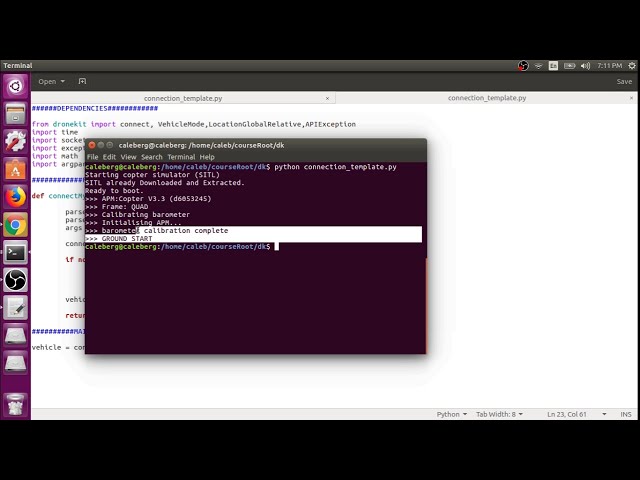
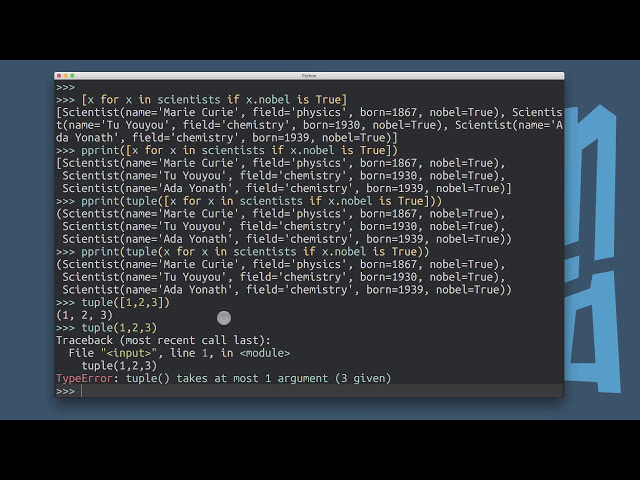
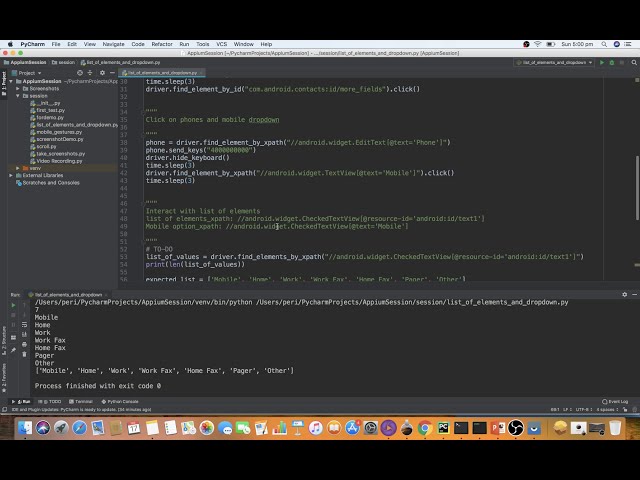
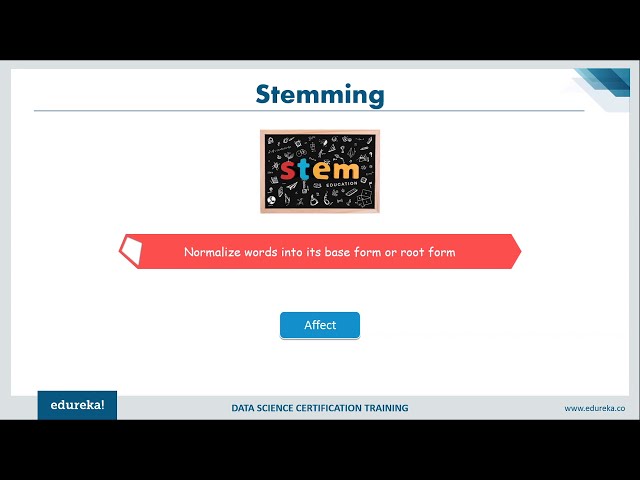
در این مطلب، ویدئو آموزش پردازش زبان طبیعی (NLP) با پایتون و NLTK با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,160 –> 00:00:02,399
به همه به اردوی کد رایگان خوش آمد می گویم. من
2
00:00:02,399 –> 00:00:04,799
کریسلی از طرف edureka
3
00:00:04,799 –> 00:00:06,640
این جلسه را در مورد پردازش زبان طبیعی
4
00:00:06,640 –> 00:00:10,000
که با نام عمومی nlp شناخته می
5
00:00:10,000 –> 00:00:12,559
شود شرکت خواهد کرد.
6
00:00:12,559 –> 00:00:14,960
7
00:00:14,960 –> 00:00:17,119
8
00:00:17,119 –> 00:00:18,720
9
00:00:18,720 –> 00:00:21,119
نگاهی به دستور کار این جلسه،
10
00:00:21,119 –> 00:00:22,720
بنابراین من با توضیح
11
00:00:22,720 –> 00:00:25,439
تکامل زبان انسان شروع
12
00:00:25,439 –> 00:00:27,920
میکنم، سپس متوجه خواهیم شد که nlp چیست و
13
00:00:27,920 –> 00:00:30,160
چگونه به تصویر کشیده شده
14
00:00:30,160 –> 00:00:31,760
است، نگاهی به
15
00:00:31,760 –> 00:00:34,160
کاربردهای مختلف خواهیم داشت. nlp در صنعت و در
16
00:00:34,160 –> 00:00:35,680
مرحله بعد،
17
00:00:35,680 –> 00:00:37,840
اجزای مختلف nlp و مشکلاتی را
18
00:00:37,840 –> 00:00:40,079
که در هنگام اجرای آنها با آن مواجه میشویم، درک
19
00:00:40,079 –> 00:00:41,840
خواهیم کرد و در نهایت این ویدیو را با
20
00:00:41,840 –> 00:00:43,840
توضیح مراحل مختلف
21
00:00:43,840 –> 00:00:45,840
یا مسیرهای درگیر در
22
00:00:45,840 –> 00:00:47,920
پردازش زبان طبیعی به شما به پایان خواهم رساند. نسخه ی نمایشی
23
00:00:47,920 –> 00:00:50,399
برای هر یک از این مراحل، بنابراین
24
00:00:50,399 –> 00:00:52,879
موفقیت نسل بشر به دلیل
25
00:00:52,879 –> 00:00:55,039
توانایی ما در برقراری ارتباط است که به
26
00:00:55,039 –> 00:00:56,800
اشتراک گذاری اطلاعات
27
00:00:56,800 –> 00:00:58,960
با استفاده از این توانایی است. جلوتر
28
00:00:58,960 –> 00:01:00,719
از حیوانات دیگر نقاب زده ایم و به پیچیده ترین موجودات تبدیل شده ایم
29
00:01:00,719 –> 00:01:02,800
30
00:01:02,800 –> 00:01:05,519
و این همان چیزی است که ما را در بین
31
00:01:05,519 –> 00:01:08,000
تمام حیوانات دیگر متمایز می کند، ما شروع به
32
00:01:08,000 –> 00:01:09,920
جستجوی راه هایی برای حفظ افکارمان،
33
00:01:09,920 –> 00:01:12,640
احساسات پیام ها و سایر اطلاعاتی می
34
00:01:12,640 –> 00:01:14,720
کنیم که مانند حیوانات دیگر با ارتباط شفاهی شروع کردیم،
35
00:01:14,720 –> 00:01:16,720
اما به دلیل
36
00:01:16,720 –> 00:01:19,119
ماهیت غیررسمی آن شروع به نقاشی روی
37
00:01:19,119 –> 00:01:21,759
دیوارها و غارهایی کردیم که در آن زندگی میکردیم، اکنون
38
00:01:21,759 –> 00:01:23,680
نیاز به استاندارد کردن نقاشی وجود داشت تا
39
00:01:23,680 –> 00:01:25,600
همه بتوانند آن را درک کنند و اینجاست
40
00:01:25,600 –> 00:01:27,680
که مفهوم توسعه یک
41
00:01:27,680 –> 00:01:29,840
زبان مطرح شد، با این حال بسیاری از چنین
42
00:01:29,840 –> 00:01:32,079
استانداردهایی به وجود آمدند که منجر به ایجاد زبانهای بسیاری
43
00:01:32,079 –> 00:01:34,960
با هر کدام شد. زبانی که
44
00:01:34,960 –> 00:01:37,759
مجموعههای الفبای اصلی خود را دارد ترکیبی
45
00:01:37,759 –> 00:01:40,000
از الفبا که به واژهها معروف بودند
