در این مطلب، ویدئو جیل کیتس – چگونه یک مدل تشخیصی بالینی در پایتون بسازیم – PyCon 2019 با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:25:07
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,199 –> 00:00:04,200
سلام و خوش آمدید به جلسه امروز بعدازظهر
2
00:00:04,200 –> 00:00:06,120
که در واقع
3
00:00:06,120 –> 00:00:09,360
آخرین جلسه امروز است در اینجا و اکنون ما به
4
00:00:09,360 –> 00:00:12,240
شما گوش می دهیم کیت
5
00:00:12,240 –> 00:00:14,700
چگونه یک مدل تشخیصی بالینی
6
00:00:14,700 –> 00:00:17,190
با استفاده از پایتون باشد، در این
7
00:00:17,190 –> 00:00:20,850
ارائه تعدادی پرسش و پاسخ وجود دارد، اما او
8
00:00:20,850 –> 00:00:22,410
در دسترس خواهد بود. در راهرو برای هر گونه
9
00:00:22,410 –> 00:00:24,449
سوالی که بعد از صحبت دارید
10
00:00:24,449 –> 00:00:26,519
، بیایید به آن
11
00:00:26,519 –> 00:00:35,430
تشویق کنیم تا این کار را انجام دهیم با تشکر سلام به
12
00:00:35,430 –> 00:00:38,070
همه، نام من جیل کیت است و من یک
13
00:00:38,070 –> 00:00:39,680
دانشمند داده در شرکتی به نام
14
00:00:39,680 –> 00:00:42,750
بیومتریک در تورنتو کانادا هستم.
15
00:00:42,750 –> 00:00:44,640
اولین باری که در اولین PyCon خود در کلیولند هستم،
16
00:00:44,640 –> 00:00:46,649
بنابراین واقعاً از حضور در اینجا هیجان زده
17
00:00:46,649 –> 00:00:49,590
هستم.
18
00:00:49,590 –> 00:00:51,480
19
00:00:51,480 –> 00:00:54,719
20
00:00:54,719 –> 00:00:58,050
21
00:00:58,050 –> 00:01:00,629
تعریف رسمی تشخیص،
22
00:01:00,629 –> 00:01:02,399
فرآیند تعیین بیماری یا
23
00:01:02,399 –> 00:01:05,369
شرایطی است که در زیربنای
24
00:01:05,369 –> 00:01:08,580
علائم یا نشانههای فرد مستلزم
25
00:01:08,580 –> 00:01:10,619
دانش تخصصی پزشک و سالها
26
00:01:10,619 –> 00:01:13,229
آموزش پزشکی است. برای آنها
27
00:01:13,229 –> 00:01:15,750
تمام دادههای بیمار را ارزیابی کنند و
28
00:01:15,750 –> 00:01:17,700
تصمیمی آگاهانه در مورد آنچه
29
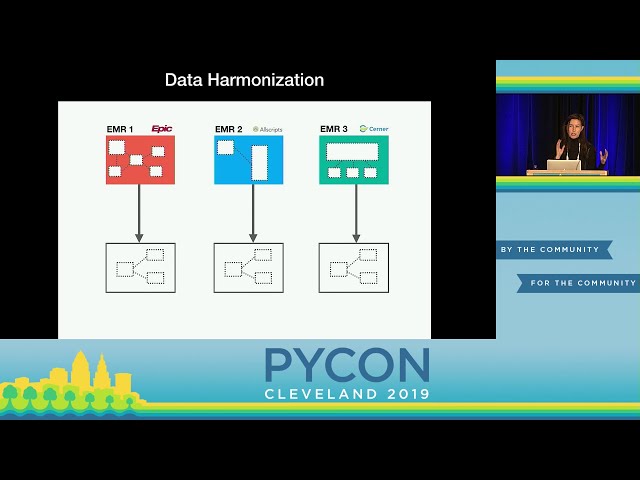
00:01:17,700 –> 00:01:21,390
بیمار قبل از اقدام به درمان
30
00:01:21,390 –> 00:01:23,430
دارد بگیرند، اما اگر بتوانیم این
31
00:01:23,430 –> 00:01:25,500
فرآیند پیچیده تصمیمگیری را با استفاده از یک
32
00:01:25,500 –> 00:01:29,040
مدل یادگیری ماشین تکرار کنیم، تلاشهای اخیر و
33
00:01:29,040 –> 00:01:30,479
یادگیری ماشینی بر
34
00:01:30,479 –> 00:01:32,520
ساخت ابزارهایی مانند این متمرکز شده است. برای تریاژ
