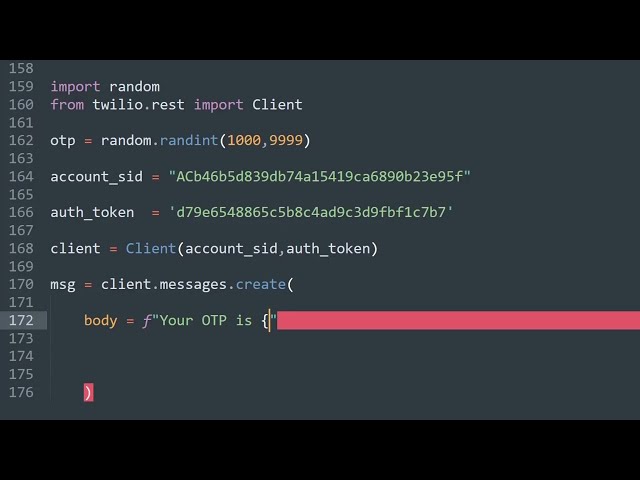
در این مطلب، ویدئو مبانی علم داده: پاکسازی داده ها در پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:34:43
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,060 –> 00:00:02,399
سلام همه می توانند با
2
00:00:02,399 –> 00:00:04,410
سومین قسمت از مجموعه مبانی علم داده من
3
00:00:04,410 –> 00:00:06,810
در این ویدیو بشنوند. من
4
00:00:06,810 –> 00:00:09,240
در مورد پاک کردن داده ها صحبت می کنم که چرا
5
00:00:09,240 –> 00:00:11,790
مهم است و همچنین برخی از
6
00:00:11,790 –> 00:00:14,429
تکنیک های اصلی یا تنظیم مجموعه داده های شما تا
7
00:00:14,429 –> 00:00:17,369
بتوان آن را به یک مدل تبدیل کرد. در علم داده، در
8
00:00:17,369 –> 00:00:19,170
مورد زباله در زباله زیاد می شنوید،
9
00:00:19,170 –> 00:00:19,980
10
00:00:19,980 –> 00:00:21,900
اگر داده های با کیفیت پایین را در یک
11
00:00:21,900 –> 00:00:24,330
مدل قرار دهید، نتیجه ضعیفی از آن
12
00:00:24,330 –> 00:00:26,430
مدل خواهید گرفت، بنابراین بسیار مهم است
13
00:00:26,430 –> 00:00:28,140
که پایه و اساس تنظیم کنید تا بفهمید چه چیزی
14
00:00:28,140 –> 00:00:30,480
یک مجموعه داده با کیفیت خوب را چگونه می سازد. شما
15
00:00:30,480 –> 00:00:32,399
یک مجموعه داده خام را می گیرید و آن را به چیزی تبدیل می
16
00:00:32,399 –> 00:00:35,250
کنید که به اندازه کافی تمیز باشد تا
17
00:00:35,250 –> 00:00:38,010
خروجی خوبی از آن در دو
18
00:00:38,010 –> 00:00:40,469
ویدیوی اولی که در مورد کاوش
19
00:00:40,469 –> 00:00:43,680
داده ها و دستکاری داده ها صحبت کردم را به دست آورید.
20
00:00:43,680 –> 00:00:45,980
21
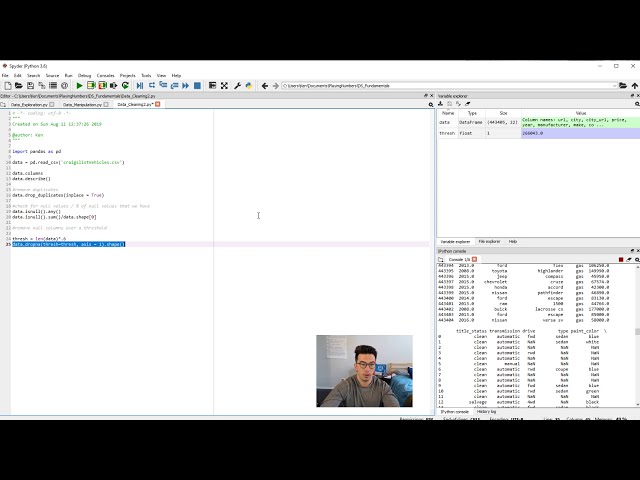
00:00:45,980 –> 00:00:48,780
هر یک از اطلاعاتی را که
22
00:00:48,780 –> 00:00:50,370
باید همراه با این ویدیوی ویدیویی دنبال کنید،
23
00:00:50,370 –> 00:00:53,430
اما ضرری ندارد که به آن ها برگردید،
24
00:00:53,430 –> 00:00:55,440
فقط برای اینکه با نحوه
25
00:00:55,440 –> 00:00:58,050
تدریس من و برخی از مفاهیمی که
26
00:00:58,050 –> 00:01:01,739
اکنون به طور معمول از آنها استفاده می کنم، آشنا شوید.
