در این مطلب، ویدئو مدل انتخاب اول من با Pandasbiogeme با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:16:16
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:03,149
سلام من میشل گلار هستم
2
00:00:03,149 –> 00:00:06,120
با هم به مدل انتخاب اول با استفاده از
3
00:00:06,120 –> 00:00:09,210
تودا بیوژن نگاه خواهیم کرد، خواهیم دید که چگونه
4
00:00:09,210 –> 00:00:11,730
مدل را مشخص کنیم و چگونه پارامترهای آن را تخمین بزنیم.
5
00:00:11,730 –> 00:00:15,150
6
00:00:15,150 –> 00:00:17,340
7
00:00:17,340 –> 00:00:20,820
8
00:00:20,820 –> 00:00:23,730
سیستم maglev تحت آزمایش قرار گرفته است که
9
00:00:23,730 –> 00:00:25,920
در سوئیس طراحی شده است و برای
10
00:00:25,920 –> 00:00:31,859
کار با سرعت 500 کیلومتر در ساعت برنامه ریزی شده است، ما علاقه مند به
11
00:00:31,859 –> 00:00:34,620
تجزیه و تحلیل تقاضا برای چنین سیستمی هستیم
12
00:00:34,620 –> 00:00:37,890
و برای انجام این کار می خواهیم یک
13
00:00:37,890 –> 00:00:40,469
مدل انتخاب حالت حمل و نقل را که
14
00:00:40,469 –> 00:00:42,660
در آن سه حالت رقابتی است، تخمین بزنیم.
15
00:00:42,660 –> 00:00:46,079
قطار معمولی سالن تشک سوئیس یا
16
00:00:46,079 –> 00:00:50,520
ماشین خواهد بود که ما سه متغیر
17
00:00:50,520 –> 00:00:52,410
از مجموعه داده های
18
00:00:52,410 –> 00:00:55,829
جمع آوری شده در سوئیس را در نظر خواهیم گرفت، اولین
19
00:00:55,829 –> 00:00:58,020
متغیر زمان سفر برای هر
20
00:00:58,020 –> 00:01:01,620
نوع حمل و نقل است، متغیر دوم هزینه سفر برای هر حالت از حمل و نقل
21
00:01:01,620 –> 00:01:04,229
است.
22
00:01:04,229 –> 00:01:06,840
حمل و نقل و آخرین
23
00:01:06,840 –> 00:01:09,500
متغیر متغیری است که
24
00:01:09,500 –> 00:01:13,140
افرادی را که دارای
25
00:01:13,140 –> 00:01:15,560
اشتراک سالانه حمل و نقل عمومی هستند مشخص می کند و
26
00:01:15,560 –> 00:01:18,720
در واقع چنین مسافرانی مبلغی را پرداخت نخواهند کرد. y
27
00:01:18,720 –> 00:01:20,580
هزینه حمل و نقل عمومی را
28
00:01:20,580 –> 00:01:24,650
به دلیل داشتن اشتراک سالانه
29
00:01:24,650 –> 00:01:27,390
و ما توابع کاربردی بسیار ساده را در نظر می گیریم
30
00:01:27,390 –> 00:01:31,170
که در آن کاربرد هر
31
00:01:31,170 –> 00:01:33,000
جایگزین به سادگی ترکیبی خطی
32
00:01:33,000 –> 00:01:35,850
از دو متغیر
33
00:01:35,850 –> 00:01:38,040
زمان سفر و هزینه سفر است، ما همچنین
34
00:01:38,040 –> 00:01:40,710
ثابت های خاص جایگزین را
35
00:01:40,710 –> 00:01:44,119
برای همه گزینه ها به جز Swiss Metro
36
00:01:44,119 –> 00:01:46,829
در مشخصاتی که اینجا می بینید
37
00:01:46,829 –> 00:01:50,369
پارامترها با رنگ قرمز باید
38
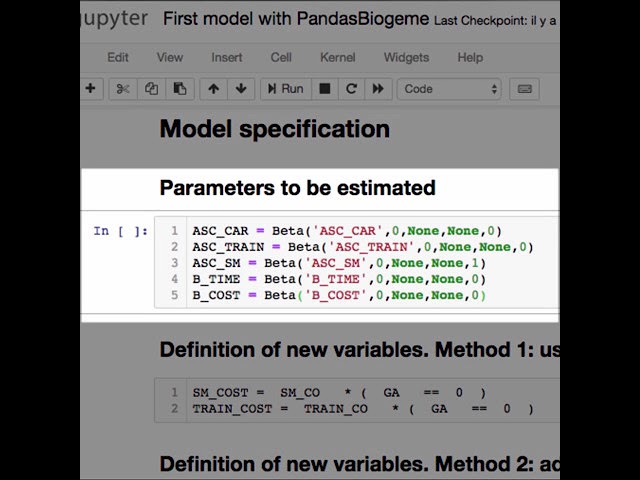
00:01:50,369 –> 00:01:52,560
از روی داده هایی که برای همیشه داریم تخمین زده شود
39
00:01:52,560 –> 00:01:58,340
بله C آموزش یک ماشین AC زمان B و هزینه B
40
00:01:58,340 –> 00:02:02,969
حالا بیایید ببینیم چگونه چنین مدلی را
41
00:02:02,969 –> 00:02:06,840
با استفاده از نحو پرادا بیوژن که آماده کرده ام کدنویسی کنیم.