35
00:01:32,520 –> 00:01:34,680
خطر کمتر در مقابل بیماران پرخطر
36
00:01:34,680 –> 00:01:38,189
شناسایی زودرس بیماری و همچنین
37
00:01:38,189 –> 00:01:40,470
کاهش خطر تشخیص اشتباه با
38
00:01:40,470 –> 00:01:42,360
هدف نهایی بهبود ایمنی بیمار،
39
00:01:42,360 –> 00:01:45,090
بنابراین مدل های تشخیصی می توانند در زمان و هزینه صرفه جویی کنند و
40
00:01:45,090 –> 00:01:47,939
به پزشکان اجازه دهند تا
41
00:01:47,939 –> 00:01:52,500
بیماران بیشتری را در محل کار ببینند و درمان کنند.
42
00:01:52,500 –> 00:01:54,180
ما مدل تشخیصی بالینی خود را خواهیم ساخت
43
00:01:54,180 –> 00:01:57,000
و از سپسیس به
44
00:01:57,000 –> 00:01:58,950
عنوان مطالعه موردی خود استفاده خواهیم کرد، زیرا این یک بیماری بسیار
45
00:01:58,950 –> 00:02:01,500
گران قیمت و کشنده است که
46
00:02:01,500 –> 00:02:03,600
در صورت شناسایی زودهنگام می تواند با پیش آگهی خوبی درمان شود،
47
00:02:03,600 –> 00:02:09,000
بنابراین
48
00:02:09,000 –> 00:02:10,459
آنچه سپسیس
49
00:02:10,459 –> 00:02:12,560
سپسیس است یک زندگی است- وضعیت تهدید کننده
50
00:02:12,560 –> 00:02:14,719
ناشی از پاسخ بدن به
51
00:02:14,719 –> 00:02:17,299
عفونت معمولاً ناشی از یک پاسخ
52
00:02:17,299 –> 00:02:20,840
التهابی و ایمنی است و می
53
00:02:20,840 –> 00:02:23,629
تواند توسط ذات الریه ایجاد شود. آنفولانزا یا
54
00:02:23,629 –> 00:02:27,889
حتی سپسیس جوش عفونی یکی
55
00:02:27,889 –> 00:02:29,930
از دلایل اصلی مرگ در بخش مراقبت های
56
00:02:29,930 –> 00:02:32,540
ویژه است و از
57
00:02:32,540 –> 00:02:34,909
هر سه مرگ بیمارستانی یک نفر را به همراه دارد، بسیار
58
00:02:34,909 –> 00:02:38,180
گران است و هزینه آن حدود 20.3
59
00:02:38,180 –> 00:02:40,819
میلیون دلار در سال است و همچنین
60
00:02:40,819 –> 00:02:43,519
زمان بسیار زیادی است. حساس است، بنابراین هر ساعت بدون
61
00:02:43,519 –> 00:02:45,889
درمان، خطر
62
00:02:45,889 –> 00:02:48,439
مرگ بیمار را چهار تا هشت درصد افزایش میدهد، بنابراین
63
00:02:48,439 –> 00:02:51,680
تشخیص سریع سپسیس میتواند
64
00:02:51,680 –> 00:02:53,680
جان انسانها را نجات
65
00:02:53,680 –> 00:02:57,139
دهد که گفته میشود مراحل اولیه سپسیس
66
00:02:57,139 –> 00:02:59,419
میتواند دشوار باشد و در حالی
67
00:02:59,419 –> 00:03:01,669
که برخی عوامل خطر برای سپسیس وجود دارد،
68
00:03:01,669 –> 00:03:03,319
بسیار دشوار است. در این مطالعه موردی، برای اینکه یک پزشک
69
