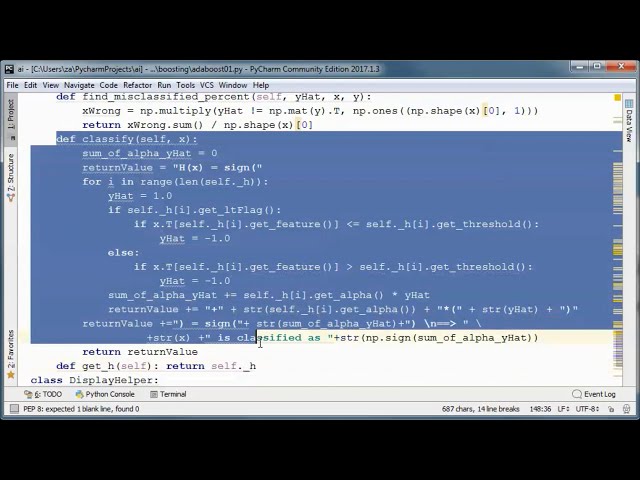
در این مطلب، ویدئو مقدمه ای بر برنامه نویسی موازی با MPI و Python با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:42:14
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:02,340 –> 00:00:05,110
سلام و خوش آمدید به سمینار امروز
2
00:00:05,110 –> 00:00:07,509
که قرار است در مورد
3
00:00:07,509 –> 00:00:11,980
برنامه نویسی موازی با MPI و Python باشد، بنابراین
4
00:00:11,980 –> 00:00:14,800
5
00:00:14,800 –> 00:00:18,730
اگر مشکلی دارید که
6
00:00:18,730 –> 00:00:22,630
به قدری بزرگ است که پیوند
7
00:00:22,630 –> 00:00:25,179
نمی دهد، در یک کامپیوتر کار نمی کند.
8
00:00:25,179 –> 00:00:26,289
قادر به محاسبه آن بر روی
9
00:00:26,289 –> 00:00:28,089
یک کامپیوتر نیست، این امر به ویژه
10
00:00:28,089 –> 00:00:30,729
مهم است زیرا کامپیوترهای منفرد از نظر
11
00:00:30,729 –> 00:00:32,529
12
00:00:32,529 –> 00:00:35,260
13
00:00:35,260 –> 00:00:36,580
14
00:00:36,580 –> 00:00:40,270
عملکرد راکد شده اند.
15
00:00:40,270 –> 00:00:41,740
16
00:00:41,740 –> 00:00:44,020
و متأسفانه لقاح را نمی
17
00:00:44,020 –> 00:00:46,150
توان فقط برای شما توسط کامپایلر انجام داد،
18
00:00:46,150 –> 00:00:48,100
شما باید خودتان کد خطر را بنویسید
19
00:00:48,100 –> 00:00:51,130
کامپایلرها به اندازه کافی هوشمند نیستند
20
00:00:51,130 –> 00:00:53,770
که کد موازی بنویسند و رویکردهای مختلف
21
00:00:53,770 –> 00:00:57,100
فلج کردن از دهه 1990 امتحان شده است
22
00:00:57,100 –> 00:01:00,520
، محبوب ترین روش
23
00:01:00,520 –> 00:01:03,250
ارسال پیام است و این چیزی است که
24
00:01:03,250 –> 00:01:05,979
امروز قرار است در مورد آن صحبت کنیم، بنابراین در
25
00:01:05,979 –> 00:01:08,859
این روش شما یک جفت کامپیوتر
26
00:01:08,859 –> 00:01:11,560
متشکل از چند سریال c دارید.
27
00:01:11,560 –> 00:01:14,469
رایانههایی که این رایانهها حافظه مشترک
28
00:01:14,469 –> 00:01:17,170
ندارند، فضای حافظه مشخصی دارند و بنابراین
29
00:01:17,170 –> 00:01:19,240
باید با شبکه خود ارتباط برقرار کنند و
30
00:01:19,240 –> 00:01:21,609
هر بار که دادهها باید بین شرکتها مبادله شود،
31
00:01:21,609 –> 00:01:24,130
رایانههایی که شما
32
00:01:24,130 –> 00:01:26,770
پیامی ارسال میکنید، این برخلاف
33
00:01:26,770 –> 00:01:29,170
پردازندههای حافظه مشترک حافظه مشترک است که در
34
00:01:29,170 –> 00:01:31,119
آن چندین هسته دارید. و رشتههایی
35
00:01:31,119 –> 00:01:34,509
که روی این هستهها اجرا میشوند فقط
36
00:01:34,509 –> 00:01:36,819
میتوانند به همان منطقه از حافظهها دسترسی داشته باشند که ما مجبور نیستیم
37
00:01:36,819 –> 00:01:39,759
به صراحت دادهها را جابهجا کنیم، اما ارسال پیام
38
00:01:39,759 –> 00:01:41,649
همچنان میتواند در
39
00:01:41,649 –> 00:01:46,090
رایانهای با حافظه مشترک استفاده شود، بنابراین آنچه MPI MPI
40
00:01:46,090 –> 00:01:48,659
مخفف رابط ارسال پیام
41
00:01:48,659 –> 00:01:50,799
است، یک زبان است.
42
00:01:50,799 –> 00:01:53,139
پروتکل ارتباطی مستقل، بنابراین به زبان برنامه نویسی خاصی وابسته نیست، بلکه
43
00:01:53,139 –> 00:01:55,479
44
00:01:55,479 –> 00:01:58,389
مستقل از پلتفرم قابل حمل است و
45
00:01:58,389 –> 00:02:00,759
امروزه استاندارد واقعی برای
46
00:02:00,759 –> 00:02:03,569
محاسبات پرل در سیستم های حافظه توزیع شده است،
47
00:02:03,569 –> 00:02:05,679
این یک استاندارد است، بنابراین
48
00:02:05,679 –> 00:02:08,020
پیاده سازی های مختلفی وجود دارد که محبوب ترین
49
00:02:08,020 –> 00:02:10,270
آنها MPI باز است و نسخه های فروشنده نیز دارید.
