

در این مطلب، ویدئو آموزش ساخت مدل در پایتون برای تجزیه و تحلیل احساسات از داده های توییتر با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,960 –> 00:00:04,670
[موسیقی]
2
00:00:04,670 –> 00:00:06,870
سلام به همه از شما برای پیوستن به
3
00:00:06,870 –> 00:00:09,480
تجزیه و تحلیل احساسات وبینار امروز برای
4
00:00:09,480 –> 00:00:11,639
تجارت الگوریتمی از طرف
5
00:00:11,639 –> 00:00:13,320
تریاک مورد نیاز سپاسگزاریم، مایلیم از دیتا کمپ برای
6
00:00:13,320 –> 00:00:15,360
میزبانی این وبینار با ما تشکر کنیم و اگر
7
00:00:15,360 –> 00:00:17,220
آموخته اید که به دنبال یادگیری بسیاری از
8
00:00:17,220 –> 00:00:18,660
مهارت های علم داده هستید تحت پوشش قرار گرفتن در
9
00:00:18,660 –> 00:00:20,460
این کمپ داده وبینار یک
10
00:00:20,460 –> 00:00:22,109
پلت فرم یادگیری عالی برای این مهارت ها است و
11
00:00:22,109 –> 00:00:23,609
ما شما را تشویق می کنیم که آنها را در کمپ داده بررسی کنید. آنها
12
00:00:23,609 –> 00:00:25,710
13
00:00:25,710 –> 00:00:29,070
دوره های آنلاین تعاملی در پایتون SQL ما دارند
14
00:00:29,070 –> 00:00:31,529
و موارد دیگر.
15
00:00:31,529 –> 00:00:34,020
و
16
00:00:34,020 –> 00:00:36,540
17
00:00:36,540 –> 00:00:37,770
پیشینه علم داده مکس باربرا و نه مکس پیشینه ماکس در آمار ریاضیات کاربردی
18
00:00:37,770 –> 00:00:40,590
و امور مالی کمی است. او
19
00:00:40,590 –> 00:00:42,540
مجموعه سخنرانی های آنلاین را در canto
20
00:00:42,540 –> 00:00:44,309
peon اجرا می کند و مسئول برنامه های درسی کارگاه ها
21
00:00:44,309 –> 00:00:46,800
و محتوای آموزشی است و
22
00:00:46,800 –> 00:00:48,329
علاوه بر تجربه
23
00:00:48,329 –> 00:00:50,070
تجارت الگوریتمی ارزهای
24
00:00:50,070 –> 00:00:52,620
دیجیتال در تخمین سوگیری کوواریانس، مسئول برنامه های درسی کارگاه ها و محتوای آموزشی است.
25
00:00:52,620 –> 00:00:54,719
matrices max کارهایی در
26
00:00:54,719 –> 00:00:56,850
زمینه ریاضیات نظری منتشر کرده است که با دانشگاه های برتر کار می کند
27
00:00:56,850 –> 00:00:58,710
28
00:00:58,710 –> 00:01:00,989
از جمله دانشگاه کلمبیا شیکاگو و کرنل و
29
00:01:00,989 –> 00:01:03,300
دارای مدرک کارشناسی ارشد در رشته مالی ریاضی
30
00:01:03,300 –> 00:01:06,600
از دانشگاه بوستون است. از همه تشکر می کنم
31
00:01:06,600 –> 00:01:09,330
برای صفحه مقدماتی، همانطور که پیج
32
00:01:09,330 –> 00:01:12,000
گفت من حداکثر مورگان هستم و من کوانتو
33
00:01:12,000 –> 00:01:15,030
کیان را می پزم او همیشه سرگرم کننده است، بنابراین این صحبت من است برای
34
00:01:15,030 –> 00:01:16,740
خرید شادی
35
00:01:16,740 –> 00:01:18,240
چون شما همیشه باید
36
00:01:18,240 –> 00:01:19,920
هر زمان که سخنرانی می کنید یک عنوان تحریک
37
00:01:19,920 –> 00:01:20,850
38
00:01:20,850 –> 00:01:22,950
کننده داشته باشید زیرا این نیمی از ارزش سرگرمی است و زیرنویس
39
00:01:22,950 –> 00:01:25,170
از lc-ms استفاده می کند تا احساسات را به معامله تبدیل کند
40
00:01:25,170 –> 00:01:29,189
همانطور که همه می توانید بخوانید بنابراین من
41
00:01:29,189 –> 00:01:30,479
اساساً در
42
00:01:30,479 –> 00:01:33,390
این سخنرانی چه خواهم کرد. دو مرحله جداگانه است،
43
00:01:33,390 –> 00:01:35,880
مرحله اول این است که چگونه پردازش زبان طبیعی اولیه را انجام دهیم
44
00:01:35,880 –> 00:01:37,860
45
00:01:37,860 –> 00:01:39,840
تا چگونه مدل احساسات را بسازید
46
00:01:39,840 –> 00:01:41,520
و سپس من در مورد اینکه چگونه
47
00:01:41,520 –> 00:01:44,579
می توانیم واقعاً از این مدل برای
48
00:01:44,579 –> 00:01:50,100
تجارت الگوریتمی استفاده کنیم، صحبت خواهم کرد، بنابراین اجازه دهید ابتدا یک
49
00:01:50,100 –> 00:01:51,000
سلب مسئولیت
50
00:01:51,000 –> 00:01:53,579
هیچ کدام از اینها توصیه سرمایه گذاری نیست،
51
00:01:53,579 –> 00:01:58,409
این فقط سرگرم کننده است، بله،
52
00:01:58,409 –> 00:02:00,810
و همانطور که عوضی گفت من بسیاری از
53
00:02:00,810 –> 00:02:02,969
مطالب آموزشی را در اینجا مدیریت می کنم و این
54
00:02:02,969 –> 00:02:05,340
چیزی است که تحت عنوان من قرار می گیرد.
55
00:02:05,340 –> 00:02:07,860
روی الگوریتمهای معبد زیادی کار کردهایم. مثالهای زیادی از
56
00:02:07,860 –> 00:02:09,570
چیزهای جالب، بخشی از کارهایی
57
00:02:09,570 –> 00:02:11,490
که مجموعه سخنرانیهای کانتو P انجام میدهد این است که
58
00:02:11,490 –> 00:02:14,460
به افراد پیشزمینهای در ریاضیات
59
00:02:14,460 –> 00:02:17,310
و آمار و امور مالی لازم برای
60
00:02:17,310 –> 00:02:18,720
ایجاد الگوریتمهای معاملاتی میدهد، زیرا این
61
00:02:18,720 –> 00:02:21,180
نوع به نتیجه ما کمک میکند.
62
00:02:21,180 –> 00:02:23,550
علاقه ویژه ای به جذب هرچه
63
00:02:23,550 –> 00:02:25,260
بیشتر افراد به خصوص کسانی
64
00:02:25,260 –> 00:02:27,150
که بخشی از جامعه ما هستند به
65
00:02:27,150 –> 00:02:28,950
امور مالی کمی علاقه مند هستند و
66
00:02:28,950 –> 00:02:31,470
تا جایی که ممکن است الگوریتم های زیادی را توسعه دهیم
67
00:02:31,470 –> 00:02:33,480
زیرا افرادی در جامعه ما
68
00:02:33,480 –> 00:02:35,190
که بهترین الگوریتم ها را ایجاد می کنند،
69
00:02:35,190 –> 00:02:38,060
می توانند به آنها اختصاص داده شوند و
70
00:02:38,060 –> 00:02:41,600
در کل مجموعه ما نویسنده شوید، بنابراین ما این
71
00:02:41,600 –> 00:02:43,800
انگیزه مستقیم را داریم که مطمئن شویم
72
00:02:43,800 –> 00:02:45,030
مردم تا حد ممکن در
73
00:02:45,030 –> 00:02:48,720
امور مالی کمی می دانند، بنابراین
74
00:02:48,720 –> 00:02:51,390
پردازش زبان طبیعی علاوه بر کلمات سرگرم کننده
75
00:02:51,390 –> 00:02:52,020
76
00:02:52,020 –> 00:02:54,180
، مجموعه ای از علوم کامپیوتر
77
00:02:54,180 –> 00:02:56,010
و ابزارهای زبان شناسی است که برای
78
00:02:56,010 –> 00:02:58,260
تفسیر زبان انسان استفاده می شود. و متن و
79
00:02:58,260 –> 00:03:00,480
parlin در درجه اول در این مورد ما
80
00:03:00,480 –> 00:03:03,000
از پردازش زبان طبیعی استفاده می کنیم برای
81
00:03:03,000 –> 00:03:05,640
تعیین کمیت متن بدون ساختار و
82
00:03:05,640 –> 00:03:07,410
دلیل اهمیت این موضوع به خصوص
83
00:03:07,410 –> 00:03:09,630
در زمینه مالی کمی
84
00:03:09,630 –> 00:03:12,450
این است که داده های زیادی وجود دارد
85
00:03:12,450 –> 00:03:15,090
و در امور مالی کمی در
86
00:03:15,090 –> 00:03:16,620
معاملات الگوریتمی در معاملات به
87
00:03:16,620 –> 00:03:18,840
طور کلی بسیاری از آنچه به شما برتری می دهد
88
00:03:18,840 –> 00:03:21,780
داشتن بهتر است. مدل نسبت به شخص
89
00:03:21,780 –> 00:03:23,280
دیگری که دارای مدلی است که می تواند
90
00:03:23,280 –> 00:03:26,850
اطلاعات بیشتری نسبت به مدل
91
00:03:26,850 –> 00:03:29,270
ایستگاه بعدی به شما بدهد و اگر ما همه این
92
00:03:29,270 –> 00:03:32,880
داده های بدون ساختار را داریم، اگر می توانید
93
00:03:32,880 –> 00:03:34,680
اطلاعاتی را از آن جمع آوری کنید، اگر می توانید ساختاری اضافه کنید،
94
00:03:34,680 –> 00:03:38,280
تمام این نویز
95
00:03:38,280 –> 00:03:40,380
را به چیزی مفید تقطیر کنید. سیگنال مفید است،
96
00:03:40,380 –> 00:03:42,570
پس شما
97
00:03:42,570 –> 00:03:46,680
نسبت به فرد بعدی مزیت اطلاعاتی دارید و متن یکی
98
00:03:46,680 –> 00:03:48,630
از طولانیترین دادههای بدون ساختار است
99
00:03:48,630 –> 00:03:49,709
که صدها سال است در حال نوشتن
100
00:03:49,709 –> 00:03:52,250
چیزهایی بودهایم، بنابراین این
101
00:03:52,250 –> 00:03:55,200
اولین مکان واضح است که نگاه کنید.
