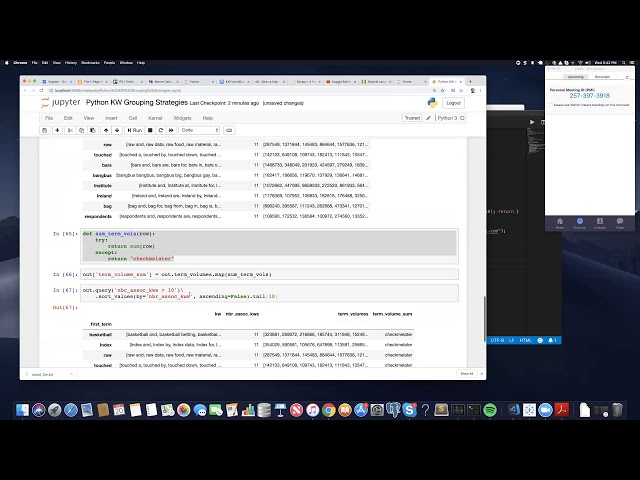
در این مطلب، ویدئو تجزیه و تحلیل داده های اکتشافی در پایتون با استفاده از پانداها با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:28:51
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:02,190
2
00:00:02,190 –> 00:00:04,950
اگر تازه وارد هستید به کانال یوتیوب پروفسور داده بازگردید، نام من
3
00:00:04,950 –> 00:00:07,379
تیم در حالت غیر سنا است و من دانشیار بیوانفورماتیک هستم
4
00:00:07,379 –> 00:00:08,849
5
00:00:08,849 –> 00:00:11,610
و این کانال یوتیوب ما در مورد
6
00:00:11,610 –> 00:00:14,309
مفاهیم علم داده و
7
00:00:14,309 –> 00:00:16,710
آموزش های عملی پوشش می دهیم، بنابراین اگر به این موضوع علاقه دارید نوع
8
00:00:16,710 –> 00:00:20,390
محتوا لطفاً اشتراک
9
00:00:21,500 –> 00:00:24,380
پیش پردازش داده ها و متخصص یا
10
00:00:24,380 –> 00:00:26,449
تجزیه و تحلیل داده را در نظر بگیرید که برای
11
00:00:26,449 –> 00:00:29,029
موفقیت هر پروژه علم داده بسیار مهم است،
12
00:00:29,029 –> 00:00:30,739
بنابراین در این ویدیو به شما نشان خواهم داد که
13
00:00:30,739 –> 00:00:33,290
چگونه پیش پردازش
14
00:00:33,290 –> 00:00:36,019
داده ها و تجزیه و تحلیل اکتشافی داده ها را انجام دهید. در پایتون
15
00:00:36,019 –> 00:00:38,570
با استفاده از کتابخانه پانداها به طوری که بتوانید
16
00:00:38,570 –> 00:00:40,820
پروژه های علم داده خود را انجام دهید، بنابراین
17
00:00:40,820 –> 00:00:44,109
بدون هیچ مقدمه ای بیایید شروع کنیم
18
00:00:44,109 –> 00:00:46,300
بسیار خوب، بنابراین اولین کاری که می خواهید
19
00:00:46,300 –> 00:00:48,429
انجام دهید این است که به github
20
00:00:48,429 –> 00:00:52,179
پروفسور داده بروید و روی مخزن کد کلیک کنید و به
21
00:00:52,179 –> 00:00:59,050
پایین بروید. روی پایتون پایین کلیک کنید
22
00:00:59,050 –> 00:01:01,870
و پانداها را پیدا کنید تجزیه و تحلیل داده های Expo Tori
23
00:01:01,870 –> 00:01:05,430
روی آن کلیک
24
00:01:05,430 –> 00:01:07,170
کنید و سپس می خواهید
25
00:01:07,170 –> 00:01:09,000
روی دکمه دانلود کلیک راست کرده و
26
00:01:09,000 –> 00:01:12,960
لینک را ذخیره کنید و آن را در رایانه خود ذخیره کنید.
27
00:01:12,960 –> 00:01:14,960
28
00:01:14,960 –> 00:01:16,370
سپس می توانید
29
00:01:16,370 –> 00:01:17,750
نوت بوک مشتری را در رایانه خود باز کنید و آن را دنبال کنید
30
00:01:17,750 –> 00:01:20,330
یا می توانید به Google collab بروید
31
00:01:20,330 –> 00:01:23,450
و ما می توانیم آن را مستقیماً از github بارگیری کنیم،
32
00:01:23,450 –> 00:01:26,990
بنابراین روی زبانه github برای جستجوی داده ها کلیک کنید تا
33
00:01:26,990 –> 00:01:32,979
استاد وارد شوید و سپس
34
00:01:32,979 –> 00:01:36,920
پانداها را که از قبل صادر می شوند پیدا کنید تجزیه و تحلیل داده ها خوب است.
