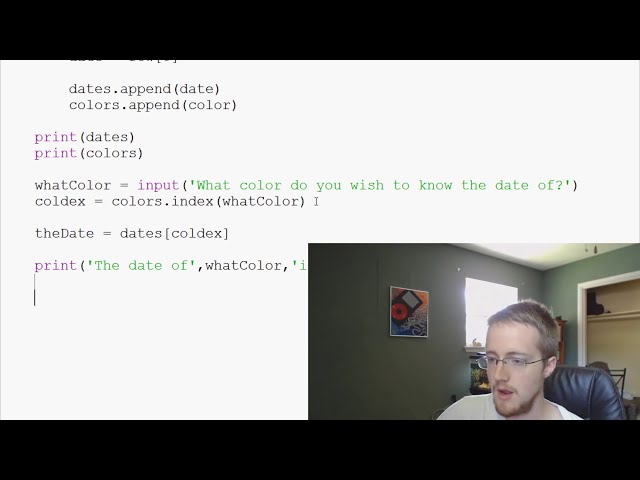
در این مطلب، ویدئو مترجم ریاضی ساده در پایتون (1/4) – Lexer با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:13:01
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,050 –> 00:00:02,669
سلام به همه، اینجا قطب سرد است
2
00:00:02,669 –> 00:00:04,350
و در این سری ما قصد
3
00:00:04,350 –> 00:00:06,390
داریم مترجم ساده خود را در پایتون ایجاد کنیم،
4
00:00:06,390 –> 00:00:09,389
این برای
5
00:00:09,389 –> 00:00:11,550
یادگیری اصول اولیه نحوه
6
00:00:11,550 –> 00:00:14,309
پردازش فرمت های قابل خواندن توسط کامپیوترها مفید است و
7
00:00:14,309 –> 00:00:15,960
اولین قدم عالی برای ایجاد برنامه شخصی شماست.
8
00:00:15,960 –> 00:00:19,529
زبان دادههای زبان و غیره بنابراین
9
00:00:19,529 –> 00:00:21,420
این مفسر میتواند محاسبات ریاضی ساده را ارزیابی کند،
10
00:00:21,420 –> 00:00:23,699
بنابراین اگر پنج و
11
00:00:23,699 –> 00:00:26,039
پنج را با هم جمع کنیم، اگر هشت را تقسیم کنیم، به ده میرسیم
12
00:00:26,039 –> 00:00:28,080
و دو را به چهار خواهیم رسید، اما
13
00:00:28,080 –> 00:00:30,210
میتواند چندین عملگر داشته باشد و
14
00:00:30,210 –> 00:00:32,308
ترتیب عملکرد را نیز در نظر بگیرد. بنابراین
15
00:00:32,308 –> 00:00:35,160
اگر دو بعلاوه سه در چهار منهای پنج انجام دهیم،
16
00:00:35,160 –> 00:00:36,809
مفسر متوجه میشود که
17
00:00:36,809 –> 00:00:38,550
قبل از
18
00:00:38,550 –> 00:00:40,230
انجام بقیه محاسبات، ابتدا عملیات ضرب را انجام میدهد،
19
00:00:40,230 –> 00:00:42,030
در حالی که اکنون میتوانیم براکتها را
20
00:00:42,030 –> 00:00:43,860
در حدود دو به علاوه سه قرار دهیم و نتیجه متفاوتی به ما خواهد داد.