102
00:03:55,200 –> 00:03:56,480
حس میکنیم که
103
00:03:56,480 –> 00:03:59,489
اطلاعاتی در متن پنهان
104
00:03:59,489 –> 00:04:02,280
میشود که برای ویژگیهای اقتصادی
105
00:04:02,280 –> 00:04:04,860
یا ویژگیهای هر سهام فردی مهم است،
106
00:04:04,860 –> 00:04:07,860
ما اطلاعات زیادی داریم.
107
00:04:07,860 –> 00:04:10,019
اسناد گزارش دهی متفاوت برای هر
108
00:04:10,019 –> 00:04:12,360
شرکت سهامی عام، ما مقالات خبری
109
00:04:12,360 –> 00:04:13,950
در مورد شرکت های سهامی عام مختلف
110
00:04:13,950 –> 00:04:15,360
داریم،
111
00:04:15,360 –> 00:04:18,180
مقالات خبری در مورد رویدادهای کلان اقتصادی
112
00:04:18,180 –> 00:04:20,010
داریم و انواع منابع رسانه های اجتماعی داریم
113
00:04:20,010 –> 00:04:21,170
که در آن افراد
114
00:04:21,170 –> 00:04:23,690
در مورد شرکت های سهامی عام در
115
00:04:23,690 –> 00:04:25,460
رویدادهای اقتصادی مختلف صحبت می کنند که می توانیم از آنها استفاده کنیم.
116
00:04:25,460 –> 00:04:27,490
همه اینها با هم برای دستیابی به
117
00:04:27,490 –> 00:04:32,630
اطلاعات به طوری که با همه منابع
118
00:04:32,630 –> 00:04:35,510
دادهها، پردازش زبان طبیعی و
119
00:04:35,510 –> 00:04:37,640
دادههای متنی تفاوتی با هم ندارند، ما باید
120
00:04:37,640 –> 00:04:40,100
زمانی را صرف پردازش دادههای خود و
121
00:04:40,100 –> 00:04:42,800
پاکسازی آنها کنیم، هر زمان که
122
00:04:42,800 –> 00:04:44,870
پروژه علم داده را شروع میکنید، کسانی که
123
00:04:44,870 –> 00:04:46,880
بیشتر آشنا هستند. با علم داده و
124
00:04:46,880 –> 00:04:49,370
پروژه های کمی به طور کلی بیشتر
125
00:04:49,370 –> 00:04:51,650
با این موضوع آشنا خواهید شد که 80٪ از هر پروژه داده شده
126
00:04:51,650 –> 00:04:54,080
و این یک آمار ساختگی است،
127
00:04:54,080 –> 00:04:55,970
اما به طور کلی درصد بسیار بالایی از
128
00:04:55,970 –> 00:04:58,370
هر پروژه محصول داده شده،
129
00:04:58,370 –> 00:05:00,500
مدیریت داده ها و تمیز کردن آنها و وارد کردن آنها به آن است.
130
00:05:00,500 –> 00:05:02,090
حالتی که در آن واقعاً قابل استفاده است،
131
00:05:02,090 –> 00:05:05,270
بنابراین هنگام برخورد با متن، چند
132
00:05:05,270 –> 00:05:07,670
چیز اصلی در این نوع y وجود دارد.
133
00:05:07,670 –> 00:05:10,250
ابتدا از فیلتر
134
00:05:10,250 –> 00:05:13,520
کردن کلمات توقف استفاده کنید و اینها کلماتی هستند که
135
00:05:13,520 –> 00:05:16,730
با فراوانی در متن به وجود می آیند، بنابراین کلماتی
136
00:05:16,730 –> 00:05:20,810
مانند a و آن که بسیار تکرار
137
00:05:20,810 –> 00:05:23,330
می شوند اما حاوی اطلاعات زیادی نیستند،
138
00:05:23,330 –> 00:05:27,200
می توانند مجموعه داده های ما را منحرف کنند
139
00:05:27,200 –> 00:05:29,060
و آسان تر است. فقط برای اینکه آنها را فیلتر
140
00:05:29,060 –> 00:05:30,440
کنیم مثل اینکه حاوی اطلاعات اضافی نیستند،
141
00:05:30,440 –> 00:05:32,060
بنابراین هیچ فایده ای ندارد
142
00:05:32,060 –> 00:05:34,640
که آنها را در آنجا قرار
143
00:05:34,640 –> 00:05:38,000
144
00:05:38,000 –> 00:05:40,400
145
00:05:40,400 –> 00:05:42,800
146
00:05:42,800 –> 00:05:46,040
دهیم. خوب، اگر بخواهم
147
00:05:46,040 –> 00:05:49,340
زمانهای مختلف فعل را انتخاب کنم، بهعنوان
148
00:05:49,340 –> 00:05:51,980
مثال، ریشه ریشهدار،
149
00:05:51,980 –> 00:05:54,250
همهی اینها ریشه یکسانی دارند،
150
00:05:54,250 –> 00:05:57,680
ریشه روی ریشه، نوعی اکتشافی خام
151
00:05:57,680 –> 00:05:59,750
است که
152
00:05:59,750 –> 00:06:01,670
انتهای همه آن کلمات را قطع میکند. که ما
153
00:06:01,670 –> 00:06:04,850
فقط کلمه ریشه را برمی گردانیم، بنابراین یک
154
00:06:04,850 –> 00:06:06,500
کلمه ریشه ممکن است در
155
00:06:06,500 –> 00:06:10,940
زمان های مختلف در یک قطعه متن خاص با
156
00:06:10,940 –> 00:06:12,530
آن استفاده شود، زمانی که در یک مشاهده معین یا
157
00:06:12,530 –> 00:06:14,210
در کل پیکره است و ما فقط
158
00:06:14,210 –> 00:06:17,360
آن را کوتاه می کنیم. به طوری که ما
159
00:06:17,360 –> 00:06:19,190
تعداد مناسبی از ارجاعات به
160
00:06:19,190 –> 00:06:21,460
یک قطعه داده شده را دریافت می کنیم که ممکن است اطلاعاتی داشته باشد
161
00:06:21,460 –> 00:06:24,260
و سپس افراد را نشانه گذاری می کنیم
162
00:06:24,260 –> 00:06:26,480
هر کلمه ای را که پس از پیش پردازش در مجموعه ما باقی می ماند را
163
00:06:26,480 –> 00:06:28,280
با یک
164
00:06:28,280 –> 00:06:33,130
نشانه عدد صحیح منحصر به فرد نمایش
165
00:06:33,439 –> 00:06:37,229
می دهیم.
166
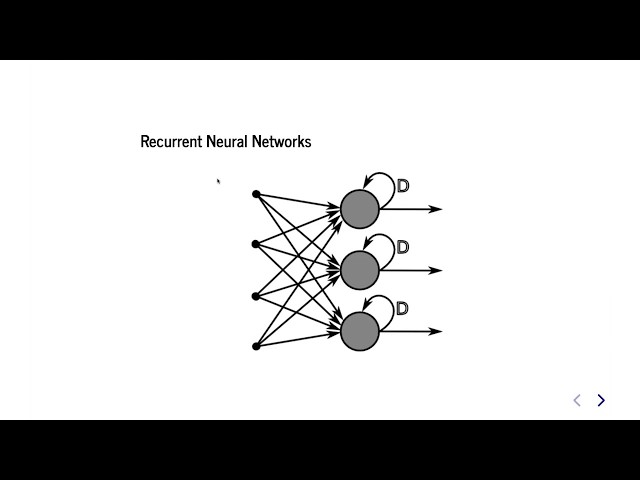
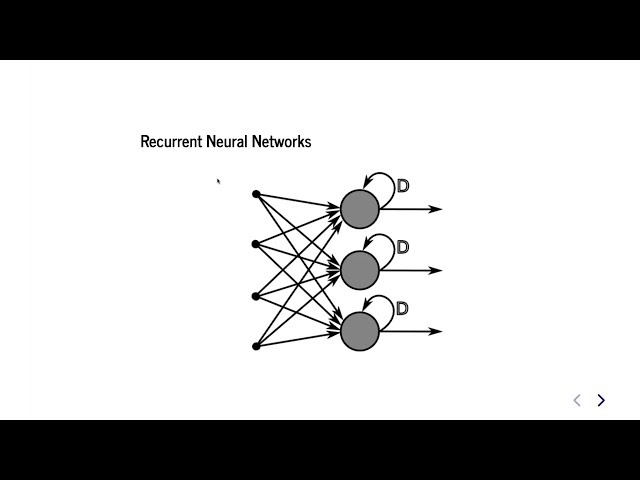
00:06:37,229 –> 00:06:40,259
ما نشانههای خود را داریم و میتوانیم وارد
167
00:06:40,259 –> 00:06:42,299
ماجراجویی شویم که تولید ویژگی است.