50
00:02:10,270 –> 00:02:12,880
بنابراین اگر رایانه خود را خریداری می کنید
51
00:02:12,880 –> 00:02:15,730
و دارای تراشه های اینتل است، می توانید نسخه اینتل
52
00:02:15,730 –> 00:02:18,670
NPI NP را خریداری کنید من بسیار محبوب هستم
53
00:02:18,670 –> 00:02:21,849
و بسیاری از بستهها و کتابخانههای نرمافزار
54
00:02:21,849 –> 00:02:24,549
دارای نسخههای مروارید NPI هستند، اما
55
00:02:24,549 –> 00:02:27,099
اشکال اصلی این است
56
00:02:27,099 –> 00:02:30,220
که برنامهنویسی یک NPI بسیار سخت است،
57
00:02:30,220 –> 00:02:32,950
برنامهنویسی موازی آن برای
58
00:02:32,950 –> 00:02:35,080
رایانههای پوشاک معمولاً سخت است، زیرا تصور
59
00:02:35,080 –> 00:02:37,420
میکردید نوشتن برای آن سخت است. یک
60
00:02:37,420 –> 00:02:39,160
برنامه واحد برای یک کامپیوتر واحد
61
00:02:39,160 –> 00:02:41,440
که قبلاً به اندازه کافی سخت است و سپس در
62
00:02:41,440 –> 00:02:42,910
بالای آن شما عارضه اضافی را اضافه می کنید
63
00:02:42,910 –> 00:02:45,090
که اکنون چندین
64
00:02:45,090 –> 00:02:49,660
رایانه دارید که یک رایانه مروارید را تشکیل می دهند بنابراین همانطور
65
00:02:49,660 –> 00:02:51,430
که گفتم NPI یک زبان برنامه نویسی جدید
66
00:02:51,430 –> 00:02:53,799
نیست بلکه یک مجموعه است. از
67
00:02:53,799 –> 00:02:57,310
توابع و ماکروهای موجود در کتابخانه که
68
00:02:57,310 –> 00:02:59,970
می توانند در برنامه های نوشته شده در C ++
69
00:02:59,970 –> 00:03:02,379
fortran و Python استفاده شوند همانطور که خواهیم دید و
70
00:03:02,379 –> 00:03:05,920
در Python MPI از طریق
71
00:03:05,920 –> 00:03:08,379
کد ماژول و py برای py
72
00:03:08,379 –> 00:03:11,079
در دسترس است در حال حاضر اکثر برنامه های MPI عملاً
73
00:03:11,079 –> 00:03:13,150
همه آنها مبتنی هستند. در یک
74
00:03:13,150 –> 00:03:16,150
برنامه یک مدل داده چندگانه به این
75
00:03:16,150 –> 00:03:18,720
معنی است که شما یک برنامه واحد می نویسید
76
00:03:18,720 –> 00:03:22,810
اما وقتی آن را شروع می کنید فقط
77
00:03:22,810 –> 00:03:24,819
یک نسخه از برنامه را اجرا نمی کنید چندین
78
00:03:24,819 –> 00:03:27,190
نسخه را اجرا کنید تا چندین کلون از
79
00:03:27,190 –> 00:03:30,190
برنامه را روی پردازنده های مختلف در رایانه پرل خود اجرا کنید،
80
00:03:30,190 –> 00:03:34,810
اما هر کلون می تواند از
81
00:03:34,810 –> 00:03:37,510
داده های ورودی برای تصمیم گیری در مورد اینکه چه کاری انجام دهد استفاده کند،
82
00:03:37,510 –> 00:03:39,849
بنابراین هر کلون داده های ورودی کمی متفاوت دریافت می کند
83
00:03:39,849 –> 00:03:41,829
و بر این اساس
84
00:03:41,829 –> 00:03:43,480
می تواند کارهای کمی متفاوت انجام دهد. و
85
00:03:43,480 –> 00:03:46,150
سپس همانطور که برنامه شما این کلون ها را اجرا می کند،
86
00:03:46,150 –> 00:03:48,280
این نمونه ها می توانند
87
00:03:48,280 –> 00:03:52,120
با یکدیگر ارتباط برقرار کنند، بنابراین MPI در پایتون
88
00:03:52,120 –> 00:03:54,519
از طریق یک رپر بسیار زیبا
89
00:03:54,519 –> 00:03:58,750
به نام NPRM pi/4 py در دسترس قرار می گیرد، این یک
90
00:03:58,750 –> 00:04:01,989
رویکرد شی گرا است، زیرا تمام
91
00:04:01,989 –> 00:04:04,660
پایتون این است که می توانم بگویم بسیار کاربر است. دوستانه
92
00:04:04,660 –> 00:04:08,260
و بسیار ساده تر از استفاده از Python در
93
00:04:08,260 –> 00:04:10,629
زبانی مانند C یا C++ کد Fortran،
94
00:04:10,629 –> 00:04:14,769
عمدتاً به این دلیل که فراخوانی و تابع MPI
95
00:04:14,769 –> 00:04:18,370
در C مستلزم آن است که
96
00:04:18,370 –> 00:04:20,738
تعدادی آرگومان ارائه دهید، آرگومان های زیادی وجود دارد، حتی
97
00:04:20,738 –> 00:04:22,419
اگر از آنها استفاده نمی کنید، باید
98
00:04:22,419 –> 00:04:23,950
آنها را ارائه دهید. شما باید منظور آنها را بفهمید
99
00:04:23,950 –> 00:04:27,159
در حالی که در پایتون، بستهبندی API
100
00:04:27,159 –> 00:04:28,370
101
00:04:28,370 –> 00:04:31,280
برخی از مقادیر آرگومان را حدس میزند، بنابراین اگر
102
00:04:31,280 –> 00:04:32,780
مقدار را ارائه نکنید،
103
00:04:32,780 –> 00:04:34,280
حدس منطقی میدهد که کدام عمل معمولاً
104
00:04:34,280 –> 00:04:36,110
استفاده از آن را برای مبتدیان بسیار سادهتر میکند،
105
00:04:36,110 –> 00:04:38,510
بنابراین در اینجا پیوندهایی که
106
00:04:38,510 –> 00:04:41,180
میتوانید NPI را برای py پیدا کنید و اسناد را
107
00:04:41,180 –> 00:04:43,970
برای بهترین نتایج پیدا کنید، سعی کنید از آخرین نسخه غارت کنید،
108
00:04:43,970 –> 00:04:46,220
به عنوان مثال اگر
109
00:04:46,220 –> 00:04:49,100
NPI NPI برای py را در جعبه اوبونتو خود نصب میکنید.
