در این مطلب، ویدئو آموزش PySpark MLlib | یادگیری ماشین در آپاچی اسپارک | آموزش PySpark | ادورکا با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:01,730 –> 00:00:06,589
[موسیقی]
2
00:00:06,589 –> 00:00:08,940
یادگیری ماشینی پیشرفتهای بسیاری را پشت سر گذاشته است
3
00:00:08,940 –> 00:00:11,219
و
4
00:00:11,219 –> 00:00:13,380
روز به روز محبوبتر میشود.
5
00:00:13,380 –> 00:00:15,089
6
00:00:15,089 –> 00:00:17,279
7
00:00:17,279 –> 00:00:19,199
8
00:00:19,199 –> 00:00:21,750
9
00:00:21,750 –> 00:00:23,550
اسپارک
10
00:00:23,550 –> 00:00:25,140
وارد بازی یادگیری ماشین با
11
00:00:25,140 –> 00:00:27,480
پایتون شد، پس بچه ها این هوای کریستالی از
12
00:00:27,480 –> 00:00:29,369
ed Rekha است و موضوع
13
00:00:29,369 –> 00:00:31,949
بحث امروز PI spark MLM است، بنابراین
14
00:00:31,949 –> 00:00:34,050
بیایید نگاهی گذرا به دستور کار امروز داشته باشیم.
15
00:00:34,050 –> 00:00:35,550
16
00:00:35,550 –> 00:00:37,230
مقدمه کوتاهی بر یادگیری ماشین
17
00:00:37,230 –> 00:00:39,480
با پیاده سازی های مختلف آن در
18
00:00:39,480 –> 00:00:41,489
صنعت در ادامه سه
19
00:00:41,489 –> 00:00:43,140
حوزه اصلی یادگیری ماشین را که
20
00:00:43,140 –> 00:00:45,420
بدون نظارت بر آن نظارت می شود و
21
00:00:45,420 –> 00:00:47,370
یادگیری تقویتی را مورد بحث قرار خواهم داد، در ادامه صحبت خواهم کرد
22
00:00:47,370 –> 00:00:49,649
که چگونه MLF نقش مهمی در محیط SPARC ایفا می
23
00:00:49,649 –> 00:00:51,719
کند و به پایان می رسد. این
24
00:00:51,719 –> 00:00:54,600
ویدیو با یک نسخه نمایشی در PI SPARC MLM، بنابراین
25
00:00:54,600 –> 00:00:56,789
بیایید اکنون شروع کنیم که دقیقاً
26
00:00:56,789 –> 00:00:58,680
یادگیری ماشینی چیست؟
27
00:00:58,680 –> 00:01:00,960
تجزیه و تحلیل پیران که
28
00:01:00,960 –> 00:01:03,149
ساخت مدل تحلیلی را با استفاده از الگوریتمهایی که به
29
00:01:03,149 –> 00:01:05,400
طور مکرر از یادگیری ماشین دادهها یاد گرفتهاند خودکار میکند،
30
00:01:05,400 –> 00:01:07,229
به رایانهها این امکان را میدهد تا بینشهای پنهان را
31
00:01:07,229 –> 00:01:09,210
بدون
32
00:01:09,210 –> 00:01:11,400
برنامهریزی صریح در کجا نگاه کنند،
33
00:01:11,400 –> 00:01:13,080
بر توسعه برنامههای رایانهای تمرکز
34
00:01:13,080 –> 00:01:14,970
میکند که میتوانند رشد و
35
00:01:14,970 –> 00:01:17,369
تغییر را در هنگام قرار گرفتن در معرض دادههای جدید آموزش دهند.
36
00:01:17,369 –> 00:01:19,170
یادگیری ماشینی از دادهها برای شناسایی
37
00:01:19,170 –> 00:01:20,939
الگوها در مجموعه داده استفاده میکند و فقط
38
00:01:20,939 –> 00:01:23,340
اقدامات را بر این اساس برنامهریزی میکند، بیشتر
39
00:01:23,340 –> 00:01:24,750
صنایعی که با مقادیر
40
00:01:24,750 –> 00:01:26,549
زیادی داده کار میکنند، ارزش
41
00:01:26,549 –> 00:01:28,560
فناوری یادگیری ماشینی را با پاک کردن
42
00:01:28,560 –> 00:01:30,360
بینشها از این دادهها که اغلب در
43
00:01:30,360 –> 00:01:32,759
سازمانهای بیدرنگ قادر به انجام آن هستند، تشخیص دادهاند. کارآمدتر کار کنید
44
00:01:32,759 –> 00:01:34,740
یا
45
00:01:34,740 –> 00:01:37,740
نسبت به رقبا برتری پیدا کنید اکنون اجازه دهید نگاهی
46
00:01:37,740 –> 00:01:39,329
به صنعت مختلفی بیندازیم که در آن
47
00:01:39,329 –> 00:01:41,130
یادگیری ماشینی مورد استفاده قرار گرفته است.
