در این مطلب، ویدئو ساخت مدل های پیش بینی با یادگیری ماشین و پایتون: یافتن مشکلات با داده های شما | packtpub.com با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:10:49
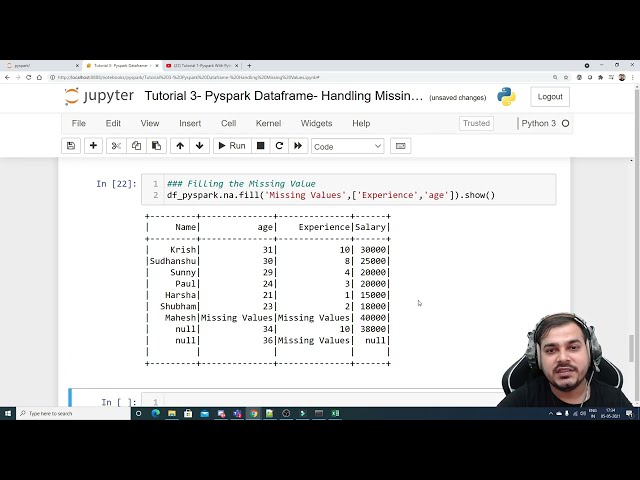
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:06,570 –> 00:00:08,580
2
00:00:08,580 –> 00:00:11,190
به ساختن
3
00:00:11,190 –> 00:00:14,420
سیستمهای پیشبینی با پایتون و یادگیری ماشین
4
00:00:14,420 –> 00:00:18,000
خوش آمدید، امروز بخش جدیدی را درباره
5
00:00:18,000 –> 00:00:19,770
حل اولین چالش خود برای
6
00:00:19,770 –> 00:00:24,070
مقابله با دادههای بد با بخش پانداها شروع
7
00:00:24,070 –> 00:00:25,920
میکنیم، میخواهیم نگاهی به
8
00:00:25,920 –> 00:00:29,200
شماره یک بیاندازیم که چگونه میتوانیم مشکلات را بدون داده پیدا کنیم.
9
00:00:29,200 –> 00:00:32,890
اگر یک فایل داده خام به ما تحویل
10
00:00:32,890 –> 00:00:35,760
داده شود که
11
00:00:35,760 –> 00:00:39,940
با استفاده از پانداها در پایتون شماره دو بارگذاری کرده ایم تا داده های
12
00:00:39,940 –> 00:00:42,940
خود را برای مدل سازی آماده کنیم و شماره
13
00:00:42,940 –> 00:00:45,699
سه یک مدل بسازیم تا شانس خود را
14
00:00:45,699 –> 00:00:49,390
برای زنده ماندن از این تایتانیک ارزیابی کنیم، اولین
15
00:00:49,390 –> 00:00:51,400
ویدیویی که می خواهیم نگاه کنیم. در این است که چگونه
16
00:00:51,400 –> 00:00:54,699
میتوانیم مشکلات مربوط به دادههایمان را پیدا کنیم،
17
00:00:54,699 –> 00:00:56,770
بهویژه میخواهیم روی سه موضوع تمرکز
18
00:00:56,770 –> 00:01:01,180
کنیم، شماره یک دادههای گمشده،
19
00:01:01,180 –> 00:01:04,390
شماره دو اطلاعات چندگانه
20
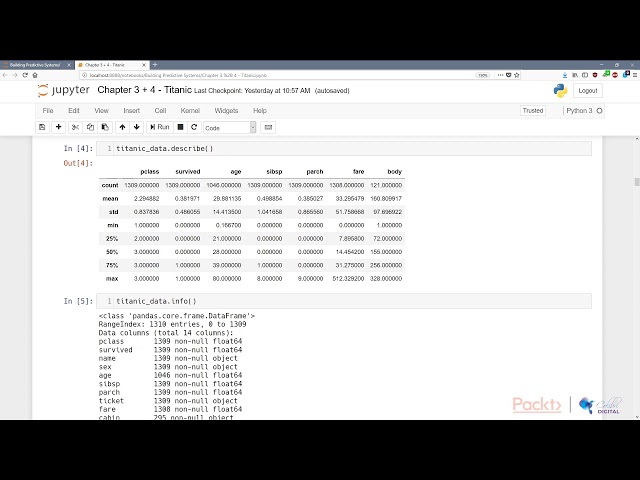
00:01:04,390 –> 00:01:07,270
در یک ستون و شماره
21
00:01:07,270 –> 00:01:10,810
سه ستونهای بیفایده یا پر سر و صدا، بیایید
22
