در این مطلب، ویدئو تجزیه و تحلیل داده های پایتون با پانداها در 10 دقیقه | مربی Udemy، فرانک کین با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:10:47
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,160 –> 00:00:01,839
سلام اینترنت، پس احتمالا شنیده اید
2
00:00:01,839 –> 00:00:03,520
که علم داده این روزها یک رشته واقعا داغ است
3
00:00:03,520 –> 00:00:05,520
و دانشمندان داده جدید
4
00:00:05,520 –> 00:00:07,440
در واقع حقوق شش رقمی دریافت می کنند،
5
00:00:07,440 –> 00:00:09,599
بنابراین چگونه می توانید به خوبی شروع کنید یک
6
00:00:09,599 –> 00:00:11,120
زبان محبوب در زمینه علم داده
7
00:00:11,120 –> 00:00:13,040
برنامه نویسی پایتون است. زبان
8
00:00:13,040 –> 00:00:15,200
و معمولاً اولین گام در تجزیه و تحلیل
9
00:00:15,200 –> 00:00:16,720
داده ها در پایتون این است که آنها را از طریق
10
00:00:16,720 –> 00:00:18,320
کتابخانه ای به نام پاندا تغذیه کنید
11
00:00:18,320 –> 00:00:19,760
که به شما امکان می دهد داده های خود را به راحتی بارگیری و
12
00:00:19,760 –> 00:00:21,600
دستکاری و تمیز کنید که
13
00:00:21,600 –> 00:00:23,039
معمولاً اولین قدم قبل از ارسال
14
00:00:23,039 –> 00:00:24,720
آن به الگوریتم های دیگر است تا در واقع
15
00:00:24,720 –> 00:00:26,240
معنی را از آن استخراج کنید. آن را یا
16
00:00:26,240 –> 00:00:28,320
یادگیری ماشین را روی آن انجام دهید اکنون یادگیری پانداها
17
00:00:28,320 –> 00:00:29,679
بسیار ساده است اگر از
18
00:00:29,679 –> 00:00:31,119
قبل پایتون را درک کرده اید، فقط باید به
19
00:00:31,119 –> 00:00:32,800
چند نمونه نگاه کنید تا واقعاً بفهمید
20
00:00:32,800 –> 00:00:34,640
که چگونه کار می کند و چه کاری انجام می دهد و این
21
00:00:34,640 –> 00:00:35,760
دقیقاً همان کاری است که ما در 10 مورد بعدی انجام خواهیم داد.
22
00:00:35,760 –> 00:00:36,880
چند دقیقه پس
23
00:00:36,880 –> 00:00:39,200
با من بمانید و بیایید در
24
00:00:39,200 –> 00:00:41,600
پانداها غواصی کنیم، این اساساً راهی برای
25
00:00:41,600 –> 00:00:44,000
پردازش دادههای جدولی است، بنابراین وقتی
26
00:00:44,000 –> 00:00:45,840
ستونها و ردیفهایی از اطلاعات دارید مانند شما
27
00:00:45,840 –> 00:00:47,440
اغلب من n pandas Science Data
28
00:00:47,440 –> 00:00:48,960
یک راه بسیار آسان برای
29
00:00:48,960 –> 00:00:50,640
بارگیری داده ها در دستکاری آن است و
30
00:00:50,640 –> 00:00:52,399
بررسی داده های شما و پاک کردن آن و
31
00:00:52,399 –> 00:00:54,640
مواردی از این قبیل است و
32
00:00:54,640 –> 00:00:55,920
با دو کتابخانه دیگر کار می کند که شما از
33
00:00:55,920 –> 00:00:57,120
آنها در زمینه علم داده استفاده زیادی خواهید کرد.
