در این مطلب، ویدئو پردازش زبان طبیعی (بخش 5): مدل سازی موضوع با تخصیص دیریکله پنهان در پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:24:14
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:01,190 –> 00:00:03,570
یکی دیگر از
2
00:00:03,570 –> 00:00:05,430
روشهای رایج پردازش زبان طبیعی، مدلسازی موضوع نامیده میشود،
3
00:00:05,430 –> 00:00:08,420
بگذارید مثالی را مرور
4
00:00:08,420 –> 00:00:11,099
کنیم، فرض کنید برای یک شرکت حقوقی
5
00:00:11,099 –> 00:00:13,080
کار میکنید و با شرکتی کار میکنید که در
6
00:00:13,080 –> 00:00:15,150
آن مقداری پول اختلاس شده است
7
00:00:15,150 –> 00:00:16,920
و میدانید که
8
00:00:16,920 –> 00:00:19,529
اطلاعات کلیدی در ایمیلها وجود دارد که
9
00:00:19,529 –> 00:00:22,920
در اطراف شرکت تنظیم شده است، بنابراین شما
10
00:00:22,920 –> 00:00:24,810
ایمیل ها را مرور می کنید و
11
00:00:24,810 –> 00:00:27,119
صدها هزار ایمیل وجود دارد، بنابراین
12
00:00:27,119 –> 00:00:29,400
آنچه باید انجام دهید این است که بفهمید
13
00:00:29,400 –> 00:00:32,700
کدام یک به پول در مقایسه با
14
00:00:32,700 –> 00:00:35,880
موضوعات دیگر مرتبط هستند، بنابراین آنچه می توانید انجام دهید این است که
15
00:00:35,880 –> 00:00:40,440
بتوانید درخواست دهید. برچسبهای تمام آن ایمیلها برای
16
00:00:40,440 –> 00:00:42,690
مثال برخی از این ایمیلها
17
00:00:42,690 –> 00:00:44,670
درباره پروژههایی هستند که برخی از آنها با پول سروکار دارند
18
00:00:44,670 –> 00:00:46,500
و برخی از آنها ایمیلهای شخصی هستند،
19
00:00:46,500 –> 00:00:50,750
بنابراین میتوانید آنها را
20
00:00:50,750 –> 00:00:53,370
بر اساس آنچه در متن خواندهاید برچسب بزنید
21
00:00:53,370 –> 00:00:55,469
که زمان زیادی طول میکشد یا میتوانید
22
00:00:55,469 –> 00:00:57,239
از تکنیکی به نام مدلسازی موضوع استفاده
23
00:00:57,239 –> 00:00:58,800
کنید تا بفهمید این برچسبها چیست و بهطور
24
00:00:58,800 –> 00:01:00,890
خودکار همه این ایمیلها را برچسبگذاری کنید و
25
00:01:00,890 –> 00:01:02,609
این چیزی است که ما در این مقاله
26
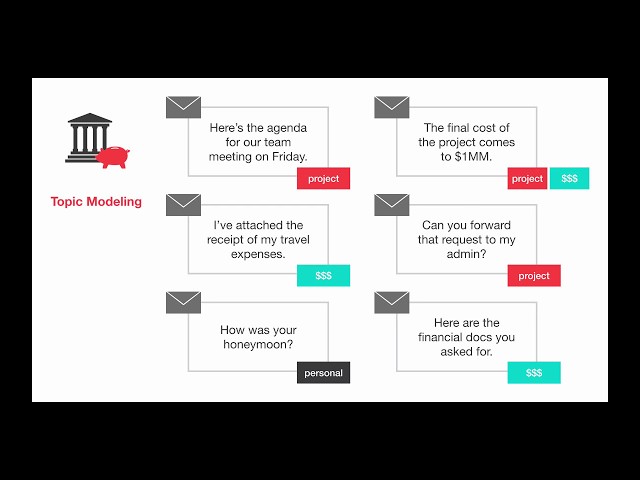
00:01:02,609 –> 00:01:05,510
با جزئیات به آن خواهیم پرداخت. بخش بعدی
27
00:01:05,510 –> 00:01:09,240
برای مدلسازی موضوع ورودی یک