27
00:01:01,739 –> 00:01:03,629
y این محتوا را لطفاً
28
00:01:03,629 –> 00:01:05,640
دکمه لایک را بزنید و اگر میخواهید
29
00:01:05,640 –> 00:01:08,159
ویدیوهای مشابه این را ببینید، لطفاً مشترک شوید و اعلانها را روشن کنید
30
00:01:08,159 –> 00:01:09,990
تا بدانید چه زمانی
31
00:01:09,990 –> 00:01:12,659
مطالب جدید منتشر میکنم خوب است، بنابراین
32
00:01:12,659 –> 00:01:15,150
از مجموعه دادههای مشابه دو مورد قبلی من استفاده خواهیم کرد.
33
00:01:15,150 –> 00:01:19,110
ویدیوها این یک مجموعه داده قیمت خودرو
34
00:01:19,110 –> 00:01:22,320
از Craigslist comm است، پیوندی
35
00:01:22,320 –> 00:01:25,259
به آن در توضیحات زیر
36
00:01:25,259 –> 00:01:26,939
37
00:01:26,939 –> 00:01:28,200
وجود دارد.
38
00:01:28,200 –> 00:01:30,090
39
00:01:30,090 –> 00:01:33,750
پوشهای که این
40
00:01:33,750 –> 00:01:36,210
اطلاعات را دارد و اولین کاری که میخواهم
41
00:01:36,210 –> 00:01:39,240
انجام دهم این است که یک فایل جدید نیز ایجاد
42
00:01:39,240 –> 00:01:40,740
کنم، بنابراین میخواهم آن را در همان
43
00:01:40,740 –> 00:01:42,689
مکانی ذخیره کنم که آن را دادههای چسبیده به آن مینامیم
44
00:01:42,689 –> 00:01:47,850
و اکنون آماده هستیم
45
00:01:47,850 –> 00:01:50,759
طبق معمول، اولین کاری که
46
00:01:50,759 –> 00:01:52,590
میخواهم انجام دهم این است که میخواهم آن را وارد کنم
47
00:01:52,590 –> 00:01:57,780
و نام مستعار آن را بهعنوان PD انجام دهم تا بتوانیم
48
00:01:57,780 –> 00:02:00,420
با استفاده از آن مطلب بعدی که قرار است
49
00:02:00,420 –> 00:02:05,890
در دادهها بخوانم، به جلو برویم. سرعت خواندن PD
50
00:02:05,890 –> 00:02:13,930
و من دوست دارم فقط این نام را کپی کنم
51
00:02:13,930 –> 00:02:21,970
، کمی در زمان ما صرفه جویی می کند، بنابراین وقتی
52
00:02:21,970 –> 00:02:24,190
شما s من آن را برجسته کنید، ctrl
53
00:02:24,190 –> 00:02:26,500
enter را در ویندوز فشار میدهم و در واقع
54
00:02:26,500 –> 00:02:28,420
این دستور را اجرا میکند، این
55
00:02:28,420 –> 00:02:30,430
سوالی است که در برخی از ویدیوهای گذشتهام مقدار معقولی از من پرسیده شده است،
56
00:02:30,430 –> 00:02:32,709
بنابراین فکر میکنم
57
00:02:32,709 –> 00:02:35,470
دستور enter در Mac برای انجام این کار است که به
58
00:02:35,470 –> 00:02:37,030
شما امکان میدهد فقط یکی را اجرا کنید. بخشی از
59
00:02:37,030 –> 00:02:38,650
کد شما به جای فشار دادن این دکمه
60
00:02:38,650 –> 00:02:41,320
و اجرای کل فایل، بنابراین اکنون که
61
00:02:41,320 –> 00:02:43,630
این را خواندیم، میتوانیم چارچوب داده را
62
00:02:43,630 –> 00:02:48,040
در نمایشگر متغیر خود در اینجا ببینیم،
63
00:02:48,040 –> 00:02:50,620
بنابراین یک تمرین خوب برای من این است که فقط به
64
00:02:50,620 –> 00:02:53,320
ستونها نگاه کنم. ما این کار را
65
00:02:53,320 –> 00:02:55,840
قبل از اینکه بتوانیم همه
66
00:02:55,840 –> 00:02:58,450
ویژگیهای مجموعه داده خود را ببینیم انجام دادهایم و سپس
67
00:02:58,450 –> 00:03:03,970
میتوانیم دادهها را توصیف کنیم که در آن
68
00:03:03,970 –> 00:03:06,370
میتوانیم همه ویژگیهای
69
00:03:06,370 –> 00:03:08,820
فیلدهای عددی را در مجموعه داده خود ببینیم،
70
00:03:08,820 –> 00:03:11,739
اکنون این مجموعه داده
71
00:03:11,739 –> 00:03:14,519
قبلاً آن را بررسی کردهام. هیچ
72
00:03:14,519 –> 00:03:17,170
تکراری ندارد اما اگر میخواستم هر
73
00:03:17,170 –> 00:03:21,580
داده تکراری را حذف کنم، این کار را انجام میدادم، بنابراین
74
00:03:21,580 –> 00:03:26,140
موارد تکراری را حذف میکنیم و سپس
75
00:03:26,140 –> 00:03:32,650
نسخههای تکراری یک سوتین را انجام میدهیم و
76
00:03:32,650 –> 00:03:37,000
در جای خود برابر true است، به این معنی که از
77
00:03:37,000 –> 00:03:39,610
آن استفاده میشود. داده های ما را در اینجا تنظیم کنید و
78
00:03:39,610 –> 00:03:42,730
al را رها کنید l ردیف های تکراری از این یکی، بنابراین
79
00:03:42,730 –> 00:03:44,410
اگر من این را نداشتم برابر با
80
00:03:44,410 –> 00:03:46,959
true است، این یک مجموعه داده جدید ایجاد می کند
81
00:03:46,959 –> 00:03:49,690
و من می توانم آن را برابر با مجموعه داده های مشابه
82
00:03:49,690 –> 00:03:51,670
تنظیم کنم، اما این قاب داده های موجود را تحت تاثیر قرار نمی دهد.
