در این مطلب، ویدئو قضیه حد مرکزی – با مثال هایی در پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:17:39
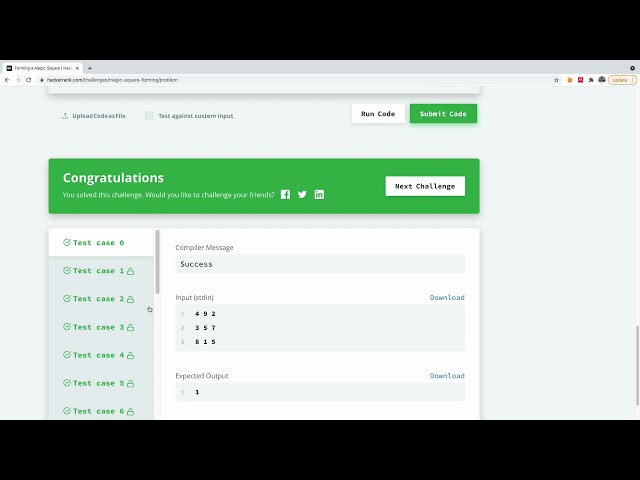
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,410 –> 00:00:04,140
سلام، من جان کرون هستم، دانشمند ارشد داده
2
00:00:04,140 –> 00:00:05,490
در شرکت یادگیری ماشینی که
3
00:00:05,490 –> 00:00:08,010
استفاده نشده است و خوشحالم
4
00:00:08,010 –> 00:00:10,230
که امروز مفهوم
5
00:00:10,230 –> 00:00:12,389
حد مرکزی یکی از
6
00:00:12,389 –> 00:00:14,219
مهمترین مفاهیم اساسی در
7
00:00:14,219 –> 00:00:17,220
آمار است که قضیه حد مرکزی
8
00:00:17,220 –> 00:00:19,109
در پس آن نهفته است. همه محبوبترین
9
00:00:19,109 –> 00:00:20,160
10
00:00:20,160 –> 00:00:21,890
روشهای آماری و
11
00:00:21,890 –> 00:00:24,300
یادگیری ماشینی در زمان ما ابتدا با یک
12
00:00:24,300 –> 00:00:26,279
نسخه آزمایشی تعاملی پایتون بازی میکنیم تا
13
00:00:26,279 –> 00:00:27,689
دقیقاً بفهمیم قضیه حد مرکزی
14
00:00:27,689 –> 00:00:30,449
در پایان نسخه آزمایشی چیست که
15
00:00:30,449 –> 00:00:32,880
در موقعیت خوبی قرار خواهیم گرفت. درک کنید که چرا این یک
16
00:00:32,880 –> 00:00:35,610
مفهوم مهم در آمار و
17
00:00:35,610 –> 00:00:38,340
یادگیری ماشین برای شروع است، ما باید
18
00:00:38,340 –> 00:00:42,030
راه خود را به کد من پیدا کنیم تا بتوانید
19
00:00:42,030 –> 00:00:46,050
به gist github.com اسلش جان
20
00:00:46,050 –> 00:00:49,500
کروم بروید و در آنجا نکات مختلفی را خواهید
21
00:00:49,500 –> 00:00:52,170
یافت که من آن را منتشر کردم.