110
00:04:49,100 –> 00:04:51,800
ممکن است در واقع یک نسخه قدیمیتر را نصب کند
111
00:04:51,800 –> 00:04:54,110
که باگ است و مستندات ضعیفی دارد،
112
00:04:54,110 –> 00:04:55,760
بنابراین واقعاً سعی کنید
113
00:04:55,760 –> 00:04:57,860
آخرین نسخه را دریافت کنید و سپس وقتی
114
00:04:57,860 –> 00:05:00,080
همه چیز را نصب کردید، روش اجرای
115
00:05:00,080 –> 00:05:03,080
برنامه Python MPI شما به این صورت است
116
00:05:03,080 –> 00:05:04,960
، بنابراین اولین دستور الگو و
117
00:05:04,960 –> 00:05:07,220
سپس شماره است. فرآیند فرآیند
118
00:05:07,220 –> 00:05:08,750
ابتدا پردازشهایی را که میخواهید انجام میشود،
119
00:05:08,750 –> 00:05:11,300
بنابراین NPI اجرا میشود، اساساً این
120
00:05:11,300 –> 00:05:12,979
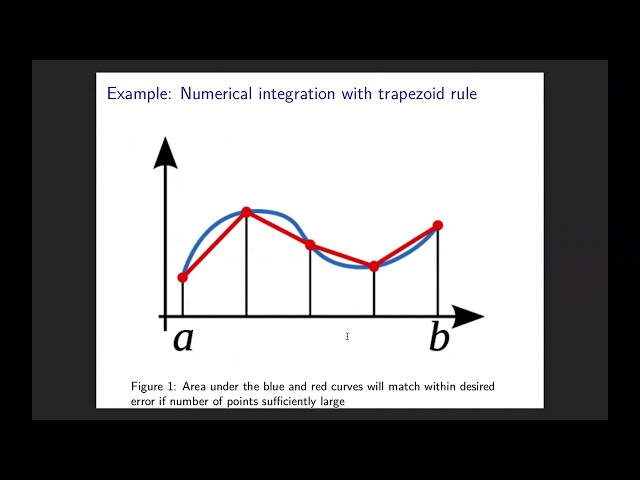
مکانیسمی است که کریل
121
00:05:12,979 –> 00:05:15,169
کلونهای برنامه شما را ایجاد میکند و پرچم خالی
122
00:05:15,169 –> 00:05:17,449
نشان میدهد که چند کلون
123
00:05:17,449 –> 00:05:19,550
میخواهید و سپس دستور پایتون و
124
00:05:19,550 –> 00:05:22,820
برنامه پایتون خود را دارید، بنابراین اگر به طور
125
00:05:22,820 –> 00:05:25,550
مقدماتی این کار را انجام دهید. در اینجا برخی از
126
00:05:25,550 –> 00:05:28,370
واژگانی است که در ادامه این بحث استفاده خواهم کرد،
127
00:05:28,370 –> 00:05:31,010
بنابراین فرآیند نمونه ای از یک
128
00:05:31,010 –> 00:05:34,240
مشکل است که می توان آن را ایجاد کرد یا از بین برد
129
00:05:34,240 –> 00:05:37,250
MPI از گروهی از همه به طور ایستا استفاده می کند.
130
00:05:37,250 –> 00:05:39,710
فرآیندهای ocated هنگامی که یک برنامه MPI را
131
00:05:39,710 –> 00:05:41,840
با اجرای MPI راه اندازی می کنید، مشخص می کنید که چه تعداد
132
00:05:41,840 –> 00:05:44,120
فرآیند می خواهید و این
133
00:05:44,120 –> 00:05:46,490
تعداد فرآیندهایی است که در
134
00:05:46,490 –> 00:05:47,990
طول اجرای برنامه به صورت ایستا مطالعه می شوند، این
135
00:05:47,990 –> 00:05:50,599
برخلاف رشته ها در مدل خواندن منحصر به فرد است
136
00:05:50,599 –> 00:05:52,130
که می توانید رشته ها را ایجاد و از بین ببرید.
137
00:05:52,130 –> 00:05:54,410
برنامه شما در MPI در حال انجام است،
138
00:05:54,410 –> 00:05:57,919
تعداد فرآیندها در حال حاضر ثابت است، در
139
00:05:57,919 –> 00:06:00,199
حالی که برنامه MPI در حال اجرا
140
00:06:00,199 –> 00:06:02,960
است، همانطور که قبلاً گفتم به هر فرآیند یا کلون
141
00:06:02,960 –> 00:06:06,110
یک شماره یا رتبه منحصر به فرد اختصاص داده می شود، بنابراین اگر
142
00:06:06,110 –> 00:06:08,690
پردازش های P دارید، رتبه ها
143
00:06:08,690 –> 00:06:12,979
0 تا P هستند. منهای 1 اکنون وقتی
144
00:06:12,979 –> 00:06:14,449
برنامه خود را اجرا می کنید، تعداد
145
00:06:14,449 –> 00:06:16,490
فرآیندهایی که ایجاد می کنید
146
00:06:16,490 –> 00:06:18,169
لزوماً تعداد پردازنده های
147
00:06:18,169 –> 00:06:20,840
رایانه شما نیست، بنابراین می توانید یک هسته تک هسته
148
00:06:20,840 –> 00:06:23,810
ای در رایانه خود داشته باشید و بیش
149
00:06:23,810 –> 00:06:26,060
از یک فرآیند را اجرا کنید، اما به طور کلی برای
150
00:06:26,060 –> 00:06:28,220
رسیدن به سرعت perros- در بالا، شما باید
151
00:06:28,220 –> 00:06:31,910
یک فرآیند در هر هسته داشته باشید، بنابراین اشکالی ندارد که
152
00:06:31,910 –> 00:06:34,070
بدانید اگر فقط 4 هسته در
153
00:06:34,070 –> 00:06:35,900
رایانه خود دارید، می توانید یک فرآیند
154
00:06:35,900 –> 00:06:39,950
MPI را با برنامه 32 MPI با 32 فرآیند
155
00:06:39,950 –> 00:06:41,380
فقط برای اشکال زدایی راه اندازی کنید.
