در این مطلب، ویدئو 2 آموزش رگرسیون خطی ساده با پاندای پایتون، اسکلارن، سیبورن، متپلیب با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:15:23
تصاویر این ویدئو:
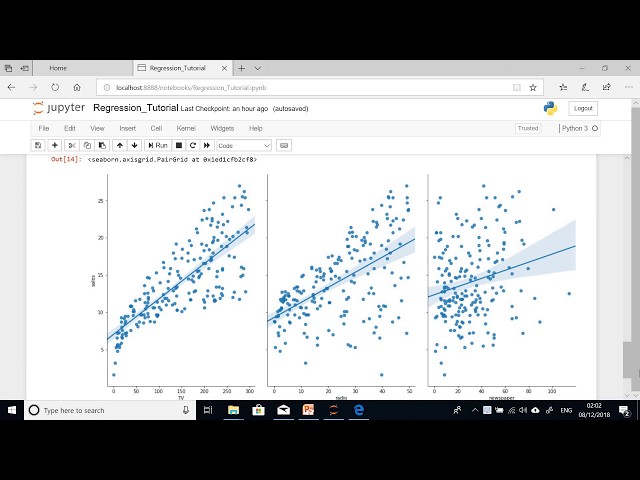
قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:02,909
بسیار خوب، بنابراین ما از همان جایی که
2
00:00:02,909 –> 00:00:05,190
از آموزش اول متوقف شده بودیم ادامه می دهیم، بنابراین
3
00:00:05,190 –> 00:00:07,500
سعی می کنیم رگرسیون خطی را
4
00:00:07,500 –> 00:00:12,660
در یک سایت بتا به این روش انجام دهیم، بنابراین روزنامه رادیویی تلویزیون داشته باشید
5
00:00:12,660 –> 00:00:15,179
و سپس سلول هایی داشته باشیم، بنابراین
6
00:00:15,179 –> 00:00:17,310
ایده پشت آن این است که ما سعی می کنیم
7
00:00:17,310 –> 00:00:22,080
ببینیم چگونه روزنامه و رادیو تلویزیون
8
00:00:22,080 –> 00:00:24,539
سلولهای جعلی هستند، بنابراین اساساً ما
9
00:00:24,539 –> 00:00:27,180
شرکتی داریم که در
10
00:00:27,180 –> 00:00:30,029
کانالهای مختلف مانند روزنامه تلویزیون
11
00:00:30,029 –> 00:00:33,059
و رادیو و رادیو تبلیغات میکند و سپس میبیند که چگونه
12
00:00:33,059 –> 00:00:36,390
روی سلولها تأثیر میگذارد، به من اجازه میدهد
13
00:00:36,390 –> 00:00:39,200
مشکل ضایعات را کاهش
14
00:00:42,230 –> 00:00:45,480
دهم، بنابراین ما موفق شدیم. انجام
15
00:00:45,480 –> 00:00:47,640
جفت نمودارها و این همان چیزی است که در اینجا نشان داده شده
16
00:00:47,640 –> 00:00:51,210
است، بنابراین اگر نمی توانید به یاد داشته باشید، مرحله 5 را تکمیل کردیم،
17
00:00:51,210 –> 00:00:52,520
18
00:00:52,520 –> 00:00:55,980
بنابراین مرحله 6 اکنون می خواهیم
19
00:00:55,980 –> 00:00:58,440
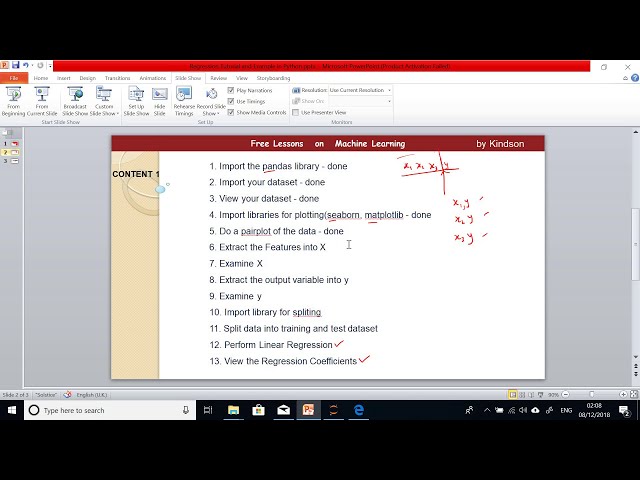
ویژگی ها را استخراج کنیم بنابراین می خواهیم ویژگی ها را استخراج
20
00:00:58,440 –> 00:01:00,870
کنیم به این معنی که می خواهیم
21
00:01:00,870 –> 00:01:04,409
ویژگی ها را از هم جدا کنیم. ویژگی ها
22
00:01:04,409 –> 00:01:07,979
به این سه مورد اشاره دارد روزنامه رادیویی تلویزیون
23
00:01:07,979 –> 00:01:10,860
آنها بیشتر شبیه
24
00:01:10,860 –> 00:01:13,740
متغیرهای مستقل هستند بنابراین سلول داریم
25