83
00:03:51,670 –> 00:03:54,280
هنگامی که
84
00:03:54,280 –> 00:03:56,860
ما در جای خود انجام می دهیم، بر روی داده های موجود
85
00:03:56,860 –> 00:03:59,049
دوستانی که در اختیار داریم تأثیر می گذارد، بنابراین من انتظار ندارم
86
00:03:59,049 –> 00:04:00,850
دوباره افرادی به
87
00:04:00,850 –> 00:04:03,310
آنجا برسند، کار بعدی که انجام می دهیم این است که
88
00:04:03,310 –> 00:04:04,930
مقادیر تهی را بررسی می کنیم، کمی از این
89
00:04:04,930 –> 00:04:06,910
بررسی از داده های ما است. کاوش، اما
90
00:04:06,910 –> 00:04:10,890
این واقعاً در اینجا خود را ایجاد می کند، بنابراین
91
00:04:12,700 –> 00:04:15,740
، ما همچنین درصد
92
00:04:15,740 –> 00:04:21,320
مقادیر تهی را که داریم بررسی می کنیم تا بتوانیم
93
00:04:21,320 –> 00:04:27,080
داده ها را انجام دهیم تهی است و بنابراین اگر فقط
94
00:04:27,080 –> 00:04:31,850
این را اجرا کنیم، در هر ستون
95
00:04:31,850 –> 00:04:34,580
هر سطر دریافت می کنیم. مقدار تهی است یا خیر و
96
00:04:34,580 –> 00:04:38,270
بنابراین در اینجا میتوانیم هر روشی را وارد کنیم
97
00:04:38,270 –> 00:04:41,930
و سپس میتوانیم برای هر ستون ببینیم
98
00:04:41,930 –> 00:04:45,920
که آیا اصلاً مقادیر تهی وجود دارد یا خیر و بنابراین
99
00:04:45,920 –> 00:04:47,240
میتوانید URL را ببینید،
100
00:04:47,240 –> 00:04:50,420
من معتقدم URL کلید اصلی
101
00:04:50,420 –> 00:04:53,030
این مجموعه داده است. نباید هیچ
102
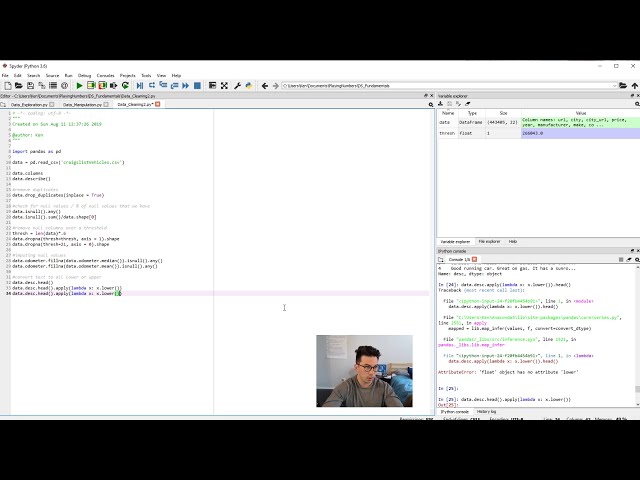
00:04:53,030 –> 00:04:55,370
تهی از آن وجود داشته باشد و پس از آن ما شهر
103
00:04:55,370 –> 00:04:58,730
یا L و قیمت را داریم بنابراین l به نظر می رسد برای یک
104
00:04:58,730 –> 00:05:00,680
آگهی ماشین Craigslist شما همیشه
105
00:05:00,680 –> 00:05:02,450
باید قیمتی را درج کنید که یک ویژگی است
106
00:05:02,450 –> 00:05:04,970
که همه آنها اختیاری به نظر می رسند،
107
00:05:04,970 –> 00:05:08,680
بنابراین ما همچنین می توانیم
108
00:05:08,680 –> 00:05:11,420
درصد هر یک از این ستون ها را که
109
00:05:11,420 –> 00:05:15,280
حذف نشده اند نگاه کنیم. و
110
00:05:15,280 –> 00:05:18,500
از آنجایی که اینها درست و نادرست هستند، زمانی که ما
111
00:05:18,500 –> 00:05:20,960
انجام دادیم، نسبت null true
112
00:05:20,960 –> 00:05:22,760
برابر با یک در پایتون است و false
113
00:05:22,760 –> 00:05:26,660
برابر با صفر است، بنابراین میتوانیم برخی از آنها را انجام دهیم و
114
00:05:26,660 –> 00:05:31,210
میتوانیم برای هر ستون دریافت کنیم که چه تعداد
115
00:05:31,210 –> 00:05:34,630
از مشخصهها درست شناخته
116
00:05:34,630 –> 00:05:38,240
نشده است. اساساً همه
117
00:05:38,240 –> 00:05:40,820
مشخصههای URL یا خیر و در واقع همه این ویژگیها نشان
118
00:05:40,820 –> 00:05:43,400
میدهد که تعداد آنها خالی است، من عذرخواهی میکنم، بنابراین اگر
119
00:05:43,400 –> 00:05:46,760
آن را بر تعداد کل در
120
00:05:46,760 –> 00:05:49,400
هر ستون تقسیم کنیم، بنابراین میتوانیم دادهها را یک شکل نقطه انجام دهیم،
121
00:05:49,400 –> 00:05:51,770
بنابراین اگر فقط به شکل نقطه داده نگاه کنیم.