00:03:03,319 –> 00:03:05,659
پیشبینی کند که چه کسی پس از پذیرش گرفتار سپسیس میشود و چه کسی پسیس نمیشود
70
00:03:05,659 –> 00:03:09,409
71
00:03:09,409 –> 00:03:11,629
، مدلی پیشنهاد کردیم که
72
00:03:11,629 –> 00:03:13,400
احتمال ابتلای بیمار به سپسیس
73
00:03:13,400 –> 00:03:15,109
را در طول اقامت در بخش مراقبتهای
74
00:03:15,109 –> 00:03:19,220
ویژه پیشبینی میکند، اگر بتوانیم به طور قابل اعتماد تشخیص دهیم که کدام
75
00:03:19,220 –> 00:03:20,930
بیماران در معرض خطر بالاتری هستند. در مقابل
76
00:03:20,930 –> 00:03:22,699
کم خطر، امید این است که این
77
00:03:22,699 –> 00:03:24,049
پزشکان بتوانند تصمیمات آگاهانه تری
78
00:03:24,049 –> 00:03:30,560
در عمل خود بگیرند
79
00:03:30,560 –> 00:03:32,810
. اگر خط لوله ما را
80
00:03:32,810 –> 00:03:34,790
می توان به سه بخش تقسیم کرد، بنابراین
81
00:03:34,790 –> 00:03:38,090
ما مدل سازی داده های آماده سازی داده ها
82
00:03:38,090 –> 00:03:41,299
و پس پردازش نتایج را داریم، بخش بزرگی
83
00:03:41,299 –> 00:03:43,099
از این گفتگو بر
84
00:03:43,099 –> 00:03:45,590
روی پیش پردازش داده ها متمرکز خواهد شد زیرا
85
00:03:45,590 –> 00:03:49,609
داده های پزشکی بسیار کثیف هستند، زیرا احتمالاً برخی از شما
86
00:03:49,609 –> 00:03:51,620
قبلاً میدانستید که دادههای مراقبتهای بهداشتی
87
00:03:51,620 –> 00:03:53,540
به دلیل تکه تکه بودن و غیرمتمرکز بودن شناخته
88
00:03:53,540 –> 00:03:55,819
شدهاند، صدها
89
00:03:55,819 –> 00:03:57,859
سیستم پرونده الکترونیکی پزشکی در
90
00:03:57,859 –> 00:03:59,900
آنجا وجود دارد و در حالی که همه این سیستمها
91
00:03:59,900 –> 00:04:02,810
نوع مشابهی از دادهها را ذخیره میکنند،
92
00:04:02,810 –> 00:04:04,819
رابطها و طرحوارههای دادهشان میتواند
93
00:04:04,819 –> 00:04:06,680
بسیار دشوار یا بسیار
94
00:04:06,680 –> 00:04:10,489
متفاوت باشد تا همه چیز را یکنواخت کند.
95
00:04:10,489 –> 00:04:13,099
پروندههای پزشکی الکترونیکی پیچیدهتر
96
00:04:13,099 –> 00:04:15,439
حاوی انواع دادههای متفاوت از جمله
97
00:04:15,439 –> 00:04:18,259
متن بدون ساختار از یادداشتهای بالینی ۲ بعدی
98
00:04:18,259 –> 00:04:21,108
و ۳ بعدی سیگنالهای سری زمانی تصاویر پزشکی
99
00:04:21,108 –> 00:04:23,510
مانند EEG و ECG
100
00:04:23,510 –> 00:04:28,550
و همچنین دادههای ژنومی هستند که این
101
00:04:28,550 –> 00:04:30,800
اختلافات در EMR باید
102
00:04:30,800 –> 00:04:33,740
مراقبت شود و میتوان از آنها مراقبت کرد.