48
00:01:41,130 –> 00:01:43,229
49
00:01:43,229 –> 00:01:44,880
50
00:01:44,880 –> 00:01:46,799
51
00:01:46,799 –> 00:01:48,750
52
00:01:48,750 –> 00:01:51,869
وب سایت های بازاریابی و فروش در حال حاضر
53
00:01:51,869 –> 00:01:54,090
توصیه اقلامی که ممکن است بر
54
00:01:54,090 –> 00:01:55,770
اساس خرید قبلی بپسندید، از یادگیری ماشین استفاده کنید،
55
00:01:55,770 –> 00:01:57,960
آنها از آن برای تجزیه و تحلیل
56
00:01:57,960 –> 00:01:59,880
تاریخچه خرید شما و تبلیغ سایر
57
00:01:59,880 –> 00:02:02,040
مواردی که علاقه مند به آنها هستید استفاده می کنند، اکنون تجزیه و تحلیل
58
00:02:02,040 –> 00:02:04,350
داده ها برای شناسایی الگوها و روندها،
59
00:02:04,350 –> 00:02:06,000
کلید صنعت حمل و نقل است
60
00:02:06,000 –> 00:02:08,160
که بر ایجاد مسیرها متکی است.
61
00:02:08,160 –> 00:02:09,720
کارآمدتر و محافظت از
62
00:02:09,720 –> 00:02:11,640
مشکلات بالقوه برای افزایش سودآوری
63
00:02:11,640 –> 00:02:13,750
در حال حاضر به بانکهای خدمات مالی
64
00:02:13,750 –> 00:02:15,220
و سایر مشاغل در
65
00:02:15,220 –> 00:02:17,260
صنعت مالی از فناوری یادگیری ماشین
66
00:02:17,260 –> 00:02:20,050
برای دو هدف کلیدی استفاده میکنند، هدف
67
00:02:20,050 –> 00:02:21,640
اول شناسایی
68
00:02:21,640 –> 00:02:23,590
بینشهای مهم در دادهها و
69
00:02:23,590 –> 00:02:25,510
دومی جلوگیری از تقلب است.
70
00:02:25,510 –> 00:02:27,130
71
00:02:27,130 –> 00:02:28,630
72
00:02:28,630 –> 00:02:30,370
به لطف ظهور
73
00:02:30,370 –> 00:02:32,380
دستگاههای متغیر و حسگرهایی که
74
00:02:32,380 –> 00:02:34,240
میتوانند از دادهها برای دسترسی به
75
00:02:34,240 –> 00:02:36,280
سلامت بیمار در زمان واقعی استفاده کنند، در نهایت در
76
00:02:36,280 –> 00:02:38,170
بخش بیومتریک علم
77
00:02:38,170 –> 00:02:39,730
ایجاد هویت یک
78
00:02:39,730 –> 00:02:41,350
فرد بر اساس ویژگی
79
00:02:41,350 –> 00:02:43,360
شیمیایی فیزیکی یا رفتار
80
00:02:43,360 –> 00:02:45,100
خصوصیات شخص یکی از مهمترین
81
00:02:45,100 –> 00:02:46,959
مزیت های کلیدی یادگیری ماشین در
82
00:02:46,959 –> 00:02:49,480
حوزه بیومتریک است، حال بیایید نگاهی به
83
00:02:49,480 –> 00:02:51,790
یک چرخه زندگی معمولی یادگیری
84
00:02:51,790 –> 00:02:53,470
85
00:02:53,470 –> 00:02:55,840
86
00:02:55,840 –> 00:02:57,640
ماشین بیندازیم. برای
87
00:02:57,640 –> 00:02:59,739
آموزش ما از 70 تا 80
88
00:02:59,739 –> 00:03:01,810
درصد داده ها استفاده می کنیم و بقیه داده
89
00:03:01,810 –> 00:03:04,090
ها برای اهداف آزمایشی استفاده می شود، بنابراین ابتدا
90
00:03:04,090 –> 00:03:06,160
داده ها را آموزش می دهیم و شما از هر
91
00:03:06,160 –> 00:03:08,230
الگوریتم خاصی برای آموزش داده ها
92
00:03:08,230 –> 00:03:10,690
استفاده می کنید و با استفاده از آن الگوریتم ما اکنون یک مدل تولید می کنیم.