34
00:00:57,120 –> 00:00:59,120
و یادگیری ماشین،
35
00:00:59,120 –> 00:01:00,879
بنابراین وقتی در مورد الگوریتمهای واقعی یادگیری ماشین صحبت
36
00:01:00,879 –> 00:01:02,239
میکنیم، از یک
37
00:01:02,239 –> 00:01:04,400
کتابخانه پایتون به نام scikit-learn یا
38
00:01:04,400 –> 00:01:05,840
بهاختصار sklearn استفاده
39
00:01:05,840 –> 00:01:07,439
میکنیم، جایی که تمام کدهای واقعی
40
00:01:07,439 –> 00:01:09,280
برای انجام کارهایی مانند رگرسیونهای خطی
41
00:01:09,280 –> 00:01:09,760
یا
42
00:01:09,760 –> 00:01:10,960
svm همه چیزهایی که داریم را دارد.
43
00:01:10,960 –> 00:01:13,520
بعداً در مورد آن صحبت خواهیم کرد و معمولاً یک آرایه numpy را به
44
00:01:13,520 –> 00:01:14,240
عنوان ورودی می
45
00:01:14,240 –> 00:01:16,479
گیرد. بنابراین numpy یک کتابخانه دیگر
46
00:01:16,479 –> 00:01:17,360
در ترکیب اینجاست
47
00:01:17,360 –> 00:01:18,960
که نمایش خاص خود را از
48
00:01:18,960 –> 00:01:20,400
آرایه های داده دارد و این نیز می تواند یک
49
00:01:20,400 –> 00:01:22,159
آرایه چند بعدی از داده ها باشد، بنابراین
50
00:01:22,159 –> 00:01:23,280
به نوعی راهی برای
51
00:01:23,280 –> 00:01:25,520
نمایش اطلاعات به طوری که
52
00:01:25,520 –> 00:01:26,560
معمولاً به این صورت است که
53
00:01:26,560 –> 00:01:28,080
میتوانید از پانداها برای بارگذاری در
54
00:01:28,080 –> 00:01:30,159
دادههای خود استفاده کنید و آنها را دستکاری کنید، آنها را تمیز کنید
55
00:01:30,159 –> 00:01:31,280
و درک کنید
56
00:01:31,280 –> 00:01:33,439
و سپس آنها را به یک آرایه ناتوان ترجمه
57
00:01:33,439 –> 00:01:34,880
کنید که سپس fe میشود. d به
58
00:01:34,880 –> 00:01:35,920
Sikit-Learn
59
00:01:35,920 –> 00:01:37,520
و این ترجمه اغلب به طور خودکار اتفاق می افتد،
60
00:01:37,520 –> 00:01:38,720
به این دلیل که شما
61
00:01:38,720 –> 00:01:40,159
مجبور نیستید کار خاصی انجام دهید، بنابراین
62
00:01:40,159 –> 00:01:41,840
آنچه در این مرحله مهم تر است
63
00:01:41,840 –> 00:01:43,600
درک درست پانداها است زیرا
64
00:01:43,600 –> 00:01:44,960
در واقع تغذیه آن در Sikit-Learn
65
00:01:44,960 –> 00:01:46,479
بسیار پیش پا افتاده است، بنابراین بیایید در مورد پانداها صحبت کنیم.