103
00:04:33,740 –> 00:04:35,300
از طریق فرآیندی به نام هماهنگ سازی داده ها،
104
00:04:35,300 –> 00:04:39,500
بنابراین هماهنگ سازی داده ها
105
00:04:39,500 –> 00:04:42,290
شامل نقشه برداری از داده های مختلف EMR است
106
00:04:42,290 –> 00:04:47,030
در قالب یک داده مشترک
107
00:04:47,030 –> 00:04:48,590
، چند مدل داده مختلف
108
00:04:48,590 –> 00:04:52,580
وجود دارد، اما یک مدل بسیار محبوب
109
00:04:52,580 –> 00:04:54,920
OMA p است – مدل داده رایج
110
00:04:54,920 –> 00:04:56,690
که توسط یک گروه بین المللی از
111
00:04:56,690 –> 00:05:00,680
محققان به نام ohd SI یا Odyssey the
112
00:05:00,680 –> 00:05:03,350
Omaha mall از پیش تعریف شده ساخته شده است. طرحواره
113
00:05:03,350 –> 00:05:06,080
با مجموعه ای از جداول داده استاندارد شده و در
114
00:05:06,080 –> 00:05:08,120
حال حاضر برای هماهنگ کردن همه
115
00:05:08,120 –> 00:05:12,580
داده ها در بیمارستان های UC در کالیفرنیا استفاده می شود.
116
00:05:12,580 –> 00:05:15,920
این کل فرآیندی که قبل از
117
00:05:15,920 –> 00:05:18,440
خط لوله انجام می شود ETL نامیده می شود یا
118
00:05:18,440 –> 00:05:21,110
بار تبدیل را استخراج می کنیم زیرا ما
119
00:05:21,110 –> 00:05:23,630
داده ها را از منبع آن استخراج می کنیم و آن را به یک معمول تبدیل می کنیم.
120
00:05:23,630 –> 00:05:25,970
فرمت داده و سپس ما
121
00:05:25,970 –> 00:05:27,770
آن را در یک پایگاه داده متمرکز تمیز بارگذاری می
122
00:05:27,770 –> 00:05:33,260
کنیم و اکنون که
123
00:05:33,260 –> 00:05:35,510
همه داده های خود را در یک مکان داریم می
124
00:05:35,510 –> 00:05:37,460
توانیم پاکسازی داده های خود را شروع کنیم.
125
00:05:37,460 –> 00:05:40,100
در این راهنما دو نوع پاکسازی داده را پوشش خواهیم داد،
126
00:05:40,100 –> 00:05:42,110
بنابراین اولین مورد:
127
00:05:42,110 –> 00:05:44,570
برای رسیدگی به مقادیر از دست رفته و مورد
128
00:05:44,570 –> 00:05:47,210
دوم استانداردسازی ناسازگاری ها و
129
00:05:47,210 –> 00:05:51,320
اصطلاحات پزشکی برای ارزیابی مقدار مقادیر از
130
00:05:51,320 –> 00:05:53,360
دست رفته در مجموعه داده های ما است، می
131
00:05:53,360 –> 00:05:55,550
توانیم از بسته ای به نام missin استفاده کنیم. gno که
132
00:05:55,550 –> 00:05:57,260
به شما یک نمای بزرگ از اینکه کدام
133
00:05:57,260 –> 00:05:59,300
ویژگیها پراکنده هستند در مقابل کدام
134
00:05:59,300 –> 00:06:02,360
ویژگیهای سرعت متراکم هستند، به شما میدهد، بنابراین همانطور که در
135
00:06:02,360 –> 00:06:04,670
این شکل مشاهده میکنید، ستونهای بیرونی بسیار
136
00:06:04,670 –> 00:06:06,860
متراکم هستند در حالی که ستونهای داخلی بسیار
137
00:06:06,860 –> 00:06:08,360
پراکنده هستند، به این معنی که مقادیر زیادی
138
00:06:08,360 –> 00:06:12,020
از دست رفته هستند.