22
00:00:52,170 –> 00:00:53,430
به دنبال یک سال،
23
00:00:53,430 –> 00:00:56,940
قضیه حد مرکزی نامیده میشود و بنابراین میتوانید
24
00:00:56,940 –> 00:00:58,680
از طریق آن پیمایش کنید و ببینید که کدامهای دیگر
25
00:00:58,680 –> 00:01:01,020
در اینجا هستند، قضیه حد مرکزی یکی از
26
00:01:01,020 –> 00:01:04,979
آنهاست که روی آن کلیک میکنیم و به
27
00:01:04,979 –> 00:01:07,290
ما میرساند از طریق کل نسخه ی نمایشی کد، اکنون کاری که
28
00:01:07,290 –> 00:01:09,180
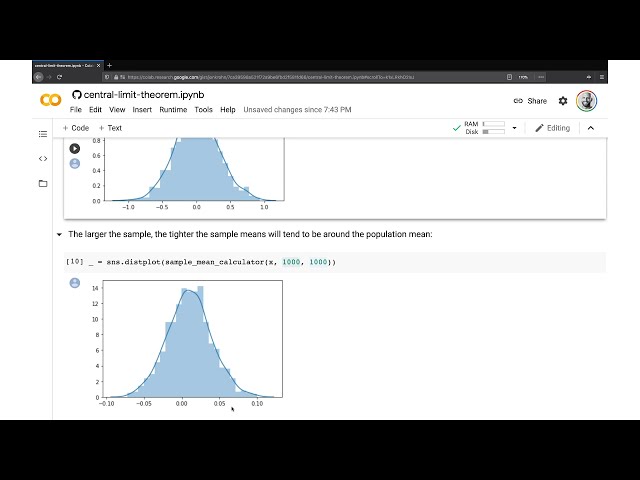
ما می خواهیم انجام دهیم این است که به صورت
29
00:01:09,180 –> 00:01:11,970
تعاملی بسیار آسان اجرا شود، روی
30
00:01:11,970 –> 00:01:15,420
این دکمه open in collab کلیک می کنیم،
31
00:01:15,420 –> 00:01:19,470
این دفترچه کد را در داخل رابط Google
32
00:01:19,470 –> 00:01:22,770
collab باز می کند که تا زمانی
33
00:01:22,770 –> 00:01:25,409
که Google دارید ورود به سیستم که رایگان است و
34
00:01:25,409 –> 00:01:28,290
از این طریق می توانید به
35
00:01:28,290 –> 00:01:31,710
منابع محاسبات ابری قدرتمند خود دسترسی پیدا کنید که
36
00:01:31,710 –> 00:01:33,780
به شما امکان می دهد این نوت بوک کد را
37
00:01:33,780 –> 00:01:36,750
در کنار من اجرا کنید و سپس می
38
00:01:36,750 –> 00:01:38,009
توانید با هر چیزی که دوست دارید بازی کنید و می
39
00:01:38,009 –> 00:01:39,060
توانید هر کدی را که می خواهید تغییر دهید. می توانید
40
00:01:39,060 –> 00:01:43,140
به میل قلبی خود آزمایش کنید، بنابراین
41
00:01:43,140 –> 00:01:44,070
اولین کاری که در
42
00:01:44,070 –> 00:01:47,189
اینجا انجام می دهیم، به منوی کشویی ویرایش
43
00:01:47,189 –> 00:01:50,009
می رویم و همه خروجی ها
44
00:01:50,009 –> 00:01:54,030
را پاک می کنیم، این به ما یک صفحه تمیز برای کار
45
00:01:54,030 –> 00:01:55,350
در اینجا می دهد. نوت بوک ما
46
00:01:55,350 –> 00:01:58,140
هیچ یک از سلول های اجرا شده را نداریم اکنون قابل مشاهده است،
47
00:01:58,140 –> 00:02:01,079
بنابراین این نوت بوک های همکار مانند هر نوت بوک مشتری دیگری
48
00:02:01,079 –> 00:02:03,409
49
00:02:03,409 –> 00:02:06,810
متن و همچنین سلول های کد را با هم مخلوط می کنند و بنابراین این
50
00:02:06,810 –> 00:02:09,030
متن در اینجا فقط برای راحتی است
51
00:02:09,030 –> 00:02:11,879
و بنابراین در بالای صفحه ما قرار دارد. دفترچه یادداشت روی
52
00:02:11,879 –> 00:02:13,540
سنت قضیه حد ral ما وابستگیهایی داریم که
53
00:02:13,540 –> 00:02:15,159
در حال بارگذاری هستند، بنابراین
54
00:02:15,159 –> 00:02:17,500
55
00:02:17,500 –> 00:02:20,349
میتوانید برای اجرای آنها روی play کلیک کنید تا
56
00:02:20,349 –> 00:02:22,450
بتوانید به این دفترچه که من
57