93
00:03:10,690 –> 00:03:12,489
پس از آن،
94
00:03:12,489 –> 00:03:14,890
ما مدل خود را تولید کردیم، اکنون بیست تا
95
00:03:14,890 –> 00:03:16,450
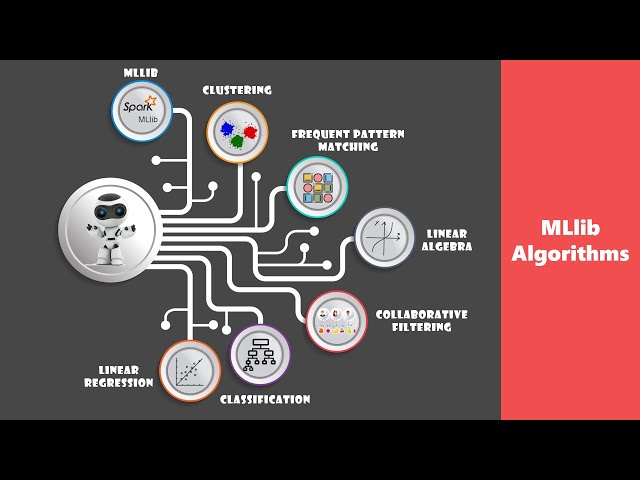
سی درصد داده های باقی مانده برای
96
00:03:16,450 –> 00:03:18,580
اهداف آزمایشی استفاده می شود، ما این داده ها را
97
00:03:18,580 –> 00:03:20,590
به مدل منتقل می کنیم و
98
00:03:20,590 –> 00:03:22,600
با آزمایش های خاص به دقت آن مدل پی می بریم،
99
00:03:22,600 –> 00:03:24,820
اکنون این همان چیزی است که یک یادگیری ماشین معمولی
100
00:03:24,820 –> 00:03:27,250
است. به نظر می رسد که
101
00:03:27,250 –> 00:03:28,600
اکنون سه دسته اصلی از
102
00:03:28,600 –> 00:03:30,850
یادگیری ماشینی وجود دارد که قبلاً ذکر کردم
103
00:03:30,850 –> 00:03:32,980
که تقویت نظارت شده و
104
00:03:32,980 –> 00:03:34,570
یادگیری بدون نظارت هستند، بنابراین بیایید
105
00:03:34,570 –> 00:03:36,280
اینها را درک کنیم. اصطلاحات با جزئیات
106
00:03:36,280 –> 00:03:38,650
شروع از
107
00:03:38,650 –> 00:03:40,120
یادگیری نظارت شده، الگوریتم های یادگیری نظارت شده
108
00:03:40,120 –> 00:03:42,459
با استفاده از مثال های برچسب مانند
109
00:03:42,459 –> 00:03:44,500
ورودی که در آن خروجی مورد نظر مشخص است
110
00:03:44,500 –> 00:03:46,660
آموزش داده می شود، الگوریتم یادگیری مجموعه ای از
111
00:03:46,660 –> 00:03:48,400
ورودی ها را به همراه خروجی های صحیح مربوطه دریافت می
112
00:03:48,400 –> 00:03:50,500
کند و الگوریتم
113
00:03:50,500 –> 00:03:52,810
با مقایسه خروجی واقعی خود با
114
00:03:52,810 –> 00:03:54,910
خروجی صحیح برای یافتن خطاها، سپس
115
00:03:54,910 –> 00:03:56,709
مدل را بر این اساس از طریق
116
00:03:56,709 –> 00:03:58,350
روشهایی مانند پیشبینی رگرسیون طبقهبندی
117
00:03:58,350 –> 00:04:00,420
و تقویت گرادیان
118
00:04:00,420 –> 00:04:02,590
یادگیری نظارتشده برای
119
00:04:02,590 –> 00:04:04,510
پیشبینی مقادیر هر برچسب روی
120
00:04:04,510 –> 00:04:06,640
دادههای بدون برچسب اضافی، اصلاح میکند،
121
00:04:06,640 –> 00:04:08,260
زیرا
122
00:04:08,260 –> 00:04:09,940
فرآیند یادگیری الگوریتم از
123
00:04:09,940 –> 00:04:11,950
مجموعه داده های آموزشی را می توان به عنوان
124
00:04:11,950 –> 00:04:13,989
معلمی در نظر گرفت که بر فرآیند یادگیری نظارت می کند
125
00:04:13,989 –> 00:04:15,880
اکنون یادگیری تحت نظارت عمدتاً
126
00:04:15,880 –> 00:04:18,209
به دو دسته تقسیم می شود:
127
00:04:18,209 –> 00:04:20,079
طبقه بندی ها و
128
00:04:20,079 –> 00:04:22,599
الگوریتم های رگرسیون رگرسیون مشکل
129
00:04:22,599 –> 00:04:24,430
تخمین عملکرد یک
130
00:04:24,430 –> 00:04:25,800
131
00:04:25,800 –> 00:04:28,500
کمیت پیوسته است که ارزش S&P 500 یک ماه خواهد بود.
