در این مطلب، ویدئو مدل پیش بینی فروش با پایتون و Power BI با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:09:53
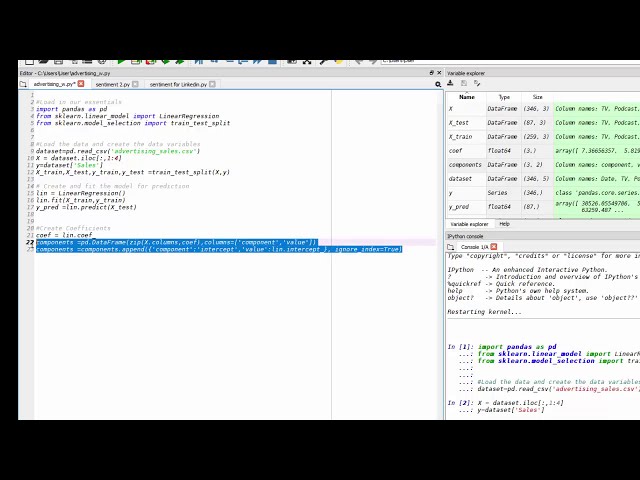
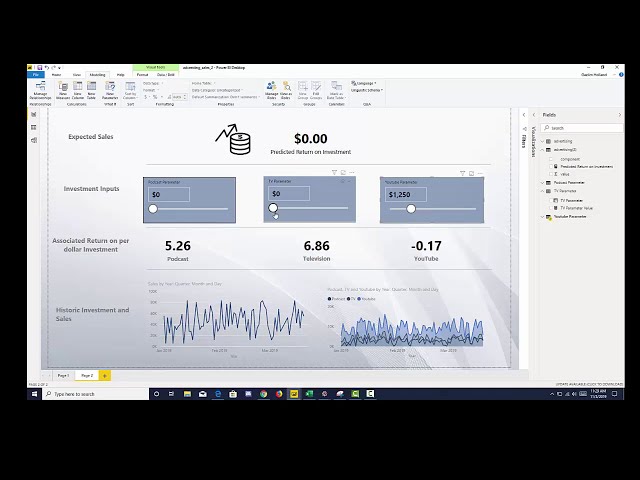
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,060 –> 00:00:02,370
ما میخواهیم یک
2
00:00:02,370 –> 00:00:05,690
مدل پیشبینی فروش با استفاده از
3
00:00:05,690 –> 00:00:10,040
رگرسیون خطی چندگانه و پایتون ایجاد کنیم و
4
00:00:10,040 –> 00:00:14,580
آن را در یک داشبورد تعاملی با استفاده از
5
00:00:14,580 –> 00:00:19,380
power bi تجسم کنیم، بنابراین بیایید شروع کنیم،
6
00:00:19,380 –> 00:00:20,939
در اینجا مجموعه دادهای از سه
7
00:00:20,939 –> 00:00:22,789
کانال بازاریابی مختلف با
8
00:00:22,789 –> 00:00:26,070
سرمایهگذاریهای متفاوت در هر کانال تلویزیون پادکست
9
00:00:26,070 –> 00:00:29,490
و YouTube داریم. و سپس یک
10
00:00:29,490 –> 00:00:33,090
کانال فروش داریم همچنین از
11
00:00:33,090 –> 00:00:38,420
رگرسیون دو برای انجام پیش بینی های خود استفاده می کنیم
12
00:00:38,420 –> 00:00:42,809
و برای انجام این کار باید این
13
00:00:42,809 –> 00:00:45,090
فرض را داشته باشیم که یک
14
00:00:45,090 –> 00:00:49,110
رابطه خطی بین متغیرهای X وجود دارد
15
00:00:49,110 –> 00:00:51,660
که در این حالت کانال های ما
16
00:00:51,660 –> 00:00:54,989
در بنابراین من این داده ها
17
00:00:54,989 –> 00:00:57,629
را در power bi بارگذاری کردم و به سرعت
18
00:00:57,629 –> 00:01:01,440
مجموعه ای از نمودارهای پراکندگی ایجاد کردم
19
00:01:01,440 –> 00:01:04,080
و می بینیم که یک
20
00:01:04,080 –> 00:01:07,350
رابطه خطی بین هر
21
00:01:07,350 –> 00:01:09,960
سه کانال وجود دارد و در نهایت می خواهیم
22
00:01:09,960 –> 00:01:14,340
بتوانیم از یک معادله استفاده کنیم. ما میخواهیم از
23
00:01:14,340 –> 00:01:19,650
متغیر x خود در اینجا استفاده کنیم که X است
24
00:01:19,650 –> 00:01:21,600
که هر یک از آن کانالها به
25
00:01:21,600 –> 00:01:26,070
اضافه ضریب برای پیشبینی فروش است، بنابراین
26
00:01:26,070 –> 00:01:30,390
بیایید مدل خود را ایجاد کنیم. مدل رگرسیون خطی
27
00:01:30,390 –> 00:01:32,729
در پایتون و آن
28
00:01:32,729 –> 00:01:36,030
ضرایب را جدا کنید تا بتوانیم این
29
00:01:36,030 –> 00:01:40,020
فرمول را تکمیل کنیم تا از یک IDE استفاده کنیم
30