168
00:06:42,299 –> 00:06:44,129
من در مورد دو روش اصلی که
169
00:06:44,129 –> 00:06:47,249
ما ویژگیها را از متن تولید
170
00:06:47,249 –> 00:06:50,009
میکنیم صحبت خواهم کرد.
171
00:06:50,009 –> 00:06:52,919
172
00:06:52,919 –> 00:06:56,219
به معنای واقعی کلمه یک کیسه از کلمات
173
00:06:56,219 –> 00:06:58,559
است، به عنوان مثال اگر من عباراتی را به
174
00:06:58,559 –> 00:07:00,569
من نشان می دهد که آلفا و کارتاگو دلندا را به من نشان می دهد از من می پرسد
175
00:07:00,569 –> 00:07:03,119
که آیا می خواهم این را به
176
00:07:03,119 –> 00:07:06,389
گرم یونا یا 1 گرم در یک کیسه کلمات بشکنم، آنگاه
177
00:07:06,389 –> 00:07:10,079
باید به من و آلفا را
178
00:07:10,079 –> 00:07:12,989
برای تکه اول متن و کارتاگو
179
00:07:12,989 –> 00:07:15,899
دلندا برای تکه دوم متن من
180
00:07:15,899 –> 00:07:18,179
فقط هر جمله
181
00:07:18,179 –> 00:07:20,459
تک تک سند را می گیرم و آن را به
182
00:07:20,459 –> 00:07:24,839
n کلمه منحصر به فرد درون آن تقسیم می کنم و این فقط
183
00:07:24,839 –> 00:07:26,309
همان کلمه تک تکی است که شما خواهید یافت در اینجا توجه کنید
184
00:07:26,309 –> 00:07:27,419
که من در واقع کلمات توقف را فیلتر نکردم،
185
00:07:27,419 –> 00:07:30,839
بنابراین da هنوز در اینجا است، اما
186
00:07:30,839 –> 00:07:32,669
فعلاً در مورد آن تاکید نخواهیم کرد فقط
187
00:07:32,669 –> 00:07:35,999
برای بعد توجه داشته باشید و ویژگی واقعی
188
00:07:35,999 –> 00:07:39,079
اینجا این است که هر یک از این کلمات
189
00:07:39,079 –> 00:07:42,509
به ستونی تبدیل می شوند. این کلمات
190
00:07:42,509 –> 00:07:44,909
یک ویژگی منحصر به فرد هستند و سپس
191
00:07:44,909 –> 00:07:48,029
مقدار آن ویژگی برای هر قطعه از
192
00:07:48,029 –> 00:07:51,719
متن، تعداد آن کلمه است،
193
00:07:51,719 –> 00:07:53,969
بنابراین در آلفا به من نشان دهید که
194
00:07:53,969 –> 00:07:57,360
تعداد 1 در این متن اول و
195
00:07:57,360 –> 00:07:59,610
کارتاگو Delinda NS I’ خواهد بود.
196
00:07:59,610 –> 00:08:02,189
در متن اول تعداد 0 عدد وجود دارد که فقط
197
00:08:02,189 –> 00:08:03,689
برای متن دوم کاملاً ورق زده شده است،
198
00:08:03,689 –> 00:08:07,649
بنابراین این فقط 1 گرم است و
199
00:08:07,649 –> 00:08:09,949
می توان مجموعه ای از کلمات را نیز ایجاد کرد و
200
00:08:09,949 –> 00:08:13,889
مجموعه بعدی را که توسط Grim’s استفاده می شود برداشت کرد، بنابراین
201
00:08:13,889 –> 00:08:17,159
این هر دو کلمه متوالی در یک
202
00:08:17,159 –> 00:08:18,929
متن معین، بنابراین به من نشان دهید
203
00:08:18,929 –> 00:08:22,319
دلندا و دلندا آلفا کارتاگو
204
00:08:22,319 –> 00:08:24,989
هر کدام از اینها ویژگی های اضافی هستند
205
00:08:24,989 –> 00:08:26,819
که با
206
00:08:26,819 –> 00:08:29,039
این گرام ها در نظر می گیریم و فقط در
207
00:08:29,039 –> 00:08:31,919
هر متنی حساب می کنیم و از اینجا می توانیم
208
00:08:31,919 –> 00:08:34,438
بسازیم. حداکثر تا سه کلمه متوالی برای
209
00:08:34,438 –> 00:08:36,149
لغات متوالی پنج کلمه متوالی
210
00:08:36,149 –> 00:08:39,539
هر تعداد که ما بخواهیم به شرطی که این
211
00:08:39,539 –> 00:08:41,250
ویژگی های اضافی در واقع
212
00:08:41,250 –> 00:08:42,980
قدرت پیش بینی را به مدل ما اضافه کنند، ما
213
00:08:42,980 –> 00:08:44,570
همه این ویژگی ها را
214
00:08:44,570 –> 00:08:46,250
با هم ترکیب
215
00:08:46,250 –> 00:08:49,130
می کنیم.
216
00:08:49,130 –> 00:08:51,620
217
00:08:51,620 –> 00:08:53,870
به طور کلی یونا گرم و بر حسب گرم
218
00:08:53,870 –> 00:08:56,450
بسیار خوب است و حداقل برای
219
00:08:56,450 –> 00:08:57,980
مدل نهایی، اما من استفاده می کنم من
220
00:08:57,980 –> 00:09:01,220
واقعا عمیق تر از خرید گرم نیستم، بنابراین راه بعدی
221
00:09:01,220 –> 00:09:04,280
که می توانیم ویژگی های متن را کمی کنیم
222
00:09:04,280 –> 00:09:07,280
استفاده از جاسازی کلمه است و این
223
00:09:07,280 –> 00:09:09,140
کمی بیشتر است. از نظر ریاضی پیچیده
224
00:09:09,140 –> 00:09:11,810
تر از شمارش کلمات است، اما من همچنین
225
00:09:11,810 –> 00:09:14,390
فکر می کنم شخصاً جالب تر است
226
00:09:14,390 –> 00:09:17,210
که کاری که ما انجام می دهیم این است که ما اساساً
227
00:09:17,210 –> 00:09:19,550
کل مجموعه کلمات خود را در یک
228
00:09:19,550 –> 00:09:22,430
فضای برداری با ابعاد بالا با توجه به
229
00:09:22,430 –> 00:09:24,590
ابعادی که انتخاب می کنیم قرار می دهیم، بنابراین
230
00:09:24,590 –> 00:09:27,130
هر کلمه منفرد را به عنوان یک
231
00:09:27,130 –> 00:09:30,260
n بعدی نشان می دهیم. بردار معمولاً با n
232
00:09:30,260 –> 00:09:33,320
که بین 100 تا 300 است، بنابراین
233
00:09:33,320 –> 00:09:36,620
هر کلمه با
234
00:09:36,620 –> 00:09:39,620
100 تا 300 بعد در این مقدار نشان داده می شود.
235
00:09:39,620 –> 00:09:42,170
فضای ابعادی، به عنوان مثال در
236
00:09:42,170 –> 00:09:43,660
مجموعه ای که من در نهایت
237
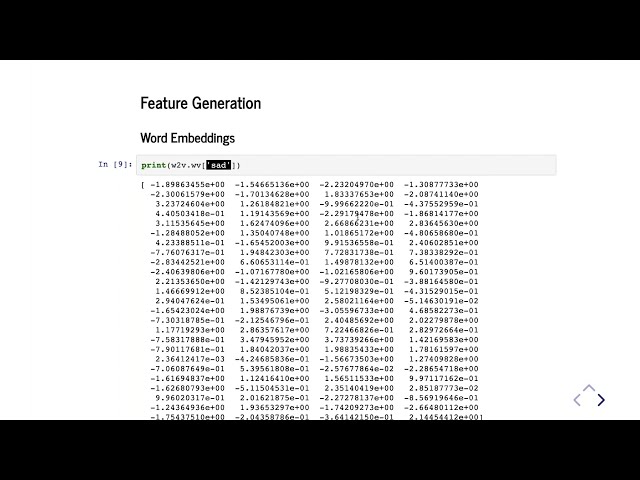
00:09:43,660 –> 00:09:48,770
کلمه برداری برای غمگین را به شما نشان خواهم داد، همین
238
00:09:48,770 –> 00:09:51,680
هیولای زشت است، اما این نشان می دهد
239
00:09:51,680 –> 00:09:54,380
که غم دقیقاً در کجای این فضا قرار دارد و
240
00:09:54,380 –> 00:09:55,760
آنچه در مورد جاسازی کلمات جالب
241
00:09:55,760 –> 00:09:57,260
است این است که می تواند به ما حس بدهد.
