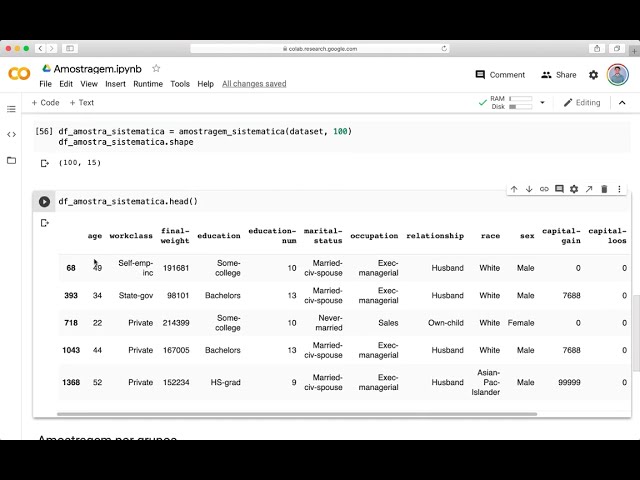
در این مطلب، ویدئو آموزش PyTorch 11 – Softmax و Cross Entropy با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:18:16
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:02,879
سلام به همه خوش آمدید به آموزش مشعل PI جدید،
2
00:00:02,879 –> 00:00:05,069
این بار در مورد
3
00:00:05,069 –> 00:00:07,020
تابع softmax و از
4
00:00:07,020 –> 00:00:09,330
دست دادن آنتروپی متقابل صحبت کردیم، اینها یکی از رایج ترین
5
00:00:09,330 –> 00:00:11,490
توابع مورد استفاده در شبکه های عصبی هستند،
6
00:00:11,490 –> 00:00:13,710
بنابراین باید بدانید که چگونه کار می کنند اکنون من
7
00:00:13,710 –> 00:00:15,540
به شما ریاضیات پشت سر آن را آموزش می دهم. این
8
00:00:15,540 –> 00:00:17,340
توابع و اینکه چگونه می توانیم از آنها در
9
00:00:17,340 –> 00:00:20,580
numpy و سپس PI مشعل استفاده کنیم و در پایان
10
00:00:20,580 –> 00:00:21,570
به شما نشان خواهم داد که یک
11
00:00:21,570 –> 00:00:23,880
نورون طبقه بندی معمولی که با آن توابع کار می کند چگونه به
12
00:00:23,880 –> 00:00:26,760
نظر می رسد بنابراین بیایید شروع کنیم
13
00:00:26,760 –> 00:00:30,439
و این فرمول softmax است
14
00:00:30,439 –> 00:00:33,480
بنابراین نمایی را اعمال می کند. تابع
15
00:00:33,480 –> 00:00:36,239
به هر عنصر و نرمال سازی آن با
16
00:00:36,239 –> 00:00:38,219
تقسیم بر مجموع این
17
00:00:38,219 –> 00:00:41,760
نمایی ها، بنابراین آنچه که انجام می دهد،
18
00:00:41,760 –> 00:00:44,280
اساساً خروجی را
19
00:00:44,280 –> 00:00:47,870
بین 0 و 1 له می کند، بنابراین احتمالات را بدست می آوریم،
20
00:00:47,870 –> 00:00:51,840
بنابراین بیایید به یک مثال نگاهی بیندازیم،
21
00:00:51,840 –> 00:00:55,350
فرض کنید یک لایه خطی داریم. که دارای 3
22
00:00:55,350 –> 00:00:58,590
مقدار خروجی است و این مقادیر به
23
00:00:58,590 –> 00:01:01,350
اصطلاح امتیاز یا همه لاجیت
24
00:01:01,350 –> 00:01:05,760
هستند پس مقادیر خام هستند و سپس softmax را اعمال می
25
00:01:05,760 –> 00:01:06,869
26
00:01:06,869 –> 00:01:11,130
کنیم و احتمالات را می گیریم بنابراین هر مقدار
27
00:01:11,130 –> 00:01:15,180
له می شود تا بین 0 باشد. و 1 و
28
00:01:15,180 –> 00:01:17,310
بالاترین مقدار در اینجا بالاترین
29
00:01:17,310 –> 00:01:21,360
احتمال را به دست میآورد و بله اگر این
30
00:01:21,360 –> 00:01:25,340
سه احتمال را جمع کنیم، 1 میگیریم
31
00:01:25,340 –> 00:01:29,070
و این پیشبینی ما است و سپس
32
00:01:29,070 –> 00:01:32,220
میتوانیم برای کلاسی با
33
00:01:32,220 –> 00:01:35,700
بالاترین احتمال انتخاب کنیم، بنابراین
34
00:01:35,700 –> 00:01:38,220
بله softmax اینطوری کار میکند و حالا بیایید
35
00:01:38,220 –> 00:01:40,880
به کد نگاهی بیندازیم، بنابراین در اینجا من قبلاً
36
00:01:40,880 –> 00:01:44,640
آن را در numpy پیادهسازی کردهام، بنابراین میتوانیم آن را
37
00:01:44,640 –> 00:01:48,030
در یک خط محاسبه کنیم، بنابراین ابتدا
38
00:01:48,030 –> 00:01:51,689
نمایی را داریم و سپس
39
00:01:51,689 –> 00:01:55,979
بر مجموع همه این نماییها تقسیم میکنیم
40
00:01:55,979 –> 00:02:01,710
و حالا بیایید این را اجرا کنیم این یکسان است.