21
00:00:43,860 –> 00:00:46,110
22
00:00:46,110 –> 00:00:47,940
سعی کنید ابتدا خودتان یک مترجم سادهتر
23
00:00:47,940 –> 00:00:49,559
بسازید و ببینید تا کجا پیش میروید
24
00:00:49,559 –> 00:00:51,420
و سپس به این مجموعه بازگردید و
25
00:00:51,420 –> 00:00:53,850
ببینید که من چگونه رویکرد میکنم، بنابراین همانطور که قبلاً
26
00:00:53,850 –> 00:00:55,710
اشاره کردم ما با هم خواهیم بود. بازخوانی این برنامه
27
00:00:55,710 –> 00:00:57,239
در پایتون، بنابراین اگر آن را
28
00:00:57,239 –> 00:00:59,160
قبلاً دریافت نکردهاید، میتوانید درخت پایتون را
29
00:00:59,160 –> 00:01:01,829
از دانلودهای اسلش python.org دانلود کنید و
30
00:01:01,829 –> 00:01:04,049
فکر میکنم حداقل به نسخه 3.7 نیاز داریم،
31
00:01:04,049 –> 00:01:06,659
من از IDE کد ویژوال استودیو
32
00:01:06,659 –> 00:01:08,490
برای این پروژه استفاده خواهم کرد، اما در صورت تمایل از
33
00:01:08,490 –> 00:01:12,030
هر شناسه ای که می خواهید استفاده کنید، بنابراین
34
00:01:12,030 –> 00:01:14,400
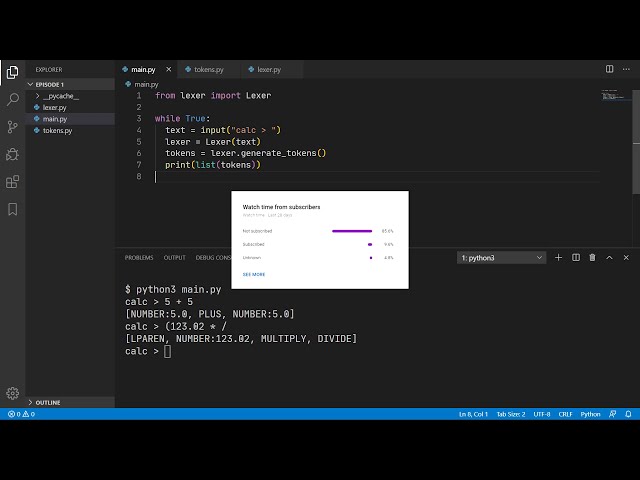
ما با ایجاد فایل اصلی نقطه py خود شروع می کنیم
35
00:01:14,400 –> 00:01:16,650
و اولین کاری که باید انجام دهیم این است که
36
00:01:16,650 –> 00:01:18,420
ورودی را از کاربر درخواست کنیم، بنابراین من فقط می خواهم
37
00:01:18,420 –> 00:01:21,000
آن را به متغیر متنی که می نویسیم اختصاص دهیم.
38
00:01:21,000 –> 00:01:22,950
در یک حلقه بی نهایت به طوری
39
00:01:22,950 –> 00:01:24,750
که ما بتوانیم محاسبات را وارد کنیم،
40
00:01:24,750 –> 00:01:27,270
بنابراین اگر برنامه خود را اجرا کنیم باید
41
00:01:27,270 –> 00:01:29,310
بتوانیم یک دسته ورودی را وارد کنیم اما
42
00:01:29,310 –> 00:01:31,860
هنوز کاری انجام نمی دهد، بنابراین اکنون
43
00:01:31,860 –> 00:01:34,020
به سمت ایجاد lexer حرکت می کنیم.
44
00:01:34,020 –> 00:01:36,000
اولین بخش اساسی برای اجازه دادن به
45
00:01:36,000 –> 00:01:38,460
برنامه شما برای درک یک قالب متن سفارشی،
46
00:01:38,460 –> 00:01:40,890
به طوری که این کاری است که در
47
00:01:40,890 –> 00:01:43,530
قسمت اول سخنرانی انجام خواهیم داد،
48
00:01:43,530 –> 00:01:45,840
کاراکترهای ورودی را در بخشهای کوچکی
49
00:01:45,840 –> 00:01:47,820
به نام نشانهها گروهبندی میکنیم و
50
00:01:47,820 –> 00:01:50,159
نوع هر نشانهای را که سخنرانی
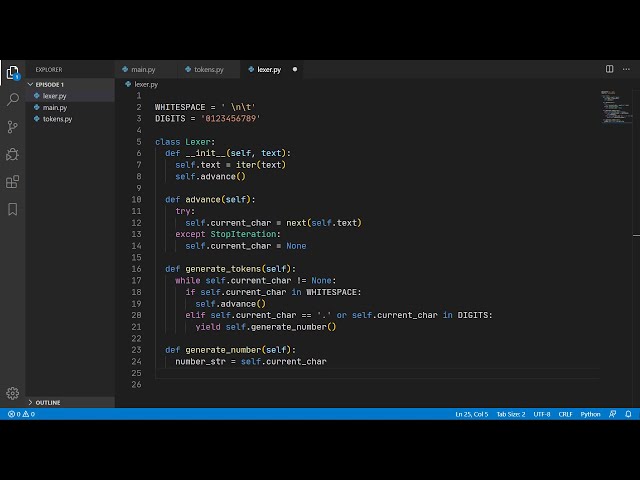
51
00:01:50,159 –> 00:01:51,570
طی میکند مشخص میکند. کاراکتر ورودی توسط کاراکتر
52
00:01:51,570 –> 00:01:54,509
همانطور که با این فلش
53
00:01:54,509 –> 00:01:57,299
علامت داده می شود، اولین کاراکتر ورودی یک رقم است و
54
00:01:57,299 –> 00:01:59,490
بنابراین سخنرانی نشان می دهد که این
55
00:01:59,490 –> 00:02:02,040
شروع یک عدد است، بنابراین سخنرانی
56
00:02:02,040 –> 00:02:04,590
این نوع نشانه را ردیابی می کند و همچنین
57
00:02:04,590 –> 00:02:06,540
ارزش ایجاد شده فعلی در
58
00:02:06,540 –> 00:02:07,860
سخنرانی ده را پیگیری می کند. به کاراکتر بعدی میرود
59
00:02:07,860 –> 00:02:10,080