242
00:09:57,260 –> 00:09:59,210
243
00:09:59,210 –> 00:10:02,120
244
00:10:02,120 –> 00:10:05,180
وقتی کلمه ای را به عنوان یک بردار نشان می دهیم، می تواند به ما حس شباهت به کلمات دیگر بدهد، فقط می توانیم
245
00:10:05,180 –> 00:10:07,520
با آن بردارها همانطور رفتار کنیم که معمولاً
246
00:10:07,520 –> 00:10:09,200
با بردارها رفتار می کنیم، می توانیم آنها را اضافه کنیم، می توانیم آنها را
247
00:10:09,200 –> 00:10:10,790
کم کنیم و می توانیم ببینیم چقدر
248
00:10:10,790 –> 00:10:11,740
به هر یک نزدیک هستند. از جمله دیگر،
249
00:10:11,740 –> 00:10:15,140
ما میتوانیم ببینیم چه کلماتی بیشتر
250
00:10:15,140 –> 00:10:17,960
شبیه به کلمات دیگر هستند، بنابراین در درون
251
00:10:17,960 –> 00:10:20,330
کلمهی دادهشده embedding که من دارم،
252
00:10:20,330 –> 00:10:22,460
این کلمهای است به Veck embedding که فقط
253
00:10:22,460 –> 00:10:25,070
یک کلاسیک است، روش کلاسیک دیگر
254
00:10:25,070 –> 00:10:26,600
تعبیه کلمه مانند
255
00:10:26,600 –> 00:10:29,090
یک دکتر است. بک که یک
256
00:10:29,090 –> 00:10:31,370
سند کامل را به جای کلمات تکی جاسازی می کند
257
00:10:31,370 –> 00:10:33,710
و از رویه تقریباً مشابهی پیروی می
258
00:10:33,710 –> 00:10:35,750
کند، اما اینها کلماتی هستند که
259
00:10:35,750 –> 00:10:38,720
بیشتر شبیه به غمگین هستند و ما چیزهایی دریافت می
260
00:10:38,720 –> 00:10:41,140
کنیم که حس شهودی را ایجاد می کند، درست ناراحت کننده
261
00:10:41,140 –> 00:10:44,840
رونق افسرده است که ریشه کلمه
262
00:10:44,840 –> 00:10:47,780
یک بدبین است یا ناامید یا هر کلمه خاصی
263
00:10:47,780 –> 00:10:52,280
مانند آن ویرانگر ناامید عصبانی
264
00:10:52,280 –> 00:10:55,670
ناراحت غمگین شرمنده ناراضی شدم و ما می
265
00:10:55,670 –> 00:10:56,800
توانیم نوعی
266
00:10:56,800 –> 00:10:59,529
رابطه ریشه ای را در نحوه خرد کردن این کلمات مشاهده کنیم،
267
00:10:59,529 –> 00:11:01,420
اما همه
268
00:11:01,420 –> 00:11:04,029
اینها حس شهودی دارند درست است
269
00:11:04,029 –> 00:11:05,860
که ناراحتی و افسردگی و همه اینها منطقی است.
270
00:11:05,860 –> 00:11:08,310
کلمات بسیار نزدیک به غم انگیز
271
00:11:08,310 –> 00:11:10,360
هستند و
272
00:11:10,360 –> 00:11:13,959
در بسیاری از موارد اساساً مترادف یکدیگر هستند و روشی
273
00:11:13,959 –> 00:11:15,070
که ما در واقع برای بررسی
274
00:11:15,070 –> 00:11:17,019
شبیه بودن یا نبودن چیزی استفاده
275
00:11:17,019 –> 00:11:19,120
می کنیم شباهت کسینوس نامیده می شود که
276
00:11:19,120 –> 00:11:20,980
اساساً فقط کسینوس بین این
277
00:11:20,980 –> 00:11:23,290
بردارها و بردارهای بعدی است.
278
00:11:23,290 –> 00:11:27,250
اگر بخواهیم انتخاب کنیم
279
00:11:27,250 –> 00:11:30,010
که همیشه با این اخطار همراه می شود که
280
00:11:30,010 –> 00:11:32,470
برخی از کلمات متریک فاصله
281
00:11:32,470 –> 00:11:34,450
در بالا بهتر کار می کنند، می توانیم از سایر معیارهای فاصله استفاده کنیم. فضاهای بعدی نسبت به
282
00:11:34,450 –> 00:11:39,100
سایرین و اگر کل پیکرهای را
283
00:11:39,100 –> 00:11:42,610
که من در اینجا استفاده کردم در نظر بگیریم، همه اینها 100
284
00:11:42,610 –> 00:11:44,079
بردار بعدی هستند، میتوانیم
285
00:11:44,079 –> 00:11:46,120
اینها را در فضای دو بعدی با استفاده از
286
00:11:46,120 –> 00:11:48,370
روشی به نام T توزیع شده تصادفی
287
00:11:48,370 –> 00:11:49,690
همسایه
288
00:11:49,690 –> 00:11:51,910
بهتر نشان دهیم.
289
00:11:51,910 –> 00:11:53,769
آنچه مهم است این است که ما
290
00:11:53,769 –> 00:11:55,329
می توانیم اساساً یک طرح ریزی را از
291
00:11:55,329 –> 00:11:57,010
فضای با ابعاد بالا به
292
00:11:57,010 –> 00:11:59,190
فضای دوبعدی ببریم به گونه ای که
293
00:11:59,190 –> 00:12:02,200
این فواصل بین اشیاء در
294
00:12:02,200 –> 00:12:04,390
فضای با ابعاد بالا در فضای کم
295
00:12:04,390 –> 00:12:06,730
بعدی حفظ شود، بنابراین کاری که من انجام داده ام این است
296
00:12:06,730 –> 00:12:08,700
که کارهای بسیار زیادی انجام داده ام. خوشهبندی اولیه
297
00:12:08,700 –> 00:12:11,079
در این فضا با استفاده از روشی به نام
298
00:12:11,079 –> 00:12:15,910
اسکن HDD و من فکر میکنم که
299
00:12:15,910 –> 00:12:17,680
Sicit-Learn در دسترس نیست، اما
300
00:12:17,680 –> 00:12:19,630
بهعنوان بستهای در دسترس است که شخصی
301
00:12:19,630 –> 00:12:21,100
که روی آن ساخته شده است، بنابراین API بسیار شبیه به آن است،
302
00:12:21,100 –> 00:12:23,200
بنابراین اگر به دنبال اسکن HDD
303
00:12:23,200 –> 00:12:26,020
باشید، یک گسترش اسکن DV که
304
00:12:26,020 –> 00:12:27,570
فکر می کنم در scikit-learn است
305
00:12:27,570 –> 00:12:32,430
و آنها فقط
306
00:12:32,550 –> 00:12:35,140
روش های بسیار خوبی برای خوشه بندی هستند که
307
00:12:35,140 –> 00:12:36,550
نیازی به تعیین تعداد
308
00:12:36,550 –> 00:12:38,380
خوشه ندارند. من و rs همین الان چند خوشه منفرد را انتخاب کردیم
309
00:12:38,380 –> 00:12:40,630
مانند همه کلماتی
310
00:12:40,630 –> 00:12:41,770
که شبیه به خداناباوران هستند
311
00:12:41,770 –> 00:12:43,990
دقیقاً در اینجا نماینده
312
00:12:43,990 –> 00:12:46,510
مشابه کار یا جدا هستند و به
313
00:12:46,510 –> 00:12:49,750
رنگ آبی مرتبط هستند اینجا پارک در این زرد است و
314
00:12:49,750 –> 00:12:52,120
سپس ما در این سبز ناامید هستیم.