28
00:01:09,240 –> 00:01:12,030
ماتریس اصطلاح سند است همانطور که در
29
00:01:12,030 –> 00:01:14,970
ویدیوی قبلی گفتم ماتریس اصطلاح سند
30
00:01:14,970 –> 00:01:17,250
ماتریسی است که در آن ردیفها اسناد مختلف هستند
31
00:01:17,250 –> 00:01:20,100
و سپس ستونها
32
00:01:20,100 –> 00:01:22,380
عبارتهای مختلف هستند و مقادیر در
33
00:01:22,380 –> 00:01:26,040
ماتریس دریچه کلمه هستند. مهم است، بنابراین
34
00:01:26,040 –> 00:01:29,189
آنچه قرار است اتفاق بیفتد این است که هر
35
00:01:29,189 –> 00:01:32,700
موضوع شامل مجموعه ای از کلمات است و در
36
00:01:32,700 –> 00:01:34,950
این مورد ترتیب مهم نیست، بنابراین
37
00:01:34,950 –> 00:01:36,119
ما با قالب کیسه کلماتی
38
00:01:36,119 –> 00:01:38,299
که قبلاً در مورد آن صحبت کردم کار می کنیم،
39
00:01:38,299 –> 00:01:41,729
اساسا شما یک کیف دارید و شما
40
00:01:41,729 –> 00:01:43,409
دسته ای از کلمات را بریزید و ترتیب
41
00:01:43,409 –> 00:01:45,780
آن کلمات مهم نیست، بنابراین هر
42
00:01:45,780 –> 00:01:50,460
موضوع فقط مجموعه ای از کلمات خواهد بود،
43
00:01:50,460 –> 00:01:52,560
روشی که ما می خواهیم مدل سازی موضوع را اعمال کنیم
44
00:01:52,560 –> 00:01:54,630
، استفاده از کتابخانه پایتون به نام
45
00:01:54,630 –> 00:01:59,520
Jennsen است تا جنسن ایجاد شود. برای انجام
46
00:01:59,520 –> 00:02:02,340
مدلسازی موضوع به همراه برخی تکنیکهای دیگر NLP
47
00:02:02,340 –> 00:02:05,040
و یکی از تکنیکهای مدلسازی موضوعی
48
00:02:05,040 –> 00:02:06,810
که واقعاً محبوب است،
49
00:02:06,810 –> 00:02:09,149
Layton dear sir allocation نام دارد و
50
00:02:09,149 –> 00:02:11,550
این همان چیزی است که
51
00:02:11,550 –> 00:02:14,090
در این بخش بعدی در مورد آن صحبت خواهیم کرد
52
00:02:14,090 –> 00:02:17,010
و سپس خروجی به مدلسازی عکس
53
00:02:17,010 –> 00:02:21,090
برای یافتن موضوعات مختلف در
54
00:02:21,090 –> 00:02:22,590
تمام متن است و اگر
55
00:02:22,590 –> 00:02:24,810
این آموزش را دنبال کردهاید، کاری که من سعی
56
00:02:24,810 –> 00:02:26,580
میکنم انجام دهم این است که روالهای کمدی مختلف
57
00:02:26,580 –> 00:02:28,980
را بررسی میکنم و سپس چیزی که میخواهم
58
00:02:28,980 –> 00:02:33,630
ببینم برای هر کمدی است.