122
00:05:51,770 –> 00:05:54,140
به ما نشان می دهد که چند سطر و
123
00:05:54,140 –> 00:05:56,930
چند ستون درست است، بنابراین می
124
00:05:56,930 –> 00:05:59,419
خواهیم اولین مورد را انتخاب کنیم که
125
00:05:59,419 –> 00:06:02,419
تعداد سطرها است و درصد
126
00:06:02,419 –> 00:06:05,870
هر یک را که شناخته شده است به ما می دهد، بنابراین تعداد بسیار کمی
127
00:06:05,870 –> 00:06:08,180
از افراد در اینجا حضور ندارند اما تعداد زیادی از آنها وجود دارد. nulls
128
00:06:08,180 –> 00:06:09,980
و اندازه ماشین ممکن است اگر این
129
00:06:09,980 –> 00:06:12,410
یک قسمت مبهم تر است، اکنون
130
00:06:12,410 –> 00:06:13,630
اولین چیزی که در رابطه با null ها به شما نشان می دهم
131
00:06:13,630 –> 00:06:16,250
این است که چگونه
132
00:06:16,250 –> 00:06:19,039
ستون ها یا ردیف هایی را حذف کنید که دارای آستانه خاصی هستند
133
00:06:19,039 –> 00:06:20,510
که شما نمی خواهید، بنابراین
134
00:06:20,510 –> 00:06:23,830
فرض کنید یک ستون دارای اندازه ای مشابه است. بیش از
135
00:06:23,830 –> 00:06:26,950
65% و همه ما ممکن است نخواهیم
136
00:06:26,950 –> 00:06:28,780
آن را در مجموعه دادههای خود لحاظ کنیم، مگر اینکه
137
00:06:28,780 –> 00:06:32,200
بگوییم سلام، میدانید این یک
138
00:06:32,200 –> 00:06:34,180
ویژگی معنیدار است اگر اندازه را شامل شود یا نباشد
139
00:06:34,180 –> 00:06:36,490
جایی که شما آن را به یک باینری یا
140
00:06:36,490 –> 00:06:38,890
یک متغیر دستهبندی کوچک تغییر دهید.
141
00:06:38,890 –> 00:06:40,630
مواقعی که اگر درصد واقعا بالایی
142
00:06:40,630 –> 00:06:41,920
در همه مواردی که به آنها نگاه می کنید وجود داشته باشد مانند
143
00:06:41,920 –> 00:06:44,530
90 95 درصد، ممکن است نخواهید
144
00:06:44,530 –> 00:06:46,090
همه آن را درج کنید و این نحوه
145
00:06:46,090 –> 00:06:48,580
رسیدگی به آن است، بنابراین در این یکی
146
00:06:48,580 –> 00:06:54,130
هیچ ستونی را بیش از یک آستانه حذف نمی کنیم.