00:02:22,450 –> 00:02:24,219
نوشتهام اعتماد کنید و به هر حال روی آن کلیک کنید
58
00:02:24,219 –> 00:02:30,970
و همانطور که ما در اینجا اجرا میکنیم، میتوانید
59
00:02:30,970 –> 00:02:32,290
روی آن کلیک کنید. دکمه پخش یا
60
00:02:32,290 –> 00:02:35,950
می توانید از shift return برای اجرای
61
00:02:35,950 –> 00:02:38,470
سلول استفاده کنید اگر می خواهید سلول های بیشتری اضافه کنید،
62
00:02:38,470 –> 00:02:40,359
می توانید با کلیک کردن بر روی کد اینجا یک سلول کد اضافه
63
00:02:40,359 –> 00:02:42,220
کنید، بنابراین با نگه داشتن ماوس روی شکاف
64
00:02:42,220 –> 00:02:44,859
بین سلول ها می توانید روی کد گفتن کلیک کنید
65
00:02:44,859 –> 00:02:46,780
و سپس می توانید کد بیشتری اضافه کنید یا می
66
00:02:46,780 –> 00:02:48,040
توانید همین کار را انجام دهید تا آن را در یک
67
00:02:48,040 –> 00:02:50,109
سلول متنی اضافه کنید تا بتوانید هر طور
68
00:02:50,109 –> 00:02:52,599
که دوست دارید در نسخه ی نمایشی با
69
00:02:52,599 –> 00:02:55,260
آن بازی کنید، بنابراین ما با شبیه سازی یک
70
00:02:55,260 –> 00:02:58,780
جمعیت به طور معمول توزیع شده شروع می کنیم تا این کار را انجام دهیم.
71
00:02:58,780 –> 00:03:00,909
ما در
72
00:03:00,909 –> 00:03:05,470
اینجا به طور پیشفرض از روش طبیعی تصادفی numpy استفاده میکنیم،
73
00:03:05,470 –> 00:03:07,450
این توزیع نرمال استاندارد را ایجاد میکند
74
00:03:07,450 –> 00:03:09,189
که در عرض یک ثانیه به شما نشان میدهم
75
00:03:09,189 –> 00:03:10,810
که نکته کلیدی که باید
76
00:03:10,810 –> 00:03:12,760
در اینجا در مورد آن تصمیم بگیریم این است که چند نقطه قرار است داشته باشیم.
77
00:03:12,760 –> 00:03:14,709
در پاپ ما داشته باشیم بنابراین شما
78
00:03:14,709 –> 00:03:17,260
می توانید این را هر عددی در حالت ایده آل هر
79
00:03:17,260 –> 00:03:19,299
عدد بزرگی که من انتخاب می کنم 10000 کنید اما
80
00:03:19,299 –> 00:03:20,799
می توانید یک 100000 یا یک میلیون انتخاب کنید
81
00:03:20,799 –> 00:03:23,739
و بنابراین من شبیه سازی می کنم یک آرایه numpy
82
00:03:23,739 –> 00:03:27,940
در اینجا با 10000 مقدار ایجاد می کنم و بیایید
83
00:03:27,940 –> 00:03:29,379
به توزیع آن مقادیر نگاه
84
00:03:29,379 –> 00:03:31,510
کنیم تا ما
85
00:03:31,510 –> 00:03:34,889
در اینجا از روش نمودار دیسک Seabourn برای رسم توزیع استفاده میکنیم،
86
00:03:34,889 –> 00:03:38,590
بنابراین این منحنی زنگشکل در اینجا
87
00:03:38,590 –> 00:03:41,440
توزیع نرمال یا توزیع گاوسی
88
00:03:41,440 –> 00:03:45,010
است و این یکی در اینجا
89
00:03:45,010 –> 00:03:47,199
توزیع نرمال استاندارد است همانطور
90
00:03:47,199 –> 00:03:49,389
که قبلاً ذکر کردم، بنابراین به طور پیشفرض این
91