66
00:01:46,479 –> 00:01:48,000
67
00:01:48,000 –> 00:01:49,520
بیایید کمی به پایین اسکرول کنیم
68
00:01:49,520 –> 00:01:51,520
و با برخی از داده ها بازی کنیم، بنابراین
69
00:01:51,520 –> 00:01:54,399
ما با وارد کردن آنچه نیاز داریم شروع می کنیم،
70
00:01:54,399 –> 00:01:55,600
بنابراین می خواهیم بگوییم که می
71
00:01:55,600 –> 00:01:56,240
خواهیم از
72
00:01:56,240 –> 00:01:58,399
کتابخانه matplotlib در خط این خط
73
00:01:58,399 –> 00:01:59,600
استفاده کنیم فقط به این معنی است که هر نموداری که ما
74
00:01:59,600 –> 00:02:00,960
ایجاد می کنیم زیرا بخشی از نوت بوک ما در خود نوت بوک ظاهر می
75
00:02:00,960 –> 00:02:01,520
76
00:02:01,520 –> 00:02:02,880
شود و نه
77
00:02:02,880 –> 00:02:04,960
در یک پنجره خارجی، سپس باید
78
00:02:04,960 –> 00:02:06,640
به طور خاص کتابخانه
79
00:02:06,640 –> 00:02:08,080
هایی را که می خواهیم در کد پایتون خود استفاده
80
00:02:08,080 –> 00:02:10,399
کنیم وارد کنیم، بنابراین کتابخانه numpy را
81
00:02:10,399 –> 00:02:12,080
به عنوان np وارد
82
00:02:12,080 –> 00:02:13,840
می کنیم. که اکنون میتوانیم به numpy بهعنوان خلاصهنویسی
83
00:02:13,840 –> 00:02:16,239
np در اسکریپت خود
84
00:02:16,239 –> 00:02:17,760
اشاره کنیم و همچنین کتابخانه pandas را بهعنوان pd وارد میکنیم،
85
00:02:17,760 –> 00:02:19,360
86
00:02:19,360 –> 00:02:20,400
بنابراین این بدان معناست که ما
87
00:02:20,400 –> 00:02:22,239
اساساً یک نام مستعار برای کتابخانه
88
00:02:22,239 –> 00:02:23,520
pandas از pd فقط ایجاد کردهایم. برای
89
00:02:23,520 –> 00:02:25,360
صرفه جویی در چند ضربه کلید، پس بیایید
90
00:02:25,360 –> 00:02:27,440
برای اولین بار از پانداها استفاده
91
00:02:27,440 –> 00:02:29,120
کنیم، میخواهیم بگوییم که df برابر با
92
00:02:29,120 –> 00:02:31,120
pd است. بخوانید
93
00:02:31,120 –> 00:02:34,239
94
00:02:34,239 –> 00:02:35,800
95
00:02:35,800 –> 00:02:37,840
underscore فایلی که یک
96
00:02:37,840 –> 00:02:39,360
فایل مقادیر جدا شده با کاما است
97
00:02:39,360 –> 00:02:40,560
که فقط به این معنی است که اطلاعات جدولی است
98
00:02:40,560 –> 00:02:42,640
که در آن هر ستون
99
00:02:42,640 –> 00:02:44,400
با کاما از هم جدا می شود، بنابراین فقط یک
100
00:02:44,400 –> 00:02:46,000
قالب متنی بسیار ساده است
101
00:02:46,000 –> 00:02:48,160
و سطر اول معمولاً
102
00:02:48,160 –> 00:02:50,239
با عنوان آن ستون ها مطابقت دارد، بنابراین با یک
103
00:02:50,239 –> 00:02:51,840
خط کد ما می تواند آن داده ها را
104
00:02:51,840 –> 00:02:52,640
از روی دیسک بخواند
105
00:02:52,640 –> 00:02:53,920
و چیزی به نام یک قاب
106
00:02:53,920 –> 00:02:55,840
داده از آن ایجاد کند، یک قاب داده پاندا
107
00:02:55,840 –> 00:02:57,040
و ما آن فریم داده را
108
00:02:57,040 –> 00:02:59,680
به متغیری به نام df اختصاص