156
00:06:41,380 –> 00:06:42,430
اما در واقع سرعت موازی به شما نمی
157
00:06:42,430 –> 00:06:45,850
دهد، بنابراین این فرآیندهایی
158
00:06:45,850 –> 00:06:48,310
که NPI ایجاد می کند، هر کدام دارای
159
00:06:48,310 –> 00:06:50,980
فضای حافظه مجزا هستند بنابراین نمی توانند
160
00:06:50,980 –> 00:06:54,070
مستقیماً به داده های یکدیگر دسترسی داشته باشند، بنابراین
161
00:06:54,070 –> 00:06:55,870
اگر نیاز به ارسال داده ها بین یک
162
00:06:55,870 –> 00:06:59,260
فرآیند و فرآیند دیگر دارید و تقریباً همیشه
163
00:06:59,260 –> 00:07:02,230
دارید به این دلیل که می دانید اگر در حال
164
00:07:02,230 –> 00:07:04,780
نوشتن یک برنامه Perl هستید، فرآیندهای شما
165
00:07:04,780 –> 00:07:06,490
باید به نحوی با یکدیگر هماهنگ شوند
166
00:07:06,490 –> 00:07:08,470
و داده ها را مبادله کنند، بنابراین برای
167
00:07:08,470 –> 00:07:10,090
برقراری ارتباط داده ها باید به
168
00:07:10,090 –> 00:07:13,720
فراخوانی های عملکرد واضح هر دو در
169
00:07:13,720 –> 00:07:16,090
فرآیندی که داده ها را ارسال می کند کمک کنید که
170
00:07:16,090 –> 00:07:18,160
از نوعی ارسال استفاده می کند. تابع
171
00:07:18,160 –> 00:07:19,690
و فرآیندی که دادهها را دریافت میکند و
172
00:07:19,690 –> 00:07:21,460
باید از نوعی
173
00:07:21,460 –> 00:07:24,160
تابع دریافت استفاده کند و برای اینکه این ارتباط با
174
00:07:24,160 –> 00:07:27,010
موفقیت انجام شود هم بهعنوان ارسال
175
00:07:27,010 –> 00:07:28,950
و هم دریافت باید به ترتیب در
176
00:07:28,950 –> 00:07:30,850
فرآیند ارسال و فرآیند دریافت
177
00:07:30,850 –> 00:07:32,770
اجرا
178
00:07:32,770 –> 00:07:36,910
شود تا ارتباط موفقیتآمیز باشد.
179
00:07:36,910 –> 00:07:40,870
بنابراین یک برنامه MPI در پایتون چگونه به نظر می
180
00:07:40,870 –> 00:07:42,340
رسد، اجازه دهید فقط اسکلت کلی را به شما ارائه دهم
181
00:07:42,340 –> 00:07:45,820
تا ابتدا MPI را وارد کنید.
182
00:07:45,820 –> 00:07:48,610
برای ماژول py یا از دجال وارد می کنید،
183
00:07:48,610 –> 00:07:51,820
سپس MPI را مقداردهی اولیه می کنید و سپس
184
00:07:51,820 –> 00:07:54,790
محاسبات خود را انجام می دهید، در حالی که
185
00:07:54,790 –> 00:07:56,800
محاسبات خود را انجام می دهید، از ارتباطات MPI MPI
186
00:07:56,800 –> 00:07:58,660
برای تبادل داده ها در صورت
187
00:07:58,660 –> 00:08:00,910
نیاز استفاده می کنید، اکنون پس
188
00:08:00,910 –> 00:08:05,650
از اتمام کار، MPI را خاموش می کنید، بنابراین اجازه دهید در مورد آن صحبت کنم. برخی
189
00:08:05,650 –> 00:08:07,660
از ابزارهایی که قرار است استفاده کنیم
190
00:08:07,660 –> 00:08:09,490
قبل از اینکه اولین نمونه برنامه را به شما نشان دهم،
191
00:08:09,490 –> 00:08:13,210
بنابراین ابتدا باید شیء ارتباطی MPI خود را
192
00:08:13,210 –> 00:08:15,400
ایجاد کنم و
193
00:08:15,400 –> 00:08:17,020
سپس از متدهای این
194
00:08:17,020 –> 00:08:20,310
شیء برای ارتباطات واقعی استفاده خواهم کرد، بنابراین من
195
00:08:20,310 –> 00:08:23,500
NPI برای ماژول py یا در این
196
00:08:23,500 –> 00:08:25,840
مورد من MPI را از ماژول وارد
197
00:08:25,840 –> 00:08:29,230
می کنم و ارتباط دهنده خود را در خط دوم ایجاد می کنم
198
00:08:29,230 –> 00:08:33,280
بنابراین این ارتباط دهنده
199
00:08:33,280 –> 00:08:36,039
روش های مختلفی دارد بنابراین روش ارسال در
200
00:08:36,039 –> 00:08:38,049
اینجا نشان داده می شود بنابراین اگر می خواهم چیزی بفرستم
201
00:08:38,049 –> 00:08:41,860
به نام comm send و این
202
00:08:41,860 –> 00:08:45,040
دارای سه آرگومان است، بنابراین اولین آرگومان
203
00:08:45,040 –> 00:08:47,380
جدا از self است، اولین
204
00:08:47,380 –> 00:08:49,120
آرگومان شی واقعی است که شما ارسال می کنید، بنابراین هر چیزی را که می خواهید آرگومان دوم i ارسال
205
00:08:49,120 –> 00:08:52,330