35
00:01:36,920 –> 00:01:39,590
اما از آنجایی که من قبلاً آن را دارم، آن را باز میکنم،
36
00:01:39,590 –> 00:01:42,159
37
00:01:42,799 –> 00:01:45,740
و سپس قبل از شروع به من اجازه
38
00:01:45,740 –> 00:01:47,899
دهید همه خروجیها را پاک کنم تا بتوانیم
39
00:01:47,899 –> 00:01:50,450
با هم از ابتدا شروع کنیم، بنابراین
40
00:01:50,450 –> 00:01:51,950
دادههایی که در این
41
00:01:51,950 –> 00:01:54,590
آموزش استفاده میکنیم مبتنی بر آن باشد. در یکی
42
00:01:54,590 –> 00:01:57,020
از ویدیوهای قبلی که در آن از
43
00:01:57,020 –> 00:01:59,990
دادههای آمار بازیکنان NBA استفاده کردهایم که مستقیماً
44
00:01:59,990 –> 00:02:02,810
از وبسایت کام مرجع بسکتبال خراشیده شده است
45
00:02:02,810 –> 00:02:04,880
و بنابراین خواهید دید
46
00:02:04,880 –> 00:02:06,530
که کد درست اینجا در اولین
47
00:02:06,530 –> 00:02:10,549
بلوک کد است، بنابراین اجازه دهید آن را اجرا کنیم و به همین
48
00:02:10,549 –> 00:02:12,739
ترتیب اساساً این کار را انجام می دهد این است که
49
00:02:12,739 –> 00:02:14,989
تانداها را وارد می کند و سپس از
50
00:02:14,989 –> 00:02:18,530
پانداها برای خواندن محتویات در یک
51
00:02:18,530 –> 00:02:20,810
متغیر داده استفاده می کند که به موجب آن محتوا یک
52
00:02:20,810 –> 00:02:22,459
جدول داده خواهد بود و سپس
53
00:02:22,459 –> 00:02:24,890
با حذف موارد اضافی، پاکسازی اولیه داده ها را انجام می دهیم.
54
00:02:24,890 –> 00:02:26,840
t هدر رول هایی که
55
00:02:26,840 –> 00:02:29,000
بیش از یک بار در محتوای
56
00:02:29,000 –> 00:02:31,069
جدول فشار می آورند و به همین ترتیب در آموزش قبلی نشان داده شده است،
57
00:02:31,069 –> 00:02:33,290
بنابراین اگر هنوز
58
00:02:33,290 –> 00:02:34,910
آن را تماشا نکرده اید، لطفاً روی پیوند بالا کلیک کنید
59
00:02:34,910 –> 00:02:41,870
خوب است و بنابراین خواهید دید که
60
00:02:41,870 –> 00:02:44,810
هدر حاوی چند نام اختصاری و
61
00:02:44,810 –> 00:02:46,690
اگر با آن آشنا نیستید
62
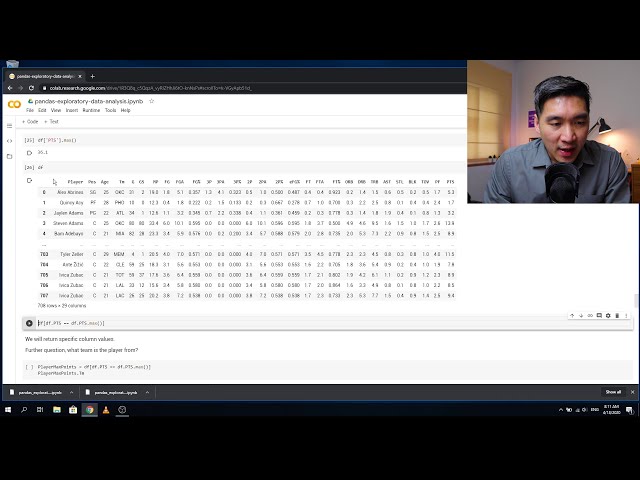
00:02:46,690 –> 00:02:49,340
در بلوک متن زیر در این جدول خلاصه شده است که در
63
00:02:49,340 –> 00:02:51,410
آن
64
00:02:51,410 –> 00:02:53,239
مخفف با توضیحات درست دنبال می شود،
65
00:02:53,239 –> 00:02:56,660
بنابراین K ما رتبه POS
66
00:02:56,660 –> 00:02:59,660
موقعیت است، بنابراین H سن بازیکنان در
67
00:02:59,660 –> 00:03:02,510
فوریه است. 1 فصل و
68
00:03:02,510 –> 00:03:05,209
نام تیم تعداد بازیهای انجام شده
69
00:03:05,209 –> 00:03:07,760
در دقیقههای انجام شده در هر بازی بسیار خوب است
70
00:03:07,760 –> 00:03:10,040
و بنابراین امروز ما
71
00:03:10,040 –> 00:03:12,530
از نظر تجزیه و تحلیل دادههای اکسپو توری نگاهی عمیقتر به آن
72
00:03:12,530 –> 00:03:14,420
خواهیم داشت و بنابراین از مقدار زیادی استفاده خواهیم کرد.