109
00:02:59,680 –> 00:03:02,000
می دهیم تا در pastires.csv بارگیری شود و
110
00:03:02,000 –> 00:03:04,159
آن را به داده پاندا تبدیل کند. فریم
111
00:03:04,159 –> 00:03:06,400
و سپس می توانیم head روی آن شی قاب داده را فراخوانی کنیم
112
00:03:06,400 –> 00:03:08,000
تا
113
00:03:08,000 –> 00:03:09,840
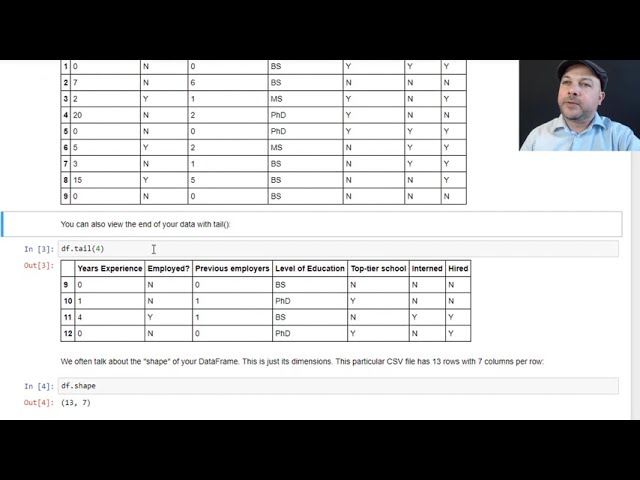
پنج ردیف اول آن فریم داده را تجسم کنیم
114
00:03:09,840 –> 00:03:11,440
و این چیزی است که به نظر می رسد، بنابراین
115
00:03:11,440 –> 00:03:12,720
بیایید در واقع اینجا را کلیک کرده و
116
00:03:12,720 –> 00:03:15,840
shift enter را فشار دهید تا اجرا شود
117
00:03:16,159 –> 00:03:18,319
و می توانید ببینید که این یک است. پیش نمایش
118
00:03:18,319 –> 00:03:19,680
کوچک w از فایل، بنابراین اگر میخواهید
119
00:03:19,680 –> 00:03:20,319
120
00:03:20,319 –> 00:03:21,599
دوبار بررسی کنید که همه چیز به درستی بارگذاری شده است
121
00:03:21,599 –> 00:03:23,040
و بفهمید چه چیزی در آن است،
122
00:03:23,040 –> 00:03:24,560
این یک راه خوب برای انجام یک بررسی نقطهای کوچک
123
00:03:24,560 –> 00:03:25,599
با سر است،
124
00:03:25,599 –> 00:03:27,040
میتوانید اینجا ببینید که ما پنج ردیف اول را
125
00:03:27,040 –> 00:03:29,200
در اینجا نمایش میدهیم. و
126
00:03:29,200 –> 00:03:30,799
ستونهای ما به درستی عنوان شدهاند در اینجا
127
00:03:30,799 –> 00:03:32,239
تجربه استخدام کارفرمایان قبلی
128
00:03:32,239 –> 00:03:33,440
سطح تحصیلات
129
00:03:33,440 –> 00:03:35,280
مدارس سطح بالای کارآموزی و استخدام شده است،
130
00:03:35,280 –> 00:03:36,720
ما از این مجموعه دادهها بعداً
131
00:03:36,720 –> 00:03:37,599
در دوره استفاده میکنیم
132
00:03:37,599 –> 00:03:38,959
تا ببینیم آیا میتوانیم پیشبینی
133
00:03:38,959 –> 00:03:40,799
کنیم که آیا یک متقاضی کار استخدام میشود یا
134
00:03:40,799 –> 00:03:41,280
خیر.
135
00:03:41,280 –> 00:03:44,000
بر اساس تاریخچه گذشته ما خوب است، بنابراین
136
00:03:44,000 –> 00:03:45,519
همه چیز در آنجا نسبتاً خوب به نظر می رسد،
137
00:03:45,519 –> 00:03:47,360
138
00:03:47,360 –> 00:03:49,280
اگر می خواهید تعداد خاصی
139
00:03:49,280 –> 00:03:50,799
از ابتدای فایل خود را ببینید، می توانید یک عدد صحیح را به سر ارسال کنید، بنابراین اگر
140
00:03:50,799 –> 00:03:52,560
می خواهم 10 ردیف اول قاب داده خود را ببینم
141
00:03:52,560 –> 00:03:53,200
142
00:03:53,200 –> 00:03:56,480
. فقط می توانید بگویید df.head 10 مانند آن
143
00:03:56,480 –> 00:03:57,840
و این 10 ردیف اول را چاپ
144
00:03:57,840 –> 00:03:59,200
می کند و می توانید
145
00:03:59,200 –> 00:04:00,000
نمونه کوچکتری از داده ها را در
146
00:04:00,000 –> 00:04:02,879
آنجا ببینید و همچنین می توانید به
147
00:04:02,879 –> 00:04:04,239
انتهای فایل داده خود نیز نگاه کنید اگر فریم داده شما باشد.