کنید، عدد صحیح خود را ارائه دهید یا float
206
00:08:52,330 –> 00:08:54,580
یا آرایه خود را
207
00:08:54,580 –> 00:08:58,959
آرگومان مقصد
208
00:08:58,959 –> 00:09:01,330
است، بنابراین در اینجا
209
00:09:01,330 –> 00:09:02,860
تعداد فرآیندی را که میخواهید این
210
00:09:02,860 –> 00:09:05,860
اطلاعات به آنجا برود را مشخص میکنید و آرگومان نهایی
211
00:09:05,860 –> 00:09:08,320
یک آرگومان اختیاری، آرگومان برچسب است،
212
00:09:08,320 –> 00:09:10,899
بنابراین میتوانید پیام خود را برچسب گذاری کنید که به
213
00:09:10,899 –> 00:09:13,690
شما امکان میدهد بین آنها تمایز قائل شوید، ما
214
00:09:13,690 –> 00:09:15,550
از این استفاده نخواهیم کرد. استدلال در مثالهای ما،
215
00:09:15,550 –> 00:09:18,040
اما گاهی اوقات
216
00:09:18,040 –> 00:09:20,230
مهم است که مطمئن
217
00:09:20,230 –> 00:09:23,250
شوید پیامهای مناسب به مقصد میرسند،
218
00:09:23,250 –> 00:09:26,620
بنابراین روش ارسال به این صورت است که
219
00:09:26,620 –> 00:09:29,230
اگر شیء ارسالی شما به
220
00:09:29,230 –> 00:09:31,779
اندازه کافی کوچک باشد، برنامه شما ممکن است در
221
00:09:31,779 –> 00:09:34,690
واقع از فراخوان ارسال عبور کند. حتی اگر
222
00:09:34,690 –> 00:09:36,790
پیام شما واقعاً به مقصد نرسیده باشد
223
00:09:36,790 –> 00:09:38,769
که در واقع خوب است
224
00:09:38,769 –> 00:09:40,870
زیرا این بدان معناست که برنامه شما
225
00:09:40,870 –> 00:09:43,690
همیشه در آن نقطه متوقف نمی شود تا
226
00:09:43,690 –> 00:09:45,190
زمانی که پیام واقعاً
227
00:09:45,190 –> 00:09:47,050
به مقصد برسد، اما می تواند ادامه دهد
228
00:09:47,050 –> 00:09:49,329
اما فقط فضای بافر بزرگ است.
229
00:09:49,329 –> 00:09:50,800
به اندازه کافی بنابراین اگر شیئی که می
230
00:09:50,800 –> 00:09:53,980
فرستید خیلی بزرگ باشد فضای بافر
231
00:09:53,980 –> 00:09:55,630
کافی نخواهد بود و سپس برنامه شما
232
00:09:55,630 –> 00:09:58,029
در مجموعه متوقف می شود. فرآیند دیگری اطلاعات
233
00:09:58,029 –> 00:10:00,880
را دریافت و انتقال می
234
00:10:00,880 –> 00:10:05,160
دهد، بنابراین در اینجا ما
235
00:10:05,160 –> 00:10:07,899
دومین فرآیند مرتبط را داریم، این
236
00:10:07,899 –> 00:10:12,100
فرآیند دریافت است، بنابراین روش دریافت
237
00:10:12,100 –> 00:10:14,860
است، بنابراین شما این را در فرآیندی
238
00:10:14,860 –> 00:10:17,620
که برای دریافت داده ها است فراخوانی کنید، بنابراین
239
00:10:17,620 –> 00:10:21,160
آرگومان ها خوب هستند شما آرگومان بافر
240
00:10:21,160 –> 00:10:23,649
را دارید. و این
241
00:10:23,649 –> 00:10:26,380
شیء را خواهد داشت که دادههای
242
00:10:26,380 –> 00:10:28,899
دریافتی را ذخیره میکند، سپس آرگومان منبع
243
00:10:28,899 –> 00:10:33,490
نشان میدهد که شما
244
00:10:33,490 –> 00:10:36,040
این دادهها را از کدام فرآیند دریافت میکنید، بنابراین اگر
245
00:10:36,040 –> 00:10:39,010
این را ارائه ندهید، در واقع از یک
246
00:10:39,010 –> 00:10:41,320
وایلدکارت هر منبعی استفاده میکند. فقط
247
00:10:41,320 –> 00:10:43,449
یک پیام را بدون توجه به اینکه از کجا می آید بپذیرید،
248
00:10:43,449 –> 00:10:45,610
249
00:10:45,610 –> 00:10:47,649
اما به طور کلی ناامن است،
250
00:10:47,649 –> 00:10:49,570
بنابراین مهم است که مشخص کنید
251
00:10:49,570 –> 00:10:51,399
کدام فرآیند می
252
00:10:51,399 –> 00:10:53,290
خواهید پیام را از تگ
253
00:10:53,290 –> 00:10:55,779
دریافت کنید دوباره اختیاری است و در تماس دریافتی
254
00:10:55,779 –> 00:10:57,459
که دارید یک آرگومان اضافی به نام
255
00:10:57,459 –> 00:10:59,829
status که به شما امکان می دهد برخی از
256
00:10:59,829 –> 00:11:02,260
داده ها را در مورد پیام پرس و جو کنید اما مقدار پیش فرض
257
00:11:02,260 –> 00:11:04,000
آن هیچ است و ما از
258
00:11:04,000 –> 00:11:06,830
این مقدار استفاده نخواهیم کرد.
