در این مطلب، ویدئو رگرسیون وزنی موضعی | یادگیری ماشین پایتون| با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:11:26
تصاویر این ویدئو:
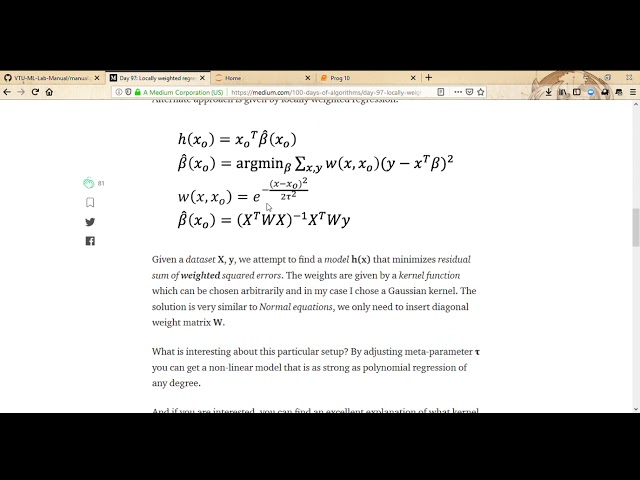
قسمتی از زیرنویس این فیلم:
00:00:01,580 –> 00:00:04,350
بنابراین این دهمین برنامه است، برنامه دهم
2
00:00:04,350 –> 00:00:06,560
رگرسیون با وزن محلی است
3
00:00:06,560 –> 00:00:10,469
تا با نقاط داده متناسب باشد، بنابراین این
4
00:00:10,469 –> 00:00:12,719
برنامه بر اساس این وبلاگ است، من
5
00:00:12,719 –> 00:00:14,700
احتمالاً پیوندی را در توضیحات خواهم گذاشت،
6
00:00:14,700 –> 00:00:17,970
بنابراین این وبلاگ اساساً در مورد
7
00:00:17,970 –> 00:00:19,470
نحوه انجام رگرسیون وزنی محلی
8
00:00:19,470 –> 00:00:22,380
در این مورد صحبت می کند. توزیع دادههای خاص، این
9
00:00:22,380 –> 00:00:24,060
همان کاری است که ما میخواهیم انجام دهیم، اگر
10
00:00:24,060 –> 00:00:25,650
میخواهید در مورد ریاضیات پشت این مطلب بخوانید
11
00:00:25,650 –> 00:00:27,029
و دوست دارید ببینید که چگونه در واقع
12
00:00:27,029 –> 00:00:28,890
با هم جمع میشود، قطعاً این پیوند را بررسی کنید،
13
00:00:28,890 –> 00:00:31,140
اما بله، اجازه دهید شروع کنیم، بنابراین اولین
14
00:00:31,140 –> 00:00:32,250
کاری که میخواهیم انجام دهیم این است که ما باید
15
00:00:32,250 –> 00:00:34,590
نقاط داده خود را ایجاد کنیم که برای آنها
16