315
00:12:52,120 –> 00:12:53,860
و اگر به درون هر
316
00:12:53,860 –> 00:12:56,140
ساختار یا هر خوشه معینی نگاه کنیم،
317
00:12:56,140 –> 00:12:59,199
میتوانیم ابعاد همه این کلمات را ببینیم
318
00:12:59,199 –> 00:13:02,500
و این فقط پنج کلمه هستند که
319
00:13:02,500 –> 00:13:05,290
ابتدا در این خوشه نشان داده میشوند با برچسب یک
320
00:13:05,290 –> 00:13:07,720
ناامید میدانم یک ناراحتی غمگین افسرده
321
00:13:07,720 –> 00:13:08,890
منطقی است که اینها همه
322
00:13:08,890 –> 00:13:10,000
خوشهای هستند. من با هم
323
00:13:10,000 –> 00:13:11,980
فقط پنج مورد از آنها را به شما نشان می دهم
324
00:13:11,980 –> 00:13:16,830
زیرا مورد ششم توهین آمیز است، بنابراین از
325
00:13:16,830 –> 00:13:19,240
چه داده هایی که در واقع برای این کار استفاده می
326
00:13:19,240 –> 00:13:20,680
کنم، به مجموعه ها ارجاع زیادی
327
00:13:20,680 –> 00:13:22,750
داده ام و چند
328
00:13:22,750 –> 00:13:24,760
نمونه از مجموعه خود و برخی
329
00:13:24,760 –> 00:13:25,990
تجسم ها را به شما نشان داده ام. که من در این مورد گردآوری
330
00:13:25,990 –> 00:13:28,950
کردم و اما من فقط از داده های توییتر استفاده
331
00:13:28,950 –> 00:13:31,960
کردم، منطقی است که همه در مورد
332
00:13:31,960 –> 00:13:35,800
اهمیت رسانه های اجتماعی در بازارهای مالی صحبت
333
00:13:35,800 –> 00:13:37,420
کنند، برای سنجش
334
00:13:37,420 –> 00:13:40,570
احساسات عمومی مهم است. افرادی که به نظر میرسد مردم
335
00:13:40,570 –> 00:13:41,980
تمایل دارند خود را در رسانههای اجتماعی ابراز کنند،
336
00:13:41,980 –> 00:13:45,160
بنابراین منطقی است که در اینجا به دنبال
337
00:13:45,160 –> 00:13:48,340
نوعی فرضیه اقتصادی بگردیم و
338
00:13:48,340 –> 00:13:50,590
بهویژه من از مجموعه دادههای احساسات 140 استفاده میکنم
339
00:13:50,590 –> 00:13:52,150
که مجموعه دادههای احساسات توییتری است
340
00:13:52,150 –> 00:13:54,130
که توسط برخی از محققان در
341
00:13:54,130 –> 00:13:56,050
استنفورد ایجاد شده است. آنها
342
00:13:56,050 –> 00:14:00,100
حدود 1.6 میلیون توییت گرفتند و برای
343
00:14:00,100 –> 00:14:01,840
برچسب زدن به آنها به ایموجی نگاه کردند
344
00:14:01,840 –> 00:14:04,480
که در آن توییت ها وجود دارد و از
345
00:14:04,480 –> 00:14:06,940
آن به عنوان یک طبقه بندی پر سر و صدا برای
346
00:14:06,940 –> 00:14:09,660
مثبت یا منفی بودن یک توییت استفاده کردند،
347
00:14:09,660 –> 00:14:12,640
بنابراین اگر تعداد نامتناسبی
348
00:14:12,640 –> 00:14:15,220
صورتک های صورتک داشته باشد، چنین خواهد بود. مثبت است و
349
00:14:15,220 –> 00:14:16,420
اگر تعداد نامتناسبی از
350
00:14:16,420 –> 00:14:19,120
چهرههای ناراضی داشت، یک توییت منفی بود
351
00:14:19,120 –> 00:14:21,339
و این مجموعه دادهای عالی است که
352
00:14:21,339 –> 00:14:22,990
قطعاً ارزش بررسی این را دارد که
353
00:14:22,990 –> 00:14:24,370
آن را آزادانه در وبسایت خود در دسترس قرار دهند،
354
00:14:24,370 –> 00:14:26,170
فقط احساس در طبقه D من فکر میکنم
355
00:14:26,170 –> 00:14:27,760
ممکن است آرام باشد اما ممکن است جای
356
00:14:27,760 –> 00:14:29,440
دیگری باشند و آنها یک API دارند که در آن می توانید
357
00:14:29,440 –> 00:14:31,420
به احساسات آنها دسترسی پیدا کنید. آنها
358
00:14:31,420 –> 00:14:32,920
مقاله ای در مورد آن دارند که واقعاً
359
00:14:32,920 –> 00:14:35,200
عالی است که من در واقع از آن به عنوان یک برنامه استفاده می کنم. معیاری
360
00:14:35,200 –> 00:14:37,810
برای مدلی که من در اینجا میدانم یک مدل خوب است،
361
00:14:37,810 –> 00:14:42,550
بنابراین حتماً آن را بررسی کنید، بنابراین من
362
00:14:42,550 –> 00:14:44,200
دو احساس جداگانه را کنار هم قرار دادم،
363
00:14:44,200 –> 00:14:45,940
اولی یک رگرسیون لجستیک با استفاده
364
00:14:45,940 –> 00:14:48,130
از مدل کیسهای از کلمات است و سپس
365
00:14:48,130 –> 00:14:50,050
دومی یک شبکه عصبی است که اکنون از جاسازی کلمه استفاده میکند.
366
00:14:50,050 –> 00:14:53,110
شما که هستید
367
00:14:53,110 –> 00:14:54,310
من با یک رگرسیون لجستیک آشنا نیستم،
368
00:14:54,310 –> 00:14:57,010
این یک
369
00:14:57,010 –> 00:14:58,930
مدل خطی بسیار معمولی است که برای طبقه بندی استفاده می شود،
370
00:14:58,930 –> 00:15:01,170
کاری که ما انجام می دهیم این است که ما اساساً یک
371
00:15:01,170 –> 00:15:03,339
رگرسیون خطی خطی چندگانه
372
00:15:03,339 –> 00:15:05,290
می گیریم که در آن تعدادی ویژگی
373
00:15:05,290 –> 00:15:08,170
و ویژگی با پارامترهای مرتبط
374
00:15:08,170 –> 00:15:10,450
با آنها داریم و یک مقدار رهگیری و ما
375
00:15:10,450 –> 00:15:12,430
آن را از طریق تابع معانی allegis Allah له می
376
00:15:12,430 –> 00:15:13,930
کنیم و این همان چیزی است که نام
377
00:15:13,930 –> 00:15:16,420
رگرسیون لجستیک را می دهد و این
378
00:15:16,420 –> 00:15:18,459
تابع لجستیک خروجی را مجبور می کند بین
379
00:15:18,459 –> 00:15:21,160
0 و 1 باشد بنابراین آنچه به دست می آوریم یک مقدار احتمال
380
00:15:21,160 –> 00:15:23,830
است که چیزی در کلاس 0 یا 0 است.
381
00:15:23,830 –> 00:15:25,690
در کلاس می توان این را
382
00:15:25,690 –> 00:15:27,760
به چندین کلاس افزایش داد، اما این فقط
383
00:15:27,760 –> 00:15:29,560
قانون اساسی است و من فقط با
384
00:15:29,560 –> 00:15:32,860
مثبت یا منفی سر و کار دارم در حال حاضر خوب است
385
00:15:32,860 –> 00:15:35,590
یک رگرسیون لجستیک و
386
00:15:35,590 –> 00:15:36,790
رگرسیون خطی چندگانه با مدلهای خطی به
387
00:15:36,790 –> 00:15:38,410
طور کلی این است که آنها دوستانه هستند، آنها
388
00:15:38,410 –> 00:15:40,510
آشنا هستند، تفسیر و درک آنها آسان است.