147
00:06:54,130 –> 00:06:56,440
درست است، بنابراین یک آستانه ایجاد
148
00:06:56,440 –> 00:07:01,660
میکنیم و میخواهیم بگوییم که میخواهیم کمتر از
149
00:07:01,660 –> 00:07:06,610
60٪ درست نباشد، بنابراین میتوانیم
150
00:07:06,610 –> 00:07:09,460
طول قاب داده
151
00:07:09,460 –> 00:07:13,780
را بگیریم که همان
152
00:07:13,780 –> 00:07:15,250
عدد شکل است. روش های مختلف برای انجام آن
153
00:07:15,250 –> 00:07:17,620
من دوست دارم آن را مخلوط کنم تا شما بچه ها
154
00:07:17,620 –> 00:07:20,800
داشته باشید کمی تنوع بیشتر و اینکه چگونه می
155
00:07:20,800 –> 00:07:22,480
توانید جرم را صادر کنید و ما آن را در
156
00:07:22,480 –> 00:07:25,090
نقطه شش به سمت راست ضرب می کنیم تا این
157
00:07:25,090 –> 00:07:29,430
آستانه به نظر برسد که حدود
158
00:07:29,430 –> 00:07:35,260
260000 مورد از این ردیف ها
159
00:07:35,260 –> 00:07:39,640
مشخص نیست و بنابراین اکنون می توانیم داده ها را رسم نقطه ای
160
00:07:39,640 –> 00:07:44,880
n انجام دهیم. /a و
161
00:07:44,880 –> 00:07:49,120
ما thrush را برابر با متغیر thrush خود قرار می دهیم که در
162
00:07:49,120 –> 00:07:51,880
بالا داشتیم و در اینجا مهم
163
00:07:51,880 –> 00:07:55,120
است که محور را برابر با یک قرار دهیم، بنابراین
164
00:07:55,120 –> 00:07:57,160
ویدیوهای قبلی من می دانید
165
00:07:57,160 –> 00:07:59,890
که اگر به ستون ها نگاه کنیم، محور است. یا
166
00:07:59,890 –> 00:08:02,110
ما به سطرها نگاه میکنیم، بنابراین در این یکی
167
00:08:02,110 –> 00:08:05,500
میخواهیم ستونهایی را که
168
00:08:05,500 –> 00:08:08,230
آستانهای کمتر از این دارند رها کنیم، بنابراین دوباره
169
00:08:08,230 –> 00:08:13,630
در اینجا ما این کار را نکردیم، ما از در محل استفاده نکردیم،
170
00:08:13,630 –> 00:08:16,030
بنابراین میبینید که دادههای بالا وجود
171
00:08:16,030 –> 00:08:18,280
ندارد. کاملاً تحت تأثیر قرار گرفته است و ما
172
00:08:18,280 –> 00:08:20,680
این قاب داده را داریم که خروجی میدهیم، بنابراین
173
00:08:20,680 –> 00:08:23,170
میتوانیم روی این کار انجام دهیم، بیایید شکل را انجام دهیم و ببینیم که
174
00:08:23,170 –> 00:08:28,020
آیا با تصویر بالا متفاوت است،
175
00:08:28,020 –> 00:08:31,020
متأسفم،
176
00:08:31,210 –> 00:08:34,340
بنابراین همانطور که میبینید ما چهار
177
00:08:34,340 –> 00:08:36,349
ستون را حذف کردیم زیرا چهار ستون بالاتر
178
00:08:36,349 –> 00:08:39,590
از آستانه صفر بودند. ما همچنین می توانیم
179
00:08:39,590 –> 00:08:43,669
ردیف ها را با شما کمتر از یک
180
00:08:43,669 –> 00:08:46,190
thres مشخص رها کنیم همینطور نگه دارید تا داده ها را
181
00:08:46,190 –> 00:08:50,120
یک تازه رها کنیم و سپس از آنجایی که در
182
00:08:50,120 –> 00:08:54,170
اینجا 22 ستون داریم، فرض کنیم یک قاب داده می خواهیم
183
00:08:54,170 –> 00:08:56,890
که در آن همه سطرها حداقل دارای
184
00:08:56,890 –> 00:09:02,029
مقادیر 21 و 21 باشند که از بین نرفتند، بنابراین
185
00:09:02,029 –> 00:09:05,630
می توانیم آستانه را فقط یک مورد تنظیم کنیم. محور
186
00:09:05,630 –> 00:09:09,320
برابر با صفر است، بنابراین بیایید این را انجام دهیم
187
00:09:09,320 –> 00:09:11,420
زیرا می بینید که خروجی آن خواهد بود، بیایید
188
00:09:11,420 –> 00:09:14,330
همین کار را با شکل انجام دهیم و انتظار
189
00:09:14,330 –> 00:09:16,370
داریم دقیقاً مقدار بسیار کمتری در جاده ها ببینیم،
190
00:09:16,370 –> 00:09:19,610
بنابراین این مجموعه داده های ما را
191
00:09:19,610 –> 00:09:22,430
تقریباً سه چهارم کاهش می دهد. با انجام این کار،
192
00:09:22,430 –> 00:09:24,589
ما دو گزینه داریم، میتوانیم
193
00:09:24,589 –> 00:09:27,290
nullها را حذف کنیم یا میتوانیم آنها را نسبت دهیم، بنابراین میتوانیم
194
00:09:27,290 –> 00:09:30,620
mas را با مقادیر متفاوتی پر کنیم، بنابراین
195
00:09:30,620 –> 00:09:32,690
گاهی اوقات منطقی است که آن را با صفر پر کنیم،
196
00:09:32,690 –> 00:09:35,960
بنابراین بیایید بگوییم که در
197
00:09:35,960 –> 00:09:38,780
یک متغیر طبقهای مقدار زیادی داریم. از
198
00:09:38,780 –> 00:09:42,350
تهیها، در واقع
199
00:09:42,350 –> 00:09:44,810
میتوانیم آن را بهعنوان ویژگی استفاده کنیم تا بگوییم اگر آنها
200
00:09:44,810 –> 00:09:46,610
به این سؤال پاسخ ندادند که
201
00:09:46,610 –> 00:09:49,910
میتواند معنیدار باشد، همچنین میتوانیم آن را
202
00:09:49,910 –> 00:09:52,190
با میانگین همه چیزهای موجود
203
00:09:52,190 –> 00:09:53,660
در ستون یا رسانه همه جایگزین کنیم.