00:01:40,020 –> 00:01:42,570
که در مورد من از
31
00:01:42,570 –> 00:01:44,520
عنکبوت استفاده می کنم ممکن است بخواهید از نوت بوک های مشتری استفاده کنید،
32
00:01:44,520 –> 00:01:47,939
بنابراین اجازه دهید آن را باز کنم و
33
00:01:47,939 –> 00:01:51,149
اجازه دهید کد را به شما معرفی کنم اولین
34
00:01:51,149 –> 00:01:52,890
کاری که میخواهیم انجام دهیم این است
35
00:01:52,890 –> 00:01:55,500
که بستههای ضروری خود را بارگیری میکنیم،
36
00:01:55,500 –> 00:01:57,570
پانداها را وارد کرده و آن را تحت
37
00:01:57,570 –> 00:02:00,180
متغیر PD ذخیره میکنیم، ما یک مدل رگرسیون خطی را از روانشناسی وارد میکنیم.
38
00:02:00,180 –> 00:02:04,290
و
39
00:02:04,290 –> 00:02:07,049
همچنین میخواهیم آزمایشهای قطار را
40
00:02:07,049 –> 00:02:11,068
تقسیم کنیم که به ما امکان میدهد یک مجموعه داده
41
00:02:11,068 –> 00:02:12,580
را به آموزش و
42
00:02:12,580 –> 00:02:15,940
سنتهایی که قرار است در دادههای خود بارگذاری کنیم
43
00:02:15,940 –> 00:02:19,990
با استفاده از تابع خواندن CSV از پانداها تقسیم کنیم،
44
00:02:19,990 –> 00:02:22,990
بنابراین اجازه دهید آن سلولها را برجسته کرده و
45
00:02:22,990 –> 00:02:27,220
اجرا کنیم و اگر شما به کاوشگر متغیر ما نگاه کنید
46
00:02:27,220 –> 00:02:29,470
، می بینیم که مجموعه داده های ما
47
00:02:29,470 –> 00:02:32,260
بارگذاری شده است و ما آن
48
00:02:32,260 –> 00:02:35,260
داده ها را در نام مجموعه داده ذخیره کرده ایم، بنابراین
49
00:02:35,260 –> 00:02:38,980
یک قاب داده با 364 سطر و پنج
50
00:02:38,980 –> 00:02:41,290
ستون داریم، اگر کلیک کنم، می توانید به راحتی
51
00:02:41,290 –> 00:02:46,450
داده های ما را ببینید. اکنون آنجا را تنظیم کنید زیرا ما نمی
52
00:02:46,450 –> 00:02:50,560
خواهیم t برای جداسازی متغیرهای x و y
53
00:02:50,560 –> 00:02:54,760
خود برای ایجاد فرمول نهایی
54
00:02:54,760 –> 00:02:58,740
X داریم که با
55
00:02:58,740 –> 00:03:02,380
استفاده از نمایه ستون با استفاده از
56
00:03:02,380 –> 00:03:04,240
تابع قفل چشم ایزوله میکنم، بنابراین
57
00:03:04,240 –> 00:03:07,510
تمام سطرهای نمایه ستون را میگیرم. 1 تا 4
58
00:03:07,510 –> 00:03:11,740
که همه کانالهای ما را محصور میکند و
59
00:03:11,740 –> 00:03:14,740
سپس من از نماد براکت
60
00:03:14,740 –> 00:03:18,220
روی آن متغیر مجموعه داده استفاده میکنم تا فقط
61
