در این مطلب، ویدئو آموزش ردهبندی چند کلاسه Python KNN با استفاده از مجموعه دادههای Iris با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:05:38
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:00,500 –> 00:00:03,389
به پایتون سریع پنج دقیقه ای من خوش آمدید
2
00:00:03,389 –> 00:00:06,120
آموزش K نزدیکترین همسایگان برای a
3
00:00:06,120 –> 00:00:08,550
طبقه بندی چند طبقه روی عنبیه
4
00:00:08,550 –> 00:00:11,610
مجموعه داده مانند سلول شما با استفاده از عنبیه
5
00:00:11,610 –> 00:00:13,920
مجموعه داده یک مجموعه داده مقدماتی معمولی
6
00:00:13,920 –> 00:00:17,070
این در حال حاضر تمیز و آماده برای ورود است
7
00:00:17,070 –> 00:00:18,779
سعی می کنم این آموزش را خوب ارائه دهم
8
00:00:18,779 –> 00:00:21,060
درک تعداد علم داده
9
00:00:21,060 –> 00:00:23,550
موضوعات مرتبط هستند، بنابراین شما می توانید شروع به حفاری کنید
10
00:00:23,550 –> 00:00:26,460
با استفاده از پایتون برای ذخیره کردن، عمیق تر شوید
11
00:00:26,460 –> 00:00:27,810
زمان من می خواهم فرض کنم که شما
12
00:00:27,810 –> 00:00:30,150
در حال حاضر پایتون نیز دانلود شده است
13
00:00:30,150 –> 00:00:34,620
به عنوان بسته هایی مانند numpy و پانداها به
14
00:00:34,620 –> 00:00:37,200
پس از انجام کار، مجموعه داده عنبیه را بارگیری کنید
15
00:00:37,200 –> 00:00:41,750
پس از آن، کتابخانه های شما بارگیری شد
16
00:00:41,750 –> 00:00:44,670
بارگذاری شده، سپس به نگاهی به
17
00:00:44,670 –> 00:00:48,149
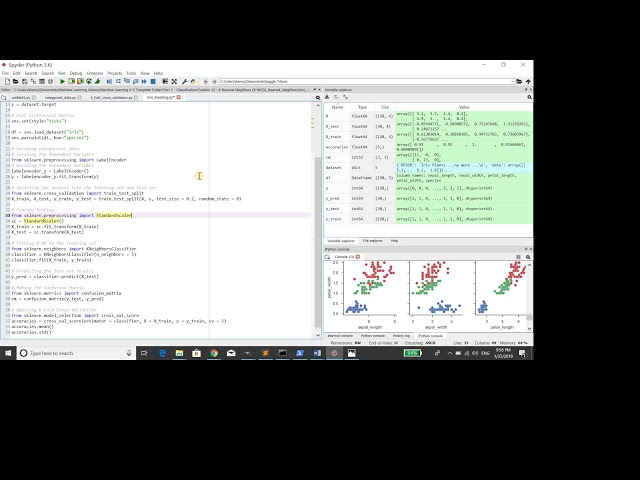
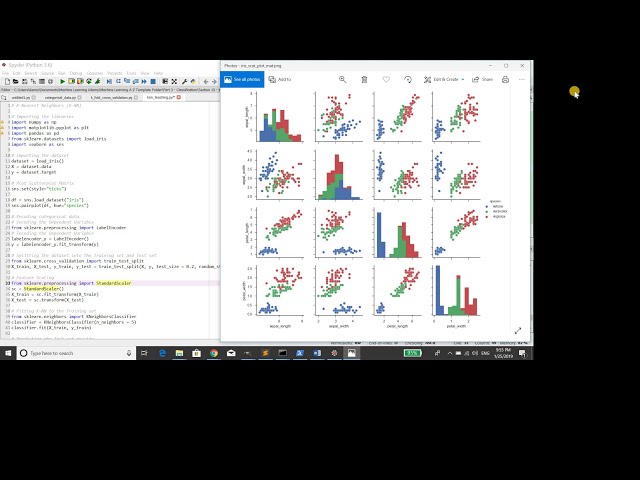
ماتریس نمودار پراکنده، بنابراین اگر به اینجا نگاه کنیم
18
00:00:48,149 –> 00:00:50,280
در ماتریس نمودار پراکندگی می توانیم ببینیم
19
00:00:50,280 –> 00:00:53,640
که بسیاری از متغیرها مانند sepal هستند
20
00:00:53,640 –> 00:00:56,160
طول کاسبرگ عرض طول گلبرگ و غیره هستند
21
00:00:56,160 –> 00:00:59,039
خطی قابل تفکیک که بازی خواهد کرد
22
00:00:59,039 –> 00:01:04,140
به خوبی با kada نزدیکترین همسایگان بنابراین در
23
00:01:04,140 –> 00:01:07,280
مورد طبقه بندی چند طبقه
24
00:01:07,280 –> 00:01:09,420
ما باید از طبقه بندی استفاده کنیم
25
00:01:09,420 –> 00:01:10,920
روش هایی که من می توانم بیش از یک باینری را مدیریت کنم
26
00:01:10,920 –> 00:01:14,189
از این رو ما از کیلومتر تا این حد استفاده می کنیم
27
00:01:14,189 –> 00:01:18,390