00:01:13,740 –> 00:01:16,380
متغیرهای وابسته است بنابراین در
26
00:01:16,380 –> 00:01:18,360
زبان یادگیری ماشین
27
00:01:18,360 –> 00:01:20,729
به جای اینکه بگوییم مستقل به آن ویژگی می گوییم.
28
00:01:20,729 –> 00:01:23,250
متغیرهای ent میگوییم ویژگیها و سلولهایی را
29
00:01:23,250 –> 00:01:25,439
که آن را متغیر خروجی میگوییم
30
00:01:25,439 –> 00:01:30,119
متغیر هدف یا نتیجه یا
31
00:01:30,119 –> 00:01:33,840
پاسخ نیز بسیار خوب است، بنابراین کاری که
32
00:01:33,840 –> 00:01:37,070
میخواهیم انجام دهیم این است که
33
00:01:37,070 –> 00:01:40,110
ببینیم یک pearpod ویژگیها را کاملاً استخراج کردهایم،
34
00:01:40,110 –> 00:01:44,189
پس بیایید ببینید چگونه این کار را انجام دهیم.
35
00:01:44,189 –> 00:01:45,570
36
00:01:45,570 –> 00:01:48,180
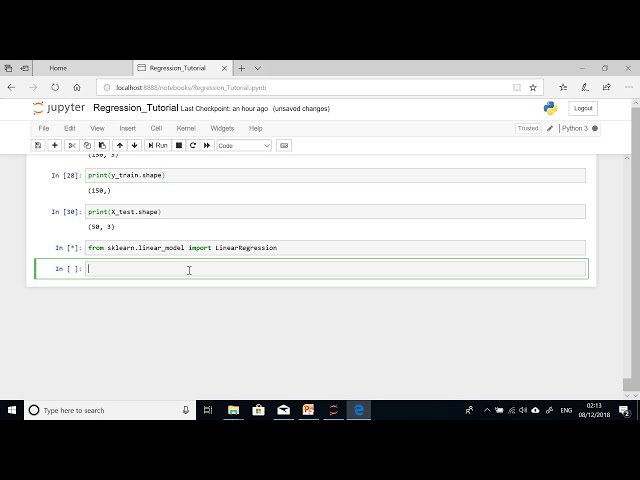
[موسیقی]
37
00:01:48,180 –> 00:01:56,729
را با مشخص کردن ویژگیها شروع میکنیم، بنابراین ویژگیها
38
00:01:56,850 –> 00:02:00,970
بله، ستونهای ویژگی باید یک رادیو تلویزیونی باشند
39
00:02:00,970 –> 00:02:03,369
و روزنامهها ستونهای آینده هستند،
40
00:02:03,369 –> 00:02:05,920
بنابراین هر بار که
41
00:02:05,920 –> 00:02:08,979
میخواهید موردی را در یک مجموعه قرار دهید، همیشه
42
00:02:08,979 –> 00:02:13,420
در پرانتز قرار دهید. ما
43
00:02:13,420 –> 00:02:16,900
در این رادیو تلویزیون زیر خوبی داریم و رادیو بعدی
44
00:02:16,900 –> 00:02:20,430
خوب است روزنامه است ما درست حدس زدیم،
45
00:02:20,430 –> 00:02:24,250
بنابراین ستون های ویژگی را درست می سازد،
46
00:02:24,250 –> 00:02:29,650
بنابراین من می خواهم روی run کلیک
47
00:02:29,650 –> 00:02:32,410
کنم خوب همه چیز خوب پیش رفت حالا می
48
00:02:32,410 –> 00:02:41,170
خواهم بگویم این است که X اکنون دادهای از
49
00:02:41,170 –> 00:02:47,230
این ستونها خواهد بود، امیدوارم متوجه شده باشید، بنابراین
50
00:02:47,230 –> 00:02:50,410
ما تعریف میکنیم که این ستونهای
51
00:02:50,410 –> 00:02:53,380
داده، ستونهای آینده هستند که میخواهیم
52
00:02:53,380 –> 00:02:58,120
از آنها برای تشکیل دادههای جدید استفاده کنیم، مثلاً X، بنابراین در
53
00:02:58,120 –> 00:03:00,340
خط دوم میگوییم که داده st.