259
00:11:06,830 –> 00:11:11,750
روشی که اگر
260
00:11:11,750 –> 00:11:14,840
تماس دریافت را فراخوانی کنید، برنامه
261
00:11:14,840 –> 00:11:17,090
همیشه متوقف میشود تا زمانی که پیام واقعاً دریافت شود، برنامه شما در آنجا متوقف میشود
262
00:11:17,090 –> 00:11:18,830
، بنابراین این به طور کامل
263
00:11:18,830 –> 00:11:20,600
مسدود میکند که پیام باید قبل از
264
00:11:20,600 –> 00:11:23,030
ادامه کار برنامه شما بمیرد، به این معنی که برای
265
00:11:23,030 –> 00:11:25,610
مثال اگر یک تماس دریافت داشته باشید. که
266
00:11:25,610 –> 00:11:28,340
با برخی از تماس های ارسال شده در فرآیند دیگری مطابقت ندارد،
267
00:11:28,340 –> 00:11:30,260
برنامه شما به بن بست می رسد،
268
00:11:30,260 –> 00:11:32,030
زیرا فقط برای همیشه منتظر می ماند
269
00:11:32,030 –> 00:11:34,340
تا پیام برسد، بنابراین به طور کلی
270
00:11:34,340 –> 00:11:36,650
مهم است که هنگام نوشتن برنامه
271
00:11:36,650 –> 00:11:38,930
خود مطمئن شوید که برای هر ارسال، یک
272
00:11:38,930 –> 00:11:41,180
دریافت منطبق دارید. همیشه باید به
273
00:11:41,180 –> 00:11:45,650
صورت جفت باشند، بنابراین این رتبه ها چه هستند
274
00:11:45,650 –> 00:11:48,920
برای ارسال یک پیام، باید بدانم
275
00:11:48,920 –> 00:11:51,380
رتبه خودم چیست و در کل چند پردازش وجود
276
00:11:51,380 –> 00:11:53,660
دارد، بنابراین یک روش رتبه بندی وجود دارد،
277
00:11:53,660 –> 00:11:55,520
بنابراین اگر در هر
278
00:11:55,520 –> 00:11:58,010
فرآیند خاصی با آن تماس بگیرید، برمی گردد.
279
00:11:58,010 –> 00:12:02,800
تعداد این فرآیند و متد get size
280
00:12:02,800 –> 00:12:06,500
برمیگرداند که چه تعداد پردازش در
281
00:12:06,500 –> 00:12:09,260
ارتباطدهنده ما وجود دارد، بنابراین این عدد
282
00:12:09,260 –> 00:12:11,210
از MK Ron میآید.
283
00:12:11,210 –> 00:12:13,730
n –
284
00:12:13,730 –> 00:12:16,340
خالی و سپس 4 یا چیزی اگر 4 داشته باشیم،
285
00:12:16,340 –> 00:12:20,900
سپس getsize به 4 برمی گردد، بنابراین با
286
00:12:20,900 –> 00:12:23,150
این مقدمات خارج از مسیر، اجازه دهید در
287
00:12:23,150 –> 00:12:27,800
واقع به اولین برنامه اصلی MPI خود نگاه کنیم
288
00:12:27,800 –> 00:12:30,470
و تمام کاری که این برنامه Entei
289
00:12:30,470 –> 00:12:34,540
انجام می دهد این است که هر فرآیند موازی را داشته باشد.
290
00:12:34,540 –> 00:12:37,220
نیست که دارای رتبه 0 نیست
291
00:12:37,220 –> 00:12:40,040
، برای پردازشی که دارای رتبه 0 است، پیامی ارسال می کند
292
00:12:40,040 –> 00:12:42,440
و سپس فرآیندی که دارای رتبه
293
00:12:42,440 –> 00:12:46,220
0 است، آن پیام را نشان می دهد، بنابراین بیایید از
294
00:12:46,220 –> 00:12:49,100
طریق این کار کنیم، بنابراین ابتدا از MPI
295
00:12:49,100 –> 00:12:52,940
برای ماژول py وارد می کنیم و ارتباط دهنده خود را راه اندازی می کنیم.
296
00:12:52,940 –> 00:12:55,460
باید در نظر داشته باشید که این
297
00:12:55,460 –> 00:12:58,580
برنامه چندین نسخه از این برنامه
298
00:12:58,580 –> 00:13:00,890
روی فرآیندهای مختلف اجرا می شود، بنابراین
299
00:13:00,890 –> 00:13:02,960
باید تصور کنید که این برنامه
300
00:13:02,960 –> 00:13:04,970
تعداد زیادی کلون از آن در یک زمان اجرا می شود،
301
00:13:04,970 –> 00:13:07,850
اما وقتی به این خط می رسیم،
302
00:13:07,850 –> 00:13:10,970
هر یک از این کلون ها فراخوانی می شوند. رتبه و
303
00:13:10,970 –> 00:13:14,930
سپس رتبه من شماره
304
00:13:14,930 –> 00:13:17,150
شناسه رتبه هر فرآیند را ذخیره می کند و این
305
00:13:17,150 –> 00:13:19,460
در هر فرآیند متفاوت خواهد بود، بنابراین فرآیندی وجود
306
00:13:19,460 –> 00:13:20,550
خواهد داشت که
307
00:13:20,550 –> 00:13:21,870
ما رتبه بندی می کنیم صفر است،
308
00:13:21,870 –> 00:13:23,670
فرآیندی با رتبه یک و غیره تا
309
00:13:23,670 –> 00:13:26,520
P وجود دارد. متر inus 1 که در آن P تعداد کل
310
00:13:26,520 –> 00:13:28,950
فرآیندهایی است که شما شروع کرده اید و در واقع ما می
311
00:13:28,950 –> 00:13:32,010
توانیم آن مقدار را در اینجا به دست آوریم، بنابراین با فراخوانی get
312
00:13:32,010 –> 00:13:35,040
size، متوجه می شویم که P چیست و PZ
313
00:13:35,040 –> 00:13:39,300
تعداد کل فرآیندها، بنابراین اینجا ما اینجا هستیم که در
314
00:13:39,300 –> 00:13:41,160
آن واگرایی در رتبه های بسیار متفاوت رخ می دهد.