00:03:49,389 –> 00:03:52,569
تابع عادی تصادفی است. به طور خودکار
92
00:03:52,569 –> 00:03:54,159
از توزیع نرمال استاندارد
93
00:03:54,159 –> 00:03:56,079
که یک
94
00:03:56,079 –> 00:03:57,909
توزیع نرمال توزیع شده با میانگین
95
00:03:57,909 –> 00:04:00,159
0 است و آنچه که انحراف معیار 1 نامیده می شود،
96
00:04:00,159 –> 00:04:03,069
نمونه برداری می کند که
97
00:04:03,069 –> 00:04:06,870
اندازه گیری میزان فاصله مقادیر
98
00:04:06,870 –> 00:04:12,129
از میانگین 0 ما است، بنابراین به طور پیش فرض
99
00:04:12,129 –> 00:04:15,519
این روش نمودار دور
100
00:04:15,519 –> 00:04:19,209
نیز یک تخمین چگالی هسته این
101
00:04:19,209 –> 00:04:22,150
منحنی آبی را در اطراف توزیع
102
00:04:22,150 –> 00:04:24,130
به ما ارائه می دهد و بنابراین می توانید در صورت
103
00:04:24,130 –> 00:04:27,100
گیج شدن آن را به صورت اختیاری خاموش کنید. میبینیم که
104
00:04:27,100 –> 00:04:29,770
همین منحنی که در اینجا بدون
105
00:04:29,770 –> 00:04:34,480
آن نمودار چگالی هسته ترسیم شده است، میتوانید آن را ببینید
106
00:04:34,480 –> 00:04:36,310
، این فقط شمارشی
107
00:04:36,310 –> 00:04:40,450
از مقادیر موجود در جمعیت ده
108
00:04:40,450 –> 00:04:42,370
هزار نقطهای شبیهسازیشده ما است که به طور معمول توزیع شده است،
109
00:04:42,370 –> 00:04:44,860
بنابراین این
110
00:04:44,860 –> 00:04:47,260
نقطه شروع ما است.
111
00:04:47,260 –> 00:04:48,850
ما برای دستیابی به قلب
112
00:04:48,850 –> 00:04:50,650
قضیه حد مرکزی این کار را انجام می دهیم، این است که
113
00:04:50,650 –> 00:04:56,110
از توزیع نرمال خود نمونه برداری می کنیم، بنابراین به یاد داشته باشید
114
00:04:56,110 –> 00:04:59,050
که ما این آرایه numpy را X نامیدیم،
115
00:04:59,050 –> 00:05:01,480
بنابراین اکنون به کار با آن ادامه می
116
00:05:01,480 –> 00:05:06,750
دهیم. نمونهبرداری از مقادیر تصادفی از
117
00:05:06,750 –> 00:05:09,760
جامعه، بنابراین ما یک
118
00:05:09,760 –> 00:05:11,920
جمعیت 10000 داریم و من در اینجا
119
00:05:11,920 –> 00:05:15,670
ده مقدار
120
00:05:15,670 –> 00:05:18,790
را نمونهبرداری میکنم.
121
00:05:18,790 –> 00:05:20,880
122
00:05:20,880 –> 00:05:24,490
ما بدون جایگزینی نمونه برداری می
123
00:05:24,490 –> 00:05:25,420
124
00:05:25,420 –> 00:05:29,110
کنیم، بنابراین ده مقدار از
125
00:05:29,110 –> 00:05:32,320
10000 را می گیریم و این برگ ها به نوعی در
126
00:05:32,320 –> 00:05:36,220
گلدان قرار می گیرند تا بعداً در 9990 نمونه برداری شوند، به این معنی است
127
00:05:36,220 –> 00:05:38,320
که اگر جایگزینی را برابر با
128
00:05:38,320 –> 00:05:41,170
true قرار دهید، در تئوری می توانید نمونه برداری مجدد را ادامه دهید.