204
00:09:53,660 –> 00:09:55,850
چیزهای موجود در ستون و این بخشی از
205
00:09:55,850 –> 00:09:57,410
آینده است مهندسی که می تواند سرگرم کننده باشد و
206
00:09:57,410 –> 00:10:00,140
می تواند به شما در بهبود مدل کمک کند،
207
00:10:00,140 –> 00:10:02,060
بنابراین تصمیماتی که در اینجا می گیرید
208
00:10:02,060 –> 00:10:04,310
می تواند بر مدل شما تأثیر بگذارد.
209
00:10:04,310 –> 00:10:05,810
210
00:10:05,810 –> 00:10:07,490
211
00:10:07,490 –> 00:10:10,820
انواع مختلفی
212
00:10:10,820 –> 00:10:13,370
از چندک ها و غیره، بنابراین من فقط
213
00:10:13,370 –> 00:10:15,760
در اینجا به شما نشان می دهم که چگونه یک
214
00:10:15,760 –> 00:10:20,330
متغیر عددی را با میانه یا
215
00:10:20,330 –> 00:10:21,950
میانگین جایگزین کنید، اگر در آن فراخوانی یک عدد تهی وجود دارد،
216
00:10:21,950 –> 00:10:24,890
خوب است، بنابراین کاری که ما در اینجا انجام می دهیم این است
217
00:10:24,890 –> 00:10:28,610
که بیایید بررسی کنیم اینجا را ببینید، بیایید
218
00:10:28,610 –> 00:10:32,630
این را برای Sentinel در اینجا دوباره اجرا کنیم تا بدانم
219
00:10:32,630 –> 00:10:36,980
کیلومترشمار یک متغیر عددی است و
220
00:10:36,980 –> 00:10:39,580
میتوانیم ببینیم که از زمانی که اجرا کردیم توصیف کنید،
221
00:10:39,580 –> 00:10:42,200
بنابراین اگر به آن نگاه میکنیم، میتوانیم بگوییم
222
00:10:42,200 –> 00:10:44,240
خوب است، میخواهم
223
00:10:44,240 –> 00:10:46,490
همه مقادیر تهی را در domitor جایگزین کنم.
224
00:10:46,490 –> 00:10:49,430
با چیزی-چیزی عددی، بنابراین
225
00:10:49,430 –> 00:10:52,220
ما بتوانیم آن را از طریق یک مدل اجرا کنیم تا
226
00:10:52,220 –> 00:10:57,830
راهی که من پیش میروم این است که هیچ مقداری وجود ندارد.
227
00:10:57,830 –> 00:11:04,190
228
00:11:04,190 –> 00:11:07,880
229
00:11:07,880 –> 00:11:10,700
بنابراین فقط
230
00:11:10,700 –> 00:11:12,680
تمام مقادیر null i را پر می کند n آن
231
00:11:12,680 –> 00:11:18,890
ستون با رسانه کیلومترسنج تتا نقطه، بنابراین
232
00:11:18,890 –> 00:11:21,440
من میانه را دوست دارم، اگر مقادیر بسیار دیوانهکنندهای داشته باشیم، عادی شده است
233
00:11:21,440 –> 00:11:24,950
که
234
00:11:24,950 –> 00:11:26,750
ممکن است کمی بعد بفهمیم که
235
00:11:26,750 –> 00:11:30,770
چگونه زیر آن را ارزیابی کنیم، بنابراین اکنون
236
00:11:30,770 –> 00:11:33,320
میدانیم که آیا این کار را در جای خود انجام دادهایم یا نه برابر
237
00:11:33,320 –> 00:11:35,180
با true است، مجموعه دادههای واقعی را
238
00:11:35,180 –> 00:11:42,459
که اکنون میتوانیم انجام دهیم پر میکند، null است و سپس any
239
00:11:42,459 –> 00:11:46,279
و ما نباید دقیقاً هیچ مقدار تهی داشته باشیم،
240
00:11:46,279 –> 00:11:48,140
بنابراین با false روی
241
00:11:48,140 –> 00:11:50,600
مقادیر null در آنجا عالی است، بنابراین ما میتوانیم
242
00:11:50,600 –> 00:11:53,959
همان کاری را که میتوانیم انجام دهیم. یک تابع را در اینجا قرار دهید
243
00:11:53,959 –> 00:11:56,540
به عنوان میانگین این جلسه فقط
244
00:11:56,540 –> 00:11:57,980
تابع پانداهای داخلی است که ما نیز میتوانیم به آن
245
00:11:57,980 –> 00:12:02,209
معنی داشته باشیم و در عوض میانگین را در آنجا دریافت میکنیم،
246
00:12:02,209 –> 00:12:04,880
بنابراین این یک راه عالی
247
00:12:04,880 –> 00:12:08,810
برای جایگزینی آن داده است.