و هنوز یک رقم است، بنابراین
60
00:02:10,080 –> 00:02:12,690
ما همچنان به ساختن عددی که مدام از آن عبور میکنیم ادامه میدهیم تا
61
00:02:12,690 –> 00:02:13,800
62
00:02:13,800 –> 00:02:16,020
این بار یک نقطه اعشار یک رقم
63
00:02:16,020 –> 00:02:18,330
دیگر و یک رقم دیگر و اکنون
64
00:02:18,330 –> 00:02:20,790
کل عدد را ساختهایم، کاراکتر بعدی
65
00:02:20,790 –> 00:02:22,860
هیچ است. یک رقم طولانی تر یا یک نقطه اعشار و
66
00:02:22,860 –> 00:02:25,170
به این ترتیب پایان آن نشانه عددی است،
67
00:02:25,170 –> 00:02:27,540
بنابراین آن نشانه در
68
00:02:27,540 –> 00:02:30,000
لیست نشانه ها ذخیره می شود، کاراکتر فعلی اکنون یک
69
00:02:30,000 –> 00:02:32,250
فضای خالی است و در برنامه ما
70
00:02:32,250 –> 00:02:33,960
فضای سفید هیچ اثری ندارد، بنابراین
71
00:02:33,960 –> 00:02:35,790
ما فقط نادیده می گیریم. فاصله سفید و
72
00:02:35,790 –> 00:02:38,370
پیشبرد کاراکتر بعدی ما
73
00:02:38,370 –> 00:02:40,260
اکنون یک نماد مثبت پیدا کرده ایم و به این ترتیب
74
00:02:40,260 –> 00:02:43,020
نشان دهنده یک نشانه مثبت است و در این مورد
75
00:02:43,020 –> 00:02:44,550
ارزشی وجود ندارد که ما باید آن را پیگیری کنیم
76
00:02:44,550 –> 00:02:46,430
زیرا همه آن نشانه ها یکسان هستند،
77
00:02:46,430 –> 00:02:48,960
بنابراین در مرحله بعدی باید آن را دنبال کنیم. یک کاراکتر فضای خالی دیگر دارید
78
00:02:48,960 –> 00:02:50,850
و این یک بار دیگر نادیده گرفته میشود،
79
00:02:50,850 –> 00:02:53,220
حالا یک رقم دیگر داریم که
80
00:02:53,220 –> 00:02:55,440
شروع یک عدد دیگر است و سپس
81
00:02:55,440 –> 00:02:57,000
به یک رقم دیگر میرویم که یک بار
82
00:02:57,000 –> 00:02:59,700
دیگر یک نشانه عددی اضافه میکند، سپس با
83
00:02:59,700 –> 00:03:01,560
یک فضای خالی مواجه میشویم که دیگر رقمی نیست،
84
00:03:01,560 –> 00:03:03,120
بنابراین ما با علامت عدد تمام شد،
85
00:03:03,120 –> 00:03:05,700
این بار با یک
86
00:03:05,700 –> 00:03:07,710
عملگر ضرب مواجه شدیم، بنابراین اکنون این یک
87
00:03:07,710 –> 00:03:10,860
نشانه ضرب است و مشابه علامت مثبت
88
00:03:10,860 –> 00:03:12,720
است و هیچ مقداری
89
00:03:12,720 –> 00:03:13,410
با آن مرتبط نیست،
90
00:03:13,410 –> 00:03:15,750
اکنون با کاراکترهای فضای خالی دیگری روبرو می شویم
91
00:03:15,750 –> 00:03:17,580
که بار دیگر نادیده گرفته شده اند و به
92
00:03:17,580 –> 00:03:20,040
جلو می رویم. به یک نشانه عددی نهایی میرسیم
93
00:03:20,040 –> 00:03:22,709
و هر رقم را ایجاد میکنیم و سپس
94
00:03:22,709 –> 00:03:24,720
این پایان فرآیند lexing است، بنابراین میتوانید
95
00:03:24,720 –> 00:03:27,510
ببینید که ما همه نشانهها را ساختهایم، بنابراین
96
00:03:27,510 –> 00:03:29,580
کد سخنرانی را در
97
00:03:29,580 –> 00:03:32,310
این ویدیو و در این ویدیو مینویسیم. ویدیوی بعدی ما
98
00:03:32,310 –> 00:03:34,020
کدی می نویسیم که به
99
00:03:34,020 –> 00:03:36,120
دنباله توکن ها نگاه می کند و مشخص می کند
100
00:03:36,120 –> 00:03:37,770
که قرار است چه اتفاقی بیفتد، بنابراین اگر