73
00:03:14,420 –> 00:03:16,940
از پانداها برای بازیابی
74
00:03:16,940 –> 00:03:19,220
دادههایی که میخواهیم به آنها نگاهی بیندازیم و
75
00:03:19,220 –> 00:03:21,739
همچنین جهان، چند نمودار اصلی و مثبت
76
00:03:21,739 –> 00:03:25,970
در اینجا درست میکند، بنابراین
77
00:03:25,970 –> 00:03:27,710
بیایید نگاهی به اینجا بیندازیم تا همانطور که قبلاً اشاره کردم
78
00:03:27,710 –> 00:03:30,050
این بلوک کد
79
00:03:30,050 –> 00:03:32,000
دادهها را مستقیماً از کد حذف کند. بسکتبال
80
00:03:32,000 –> 00:03:34,280
دوباره وبسایت مرجع و دادههای جدول
81
00:03:34,280 –> 00:03:36,740
در قاب دادهای به نام
82
00:03:36,740 –> 00:03:39,620
DF 2019 درست قرار داده میشوند و سپس
83
00:03:39,620 –> 00:03:41,990
همه سرصفحههایی را که اضافی هستند حذف میکنیم
84
00:03:41,990 –> 00:03:44,150
و سپس در
85
00:03:44,150 –> 00:03:47,570
متغیر خام قرار میگیرند و اجازه دهید به شکل نگاهی بیندازیم.
86
00:03:47,570 –> 00:03:51,230
از دادهها، بنابراین دارای 708
87
00:03:51,230 –> 00:03:54,540
ردیف و 30 ستون است،
88
00:03:54,540 –> 00:03:56,580
بیایید نگاهی به چند رول اول بیندازیم،
89
00:03:56,580 –> 00:03:59,489
بنابراین اساساً اینجاست، بیایید
90
00:03:59,489 –> 00:04:02,099
با استفاده از تابع اتانول مقادیر گمشده را بررسی
91
00:04:02,099 –> 00:04:03,599
کنیم و سپس
92
00:04:03,599 –> 00:04:05,940
جمعبندی چند مقدار از دست رفته را انجام میدهیم.
93
00:04:05,940 –> 00:04:07,530
می بینیم که چند
94
00:04:07,530 –> 00:04:12,299
مقدار از دست رفته در اینجا وجود دارد و بیایید
95
00:04:12,299 –> 00:04:14,280
بگوییم که همه
96
00:04:14,280 –> 00:04:16,579
مقدار از دست رفته را با یک عدد صفر جایگزین می کنیم و
97
00:04:16,579 –> 00:04:18,930
سپس دوباره مقدار موسیقی را بررسی می
98
00:04:18,930 –> 00:04:21,449
کنیم و خواهیم دید که ما
99
00:04:21,449 –> 00:04:23,340
قبلاً مشکل مقدار گمشده را
100
00:04:23,340 –> 00:04:26,190
در اینجا حل کردهایم و سپس رتبه
101
00:04:26,190 –> 00:04:27,720
در حال حاضر چیزی به ما نمیگوید، بنابراین ما فقط
102
00:04:27,720 –> 00:04:30,270
با انداختن ستون آن را حذف میکنیم
103
00:04:30,270 –> 00:04:32,729
و سپس میبینیم که اکنون ستون رتبه
104
00:04:32,729 –> 00:04:35,789
حذف شده است و دادههای جدول را
105
00:04:35,789 –> 00:04:38,729
در اینجا داریم. به نام DF بنابراین اجازه دهید این را در یک
106
00:04:38,729 –> 00:04:42,000
فایل CSV بنویسید و بنابراین ما DF را تایپ می کنیم
107
00:04:42,000 –> 00:04:44,010
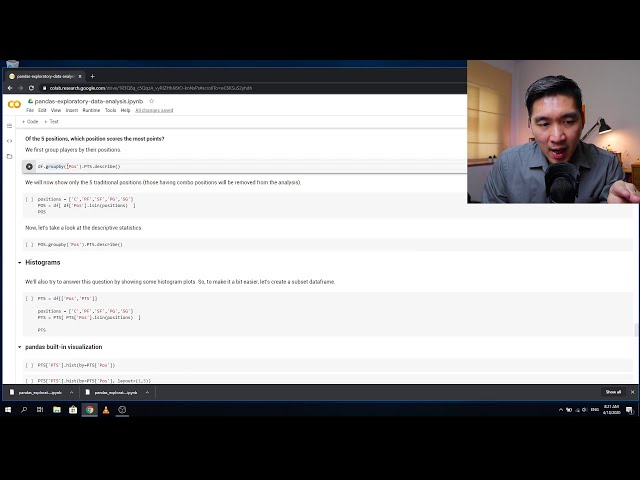
که نامی حاوی جدول و
108
00:04:44,010 –> 00:04:47,130
نقطه – تابع csv است و سپس
109
00:04:47,130 –> 00:04:50,460
آن را و BA 2019 dot csv را فراخوانی می کنیم تا آن را
110
00:04:50,460 –> 00:04:52,530
بنویسیم. یک فایل csv و سپس
111
00:04:52,530 –> 00:04:54,690
ما ایندکس برابر با false
112
00:04:54,690 –> 00:04:56,490
خواهیم داشت زیرا نمیخواهیم ایندکس
113
00:04:56,490 –> 00:04:58,800
نوشته شود و بنابراین بیایید فایل را بنویسیم
114
00:04:58,800 –> 00:05:01,800
و به همین ترتیب LS بررسی کنیم که آیا فایل
115
00:05:01,800 –> 00:05:04,919
ایجاد شده است و درست اینجا NBA 2019 است
116
00:05:04,919 –> 00:05:06,510
و سپس اجازه دهید به طور خلاصه به
117
00:05:06,510 –> 00:05:08,610
محتویات فایل در bash نگاهی بیندازیم و
118
00:05:08,610 –> 00:05:12,360
بنابراین محتوا در اینجا به عنوان یک فایل csv خوب است
119
00:05:12,360 –> 00:05:13,919
و بنابراین ما میخواهیم دادهها را مجدداً بخوانیم
120
00:05:13,919 –> 00:05:15,370
121
00:05:15,370 –> 00:05:18,430
و سپس دوباره آن را به قاب داده DF اختصاص دهیم.