248
00:12:08,810 –> 00:12:12,560
مقادیر، بنابراین
249
00:12:12,560 –> 00:12:15,110
از مقادیر تهی حرکت میکنیم، فکر
250
00:12:15,110 –> 00:12:17,329
میکنم مدیریت کار
251
00:12:17,329 –> 00:12:21,070
با برخی از متنها در مجموعه دادههای شما همیشه جالب است، بنابراین در
252
00:12:21,070 –> 00:12:25,940
این مجموعه داده خاص، ما مانند یک
253
00:12:25,940 –> 00:12:27,920
فیلد توضیحات و فیلد توضیحات
254
00:12:27,920 –> 00:12:29,870
ترکیبی از
255
00:12:29,870 –> 00:12:33,020
حروف بزرگ کوچک و غیره داریم و اگر ما خواستن برای
256
00:12:33,020 –> 00:12:34,910
اینکه بتوانیم تا حد امکان موثر ارزیابی
257
00:12:34,910 –> 00:12:37,520
کنیم، احتمالاً باید
258
00:12:37,520 –> 00:12:39,130
همه حروف را کوچک یا بزرگ
259
00:12:39,130 –> 00:12:41,180
کنیم، به این معنی که اگر بخواهیم از یک کیسه
260
00:12:41,180 –> 00:12:42,260
کلمه استفاده کنیم، اگر میخواهیم از برخی از این
261
00:12:42,260 –> 00:12:44,060
تکنیکهای دیگر استفاده کنیم، همه چیز
262
00:12:44,060 –> 00:12:46,130
عادی شده است، واقعاً نمیتوانید از شر مشکلات املایی خلاص شوید،
263
00:12:46,130 –> 00:12:49,100
اما این یک
264
00:12:49,100 –> 00:12:50,510
راه عالی برای شبیهسازی دادههای
265
00:12:50,510 –> 00:12:55,500
شما تا حد امکان
266
00:12:55,500 –> 00:12:59,670
267
00:12:59,670 –> 00:13:03,480
268
00:13:03,480 –> 00:13:05,790
میخواهیم به بخش اصلی نگاه
269
00:13:05,790 –> 00:13:09,000
270
00:13:09,000 –> 00:13:10,590
کنیم، بنابراین پنج مورد اول را به ما میدهیم تا
271
00:13:10,590 –> 00:13:15,000
بتوانید فروش بیامو را مشاهده کنید، یک
272
00:13:15,000 –> 00:13:17,010
نمونه خوب این است که ما تابلوی کلاسیک
273
00:13:17,010 –> 00:13:17,730
داریم، به خانهای
274
00:13:17,730 –> 00:13:20,490
با سرمایه نیاز دارد که ممکن
275
00:13:20,490 –> 00:13:21,900
است در برخی از موارد متفاوت به نظر برسد. این الگوریتمهای مختلف،
276
00:13:21,900 –> 00:13:23,820
بنابراین ما میخواهیم
277
00:13:23,820 –> 00:13:28,410
همه اینها را به حروف کوچک تبدیل کنیم، بنابراین کاری که
278
00:13:28,410 –> 00:13:33,380
میتوانیم انجام دهیم این است که میتوانیم دادهها را نزولی
279
00:13:35,150 –> 00:13:38,160
کنیم، متأسفیم که تابع لامبدا را اعمال میکنیم
280
00:13:38,160 –> 00:13:39,570
که در ویدیوهای قبلیام در مورد آن صحبت کردم،
281
00:13:39,570 –> 00:13:42,510
این اساساً به شما اجازه میدهد. ما بنویسیم
282
00:13:42,510 –> 00:13:44,520
یک تابع بسیار سریع است و من آن را
283
00:13:44,520 –> 00:13:55,380
به متغیر منتقل می کنم، بنابراین لامبدا X را انجام دهید، اکنون
284
00:13:55,380 –> 00:13:59,280
X نقطه را پایین تر انجام می دهیم تا فقط
285
00:13:59,280 –> 00:14:03,120
تمام متن در X که ردیف ما است به
286
00:14:03,120 –> 00:14:05,220
حروف کوچک تبدیل شود، بنابراین اجازه دهید سر
287
00:14:05,220 –> 00:14:09,560
این کار را در اینجا انجام دهیم. دیوار به خوبی جلو نیست
288
00:14:09,560 –> 00:14:12,990
و ما می توانیم همان چیزی را ببینیم که
289
00:14:12,990 –> 00:14:17,870
اکنون تبدیل به شناور شده است،
290
00:14:31,009 –> 00:14:33,300
به نظر می رسد
291
00:14:33,300 –> 00:14:35,069
مقادیر عددی در اینجا وجود دارد که یکی دیگر از کارهای
292
00:14:35,069 –> 00:14:36,779
پیش پردازش داده است که باید
293
00:14:36,779 –> 00:14:39,120
انجام دهیم، می دانم که هیچ مقداری وجود ندارد.