59
00:02:33,630 –> 00:02:35,910
موضوعات مختلفی را که کمدین ها در مورد آنها صحبت می کنند معمول کنید،
60
00:02:35,910 –> 00:02:37,980
بنابراین آنچه در پایان می بینم
61
00:02:37,980 –> 00:02:40,380
این است که همه موضوعاتی
62
00:02:40,380 –> 00:02:42,209
که کمدین ها در مورد آنها صحبت می کنند چیست و سپس
63
00:02:42,209 –> 00:02:44,370
برای هر کمدین درباره چه موضوعاتی
64
00:02:44,370 –> 00:02:48,030
صحبت می کنند دوباره تکنیکی که
65
00:02:48,030 –> 00:02:49,110
من میخواهم در مورد آن صحبت کنم به نام
66
00:02:49,110 –> 00:02:52,620
لیتون عزیزان تخصیص نور وجود
67
00:02:52,620 –> 00:02:55,560
دارد چند بخش از
68
00:02:55,560 –> 00:02:57,540
این عبارت درست در اینجا یا این عبارت در اینجا
69
00:02:57,540 –> 00:02:59,700
اولی نهفته است که کلمه دیگری برای
70
00:02:59,700 –> 00:03:02,459
پنهان است بنابراین ما سعی می کنیم انجام دهیم این است که
71
00:03:02,459 –> 00:03:04,020
همه اینها را داریم متنی که در حال تلاش برای یافتن
72
00:03:04,020 –> 00:03:07,080
موضوعات پنهانی هستیم که آنها در آنجا هستند و سپس
73
00:03:07,080 –> 00:03:09,170
Dersch lay یک نوع
74
00:03:09,170 –> 00:03:11,790
توزیع احتمال است، بنابراین فعلاً آن را رها می کنم و در
75
00:03:11,790 –> 00:03:14,610
76
00:03:14,610 –> 00:03:17,160
مورد توزیع احتمالات و نحوه
77
00:03:17,160 –> 00:03:20,820
ارتباط آنها بیشتر توضیح خواهم داد. به LD در چند ثانیه خوب است،
78
00:03:20,820 –> 00:03:24,330
پس چگونه تخصیص یهودیان لیتون
79
00:03:24,330 –> 00:03:27,480
خوب کار می کند، فرض کنید من این پنج
80
00:03:27,480 –> 00:03:30,120
سند را همینجا داشتم، اگر
81
00:03:30,120 –> 00:03:31,709
یک لحظه به آنها نگاه کنید، خواهید دید که
82
00:03:31,709 –> 00:03:33,959
برخی از آنها در مورد میوه هستند، برخی از
83
00:03:33,959 –> 00:03:39,090
آنها در مورد حیوانات خانگی و غیره هستند. اگر
84
00:03:39,090 –> 00:03:41,940
بخواهم این
85
00:03:41,940 –> 00:03:45,720
مجموعه اسناد را بگیرم و LD
86
00:03:45,720 –> 00:03:48,150
a را روی آن اعمال کنم، چه اتفاقی میافتد این است
87
00:03:48,150 –> 00:03:50,700
که این را به عنوان خروجی میگیرم، میبینم
88
00:03:50,700 –> 00:03:52,590
که سند اول صد در
89
00:03:52,590 –> 00:03:56,310
صد در مورد موضوع a است و سپس دو مورد بعدی
90
00:03:56,310 –> 00:03:59,190
در مورد مبحث B و آخرین مورد
91
00:03:59,190 –> 00:04:02,700
ترکیبی از ambi است و این همان کاری است که
92
00:04:02,700 –> 00:04:04,920
ماشین برای من انجام می دهد و سپس وظیفه من به
93
00:04:04,920 –> 00:04:08,010
عنوان کاربر این است که بفهمم
94
00:04:08,010 –> 00:04:10,820
موضوع a و موضوع B واقعاً چه چیزی را نشان می دهند
95
00:04:10,820 –> 00:04:13,260
اگر نگاهی به آن موضوعات بیندازم.