این مورد را میخواهیم اندازهگیری کنیم
28
00:01:18,390 –> 00:01:21,060
فاصله نسبی بین عدد K
29
00:01:21,060 –> 00:01:22,920
امتیازات و تطبیق آنهایی که نزدیکتر است
30
00:01:22,920 –> 00:01:25,799
با هم از این رو نام K نزدیکترین
31
00:01:25,799 –> 00:01:28,890
همسایگان در فرآیند انتخاب الف
32
00:01:28,890 –> 00:01:31,409
مدلی مانند KN ابتدا باید a را در نظر بگیرید
33
00:01:31,409 –> 00:01:33,960
چند چیز یک چند مستقل
34
00:01:33,960 –> 00:01:36,240
متغیرهایی نسبت به
35
00:01:36,240 –> 00:01:38,670
اندازه مجموعه داده های شما زیرا این یک است
36
00:01:38,670 –> 00:01:41,220
مجموعه داده های کوچک خوب است که ما فقط
37
00:01:41,220 –> 00:01:43,829
دارای چند پارامتر این نیز است
38
00:01:43,829 –> 00:01:45,540
دلیل اینکه چرا از چیزی استفاده نمی کنیم
39
00:01:45,540 –> 00:01:47,670
مانند یک شبکه عصبی که اغلب
40
00:01:47,670 –> 00:01:51,180
به حجم زیادی از مدل داده نیاز دارد
41
00:01:51,180 –> 00:01:53,939
توپ سبک به شدت آسیب می بیند
42
00:01:53,939 –> 00:01:56,790
لعنت ابعادی من مطمئن هستم که شما
43
00:01:56,790 –> 00:02:00,390
قبلاً در مورد آن شنیده ام به عنوان مثال در
44
00:02:00,390 –> 00:02:01,860
طبقه بندی تصویر می تواند وجود داشته باشد
45
00:02:01,860 –> 00:02:03,899
هزاران پارامتر یا میلیون ها
46
00:02:03,899 –> 00:02:06,540
پارامترها بسته به مجموعه داده a
47
00:02:06,540 –> 00:02:10,229
مدلی مانند کیلومتر عملکرد خوبی ندارد
48
00:02:10,229 –> 00:02:12,930
این نوع از مجموعه داده های ذخیره شده به دلیل آن است
49
00:02:12,930 –> 00:02:14,010
بر اساس
50
00:02:14,010 –> 00:02:15,599
نسبی از جمله فواصل بین
51
00:02:15,599 –> 00:02:19,230
نقطه دوم توپ بسیار خوب کار می کند
52
00:02:19,230 –> 00:02:21,569
هنگامی که یک جدایی خطی قوی وجود دارد
53
00:02:21,569 –> 00:02:23,810
بین عوامل در یک متغیر معین
54
00:02:23,810 –> 00:02:26,430
که در مورد عنبیه انجام داد است
55
00:02:26,430 –> 00:02:29,849
که پس در حال حاضر در حال حرکت در حال حاضر که ما
56
00:02:29,849 –> 00:02:32,959
نگاه کرد که ما می توانیم جلو برویم و
57
00:02:32,959 –> 00:02:39,109
متغیرهای ما را رمزگذاری کنید زیرا ما
58
00:02:39,109 –> 00:02:42,599
متغیر وابسته یک طبقه بندی است
59
00:02:42,599 –> 00:02:44,280
متغیری که باید آن را رمزگذاری کنیم
60
00:02:44,280 –> 00:02:46,769
خوشبختانه چون ما آن را بارگذاری کردیم
61
00:02:46,769 –> 00:02:47,70