00:03:18,220 –> 00:03:22,260
فروش را نشان دهد، بنابراین بیایید آنها را روی
62
00:03:22,260 –> 00:03:25,030
آن متغیرهای جدیدی اجرا کنیم که در متغیر Explorer ما ایجاد شدهاند،
63
00:03:25,030 –> 00:03:30,670
حالا که
64
00:03:30,670 –> 00:03:32,769
x خود را داریم. و متغیر y ما می خواهیم بتوانیم
65
00:03:32,769 –> 00:03:36,700
مدل خود را روی مجموعه آموزشی از
66
00:03:36,700 –> 00:03:39,160
آن متغیرها آموزش دهیم و آن را روی
67
00:03:39,160 –> 00:03:41,200
مجموعه آزمایشی آن متغیر آزمایش کنیم، بنابراین من فقط
68
00:03:41,200 –> 00:03:43,690
از train برای تقسیم استفاده می
69
00:03:43,690 –> 00:03:47,320
کنم و این آموزش و تست های ما را به من می دهد. متغیرهای x و
70
00:03:47,320 –> 00:03:49,720
y و میتوانید آنهایی را که در اینجا فهرست شدهاند،
71
00:03:49,720 –> 00:03:52,890
ببینید اکنون که ما مؤلفههای اصلی خود
72
00:03:52,890 –> 00:03:55,989
را داریم که میخواهیم آن را در
73
00:03:55,989 –> 00:03:58,690
مدل رگرسیون خطی بارگذاری کنیم و آن را
74
00:03:58,690 –> 00:04:02,680
در Li n ذخیره کنیم، سپس
75
00:04:02,680 –> 00:04:07,570
دادههای آموزشی خود را با مدل خود تطبیق میدهیم.
76
00:04:07,570 –> 00:04:09,900
می تواند یاد بگیرد و سپس ما قصد داریم آن را
77
00:04:09,900 –> 00:04:15,660
آزمایش کنیم مدل e با مجموعه آزمایشی متغیرهای X ما،
78
00:04:15,660 –> 00:04:19,149
بنابراین بیایید آن بلوک
79
00:04:19,149 –> 00:04:23,800
کد را اجرا کنیم، پیشبینی خود را در اینجا داریم و اگر
80
00:04:23,800 –> 00:04:25,360
روی آن مقدار پیشبینی شده دوبار کلیک کنم،
81
00:04:25,360 –> 00:04:26,940
82
00:04:26,940 –> 00:04:29,790
اما برای تکمیل
83
00:04:29,790 –> 00:04:34,030
معادله ما باید ضرایب را
84
00:04:34,030 –> 00:04:37,960
اکنون که x خود را داریم به دست آوریم. و y و برای انجام
85
00:04:37,960 –> 00:04:40,090
این کار اکنون که مدل مورد آزمایش خود را آموزش داده
86
00:04:40,090 –> 00:04:43,840
ایم، می توانیم ضرایب را با
87
00:04:43,840 –> 00:04:50,500
استفاده از تابع co F در متغیر رگرسیون خطی خود بدست آوریم،
88
00:04:50,500 –> 00:04:54,340
بنابراین من به سرعت
89
00:04:54,340 –> 00:04:56,920
آن را اجرا می کنم و فقط به شما نشان می دهم چه چیزی
90
00:04:56,920 –> 00:05:00,310
برگردانده شده است تا بتوانید ببینید ما همه ضرایب را دریافت می کنیم،
91
00:05:00,310 –> 00:05:02,290
اما