00:01:10,810 –> 00:01:14,200
وارد هر دو شویم و نگاهی بیندازیم. فصل سوم
23
00:01:14,200 –> 00:01:16,780
و چهارم در مورد
24
00:01:16,780 –> 00:01:19,630
مجموعه دادههای تایتانیک صحبت میکنیم تا بتوانید
25
00:01:19,630 –> 00:01:22,149
مجموعه دادههای تایتانیک را به صورت آنلاین پیدا کنید و مجموعهای که من
26
00:01:22,149 –> 00:01:25,390
استفاده میکنم از مخزن دانشگاه است و
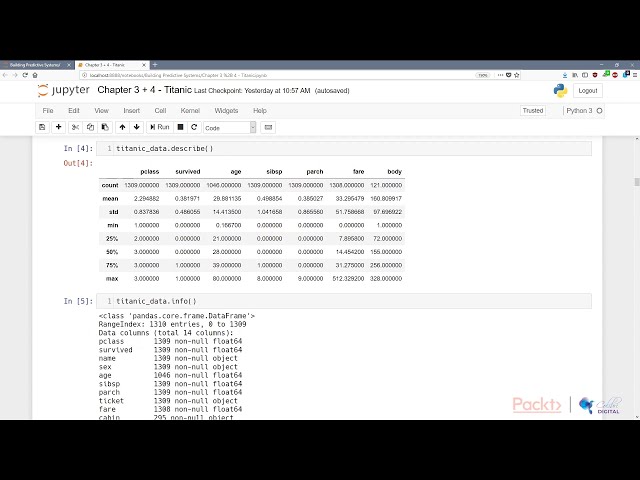
27
00:01:25,390 –> 00:01:27,990
باید حدود هزار داده داشته باشد.
28
00:01:27,990 –> 00:01:31,630
اولین کاری که باید انجام دهیم این است که
29
00:01:31,630 –> 00:01:35,259
طبق معمول پانداها را وارد میکنیم، ما
30
00:01:35,259 –> 00:01:37,150
پانداها را با استفاده از
31
00:01:37,150 –> 00:01:39,579
پانداهای وارداتی انجمن علم داده بهعنوان
32
00:01:39,579 –> 00:01:44,079
PD وارد میکنیم و در کاری که انجام میدهیم
33
00:01:44,079 –> 00:01:47,829
دادههای Titanic را به عنوان قاب داده اختصاص میدهیم
34
00:01:47,829 –> 00:01:52,340
و csv titanic csv را میخوانیم.
35
00:01:52,340 –> 00:01:54,649
سپس میتوانیم به دادههای تایتانیک نگاهی بیندازیم،
36
00:01:54,649 –> 00:01:57,590
زیرا ما این را بهعنوان یک
37
00:01:57,590 –> 00:02:01,789
قاب داده ایجاد کردهایم مشتری با مهربانی
38
00:02:01,789 –> 00:02:04,939
آن را برای ما بسیار زیبا قالببندی
39
00:02:04,939 –> 00:02:09,940
40
00:02:09,940 –> 00:02:12,709
41
00:02:12,709 –> 00:02:16,580
میکند. ردیف آخر خالی است و می توانید
42
00:02:16,580 –> 00:02:20,420
ببینید که ما
43
00:02:20,420 –> 00:02:22,220
در این مجموعه داده ها داده های زیادی در
44
00:02:22,220 –> 00:02:24,260
مورد مسافران داریم، به ویژه چیزی که می خواهیم
45
00:02:24,260 –> 00:02:25,640
پیش بینی کنیم این است که آیا کسی
46
00:02:25,640 –> 00:02:29,630
از فاجعه تایتانیک جان سالم به در برده است یا خیر.