389
00:15:40,510 –> 00:15:42,910
وجود معنی مشخصی
390
00:15:42,910 –> 00:15:45,760
برای این بتاها در این رگرسیون وجود دارد که ما
391
00:15:45,760 –> 00:15:49,210
به راحتی میتوانیم قدرت یک
392
00:15:49,210 –> 00:15:51,100
کلمه را در مقابل استنباط کنیم. دیگری در تعیین
393
00:15:51,100 –> 00:15:53,080
394
00:15:53,080 –> 00:15:56,380
مثبت یا منفی بودن یک سند داده شده یا یک توییت داده شده به
395
00:15:56,380 –> 00:15:57,640
عنوان مثال اینها
396
00:15:57,640 –> 00:15:59,260
ضرایب رگرسیون لجستیک با استفاده از مدل کیف کلمات من هستند
397
00:15:59,260 –> 00:16:01,180
و می بینیم که
398
00:16:01,180 –> 00:16:03,580
مثبت ترین ضرایب آرزوی شانس هستند
399
00:16:03,580 –> 00:16:06,610
ممنون نگران نباشید لبخند بد نیست. و
400
00:16:06,610 –> 00:16:07,870
غیره و غیره و منفی ترین
401
00:16:07,870 –> 00:16:10,990
ضرایب غم انگیز است
402
00:16:10,990 –> 00:16:15,130
متأسفانه mmm و مقدار واقعی این
403
00:16:15,130 –> 00:16:17,800
ضریب بتا هر چه بیشتر
404
00:16:17,800 –> 00:16:20,020
یا منفی تر باشد
405
00:16:20,020 –> 00:16:23,170
تأثیر بیشتری بر خروجی حاصل خواهد داشت بنابراین اگر
406
00:16:23,170 –> 00:16:25,840
غم را در آن قرار دهیم یک توییت
407
00:16:25,840 –> 00:16:27,940
تاثیر بزرگی روی
408
00:16:27,940 –> 00:16:30,490
دسته بندی آن توییت به عنوان مثبت یا
409
00:16:30,490 –> 00:16:32,740
منفی خواهد داشت و در اینجا یک مصنوع جالب این
410
00:16:32,740 –> 00:16:35,920
است که بسیاری از کلمات
411
00:16:35,920 –> 00:16:38,890
مثبت و مثبت ترین کلمات نفی
412
00:16:38,890 –> 00:16:42,430
منفی هستند پس نگران نباش
413
00:16:42,430 –> 00:16:45,490
بد نیست بد نبود هیچ اشتباهی نیست فراموش
414
00:16:45,490 –> 00:16:47,770
نکن صدمه نمی زند و من واقعاً
415
00:16:47,770 –> 00:16:49,000
توضیحی برای آن ندارم فقط فکر می کنم این یک
416
00:16:49,000 –> 00:16:53,080
نکته کوچک جالبی که باید به آن توجه
417
00:16:53,080 –> 00:16:54,430
کرد، نتایج واقعی این است که در
418
00:16:54,430 –> 00:16:57,730
نمونه ما حدود 80 درصد دقت و 78
419
00:16:57,730 –> 00:17:02,380
درصد دقت خارج از نمونه به دست می آوریم، بنابراین
420
00:17:02,380 –> 00:17:04,240
بد نیست که مردم معمولاً
421
00:17:04,240 –> 00:17:06,790
در ارزیابی احساسات یک
422
00:17:06,790 –> 00:17:08,770
قطعه معین خیلی خوب نیستند. متن چه رسد به احساسات
423
00:17:08,770 –> 00:17:09,910
افراد دیگر که واقعاً از
424
00:17:09,910 –> 00:17:12,940
نظر فیزیکی در اطراف هستند، بنابراین دقت 80 درصد یا
425
00:17:12,940 –> 00:17:15,630
در اطراف وجود دارد، البته بسیار خوب است
426
00:17:15,630 –> 00:17:17,680
زیرا من یک
427
00:17:17,680 –> 00:17:20,050
فرد کمی رقابتی هستم و همیشه به
428
00:17:20,050 –> 00:17:22,900
دنبال بهانه ای می گردم تا یک مشکل ساده را
429
00:17:22,900 –> 00:17:24,369
پیچیده تر کنم. در واقع
430
00:17:24,369 –> 00:17:27,430
تصمیم گرفتم در عوض از برخی
431
00:17:27,430 –> 00:17:32,050
شبکه های عصبی استفاده کنم. مقاله استنفورد روی حس 140
432
00:17:32,050 –> 00:17:33,820
در نهایت دقتی در حدود 81 و نیم تا
433
00:17:33,820 –> 00:17:36,430
82 درصد دارد و این
434
00:17:36,430 –> 00:17:37,450
تفاوت دو
435
00:17:37,450 –> 00:17:40,299
سه درصدی در مجموعه تست
436
00:17:40,299 –> 00:17:43,929
من برای من غیرقابل قبول است، بنابراین برگشتم. به
437
00:17:43,929 –> 00:17:46,210
شبکههای عصبی و اگر
438
00:17:46,210 –> 00:17:48,909
با شبکههای عصبی آشنایی ندارید، احتمالاً نام
439
00:17:48,909 –> 00:17:51,730
آنها را شنیدهاید، ایده اصلی این است که ما
440
00:17:51,730 –> 00:17:55,029
در مجموعهای از ورودیها تغذیه میکنیم، آن
441
00:17:55,029 –> 00:17:59,320
ورودیها را در وزنها ضرب میکنیم مجموع وزنها
442
00:17:59,320 –> 00:18:02,289
مجموع آن ضرب را جمع میکنیم و آن را پاس میکنیم.
443
00:18:02,289 –> 00:18:04,210
به لایه بعدی پس از عبور آن
444
00:18:04,210 –> 00:18:06,179
از نوعی تابع غیرخطی
445
00:18:06,179 –> 00:18:09,700
، ایده اینجا این است که ما می توانیم یک
446
00:18:09,700 –> 00:18:12,669
مدل غیرخطی بسیار انعطاف پذیر ایجاد کنیم
447
00:18:12,669 –> 00:18:14,289
که توسط این
448
00:18:14,289 –> 00:18:15,970
تابع فعال سازی بین هر
449
00:18:15,970 –> 00:18:19,539
لایه ایجاد می شود، بنابراین ما خروجی را از زمان قبل می گیریم.
450
00:18:19,539 –> 00:18:21,460
ما مجموعه ای
451
00:18:21,460 –> 00:18:23,200
از وزن ها را داریم که به مجموعه
452
00:18:23,200 –> 00:18:25,899
گره های بعدی نگاشت می شوند و همانطور که این مجموع وزنی را
453
00:18:25,899 –> 00:18:28,779
بین چیزها می گیریم، آن را با استفاده از
454
00:18:28,779 –> 00:18:31,029
یک مماس هذلولی یا یک
455
00:18:31,029 –> 00:18:34,840
واحد خطی اصلاح شده یا بسیاری از یا هر یک از ده ها
456
00:18:34,840 –> 00:18:36,850
تابع فعال سازی مختلف که همه
457
00:18:36,850 –> 00:18:40,450
معرفی می کنند، له می کنیم. این غیر خطی بودن و این
458
00:18:40,450 –> 00:18:42,370
به ما انعطافپذیری زیادی میدهد، چیزی که
459
00:18:42,370 –> 00:18:45,010
اساساً در
460
00:18:45,010 –> 00:18:46,630
محاورهایترین شرایط ممکن حدس میزنم این است که
461
00:18:46,630 –> 00:18:48,399
ضرب ماتریس را انجام میدهیم و سپس آن را له میکنیم.
462
00:18:48,399 –> 00:18:50,350
d سپس ضرب ماتریس را انجام می دهیم و
463
00:18:50,350 –> 00:18:52,419
سپس آن را له می کنیم و غیره و غیره
464
00:18:52,419 –> 00:18:54,010
تا زمانی که احساس کنیم به اندازه کافی این کار را انجام داده
465
00:18:54,010 –> 00:18:56,279
ایم و سپس یک خروجی دریافت می کنیم
466
00:18:56,279 –> 00:19:00,399
تا مشکل این شبکه عصبی وانیلی
467
00:19:00,399 –> 00:19:04,269
به ویژه به
468
00:19:04,269 –> 00:19:06,370
هر نوع مربوط شود. مدلسازی سریهای زمانی یا
469
00:19:06,370 –> 00:19:07,899
هر چیزی که ساختار توالی دارد
470
00:19:07,899 –> 00:19:10,779
این است که من توضیح میدهم یک
471
00:19:10,779 –> 00:19:13,990
مدل بسیار ساده است، این احتمالاً یکی
472
00:19:13,990 –> 00:19:15,340
از سادهترین موارد در کار من است، بنابراین
473
00:19:15,340 –> 00:19:16,389
میتوانید این یک
474
00:19:16,389 –> 00:19:17,860
شبکه عصبی کاملاً متصل یک فید است. -شبکه عصبی فوروارد
475
00:19:17,860 –> 00:19:19,299
اینجا واقعاً
476
00:19:19,299 –> 00:19:21,429
چیز جالبی در جریان نیست، اما اگر بخواهم
477
00:19:21,429 –> 00:19:23,889
از چیزی عبور کنم که ساختاری
478
00:19:23,889 –> 00:19:27,220
به ترتیب ورودیها داشته باشد،
479
00:19:27,220 –> 00:19:29,470
اگر این سه نقطه در زمان را تصور کنیم که به لایه بعدی منتقل میشوند، با مشکل مواجه خواهم شد.