132
00:04:28,500 –> 00:04:30,659
از امروز قد یک
133
00:04:30,659 –> 00:04:32,819
کودک در بزرگسالی چقدر
134
00:04:32,819 –> 00:04:34,590
خواهد بود که امسال چه تعداد از مشتریان برای یک رقیب ترک خواهند کرد،
135
00:04:34,590 –> 00:04:36,629
اینها نمونه هایی از سوالاتی است که
136
00:04:36,629 –> 00:04:38,190
در زیر چتر
137
00:04:38,190 –> 00:04:40,080
رگرسیون قرار می گیرند و اکنون به طبقه
138
00:04:40,080 –> 00:04:42,270
بندی طبقه بندی می رسند و با تخصیص
139
00:04:42,270 –> 00:04:44,069
مشاهده به صورت گسسته سروکار دارند. دسته بندی ها
140
00:04:44,069 –> 00:04:45,840
به جای تخمین
141
00:04:45,840 –> 00:04:48,300
مقادیر پیوسته در ساده ترین حالت
142
00:04:48,300 –> 00:04:50,669
، دو دسته ممکن وجود دارد، این مورد
143
00:04:50,669 –> 00:04:52,770
به عنوان طبقه بندی باینری شناخته
144
00:04:52,770 –> 00:04:54,479
می شود.
145
00:04:54,479 –> 00:04:56,430
146
00:04:56,430 –> 00:04:58,409
147
00:04:58,409 –> 00:05:00,780
148
00:05:00,780 –> 00:05:03,479
تصویر داده شده حاوی یک سند است یا نه،
149
00:05:03,479 –> 00:05:05,099
طبقهبندی عمدتاً شامل
150
00:05:05,099 –> 00:05:07,080
طبقهبندی درختان است که از ماشینهای برداری پشتیبانی میکنند
151
00:05:07,080 –> 00:05:09,180
و الگوریتمهای جنگل تصادفی
152
00:05:09,180 –> 00:05:11,430
و همچنین یک رگرسیون شامل
153
00:05:11,430 –> 00:05:13,710
رگرسیون خطی بایاس درختان تصمیمگیری در
154
00:05:13,710 –> 00:05:16,139
شبکهها و طبقهبندی فلوسی است
155
00:05:16,139 –> 00:05:17,430
که اکنون الگوریتمهای دیگری مانند
156
00:05:17,430 –> 00:05:19,139
برنامهنویسی شبکه عصبی مصنوعی
157
00:05:19,139 –> 00:05:21,300
و تقویت گرادیان وجود دارد. که همچنین com es
158
00:05:21,300 –> 00:05:24,240
تحت الگوریتمهای یادگیری نظارتشده در حال
159
00:05:24,240 –> 00:05:25,830
حاضر یادگیری تقویتی داریم
160
00:05:25,830 –> 00:05:27,840
اکنون یادگیری تقویتی یاد میگیرد که
161
00:05:27,840 –> 00:05:31,050
چگونه موقعیتها را به عملکردها ترسیم کنیم تا
162
00:05:31,050 –> 00:05:33,539
پاداش را به حداکثر برسانیم و اغلب برای
163
00:05:33,539 –> 00:05:36,060
بازیهای روباتیک و ناوبری با
164
00:05:36,060 –> 00:05:37,949
یادگیری تقویتی استفاده میشود.