122
00:05:18,430 –> 00:05:20,889
در عوض دادهها
123
00:05:20,889 –> 00:05:24,040
دقیقاً در اینجا هستند، بسیار تمیز به نظر میرسند و حالا
124
00:05:24,040 –> 00:05:26,290
بیایید بگوییم که شما این را میدانید که
125
00:05:26,290 –> 00:05:29,440
فقط ده رول
126
00:05:29,440 –> 00:05:31,240
قاب داده شما را نمایش میدهد، بنابراین
127
00:05:31,240 –> 00:05:33,669
پنج عدد اول و پنج داده پایین را نشان میدهد
128
00:05:33,669 –> 00:05:35,290
، فرض کنید میخواهید مشاهده
129
00:05:35,290 –> 00:05:37,840
کل محتوا همه رول ها
130
00:05:37,840 –> 00:05:40,000
امکان پذیر است، بله، می توانید این کار را با استفاده از
131
00:05:40,000 –> 00:05:42,310
گزینه تنظیم انجام دهید، بنابراین بروید تبلیغ کنید و آن را اجرا کنید و
132
00:05:42,310 –> 00:05:45,280
سپس دوباره دیتا فریم را اجرا کنید و اکنون
133
00:05:45,280 –> 00:05:48,160
تمام داده های کل
134
00:05:48,160 –> 00:05:50,410
قاب داده را لیست می کند، بنابراین در صورتی
135
00:05:50,410 –> 00:05:52,479
که بخواهید همه بازیکنان را ببینید
136
00:05:52,479 –> 00:05:55,330
و انجام آن در داخل امکان پذیر نباشد، وجود دارد.
137
00:05:55,330 –> 00:05:57,400
نوت بوک را رایت کنید، بنابراین اکنون
138
00:05:57,400 –> 00:06:00,220
میتوانید این گزینه را در اینجا تنظیم کنید و فرض
139
00:06:00,220 –> 00:06:02,950
کنید نمیخواهید این قاب داده طولانی
140
00:06:02,950 –> 00:06:05,650
را داشته باشید، فقط میتوانید آن را
141
00:06:05,650 –> 00:06:08,200
به گزینه پیشفرض با تنظیم برگردانید و
142
00:06:08,200 –> 00:06:11,860
نقش اصلی را روی ده تنظیم کنید، خوب اجازه دهید
143
00:06:11,860 –> 00:06:13,270
دوباره به قاب داده نگاهی بیندازید و
144
00:06:13,270 –> 00:06:15,460
بنابراین درست مانند قبل به نظر می رسد که
145
00:06:15,460 –> 00:06:17,380
پنج مورد اول و پنج پایینی
146
00:06:17,380 –> 00:06:18,940
قاب داده را کاملاً درست
147
00:06:18,940 –> 00:06:20,710
می بینید، بنابراین بیایید نگاهی به
148
00:06:20,710 –> 00:06:24,720
نوع داده هر ستون از قاب داده خود
149
00:06:24,720 –> 00:06:27,180
بیندازیم و بنابراین ما میبینیم که بازیکنان
150
00:06:27,180 –> 00:06:29,880
موقعیت اشیاء ما یک تیم
151
00:06:29,880 –> 00:06:32,160
شی است و بقیه یا اعداد صحیح هستند
152
00:06:32,160 –> 00:06:36,630
یا اعداد شناور هستند، بنابراین فرض
153
00:06:36,630 –> 00:06:38,700
میکنیم که میخواهیم نوع داده خاصی را
154
00:06:38,700 –> 00:06:41,340
در قاب داده خود نشان دهیم تا بتوانیم از
155
00:06:41,340 –> 00:06:44,610
نوع Select D استفاده کنیم. تابع و شامل برابر
156
00:06:44,610 –> 00:06:46,530
با نوع داده ای است که ما w
157
00:06:46,530 –> 00:06:48,690
بنابراین اگر بخواهیم همه
158
00:06:48,690 –> 00:06:51,090
اعداد را نشان دهیم شامل اعداد صحیح و
159
00:06:51,090 –> 00:06:53,220
شناور می شود، می خواهیم از
160
00:06:53,220 –> 00:06:55,920
آرگومان include برابر با دو عدد در اینجا استفاده کنیم
161
00:06:55,920 –> 00:06:58,860
و بنابراین فقط اعداد را می بینیم
162
00:06:58,860 –> 00:07:02,400
یا اگر می خواهیم فقط نشان دهیم سپس اشیاء
163
00:07:02,400 –> 00:07:04,290
در آرگومان مورد استفاده
164
00:07:04,290 –> 00:07:07,500
شامل شیء okay است و فقط شیء را نشان میدهد
165
00:07:07,500 –> 00:07:09,420
که نام بازیکن است
166
00:07:09,420 –> 00:07:13,170
، موقعیت و تیم اوکی است و بنابراین
167
00:07:13,170 –> 00:07:14,460
وقتی در حال انجام
168
00:07:14,460 –> 00:07:17,280
تجزیه و تحلیل دادههای انقضا هستیم قبل از اینکه به همه توابع شیرجه بزنیم.