41
00:02:01,710 –> 00:02:04,590
مقادیر مانند اسلاید من است و سپس در اینجا
42
00:02:04,590 –> 00:02:08,369
نیز می بینیم که بالاترین مقدار
43
00:02:08,369 –> 00:02:10,440
بالاترین logit بیشترین
44
00:02:10,440 –> 00:02:13,770
احتمال را در اطراف آن دارد سپس
45
00:02:13,770 –> 00:02:16,140
در اسلاید من بنابراین کمی متفاوت است
46
00:02:16,140 –> 00:02:18,420
اما اساساً می بینیم که درست است
47
00:02:18,420 –> 00:02:22,740
و البته می توانیم آن را در pi نیز محاسبه کنیم
48
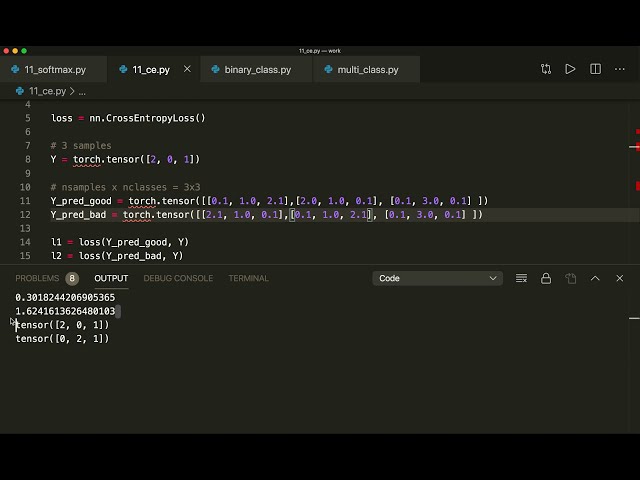
00:02:22,740 –> 00:02:26,160
. مشعل و برای این ما یک 10-0 ایجاد می کنیم،
49
00:02:26,160 –> 00:02:30,540
بنابراین فرض کنید x برابر است با تانسور نقطه مشعل
50
00:02:30,540 –> 00:02:34,560
و همان مقادیر را
51
00:02:34,560 –> 00:02:39,590
می گیرد و سپس می توانیم بگوییم خروجی
52
00:02:39,590 –> 00:02:43,650
برابر است با نقطه مشعل
53
00:02:43,650 –> 00:02:47,940
softmax X و همچنین باید
54
00:02:47,940 –> 00:02:52,050
کم نور را مشخص کنیم. بنابراین ما می گوییم dim برابر با صفر است، بنابراین
55
00:02:52,050 –> 00:02:56,040
آن را در امتداد محور اول محاسبه می کند و
56
00:02:56,040 –> 00:03:01,440
حالا اجازه دهید این خروجی ها را چاپ کنیم، بنابراین بله،
57
00:03:01,440 –> 00:03:03,840
در اینجا می بینیم که نتیجه
58
00:03:03,840 –> 00:03:08,280
تقریباً یکسان است، بنابراین این کار می کند و حالا اجازه دهید
59
00:03:08,280 –> 00:03:12,570
ادامه دهیم تا چندین بار تابع softmax
60
00:03:12,570 –> 00:03:15,480
ترکیب شود. با به اصطلاح
61
00:03:15,480 –> 00:03:19,740
از دست دادن آنتروپی متقاطع، بنابراین
62
00:03:19,740 –> 00:03:22,470
عملکرد مدل طبقهبندی ما را اندازهگیری میکند
63
00:03:22,470 –> 00:03:25,230
که خروجی آن احتمالی بین 0
64
00:03:25,230 –> 00:03:29,660
و 1 است و میتوان از آن در مسائل چند کلاسه
65
00:03:29,660 –> 00:03:34,590
استفاده کرد و با فاصله گرفتن
66
00:03:34,590 –> 00:03:37,320
احتمال پیشبینیشده از
67
00:03:37,320 –> 00:03:40,620
برچسب واقعی، ضرر افزایش مییابد.