165
00:05:37,949 –> 00:05:40,139
166
00:05:40,139 –> 00:05:42,090
بیشترین پاداش را دریافت می کند
167
00:05:42,090 –> 00:05:44,159
و الگوریتم اطلاعاتی در مورد
168
00:05:44,159 –> 00:05:45,870
درست یا نبودن پاسخ ارائه می دهد،
169
00:05:45,870 –> 00:05:48,630
اما نحوه بهبود آن را نمی گوید،
170
00:05:48,630 –> 00:05:50,370
عامل یادگیرنده یا تصمیم گیرنده است
171
00:05:50,370 –> 00:05:52,500
که وظیفه او انتخاب اقداماتی است که
172
00:05:52,500 –> 00:05:54,719
پاداش مورد انتظار را در
173
00:05:54,719 –> 00:05:57,060
مدت زمان معینی از اقدامات به حداکثر می رساند. کاری است
174
00:05:57,060 –> 00:05:59,699
که عامل می تواند انجام دهد و محیط
175
00:05:59,699 –> 00:06:02,009
هر چیزی است که نماینده با الگوریتمی تعامل می
176
00:06:02,009 –> 00:06:03,779
کند که هدف نهایی آن
177
00:06:03,779 –> 00:06:05,849
کسب حداکثر پاداش عددی
178
00:06:05,849 –> 00:06:08,279
ممکن است، هر بار که
179
00:06:08,279 –> 00:06:10,590
حریف امتیازی کسب کند جریمه می شود و
180
00:06:10,590 –> 00:06:12,750
هر بار که موفق به کسب امتیاز می شود، پاداش می گیرد.
181
00:06:12,750 –> 00:06:15,270
در مقابل حریف از این
182
00:06:15,270 –> 00:06:17,099
بازخورد برای به روز رسانی خط مشی خود استفاده می کند و
183
00:06:17,099 –> 00:06:19,259
به تدریج فی تمام اقداماتی را
184
00:06:19,259 –> 00:06:21,389
که منجر به جریمه می شود را نشان می دهد.
185
00:06:21,389 –> 00:06:23,069
یادگیری تقویتی در مواردی که
186
00:06:23,069 –> 00:06:25,289
فضای راه حل بسیار زیاد یا بی نهایت است مفید است
187
00:06:25,289 –> 00:06:27,509
و معمولاً در مواردی که
188
00:06:27,509 –> 00:06:29,370
یادگیری ماشین را می توان به عنوان عاملی در
189
00:06:29,370 –> 00:06:31,409
تعامل با محیط
190
00:06:31,409 –> 00:06:33,599
خود در نظر گرفت، در حال حاضر یادگیری تقویتی زیادی وجود دارد اعمال می
191
00:06:33,599 –> 00:06:35,940
شود. الگوریتمهایی که تعداد کمی از آنها
192
00:06:35,940 –> 00:06:39,060
نشانه یادگیری هستند SA RSA را داریم
193
00:06:39,060 –> 00:06:39,689
که حالت به عنوان
194
00:06:39,689 –> 00:06:41,909
اقدام حالت پاداش است، شبکه صف عمیق
195
00:06:41,909 –> 00:06:43,979
داریم، گرادیان خطمشی قطعی عمیق داریم
196
00:06:43,979 –> 00:06:46,199
که DD PT است و
197
00:06:46,199 –> 00:06:48,149
در نهایت T ظاهر میشود که
198
00:06:48,149 –> 00:06:50,969
سیاست منطقه اعتماد است. بهینه سازی در حال
199
00:06:50,969 –> 00:06:52,799
حاضر آخرین دسته از یادگیری ماشینی
200
00:06:52,799 –> 00:06:55,259
یادگیری بدون نظارت است، بنابراین همانطور که قبلاً ذکر کردم،
201
00:06:55,259 –> 00:06:57,239
وظایف یادگیری نظارت شده
202
00:06:57,239 –> 00:06:59,519
الگوهایی را پیدا می کنیم که در آنها مجموعه داده ای از
203
00:06:59,519 –> 00:07:01,499
پاسخ های مناسب برای یادگیری داریم، در حالی که در
204
00:07:01,499 –> 00:07:03,599
مورد وظایف یادگیری بدون نظارت،
205
00:07:03,599 –> 00:07:05,759
الگوهایی را پیدا کنید که در آنها نیستیم.