315
00:13:41,160 –> 00:13:42,930
کارهای مختلفی انجام خواهد داد،
316
00:13:42,930 –> 00:13:45,600
بنابراین میخواهم اتفاقی که میخواهم در اینجا بیفتد
317
00:13:45,600 –> 00:13:49,380
، همه رتبههایی است که رتبه 0
318
00:13:49,380 –> 00:13:52,020
ندارند، بنابراین رتبه 1 رتبه 2 آنها یک
319
00:13:52,020 –> 00:13:55,050
پیام ایجاد میکنند و این پیام را
320
00:13:55,050 –> 00:13:57,420
برای پردازش 0 ارسال میکنند، بنابراین پیام یک رشته است.
321
00:13:57,420 –> 00:14:02,220
حاوی رتبه و سپس comm dots است
322
00:14:02,220 –> 00:14:05,160
و سپس این پیام را برای پردازش 0
323
00:14:05,160 –> 00:14:08,460
این کشور 0 می فرستد و سپس مورد دیگر در اینجا
324
00:14:08,460 –> 00:14:12,000
کد دیگری است که زمانی اجرا می شود
325
00:14:12,000 –> 00:14:15,720
که رتبه 0 باشد بنابراین در فرآیند 0 یک حلقه وجود دارد
326
00:14:15,720 –> 00:14:18,300
زیرا فرآیند 0 می خواهد
327
00:14:18,300 –> 00:14:20,970
این پیام را دریافت کند. از هر فرآیند دیگر،
328
00:14:20,970 –> 00:14:25,530
بنابراین یک حلقه برای شناسه proc در محدوده 1 تا
329
00:14:25,530 –> 00:14:31,140
P منهای 1 وجود دارد و ما comm را دریافت میکنیم، بنابراین
330
00:14:31,140 –> 00:14:33,000
این پیام را دریافت میکند و
331
00:14:33,000 –> 00:14:36,060
منبع را مشخص میکنیم و منبع متغیر حلقه
332
00:14:36,060 –> 00:14:39,030
است، بنابراین منبع 1 و 2
333
00:14:39,030 –> 00:14:40,170
و 3 خواهد بود. و غیره
334
00:14:40,170 –> 00:14:42,810
و O را چاپ می کنیم پیامی را که
335
00:14:42,810 –> 00:14:46,830
دریافت می کنیم، خروجی شبیه به این است، بنابراین
336
00:14:46,830 –> 00:14:50,310
من MPA را اجرا می کنم – NP به این معنی که من
337
00:14:50,310 –> 00:14:53,250
MPI را فراخوانی کردم، چهار فرآیند برنامه idon.t ایجاد می
338
00:14:53,250 –> 00:14:57,120
کنم و یک پیام دریافت می کنم، بنابراین در اینجا
339
00:14:57,120 –> 00:14:59,580
فرآیند 0 چاپ می شود و protis 0
340
00:14:59,580 –> 00:15:01,620
پیام را دریافت می کند. از فرآیند 1
341
00:15:01,620 –> 00:15:04,230
تا پردازش رایگان و آن را چاپ می
342
00:15:04,230 –> 00:15:07,920
کند، بنابراین در اینجا برنامه اصلی MPI
343
00:15:07,920 –> 00:15:12,000
ما است که به ما نشان می دهد MPA چه کاری انجام می دهد، اما آن
344
00:15:12,000 –> 00:15:14,220
برنامه خیلی جالب نیست، بنابراین بیایید در
345
00:15:14,220 –> 00:15:15,720
واقع سعی کنیم چیزی را محاسبه کنیم
346
00:15:15,720 –> 00:15:18,360
زیرا این همان چیزی است که ما معمولاً
347
00:15:18,360 –> 00:15:21,330
از برنامه نویسی موازی MPI برای آن استفاده خواهیم کرد. بنابراین
348
00:15:21,330 –> 00:15:24,960
بیایید یک انتگرال را محاسبه کنیم و
349
00:15:24,960 –> 00:15:27,180
موقعیتهای زیادی وجود دارد که یک انتگرال باید
350
00:15:27,180 –> 00:15:28,650
آن را محاسبه
351
00:15:28,650 –> 00:15:30,990
کند اغلب اوقات
352
00:15:30,990 –> 00:15:33,750
شما نمیدانید یک فرم بسته را میشناسید، بنابراین
353
00:15:33,750 –> 00:15:34,470
پاسخ انتگرال است،
354
00:15:34,470 –> 00:15:37,320
بنابراین اساسیترین و اساسیترین راه برای
355
00:15:37,320 –> 00:15:40,140
انتگرال کامپیوتری است. منحنی آبی در
356
00:15:40,140 –> 00:15:44,100
اینجا برای ایجاد یک منحنی قرمز است که از
357
00:15:44,100 –> 00:15:46,680
قطعات خط مستقیم ساخته شده است و می بینید
358
00:15:46,680 –> 00:15:49,220
که مساحت زیر منحنی آبی
359
00:15:49,220 –> 00:15:51,690
تقریباً برابر با مساحت زیر
360
00:15:51,690 –> 00:15:53,880
منحنی قرمز است و شما می توانید ببینید که
361
00:15:53,880 –> 00:15:56,730
قطعات زیر منحنی قرمز ذوزنقه هستند،
362
00:15:56,730 –> 00:15:59,190
بنابراین به این روش ذوزنقه می گویند
363
00:15:59,190 –> 00:16:01,950
و اگر
364
00:16:01,950 –> 00:16:03,840
تعداد نقاط را افزایش دهیم و
365
00:16:03,840 –> 00:16:06,420
ذوزنقه خود را کوچکتر و کوچکتر کنیم،
366
00:16:06,420 –> 00:16:08,430
معمولاً سطح زیر منحنی قرمز
367
00:16:08,430 –> 00:16:10,530
تقریباً به سطح زیر می رسد.