68
00:03:40,620 –> 00:03:45,150
پیشبینی ما هرچه کمتر ضرر ما است، بنابراین در اینجا
69
00:03:45,150 –> 00:03:49,710
ما دو مثال داریم، بنابراین در اینجا این یک
70
00:03:49,710 –> 00:03:52,830
پیشبینی خوب است و سپس ما یک
71
00:03:52,830 –> 00:03:56,460
اتلاف آنتروپی متقاطع کم داریم و در اینجا این یک
72
00:03:56,460 –> 00:03:59,190
پیشبینی بد است و پس از آن ما یک
73
00:03:59,190 –> 00:04:03,300
اتلاف آنتروپی بالا داریم و آنچه را که باید نیز
74
00:04:03,300 –> 00:04:06,480
داشته باشیم. بدانید که در این مورد Y ما
75
00:04:06,480 –> 00:04:08,310
باید داغ باشد
76
00:04:08,310 –> 00:04:12,090
که یک کدگذاری داغ باشد، بنابراین فرض
77
00:04:12,090 –> 00:04:16,230
کنید سه کلاس ممکن داریم کلاس
78
00:04:16,230 –> 00:04:19,798
0 1 و 2 و در این مورد
79
00:04:19,798 –> 00:04:24,000
برچسب صحیح کلاس 0 است، بنابراین در اینجا باید قرار دهیم
80
00:04:24,000 –> 00:04:27,250
a 1 و برای همه کلاسهای دیگر
81
00:04:27,250 –> 00:04:30,040
یک صفر قرار میدهیم، بنابراین به این صورت است که یک کدگذاری داغ را انجام میدهیم
82
00:04:30,040 –> 00:04:34,270
و سپس برای پیشبینیشده چرا
83
00:04:34,270 –> 00:04:38,020
باید احتمالات داشته باشیم، به
84
00:04:38,020 –> 00:04:40,180
عنوان مثال، این softmax را قبلاً در اینجا اعمال میکنیم
85
00:04:40,180 –> 00:04:45,550
و بله، پس حالا دوباره
86
00:04:45,550 –> 00:04:48,010
بیایید نگاهی به کد چگونه این کار را در
87
00:04:48,010 –> 00:04:52,470
numpy انجام می دهیم تا بتوانیم آن را در اینجا محاسبه
88
00:04:52,470 –> 00:04:57,310
کنیم تا مجموع برچسب های واقعی
89
00:04:57,310 –> 00:05:01,690
ضربدر قفل برچسب های پیش بینی شده را
90
00:05:01,690 –> 00:05:05,230
داشته باشیم و سپس باید یک منفی را در
91
00:05:05,230 –> 00:05:10,360
ابتدا قرار دهیم و همچنین می توانیم آن را عادی سازی
92
00:05:10,360 –> 00:05:12,570
کنیم اما این کار را انجام نمی دهیم. این کار را در اینجا انجام ندهید تا بتوانیم
93
00:05:12,570 –> 00:05:17,280
آن را بر تعداد نمونه ها تقسیم کنیم و
94
00:05:17,280 –> 00:05:21,100
سپس Y خود را ایجاد می کنیم، بنابراین همانطور که گفتم این
95
00:05:21,100 –> 00:05:24,130
باید یک کدگذاری داغ باشد، بنابراین در اینجا
96
00:05:24,130 –> 00:05:27,640
مثال های دیگری داریم، بنابراین اگر کلاس
97
00:05:27,640 –> 00:05:29,980
یک است، باید به این شکل باشد. به عنوان مثال
98
00:05:29,980 –> 00:05:34,200
و سپس در اینجا دو پیشبینی خود را قرار میدهیم،
99
00:05:34,200 –> 00:05:36,450
بنابراین اینها اکنون
100
00:05:36,450 –> 00:05:40,210
احتمالات هستند، بنابراین اولی یک
101
00:05:40,210 –> 00:05:43,870
پیشبینی خوب دارد، زیرا در اینجا
102
00:05:43,870 –> 00:05:45,729
کلاس صفر بیشترین احتمال را دارد
103
00:05:45,729 –> 00:05:49,060
و پیشبینی دوم یک پیشبینی بد است،
104
00:05:49,060 –> 00:05:51,340
بنابراین در اینجا کلاس صفر
105
00:05:51,340 –> 00:05:55,000
احتمال بسیار پایینی دارد. و به علاوه دو o یک
106
00:05:55,000 –> 00:05:58,660
احتمال زیاد میشود و حالا
107
00:05:58,660 –> 00:06:01,090
آنتروپی را آنتروپی متقاطع محاسبه میکنم و
108
00:06:01,090 –> 00:06:04,510
هر دوی آنها را پیشبینی میکنم، بنابراین بیایید این را اجرا کنیم
109
00:06:04,510 –> 00:06:06,490
و در اینجا میبینیم که
110