206
00:07:05,759 –> 00:07:07,919
زیرا پاسخهای درست غیرقابل
207
00:07:07,919 –> 00:07:10,979
حل یا غیرممکن هستند یا شاید برای یک
208
00:07:10,979 –> 00:07:12,599
مشکل معین حتی یک ری وجود نداشته باشد. پاسخ ght به
209
00:07:12,599 –> 00:07:14,819
خودی خود یک زیر کلاس بزرگ از
210
00:07:14,819 –> 00:07:16,769
سؤال بدون نظارت مشکل
211
00:07:16,769 –> 00:07:18,959
خوشه بندی است که به گروه بندی
212
00:07:18,959 –> 00:07:20,939
مشاهدات با هم اشاره دارد به گونه ای که
213
00:07:20,939 –> 00:07:23,159
اعضای یک گروه مشترک شبیه
214
00:07:23,159 –> 00:07:25,379
یکدیگر و متفاوت از اعضای
215
00:07:25,379 –> 00:07:27,749
گروه های دیگر هستند، یک کاربرد رایج در
216
00:07:27,749 –> 00:07:30,059
اینجا در بازاریابی است. جایی که میخواهیم
217
00:07:30,059 –> 00:07:32,219
بخشهایی از مشتریان یا مشتریان
218
00:07:32,219 –> 00:07:34,169
بالقوه را با ترجیحات یا
219
00:07:34,169 –> 00:07:36,389
عادات خرید مشابه شناسایی کنیم، یک چالش بزرگ در
220
00:07:36,389 –> 00:07:38,129
خوشهبندی این است که اغلب دشوار
221
00:07:38,129 –> 00:07:40,289
یا غیرممکن است که بدانیم چه تعداد خوشه
222
00:07:40,289 –> 00:07:42,389
باید وجود داشته باشد یا اینکه خوشه چگونه
223
00:07:42,389 –> 00:07:44,369
باید بدون نظارت به نظر برسد، یادگیری در
224
00:07:44,369 –> 00:07:46,259
برابر دادههایی استفاده میشود که بدون
225
00:07:46,259 –> 00:07:48,569
برچسب تاریخی به سیستم پاسخ صحیح داده نشده است.
226
00:07:48,569 –> 00:07:50,309
الگوریتم باید بفهمد که
227
00:07:50,309 –> 00:07:52,409
چه چیزی نشان داده میشود، هدف
228
00:07:52,409 –> 00:07:54,629
کاوش در دادهها و یافتن ساختاری
229
00:07:54,629 –> 00:07:56,879
در یادگیری بدون نظارت است که
230
00:07:56,879 –> 00:07:58,800
روی دادههای تراکنشی به خوبی کار میکند و این
231
00:07:58,800 –> 00:08:01,139
الگوریتمها همچنین برای تقسیمبندی
232
00:08:01,139 –> 00:08:03,779
موضوعات متنی موارد پیشنهادی استفاده میشوند. و خطوط کلی
233
00:08:03,779 –> 00:08:06,089
داده های شناسایی شده در حال حاضر عمدتاً دو
234
00:08:06,089 –> 00:08:07,909
طبقه بندی از unsup وجود دارد یادگیری ارائه شده،
235
00:08:07,909 –> 00:08:10,529
یکی خوشهبندی است همانطور که قبلاً بحث کردم
236
00:08:10,529 –> 00:08:13,050
و دیگری کاهش ابعاد است
237
00:08:13,050 –> 00:08:14,909
که شامل موضوعاتی مانند
238
00:08:14,909 –> 00:08:17,219
تجزیه تانسور تجزیه و تحلیل مؤلفههای اصلی است که
239
00:08:17,219 –> 00:08:20,039
آسیبهای چندگانه به آمار
240
00:08:20,039 –> 00:08:22,619
و پیشبینی تصادفی را شامل میشود، بنابراین اکنون که
241
00:08:22,619 –> 00:08:23,819
ما فهمیدیم یادگیری ماشین
242
00:08:23,819 –> 00:08:26,039
چیست و انواع مختلف ماشین آن چیست.