139
00:06:12,020 –> 00:06:14,270
راههای مختلفی برای مدیریت مقادیر گمشده وجود
140
00:06:14,270 –> 00:06:17,450
دارد که میتوانیم حذف مورد یا
141
00:06:17,450 –> 00:06:21,440
نوعی از انتساب را انجام دهیم، اما برای
142
00:06:21,440 –> 00:06:23,480
اینکه بتوانیم روش انتساب درست را انتخاب
143
00:06:23,480 –> 00:06:25,880
کنیم، ابتدا باید مکانیسم فقدان دادهها را شناسایی کنیم،
144
00:06:25,880 –> 00:06:30,830
بنابراین
145
00:06:30,830 –> 00:06:32,830
سه مکانیسم ممکن وجود دارد. آشفتگی
146
00:06:32,830 –> 00:06:35,930
مکانیسم اول به طور کامل از دست رفته است
147
00:06:35,930 –> 00:06:36,980
148
00:06:36,980 –> 00:06:39,950
و در این شرایط هیچ دلیلی
149
00:06:39,950 –> 00:06:41,480
برای از دست دادن داده ها وجود ندارد، این فقط
150
00:06:41,480 –> 00:06:44,210
کاملا تصادفی است، یک مثال از این
151
00:06:44,210 –> 00:06:45,800
زمانی است که پرستار فراموش می کند
152
00:06:45,800 –> 00:06:48,980
فشار خون بیمار را ثبت کند،
153
00:06:48,980 –> 00:06:51,250
مکانیسم دوم به صورت تصادفی گم شده نامیده
154
00:06:51,250 –> 00:06:54,020
می شود. تفاوت بین
155
00:06:54,020 –> 00:06:56,300
فشار خون از دست رفته و مشاهده شده وجود داشته باشد، اما
156
00:06:56,300 –> 00:06:57,890
این تفاوت ها را می توان از طریق
157
00:06:57,890 –> 00:07:01,790
متغیرهای دیگری مانند جنس سن یا بیمار توضیح داد.
158
00:07:01,790 –> 00:07:04,520
تاریخچه بیماری قلبی عروقی است، بنابراین در
159
00:07:04,520 –> 00:07:06,740
این مثال، بیماران جوانتر بدون
160
00:07:06,740 –> 00:07:09,080
خطر بیماری قلبی عروقی تمایل
161
00:07:09,080 –> 00:07:11,180
دارند فشار خون خود را از دست بدهند و
162
00:07:11,180 –> 00:07:12,830
فشار خون پایینتری نسبت به
163
00:07:12,830 –> 00:07:14,900
بیماران مسنتر مبتلا به بیماری قلبی عروقی دارند،
164
00:07:14,900 –> 00:07:17,510
بنابراین دادههای اینجا وجود
165
00:07:17,510 –> 00:07:20,300
ندارد و مشروط به سن و سال است. آیا
166
00:07:20,300 –> 00:07:21,770
بیمار مبتلا به بیماری قلبی عروقی است یا خیر
167
00:07:21,770 –> 00:07:25,640
، مکانیسم سوم گم شدن نامیده می شود،
168
00:07:25,640 –> 00:07:28,280
نه به طور تصادفی، یعنی زمانی
169
00:07:28,280 –> 00:07:30,170
که تفاوت هایی بین
170
00:07:30,170 –> 00:07:32,030
فشار خون از دست رفته و مشاهده شده وجود دارد،
171
00:07:32,030 –> 00:07:34,490
حتی زمانی که همه متغیرهای دیگر
172
00:07:34,490 –> 00:07:37,750
در جمعیت بیمار
173
00:07:38,710 –> 00:07:41,150
یک راه برای مقابله با داده ها به حساب می آیند. مواردی که به
174
00:07:41,150 –> 00:07:43,490
طور تصادفی گم شده اند این است که فقط