42
00:02:06,840 –> 00:02:09,628
یک دفترچه ثبت نام مشتری برای نشان دادن
43
00:02:09,628 –> 00:02:11,940
مراحل مختلف
44
00:02:11,940 –> 00:02:13,380
مشخصات مدل و
45
00:02:13,380 –> 00:02:18,150
تخمین پارامترها اولین
46
00:02:18,150 –> 00:02:22,370
کاری که باید انجام دهید این است که سه بسته
47
00:02:22,370 –> 00:02:26,820
da da را وارد کنید که بسته پایتون است
48
00:02:26,820 –> 00:02:29,760
که برای آن مدیریت و
49
00:02:29,760 –> 00:02:32,970
تجزیه و تحلیل طراحی شده است و در اینجا از
50
00:02:32,970 –> 00:02:38,130
میانبر PD استفاده می کنیم. سپس توسط
51
00:02:38,130 –> 00:02:40,710
یک پایگاه داده ژن نقطه ای
52
00:02:40,710 –> 00:02:43,140
که بسته ژن زیستی است که برای
53
00:02:43,140 –> 00:02:45,870
تهیه پایگاه داده طراحی شده است به محصول مراجعه کنید و ما از
54
00:02:45,870 –> 00:02:49,710
میانبر DB و سپس توسط og m dot bio g
55
00:02:49,710 –> 00:02:53,060
m– به این ترتیب استفاده خواهیم کرد و ما از راه میانبر
56
00:02:53,060 –> 00:02:59,820
بیو برای مراجعه به آن استفاده خواهیم کرد، اکنون اولین
57
00:02:59,820 –> 00:03:01,440
کاری که باید انجام دهیم این است که داده ها را آماده
58
00:03:01,440 –> 00:03:03,900
کنیم و داده ها را از یک فایل داده مرتبط کنیم.
59
00:03:03,900 –> 00:03:06,360
به نام Swiss-made for Dat که
60
00:03:06,360 –> 00:03:09,180
از اینترنت قابل دسترسی است و ما از
61
00:03:09,180 –> 00:03:13,170
تابع پودری به نام جدول خواندن استفاده
62
00:03:13,170 –> 00:03:16,110
می کنیم، فایل داده کثیف را می خواند و
63
00:03:16,110 –> 00:03:19,310
نتایج را در قاب داده حاشیه ذخیره می کند،
64
00:03:19,310 –> 00:03:22,290
در واقع ما می توانیم این پودر را چاپ کنیم که
65
00:03:22,290 –> 00:03:24,600
توهین می کند همانطور که می بینید. به تعداد
66
00:03:24,600 –> 00:03:26,790
متغیرها ستون در
67
00:03:26,790 –> 00:03:30,720
فایل داده داشته باشیم و به تعداد خطوط
68
00:03:30,720 –> 00:03:36,270
مشاهدات، ده هزار و
69
00:03:36,270 –> 00:03:38,730
هفتصد و بیست و هشت صفر و بیست و
70
00:03:38,730 –> 00:03:43,440
هشت ستون داریم راه دیگر برای مشاهده
71
00:03:43,440 –> 00:03:47,450
داده ها استفاده از تابع توصیف است
72
00:03:47,450 –> 00:03:50,820
که برای هر ستون بنابراین برای هر
73
00:03:50,820 –> 00:03:52,950
متغیر در این قاب داده،
74
00:03:52,950 –> 00:03:56,130
آمار ارزشی را ارائه می دهد، تعداد میانگین
75
00:03:56,130 –> 00:03:59,430
انحراف استاندارد را ارائه می دهد و به
76
00:03:59,430 –> 00:04:01,770
همین ترتیب، نمونه ای از پایگاه داده ژن زیستی را
77
00:04:01,770 –> 00:04:05,459
با ارائه یک نام و
78
00:04:05,459 –> 00:04:10,080
چارچوب داده پودر به عنوان آرگومان در طول ساخت
79