96
00:04:13,260 –> 00:04:15,840
با جزئیات می توانید بگویید که موضوع a در
97
00:04:15,840 –> 00:04:18,000
مورد غذا است و موضوع گوشت گاو در مورد
98
00:04:18,000 –> 00:04:22,620
حیوانات است و بنابراین می توانید به عقب برگردید و
99
00:04:22,620 –> 00:04:26,520
سپس می بینید که من با
100
00:04:26,520 –> 00:04:27,580
این پنج قرص شروع
101
00:04:27,580 –> 00:04:30,580
کردم و از Lda برای برچسب زدن خودکار
102
00:04:30,580 –> 00:04:34,690
آنها با این دو قرص استفاده کردم. خوب پس
103
00:04:34,690 –> 00:04:36,330
این یک مثال ساده از Lda
104
00:04:36,330 –> 00:04:39,819
let بود صحبت در مورد این با کمی
105
00:04:39,819 –> 00:04:43,210
جزئیات بیشتر است، بنابراین LTE همانطور که
106
00:04:43,210 –> 00:04:45,039
قبلا ذکر کردم همه چیز در مورد احتمال به
107
00:04:45,039 –> 00:04:47,050
توزیع است و
108
00:04:47,050 –> 00:04:49,870
توزیع احتمال روش پیچیده تری برای
109
00:04:49,870 –> 00:04:54,669
گفتن ترکیبی از چیزهای مختلف است، بنابراین در
110
00:04:54,669 –> 00:04:57,039
سمت چپ اینجا می گویم که هر سند شامل مواردی است
111
00:04:57,039 –> 00:05:00,490
ترکیبی از موضوعات راه دیگری
112
00:05:00,490 –> 00:05:03,000
برای بیان این موضوع به زبان فنی تر این است که
113
00:05:03,000 –> 00:05:05,860
هر سند
114
00:05:05,860 –> 00:05:09,250
توزیع احتمالی موضوعات است، بنابراین به چه
115
00:05:09,250 –> 00:05:14,250
معنی است که هر سند در اینجا
116
00:05:14,250 –> 00:05:15,419
[موسیقی]
117
00:05:15,419 –> 00:05:20,560
تقسیم می شود و بین چند موضوع مختلف تقسیم
118
00:05:20,560 –> 00:05:24,219
می شود، بنابراین خواهید دید برای سند اول
119
00:05:24,219 –> 00:05:26,650
صد در صد موضوع a است
120
00:05:26,650 –> 00:05:29,889
و آخرین سند ترکیبی یا
121
00:05:29,889 –> 00:05:33,610
توزیعی از موضوعات مختلف در
122
00:05:33,610 –> 00:05:36,639
سمت راست در اینجا خواهید دید که هر
123
00:05:36,639 –> 00:05:39,930
موضوعی یک توزیع احتمال کلمات است
124
00:05:39,930 –> 00:05:42,729
راه ساده تر برای گفتن اینکه هر
125
00:05:42,729 –> 00:05:47,199
موضوع ترکیبی است از کلمات، بنابراین شما موضوع را
126
00:05:47,199 –> 00:05:50,409
در بالای صفحه می بینید، آن ها همه کلماتی
127
00:05:50,409 –> 00:05:54,099
هستند که در کل مجموعه ما یا
128
00:05:54,099 –> 00:05:56,830
مجموعه کاملی از اسناد وجود دارد و می
129
00:05:56,830 –> 00:06:00,099
توانید آن را در تاپیک در موضوع
130
00:06:00,099 –> 00:06:03,039
موز غذا مشاهده کنید. خیلی
131
00:06:03,039 –> 00:06:06,400
اتفاق میافتد و کلم پیچ زیاد اتفاق میافتد و به این ترتیب میدانید
132
00:06:06,400 –> 00:06:10,539
که آن موضوع غذا است،
133
00:06:10,539 –> 00:06:13,629
سپس موضوع حیوانات را دارید و میبینید
134
00:06:13,629 –> 00:06:16,360
بچهگربهها خیلی اتفاق میافتند تولهسگ و ناز خیلی اتفاق میافتد،
135
00:06:16,360 –> 00:06:18,430
بنابراین برای
136