169
00:07:17,280 –> 00:07:19,800
دستوراتی که به شما امکان می دهد
170
00:07:19,800 –> 00:07:22,110
تجزیه و تحلیل داده های متخصص را انجام دهید که
171
00:07:22,110 –> 00:07:24,090
ممکن است کمی خسته کننده یا طولانی باشد،
172
00:07:24,090 –> 00:07:26,340
بنابراین چرا روی قسمت جلویی تمرکز نمی کنیم،
173
00:07:26,340 –> 00:07:28,470
اجازه دهید چند سوال بپرسیم و ببینیم
174
00:07:28,470 –> 00:07:31,410
کدام دستورات می توانند به ما کمک کنند تا به سؤالات خود پاسخ مناسبی بدهیم.
175
00:07:31,410 –> 00:07:34,770
من قصد دارم
176
00:07:34,770 –> 00:07:37,470
این را در عناوین مختلفی که
177
00:07:37,470 –> 00:07:39,570
بعد از آن در اینجا به شما نشان خواهم داد گروه بندی کنم، بنابراین اولین
178
00:07:39,570 –> 00:07:42,419
مفهوم در اینجا انتخاب شرطی است، بنابراین
179
00:07:42,419 –> 00:07:44,550
بیایید بگوییم که می خواهیم
180
00:07:44,550 –> 00:07:47,040
ردیف ها یا ستون های خاصی را در مجموعه داده نشان دهیم که
181
00:07:47,040 –> 00:07:49,919
با شرایط خاص ما مطابقت دارد. خوب است،
182
00:07:49,919 –> 00:07:51,660
پس بیایید نشان دهیم که با اولین
183
00:07:51,660 –> 00:07:54,840
مثال خود خوب است، بنابراین کدام بازیکن
184
00:07:54,840 –> 00:07:56,790
بیشترین امتیاز را در هر بازی به دست آورده است، بیایید ببینیم چگونه
185
00:07:56,790 –> 00:08:00,300
می توانیم این کار را انجام دهیم، بنابراین امتیازها امتیاز ستون
186
00:08:00,300 –> 00:08:02,850
و امتیاز در اینجا باشد، اجازه دهید نگاهی به
187
00:08:02,850 –> 00:08:09,810
معنی داشته باشیم بنابراین امتیاز به معنای امتیاز در هر بازی است.