00:04:10,080 –> 00:04:11,730
، ایجاد می کنیم. استفاده از این نمونه
80
00:04:11,730 –> 00:04:14,670
Biogen فایلی به نام آدرس نقطه
81
00:04:14,670 –> 00:04:18,450
py ایجاد می کند که در واقع تمام نام ستون
82
00:04:18,450 –> 00:04:21,870
ها را به عنوان متغیر تعریف
83
00:04:21,870 –> 00:04:24,340
می کند تا بتوانیم از این
84
00:04:24,340 –> 00:04:26,440
متغیرها استفاده کنیم که باید این فایل را وارد
85
00:04:26,440 –> 00:04:29,950
کنیم و از این عبارت از
86
00:04:29,950 –> 00:04:35,500
شروع import سرصفحه استفاده می کنیم که پس از آن باید
87
00:04:35,500 –> 00:04:37,240
برخی از مشاهدات را که
88
00:04:37,240 –> 00:04:40,720
برای تخمین مدل نمیخواهیم حذف کنیم، ابتدا
89
00:04:40,720 –> 00:04:44,320
اندازه نمونه را قبلاً چاپ میکنیم و همانطور که
90
00:04:44,320 –> 00:04:46,660
قبلاً دیدیم ده هزار و
91
00:04:46,660 –> 00:04:49,120
هفتصد و بیست و هشت است و سپس
92
00:04:49,120 –> 00:04:52,750
یک متغیر استثنا تعریف میکنیم و ایده این است که
93
00:04:52,750 –> 00:04:56,160
این متغیر باید یک باشد اگر
94
00:04:56,160 –> 00:04:59,169
مشاهده باید حذف شود و
95
00:04:59,169 –> 00:05:02,889
در غیر این صورت این شرط می گوید
96
00:05:02,889 –> 00:05:05,850
که همه مشاهدات را حذف می کنیم به
97
00:05:05,850 –> 00:05:10,389
طوری که هدف یک نباشد و شروع
98
00:05:10,389 –> 00:05:13,300
پیشنهادی سه نباشد یا
99
00:05:13,300 –> 00:05:16,780
انتخاب صفر باشد نه اینکه
100
00:05:16,780 –> 00:05:21,190
ضرب با پایان منطقی و
101
00:05:21,190 –> 00:05:23,590
جمع همراه باشد. با یک منطقی مرتبط است یا
102
00:05:23,590 –> 00:05:27,490
و چون باید بررسی کنیم که آیا این
103
00:05:27,490 –> 00:05:29,860
متغیر صفر از یک است، در واقع
104
00:05:29,860 –> 00:05:32,550
بررسی می کنیم که آیا بزرگتر از صفر است یا خیر
105
00:05:32,550 –> 00:05:37,600
و سپس ما
106
00:05:37,600 –> 00:05:39,370
107
00:05:39,370 –> 00:05:42,550
اگر اندازه نمونه را چاپ
108
00:05:42,550 –> 00:05:45,610
کنیم بعداً متوجه می شویم که شش
109
00:05:45,610 –> 00:05:49,690
هزار و 768 مشاهدات در نمونه باقی مانده است، این متغیر حذف را به
110
00:05:49,690 –> 00:05:54,220
تابع حذف پایگاه داده ارائه دهیم، اکنون به مشخصات مدل منتقل می
111
00:05:54,220 –> 00:05:57,760
کنیم ابتدا
112
00:05:57,760 –> 00:06:00,729
پارامترهایی را که تخمین زده می شوند لیست می کنیم تا
113
00:06:00,729 –> 00:06:03,460
تعریف کنیم. یک متغیر پایتون برای هر یک از
114
00:06:03,460 –> 00:06:07,030
آنها و برابر است با تابع
115
00:06:07,030 –> 00:06:11,740
بتا که پنج آرگومان می گیرد، اولین
116
00:06:11,740 –> 00:06:15,190
آرگومان نام پارامتری
117
00:06:15,190 –> 00:06:18,400
است که توسط زیست شناسی استفاده می شود.