480
00:19:29,470 –> 00:19:33,639
481
00:19:33,639 –> 00:19:36,700
نقاط
482
00:19:36,700 –> 00:19:39,580
آینده به نحوی بر مقادیر عبور تأثیر میگذارند،
483
00:19:39,580 –> 00:19:41,169
ما در اینجا
484
00:19:41,169 –> 00:19:43,899
برخی از تعصبات پیشرو را معرفی میکنیم، بنابراین شبکههای عصبی
485
00:19:43,899 –> 00:19:46,120
بهویژه شبکههای عصبی وانیلی
486
00:19:46,120 –> 00:19:47,710
برای مشاهده این
487
00:19:47,710 –> 00:19:49,600
ساختار فضایی بسیار بهتر هستند. یک
488
00:19:49,600 –> 00:19:50,890
ساختار این توالی،
489
00:19:50,890 –> 00:19:53,170
بنابراین تعدادی تنوع و یک
490
00:19:53,170 –> 00:19:55,450
خانواده کلی از شبکههای عصبی مختلف
491
00:19:55,450 –> 00:19:56,890
به نام شبکههای عصبی مکرر وجود دارد
492
00:19:56,890 –> 00:19:58,660
که کمک میکنند تا کمی با این مشکل برخورد
493
00:19:58,660 –> 00:20:01,299
کنیم و اساساً چیزها را
494
00:20:01,299 –> 00:20:03,670
به داخل منتقل میکنیم و قبل از ارسال آن به لایه بعدی
495
00:20:03,670 –> 00:20:06,760
، مقداری را که وجود داشت ارسال میکنیم. فقط
496
00:20:06,760 –> 00:20:09,250
با یک وزن دوباره به خودش محاسبه میشود،
497
00:20:09,250 –> 00:20:12,970
بنابراین به هر گره
498
00:20:12,970 –> 00:20:15,520
مفهومی از حافظه میدهد که میتواند
499
00:20:15,520 –> 00:20:18,250
چیزی را از دفعه قبل
500
00:20:18,250 –> 00:20:21,130
که چیز دیگری را پاس کردهایم به خاطر بیاورد و این
501
00:20:21,130 –> 00:20:23,950
برای سکانسها و ساختار سریهای زمانی بسیار بهتر است و
502
00:20:23,950 –> 00:20:26,620
من در واقع اینگونه تنظیم کردم
503
00:20:26,620 –> 00:20:30,220
. شبکه عصبی من برای
504
00:20:30,220 –> 00:20:33,360
تجزیه و تحلیل احساسات ما میتوانیم همه جملات را بهعنوان
505
00:20:33,360 –> 00:20:37,090
دنبالهای از کلمات مشاهده کنیم که یک کلمه به دنبال
506
00:20:37,090 –> 00:20:40,120
دیگری میآید که کاملاً منطقی است
507
00:20:40,120 –> 00:20:44,020
ساختار جمله وقتی شما زبان را درست میفهمید از الگوهای داده شده پیروی میکند،
508
00:20:44,020 –> 00:20:46,240
509
00:20:46,240 –> 00:20:47,770
بنابراین دیدن آن به این صورت منطقی است،
510
00:20:47,770 –> 00:20:50,350
همچنین میتوانید جمله فقط به عنوان یک
511
00:20:50,350 –> 00:20:52,390
مجموعه کلی از فضا است، اما این فقط
512
00:20:52,390 –> 00:20:54,549
روش ترجیحی است که من می
513
00:20:54,549 –> 00:20:55,860
خواهم با شما همراه باشم، می توانید کاملاً از آن استفاده کنید مانند
514
00:20:55,860 –> 00:20:58,090
c اگر میخواهید، احتمالاً میتوانید
515
00:20:58,090 –> 00:21:00,100
فقط از یک شبکه عصبی پیشخور وانیلی استفاده کنید،
516
00:21:00,100 –> 00:21:01,750
517
00:21:01,750 –> 00:21:04,390
اما البته من فقط
518
00:21:04,390 –> 00:21:05,559
مسائل را پیچیدهتر میکنم و در واقع
519
00:21:05,559 –> 00:21:06,150
باید این کار را انجام
520
00:21:06,150 –> 00:21:08,500
دهم و بهویژه از چیزی
521
00:21:08,500 –> 00:21:11,049
به نام کوتاهمدت بلندمدت استفاده میکنم. شبکه حافظه
522
00:21:11,049 –> 00:21:14,590
و این حافظه کوتاه مدت بلندمدت
523
00:21:14,590 –> 00:21:17,320
نشان می دهد که ما این
524
00:21:17,320 –> 00:21:20,070
مدت زمان دلخواه را بین زمانی که چیزی
525
00:21:20,070 –> 00:21:22,900
یاد می گیریم و زمانی که بتوان از آن استفاده کرد
526
00:21:22,900 –> 00:21:26,290
، یک حافظه کوتاه مدت طولانی مدت داریم و
527
00:21:26,290 –> 00:21:28,419
این با داشتن دنباله ای از
528
00:21:28,419 –> 00:21:30,610
دروازه ها در هر یک جمع می شود. واحد جداگانه بنابراین ما
529
00:21:30,610 –> 00:21:33,100
مقادیر را وارد می کنیم و سپس گیت ها
530
00:21:33,100 –> 00:21:34,780
نشان می دهند که آیا باید چیزی را به خاطر بسپاریم
531
00:21:34,780 –> 00:21:36,760
یا چیزی را فراموش کنیم یا چگونه یا
532
00:21:36,760 –> 00:21:39,040
و برای چه مدت قبل از اینکه آن را به
533
00:21:39,040 –> 00:21:41,350
لایه بعدی منتقل کنیم و غیره و غیره
534
00:21:41,350 –> 00:21:44,679
و این فاصله برای صبر کردن بین
535
00:21:44,679 –> 00:21:46,929
یادگیری و فراموش کردن چیزها
536
00:21:46,929 –> 00:21:49,330
فقط به عنوان بخشی از فرآیند آموزش
537
00:21:49,330 –> 00:21:54,010
برای یک شبکه عصبی یاد میشود، بنابراین من از Kerris استفاده کردم
538
00:21:54,010 –> 00:21:56,200
که لایهای است که بر روی فولکلور تانسور ساخته شده
539
00:21:56,200 –> 00:21:58,440
است تا LST m/s خود را پیادهسازی
540
00:21:58,440 –> 00:22:03,100
کند. بسیار ساده است برای ایجاد هر نوع
541
00:22:03,100 –> 00:22:04,120
مراقبت از شبکه های عصبی،
542
00:22:04,120 –> 00:22:05,890
من به شدت آن را توصیه می کنم، API
543
00:22:05,890 –> 00:22:08,920
بسیار آشنا است، تقریباً نزدیک به
544
00:22:08,920 –> 00:22:10,720
scikit-learn است، اگر با
545
00:22:10,720 –> 00:22:14,440
دسته کلی پانداهای ناتوان آشنا هستید و Python
546
00:22:14,440 –> 00:22:17,200
من یک لایه ورودی دارم که آن را به آن ارسال کردم. یک
547
00:22:17,200 –> 00:22:19,860
لایه جاسازی که
548
00:22:19,860 –> 00:22:21,940
رابطه بین کلمات را در یک
549
00:22:21,940 –> 00:22:23,740
فضای برداری یاد می گیرد و می توانید آن را با
550
00:22:23,740 –> 00:22:25,540
مجموعه ای از وزن های جاسازی شده از قبل آموزش دهید، اما من این کار را انجام دادم و
551
00:22:25,540 –> 00:22:27,910
یک مدل کلمه به برداری ایجاد کردم و سپس
552
00:22:27,910 –> 00:22:30,280
این لایه جاسازی را از قبل آموزش دادم که
553
00:22:30,280 –> 00:22:32,620
در نهایت به طور کلی سریعتر شد. سپس
554
00:22:32,620 –> 00:22:35,950
میتوانید هر لایه جداگانه را به لایه
555
00:22:35,950 –> 00:22:37,900
بعدی منتقل کنید، بنابراین من یک لایه LCM برای آنها دارم یک
556
00:22:37,900 –> 00:22:39,520
لایه LS cm دیگر با انتخاب
557
00:22:39,520 –> 00:22:43,360
تابع فعالسازی مماس هذلولی با
558
00:22:43,360 –> 00:22:45,070
یک نرخ ریزش معین، تقریباً
559
00:22:45,070 –> 00:22:47,020
10% افت فقط یک
560
00:22:47,020 –> 00:22:49,780
روش منظمسازی است که به ما امکان میدهد خطر
561
00:22:49,780 –> 00:22:51,220
بیش از حد برازش را کاهش می دهیم و در نهایت
562
00:22:51,220 –> 00:22:53,470
همه چیز را از این لایه خروجی متراکم عبور می دهیم
563
00:22:53,470 –> 00:22:55,600
که یک تابع سیگموئید است که
564
00:22:55,600 –> 00:22:58,300
خروجی را مجبور می کند بین 0 و 1 باشد بنابراین
565
00:22:58,300 –> 00:23:00,160
احتمال خود را بدست می آوریم. y ارزش
566
00:23:00,160 –> 00:23:04,720
مثبت یا منفی بودن را دارد، بنابراین
567
00:23:04,720 –> 00:23:06,520
نتایج واقعی برای این در نهایت
568
00:23:06,520 –> 00:23:09,130
دقت حدود 81 و نیم درصد است
569
00:23:09,130 –> 00:23:10,900
و مجموعه اعتبارسنجی که بسیار
570
00:23:10,900 –> 00:23:12,760
خوب است، یعنی همان جایی که احساسات
571
00:23:12,760 –> 00:23:14,940
140 نفر آن را دریافت کردند، بنابراین مزیت رقابتی خوب به
572
00:23:14,940 –> 00:23:19,240
اوج می رسد، این خوب است.
573
00:23:19,240 –> 00:23:22,630
فقط هشت تا نه ساعت طول کشید
574
00:23:22,630 –> 00:23:25,630
تا در مقابل بیست دقیقه برای رگرسیون لجستیکی من اجرا کنم،
575
00:23:25,630 –> 00:23:28,420
بنابراین به شما اجازه میدهم محاسبه
576
00:23:28,420 –> 00:23:31,360
کنید که آیا این همه
577
00:23:31,360 –> 00:23:32,890
تلاش اضافی ارزشش را داشت یا نه
578
00:23:32,890 –> 00:23:36,460
تا سه درصد دقت اضافی را
579
00:23:36,460 –> 00:23:37,330
که من آن را انجام میدهم بدست آوریم.
