03:45,180 –> 00:03:47,580
در موقعیت های واقعی ممکن است
76
00:03:47,580 –> 00:03:50,730
پایگاه های داده دیگری مانند MySQL
77
00:03:50,730 –> 00:03:53,310
یا PostgreSQL یا MongoDB یا هر پایگاه داده دیگری داشته
78
00:03:53,310 –> 00:03:55,980
باشید. se و ممکن است بخواهید پایگاه داده خود را آزمایش کنید،
79
00:03:55,980 –> 00:03:58,470
بنابراین
80
00:03:58,470 –> 00:04:01,860
هر زمان که می خواهید از پایگاه داده واقعی استفاده کنید می توانید از همان رویکردی استفاده کنید،
81
00:04:01,860 –> 00:04:05,370
بنابراین اول از همه
82
00:04:05,370 –> 00:04:07,920
این تست ها را اجرا کنیم و ببینیم
83
00:04:07,920 –> 00:04:09,900
نتیجه اینجا چیست، بنابراین من فقط
84
00:04:09,900 –> 00:04:12,360
این تست ها را اجرا می کنم. و شما می توانید هر دو تست
85
00:04:12,360 –> 00:04:15,480
را در اینجا ببینید اکنون اجازه دهید در مورد
86
00:04:15,480 –> 00:04:19,140
مشکلات این دو تست صحبت کنیم،
87
00:04:19,140 –> 00:04:21,690
اکنون ممکن است حدس زده باشید که
88
00:04:21,690 –> 00:04:24,090
ما خودمان را تکرار می کنیم، بنابراین ما
89
00:04:24,090 –> 00:04:27,000
این پایگاه داده را دو بار برای دو تست مقداردهی اولیه می کنیم،
90
00:04:27,000 –> 00:04:27,570
91
00:04:27,570 –> 00:04:30,930
اما فرض کنید هزاران و هزاران تست داریم.
92
00:04:30,930 –> 00:04:33,660
آزمایش می کند، سپس باید
93
00:04:33,660 –> 00:04:35,850
این پایگاه داده را هزار بار مقداردهی اولیه کنید،
94
00:04:35,850 –> 00:04:38,820
بنابراین مشکل اول
95
00:04:38,820 –> 00:04:41,400
تکرار کد است، مشکل دوم این است که
96
00:04:41,400 –> 00:04:44,100
هر زمان که می خواهید پایگاه داده خود را مقداردهی اولیه کنید،
97
00:04:44,100 –> 00:04:47,030
به عنوان مثال هزاران بار که این
98
00:04:47,030 –> 00:04:49,280
مقداردهی اولیه منابع فشرده هستند،
99
00:04:49,280 –> 00:04:53,130
بنابراین برای سیستم شما که در آن هستید گران تر خواهد بود.
100
00:04:53,130 –> 00:04:55,440
این موارد تست را اجرا کنید
101
00:04:55,440 –> 00:04:58,860
زیرا آنها منابع شما را مصرف
102
00:04:58,860 –> 00:05:01,710
می کنند، بنابراین راه حل
103
00:05:01,710 –> 00:05:04,200
اینجا چیست تا بتوانید از دو نوع
104
00:05:04,200 –> 00:05:07,440
راه حل در این نوع موارد استفاده کنید.
105
00:05:07,440 –> 00:05:10,230
اولین رویکرد با استفاده از روشهای راهاندازی و حذف است،
106
00:05:10,230 –> 00:05:13,140
اکنون
107
00:05:13,140 –> 00:05:15,990
108
00:05:15,990 –> 00:05:20,610
اگر
109
00:05:20,610 –> 00:05:23,460
با سایر چارچوبهای آزمایشی
110
00:05:23,460 –> 00:05:27,420
مانند تستهای واحد آشنا هستید یا میدانید این روشها
111
00:05:27,420 –> 00:05:30,810
ممکن است برای شما آشنا باشند، این روش راهاندازی و حذف در دسته راهاندازی سبک xunit کلاسیک قرار میگیرد.