00:06:06,490 –> 00:06:11,530
پیشبینی اول ضرر کم دارد و
111
00:06:11,530 –> 00:06:15,130
پیشبینی دوم ضرر زیاد دارد و حالا دوباره
112
00:06:15,130 –> 00:06:19,440
ببینیم چگونه ما میتوانیم این کار را در مشعل pi انجام دهیم،
113
00:06:19,440 –> 00:06:27,580
بنابراین برای این ابتدا اتلاف را ایجاد میکنیم، بنابراین
114
00:06:27,580 –> 00:06:32,080
میگوییم ضرر برابر است با n n از
115
00:06:32,080 –> 00:06:38,110
مشعل nura و n ماژول و n نقطه از
116
00:06:38,110 –> 00:06:40,220
دست دادن آنتروپی متقاطع
117
00:06:40,220 –> 00:06:44,240
و اکنون آنچه باید بدانیم بیایید
118
00:06:44,240 –> 00:06:47,660
دوباره به اسلایدها نگاهی بیندازیم. ما
119
00:06:47,660 –> 00:06:51,140
باید مراقب باشیم زیرا قوانین آنتروپی متقابل
120
00:06:51,140 –> 00:06:55,820
قبلاً softmax قفل
121
00:06:55,820 –> 00:06:58,940
و سپس تلفات احتمال لاگ منفی را اعمال می کند
122
00:06:58,940 –> 00:07:02,960
بنابراین ما نباید یا نباید
123
00:07:02,960 –> 00:07:05,240
لایه softmax را برای خودمان پیاده سازی
124
00:07:05,240 –> 00:07:08,840
کنیم بنابراین این اولین چیزی است که
125
00:07:08,840 –> 00:07:11,240
باید بدانیم و دومین چیز این است که که
126
00:07:11,240 –> 00:07:17,630
در اینجا Y ما نباید یک کدگذاری داغ باشد،
127
00:07:17,630 –> 00:07:20,360
بنابراین ما باید فقط برچسب کلاس صحیح را
128
00:07:20,360 –> 00:07:26,540
در اینجا قرار دهیم و همچنین پیشبینیهای Y را
129
00:07:26,540 –> 00:07:32,390
و دارای امتیازات خام است، بنابراین در اینجا هیچ نرمافزاری وجود ندارد، بنابراین
130
00:07:32,390 –> 00:07:35,930
مراقب این موضوع باشید و حالا بیایید
131
00:07:35,930 –> 00:07:39,290
این را در عمل ببینیم، پس بیایید بگوییم بیایید
132
00:07:39,290 –> 00:07:43,070
برچسب های واقعی ما را ایجاد کنید و این یک
133
00:07:43,070 –> 00:07:47,120
تانسور نقطه مشعل است و اکنون در اینجا فقط
134
00:07:47,120 –> 00:07:50,330
برچسب کلاس صحیح را قرار می دهیم، بنابراین بیایید بگوییم
135
00:07:50,330 –> 00:07:54,530
در این مورد کلاس صفر است و
136
00:07:54,530 –> 00:07:58,040
دیگر کدگذاری یک داغ نیست و سپس یک
137
00:07:58,040 –> 00:08:03,640
پیش بینی خوب داریم Y پیش بینی خوب برابر با
138
00:08:03,640 –> 00:08:08,750
ده ها نقطه مشعل است. یا و سپس در اینجا باید
139
00:08:08,750 –> 00:08:12,590
مراقب اندازه باشیم، بنابراین
140
00:08:12,590 –> 00:08:18,410
تعداد نمونه ها برابر
141
00:08:18,410 –> 00:08:22,370
تعداد کلاس ها است، بنابراین فرض کنید در
142
00:08:22,370 –> 00:08:25,490
مورد ما یک نمونه و سه
143
00:08:25,490 –> 00:08:29,620
کلاس ممکن داریم، بنابراین این آرایه ای از
144
00:08:29,620 –> 00:08:38,020
آرایه ها است و در اینجا ما قرار می دهیم 2.0 1.0 و
145
00:08:38,020 –> 00:08:43,250
0.1 و به یاد داشته باشید و اینها
146
00:08:43,250 –> 00:08:45,290
مقادیر خام هستند، بنابراین ما softmax را اعمال نکردیم
147
00:08:45,290 –> 00:08:51,650
و در اینجا بالاترین یا
148
00:08:51,650 –> 00:08:53,990
کلاس صفر بالاترین
149
00:08:53,990 –> 00:08:56,180
مقدار را دارد، بنابراین این یک پیش بینی خوب است و
150
00:08:56,180 –> 00:08:59,600
حالا بیایید یک پیش
151
00:08:59,600 –> 00:09:03,170
بینی بد انجام دهیم، بنابراین پیش بینی بد است. بنابراین در اینجا همان
152
0