00:06:18,430 –> 00:06:20,560
حیوانات منطقیتر است، بنابراین دوباره کل ایده پشت
137
00:06:20,560 –> 00:06:23,080
تخصیص های Schley رهبر این است که شما
138
00:06:23,080 –> 00:06:24,449
همه چیز را به عنوان یک توزیع احتمال می بینید،
139
00:06:24,449 –> 00:06:28,180
بنابراین هر سند توزیعی از
140
00:06:28,180 –> 00:06:30,849
موضوعات است و هر موضوعی توزیعی
141
00:06:30,849 –> 00:06:36,460
از کلمات است، خوب، پس چگونه تخصیص Layton daresay
142
00:06:36,460 –> 00:06:38,830
واقعاً کار می کند اکنون که
143
00:06:38,830 –> 00:06:40,419
ما این توزیع های احتمال را در
144
00:06:40,419 –> 00:06:40,990
ذهن داریم،
145
00:06:40,990 –> 00:06:48,130
خوب اجازه دهید یک به عنوان مثال، دوباره
146
00:06:48,130 –> 00:06:51,550
هدف ما این است که ما می خواهیم Lda در مورد
147
00:06:51,550 –> 00:06:54,370
ترکیب موضوع در هر سند و ترکیب کلمه
148
00:06:54,370 –> 00:06:58,630
در هر موضوع بیاموزد، بنابراین اولین کاری که
149
00:06:58,630 –> 00:07:01,060
باید انجام دهیم این است که تعداد
150
00:07:01,060 –> 00:07:03,900
موضوعاتی را که فکر می کنیم در مجموعه ما
151
00:07:03,900 –> 00:07:07,449
در این مثال اول وجود دارد انتخاب کنیم. جایی که ما غذا
152
00:07:07,449 –> 00:07:10,020
و حیوانات داشتیم من دو موضوع را انتخاب کردم و
153
00:07:10,020 –> 00:07:12,370
این مقدار بسیار استانداردی برای شروع است.
154
00:07:12,370 –> 00:07:13,990
155
00:07:13,990 –> 00:07:15,849
156
00:07:15,849 –> 00:07:22,500
ns در همان ابتدا این
157
00:07:22,650 –> 00:07:26,080
است که Lda به تمام کلمات موجود در
158
00:07:26,080 –> 00:07:28,210
مجموعه شما یا همه کلمات موجود در
159
00:07:28,210 –> 00:07:30,580
اسناد موجود در مجموعه نگاه می کند و
160
00:07:30,580 –> 00:07:33,220
به طور تصادفی هر کلمه در هر
161
00:07:33,220 –> 00:07:36,370
سند را به یکی از دو موضوع اختصاص می
162
00:07:36,370 –> 00:07:39,729
دهد. در بالا سمت راست
163
00:07:39,729 –> 00:07:42,490
، ما اولین سند خود را داریم و فرض
164
00:07:42,490 –> 00:07:45,729
کنید کلمه موز سند یک به
165
00:07:45,729 –> 00:07:49,300
طور تصادفی به مبحث B که موضوع حیوانات است، اختصاص داده می شود
166
00:07:49,300 –> 00:07:52,300
، بنابراین در حال حاضر می دانیم
167
00:07:52,300 –> 00:07:54,340
که این نادرست است، اما اشکالی ندارد،
168
00:07:54,340 –> 00:07:58,770
این اولین تصادفی است. تکلیف
169
00:07:59,039 –> 00:08:02,590
بسیار خوب است، بنابراین اکنون آنچه اتفاق میافتد این است که بعد از
170
00:08:02,590 –> 00:08:05,110
تکالیف تصادفی، LTA
171
00:08:05,110 –> 00:08:08,650
همه کلمهها و موضوع را این
172
00:08:08,650 –> 00:08:09,699
بار در هر سند بررسی میکند،
173
00:08:09,699 –> 00:08:11,650
بنابراین کاری که میخواهد انجام دهد این است که
174
00:08:11,650 –> 00:08:13,960
سند یک را در بالا سمت راست مرور میکند
175
00:08:13,960 –> 00:08:15,820
، به آن کلمه banana نگاه میکند.