46
00:01:40,000 –> 00:01:41,759
و ترکیب کلماتی که به
47
00:01:41,759 –> 00:01:44,159
صورت معنیداری مرتب شدهاند که تبدیل به
48
00:01:44,159 –> 00:01:47,280
جمله میشود و اکنون هر زبان یک مجموعه
49
00:01:47,280 –> 00:01:50,320
قواعد بر اساس کلمات دارد و با هم ترکیب میشوند
50
00:01:50,320 –> 00:01:52,560
تا این جملات را تشکیل دهند.
51
00:01:52,560 –> 00:01:55,119
قواعد چیزی نیست جز چیزی که ما آن را دستور زبان می نامیم.
52
00:01:55,119 –> 00:01:57,520
اکنون دیگر از آن استفاده نمی کنم
53
00:01:57,520 –> 00:01:59,439
وقت آن است که در مورد گرامر
54
00:01:59,439 –> 00:02:01,439
و همه چیزهایی که اکنون به دنیای امروز می آیند،
55
00:02:01,439 –> 00:02:03,600
طبق تخمین های صنعت توضیح بدهم، تنها
56
00:02:03,600 –> 00:02:05,920
21 درصد از داده های
57
00:02:05,920 –> 00:02:07,920
موجود در فرم ساختار یافته وجود دارد.
58
00:02:07,920 –> 00:02:10,800
59
00:02:10,800 –> 00:02:12,879
60
00:02:12,879 –> 00:02:15,360
و پلتفرم های مختلف دیگر
61
00:02:15,360 –> 00:02:17,920
اکثر این داده ها
62
00:02:17,920 –> 00:02:19,760
به صورت متنی وجود دارند که ماهیت آن بسیار
63
00:02:19,760 –> 00:02:21,760
بدون ساختار است، اکنون برای
64
00:02:21,760 –> 00:02:23,760
ایجاد بینش قابل توجه و عملی
65
00:02:23,760 –> 00:02:26,000
از این داده های متنی،
66
00:02:26,000 –> 00:02:27,520
آشنایی با
67
00:02:27,520 –> 00:02:29,360
تکنیک ها و اصل
68
00:02:29,360 –> 00:02:31,760
پردازش زبان طبیعی مهم است. درک
69
00:02:31,760 –> 00:02:34,000
اینکه nlp اکنون دقیقاً چیست
70
00:02:34,000 –> 00:02:36,319
پردازش زبان طبیعی که
71
00:02:36,319 –> 00:02:38,640
nlp است به
72
00:02:38,640 –> 00:02:40,800
روش هوش مصنوعی ارتباط با
73
00:02:40,800 –> 00:02:42,879
یک سیستم هوشمند با استفاده از زبان طبیعی اشاره
74
00:02:42,879 –> 00:02:45,120
دارد که اکنون بخشی از علوم کامپیوتر
75
00:02:45,120 –> 00:02:47,280
و هوش مصنوعی است
76
00:02:47,280 –> 00:02:49,599
که با
77
00:02:49,599 –> 00:02:52,160
استفاده از nlp و اجزای آن با زبان انسان سروکار دارد. می تواند
78
00:02:52,160 –> 00:02:54,720
تکه های عظیم داده های متنی
79
00:02:54,720 –> 00:02:56,879
را سازماندهی کند انجام وظایف خودکار و
80
00:02:56,879 –> 00:02:59,280
حل طیف گسترده ای از مشکلات مانند
81
00:02:59,280 –> 00:03:01,280
خلاصه سازی خودکار ترجمه ماشینی با
82
00:03:01,280 –> 00:03:03,680
نام شناسایی موجودیت
83
00:03:03,680 –> 00:03:06,400
استخراج رابطه
84
00:03:06,400 –> 00:03:08,800
تجزیه و تحلیل احساساتی تشخیص گفتار و
85
00:03:08,800 –> 00:03:10,159
تقسیم بندی موضوع
86
00:03:10,159 –> 00:03:12,000
اکنون ما در مورد همه اینها بعداً
87
00:03:12,000 –> 00:03:14,720
در این ویدیو یاد خواهیم گرفت اکنون هدف اینجا
88
00:03:14,720 –> 00:03:16,879
پردازش i’ بهتر است بگوییم
89
00:03:16,879 –> 00:03:18,560
برای انجام وظایف مفید زبان طبیعی را درک کنید،
90
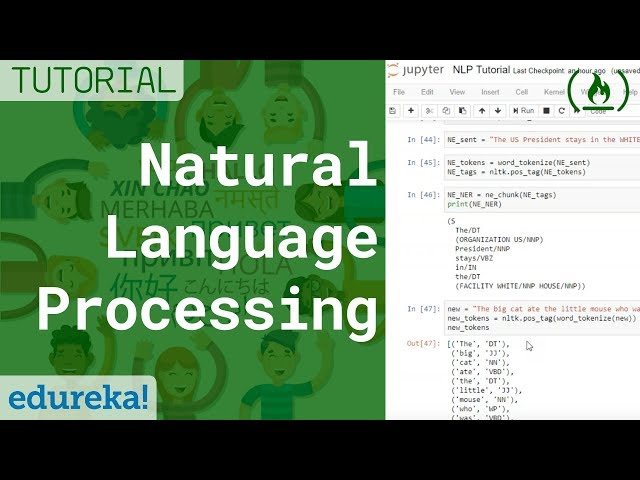
00:03:18,560 –> 00:03:21,120
برخی از این وظایف عبارتند از:
91
00:03:21,120 –> 00:03:23,120
قرار ملاقات، خرید املای چیزها،
92
00:03:23,120 –> 00:03:25,760
ایجاد پاسخها و
93
00:03:25,760 –> 00:03:27,840
نظارت بر رسانههای اجتماعی، اکنون اگر به
94
00:03:27,840 –> 00:03:29,920
کاربردهای مختلف nlp در
95
00:03:29,920 –> 00:03:32,319
صنعت نگاه کنیم، اولاً چک کردن املا را داریم.