54
00:03:00,340 –> 00:03:03,609
X زیرمجموعه ای از داده های ما است
55
00:03:03,609 –> 00:03:07,120
به خاطر داشته باشید که داده ها حاوی همه چیز هستند، بنابراین
56
00:03:07,120 –> 00:03:09,130
اکنون ما از داده ها می گیریم،
57
00:03:09,130 –> 00:03:11,739
این سه ستون را می گیریم، بنابراین من
58
00:03:11,739 –> 00:03:13,840
واقعاً می توانستم آن را در یک خط انجام
59
00:03:13,840 –> 00:03:18,010
دهم، اما من آن را انجام می دهم که شما در
60
00:03:18,010 –> 00:03:24,450
خط قرار دهید تا ما یک خطای X برابر است با
61
00:03:24,450 –> 00:03:30,389
میگوید یک عدد صحیح بولی یا فانتزی اضافه کنید خوب
62
00:03:30,389 –> 00:03:33,730
روزنامه، میتوانید این روزنامه را کاملاً ببینید،
63
00:03:33,730 –> 00:03:37,209
بنابراین من میخواهم اجرا کنم و
64
00:03:37,209 –> 00:03:41,910
دوباره اجرا میکنم، اگر هم بگویم x
65
00:03:41,910 –> 00:03:45,850
برابر است اکنون من هستم قرار است همه چیز را
66
00:03:45,850 –> 00:03:49,889
در یک ردیف قرار دهم،
67
00:03:55,460 –> 00:04:06,180
بنابراین میخواهم بگویم رادیو تلویزیون و روزنامه، بنابراین
68
00:04:06,180 –> 00:04:11,340
یک پرانتز دیگر در اطراف آن قرار میدهم، بنابراین
69
00:04:11,340 –> 00:04:13,350
این همان خطی است که در لی وجود دارد،
70
00:04:13,350 –> 00:04:16,140
با این دو خط یکسان است.
71
00:04:16,140 –> 00:04:21,269
خوب است، پس حالا بیایید ببینیم
72
00:04:21,269 –> 00:04:24,570
در متن چه چیزی وجود دارد، بنابراین من به شما
73
00:04:24,570 –> 00:04:28,260
در مورد تابعی گفتم که X dot heads است، به طوری
74
00:04:28,260 –> 00:04:30,840
که نفرت پنج مورد اول را
75
00:04:30,840 –> 00:04:33,840
در دید داده نشان می دهد، بنابراین بیایید ببینیم
76
00:04:33,840 –> 00:04:37,470
در تخم مرغ ها چه
77
00:04:37,470 –> 00:04:47,960
چیزی وجود دارد. X فقط X و سپس oh oh اجرا کنید،
78
00:04:47,960 –> 00:04:53,280
بنابراین به یاد داشته باشید که ما باید داده ها را در اینجا قرار
79
00:04:53,280 –> 00:04:55,380
دهیم تا مشکل اینجا باشد
80
00:04:55,380 –> 00:04:57,870
من می خواهم این را اجرا کنم و
81
00:04:57,870 –> 00:05:01,920
این را اجرا کنم تا X فقط
82
00:05:01,920 –> 00:05:04,980
ویژگی ها یا متغیرهای مستقل را داشته باشد
83
00:05:04,980 –> 00:05:08,000
روزنامه رادیویی تلویزیون و این خیلی خوب است،
84
00:05:08,000 –> 00:05:11,730
بنابراین بیایید ببینیم در این کجا هستیم.
