در این مطلب، ویدئو راهنمای سریع تحلیل احساسات | تجزیه و تحلیل احساسات در پایتون با استفاده از Textblob | ادورکا با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,580 –> 00:00:06,529
[موسیقی] با
2
00:00:06,529 –> 00:00:08,820
سلام و خوش آمدگویی به این
3
00:00:08,820 –> 00:00:11,010
جلسه یوتیوب، عروسکی از Eureka وجود دارد و
4
00:00:11,010 –> 00:00:12,389
در جلسه امروز ما با
5
00:00:12,389 –> 00:00:15,360
تجزیه و تحلیل احساسات با استفاده از Python سروکار داریم، همانطور که همه شما می
6
00:00:15,360 –> 00:00:17,190
دانید که موفقیت یک شرکت یا
7
00:00:17,190 –> 00:00:18,990
محصول مستقیماً به مشتری آن بستگی دارد.
8
00:00:18,990 –> 00:00:21,359
مشتری محصول شما را دوست دارد
9
00:00:21,359 –> 00:00:23,189
، اگر نه، موفقیت شماست، پس
10
00:00:23,189 –> 00:00:24,990
مطمئناً باید با ایجاد
11
00:00:24,990 –> 00:00:27,119
تغییراتی در آن، آن را بداهه بسازید، بنابراین چگونه می توانید بفهمید
12
00:00:27,119 –> 00:00:28,800
که آیا محصول شما موفق است یا
13
00:00:28,800 –> 00:00:30,810
خیر، برای این کار باید مشتریان خود را تجزیه و تحلیل
14
00:00:30,810 –> 00:00:33,120
کنید و یکی از ویژگی
15
00:00:33,120 –> 00:00:35,280
های تجزیه و تحلیل کنید. مشتری شما
16
00:00:35,280 –> 00:00:37,290
باید احساسات آنها را تجزیه و تحلیل کند و اینجاست که
17
00:00:37,290 –> 00:00:38,940
تجزیه و تحلیل احساسات به
18
00:00:38,940 –> 00:00:41,070
تصویر کشیده می شود، بنابراین شروع با کلمه،
19
00:00:41,070 –> 00:00:43,320
تجزیه و تحلیل احساسات است، می توانید
20
00:00:43,320 –> 00:00:45,239
تجزیه و تحلیل احساسات را به عنوان فرآیندی برای
21
00:00:45,239 –> 00:00:46,950
شناسایی محاسباتی و
22
00:00:46,950 –> 00:00:49,079
دسته بندی نظرات از یک قطعه
23
00:00:49,079 –> 00:00:51,510
متن تعریف کنید و تعیین کنید که آیا
24
00:00:51,510 –> 00:00:53,430
نگرش نویسندگان نسبت به یک موضوع خاص
25
00:00:53,430 –> 00:00:55,350
یا محصول مثبت منفی یا
26
00:00:55,350 –> 00:00:58,109
خنثی است، به خوبی ممکن است نه به
27
00:00:58,109 –> 00:00:59,670
صورت هندی هر بار که
28
00:00:59,670 –> 00:01:02,340
تجزیه و تحلیل احساسات انجام نمی دهید اما دقیقاً
29
00:01:02,340 –> 00:01:04,349
به دنبال یک بازخورد هستید، مانند قبل از
30
00:01:04,349 –> 00:01:06,090
خرید یک محصول، می توانید به دنبال
31
00:01:06,090 –> 00:01:08,250
بازخوردی مانند آنچه سایر مشتریان
32
00:01:08,250 –> 00:01:09,420
درباره آن محصول خاص می گویند
33
00:01:09,420 –> 00:01:10,890
، خوب یا بد نباشید، بگردید.