96
00:03:32,319 –> 00:03:34,720
معمولاً در اینجا وجود دارد که
97
00:03:34,720 –> 00:03:36,400
می توانید آن را بیشتر به صورت کلمات یا
98
00:03:36,400 –> 00:03:38,720
سند خوان حتی آنلاین پیدا کنید، همچنین می
99
00:03:38,720 –> 00:03:40,560
توانید املای آن را اکنون در مرحله بعدی
100
00:03:40,560 –> 00:03:42,959
جستجوی کلمه کلیدی داریم و همچنین زمینه ای است
101
00:03:42,959 –> 00:03:45,599
که در آن nlp به شدت استفاده می شود و
102
00:03:45,599 –> 00:03:48,319
اطلاعات را از وب سایت ها یا هر
103
00:03:48,319 –> 00:03:50,080
سند خاصی استخراج می کند. همچنین نیاز به
104
00:03:50,080 –> 00:03:52,480
دانش nlp در حال حاضر یکی از جالب ترین
105
00:03:52,480 –> 00:03:54,799
کاربردهای nlp است آدرس در
106
00:03:54,799 –> 00:03:56,319
تطبیق که اساساً یک
107
00:03:56,319 –> 00:03:58,480
توصیه تبلیغاتی است بر اساس جستجوی شما.
108
00:03:58,480 –> 00:04:01,280
آنچه انجام می دهد این است که
109
00:04:01,280 –> 00:04:03,040
متن داده هایی را که قبلاً استفاده می کنید
110
00:04:03,040 –> 00:04:05,599
یا جستجو کرده اید تجزیه و تحلیل می کند و آن را با داده های متنی تبلیغات مطابقت می دهد
111
00:04:05,599 –> 00:04:08,400
در حال حاضر
112
00:04:08,400 –> 00:04:10,799
تجزیه و تحلیل احساسات نیز بخش بسیار
113
00:04:10,799 –> 00:04:13,920
مهمی است. از nlp یکی دیگر از برنامه
114
00:04:13,920 –> 00:04:15,920
های احتراق اسپیکر است، اکنون در اینجا ما در
115
00:04:15,920 –> 00:04:17,918
مورد دستیارهای صوتی
116
00:04:17,918 –> 00:04:20,320
مانند دستیار گوگل سیری، کورتانا نیز صحبت می
117
00:04:20,320 –> 00:04:23,040
کنیم و باید از اپل برای
118
00:04:23,040 –> 00:04:24,639
ایجاد اولین دستیار صوتی
119
00:04:24,639 –> 00:04:26,400
که siri است تشکر کنیم.
120
00:04:26,400 –> 00:04:28,960
از
121
00:04:28,960 –> 00:04:31,280
شما بچه ها ممکن است از
122
00:04:31,280 –> 00:04:33,840
خدمات چت مشتری ارائه شده در برنامه های مختلف استفاده کرده باشید
123
00:04:33,840 –> 00:04:35,840
در حال حاضر اکثر این برنامه ها از چت بات استفاده می کنند
124
00:04:35,840 –> 00:04:38,320
که از nlp برای پردازش داده
125
00:04:38,320 –> 00:04:40,400
هایی که ما وارد کرده ایم استفاده می کند و
126
00:04:40,400 –> 00:04:43,040
سپس بر اساس ورودی که
127
00:04:43,040 –> 00:04:44,560
یک برنامه طبیعی است پاسخ می دهد.
128
00:04:44,560 –> 00:04:46,639
پردازش زبان در حال حاضر یکی دیگر از کاربردهای
129
00:04:46,639 –> 00:04:49,280
nlp ترجمه ماشینی است
130
00:04:49,280 –> 00:04:52,240
که رایج ترین نمونه آن Google
131
00:04:52,240 –> 00:04:54,400
translate است همانطور که می دانید و اکنون از
132
00:04:54,400 –> 00:04:57,040
nlp برای ترجمه داده ها استفاده می کند یا
133
00:04:57,040 –> 00:04:59,600
باید متن را از یک زبان به
134
00:04:59,600 –> 00:05:02,479
زبان دیگر بگویم و این نیز در زمان واقعی اکنون
135
00:05:02,479 –> 00:05:05,520
nlp از دو جزء تشکیل شده
136
00:05:05,520 –> 00:05:06,960
است که درک زبان طبیعی
137
00:05:06,960 –> 00:05:10,000
به نام nlu و
138
00:05:10,000 –> 00:05:11,600
زبان طبیعی است. نسلی که از
139
00:05:11,600 –> 00:05:14,960
آن به عنوان nlg یاد می شود اکنون درک
140
00:05:14,960 –> 00:05:16,960
زبان طبیعی شامل
141
00:05:16,960 –> 00:05:18,800
نگاشت ورودی های ارائه شده به زبان طبیعی
142
00:05:18,800 –> 00:05:21,520
به بازنمایی مفید و
143
00:05:21,520 –> 00:05:23,120
تجزیه و تحلیل جنبه های مختلف
144
00:05:23,120 –> 00:05:25,600
زبان است که اکنون تولید زبان
145
00:05:25,600 –> 00:05:27,520
طبیعی فرآیند تولید
146
00:05:27,520 –> 00:05:30,000
عبارات و جملات معنادار در قالب
147
00:05:30,000 –> 00:05:32,160
زبان طبیعی از برخی از
148
00:05:32,160 –> 00:05:34,639
بازنمایی های داخلی در حال حاضر شامل
149
00:05:34,639 –> 00:05:36,560
برنامه ریزی متن است که شامل بازیابی
150
00:05:36,560 –> 00:05:38,560
مطالب مربوطه از پایگاه دانش
151
00:05:38,560 –> 00:05:41,360
است و شامل برنامه ریزی جملات است که
152
00:05:41,360 –> 00:05:44,160
شامل انتخاب کلمات مورد نیاز از
153
00:05:44,160 –> 00:05:46,240
عبارات معنی دار است که لحن جملات را تنظیم می کند
154
00:05:46,240 –> 00:05:49,199
و در نهایت
155
00:05:49,199 –> 00:05:52,080
متوجه می شویم که در حال نگاشت طرح
156
00:05:52,080 –> 00:05:54,560
جمله در ساختار جمله است. حالا ما
157
00:05:54,560 –> 00:05:57,120
در این مورد بعداً در این مورد یاد خواهیم گرفت درک ویدیویی و
158
00:05:57,120 –> 00:05:59,600
معمولاً زبان طبیعی
159
00:05:59,600 –> 00:06:02,000
که nlu است بسیار سختتر از
160
00:06:02,000 –> 00:06:03,840
انرژی است، اکنون ممکن است فکر کنید که
161
00:06:03,840 –> 00:06:05,919
حتی یک کودک کوچک هم میتواند یک زبان را بفهمد،
162
00:06:05,919 –> 00:06:08,400
پس چرا پردازش آن برای انسانها اینقدر آسان
163
00:06:08,400 –> 00:06:10,479
است که کامپیوتر آنقدر سخت
164
00:06:10,479 –> 00:06:12,560
است.