176
00:08:15,820 –> 00:08:18,520
به عنوان مثال و به موضوعی
177
00:08:18,520 –> 00:08:20,860
که به آن اختصاص داده شده است نگاه می کند که در این
178
00:08:20,860 –> 00:08:23,590
مورد موضوع B یا حیوانات بود و بنابراین اکنون
179
00:08:23,590 –> 00:08:25,479
دو کار را انجام
180
00:08:25,479 –> 00:08:28,509
می دهد و به این موضوع نگاه می کند که چند بار این موضوع در سند رخ می دهد،
181
00:08:28,509 –> 00:08:30,940
بنابراین چند بار این موضوع opic B
182
00:08:30,940 –> 00:08:33,969
حیوانات یک شخص را مستند می کند و
183
00:08:33,969 –> 00:08:36,450
همچنین به بررسی تعداد دفعات استفاده از کلمه
184
00:08:36,450 –> 00:08:40,360
در مبحث کلی می پردازد، بنابراین هر چند وقت
185
00:08:40,360 –> 00:08:42,909
یکبار کلمه موز تکرار می شود و
186
00:08:42,909 –> 00:08:46,420
موضوع B یا موضوع حیوانات و ما
187
00:08:46,420 –> 00:08:49,329
از اسلاید قبلی متوجه شدیم که اغلب
188
00:08:49,329 –> 00:08:51,550
موز درست نیست. بیشتر در موضوع غذا رخ می دهد،
189
00:08:51,550 –> 00:08:54,830
بنابراین بر اساس این دو مورد
190
00:08:54,830 –> 00:08:57,530
، کاری که قرار است انجام دهد این است که یک
191
00:08:57,530 –> 00:09:00,170
موضوع جدید برای آن کلمه
192
00:09:00,170 –> 00:09:03,830
موز ایجاد می کند، بنابراین دوباره با
193
00:09:03,830 –> 00:09:06,620
مثال موز به نظر می رسد حیوانات
194
00:09:06,620 –> 00:09:09,170
اغلب در سند یک و موز وجود ندارند
195
00:09:09,170 –> 00:09:11,870
و در مبحث B زیاد اتفاق می افتد، بنابراین
196
00:09:11,870 –> 00:09:13,900
کاری که قرار است انجام شود این است که
197
00:09:13,900 –> 00:09:16,850
موضوع موز
198
00:09:16,850 –> 00:09:19,130
را مجدداً اختصاص می دهد، قبلاً به مبحث B اختصاص داده می شد، اکنون
199
00:09:19,130 –> 00:09:21,500
به موضوع a اختصاص داده می شود که
200
00:09:21,500 –> 00:09:23,510
غذا است و به نظر می رسد که تکلیف بهتری باشد
201
00:09:23,510 –> 00:09:27,550
، بنابراین Lda
202
00:09:27,550 –> 00:09:30,230
دوباره اگر به گلوله سوم در آنجا نگاه کنید،
203
00:09:30,230 –> 00:09:32,330
کاری که انجام می دهد این است که به طور تصادفی
204
00:09:32,330 –> 00:09:35,420
هر کلمه در سند را به یکی
205
00:09:35,420 –> 00:09:38,330
از دو مبحث به عنوان اولین پاس اختصاص می دهد،
206
00:09:38,330 –> 00:09:40,940
سپس از هر کلمه در کل مجموعه می گذرد
207
00:09:40,940 –> 00:09:44,930
تا ببیند آیا سند شما موضوع را به شما می گوید یا خیر.
208
00:09:44,930 –> 00:09:47,840
gnment درست است و بعد از یک
209
00:09:47,840 –> 00:09:49,820
بار تکرار می توانید به
210
00:09:49,820 –> 00:09:51,590
عقب برگردید و تکرار دوم را
211
00:09:51,590 –> 00:09:54,140
بررسی کنید تا تکالیف موضوعی کلمات را
212
00:09:54,140 –> 00:09:55,580
که می خواهید بارها
213
00:09:55,580 –> 00:09:58,220
و بارها انجام دهید بررسی کنید و در نهایت
214
00:09:58,220 –> 00:10:00,290
موضوعات شروع به معنی دار شدن می کنند و سپس
215
00:10:00,290 –> 00:10:03,320
وظیفه شما به عنوان انسان این است که موضوعات را تفسیر کنید
216
00:10:03,320 –> 00:10:05,600
و بفهمید که ما واقعاً چه موضوعاتی را
217