47
00:02:29,630 –> 00:02:33,250
که
48
00:02:33,250 –> 00:02:36,290
زنده مانده است روی یک تنظیم می شود و این
49
00:02:36,290 –> 00:02:40,640
نقطه داده باقی نمانده است این پرچم
50
00:02:40,640 –> 00:02:42,590
روی صفر تنظیم می شود، بنابراین این هدفی
51
00:02:42,590 –> 00:02:44,360
برای زنده ماندن است تا آنها را به عنوان هدف فراخوانی کنیم.
52
00:02:44,360 –> 00:02:47,150
53
00:02:47,150 –> 00:02:49,880
54
00:02:49,880 –> 00:02:51,620
داده است اولین چیزی
55
00:02:51,620 –> 00:02:54,140
که می توانیم ببینیم که ردیف آخر خالی است،
56
00:02:54,140 –> 00:02:56,180
سمت راست لیز حتی یک نقطه داده هم
57
00:02:56,180 –> 00:02:59,630
ندارد، فقط بی فایده است.
58
00:02:59,630 –> 00:03:01,549
59
00:03:01,549 –> 00:03:04,850
60
00:03:04,850 –> 00:03:06,980
تابع بنابراین تابع توصیف
61
00:03:06,980 –> 00:03:09,829
بر روی فریمهای داده در پانداها کار میکند و کاری
62
00:03:09,829 –> 00:03:13,160
که انجام میدهد این است که تمام
63
00:03:13,160 –> 00:03:17,120
ویژگیهای عددی را میگیرد، بنابراین در اینجا برای
64
00:03:17,120 –> 00:03:19,239
مثال نام یک چیز عددی
65
00:03:19,239 –> 00:03:22,190
نیست Genda یک ویژگی عددی نیست، اما
66
00:03:22,190 –> 00:03:24,440
برای مثال سن است. یک ویژگی عددی است که به
67
00:03:24,440 –> 00:03:28,639
درستی توصیف میکند تمام
68
00:03:28,639 –> 00:03:33,109
ویژگیهای عددی را میگیرد و خلاصهای از میانگین
69
00:03:33,109 –> 00:03:35,680
انحرافات استاندارد و
70
00:03:35,680 –> 00:03:39,620
ربعهای این ویژگی را به درستی به شما ارائه میدهد، به
71
00:03:39,620 –> 00:03:43,000
عنوان مثال در اینجا میتوانیم ببینیم که 38٪ از
72
00:03:43,000 –> 00:03:45,829
افراد در این مجموعه داده زنده ماندهاند
73
00:03:45,829 –> 00:03:49,489
و 62 نفر دیگر زنده ماندهاند. آیا اکثر افراد
74
00:03:49,489 –> 00:03:51,850
در کالسکه خود بین کلاس دو و سه هستند
75
00:03:51,850 –> 00:03:55,010
و میانگین سنی
76
00:03:55,010 –> 00:03:56,780
مثلاً بیست و نه امتیاز هشت است که
77
00:03:56,780 –> 00:03:59,239
نزدیک به سی است و
78
00:03:59,239 –> 00:04:02,180
با حداکثر نفر چیزی حدود سی و سه دلار می پردازند.