165
00:06:12,560 –> 00:06:14,479
درک کنید که یک
166
00:06:14,479 –> 00:06:16,479
ماشین در حین درک یک
167
00:06:16,479 –> 00:06:18,960
زبان با چه مشکلاتی مواجه است، بنابراین در درک زبان طبیعی
168
00:06:18,960 –> 00:06:20,160
ابهامات خاصی وجود دارد
169
00:06:20,160 –> 00:06:22,400
که عبارتند از
170
00:06:22,400 –> 00:06:24,560
ابهامات واژگانی ابهام نحوی
171
00:06:24,560 –> 00:06:26,560
و ابهام ارجاعی که اکنون
172
00:06:26,560 –> 00:06:28,240
درک یک زبان جدید با
173
00:06:28,240 –> 00:06:30,240
در نظر گرفتن انگلیسی ما بسیار سخت است.
174
00:06:30,240 –> 00:06:32,160
175
00:06:32,160 –> 00:06:33,840
ابهام و اینکه در
176
00:06:33,840 –> 00:06:35,759
سطوح مختلف اکنون با ابهام واژگانی شروع می شود
177
00:06:35,759 –> 00:06:37,759
ابهام واژگانی
178
00:06:37,759 –> 00:06:39,600
وجود دو یا چند
179
00:06:39,600 –> 00:06:42,400
معنی ممکن در یک کلمه واحد است که به آن ابهام معنایی نیز می
180
00:06:42,400 –> 00:06:44,720
گویند برای مثال
181
00:06:44,720 –> 00:06:46,479
اجازه دهید جملات زیر را در نظر
182
00:06:46,479 –> 00:06:49,440
بگیریم و روی دنیای ایتالیک تمرکز
183
00:06:49,440 –> 00:06:51,919
کنیم. به دنبال یک مسابقه در حال حاضر
184
00:06:51,919 –> 00:06:54,000
شما در اینجا از مادر چه استنباط می کنید tch
185
00:06:54,000 –> 00:06:56,080
world آیا او به دنبال مسابقه ای می گردد
186
00:06:56,080 –> 00:06:58,000
که به صورت رودررو بازی کند یا به
187
00:06:58,000 –> 00:07:00,080
دنبال مسابقه ای می گردد که در شریکی که
188
00:07:00,080 –> 00:07:03,280
ماهیگیر به بانکی رفته است، بانکی است که ما پول خود را از آنجا
189
00:07:03,280 –> 00:07:06,240
برداشت می کنیم یا بانکی است
190
00:07:06,240 –> 00:07:08,960
که در آن پارو می زند. قایق خود یا
191
00:07:08,960 –> 00:07:12,240
ماهی ها را می گیرد حالا ابهام نحوی در
192
00:07:12,240 –> 00:07:14,160
دستور زبان انگلیسی این ابهام
193
00:07:14,160 –> 00:07:16,240
وجود دو یا چند
194
00:07:16,240 –> 00:07:18,720
معنی ممکن در یک جمله یا
195
00:07:18,720 –> 00:07:20,880
دنباله ای از کلمات است که به
196
00:07:20,880 –> 00:07:22,960
آن ابهام ساختار یا ابهام گرامری
197
00:07:22,960 –> 00:07:25,120
نیز می گویند حالا بیایید نگاهی به این جملات بیندازیم.
198
00:07:25,120 –> 00:07:28,160
مرغ آماده خوردن است،
199
00:07:28,160 –> 00:07:30,639
پس آیا مرغ برای خوردن چیزی آماده است
200
00:07:30,639 –> 00:07:32,800
یا مرغ برای خوردن ما آماده است، بنابراین
201
00:07:32,800 –> 00:07:35,280
این یک نوع ابهام نحوی است
202
00:07:35,280 –> 00:07:38,800
که اغلب برای یک
203
00:07:38,800 –> 00:07:41,520
فرد جدید یا بهتر است بگویم رایانه بسیار سخت است.
204
00:07:41,520 –> 00:07:43,280
زیرا به این معنی است که معنای
205
00:07:43,280 –> 00:07:45,039
جمله برای
206
00:07:45,039 –> 00:07:48,000
لحن های مختلف یا در جنبه های مختلف متفاوت است، به
207
00:07:48,000 –> 00:07:50,639
عنوان مثال اگر به آخرین جمله نگاه
208
00:07:50,639 –> 00:07:53,360
کنم مرد را با دوربین دوچشمی دیدم
209
00:07:53,360 –> 00:07:55,919
پس آیا من یک قاتل بنر دارم یا
210
00:07:55,919 –> 00:07:57,360
مرد سطل زباله دارد.
211
00:07:57,360 –> 00:07:59,599
ممکن است
212
00:07:59,599 –> 00:08:01,360
فکر کنید که اوه من مرد دوربین دوچشمی را دیدم به این
213
00:08:01,360 –> 00:08:02,800
214
00:08:02,800 –> 00:08:04,639
معنی است که من لباس بنر را دارم اما در
215
00:08:04,639 –> 00:08:07,280
جایی ممکن است برخی فکر کنند
216
00:08:07,280 –> 00:08:09,280
که مردی که من می بینم به
217
00:08:09,280 –> 00:08:11,280
جای من دوربین دوچشمی دارد، بنابراین این یک
218
00:08:11,280 –> 00:08:13,440
ابهام نحوی است. آمدن به
219
00:08:13,440 –> 00:08:15,199
ابهام سوم که ابهام ارجاعی است،
220
00:08:15,199 –> 00:08:17,919
حالا این ابهام زمانی به وجود می آید که
221
00:08:17,919 –> 00:08:20,879
ما به چیزی با استفاده از ضمایر اشاره می کنیم،
222
00:08:20,879 –> 00:08:24,240
حالا پسر دزدی را به پدرش گفته بود،
223
00:08:24,240 –> 00:08:27,520
خیلی ناراحت بود حالا وقتی در مورد آن صحبت می کنیم
224
00:08:27,520 –> 00:08:29,199
خیلی ناراحت بود اگر روی
225
00:08:29,199 –> 00:08:32,000
کلمه مورب او تمرکز کنید. آیا این بدان معنی است
226
00:08:32,000 –> 00:08:33,760
که پسر ناراحت بود
227
00:08:33,760 –> 00:08:36,719
یا دزد ناراحت بود یا پدر
228
00:08:36,719 –> 00:08:39,440
ناراحت بود هیچ کس نمی داند این ابهام مرجع است
229
00:08:39,440 –> 00:08:40,479
230
00:08:40,479 –> 00:08:42,399
اکنون
231
00:08:42,399 –> 00:08:45,760
برای استفاده از nlp در سیستم خود یا انجام
232
00:08:45,760 –> 00:08:47,839
هر پردازش زبان طبیعی که
233
00:08:47,839 –> 00:08:50,720
برای نصب کتابخانه nltk نیاز داریم به nlp برمی گردیم.