00:00:34,590 –> 00:00:36,899
الگوریتم یادگیری خود را
17
00:00:36,899 –> 00:00:39,629
به درستی مشخص کنیم، بنابراین نیاز داریم تا نتوانیم از
18
00:00:39,629 –> 00:00:41,700
هیچ کلاس داخلی برای ساخت
19
00:00:41,700 –> 00:00:44,430
مدل استفاده کنیم، بنابراین باید فقط از احتمالا
20
00:00:44,430 –> 00:01:03,090
numpy در متلب استفاده کنیم، بنابراین من از آن استفاده می کنم. بله، بنابراین ما
21
00:01:03,090 –> 00:01:05,369
حلقه متد numpad را وارد کردهایم، بنابراین من
22
00:01:05,369 –> 00:01:08,580
باید X را ایجاد کنم، بنابراین اساساً میخواهم
23
00:01:08,580 –> 00:01:13,260
مجموعه دادههای من هزار باشد و ورودیهایی
24
00:01:13,260 –> 00:01:15,689
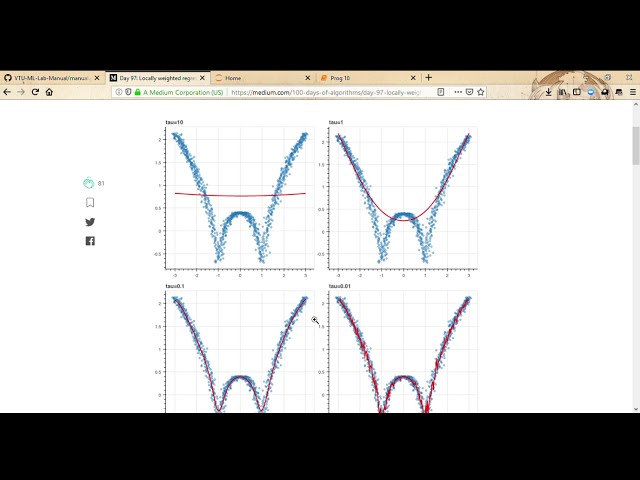
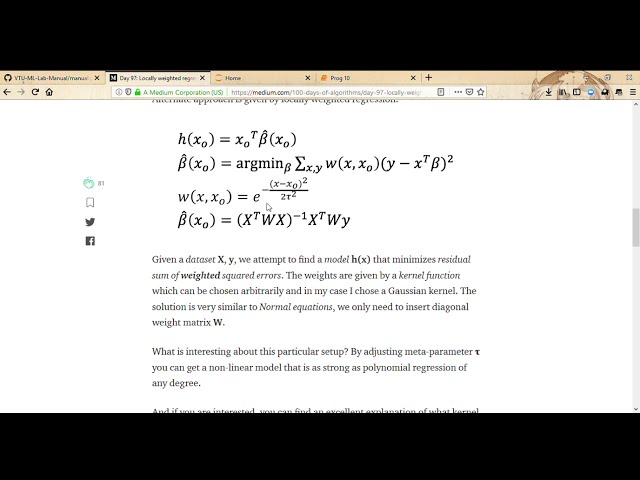
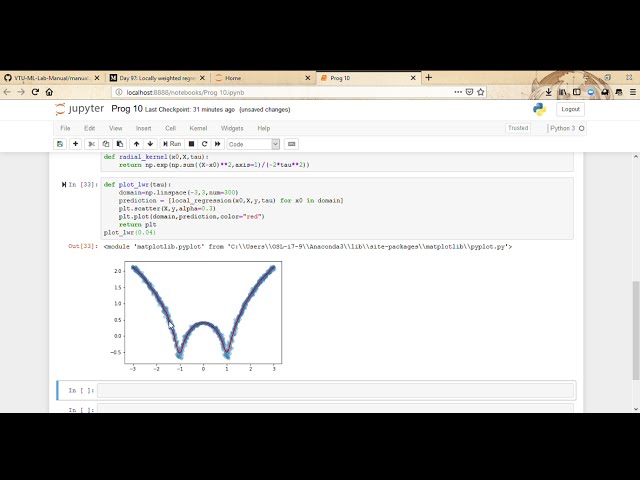
مانند هزار ورودی داشته باشد، بنابراین میخواهم
25
00:01:15,689 –> 00:01:19,409
از linspace برای ایجاد هزار
26
00:01:19,409 –> 00:01:23,280
ورودی استفاده کنم. به متغیر X من وارد میشود، بنابراین من آن را درست
27
00:01:23,280 –> 00:01:34,380
میکنم تا به هزار ورودی نیاز داشته باشم،
28
00:01:34,380 –> 00:01:36,060
بنابراین معنی این خط این است
29
00:01:36,060 –> 00:01:38,490
که بین محدوده منهای سه تا
30
00:01:38,490 –> 00:01:40,229
سه هزار عدد را به من برگردانید و آنها را
31
00:01:40,229 –> 00:01:42,570
در متغیر X خود قرار دهید تا من همین باشم.