294
00:14:39,120 –> 00:14:42,180
حروف کوچکتر و در سر آن قاب داده،
295
00:14:42,180 –> 00:14:45,240
بنابراین اجازه دهید فقط به سر نگاه کنیم
296
00:14:45,240 –> 00:14:49,860
و همان تابع را به خوبی اعمال کنیم تا
297
00:14:49,860 –> 00:14:52,740
298
00:14:52,740 –> 00:14:56,519
بتوانیم قبل از اینکه بتوانیم همان کار را با گزینه دیگر انجام دهیم، همه موارد بالایی را که مشاهده می کردیم حذف کنیم
299
00:14:56,519 –> 00:14:58,769
.
300
00:14:58,769 –> 00:15:01,649
حروف کوچک خواهد بود، اما جایی که شما میتوانید آن را بزرگ کنید
301
00:15:01,649 –> 00:15:06,240
، ما میرویم و
302
00:15:06,240 –> 00:15:10,439
همه چیز را دوباره به حروف بزرگ تغییر میدهد، حالا
303
00:15:10,439 –> 00:15:12,269
دیدید که قبلاً یک نوع خطای تایپ
304
00:15:12,269 –> 00:15:15,240
داشتیم، این چیزی است که اکنون میتوانیم وارد آن شویم
305
00:15:15,240 –> 00:15:16,949
و در مورد آن صحبت کنیم. شما
306
00:15:16,949 –> 00:15:19,589
خطاهای نوع را مدیریت می کنید، بنابراین ما مقداری شناور داشتیم که به
307
00:15:19,589 –> 00:15:22,110
نظر می رسد l یعنی
308
00:15:22,110 –> 00:15:25,259
میدانستم که یک مقدار عددی وجود دارد، تنظیم یک
309
00:15:25,259 –> 00:15:27,899
مقدار عددی در اینجا، رفتن از float به
310
00:15:27,899 –> 00:15:31,379
رشته دیگر بسیار آسان است.
311
00:15:31,379 –> 00:15:32,189
312
00:15:32,189 –> 00:15:35,040
313
00:15:35,040 –> 00:15:37,230
314
00:15:37,230 –> 00:15:40,230
315
00:15:40,230 –> 00:15:44,430
بنابراین برای فریم کردن تا بتوانیم
316
00:15:44,430 –> 00:15:49,860
توصیف دادهها را بهعنوان رشته تایپ انجام
317
00:15:49,860 –> 00:15:51,990
دهیم و همه چیز را برمیگرداند، عجیب است،
318
00:15:51,990 –> 00:15:53,490
بنابراین نباید همان مشکلی را
319
00:15:53,490 –> 00:16:02,490
داشته باشیم که قبل از پایینتر شدن آن
320
00:16:02,490 –> 00:16:07,350
داشتیم و باید دوباره کار کند، برخلاف قبل
321
00:16:07,350 –> 00:16:09,629
که برخی از موارد را داشتیم. این مشکلات اکنون
322
00:16:09,629 –> 00:16:12,329
کار می کند زیرا همه اینها
323
00:16:12,329 –> 00:16:14,550
به عنوان یک رشته طبقه بندی می شود، ما می توانیم با انجام دادن
324
00:16:14,550 –> 00:16:20,449
نوع d آن را ببینیم و انواع اوپ را در آنجا نشان
325
00:16:22,380 –> 00:16:28,390
می دهد که در انواع D پایین می آییم و
326
00:16:28,390 –> 00:16:30,280
نوع همه این موارد را نشان می دهم
327
00:16:30,280 –> 00:16:33,220
اگر این یک شی است که می تواند ترکیبی از
328
00:16:33,220 –> 00:16:36,340
رشته و شناور یک int یا برخی از
329
00:16:36,340 –> 00:16:37,840
انواع مختلف باشد، بنابراین ما می خواهیم مطمئن شویم
330
00:16:37,840 –> 00:16:41,230
که در شرایطی مانند این،
331
00:16:41,230 –> 00:16:43,150
یک قانون سخت در مورد اینکه چیست و چه چیزی
332
00:16:43,150 –> 00:16:46,780
باید برعکس باشد تعیین می کنیم. این
333
00:16:46,780 –> 00:16:49,000
تقریباً شبیه به تکس است تصویر tbook
334
00:16:49,000 –> 00:16:51,670
مثال کاملی از اینکه چگونه ممکن است
335
00:16:51,670 –> 00:16:55,690
بخواهید از رشته ای به int یا float بروید، بنابراین ما این
336
00:16:55,690 –> 00:16:59,260
کار را انجا