243
00:08:26,039 –> 00:08:28,019
یادگیری بیایید نگاهی
244
00:08:28,019 –> 00:08:30,059
به مولفه زباله اکوسیستم SPARC بیندازیم
245
00:08:30,059 –> 00:08:31,739
و درک کنیم که چگونه یادگیری ماشین
246
00:08:31,739 –> 00:08:33,629
نقش مهمی در اینجا بازی می کند، همانطور که
247
00:08:33,629 –> 00:08:35,279
می بینید در اینجا ما یک جزء
248
00:08:35,279 –> 00:08:37,979
به نام ml
249
00:08:37,979 –> 00:08:40,078
lip داریم.
250
00:08:40,078 –> 00:08:41,879
هسته جرقه PI
251
00:08:41,879 –> 00:08:43,620
برای انجام تجزیه و تحلیل با استفاده از
252
00:08:43,620 –> 00:08:45,839
الگوریتم های یادگیری ماشینی روی سیستم های توزیع شده کار می کند
253
00:08:45,839 –> 00:08:48,059
و مقیاس پذیر است و ما می توانیم
254
00:08:48,059 –> 00:08:49,740
اجرای
255
00:08:49,740 –> 00:08:51,839
رگرسیون خطی خوشه بندی طبقه بندی و سایر
256
00:08:51,839 –> 00:08:53,520
الگوریتم های یادگیری ماشین را در لایو PI پیدا
257
00:08:53,520 –> 00:08:55,500
کنیم.
258
00:08:55,500 –> 00:08:57,660
259
00:08:57,660 –> 00:08:59,520
الگوریتمهایی که بسیاری از الگوریتمهای یادگیری ماشین
260
00:08:59,520 –> 00:09:00,600
261
00:09:00,600 –> 00:09:02,790
پیادهسازی شدهاند وارد شده در PI Spock ma live جدا
262
00:09:02,790 –> 00:09:04,560
از PI sparks کارایی و
263
00:09:04,560 –> 00:09:07,080
مقیاس پذیری PI spark ma lib api
264
00:09:07,080 –> 00:09:09,240
کتابخانه های نرم افزاری بسیار کاربرپسندی
265
00:09:09,240 –> 00:09:10,800
هستند که برای ارائه راه حل
266
00:09:10,800 –> 00:09:12,750
برای مشکلات مختلف با
267
00:09:12,750 –> 00:09:14,790
ساختار داده خاص خود تعریف شده اند، این
268
00:09:14,790 –> 00:09:16,920
ساختارهای داده برای حل یک مشکل خاص ارائه شده است. مجموعه ای از
269
00:09:16,920 –> 00:09:19,680
مشکلات با گزینه های کارآمد pi spark
270
00:09:19,680 –> 00:09:21,150
em بیضی دارای ساختارهای داده بسیاری
271
00:09:21,150 –> 00:09:23,610
از جمله بردارهای چادری بردارهای فضایی
272
00:09:23,610 –> 00:09:25,890
و یک ماتریس محلی و توزیع شده
273
00:09:25,890 –> 00:09:29,490
است، بنابراین الگوریتم های زنده ml اصلی
274
00:09:29,490 –> 00:09:32,640
شامل ml Lib هستند، ما خوشه بندی داریم
275
00:09:32,640 –> 00:09:34,590
، ما تطبیق الگوی مکرر داریم،
276
00:09:34,590 –> 00:09:36,990
جبر خطی داریم، ما مشترک هستیم.
277
00:09:36,990 –> 00:09:39,120
فیلتر کردن ما طبقه بندی داریم و
278
00:09:39,120 –> 00:09:41,550
در نهایت رگرسیون خطی داریم حالا
279
00:09:41,550 –> 00:09:42,810
ببینیم چگونه می توانیم از
280
00:09:42,810 –> 00:09:45,930
MLF برای حل مشکلات معدود خود استفاده کنیم، بنابراین اجازه
281
00:09:45,930 –> 00:09:48,690
دهید این مورد استفاده را برای شما توضیح دهم که یک
282
00:09:48,690 –> 00:09:49,320
سیستم هک شده است
283
00:09:49,320 –> 00:09:51,360
اما متادیتای هر جلسه
284
00:09:51,360 –> 00:09:52,800
که هکرها برای اتصال
285
00:09:52,800 –> 00:09:54,990
سرورهای خود استفاده می کردند. اکنون متوجه شدهایم که این
286
00:09:54,990 –> 00:09:57,660
ویژگیها شامل ویژگیهایی مانند زمان اتصال جلسه،
287
00:09:57,660 –> 00:09:59,850
انتقال بایتها میشود درختان لی
288
00:09:59,850 –> 00:10:02,760
مورد استفاده ما دادههای خاصی داریم مانند
289
00:10:02,760 –> 00:10:05,610
صفحات خراب سرورها که مکان را خراب
290
00:10:05,610 –> 00:10:08,460
کردهاند و سرعت تایپ wpm را داریم
291
00:10:08,460 –> 00:10:10,560
اکنون سه هکر بالقوه برای
292
00:10:10,560 –> 00:10:12,840
تایید هکرها وجود دارد و یکی هنوز تایید نکرده است.