175
00:07:43,490 –> 00:07:46,010
تمام مشاهدات را با مقدار گم شده رها کنید،
176
00:07:46,010 –> 00:07:48,740
بنابراین می توانید این کار را با استفاده از روش pandas
177
00:07:48,740 –> 00:07:52,640
drop n/a انجام دهید، اگر با
178
00:07:52,640 –> 00:07:54,680
داده های سری زمانی سروکار دارید، می توانید از
179
00:07:54,680 –> 00:07:57,730
رویکرد آخرین مقدار منتقل شده
180
00:07:57,730 –> 00:08:00,170
در جایی که اساسا پر کردن
181
00:08:00,170 –> 00:08:01,940
مقادیر از دست رفته با آخرین مقادیر مشاهده
182
00:08:01,940 –> 00:08:04,880
شده، پانداها نیز برای این کار روشی دارند
183
00:08:04,880 –> 00:08:10,340
و به آن fill na th می گویند. از آنجا
184
00:08:10,340 –> 00:08:12,380
که روشهای قویتری برای مدیریت مقادیر گمشده وجود
185
00:08:12,380 –> 00:08:14,930
دارد، میتوانید از بستهای به نام
186
00:08:14,930 –> 00:08:17,210
انباشت فانتزی برای اجرای
187
00:08:17,210 –> 00:08:19,010
روشهای انتساب استاندارد مانند k نزدیکترین
188
00:08:19,010 –> 00:08:21,460
همسایهها و
189
00:08:21,460 –> 00:08:24,230
مدلهای پشتههای فاکتورسازی ماتریسی استفاده کنید، همچنین یک روش انتساب دارد
190
00:08:24,230 –> 00:08:26,840
که به شما امکان میدهد تکنیکهایی
191
00:08:26,840 –> 00:08:29,060
مانند انتساب چندگانه بیزی و
192
00:08:29,060 –> 00:08:31,100
موشها را اجرا کنید. برای
193
00:08:31,100 –> 00:08:33,610
انتساب چندگانه با معادلات زنجیره ای و
194
00:08:33,610 –> 00:08:36,260
اینها بسیار قوی تر از
195
00:08:36,260 –> 00:08:41,450
نمونه های قبلی هستند که نشان دادم بخش بسیار
196
00:08:41,450 –> 00:08:43,429
مهمی از تمیز کردن داده های بیمار
197
00:08:43,429 –> 00:08:45,800
استاندارد کردن تمام اصطلاحات پزشکی است
198
00:08:45,800 –> 00:08:48,890
که هر پزشک نام خود را دارد که
199
00:08:48,890 –> 00:08:49,860
می تواند
200
00:08:49,860 –> 00:08:51,870
هنگام نوشتن داروهای تجویزی
201
00:08:51,870 –> 00:08:54,839
و تشخیص به آن اشاره کند. پزشکان می
202
00:08:54,839 –> 00:08:57,149
نویسند برخی از پزشکان تیلنول می نویسند در حالی که
203
00:08:57,149 –> 00:08:59,220
پزشکان دیگر استومینوفن را می نویسند، اما
204
00:08:59,220 –> 00:09:02,000
اینها اساساً همان داروی
205
00:09:02,000 –> 00:09:04,470
سالین نجیب وریدی هستند که
206
00:09:04,470 –> 00:09:07,170
معمولاً به بیماران در ICU داده می شود اما برخی از
207
00:09:07,170 –> 00:09:09,360
یادداشت ها n را نشان می دهند که مخفف یک نرمال
208
00:09:09,360 –> 00:09:12,300
سالین است در حالی که برخی دیگر می گویند 0.9٪
209
00:09:12,300 –> 00:09:14,040
کلرید سدیم که اساساً حاوی کلرید سدیم است.