188
00:08:09,810 –> 00:08:11,910
در بسکتبال تعداد امتیازهایی است
189
00:08:11,910 –> 00:08:14,160
که بازیکن در یک بازی معین
190
00:08:14,160 –> 00:08:17,010
به دست می آورد، بنابراین میانگین امتیازاتی است که در
191
00:08:17,010 –> 00:08:19,710
هر بازی به دست می آید، بنابراین با
192
00:08:19,710 –> 00:08:21,360
گرفتن تمام امتیازهایی که بازیکن
193
00:08:21,360 –> 00:08:23,910
در طول فصل جمع کرده است تقسیم
194
00:08:23,910 –> 00:08:25,620
بر تعداد بازی ها محاسبه می شود. که بازیکن
195
00:08:25,620 –> 00:08:28,260
بازی می کند و به این ترتیب امتیازات در هر
196
00:08:28,260 –> 00:08:30,810
بازی بسیار خوب است و در ستون امتیازها خواهد بود،
197
00:08:30,810 –> 00:08:33,900
پس بیایید دوباره به سوال نگاهی بیندازیم،
198
00:08:33,900 –> 00:08:35,220
199
00:08:35,220 –> 00:08:37,710
بنابراین این سوال می پرسد که کدام بازیکن
200
00:08:37,710 –> 00:08:39,690
بیشترین امتیاز را در هر بازی به دست آورده است و می بینیم
201
00:08:39,690 –> 00:08:42,510
که در حدود 700 بازیکن در قاب داده وجود
202
00:08:42,510 –> 00:08:44,490
دارد و بنابراین برای
203
00:08:44,490 –> 00:08:46,770
اینکه بفهمیم کدام بازیکن بیشترین امتیاز را به دست آورده است باید
204
00:08:46,770 –> 00:08:49,860
از تابع ma X استفاده کنیم
205
00:08:49,860 –> 00:08:53,220
که حداکثر مقدار را برای متغیر داده شده به ما می گوید،
206
00:08:53,220 –> 00:08:57,870
بنابراین برای انتخاب pts ستون
207
00:08:57,870 –> 00:09:01,290
از آن طرف. m در قاب داده DF ما از DF pts استفاده خواهیم کرد
208
00:09:01,290 –> 00:09:05,130
که یک راه دیگر این است
209
00:09:05,130 –> 00:09:11,280
که از pts نقل قول براکت DF استفاده کنیم بنابراین
210
00:09:11,280 –> 00:09:13,650
این انتخاب ستون خاص
211
00:09:13,650 –> 00:09:16,920
است و برای بدست آوردن حداکثر مقدار
212
00:09:16,920 –> 00:09:20,760
دوباره از تابع max استفاده می کنیم که نشان
213
00:09:20,760 –> 00:09:23,490
می دهد شما 36.1 اما نام بازیکن را به شما نمی گوید
214
00:09:23,490 –> 00:09:26,370
اوکی است، بنابراین در هر
215
00:09:26,370 –> 00:09:28,650
صورت پاسخ یکسان خواهد بود، بنابراین
216
00:09:28,650 –> 00:09:30,690
سی و شش امتیاز یک است، بنابراین
217
00:09:30,690 –> 00:09:32,820
سوال بعدی این است که کدام بازیکن سی و
218
00:09:32,820 –> 00:09:35,070
شش امتیاز یک خوب می گیرد و آن بازیکن همان بازیکن
219
00:09:35,070 –> 00:09:37,320
خواهد بود. به سوال ما
220
00:09:37,320 –> 00:09:39,930
دقیقاً در اینجا پاسخ دهید و بنابراین ما باید از این
221
00:09:39,930 –> 00:09:42,300
چیزی به نام انتخاب شرطی استفاده کنیم، بنابراین ما
222
00:09:42,300 –> 00:09:44,610
قبلاً می دانیم که پاسخ 36
223
00:09:44,610 –> 00:09:47,760
نقطه یک خوب است و بنابراین توجه کنید که این
224
00:09:47,760 –> 00:09:50,550
بلوک کد در اینجا اساساً درست
225
00:09:50,550 –> 00:09:53,760
در اینجا خوب است بنابراین هنگامی که ما آن را تایپ می کنیم
226
00:09:53,760 –> 00:09:56,760
قاب داده DF همه
227
00:09:56,760 –> 00:10:00,360
بازیکنان را خوب نمایش می دهد و اگر بگویم DF یک
228
00:10:00,360 –> 00:10:03,570
ستون خاص، مقادیر آن ستون را نشان می دهد،
229
00:10:03,570 –> 00:10:05,910
بنابراین برای
230
00:10:05,910 –> 00:10:08,070
اینکه بازیکنی را که بیشترین
231
00:10:08,070 –> 00:10:11,070
امتیاز را کسب می کند نشان دهیم باید در DF براکت باز DF تایپ کنیم.
232
00:10:11,070 –> 00:10:14,310
امتیاز و سپس دو علامت مساوی
233
00:10:14,310 –> 00:10:18,300
و به دنبال آن DF امتیاز حداکثر و در
234
00:10:18,300 –> 00:10:20,370
پرانتز باز و بسته و
235
00:10:20,370 –> 00:10:22,710
در براکت بسته
236
00:10:22,710 –> 00:10:25,200
و به ما نشان می دهد که جیمز هاردن
237
00:10:25,200 –> 00:10:27,240
از هیوستون راکتس با
238
00:10:27,240 –> 00:10:29,460
موقعیت یک گارد
239
00:10:29,460 –> 00:10:32,670
پوینت بیشترین امتیاز را در امتیاز 36 کسب می کند.