85
00:05:11,730 –> 00:05:14,670
ویژگیهای ساختاری
86
00:05:14,670 –> 00:05:17,670
که ما آن را انجام دادهایم و همچنین نحوه
87
00:05:17,670 –> 00:05:19,230
بررسی ما طول میکشد بله،
88
00:05:19,230 –> 00:05:22,640
ما X را فرض میکنیم، بنابراین این کار را نیز انجام دادهایم،
89
00:05:22,640 –> 00:05:26,040
بنابراین کار بعدی که میخواهم انجام دهم
90
00:05:26,040 –> 00:05:28,650
استخراج متغیر خروجی Y و همچنین
91
00:05:28,650 –> 00:05:31,290
بررسی آن در این I است. می توانم اطمینان داشته
92
00:05:31,290 –> 00:05:34,860
باشید که می توانید این کار را انجام دهید، بنابراین کاری که من می توانم انجام دهم این است
93
00:05:34,860 –> 00:05:39,180
که آن را کپی کنم تا این را کپی کنم و سپس از آن استفاده کنم،
94
00:05:39,180 –> 00:05:41,850
اما بیایید آن را بنویسیم تا هر چه
95
00:05:41,850 –> 00:05:45,990
بیشتر بنویسیم، تاریخ بیشتری به دست می آوریم، بنابراین در
96
00:05:45,990 –> 00:05:48,210
تمام این مدت چه کاری انجام خواهم داد. فقط
97
00:05:48,210 –> 00:05:56,730
می توان گفت y برابر است با داده های دستور دادن به سلول
98
00:05:56,730 –> 00:05:59,400
های ستون just cell و این خوب است،
99
00:05:59,400 –> 00:06:03,680
بنابراین اگر من اجرا کنم خوب است، بنابراین اگر بگویم Y و
100
00:06:03,680 –> 00:06:07,860
روی run کلیک کنم، فقط مقدار Y را نشان می دهد
101
00:06:07,860 –> 00:06:08,670
102
00:06:08,670 –> 00:06:12,990
درست است بسیار خوب بنابراین 1/2 X و ما داریم
103
00:06:12,990 –> 00:06:19,200
Y پس بیایید ببینیم ما در کجا هستیم تقریباً تمام
104
00:06:19,200 –> 00:06:23,700
شده است، بنابراین Y را به y استخراج کردیم و
105
00:06:23,700 –> 00:06:25,860
تخم مرغ نیز داریم، بنابراین ما با
106
00:06:25,860 –> 00:06:28,050
اینها امتحان کردیم برای اینکه ببینیم چگونه
107
00:06:28,050 –> 00:06:29,880
به نظر میرسد، اکنون
108
00:06:29,880 –> 00:06:32,310
کتابخانهای را وارد میکنیم که میخواهیم از آن برای تقسیم استفاده
109
00:06:32,310 –> 00:06:35,310
کنیم، زیرا در واقع میخواهیم
110
00:06:35,310 –> 00:06:38,130
دادهها را به سایتهای داده اولیه و
111
00:06:38,130 –> 00:06:41,760
سایت دادههای آموزشی تقسیم کنیم، بنابراین برای انجام این کار از SK میگویم.
112
00:06:41,760 –> 00:06:44,960
خط SK خط یک کتابخانه یادگیری ماشینی
113
00:06:44,960 –> 00:06:48,600
در پایتون است که میتوانید برای
114
00:06:48,600 –> 00:06:54,090
تقسیم دادههای خود به دادههای رابط
115
00:06:54,090 –> 00:06:58,440
و دادههای آموزشی از انت