210
00:09:14,040 –> 00:09:17,760
همین یک مثال دیگر مورفین است که
211
00:09:17,760 –> 00:09:19,890
در این جدول در اینجا مشاهده می کنیم،
212
00:09:19,890 –> 00:09:21,779
همه این تغییرات مختلف برای
213
00:09:21,779 –> 00:09:23,399
توصیف مورفین وجود دارد، بنابراین می توانید بگویید
214
00:09:23,399 –> 00:09:26,490
مورفین سولفات مورفین مورفین تمام
215
00:09:26,490 –> 00:09:29,310
کلاهک ها و به عنوان بخشی از پیش پردازش
216
00:09:29,310 –> 00:09:31,560
ما باید همه این
217
00:09:31,560 –> 00:09:37,230
نام های دارو را به داروی رایج استاندارد کنیم. استانداردهای نامگذاری
218
00:09:37,230 –> 00:09:40,860
rxnorm و کد ملی دارو یا
219
00:09:40,860 –> 00:09:43,500
NDC ما، بنابراین با رعایت مثال مورفین،
220
00:09:43,500 –> 00:09:46,110
میتوانیم تمام تغییرات
221
00:09:46,110 –> 00:09:48,690
مورفین را به یک کد دارویی نگاشت کنیم، همانطور که در اینجا نشان داده شده است
222
00:09:48,690 –> 00:09:52,529
.
223
00:09:52,529 –> 00:09:56,940
224
00:09:56,940 –> 00:10:02,430
کدهای مناسب آنها در
225
00:10:02,430 –> 00:10:04,680
عبارات ثابت، اگرچه فراتر از نام داروها گسترش می یابد
226
00:10:04,680 –> 00:10:06,660
و می توان آن را در یادداشت های بالینی که
227
00:10:06,660 –> 00:10:09,510
مشترک یک بیماری یا علامت
228
00:10:09,510 –> 00:10:11,550
هستند، یافت در اینجا چند نمونه از مترادف های پزشکی هستند
229
00:10:11,550 –> 00:10:14,399
که می توانند به جای یکدیگر استفاده شوند، به
230
00:10:14,399 –> 00:10:17,610
عنوان مثال سکته قلبی اصطلاح دیگری
231
00:10:17,610 –> 00:10:20,399
برای حمله قلبی کبودی نیز می تواند توصیف شود.
232
00:10:20,399 –> 00:10:23,070
از آنجایی که کوفتگی و بیماری لو گهریگ
233
00:10:23,070 –> 00:10:25,019
معمولاً به عنوان
234
00:10:25,019 –> 00:10:30,029
اسکلروز جانبی آمیوتروفیک یا ALS نامیده می شود،
235
00:10:30,029 –> 00:10:32,640
می توانیم این اصطلاحات را به C استاندارد کنیم.