34
00:01:10,890 –> 00:01:13,320
درست است و شما آن را به صورت دستی با
35
00:01:13,320 –> 00:01:14,909
نگاه کردن به بازخوردهای آنها تجزیه و تحلیل می کنید، اکنون
36
00:01:14,909 –> 00:01:16,950
فقط در سطح شرکت در نظر بگیرید، بنابراین
37
00:01:16,950 –> 00:01:18,659
چگونه شرکت تحلیل می کند که
38
00:01:18,659 –> 00:01:20,130
مشتریان در مورد محصول خود چه فکر می کنند،
39
00:01:20,130 –> 00:01:21,840
آنها فقط یک یا دو
40
00:01:21,840 –> 00:01:23,580
مشتری ندارند، درست است که بیش از
41
00:01:23,580 –> 00:01:25,560
میلیون ها مشتری دارند. بنابراین چه
42
00:01:25,560 –> 00:01:27,479
کاری انجام خواهند داد، بنابراین اینجا جایی است که شرکت باید
43
00:01:27,479 –> 00:01:29,610
تجزیه و تحلیل احساسات انجام دهد تا بداند
44
00:01:29,610 –> 00:01:31,710
آیا محصول واقعاً
45
00:01:31,710 –> 00:01:34,860
در بازار عملکرد خوبی دارد یا خوب نیست، بنابراین اکنون
46
00:01:34,860 –> 00:01:36,750
که میدانید دقیقاً چه تحلیل احساساتی را میدانید،
47
00:01:36,750 –> 00:01:38,670
بیایید ادامه دهیم و ببینیم واقعاً چگونه است.
48
00:01:38,670 –> 00:01:40,950
کار، بنابراین بیایید
49
00:01:40,950 –> 00:01:42,990
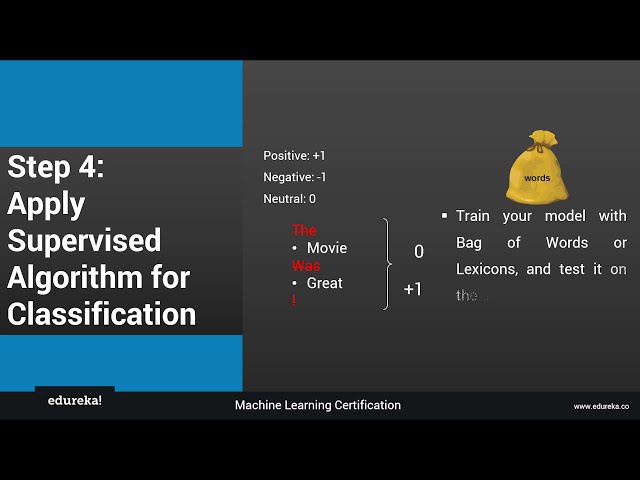
بیانیه را به عنوان مثال در نظر بگیریم، فیلم عالی بود،
50
00:01:42,990 –> 00:01:45,149
بنابراین اولین گام
51
00:01:45,149 –> 00:01:47,340
مرحله توکنسازی خواهد بود، بنابراین توکنسازی دقیقاً چیست؟
52
00:01:47,340 –> 00:01:49,860
53
00:01:49,860 –> 00:01:51,869
اما تقسیم Pera خود به
54
00:01:51,869 –> 00:01:53,490
مجموعهای از بیانیهها یا تقسیم یک
55
00:01:53,490 –> 00:01:56,040
بیانیه به مجموعهای از کلمات مختلف، به طوری
56
00:01:56,040 –> 00:01:57,840
که عبارت فیلم عالی
57
00:01:57,840 –> 00:01:59,700
بود، بیشتر به کلمات مختلف آن تفکیک میشود،
58
00:01:59,700 –> 00:02:01,649
بنابراین هنگامی که فرآیند
59
00:02:01,649 –> 00:02:03,899
سازماندهی انجام شد، مرحله
60
00:02:03,899 –> 00:02:06,000
دوم پاکسازی داده ها بنابراین
61
00:02:06,000 –> 00:02:07,680
منظور من از پاک کردن داده ها حذف تمام
62
00:02:07,680 –> 00:02:09,449
این کاراکترهای خاص یا هر
63
00:02:09,449 –> 00:02:11,220
کلمه دیگری است که هیچ ارزشی به قسمت تجزیه و تحلیل اضافه نمی کند،
64
00:02:11,220 –> 00:02:12,500
65
00:02:12,500 –> 00:02:15,140
بنابراین در مرحله دوم کاراکترهای ویژه را حذف می
66
00:02:15,140 –> 00:02:17,390
کنم بنابراین به این علامت تعجب نیازی ندارم.