32
00:01:42,570 –> 00:01:45,990
میخواهیم با X انجام دهیم و به همین ترتیب باید
33
00:01:45,990 –> 00:01:49,140
مقداری را انجام دهیم، باید Y را نیز اضافه کنیم، بنابراین
34
00:01:49,140 –> 00:01:51,540
من میخواهم تابعی از X باشد، بنابراین
35
00:01:51,540 –> 00:01:55,049
میخواهم خیلی مستقیم را نشان دهم، بگذارید
36
00:01:55,049 –> 00:01:58,799
Y یک تابع سینوسی از X باشد. بیایید این
37
00:01:58,799 –> 00:02:05,090
کار را انجام دهیم و اجازه دهید من فقط آن را رسم کنم
38
00:02:07,190 –> 00:02:10,530
تا همانطور که می بینید یک تابع سینوس ایجاد می کند
39
00:02:10,530 –> 00:02:12,930
که تقریباً
40
00:02:12,930 –> 00:02:17,099
بین محدوده منهای 3 تا مثبت 3 است اما می
41
00:02:17,099 –> 00:02:19,110
دانید که ما می خواهیم نموداری را که
42
00:02:19,110 –> 00:02:21,269
در این وبلاگ نشان داده شده است به دست آوریم
43
00:02:21,269 –> 00:02:23,819
زیرا خیلی جالب است، بنابراین اجازه
44
00:02:23,819 –> 00:02:25,890
دهید این تابع را تغییر دهیم
45
00:02:25,890 –> 00:02:29,220
تا یک تابع لگاریتمی باشد که از سیستم خارج شود،
46
00:02:29,220 –> 00:02:32,040
من مقادیر منفی نمی خواهم، بنابراین
47
00:02:32,040 –> 00:02:35,549
از NP absolute استفاده می کنم که فقط
48
00:02:35,549 –> 00:02:40,220
قدر مطلق x مجذور
49
00:02:40,400 –> 00:02:48,989
منهای 1 به اضافه 0.5 را درست می دهد. بیایید ببینیم که چگونه پیش
50
00:02:48,989 –> 00:02:51,870
می رود من فقط کمی
51
00:02:51,870 –> 00:02:54,030
شفافیت را اضافه می کنم تا من فقط مقدار آلفا
52
00:02:54,030 –> 00:03:03,569
را به 0.3 تغییر دهید، بنابراین اکنون به نوعی می بینید
53
00:03:03,569 –> 00:03:05,910
که نمودار چگونه به نظر می رسد، اما به نوعی
54
00:03:05,910 –> 00:03:08,790
بسیار قابل پیش بینی است و بنابراین من آن را
55
00:03:08,790 –> 00:03:10,290
هزاران نقطه داده در واقع بسیار کم
56
00:03:10,290 –> 00:03:16,019
در اینجا می کنم، بنابراین بله، بنابراین می توانید ببینید که
57
00:03:16,019 –> 00:03:17,579
نقطه داده ما بوده است. با این حال ایجاد شده است
58
00:03:17,579 –> 00:03:19,859
، همه آنها در یک راستا هستند و
59
00:03:19,859 –> 00:03:21,810
بسیار نرم هستند، بنابراین ما باید
60
00:03:21,810 –> 00:03:24,630
کمی تصادفی را در آن وارد کنیم، بنابراین من
61
00:03:24,630 –> 00:03:51,750
فقط X را به روز می کنم تا آه بکشد، بله، بنابراین اکنون
62
00:03:51,750 –> 00:03:54,269
می توانید ببینید که مقدار کمی از شما
63
00:03:54,269 –> 00:03:55,799
می دانید تصادفی بودن مرتبط با آن
64
00:03:55,799 –> 00:03:59,280
کاملاً قابل پیشبینی نیست، بنابراین
65
00:03:59,280 –> 00:04:01,440
ایجاد مجموعهای از دادهها برای دادن
66
00:04:01,440 –> 00:04:04,260
67
00:04:04,260 –> 00:04:06,239
68
00:04:06,239 –> 00:04:08,819
آن به خزش است.
69
00:04:08,819 –> 00:04:11,510
منهای 1 مقدار مطلق به اضافه 0.5
70
00:04:11,510 –> 00:04:13,430
سپس در یک تابع log کشیده می شود، بنابراین این
71
00:04:13,430 –> 00:04:16,750
چیزی است که اکنون به دست می آورید، بیایید الگوریتم خود را تعریف کنیم
72
00:04:16,750 –> 00:04:18,649
که قرار است از
73
00:04:18,649 –> 00:04:29,210
بخش یادگیری مراقبت کند، بنابراین در اینجا چیزی است که
74
00:04:29,210 –> 00:04:30,590
ما می توانیم اصطلاح بایاس tau را اضافه کنیم.
75
00:04:30,590 –> 00:04:33,889
پارامت