580
00:23:37,330 –> 00:23:40,030
پس چگونه میخواهیم
581
00:23:40,030 –> 00:23:45,180
از این مدل مرکزی به درستی استفاده کنیم، ما به
582
00:23:45,180 –> 00:23:48,670
متنی نیاز داریم که بتوانیم
583
00:23:48,670 –> 00:23:51,220
مثبت یا منفی بودن آن را ارزیابی کنیم که
584
00:23:51,220 –> 00:23:53,920
فکر میکنیم به نوعی از
585
00:23:53,920 –> 00:23:55,800
دانش اقتصادی تبدیل به نوعی
586
00:23:55,800 –> 00:23:57,580
سیگنال اقتصاد کلان میشود که سپس میتوانیم
587
00:23:57,580 –> 00:23:59,560
برای سهامهای جداگانه استفاده کنیم. بنابراین
588
00:23:59,560 –> 00:24:02,230
تصمیم گرفتم توییتر رئیس
589
00:24:02,230 –> 00:24:04,600
جمهور ایالات متحده دونالد ترامپ را انتخاب کنم که او
590
00:24:04,600 –> 00:24:07,330
زیاد توییت می کند و بسیار منطقی است
591
00:24:07,330 –> 00:24:09,160
که رئیس جمهور قدرتمندترین
592
00:24:09,160 –> 00:24:12,940
اقتصاد در جهان او
593
00:24:12,940 –> 00:24:14,930
در
594
00:24:14,930 –> 00:24:18,740
مورد نحوه عملکرد این اقتصاد جهانی تأثیر میگذارد یا تأثیری بر نحوه عملکرد این اقتصاد جهانی خواهد داشت
595
00:24:18,740 –> 00:24:21,800
که چگونه در طول زمان تغییر میکند،
596
00:24:21,800 –> 00:24:24,890
سوابق زیادی برای این موضوع وجود دارد، اما چگونه میتوانیم
597
00:24:24,890 –> 00:24:26,270
یک سیگنال را درست محاسبه کنیم.
598
00:24:26,270 –> 00:24:29,320
599
00:24:29,320 –> 00:24:32,090
میتواند
600
00:24:32,090 –> 00:24:34,250
در github پیدا کند و منتظر میماند تا رئیسجمهور
601
00:24:34,250 –> 00:24:35,930
شرکتهای سهامی عام را ذکر کند، سپس
602
00:24:35,930 –> 00:24:38,480
آن توییت را
603
00:24:38,480 –> 00:24:40,280
مثبت یا منفی ارزیابی میکند و
604
00:24:40,280 –> 00:24:42,350
بر اساس آن احساسات، موقعیتهای لانگ و شورت را وارد میکند
605
00:24:42,350 –> 00:24:45,650
، همچنین پاداشی در مورد ایالات
606
00:24:45,650 –> 00:24:47,900
متحده در توییتر موجود است که
607
00:24:47,900 –> 00:24:49,280
منتظر رئیسجمهور میماند تا شرکتهای منشن که به صورت عمومی
608
00:24:49,280 –> 00:24:51,830
معامله میشوند از تحلیل احساسات
609
00:24:51,830 –> 00:24:53,000
برای تعیین مثبت یا منفی استفاده میکنند
610
00:24:53,000 –> 00:24:55,670
و سپس
611
00:24:55,670 –> 00:24:57,680
بر اساس احساس
612
00:24:57,680 –> 00:24:59,750
سومی که من پیدا کردم ترامپ و دامپ است
613
00:24:59,750 –> 00:25:02,780
که از طریق این لینک در دسترس است و
614
00:25:02,780 –> 00:25:04,100
منتظر است رئیس جمهور به صورت عمومی اشاره کند، پوزیشنهای خرید یا فروش را وارد میکند.
615
00:25:04,100 –> 00:25:06,410
شرکت های معامله شده از
616
00:25:06,410 –> 00:25:07,820
تجزیه و تحلیل احساسات برای تعیین مثبت یا منفی بودن آنها استفاده می
617
00:25:07,820 –> 00:25:09,740
کنند و سپس فقط سهام
618
00:25:09,740 –> 00:25:12,710
کوتاه را وارد می کنند موضعگیریها بر اساس
619
00:25:12,710 –> 00:25:15,560
منفی بودن احساسات است، بنابراین این
620
00:25:15,560 –> 00:25:17,420
واقعاً تنها نوآوری است که من در
621
00:25:17,420 –> 00:25:19,340
افرادی یافتم که علناً در مورد مدلهایی صحبت
622
00:25:19,340 –> 00:25:21,260
میکنند که به ترامپ وثیقه دادهاند و این
623
00:25:21,260 –> 00:25:25,040
برای من خیلی جالب نیست، فقط به این دلیل که
624
00:25:25,040 –> 00:25:28,100
همه این روشهای فردی با نامهای واحد مبادله میکنند
625
00:25:28,100 –> 00:25:29,960
و زمانی که ما در
626
00:25:29,960 –> 00:25:31,130
تجارت الگوریتمی، ما میخواهیم تا جایی
627
00:25:31,130 –> 00:25:34,670
که ممکن است با نامهای بیشتری معامله کنیم، درست
628
00:25:34,670 –> 00:25:36,710
میخواهیم یک سبد متنوع داشته باشیم،
629
00:25:36,710 –> 00:25:38,180
میخواهیم شرطبندیهای مختلف را
630
00:25:38,180 –> 00:25:40,640
همزمان انجام دهیم، در حالی که این جالب و
631
00:25:40,640 –> 00:25:41,900
شهودی است و بسیار منطقی است
632
00:25:41,900 –> 00:25:43,850
و شاید عملکرد خوب باشد و
633
00:25:43,850 –> 00:25:47,600
در واقع نمیدانم که این برخلاف
634
00:25:47,600 –> 00:25:48,890
بسیاری از حساسیتهای من
635
00:25:48,890 –> 00:25:50,990
636
00:25:50,990 –> 00:25:52,610
637
00:25:52,610 –> 00:25:54,820
638
00:25:54,820 –> 00:25:58,250
639
00:25:58,250 –> 00:26:01,130
است.
640
00:26:01,130 –> 00:26:05,180
مجموعه ای از مدل های تغییر نام تجاری از رگرسیون خطی
641
00:26:05,180 –> 00:26:07,100
و مدل سازی دو عاملی در
642
00:26:07,100 –> 00:26:10,180
فضای مالی به ما امکان می دهد
643
00:26:10,180 –> 00:26:13,400
اهمیت سری های زمانی را در o ارزیابی کنیم.
644
00:26:13,400 –> 00:26:16,310
سریهای زمانی و مالی، بنابراین ما
645
00:26:16,310 –> 00:26:17,810
مدل قیمتگذاری داراییهای سرمایهای را داریم که
646
00:26:17,810 –> 00:26:19,580
بهنوعی اولین مورد از این مدلها بود
647
00:26:19,580 –> 00:26:22,730
که بازده پرتفوی من را میگیرد و
648
00:26:22,730 –> 00:26:25,550
آنها را بر حسب
649
00:26:25,550 –> 00:26:28,250
بازده بازار به طور کلی بیان میکند و مقداری
650
00:26:28,250 –> 00:26:29,000
رهگیری میکند
651
00:26:29,000 –> 00:26:31,220
تا بتوانیم آن را به این شکل تفسیر کنیم. از آنجایی که
652
00:26:31,220 –> 00:26:33,320
بازده پرتفوی من
653
00:26:33,320 –> 00:26:37,010
تا حدودی به دلیل بازار است و سپس چیز
654
00:26:37,010 –> 00:26:41,179
دیگری، و این عبارت بتا در اینجا
655
00:26:41,179 –> 00:26:43,460
تأثیر بازار را بر پرتفوی من کمی نشان میدهد،
656
00:26:43,460 –> 00:26:46,280
این به فونت
657
00:26:46,280 –> 00:26:48,530
فاکتورهای فرانسوی تعمیم مییابد که دو
658
00:26:48,530 –> 00:26:50,539
عامل اضافی را معرفی میکند – بالا و پایین. کوچک
659
00:26:50,539 –> 00:26:53,659
– بزرگ که دفتری بالا هستند – نسبت قیمت
660
00:26:53,659 –> 00:26:56,600
– دفتری کم – نسبت قیمت و
661
00:26:56,600 –> 00:26:59,240
ارزش بازار کوچک – ارزش بازار بزرگ و اینها
662
00:26:59,240 –> 00:27:01,010
جریانهای بازدهی هستند که با هم ترکیب
663
00:27:01,010 –> 00:27:04,190
میشوند تا تأثیر
664
00:27:04,190 –> 00:27:07,700
سهام در حال رشد و سهام بازارهای کوچک را تعیین کنند
665
00:27:07,700 –> 00:27:09,530
و به دست آورند. حق بیمههای ریسک
666
00:27:09,530 –> 00:27:11,480
مرتبط با آنها، بنابراین اکنون میتوانیم
667
00:27:11,480 –> 00:27:12,799
پورتفولیوی خود را بر اساس
668
00:27:12,799 –> 00:27:14,720
این سه رشته بازدهی تجزیه کنیم و
669
00:27:14,720 –> 00:27:16,850
امتیاز پایان هر یک از این
670
00:27:16,850 –> 00:27:19,850
جریانهای بازده رایگان را دریافت کنیم. در پورتفولیوی خود و
671
00:27:19,850 –> 00:27:22,250
سپس چیزی باقی مانده است و سپس
672
00:27:22,250 –> 00:27:24,169
میتوانیم
673
00:27:24,169 –> 00:27:26,240
هر تعداد جریان بازگشتی
674
00:27:26,240 —



![فیلم آموزشی: تایپ پایتون: ژنراتور[T, S, R] (متوسط) آنتونی #297 توضیح میدهد با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/DTegfCNAXoMimage2.jpg)




![فیلم آموزشی: رگرسیون خطی 1 [پایتون] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/q6ksri0LeDEimage2.jpg)