67
00:02:17,390 –> 00:02:19,340
در اینجا، بنابراین من
68
00:02:19,340 –> 00:02:22,250
با چهار کلمه باقی ماندهام، اگرچه فیلم بسیار
69
00:02:22,250 –> 00:02:23,000
عالی بود،
70
00:02:23,000 –> 00:02:25,400
بنابراین قدم بعدی حذف کلمات توقف است،
71
00:02:25,400 –> 00:02:27,680
همانطور که گفتم، من به هیچ کلمهای
72
00:02:27,680 –> 00:02:29,270
که ارزشی به نتیجه تجزیه و تحلیل اضافه نمیکند نیازی ندارم،
73
00:02:29,270 –> 00:02:31,940
بنابراین کلمات توقف
74
00:02:31,940 –> 00:02:35,330
مانند بود. آیا او ارزش زیادی
75
00:02:35,330 –> 00:02:37,490
به بخش تجزیه و تحلیل اضافه نمی کند، بنابراین ما به راحتی می توانیم
76
00:02:37,490 –> 00:02:39,770
آنها را حذف کنیم، بنابراین اکنون فقط با
77
00:02:39,770 –> 00:02:44,120
دو کلمه فیلم باقی مانده ایم و بسیار خوب، اکنون مرحله
78
00:02:44,120 –> 00:02:46,340
چهار مرحله طبقه بندی است، بنابراین اکنون
79
00:02:46,340 –> 00:02:47,840
که شما تنها با دو کلمه باقی مانده اید.
80
00:02:47,840 –> 00:02:49,640
وظیفه شما این است
81
00:02:49,640 –> 00:02:51,650
که آنها را به عنوان یک
82
00:02:51,650 –> 00:02:53,510
کلمه مثبت یا یک کلمه منفی یا یک
83
00:02:53,510 –> 00:02:55,790
کلمه خنثی برای یک کلمه مثبت طبقه بندی کنید، ما برای یک کلمه مثبت
84
00:02:55,790 –> 00:02:57,770
یک نمره احساسی به اضافه یک برای
85
00:02:57,770 –> 00:02:59,690
منفی ما یک نمره منفی داریم.
86
00:02:59,690 –> 00:03:02,360
اکنون برای یک کلاه گیس خنثی صفر،
87
00:03:02,360 –> 00:03:03,650
این قسمتی است که یادگیری ماشینی میآید،
88
00:03:03,650 –> 00:03:05,540
میتوانید دادههای خود را با مجموعهای از کلمات مدلسازی کنید
89
00:03:05,540 –> 00:03:07,760
یا میتوانید از واژگانی استفاده کنید که
90
00:03:07,760 –> 00:03:09,440
چیزی نیست جز فرهنگ لغت
91
00:03:09,440 –> 00:03:12,440
مجموعهای از کلمات از پیش طبقهبندیشده و اکنون پس از
92
00:03:12,440 –> 00:03:14,510
فشار مدل میتوانید انجام دهید. تست
93
00:03:14,510 –> 00:03:16,880
بیانیه تحلیل و حالت
94
00:03:16,880 –> 00:03:18,290
نمره دقت بهتر خواهد بود
95
00:03:18,290 –> 00:03:20,930
اگر مدل شما خیلی دقیق باشد طبقه بندی درست است
96
00:03:20,930 –> 00:03:23,720
پس بله
97
00:03:23,720 –> 00:03:26,360
طبقه بندی بسیار خوبی خواهد بود پس خوب حالا کاری که
98
00:03:26,360 –> 00:03:28,070
ما انجام داده ایم




![فیلم آموزشی: ایجاد یک برنامه آب و هوا در جنگو با استفاده از درخواست های پایتون [قسمت 1] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/v7xjdXWZafYimage2.jpg)