148
00:04:04,239 –> 00:04:04,959
e همچنین
149
00:04:04,959 –> 00:04:08,400
بنابراین df.tail به این شکل خواهد بود و
150
00:04:08,400 –> 00:04:10,159
چهار ردیف آخر را
151
00:04:10,159 –> 00:04:11,599
در قاب داده ما نشان می دهد، می توانید ببینید که
152
00:04:11,599 –> 00:04:13,200
این مجموعه داده بسیار کوچکی است، فقط
153
00:04:13,200 –> 00:04:14,239
چیزی است که من ساخته ام
154
00:04:14,239 –> 00:04:17,199
آن را فقط شامل 12 ردیف اطلاعات
155
00:04:17,199 –> 00:04:18,959
می کنیم، اکنون گاهی اوقات ما در مورد
156
00:04:18,959 –> 00:04:20,478
شکل قاب داده خود یا شکل داده خود
157
00:04:20,478 –> 00:04:21,279
158
00:04:21,279 –> 00:04:22,560
صحبت کنید و منظور ما از
159
00:04:22,560 –> 00:04:24,720
شکل فقط ابعاد آن
160
00:04:24,720 –> 00:04:28,240
است، به عنوان مثال اگر بگوییم df.shape
161
00:04:28,240 –> 00:04:31,520
که با 13 کاما 7 برمی گردد.
162
00:04:31,520 –> 00:04:33,520
این بدان معناست که ما 13
163
00:04:33,520 –> 00:04:36,160
سطر و 7 ستون در قاب داده خود داریم
164
00:04:36,160 –> 00:04:37,759
و این شکل قاب داده ما است
165
00:04:37,759 –> 00:04:39,360
که چند ستون دارد و
166
00:04:39,360 –> 00:04:41,520
چند سطر دارد، فقط یک کلمه فانتزی
167
00:04:41,520 –> 00:04:43,120
برای یک مفهوم بسیار ساده دارد
168
00:04:43,120 –> 00:04:45,919
که می توانیم بگوییم df.size. و این به
169
00:04:45,919 –> 00:04:47,840
عنوان 91 برمی گردد که فقط
170
00:04:47,840 –> 00:04:49,120
تعداد سلول های قاب داده ما است که
171
00:04:49,120 –> 00:04:50,560
اساساً تعداد نقاط داده منحصر به فرد
172
00:04:50,560 –> 00:04:51,280
173
00:04:51,280 –> 00:04:53,120
است و
174
00:04:53,120 –> 00:04:54,720
در مثال ما 13
175
00:04:54,720 –> 00:04:57,919
ضربدر 7 خواهد بود.
176
00:04:57,919 –> 00:04:58,639
177
00:04:58,639 –> 00:05:01,280
می تواند len df را فراخوانی کند و
178
00:05:01,280 –> 00:05:02,800
با 13 تیل برمی گردد
179
00:05:02,800 –> 00:05:04,160
180
00:05:04,160 –> 00:05:06,160
اگر فقط به آن نیاز داشته باشید، t فقط تعداد ردیفهای قاب دادهتان را به
181
00:05:06,160 –> 00:05:09,039
شما برمیگرداند، و اگر ستونهای نقطهای df را انجام دهید
182
00:05:09,039 –> 00:05:10,560
183
00:05:10,560 –> 00:05:13,199
، آرایهای از نامهای ستون واقعی را
184
00:05:13,199 –> 00:05:14,160
به شما نشان میدهد، بنابراین اگر میخواهید
185
00:05:14,160 –> 00:05:15,600
یک یادآوری سریع درباره آنچه انجام دهید، انجام دهید.
186
00:05:15,600 –> 00:05:17,600
نام ستونهای شما هستند و معنی
187
00:05:17,600 –> 00:05:18,960
آنها راه خوبی است برای دوست داشتن کمی
188
00:05:18,960 –> 00:05:20,320
تجسم سریع به معنای هر
189
00:05:20,320 –> 00:05:21,680
ستون گاهی اوقات لازم است به
190
00:05:21,680 –> 00:05:23,600
خودتان یادآوری کنید و این یک
191
00:05:23,600 –> 00:05:26,800
ترفند