293
00:10:12,840 –> 00:10:15,360
294
00:10:15,360 –> 00:10:17,790
295
00:10:17,790 –> 00:10:19,560
تقریباً به همان
296
00:10:19,560 –> 00:10:21,870
میزان حمله برای مثال اگر 100 حمله وجود داشته باشد،
297
00:10:21,870 –> 00:10:24,390
در یک موقعیت – هکری
298
00:10:24,390 –> 00:10:26,400
هر کدام 50 حمله خواهد داشت و در یک
299
00:10:26,400 –> 00:10:27,810
موقعیت سه هکری هر کدام
300
00:10:27,810 –> 00:10:30,510
30 حمله C خواهند داشت، بنابراین در اینجا ما از
301
00:10:30,510 –> 00:10:33,030
خوشه بندی استفاده می کنیم، بیایید ببینیم چگونه می توانیم از
302
00:10:33,030 –> 00:10:35,220
خوشهبندی برای پیدا کردن تعداد هکرها استفاده کنید
303
00:10:35,220 –> 00:10:37,650
، بنابراین امروز میخواهم
304
00:10:37,650 –> 00:10:39,330
از نوتبوک Jupiter برای انجام تمام
305
00:10:39,330 –> 00:10:42,030
برنامهنویسیهایم استفاده کنم، اجازه دهید فقط یک پایتون جدید را باز کنم
306
00:10:42,030 –> 00:10:46,050
تا آن را تبدیل به یک نوت بوک کنم، بنابراین اول از
307
00:10:46,050 –> 00:10:47,460
همه کاری که ما میخواهیم انجام دهیم این است که
308
00:10:47,460 –> 00:10:49,320
همه را وارد کنیم. کتابخانه های مورد نیاز و شروع
309
00:10:49,320 –> 00:10:51,900
جلسه SPARC اکنون کاری که می
310
00:10:51,900 –> 00:10:53,580
خواهیم انجام دهیم این است که داده ها را با استفاده از این
311
00:10:53,580 –> 00:10:55,870
قسمت بخوانیم یا روش درمان را
312
00:10:55,870 –> 00:10:58,120
در اینجا انجام می دهیم
313
00:10:58,120 –> 00:11:01,600
. در فرمت CSV و
314
00:11:01,600 –> 00:11:03,700
ما سربرگ و در fátima را درست در نظر گرفتهایم، اکنون
315
00:11:03,700 –> 00:11:07,060
در اینجا مکان پیشفرض
316
00:11:07,060 –> 00:11:10,029
SD FS است که وقتی این قسمت یا فید را انجام میدهیم،
317
00:11:10,029 –> 00:11:11,860
بنابراین برای تغییر مکان پیشفرض
318
00:11:11,860 –> 00:11:13,870
به سیستم فایل محلی خود باید
319
00:11:13,870 –> 00:11:16,000
کولون فایل را ارائه کنید. و دو اسلش رو به جلو
320
00:11:16,000 –> 00:11:17,500
و سپس
321
00:11:17,500 –> 00:11:19,450
قسمت مطلق فایل داده را ارائه می دهد که اکنون می خواهیم آن
322
00:11:19,450 –> 00:11:21,279
را بخوانیم. اجازه دهید به
323
00:11:21,279 –> 00:11:23,170
اولین رکورد قاب داده و
324
00:11:23,170 –> 00:11:25,330
همچنین خلاصه مجموعه داده ها نگاهی بیندازیم
325
00:11:25,330 –> 00:11:27,550
تا خلاصه ای از مجموعه داده را داشته باشیم. ما در
326
00:11:27,550 –> 00:11:30,520
اینجا از تابع توصیف استفاده می کنیم اکنون خروجی
327
00:11:30,520 –> 00:11:32,440
این ی