234
00:08:50,720 –> 00:08:53,600
جعبه ابزار زبان طبیعی بنابراین nltk یک
235
00:08:53,600 –> 00:08:55,839
پلت فرم پیشرو برای ساخت
236
00:08:55,839 –> 00:08:58,240
برنامه های پایتون برای کار با داده های زبان انسانی است و
237
00:08:58,240 –> 00:09:00,880
رابط های کاربری آسان را برای 50 شرکت فراهم می کند.
238
00:09:00,880 –> 00:09:03,760
ra و منابع واژگانی
239
00:09:03,760 –> 00:09:06,160
مانند wordnet به همراه مجموعه کتابخانههای پردازش متن برای طبقهبندی نشانهگذاری برچسبهای ریشهای
240
00:09:06,160 –> 00:09:08,480
241
00:09:08,480 –> 00:09:11,200
و خیلی چیزهای
242
00:09:11,200 –> 00:09:12,080
دیگر،
243
00:09:12,080 –> 00:09:14,640
اجازه دهید به شما نشان دهم چگونه میتوانید اکنون
244
00:09:14,640 –> 00:09:16,160
یک ltk
245
00:09:16,160 –> 00:09:18,959
دانلود کنید تا nltk را دانلود کنید، فقط به
246
00:09:18,959 –> 00:09:21,120
پوسته پایتون خود بروید و فقط آن را تایپ کنید.
247
00:09:21,120 –> 00:09:24,480
کلمه nltk dot را با استفاده از پرانتز دانلود کنید
248
00:09:24,480 –> 00:09:26,959
و سپس این
249
00:09:26,959 –> 00:09:29,440
نوع پنجره پاپ آپ را دریافت خواهید کرد که همان nltk
250
00:09:29,440 –> 00:09:31,839
downloader است فقط کافی است گزینه all را
251
00:09:31,839 –> 00:09:33,920
انتخاب کنید و روی دکمه دانلود کلیک کنید
252
00:09:33,920 –> 00:09:36,240
و تمام corpora و
253
00:09:36,240 –> 00:09:37,040
254
00:09:37,040 –> 00:09:39,839
متنی که دارد دانلود می شود. تمام بستههایی که دارد در
255
00:09:39,839 –> 00:09:41,600
یک مکان واحد است و میتوانید دایرکتوری را انتخاب کنید
256
00:09:41,600 –> 00:09:43,920
که میخواهید آن را نصب کنید
257
00:09:43,920 –> 00:09:45,600
، بهتر است اگر آن را در دایرکتوری پایتون خود دانلود کنید،
258
00:09:45,600 –> 00:09:47,760
259
00:09:47,760 –> 00:09:50,399
دسترسی به همه فایلها و
260
00:09:50,399 –> 00:09:53,040
تمام متنهایی که دارد برای شما آسانتر میشود. برای ارائه اکنون وقتی
261
00:09:53,040 –> 00:09:54,720
متن را پردازش می کنیم، چند
262
00:09:54,720 –> 00:09:56,080
اصطلاح وجود دارد که باید آنها را
263
00:09:56,080 –> 00:09:57,120
درک کنیم،
264
00:09:57,120 –> 00:09:58,959
بنابراین اولین اصطلاحی که در اینجا در مورد آن صحبت می کنیم، نشانه گذاری
265
00:09:58,959 –> 00:10:01,360
است، بنابراین این یک
266
00:10:01,360 –> 00:10:03,120
فرآیند تجزیه و تحلیل است. تبدیل به
267
00:10:03,120 –> 00:10:05,040
نشانه هایی می شود که به نوبه خود
268
00:10:05,040 –> 00:10:07,760
ساختارها یا واحدهای کوچکی هستند که می توانند برای نشانه گذاری استفاده شوند،
269
00:10:07,760 –> 00:10:10,320
اکنون شامل سه مرحله
270
00:10:10,320 –> 00:10:12,800
شکستن یک جمله پیچیده به کلمات
271
00:10:12,800 –> 00:10:14,560
است که اهمیت هر یک
272
00:10:14,560 –> 00:10:16,399
از کلمات را با توجه به جمله درک می
273
00:10:16,399 –> 00:10:18,880
کند و یک توصیف ساختاری در
274
00:10:18,880 –> 00:10:21,200
یک جمله ورودی ایجاد می کند. بنابراین اگر این
275
00:10:21,200 –> 00:10:22,800
جمله را امروز بگیریم، توکنیزاسیون را درک خواهیم کرد،
276
00:10:22,800 –> 00:10:25,760
بنابراین همانطور که می بینید ما
277
00:10:25,760 –> 00:10:29,440
پنج نشانه داریم، اولین مورد امروز ما توکن سازی را درک خواهیم کرد،
278
00:10:29,440 –> 00:10:31,920
بنابراین همه این
279
00:10:31,920 –> 00:10:34,800
کلمات در اصطلاح کامپیوتری به عنوان نشانه شناخته می شوند
280
00:10:34,800 –> 00:10:37,040
و این همان چیزی است که به
281
00:10:37,040 –> 00:10:39,440
عنوان نشانه گذاری شناخته می شود. اجازه دهید به شما دوستان نشان دهم
282
00:10:39,440 –> 00:10:42,160
که چگونه می توانید توکن سازی را با استفاده از کتابخانه nltk پیاده سازی
283
00:10:42,160 –> 00:10:45,519
284
00:10:45,519 –> 00:10:49,040
کنید، بنابراین در اینجا من از نوت بوک jupiter استفاده می کنم،
285
00:10:49,040 –> 00:10:51,920
شما می توانید از هر نوع شناسه استفاده کنید، همچنین
286
00:10:51,920 –> 00:10:53,760
ترجیح شخصی من نوت بوک jupiter است،
287
00:10:53,760 –> 00:10:55,920
بنابراین اول از همه اجازه دهید
288
00:10:55,920 –> 00:10:58,720
سیستم عامل را به کتابخانه nltk وارد کنیم. ما
289
00:10:58,720 –> 00:11:02,000
دانلود و مجموعه بلیط nl را داریم
290
00:11:02,000 –> 00:11:04,560
اکنون بیایید نگاهی به
291
00:11:04,560 –> 00:11:07,120
مجموعه هایی که توسط nltk ارائه می شود بیندازیم
292
00:11:07,120 –> 00:11:09,040
که کل داده ها است.
