در این مطلب، ویدئو نحوه حذف رکوردهای تکراری از جدول DataFrame Pandas در پایتون | آموزش پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:

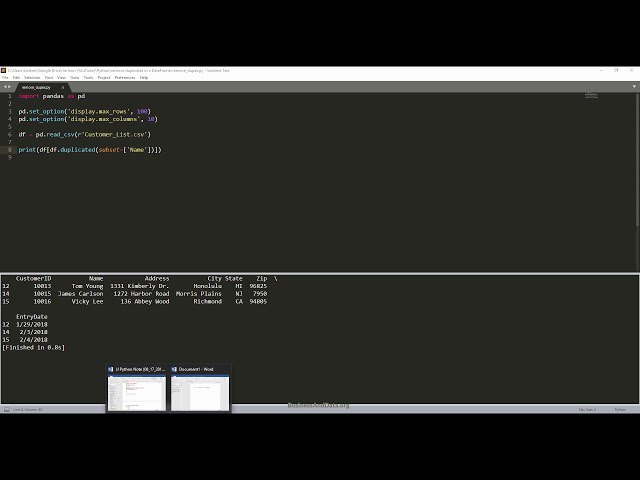
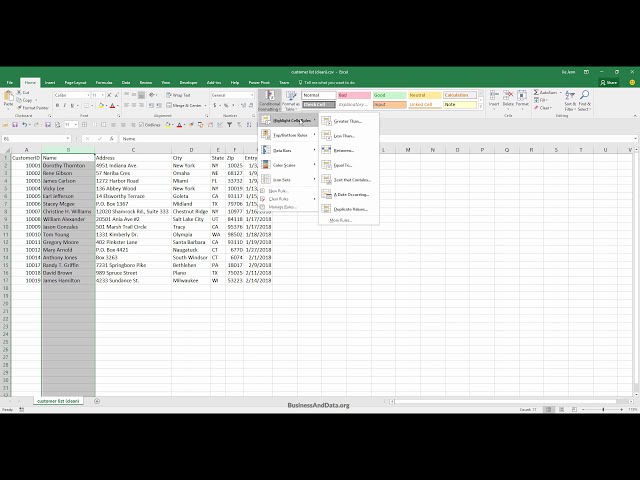
قسمتی از زیرنویس این فیلم:
00:00:00,170 –> 00:00:04,290
سلام نام من J است در این ویدیو می خواهم
2
00:00:04,290 –> 00:00:05,879
به شما نشان دهم که چگونه
3
00:00:05,879 –> 00:00:10,469
رکوردهای تکراری را از جدول داده فریم پانداها حذف کنید، بنابراین
4
00:00:10,469 –> 00:00:15,719
اگر یک فایل CSV دارید تا فایل ها
5
00:00:15,719 –> 00:00:18,779
مشتریان ما را بپزند، بنابراین در اینجا چند
6
00:00:18,779 –> 00:00:22,500
رکورد ساختگی وجود دارد که من ایجاد می کنم و ما
7
00:00:22,500 –> 00:00:24,570
دو برابر داریم. در ستونها، نام شناسه مشتری،
8
00:00:24,570 –> 00:00:27,689
آدرس شهر کد پستی و
9
00:00:27,689 –> 00:00:28,500
تاریخ ورود را داریم،
10
00:00:28,500 –> 00:00:31,920
بنابراین از ستون نام برای تعیین رکورد
11
00:00:31,920 –> 00:00:34,350
12
00:00:34,350 –> 00:00:37,980
استفاده میکنیم، بنابراین در حال حاضر در فایل اکسل من اگر
13
00:00:37,980 –> 00:00:39,660
فقط از قالببندی شرطی استفاده میکنم استفاده میکنم و آن را
14
00:00:39,660 –> 00:00:43,200
برجسته میکنم. مقادیر تکراری و ما
15
00:00:43,200 –> 00:00:45,329
می دانیم که باید به درمان
16
00:00:45,329 –> 00:00:48,780
رکوردهای تکراری کمک کند، بنابراین باید
17
00:00:48,780 –> 00:00:52,500
از اولین نمونه چشم پوشی کنیم و بنابراین
18
00:00:52,500 –> 00:00:54,809
اگر فقط روی نمونه دوم تمرکز
19
00:00:54,809 –> 00:00:57,449
کنیم و تام جوان جیمز و
20
00:00:57,449 –> 00:00:59,640
ویکی لی را نزدیکتر کنیم، بنابراین این سه
21
00:00:59,640 –> 00:01:05,760
رکورد هستند. که من میخواهم این فایل را حذف و ببندم،
22
00:01:05,760 –> 00:01:09,110
پس بیایید ادامه دهیم و محیط توسعه خود را باز کنیم،
23
00:01:09,110 –> 00:01:12,229
24
00:01:12,560 –> 00:01:15,810
بنابراین اجازه دهید ابتدا ماژول استقلال ورودی خود را مدیون ماژول مستقل خود باشیم
25
00:01:15,810 –> 00:01:20,900
و من میخواهم
26
00:01:20,900 –> 00:01:28,350
نمایشگر را به گونهای تنظیم کنم که بیایید حداکثر افزایش را
27
00:01:28,350 –> 00:01:33,630
برای فقط یک hu تنظیم کنید. سطرهای ndred و