101
00:03:37,770 –> 00:03:39,959
یک عدد به همراه یک مثبت و به دنبال
102
00:03:39,959 –> 00:03:42,720
آن یک عدد دیگر داشته باشیم، می دانیم که باید آن ها
103
00:03:42,720 –> 00:03:45,690
را اضافه کنیم. دو عدد با هم، بنابراین ما
104
00:03:45,690 –> 00:03:47,730
به کد ویژوال استودیو بازگشته ایم و
105
00:03:47,730 –> 00:03:50,070
یک فایل جدید برای توکن های خود ایجاد می کنیم و
106
00:03:50,070 –> 00:03:52,010
این چیزهای توکن را py
107
00:03:52,010 –> 00:03:54,660
می نامیم، بنابراین در اینجا ما می خواهیم انواع مختلف توکن خود را تعریف کنیم
108
00:03:54,660 –> 00:03:57,330
تا این کار را انجام دهیم.
109
00:03:57,330 –> 00:03:59,610
ما قصد داریم یک نوع رمز ایجاد کنیم enum
110
00:03:59,610 –> 00:04:02,040
هر نوع توکن یک شناسه دارد
111
00:04:02,040 –> 00:04:04,410
که یک عدد است و کاری که e
112
00:04:04,410 –> 00:04:06,660
عادی میکند این است که یک نام را
113
00:04:06,660 –> 00:04:09,420
با آن شناسه مرتبط میکنیم، بنابراین اولین نوع نشانهای که
114
00:04:09,420 –> 00:04:11,100
داریم یک نشانه عددی است و ما. به
115
00:04:11,100 –> 00:04:13,530
این شناسه صفر میدهیم و همانطور که دیدید، ما
116
00:04:13,530 –> 00:04:15,510
یک نشانه مثبت نیز داریم، بنابراین یک
117
00:04:15,510 –> 00:04:17,970
شناسه یک خواهد بود و یک نوع رمز
118
00:04:17,970 –> 00:04:19,260
برای بقیه عملگرها داریم، بنابراین
119
00:04:19,260 –> 00:04:22,019
منهای ضرب و تقسیم و ما هستیم
120
00:04:22,019 –> 00:04:23,760
همچنین یک نوع توکن برای
121
00:04:23,760 –> 00:04:26,520
پرانتزها خواهیم داشت، بنابراین یک پرانتز چپ و یک
122
00:04:26,520 –> 00:04:26,870
123
00:04:26,870 –> 00:04:29,630
پرانتز راست و برای اینکه واقعاً
124
00:04:29,630 –> 00:04:31,669
این enum را ایجاد کنیم، باید
125
00:04:31,669 –> 00:04:34,060
آن را از بسته enum Python
126
00:04:34,060 –> 00:04:36,710
وارد کنیم، سپس تعریف می کنیم که یک توکن در واقع
127
00:04:36,710 –> 00:04:38,510
چیست و ما از کلاس داده برای انجام این کار استفاده خواهد کرد
128
00:04:38,510 –> 00:04:41,120
و کلاس داده فقط کلاسی است
129
00:04:41,120 –> 00:04:42,680
که می تواند نگه دارد فیلدها و
130
00:04:42,680 –> 00:04:45,440
مقادیر مختلف بنابراین همانطور که قبلاً دیدیم هر
131
00:04:45,440 –> 00:04:47,479
نشانه یک نوع دارد بنابراین یک فیلد
132
00:04:47,479 –> 00:04:49,940
به نام type ایجاد می کنیم و مقدار آن
133
00:04:49,940 –> 00:04:51,620
باید یکی از انواع توکن هایی باشد که در بالا تعریف کردیم
134
00:04:51,620 –> 00:04:54,500
و همچنین دارای یک فیلد مقدار و
135
00:04:54,500 –> 00:04:56,660
این است. یک نوع e خواهد بود و
136
00:04:56,660 –> 00:04:59,000
بسته به نوع توکن میتواند متفاوت باشد و
137
00:04:59,000 –> 00:05:01,310
بار دیگر همانطور که دیدیم برخی از نشانهها
138
00:05:01,310 –> 00:05:03,229
در واقع مقداری ندارند و بنابراین ما
139
00:05:03,229 –> 00:05:05,150
فقط یک مقدار پیشفرض از هیچ ایجاد میکنیم در
140
00:05:05,150 –> 00:05:07,400
این صورت من.