293
00:11:09,040 –> 00:11:12,000
n ببینید ما فایلهای زیادی داریم
294
00:11:12,000 –> 00:11:13,680
و همه این فایلها
295
00:11:13,680 –> 00:11:15,760
عملکردهای متفاوتی دارند، برخی دادههای متنی دارند،
296
00:11:15,760 –> 00:11:18,079
برخی عملکردهای مختلفی
297
00:11:18,079 –> 00:11:19,760
با آن مرتبط هستند، ما کرونومتر داریم، همانطور که میتوانید
298
00:11:19,760 –> 00:11:22,640
در اینجا ببینید نام اتحادیه ایالت شما،
299
00:11:22,640 –> 00:11:24,959
دادههای نمونه توییتر داریم،
300
00:11:24,959 –> 00:11:26,240
انواع مختلف دادهها داریم و انواع مختلف
301
00:11:26,240 –> 00:11:29,680
توابع در اینجا وجود دارد، بنابراین بیایید رنگ قهوه ای
302
00:11:29,680 –> 00:11:31,680
را در نظر بگیریم، همانطور که می بینید در اینجا
303
00:11:31,680 –> 00:11:34,240
زیپ قهوه ای و قهوه ای داریم، بنابراین ابتدا
304
00:11:34,240 –> 00:11:37,120
تنها کاری که باید انجام دهیم این است که قهوه ای را وارد کنیم
305
00:11:37,120 –> 00:11:38,720
و سپس اجازه دهید نگاهی به کلمات
306
00:11:38,720 –> 00:11:40,640
موجود در قهوه ای بیندازیم. شما می توانید
307
00:11:40,640 –> 00:11:43,519
ببینید که ما اعطای کشور فلوتون را به شما
308
00:11:43,519 –> 00:11:46,079
بازنشانی می کنیم و این کار ادامه دارد و
309
00:11:46,079 –> 00:11:48,079
اکنون بیایید نگاهی به فیلدهای مختلف
310
00:11:48,079 –> 00:11:50,240
کوئیدنبرگ بیندازیم تا همانطور که می توانید در فایل گوتنبرگ ببینید،
311
00:11:50,240 –> 00:11:53,120
ما متن آقای آستین
312
00:11:53,120 –> 00:11:55,279
داریم، متن کتاب مقدس را داریم،
313
00:11:55,279 –> 00:11:58,560
اشعار بلیک را داریم. متن کارول آلیس
314
00:11:58,560 –> 00:12:01,120
ما
315
00:12:01,120 –> 00:12:03,120
316
00:12:03,120 –> 00:12:05,760
317
00:12:05,760 –> 00:12:09,040
دارای edgeworth والدین هستیم.
318
00:12:09,040 –> 00:12:10,880
319
00:12:10,880 –> 00:12:12,639
برای دانلود این کتابخانه به چند دقیقه زمان نیاز دارید،
320
00:12:12,639 –> 00:12:14,160
321
00:12:14,160 –> 00:12:18,240
بنابراین بیایید shakespeare hamlet.txt را انتخاب کنیم
322
00:12:18,240 –> 00:12:20,480
و اگر به کلمات
323
00:12:20,480 –> 00:12:23,279
داخل این فایل هملت نگاه کنید، می بینیم که
324
00:12:23,279 –> 00:12:26,399
با تراژدی هملت شروع می شود و
325
00:12:26,399 –> 00:12:28,720
ادامه می یابد و اگر داشته باشیم ادامه می یابد. نگاهی
326
00:12:28,720 –> 00:12:32,079
به 500 کلمه اول این
327
00:12:32,079 –> 00:12:34,560
پاراگراف متنی یا آنچه ما می گوییم فایل متنی،
328
00:12:34,560 –> 00:12:35,360
329
00:12:35,360 –> 00:12:38,399
بنابراین من از اینجا برای کلمه در هملت
330
00:12:38,399 –> 00:12:41,120
استفاده می کنم و از دو نقطه و 500 که
331
00:12:41,120 –> 00:12:42,959
نقطه پایانی است استفاده می کنم، بنابراین همانطور که می بینید شروع می
332
00:12:42,959 –> 00:12:44,880
شود تراژدی هملت اثر ویلیام
333
00:12:44,880 –> 00:12:48,639
شکسپیر بازیگر 1599 premise scona
334
00:12:48,639 –> 00:12:51,200
prima و ادامه می یابد و
335
00:12:51,200 –> 00:12:53,040
بنابراین برای پردازش زبان طبیعی می
336
00:12:53,040 –> 00:12:54,560
توانید از هر یک از متن هایی که در
337
00:12:54,560 –> 00:12:56,800
اینجا برای درک مطلب ارائه شده است استفاده کنید یا می
338
00:12:56,800 –> 00:12:58,959
توانید کلمات خود را ایجاد کنید ،
339
00:12:58,959 –> 00:13:01,760
به عنوان مثال در اینجا من تعریف کردم یک
340
00:13:01,760 –> 00:13:03,519
پاراگراف مبتنی بر
341
00:13:03,519 –> 00:13:06,079
هوش مصنوعی خوب است، بنابراین ادامه مییابد،
342
00:13:06,079 –> 00:13:07,680
مانند پدر
343
00:13:07,680 –> 00:13:09,519
هوش مصنوعی جان مککارتی، هنوز
344
00:13:09,519 –> 00:13:11,760
علم مهندسی است و غیره و
345
00:13:11,760 –> 00:13:14,720
غیره، بنابراین اجازه دهید ابتدا این رشته را تعریف کنیم خب
346
00:13:14,720 –> 00:13:16,720
حالا چرا من میگیرم یک رشته به این
347
00:13:16,720 –> 00:13:18,959
دلیل است که نشان دادن
348
00:13:18,959 –> 00:13:21,279
نحوه کار بر روی یک رشته آسان است، بنابراین اگر نوع ai را انجام دهیم،
349
00:13:21,279 –> 00:13:24,320
می توانید ببینید که با یک رشته str است،
350
00:13:24,320 –> 00:13:27,920
اکنون در زیر nltk، ما nltk.tokenize
351
00:13:27,920 –> 00:13:30,320
را داریم و می خواهیم کلمه را وارد کنیم.