129
00:05:41,170 –> 00:05:43,420
هفتم مقادیر یکسانی از جمعیت شما وجود
130
00:05:43,420 –> 00:05:45,660
دارد و ما نمی خواهیم این کار را انجام دهیم که
131
00:05:45,660 –> 00:05:48,790
شما تمایل دارید این کار را بدون جایگزین انجام
132
00:05:48,790 –> 00:05:52,570
دهید، بنابراین بیایید نمونه ای از ده نقطه تصادفی را
133
00:05:52,570 –> 00:05:54,610
از بین ده هزار نفر خود برداریم و
134
00:05:54,610 –> 00:05:55,990
ببینیم چگونه به نظر می رسند، خوب این
135
00:05:55,990 –> 00:05:58,750
مقادیر هستند و سپس نکته کلیدی که ما در
136
00:05:58,750 –> 00:05:59,860
طول این آموزش انجام خواهیم داد
137
00:05:59,860 –> 00:06:03,040
، محاسبه میانگین
138
00:06:03,040 –> 00:06:05,230
نمونه ها است، بنابراین در اینجا من از روش میانگین
139
00:06:05,230 –> 00:06:09,670
از کتابخانه آمار استفاده می کنم و بنابراین شما
140
00:06:09,670 –> 00:06:14,170
می توانید در اینجا جمعیت نمونه من را در
141
00:06:14,170 –> 00:06:15,880
اجرای آن و هر بار مشاهده کنید. زمانی که این را اجرا
142
00:06:15,880 –> 00:06:16,920
می کنید مقادیر متفاوتی دریافت خواهید کرد
143
00:06:16,920 –> 00:06:20,230
زیرا هم توزیع دقیق
144
00:06:20,230 –> 00:06:21,550
و هم مقادیری که از آن نمونه برداری
145
00:06:21,550 –> 00:06:22,630
می کنیم هر
146
00:06:22,630 –> 00:06:24,790
بار که این را اجرا می کنیم متفاوت خواهد بود اما این بار
147
00:06:24,790 –> 00:06:29,020
میانگین 0.25 را دریافت می کنم. اکنون این در
148
00:06:29,020 –> 00:06:32,350
واقع کمی با میانگین جمعیت واقعی ما فاصله دارد،
149
00:06:32,350 –> 00:06:35,650
بنابراین به
150
00:06:35,650 –> 00:06:39,280
خاطر داشته باشید که البته هر چه نمونه بزرگتر را بگیریم
151
00:06:39,280 –> 00:06:40,960
152
00:06:40,960 –> 00:06:43,449
، احتمال اینکه میانگینی
153
00:06:43,449 –> 00:06:46,360
نزدیک به میانگین جمعیت
154
00:06:46,360 –> 00:06:48,220
واقعی صفر باشد بیشتر می شود. بنابراین به خاطر داشته باشید
155
00:06:48,220 –> 00:06:51,039
که ما خواهیم دید اگر بعداً وارد
156
00:06:51,039 –> 00:06:54,910
شوید تا این نسخه آزمایشی تا
157
00:06:54,910 –> 00:06:57,130
حد امکان کارآمد باشد، یک محاسبه خاص وجود
158
00:06:57,130 –> 00:06:59,560
دارد که میخواهیم بارها و بارها آن را تکرار کنیم،
159
00:06:59,560 –> 00:07:02,080
بنابراین من آن را در یک
160
00:07:02,080 –> 00:07:03,940
تابع قرار دادم، بنابراین یک تابع در اینجا ایجاد کردم
161
00:07:03,940 –> 00:07:07,000
به نام میانگین میانگین ماشینحساب
162
00:07:07,000 –> 00:07:10,569
در یک آرایهی کمرنگ قرار میگیرد که شامل تمام
163
00:07:10,569 –> 00:07:12,789
نقاط داده در جمعیت ما است، به
164