118
00:06:18,400 –> 00:06:20,740
119
00:06:20,740 –> 00:06:24,220
120
00:06:24,220 –> 00:06:26,139
متغیر پایتون که با پارامتر مرتبط است
121
00:06:26,139 –> 00:06:29,919
آرگومان دوم
122
00:06:29,919 –> 00:06:33,190
مقدار شروع پارامتر برای
123
00:06:33,190 –> 00:06:34,300
تخمین است در
124
00:06:34,300 –> 00:06:36,220
اکثر مواقع مقدار صفر
125
00:06:36,220 –> 00:06:40,000
مناسب است، دو آرگومان بعدی
126
00:06:40,000 –> 00:06:43,300
کران پایین و بالای
127
00:06:43,300 –> 00:06:46,120
مقدار پارامترها هستند. نمی
128
00:06:46,120 –> 00:06:48,789
خواهید هیچ کرانی مانند این مثال قرار دهید که
129
00:06:48,789 –> 00:06:53,310
از اسم به عنوان مقدار یافت شده استفاده می کنید
130
00:06:53,310 –> 00:06:55,599
و آخرین سند می تواند دو مقدار
131
00:06:55,599 –> 00:06:59,050
صفر یا یک مقدار صفر داشته باشد. یعنی
132
00:06:59,050 –> 00:07:01,330
لطفاً مقدار
133
00:07:01,330 –> 00:07:03,639
پارامتر و مقدار یک میانگین
134
00:07:03,639 –> 00:07:06,009
را تخمین بزنید این پارامتر را در طول
135
00:07:06,009 –> 00:07:07,810
تخمین به مقداری که به
136
00:07:07,810 –> 00:07:11,349
عنوان مقدار اولیه داده می شود ثابت نگه دارید، بنابراین در این مورد ما
137
00:07:11,349 –> 00:07:14,500
در واقع از این آخرین سند برای
138
00:07:14,500 –> 00:07:16,599
عادی سازی
139
00:07:16,599 –> 00:07:18,789
ثابت های خاص جایگزین برای Swiss استفاده کرده ایم. حفرهای به
140
00:07:18,789 –> 00:07:21,190
مقدار صفر داشتیم، زیرا یک را
141
00:07:21,190 –> 00:07:24,580
در آخرین عنصر قرار دادهایم، این
142
00:07:24,580 –> 00:07:26,349
ثابت خاص جایگزین تخمین
143
00:07:26,349 –> 00:07:28,659
زده نمیشود، برای ما حفظ میشود، میدانیم که
144
00:07:28,659 –> 00:07:31,000
بیش از چهار پارامتر
145
00:07:31,000 –> 00:07:33,340
برای آخرین همارزی مقدار صفر دارند به این معنی
146
00:07:33,340 –> 00:07:38,139
که تخمین زده میشوند. در مرحله بعد
147
00:07:38,139 –> 00:07:40,659
متغیرهای جدیدی را تعریف می کنیم، ما دو راه برای
148
00:07:40,659 –> 00:07:43,930
انجام این کار در honde bhaiyaji داریم، اولین
149
00:07:43,930 –> 00:07:46,479
راه استفاده از متغیرهای پایتون است، به
150
00:07:46,479 –> 00:07:49,659
عنوان مثال در اینجا ما هزینه
151
00:07:49,659 –> 00:07:53,740
تمام هزینه SM ساخت سوئیس را به عنوان SM Co تعریف می کنیم
152
00:07:53,740 –> 00:07:55,120
که نام متغیر از
153
00:07:55,120 –> 00:08:04,500
پایگاه داده x GA برابر با 0 است، به این معنی که
154
00:08:04,500 –> 00:08:08,650
ارزش هزینه برابر با 0 خواهد بود
155
00:08:08,650 –> 00:08:11,590
اگر شخص دارای اشتراک سالانه باشد، بنابراین
156
00:08:11,590 –>