352
00:13:30,320 –> 00:13:32,880
tokenize right زیرا تابع میداند
353
00:13:32,880 –> 00:13:34,800
که اکنون چگونه کار میکند،
354
00:13:34,800 –> 00:13:36,480
ما کلمه underscore
355
00:13:36,480 –> 00:13:37,920
tokenize function
356
00:13:37,920 –> 00:13:41,279
را روی پاراگراف اجرا میکنیم و به آن یک نام اختصاص میدهیم،
357
00:13:41,279 –> 00:13:44,079
بیایید آن را بهعنوان نشانههای underscore اختصاص دهیم،
358
00:13:44,079 –> 00:13:45,760
بنابراین اکنون اگر نگاهی به
359
00:13:45,760 –> 00:13:48,320
نشانههای زیرخط بیندازیم، میتوانید ببینید
360
00:13:48,320 –> 00:13:50,800
کل پاراگراف ai را که
361
00:13:50,800 –> 00:13:53,519
به نشانهها دادیم تقسیم کرده است، بنابراین همانطور که میبینید
362
00:13:53,519 –> 00:13:54,959
363
00:13:54,959 –> 00:13:58,000
، خط فاصله را نیز با کاما در نظر گرفته است و
364
00:13:58,000 –> 00:13:59,440
ادامه مییابد و
365
00:13:59,440 –> 00:14:00,880
حالا اجازه دهید به تعداد
366
00:14:00,880 –> 00:14:03,199
نشانههایی که در اینجا داریم نگاهی بیندازیم.
367
00:14:03,199 –> 00:14:04,800
بنابراین برای این کار از
368
00:14:04,800 –> 00:14:06,240
تابع طول استفاده می کنیم، بنابراین همانطور که می
369
00:14:06,240 –> 00:14:08,720
بینید، اکنون 273 توکن
370
00:14:08,720 –> 00:14:11,279
از یک ltk داریم، یک تابع احتمال داریم
371
00:14:11,279 –> 00:14:13,920
که فرکانس آن متمایز است،
372
00:14:13,920 –> 00:14:14,639
بنابراین
373
00:14:14,639 –> 00:14:16,959
من به شما نشان خواهم داد
374
00:14:16,959 –> 00:14:20,000
که برای یک کلمه در زیر خط ea چه کاری انجام می دهد.
375
00:14:20,000 –> 00:14:23,040
توکنهای f را تست میکنیم و میخواهیم تبدیل کنیم آن را روی
376
00:14:23,040 –> 00:14:24,560
کلیدهای پایین تر قرار دهید تا از
377
00:14:24,560 –> 00:14:26,480
احتمال متفاوت در نظر گرفتن یک کلمه با
378
00:14:26,480 –> 00:14:28,959
حروف بزرگ و کوچک جلوگیری کنیم و
379
00:14:28,959 –> 00:14:31,279
سپس به آن یک عدد اختصاص می دهیم که
380
00:14:31,279 –> 00:14:33,600
اساساً یک برنامه شمارش کلمات است
381
00:14:33,600 –> 00:14:35,120
و با استفاده از
382
00:14:35,120 –> 00:14:36,959
تابع متمایز فرکانس اجرا می شود.
383
00:14:36,959 –> 00:14:39,519
در حال حاضر در کتابخانه nltq وجود دارد، بنابراین
384
00:14:39,519 –> 00:14:42,079
بیایید ببینیم خروجی این یکی چیست،
385
00:14:42,079 –> 00:14:44,480
بنابراین همانطور که می بینید کاما
386
00:14:44,480 –> 00:14:47,760
30 بار نقطه ظاهر شده است 9 بار
387
00:14:47,760 –> 00:14:50,560
علامت سوال 1 و غیره و به همین ترتیب مانند
388
00:14:50,560 –> 00:14:52,160
می بینید که هوش 6
389
00:14:52,160 –> 00:14:54,000
بار هوشمند ظاهر شده است ششم زمان به طور
390
00:14:54,000 –> 00:14:56,880
هوشمند یک بار ظاهر شده است،
391
00:14:56,880 –> 00:14:59,040
فرض کنید اگر می خواهید
392
00:14:59,040 –> 00:15:01,839
بسامد یک کلمه خاص را در اینجا بدانید،
393
00:15:01,839 –> 00:15:03,680
بنابراین ما می خواهیم از
394
00:15:03,680 –> 00:15:05,279
تست تابع f استفاده
395
00:15:05,279 –> 00:15:07,440
کنیم که فرکانس متمایز است، بنابراین
396
00:15:07,440 –> 00:15:09,279
از آن تابع روی کلمه خاص استفاده می کنیم.
397
00:15:09,279 –> 00:15:11,440
به عنوان مثال فرض کنید
398
00:15:11,440 –> 00:15:13,440
می خواهم فرکانس مصنوعی را بدانم
399
00:15:13,440 –> 00:15:14,720
400
00:15:14,720 –> 00:15:16,880
بنابراین همانطور که می بینید سه برابر است
401
00:15:16,880 –> 00:15:19,680
و اگر آن را در پایگاه داده بررسی کنیم
402
00:15:19,680 –> 00:15:21,600
می توانید مصنوعی بودن آن را ببینید به صورت زیر داده می شود.
403
00:15:21,600 –> 00:15:22,480
404
00:15:22,480 –> 00:15:24,800
حالا اگر میخواهید تعداد کلمات متمایز را داشته باشید و به
405
00:15:24,800 –> 00:15:27,120
تعداد کلمات متمایز در اینجا نگاه کنید، تنها کاری که
406
00:15:27,120 –> 00:15:28,320
باید انجام دهیم این است
407
00:15:28,320 –> 00:15:30,480
که تابع تست f را به
408
00:15:30,480 –> 00:15:33,519
تابع طول منتقل کنیم، بنابراین میتوانید ببینید که 121 است.