236
00:10:32,640 –> 00:10:35,310
شناسههای منحصربهفرد رایج با استفاده از سیستم یکپارچه
237
00:10:35,310 –> 00:10:39,120
زبان پزشکی یا umls این
238
00:10:39,120 –> 00:10:41,100
یک چارچوب منبع دارویی است که توسط
239
00:10:41,100 –> 00:10:43,260
کتابخانه ملی پزشکی ایالات متحده پشتیبانی میشود و
240
00:10:43,260 –> 00:10:45,959
برای انجام هر
241
00:10:45,959 –> 00:10:50,250
نوع پروژه NLP که شامل دادههای پزشکی است،
242
00:10:50,250 –> 00:10:56,310
زمانی که دادههای تمیز خود را داشته باشیم، بسیار قدرتمند
243
00:10:56,310 –> 00:10:59,399
است. قدم بعدی این است که ویژگیهای ما را مهندسی کنیم،
244
00:10:59,399 –> 00:11:01,500
میتوانیم از سیستمهای طبقهبندی مانند مش
245
00:11:01,500 –> 00:11:03,690
یا ATC برای استخراج
246
00:11:03,690 –> 00:11:06,240
Bertie’s از نام داروها استفاده کنیم، بنابراین
247
00:11:06,240 –> 00:11:09,030
سرفصلهای موضوعی پزشکی یا مش برای
248
00:11:09,030 –> 00:11:11,820
دستهبندی داروها بر اساس ویژگی مفید است،
249
00:11:11,820 –> 00:11:14,100
میتوانید آنها را به عنوان هشتگ یا
250
00:11:14,100 –> 00:11:17,970
توصیفکنندههایی در نظر بگیرید که یک اصطلاح پزشکی و در این
251
00:11:17,970 –> 00:11:20,520
مثال مرفین را توصیف میکنند. دارای سه اصطلاح مش است بنابراین
252
00:11:20,520 –> 00:11:24,480
مخدرهای مخدر ضددرد و به
253
00:11:24,480 –> 00:11:26,340
ما یک درک کلی از اینکه
254
00:11:26,340 –> 00:11:29,370
مورفین در چه چیزی در
255
00:11:29,370 –> 00:11:32,790
زمینه پزشکی برای مدل سپسیس ما استفاده می شود به ما می دهد، ما
256
00:11:32,790 –> 00:11:34,260
باید بدانیم که آیا به بیمار آنتی بیوتیک داده شده است
257
00:11:34,260 –> 00:11:36,300
که ما دریافت خواهیم کرد. در
258
00:11:36,300 –> 00:11:38,790
ادامه به جزئیات بیشتر میپردازیم، بنابراین شناسایی همه
259
00:11:38,790 –> 00:11:40,350
نسخهها با اصطلاح
260
00:11:40,350 –> 00:11:42,480
عوامل ضد باکتریایی بسیار
261
00:11:42,480 –> 00:11:47,280
مهم است. us ATC
262
00:11:47,280 –> 00:11:49,890
سیستم طبقه بندی دارویی دیگری است که
263
00:11:49,890 –> 00:11:52,470
داروها را بر اساس کاربردهای درمانی تشریحی و
264
00:11:52,470 –> 00:11:55,500
شیمیایی دسته بندی می کند، بنابراین در اینجا نمونه ای از
265
00:11:55,500 –> 00:11:58,590
کد ATC مرفین آورده شده است که می تواند
266
00:11:58,590 –> 00:12:00,230
به چهار بخش تجزیه شود و هر بخش
267
00:12:00,230 –> 00:12:02,250
ویژگی متفاوتی از
268
00:12:02,250 –> 00:12:09,300
دارو را با جزئیات بیشتر نشان می دهد، بنابراین برای
269
00:12:09,300 –> 00:12:12,270
استاندارد کردن تشخیص، ما میتواند از طبقهبندی
270
00:12:12,270 –> 00:12:15,690
استاندارد بینالمللی
271
00:12:15,690 –> 00:12:17,760
آماری بینالمللی بیماریها
272
00:12:17,760 –> 00:12:20,760
و مشکلات مرتبط با سلامت که
273
00:12:20,760 –> 00:12:24,300
به عنوان ICD نیز شناخته میشود، در پایان روز بیمار استفاده کند،
274
00:12:24,300 –> 00:12:26,280
پزشک معمولاً
275
00:12:26,280 –> 00:12:28,860
تشخیص اولیه بیمار و همچنین
276
00:12:28,860 –> 00:12:30,630
بیماریهای مرتبط مربوطه را در قالب
277
00:12:30,630 –> 00:12:34,500
کدهای ICD گزارش میکند.
278
00:12:34,500 –> 00:12:36,450
صورتحساب این موارد برای مقاصد صورتحساب نیز مورد استفاده قرار میگیرند
279
00:12:36,450 –> 00:12:39,