28
00:01:33,630 –> 00:01:39,720
همچنین ستون های بعدی برای دیدن من فقط
29
00:01:39,720 –> 00:01:42,329
به ده ستون نیاز دارم، فقط وضعیت داده های من
30
00:01:42,329 –> 00:01:46,740
، ستون های غالب دارم و سپس می خواهم
31
00:01:46,740 –> 00:01:49,110
داده ها را وارد کنم، بنابراین از
32
00:01:49,110 –> 00:01:55,259
روش فایل PD da re CSV خود از DP استفاده می کنم و در
33
00:01:55,259 –> 00:01:58,469
اینجا میخواهم نام فایل را بگیرم، بنابراین فقط میخواهم نام فایل را
34
00:01:58,469 –> 00:02:01,820
پنهان کنم.
35
00:02:04,219 –> 00:02:07,399
unita fighters امن هستند و
36
00:02:07,399 –> 00:02:12,000
ویدیو را چاپ میکند بله متن اضافی، پس حالا اگر من فقط این را
37
00:02:12,000 –> 00:02:16,200
ذخیره و اجرا کنم و اگر
38
00:02:16,200 –> 00:02:19,879
خروجی مجموعه داده را دریافت کنیم
39
00:02:19,879 –> 00:02:22,860
ما می دانیم که در پانداهای ما که
40
00:02:22,860 –> 00:02:28,769
در کلاس هستند، باید این کار را انجام دهیم بله،
41
00:02:28,769 –> 00:02:32,670
روشی به نام تکرار و متد وجود دارد، اما
42
00:02:32,670 –> 00:02:35,700
متأسفانه چون شناسه مشتری ما
43
00:02:35,700 –> 00:02:40,110
برای هر رکورد منحصر به فرد است، بنابراین اگر
44
00:02:40,110 –> 00:02:43,170
اینها را رایت کنم، روش با این فرض پیش می رود
45
00:02:43,170 –> 00:02:46,380
که همه رکوردها منحصر به فرد هستند و برای
46
00:02:46,380 –> 00:02:49,319
رفع آن، از زیرمجموعه کد ویژگی استفاده خواهیم کرد،
47
00:02:49,319 –> 00:02:53,340
بنابراین ویژگی زیرمجموعه به
48
00:02:53,340 –> 00:02:56,489
شما اجازه می دهد تا مشخص کنید از کدام ستون ها می خواهید
49
00:02:56,489 –> 00:02:59,730
برای تعیین رکورد بودن استفاده کنید، بنابراین
50
00:02:59,730 –> 00:03:02,160
ما بدانیم که از نام استفاده نمی کنم.
51
00:03:02,160 –> 00:03:05,400
ستون بنابراین من قصد دارم یک لیست ایجاد کنم و
52
00:03:05,400 –> 00:03:08,549
اساساً در l آیا اینها
53
00:03:08,549 –> 00:03:10,260
نام
54
00:03:10,260 –> 00:03:13,290
ستونهایی هستند که میخواهم برای تعیین اینکه از چه ستونهایی برای
55
00:03:13,290 –> 00:03:17,250
تعیین موارد فریبنده استفاده کنم استفاده کنم و حالا اگر اضافه کنم اگر
56
00:03:17,250 –> 00:03:20,430
فقط این را ذخیره و اجرا کنم و میدانیم
57
00:03:20,430 –> 00:03:21