240
00:10:32,670 –> 00:10:35,700
فرد نقش ها را در کل
241
00:10:35,700 –> 00:10:37,680
نقش نمایش می دهد، بنابراین نام بازیکن به
242
00:10:37,680 –> 00:10:40,110
همراه تمام داده هایی
243
00:10:40,110 –> 00:10:42,150
که با این بازیکن مرتبط است، اما
244
00:10:42,150 –> 00:10:43,950
فرض کنید که می خواهیم
245
00:10:43,950 –> 00:10:46,500
مقادیر خاصی را در این مورد برگردانیم، فرض کنید می خواهیم
246
00:10:46,500 –> 00:10:48,900
تیم را بشناسیم. چگونه میخواهیم
247
00:10:48,900 –> 00:10:51,270
نام تیم را برگردانیم، بنابراین
248
00:10:51,270 –> 00:10:53,250
این کار را با کپی کردن این بلوک
249
00:10:53,250 –> 00:10:55,020
کد در اینجا انجام میدهیم و سپس آن را
250
00:10:55,020 –> 00:10:57,240
به متغیر دادهای به نام
251
00:10:57,240 –> 00:10:59,430
نقاط نقشه بازیکن اختصاص میدهیم تا ظاهر آن را
252
00:10:59,430 –> 00:11:02,040
سادهتر کنیم. کمی کد کنید و سپس
253
00:11:02,040 –> 00:11:04,050
دوباره نقاط نقشه بازیکن را صدا می
254
00:11:04,050 –> 00:11:06,480
زنیم و سپس از نقطه TM استفاده می کنیم زیرا
255
00:11:06,480 –> 00:11:08,970
ستونی به نام TM را انتخاب می کنیم
256
00:11:08,970 –> 00:11:11,280
که تیم است خوب اجازه دهید این را اجرا
257
00:11:11,280 –> 00:11:13,710
کنیم و می بینیم که تیم Hou است.
258
00:11:13,710 –> 00:11:16,170
پس این سنگ هیوستون است ets و بنابراین
259
00:11:16,170 –> 00:11:19,140
بازیکنی که در حال بازی کردن است در کدام موقعیت قرار دارد، بنابراین
260
00:11:19,140 –> 00:11:23,070
ما فقط ستون POS را انتخاب می کنیم
261
00:11:23,070 –> 00:11:27,370
و بنابراین موقعیت به صورت پیتی گارد
262
00:11:27,370 –> 00:11:30,010
263
00:11:30,010 –> 00:11:34,110
264
00:11:34,110 –> 00:11:37,330
است. پاسخ اول برای
265
00:11:37,330 –> 00:11:39,520
سوال اول بسیار خوب است، پس حالا بیایید
266
00:11:39,520 –> 00:11:41,500
به سوال دوم برویم، بنابراین بیایید بگوییم که
267
00:11:41,500 –> 00:11:43,750
می خواهیم بدانیم کدام بازیکن بیش
268
00:11:43,750 –> 00:11:45,730
از 20 امتیاز در هر بازی کسب کرده است، بنابراین
269
00:11:45,730 –> 00:11:47,920
سوال اول این بود که کدام بازیکن تک
270
00:11:47,920 –> 00:11:50,020
نفره بیشترین امتیاز را در بازی کسب کرده است. بازی
271
00:11:50,020 –> 00:11:52,690
و این یکی خواهد بود که کدام بازیکن
272
00:11:52,690 –> 00:11:54,910
در هر بازی بیش از 20 امتیاز کسب کند و بنابراین
273
00:11:54,910 –> 00:11:56,410
ما بازیکنان زیادی را
274
00:11:56,410 –> 00:11:58,780
در اینجا بازیابی می کنیم و بنابراین شرط در اینجا
275
00:11:58,780 –> 00:12:02,590
امتیاز DF بزرگتر از 20 خواهد بود که
276
00:12:02,590 –> 00:12:04,990
شرط است و ما این را به عنوان شرط قرار می دهیم.
277
00:12:04,990 –> 00:12:07,390
آرگومان در انتخاب ستون
278
00:12:07,390 –> 00:12:09,400
خوب است، بنابراین در داخل براکت
279
00:12:09,400 –> 00:12:12,370
شرط است و براکت DF به این معنی است که
280
00:12:12,370 –> 00:12:15,640
میخواهیم رولهای حاوی شرط داده شده را انتخاب
281
00:12:15,640 –> 00:12:18,850
کنیم که امتیاز DF بزرگتر از
282
00:12:18,850 –> 00:12:21,190
20 است، بنابراین در اینجا
283
00:12:21,190 –> 00:12:23,710
نام همه بازیکنان را در کنار آن بازیابی میکنیم. با
284
00:12:23,710 –> 00:12:26,200
داده های Associated که بیش از
285
00:12:26,200 –> 00:12:29,470
20 امتیاز کسب می کند، بسیار خوب است، بنابراین رول ها جایی هستند
286
00:12:29,470 –> 00:12:31,420
که بازیکن در هر بازی بیش از 20 امتیاز کسب
287
00:12:31,420 –> 00:12:33,610
می کند و بنابراین خواهید دید
288
00:12:33,610 –> 00:12:35,290
که اطلاعات میانی در اینجا وجود ندارد،
289
00:12:35,290 –> 00:12:37,360
بنابراین اگر می خواهید آن را نشان دهید، می توانید به بالا بروید.