112
00:05:30,810 –> 00:05:32,940
همه ما نحوه حل این مشکل را
113
00:05:32,940 –> 00:05:36,810
با استفاده از روشهای راهاندازی و حذف
114
00:05:36,810 –> 00:05:38,880
میبینیم و سپس خواهیم دید که چگونه
115
00:05:38,880 –> 00:05:42,990
با استفاده از فیکسچرهای تست PI این مشکل را حل کنیم، بنابراین از
116
00:05:42,990 –> 00:05:45,000
قبل مشکل را میدانیم، بنابراین برای حل
117
00:05:45,000 –> 00:05:49,080
آن روشی به نام
118
00:05:49,080 –> 00:05:52,110
راهاندازی و ماژول حذف وجود دارد. روش، بنابراین من
119
00:05:52,110 –> 00:05:55,820
فقط میخواهم ماژول underscore setup را بنویسم
120
00:05:55,820 –> 00:05:59,250
و این یک آرگومان میگیرد که
121
00:05:59,250 –> 00:06:03,690
اژول است و سپس در اینجا در داخل این رو
122
00:06:03,690 –> 00:06:07,080
میتوانید منابع خود را مقداردهی اولیه کنید، بن
123
00:06:07,080 –> 00:06:11,910
براین اجازه دهید من یک متغیر DB جهانی تعریف کن
124
00:06:11,910 –> 00:06:15,000
و آن را با هیچ مقداردهی اولیه کن
125
00:06:15,000 –> 00:06:19,200
. سپس من فقط از این
126
00:06:19,200 –> 00:06:21,930
مقداردهی اولیه در داخل این ماژول راه اندازی استفاده می کنم،
127
00:06:21,930 –> 00:06:24,840
بنابراین هر زمان که ماژول راه اندازی را
128
00:06:24,840 –> 00:06:27,660
همانطور که هست بنویسید، تست PI
129
00:06:27,660 –> 00:06:30,900
متوجه می شود که این یک روش راه اندازی است
130
00:06:30,900 –> 00:06:33,750
و من t قرار است این کد را
131
00:06:33,750 –> 00:06:36,930
قبل از اجرای تست های شما اجرا کند، بنابراین کاری که
132
00:06:36,930 –> 00:06:39,260
من انجام دادم این است که متغیر DB جهانی را تعریف کرده
133
00:06:39,260 –> 00:06:41,280
134
00:06:41,280 –> 00:06:44,760
ام یعنی باید در
135
00:06:44,760 –> 00:06:46,950
روش تنظیم نشان دهم که این متغیر جهانی
136
00:06:46,950 –> 00:06:50,880
است و این بدان معناست که اکنون در داخل این
137
00:06:50,880 –> 00:06:55,110
DB ما نمونه پایگاه داده خود را داریم. بنابراین اکنون
138
00:06:55,110 –> 00:06:57,480
در این دو مورد آزمایشی به این مقداردهی اولیه نیاز نداریم
139
00:06:57,480 –> 00:07:00,120
و اکنون میتوانیم از
140
00:07:00,120 –> 00:07:04,040
این نمونه DB برای فراخوانی متد دریافت داده
141
00:07:04,040 –> 00:07:07,770
برای دریافت دادههای مربوط به دانشآموز خاص استفاده کنیم،
142
00:07:07,770 –> 00:07:10,050
بنابراین این
143
00:07:10,050 –> 00:07:12,240
روش ماژول
144
00:07:12,240 –> 00:07:15,419
راهاندازی است. می توانید در اینجا تعریف کنید، بنابراین فقط
145
00:07:15,419 –> 00:07:18,450
ماژول زیر خط d EF teardown را بنویسید و سپس
146
00:07:18,450 –> 00:07:22,290
در داخل پرانتز
147
00:07:22,290 –> 00:07:25,200
ماژول را به عنوان آرگومان می دهید و در داخل
148
00:07:25,200