141
00:05:07,400 –> 00:05:09,289
این روش نمایش را نیز اضافه کردهام، اما نیازی
142
00:05:09,289 –> 00:05:11,389
نیست زیاد نگران این باشید، این
143
00:05:11,389 –> 00:05:13,729
فقط برای اشکالزدایی مفید است، بنابراین اگر ما
144
00:05:13,729 –> 00:05:15,620
یک توکن را در هر مرحله چاپ
145
00:05:15,620 –> 00:05:18,050
کنیم، آن را با فرمت زیبا چاپ میکند، بنابراین
146
00:05:18,050 –> 00:05:21,289
توکن خواهد بود.
147
00:05:21,289 –> 00:05:24,590
فقط در صورتی که دارای یک مقدار باشد، مقدار دو نقطه و دو نقطه را نام ببرید، بنابراین برای
148
00:05:24,590 –> 00:05:26,330
ایجاد این کلاس داده نشانه، یک بار
149
00:05:26,330 –> 00:05:28,850
دیگر باید کلاس داده را
150
00:05:28,850 –> 00:05:31,270
از بسته پایتون کلاس تیلور وارد کنیم،
151
00:05:31,270 –> 00:05:34,160
بنابراین اکنون میتوانیم در نهایت از lexer
152
00:05:34,160 –> 00:05:35,450
شروع کنیم. یک فایل جدید
153
00:05:35,450 –> 00:05:38,360
به نام lecture py ایجاد می کنیم، بنابراین یک
154
00:05:38,360 –> 00:05:41,090
کلاس برای lexer and ایجاد می کنیم در سازنده
155
00:05:41,090 –> 00:05:43,070
، متنی را که پردازش میکنیم، میگیریم،
156
00:05:43,070 –> 00:05:45,200
بنابراین میتوان آن را
157
00:05:45,200 –> 00:05:46,910
برای استفاده بیشتر به متن خودآموز اختصاص داد
158
00:05:46,910 –> 00:05:48,919
و همچنین این متن و
159
00:05:48,919 –> 00:05:50,870
تکرارکننده را میسازیم و اگر مطمئن نیستید
160
00:05:50,870 –> 00:05:52,280
که چیست شما در یک لحظه خواهید دید که چیست،
161
00:05:52,280 –> 00:05:54,410
ما اکنون می خواهیم یک
162
00:05:54,410 –> 00:05:57,050
متد توکن های تولید ایجاد کنیم، بنابراین این
163
00:05:57,050 –> 00:05:58,699
پیام اساساً همان کاری را که می گوید انجام می دهد و
164
00:05:58,699 –> 00:06:00,889
تمام نشانه ها را از متن ورودی تولید می کند،
165
00:06:00,889 –> 00:06:03,590
بنابراین قبل از اینکه ادامه دهیم مهم است
166
00:06:03,590 –> 00:06:05,389
که نیاز به پیگیری
167
00:06:05,389 –> 00:06:07,460
کاراکتر فعلی در هر مرحله در
168
00:06:07,460 –> 00:06:09,470
داخل lexer به روشی که می خواهیم انجام دهیم این
169
00:06:09,470 –> 00:06:11,060
است که یک روش پیشرفته ایجاد می کنیم
170
00:06:11,060 –> 00:06:13,370
تا این روش به
171
00:06:13,370 –> 00:06:15,560
کاراکتر بعدی رفته و آن را در جریان خود نقطه ذخیره کند.
172
00:06:15,560 –> 00:06:18,320
از آنجایی که این
173
00:06:18,320 –> 00:06:20,360
هگز یک تکرارکننده است، میتوانیم از
174
00:06:20,360 –> 00:06:22,400
تابع next Python در متن استفاده کنیم و
175
00:06:22,400 –> 00:06:24,680
این کاراکتر بعدی را به ما میدهد
176
00:06:24,680 –> 00:06:26,360
که در واقع میخواهیم آن را در یک امتحان
177
00:06:26,360 –> 00:06:29,000
بپیچیم، به جز و این نشان میدهد که چه زمانی