290
00:12:37,360 –> 00:12:39,640
و کد مربوط به گزینههای تنظیم را پیدا کنید و
291
00:12:39,640 –> 00:12:41,950
سپس میتوانید آن را اجرا کنید، اما
292
00:12:41,950 –> 00:12:43,420
اکنون به سؤال بعدی میرویم،
293
00:12:43,420 –> 00:12:46,600
بنابراین سؤال بعدی این است که کدام
294
00:12:46,600 –> 00:12:48,820
بازیکن بیشترین گلهای سه امتیازی را در هر
295
00:12:48,820 –> 00:12:51,820
بازی داشته است و این ستون 3p خواهد بود. نام
296
00:12:51,820 –> 00:12:54,490
و بنابراین مثل همیشه از DF
297
00:12:54,490 –> 00:12:56,530
و سپس براکت استفاده می کنیم و در داخل
298
00:12:56,530 –> 00:12:58,480
آرگومان براکت
299
00:12:58,480 –> 00:13:03,910
از DF 3 P برابر با 3 f 3 P max استفاده
300
00:13:03,910 –> 00:13:05,860
می کنیم تا حداکثر مقدار 3p را به شما بدهد.
301
00:13:05,860 –> 00:13:07,990
ستون و سپس
302
00:13:07,990 –> 00:13:11,110
رول های مطابق با آن شرایط را برمی گرداند
303
00:13:11,110 –> 00:13:13,779
و بنابراین استفن کری پاسخی است
304
00:13:13,779 –> 00:13:16,810
که به موجب آن او به طور متوسط 5 امتیاز در هر
305
00:13:16,810 –> 00:13:19,240
306
00:13:19,240 –> 00:13:21,610
307
00:13:21,610 –> 00:13:24,130
ازی به ثمر می رساند. ast
308
00:13:24,130 –> 00:13:27,100
است و بنابراین همان
309
00:13:27,100 –> 00:13:29,350
con در اینجا ما از DF استفاده می کنیم و
310
00:13:29,350 –> 00:13:31,750
در براکت و داخل به عنوان آرگومان
311
00:13:31,750 –> 00:13:35,050
از DF ast برابر با DF
312
00:13:35,050 –> 00:13:39,310
ast max استفاده می کنیم، بسیار خوب است و راسل وستبروک را برمی گرداند
313
00:13:39,310 –> 00:13:42,370
که در آن
314
00:13:42,370 –> 00:13:44,769
نقطه ده نقطه هفت KS sis از ده نقطه دارد.
315
00:13:44,769 –> 00:13:46,230
هفت
316
00:13:46,230 –> 00:13:48,480
بسیار خوب و بنابراین چندین
317
00:13:48,480 –> 00:13:50,460
سؤال بعدی استفاده از مفهوم گروه به
318
00:13:50,460 –> 00:13:52,680
تابع است، بنابراین سؤال اینجاست
319
00:13:52,680 –> 00:13:55,290
که کدام بازیکن بالاترین امتیاز را
320
00:13:55,290 –> 00:13:57,780
از لس آنجلس لیکرز کسب کرده است، بنابراین
321
00:13:57,780 –> 00:14:00,060
بیایید به طور متوالی نگاهی بیندازیم که
322
00:14:00,060 –> 00:14:02,580
این بلوک کد ابتدا این کار را انجام می دهد.
323
00:14:02,580 –> 00:14:05,190
متغیری به نام Lal را اختصاص
324
00:14:05,190 –> 00:14:07,770
325
00:14:07,770 –> 00:14:09,690
میدهیم و محتوا از فریم دادههای DF استفاده میکند و دادهها را
326
00:14:09,690 –> 00:14:11,640
گروهبندی میکند و بعد از گروهبندی دادهها توسط تیم،
327
00:14:11,640 –> 00:14:14,100
تیم خاصی را که
328
00:14:14,100 –> 00:14:16,590
میخواهیم انتخاب میکند که لسآنجلس لیکرز و
329
00:14:16,590 –> 00:14:19,740
غیره است. بیایید این کد را اجرا کنیم و نگاهی بیندازیم
330
00:14:19,740 –> 00:14:24,090
و بنابراین همانطور که در ستون تیم می بینید
331
00:14:24,090 –> 00:14:26,310
همه بازیکنان اینجا از
332
00:14:26,310 –> 00:14:29,190
لس آنجلس لیکرز هستند و 22 رول وجود دارد
333
00:14:29,190 –> 00:14:31,740
خوب است و بعد غذای
334
00:14:31,740 –> 00:14:35,190
ستون ها نشان داده می شود ، بنابراین اگر ما تغییر دهیم. al
335
00:14:35,190 –> 00:14:36,120
به som چیزهای
336
00:14:36,120 –> 00:14:40,140
دیگر تیم درست تغییر می کند خوب ببینید
337
00:14:40,140 –> 00:14:43,520
و تیم به اوکی تغییر می کند ببینید خوب است
338
00:14:43,520 –> 00:14:47,300
بیایید آن را به Lal تغییر دهیم بسیار
339
00:14:47,300 –> 00:14:49,820
خوب و این پاسخ است و بنابراین
340
00:14:49,820 –> 00:14:51,890
بیایید به سؤال بعدی از موقعیت پنج گانه برویم
341
00:14:51,890