00:07:12,789 –> 00:07:15,120
عنوان مثال، ما
165
00:07:15,120 –> 00:07:17,199
166
00:07:17,199 –> 00:07:18,310
جمعیت توزیع شده معمولی توزیع شده معمولی را که قبلاً بهطور
167
00:07:18,310 –> 00:07:20,250
لحظهای در اینجا ایجاد کردهایم به X منتقل میکنیم و
168
00:07:20,250 –> 00:07:22,750
سپس دو آرگومان دیگر وجود دارد که در آن ارسال میکنیم
169
00:07:22,750 –> 00:07:25,930
. این که ما میخواهیم چقدر حجم نمونه
170
00:07:25,930 –> 00:07:27,940
را جمعآوری کنیم، در اینجا
171
00:07:27,940 –> 00:07:30,250
یک اندازه نمونه 10 داشتیم که به شما امکان میدهد
172
00:07:30,250 –> 00:07:32,680
آن تعداد را تغییر دهید و سپس به
173
00:07:32,680 –> 00:07:35,770
طور کلی چند نمونه
174
00:07:35,770 –> 00:07:37,210
جمعآوری میکنیم و من توضیح خواهم داد که چرا ما این کار را به صورت
175
00:07:37,210 –> 00:07:40,120
لحظه ای در اینجا انجام دادیم، فقط یک نمونه جمع آوری کردیم،
176
00:07:40,120 –> 00:07:42,069
اما برای
177
00:07:42,069 –> 00:07:43,389
درک قضیه حد مرکزی،
178
00:07:43,389 –> 00:07:45,729
باید نمونه های زیادی را محاسبه کنیم،
179
00:07:45,729 –> 00:07:49,270
بنابراین در داخل تابع
180
00:07:49,270 –> 00:07:51,310
، با یک لیست خالی شروع می کنیم. من آن را
181
00:07:51,310 –> 00:07:54,190
به معنای نمونه می نامم و سپس ما یک حلقه داریم
182
00:07:54,190 –> 00:07:56,680
که بر روی هر تعداد نمونه که قرار است گرفته شود تکرار
183
00:07:56,680 –> 00:07:59,680
می شود و سپس کاری که انجام می دهیم این
184
00:07:59,680 –> 00:08:03,940
است که دقیقاً مانند اینجا نمونه برداری می کنیم و
185
00:08:03,940 –> 00:08:06,580
از روش انتخاب تصادفی برای نمونه برداری
186
00:08:06,580 –> 00:08:09,460
بدون جایگزینی یک نمونه استفاده می کنیم.
187
00:08:09,460 –> 00:08:12,039
اندازه خاصی که ما می
188
00:08:12,039 –> 00:08:15,729
خواهیم و مشخص کرده ایم و به
189
00:08:15,729 –> 00:08:17,949
این ترتیب نمونه ما را به ما می دهد و سپس همانطور
190
00:08:17,949 –> 00:08:19,090
که در اینجا انجام دادیم
191
00:08:19,090 –> 00:08:21,490
میانگین را محاسبه می کنیم بنابراین من از
192
00:08:21,490 –> 00:08:23,020
روش میانگین آماری برای محاسبه میانگین نمونه استفاده می
193
00:08:23,020 –> 00:08:26,620
کنم و من معنی نمونه را به
194
00:08:26,620 –> 00:08:31,030
لیست معنیهای نمونهام در اینجا اضافه کنید، بنابراین این نشان
195
00:08:31,030 –> 00:08:32,979
میدهد که چند نمونه
196
00:08:32,979 –> 00:08:35,260
جمعآوری میکنیم که توسط










![فیلم آموزشی: K-Nearest Neighbors (KNN) به عنوان پایتون تک خطی [آموزش آسان] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/0WfWcf58qtUimage2.jpg)