409
00:15:33,519 –> 00:15:37,360
بنابراین قبلاً ما 273 توکن داشتیم و اکنون
410
00:15:37,360 –> 00:15:40,880
از آن تعداد ما 121 نشانه متمایز داریم
411
00:15:40,880 –> 00:15:43,040
حالا فرض کنید اگر قرار بود
412
00:15:43,040 –> 00:15:45,920
10 توکن برتر را با بالاترین فرکانس انتخاب
413
00:15:45,920 –> 00:15:48,160
کنیم، من یک علامت جدید به این
414
00:15:48,160 –> 00:15:50,720
زیرخط بالای 10 اختصاص میدهم و از
415
00:15:50,720 –> 00:15:53,519
بیشترین تابع رایج زیرخط در اینجا استفاده میکنم و
416
00:15:53,519 –> 00:15:56,240
از 10 عبور میکنم که تعداد مواردی را که
417
00:15:56,240 –> 00:15:57,120
می خواهم
418
00:15:57,120 –> 00:15:57,920
پس
419
00:15:57,920 –> 00:16:00,800
بیایید خروجی را ببینیم
420
00:16:00,800 –> 00:16:02,959
تا همانطور که قبلاً ذکر کردم کاما 30 بار ظاهر می شود
421
00:16:02,959 –> 00:16:04,880
که بالاترین فرکانس
422
00:16:04,880 –> 00:16:06,800
هر دنیا است
423
00:16:06,800 –> 00:16:09,360
و پنج بار آرام می شود، بنابراین این
424
00:16:09,360 –> 00:16:10,800
10 کلمه برتر هستند که بیشترین
425
00:16:10,800 –> 00:16:13,040
تکرار را در داده شده دارند. پاراگراف
426
00:16:13,040 –> 00:16:15,759
یا جمله داده شده
427
00:16:15,759 –> 00:16:18,079
اکنون بیایید از توکنایزر خط خالی
428
00:16:18,079 –> 00:16:19,839
روی همان رشته استفاده کنیم تا یک
429
00:16:19,839 –> 00:16:22,639
پاراگراف را با توجه به یک رشته
430
00:16:22,639 –> 00:16:24,240
431
00:16:24,240 –> 00:16:27,120
خالی نشانه گذاری کنیم، بنابراین همانطور که می بینید ما در حال وارد کردن خط خالی زیر خط نشان
432
00:16:27,120 –> 00:16:29,519
می کنیم. یا کلمه
433
00:16:29,519 –> 00:16:32,000
underscore tokenize و اکنون از
434
00:16:32,000 –> 00:16:34,000
خط خالی در زیر نویز stroke استفاده می کنیم و
435
00:16:34,000 –> 00:16:36,000
دوباره همان
436
00:16:36,000 –> 00:16:37,920
پاراگراف ai را که قبلا داده بودم عبور می دهیم و سپس
437
00:16:37,920 –> 00:16:39,759
طول ai
438
00:16:39,759 –> 00:16:42,320
و scope خالی را بررسی می کنیم تا همانطور که می بینید
439
00:16:42,320 –> 00:16:45,279
ارائه می کند. خروجی 9 ما اکنون آنچه
440
00:16:45,279 –> 00:16:46,959
به ما می گوید
441
00:16:46,959 –> 00:16:48,800
تعداد پاراگراف هایی است که
442
00:16:48,800 –> 00:16:51,759
با یک خط جدید در سند داده شده ما از هم جدا شده اند،
443
00:16:51,759 –> 00:16:53,920
بنابراین فرض کنید می خواهید
444
00:16:53,920 –> 00:16:57,199
به پاراگراف اول یا فرضاً
445
00:16:57,199 –> 00:16:59,440
پاراگراف دوم نگاهی بیندازید تنها کاری که باید انجام دهید این است که آن را
446
00:16:59,440 –> 00:17:01,839
ارسال کنید. عدد و
447
00:17:01,839 –> 00:17:04,400
کل پاراگراف را همانطور که می خواهید به شما می دهد که
448
00:17:04,400 –> 00:17:07,039
با یک خط جدید از هم جدا می شود البته
449
00:17:07,039 –> 00:17:10,000
اکنون به قسمت توکن سازی ما برمی گردیم.
450
00:17:10,000 –> 00:17:13,839
451
00:17:13,839 –> 00:17:15,760
452
00:17:15,760 –> 00:17:17,679
453
00:17:17,679 –> 00:17:19,760
454
00:17:19,760 –> 00:17:21,439
از سه کلمه نوشتاری متوالی
455
00:17:21,439 –> 00:17:23,679
و معمولاً n گرم به
456
00:17:23,679 –> 00:17:25,359
عنوان نشانه هایی از هر تعداد
457
00:17:25,359 –> 00:17:27,839
کلمه نوشتاری متوالی برای n عدد نامیده می شود،
458
00:17:27,839 –> 00:17:29,760
بنابراین بیایید ببینیم چگونه می توانیم
459
00:17:29,760 –> 00:17:31,600
همان را با استفاده از
460
00:17:31,600 –> 00:17:34,720
nl پیاده سازی کنیم. کتابخانههای tk برای نمودارهای
461
00:17:34,720 –> 00:17:36,240
بیگرام و انگرامها،
462
00:17:36,240 –> 00:17:38,080
بنابراین ابتدا کاری که باید انجام دهیم این است که
463
00:17:38,080 –> 00:17:41,160
نمودارهای پسزمینه و انگرامها را از
464
00:17:41,160 –> 00:17:42,799
nltk.util وارد کنیم،
465
00:17:42,799 –> 00:17:44,880
بنابراین بیایید رشتهای را انتخاب کنیم که بهترین
466
00:17:44,880 –> 00:17:46,799
و بصریترین چیز در جهان
467
00:17:46,799 –> 00:17:48,400
دیده نمیشود یا حتی
468
00:17:48,400 –> 00:17:50,000
باید آنها را آزمایش کنیم. با قلب
469
00:17:50,000 –> 00:17:52,799
چه کد زیبایی، پس اجازه دهید
470
00:17:52,799 –> 00:17:54,320
ابتدا توکن های رشته خود را
471
00:17:54,320 –> 00:17:56,559
با استفاده از کلمه underscore tokenize ایجاد کنیم، همانطور که
472
00:17:56,559 –> 00:17:58,720
قبلاً انجام دادیم تا پس زمینه ایجاد کنیم،
473
00:17:58,720 –> 00:18:01,760
کاری که باید انجام دهیم استفاده از تابع لیست
474
00:18:01,760 –> 00:18:03,520
است و در داخل آن می خواهیم
475
00:18:03,520 –> 00:18:05,360
از nltk.diagrams استفاده کنید
476
00:18:05,360 –> 00:18:07,919
و توکن ها را ارسال کنید
477
00:18:07,919 –> 00:18:10,000
تا همانطور که می بینید
478
00:18:10,000 –> 00:18:12,559
نموداری از سند داده شده را
479
00:18:12,559 –> 00:18:15,200
به طور مشابه ایجاد کرده است اگر ما
480
00:18:15,200 –> 00:18:16,799
تریگرام ها و انگرام ها را ایجاد کنیم،
481
00:18:16,799 –> 00:18:18,400
بنابراین تنها کاری که باید انجام دهید این است که
482
00:18:18,400 –> 00:18:20,799
نمودارها را به trigrams تغییر دهید و به شما می دهد.
483
00:18:20,799 –> 00:18:23,039
لیست trigram اکنون اجازه دهید
484
00:18:23,039 –> 00:18:26,000
یک لیست n-gram درست کنیم،
485
00:18:26,000 –> 00:18:27,679
بنابراین بچه ها همانطور که می بینید در اینجا ما
486
00:18:27,679 –> 00:18:30,480
از همان تابع ltk dot ngrams استفاده می کنیم و
487
00:18:30,480 –> 00:18:31,919
در داخل آن، نقل قول ها را
488
00:18:31,919 –> 00:18:34,160
زیر نشانه دوره قرار می دهیم و
489
00:18:34,160 –> 00:18:36,799
اینجا به جای n ما goi هستیم. ng تا
490
00:18:36,799 –> 00:18:38,960
عدد ما را بدهیم، بنابراین فرض کنید
491
00:18:38,960 –> 00:18:41,120
من پنج را در اینجا ارائه می کنم، بنابراین همانطور که می بینید
492
00:18:41,120 –> 00:18:44,400
، یک n گرم طول پنج به
493
00:18:44,400 –> 00:18:46,880
ما داده است، حالا وقتی همه کلمات را بدست آوریم یا همانطور که
494
00:18:46,880 –> 00:18:49,360
من می گویم نشانه هایی را که باید
495
00:18:49,360 –> 00:18:52,000
تغییراتی در آن ای