79
00:04:02,180 –> 00:04:05,540
با پرداخت 500 دلار، همه ما میتوانیم
80
00:04:05,540 –> 00:04:08,150
با استفاده از تابع اطلاعات ببینیم چه مقدار داده از دست رفته است،
81
00:04:08,150 –> 00:04:12,620
در واقع میتوانید
82
00:04:12,620 –> 00:04:14,540
آن را در دو تعداد مشاهده کنید، اما من فکر میکنم
83
00:04:14,540 –> 00:04:16,370
بخش اطلاعات کمی
84
00:04:16,370 –> 00:04:18,940
واضحتر است در مورد اینکه چه دادههایی را از دست دادهاید،
85
00:04:18,940 –> 00:04:21,769
میتوانیم ببینیم. که ما
86
00:04:21,769 –> 00:04:26,449
سیصد و ده ورودی داریم و چون می
87
00:04:26,449 –> 00:04:29,020
دانیم که یک ردیف کاملاً خالی
88
00:04:29,020 –> 00:04:32,210
است، سی و سیصد و نه
89
00:04:32,210 –> 00:04:36,190
مدخل برای مواردی مانند کلاس مسافر وجود دارد
90
00:04:36,190 –> 00:04:38,660
که آیا کسی نام جنسیت خود را
91
00:04:38,660 –> 00:04:42,470
حفظ کرده است، مثلاً در سن، ما
92
00:04:42,470 –> 00:04:44,150
در واقع همیشه این را نداریم. سن یک
93
00:04:44,150 –> 00:04:46,940
مسافر اما بعد اینکه آیا آنها
94
00:04:46,940 –> 00:04:48,229
والدین و فرزندان با تعداد کافی
95
00:04:48,229 –> 00:04:51,130
خواهر و برادر دارند که همیشه در دسترس ما هستند،
96
00:04:51,130 –> 00:04:53,389
بنابراین این اولین مسئله است درست
97
00:04:53,389 –> 00:04:55,970
اولین مسئله این است که ما همیشه
98
00:04:55,970 –> 00:04:59,360
همه ارزش ها را در دو ویژگی نداریم و بنابراین همیشه می توانیم
99
00:04:59,360 –> 00:05:02,120
به آنها وابسته باشیم. ویژگی که به ما
100
00:05:02,120 –> 00:05:04,460
اطلاعات می دهد که آیا این شخص در
101
00:05:04,460 –> 00:05:07,550
مورد دوم جان سالم به در برده است یا خیر، این است که ما
102
00:05:07,550 –> 00:05:09,560
چندین اطلاعات را در یک
103
00:05:09,560 –> 00:05:13,099
ویژگی داریم که در مجموعه داده های خام بسیار زیاد به نظر می رسد
104
00:05:13,099 –> 00:05:15,590
زیرا مجموعه داده ها فرآیند عمل
105
00:05:15,590 –> 00:05:19,370
ممکن است کاملاً تمیز نباشد، به عنوان مثال
106
00:05:19,370 –> 00:05:21,770
نام اطلاعات زیادی را به ما میدهد درست
107
00:05:21,770 –> 00:05:24,289
با اینکه نام خانوادگی آنها چقدر طولانی است
108
00:05:24,289 –> 00:05:26,690
، نشان میدهد که آنها از عنوان آنها کجا هستند،
109
00:05:26,690 –> 00:05:30,020
110
00:05:30,020 –> 00:05:33,949
طبقه اجتماعی و جنسیت آنها را نشان میدهد، بنابراین یک ویژگی
111
00:05:33,949 –> 00:05:36,500
یک ستون در اینجا در دادههای خام در واقع
112
00:05:36,500 –> 00:05:39,110
حاوی چندین بخش از اطلاعات است
113
00:05:39,110 –> 00:05:41,389
که ما فقط آنها را تقسیم کردهایم، بنابراین
114
00:05:41,389 –> 00:05:42,710
بارها این موضوع دوم است،
115
00:05:42,710 –> 00:05:44,659
زیرا جمعآوری دادهها
116
00:05