00:10:05,600 –> 00:10:08,750
نشان می دهیم، بنابراین
218
00:10:08,750 –> 00:10:11,290
این بسیار پیچیده به نظر می رسد، خوشبختانه
219
00:10:11,290 –> 00:10:14,960
جنسن این قسمت را برای شما انجام می دهد، بنابراین تنها کاری که
220
00:10:14,960 –> 00:10:16,940
باید انجام دهید این است که بدانید هدف شما این
221
00:10:16,940 –> 00:10:19,670
است که از LD a برای انجام مدلسازی موضوع استفاده کنید،
222
00:10:19,670 –> 00:10:21,230
باید تعداد موضوعات خود را انتخاب کنید و
223
00:10:21,230 –> 00:10:23,740
سپس باید تکرارهای خود را تنظیم کنید و
224
00:10:23,740 –> 00:10:30,770
میتوانید LD را اجرا کنید و جنسن خوب است، بنابراین
225
00:10:30,770 –> 00:10:33,080
اجازه دهید ابتدا جزئیات آنچه
226
00:10:33,080 –> 00:10:36,410
را که برای تبدیل LD به کار نیاز دارید بررسی کنیم. شما
227
00:10:36,410 –> 00:10:39,410
باید ورودی های خود را مشخص کنید، بنابراین یکی از
228
00:10:39,410 –> 00:10:43,070
آن ماتریس اصطلاح سند است که
229
00:10:43,070 –> 00:10:44,510
من نمونه ای از آن را در دفترچه مشتری نشان خواهم داد،
230
00:10:44,510 –> 00:10:47,360
دو تعداد موضوعات و
231
00:10:47,360 –> 00:10:49,640
سه تعداد تکرارهایی است که
232
00:10:49,640 –> 00:10:52,640
می خواهید آن را طی کند، بنابراین جنسن چه
233
00:10:52,640 –> 00:10:54,920
خواهد کرد. انجام این کار این است که به
234
00:10:54,920 –> 00:10:56,470
فرآیند مرور کل سند اختصاص
235
00:10:56,470 –> 00:10:58,850
مجدد آن تکالیف موضوعی میرود و
236
00:10:58,850 –> 00:11:01,070
سپس بهترین توزیع کلمه را
237
00:11:01,070 –> 00:11:03,410
برای هر موضوع و
238
00:11:03,410 –> 00:11:05,510
توزیع موضوع برای هر سند پیدا میکند، بنابراین دوباره
239
00:11:05,510 –> 00:11:07,820
برای هر موضوعی که قرار است مشخص شود این به چه معناست.
240
00:11:07,820 –> 00:11:08,660
241
00:11:08,660 –> 00:11:10,579
ترکیبی از کلماتی که
242
00:11:10,579 –> 00:11:12,139
برای آن موضوع بهترین هستند چیست و سپس برای هر
243
00:11:12,139 –> 00:11:14,269
سند، مشخص میشود
244
00:11:14,269 –> 00:11:16,550
که بهترین ترکیب از موضوعات برتر که
245
00:11:16,550 –> 00:11:20,360
برای آن سند بیشترین معنا را دارد کدام است و
246
00:11:20,360 –> 00:11:22,940
سپس خروجی این مرحله، کلمات برتر
247
00:11:22,940 –> 00:11:26,180
در هر موضوع است. فرض کنید ما دو
248
00:11:26,180 –> 00:11:30,110
موضوع را برای Lda انتخاب کردیم که قرار است چه اتفاقی بیفتد
249
00:11:30,110 –> 00:11:33,889
این است که به من بگوید مبحث 1
250
00:11:33,889 –> 00:11:36,199
عمدتاً از این کلمات تشکیل شده است و سپس مبحث
251
00:11:36,199 –> 00:11:38,509
2 عمدتاً از این کلمات تشکیل شده است و
252
00:11:38,509 –> 00:11:40,939
سپس وظیفه شما این است که بفهمید آیا آنها
253
00:11:40,939 –> 00:11:42,920
منطقی هستند یا خیر. آنها
254
00:11:42,920 –> 00:11:45,050
معنی ندارند، سپس پارامترهای دیگری وجود دارد
255
00:11:45,050 –> 00:11:47,870
که می توانید آنها را تغییر دهید



![فیلم آموزشی: پروژه OTP Generator در پایتون ( 11 خط ) [ پروژه مبتدی ] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/-ps98ixrP1Uimage2.jpg)