368
00:16:10,530 –> 00:16:12,180
منحنی آبی آبی و البته آنچه در
369
00:16:12,180 –> 00:16:14,100
مورد ناحیه در منحنی قرمز خوب است
370
00:16:14,100 –> 00:16:18,660
این است که آن ناحیه دارای یک عبارت بسته بسیار زیبا است،
371
00:16:18,660 –> 00:16:20,850
فقط یک دسته از
372
00:16:20,850 –> 00:16:24,720
مناطق ذوزنقه ای است، بنابراین اینجا
373
00:16:24,720 –> 00:16:26,940
نوشته شده است ما انتگرال برخی از
374
00:16:26,940 –> 00:16:29,310
تابع های خود را از A تا داریم. B را می توان
375
00:16:29,310 –> 00:16:32,610
با این فرمول تقریب زد که فقط
376
00:16:32,610 –> 00:16:34,260
مساحت ذوزنقه ها است همانطور که من آنها را ترسیم کردم،
377
00:16:34,260 –> 00:16:38,160
بنابراین روشی که می توانیم به طور موازی آن را محاسبه کنیم این
378
00:16:38,160 –> 00:16:41,130
است که می توانیم قطعه خود را از
379
00:16:41,130 –> 00:16:44,580
A به B ببریم و می توانیم آن را به
380
00:16:44,580 –> 00:16:47,970
قطعات کوچکتر تقسیم کنیم. سپس فرآیند 0
381
00:16:47,970 –> 00:16:50,460
انتگرال را از A به A
382
00:16:50,460 –> 00:16:54,060
به اضافه n بر روی فرآیند pH 1 محاسبه می کنیم، بخش بعدی را انجام می دهیم به
383
00:16:54,060 –> 00:16:56,640
طوری که هر
384
00:16:56,640 –> 00:16:59,670
بخش روی ناحیه کوچکتری با
385
00:16:59,670 –> 00:17:02,910
تعداد قطعات کمتر کار می کند، بنابراین هر فرآیند
386
00:17:02,910 –> 00:17:06,480
انجام می دهد. بخشی از انتگرال و سپس
387
00:17:06,480 –> 00:17:08,369
میخواهیم نتایج را جمعآوری کنیم و آنها را با هم جمع کنیم
388
00:17:08,369 –> 00:17:10,829
و این یک مقدار پیشفرض ok انتگرال را به ما میدهد،
389
00:17:10,829 –> 00:17:13,410
بنابراین بیایید یک
390
00:17:13,410 –> 00:17:16,560
تابع ساده را برای ادغام انتخاب کنیم، ما میتوانیم
391
00:17:16,560 –> 00:17:18,750
هر چیزی را که x مربع میگیرم انتخاب کنیم،
392
00:17:18,750 –> 00:17:20,939
زیرا چیز خوبی است. در مورد آن است
393
00:17:20,939 –> 00:17:23,099
که من می دانم دسته واقعی آن در برابر یا
394
00:17:23,099 –> 00:17:25,079
خارجی است، بنابراین مقایسه
395
00:17:25,079 –> 00:17:28,410
نتایج عددی ما با نتیجه کامل آسان خواهد بود،
396
00:17:28,410 –> 00:17:32,370
بنابراین من تابعی می نویسم تا
397
00:17:32,370 –> 00:17:36,630
با استفاده از
398
00:17:36,630 –> 00:17:39,750
روش ذوزنقه، یک محاسبه سریالی از روش ذوزنقه ای انجام دهم، بنابراین اگر از یک
399
00:17:39,750 –> 00:17:43,590
واحد استفاده می کردم کامپیوتر و من در حال محاسبه
400
00:17:43,590 –> 00:17:46,110
انتگرال از A به B با استفاده از n ذوزنقه
401
00:17:46,110 –> 00:17:48,030
و طول هر مرحله
402
00:17:48,030 –> 00:17:49,920
بودم، بنابراین H خواهد
403
00:17:49,920 –> 00:17:51,750
404
00:17:51,750 –> 00:17:55,740
405
00:17:55,740 –> 00:17:57,410
406
00:17:57,410 –> 00:18:01,020
بود. برنامه پوشاک واقعی
407
00:18:01,020 –> 00:18:03,540
است، بنابراین در اینجا من می خواهم
408
00:18:03,540 –> 00:18:05,820
انتگرال A به B تابعی از f
409
00:18:05,820 –> 00:18:10,170
از X را محاسبه کنم، بنابراین قطعه خود را
410
00:18:10,170 –> 00:18:12,420
از A به B به تعداد قطعات
411
00:18:12,420 –> 00:18:14,220
برابر با تعداد فرآیندهایی که دارم تقسیم می کنم.
412
00:18:14,220 –> 00:18:17,100
و سپس هر فرآیند بخشی از انتگرال را انجام می دهد،
413
00:18:17,100 –> 00:18:21,120
بنابراین من متغیرهای مختلفی دارم
414
00:18:21,120 –> 00:18:24,210
a B a شروع
415
00:18:24,210 –> 00:18:26,370
یکپارچگی است در اینجا B 0 B
416
00:18:26,370 –> 00:18:30,150
پایان آن است B 1 را می
417
00:18:30,150 –> 00:18:32,340
گیرم من برای سادگی فرض می کنم 1024 امتیاز در اینجا دارم.
418
00:18:32,340 –> 00:18:33,900
که تعداد نقاط در تعداد
419
00:18:33,900 –> 00:18:36,390
ذوزنقهها دقیقاً بر
420
00:18:36,390 –> 00:18:37,770
تعداد پردازشها تقسیم میشود که فقط
421
00:18:37,770 –> 00:18:41,850
کد را ساده میکند، بنابراین در اینجا برنامه من چگونه به
422
00:18:41,850 –> 00:18:43,560
نظر میرسد، مقدماتی را انجام میدهم،
423
00:18:43,560 –> 00:18:50,060
بنابراین MPI را از MPI برای py وارد میکنم، ارتباطدهنده خود را
424
00:18:50,060 –> 00:18:53,850
مقداردهی اولیه میکنم و متوجه میشوم.
425
00:18:53,850 –> 00:18:56,130
رتبه و اندازه هر
426
00:18:56,130 –> 00:18:59,340
فرآیند و در اینجا من در این کد هستم،
427
00:18:59,340 –> 00:19:01,500
فقط میخواهم مقدار D را سیمکشی
428
00:19:01,500 –> 00:19:06,230
کنم، بنابراین b و n را روی هر چیزی که میخواهم تنظیم
429
00:19:06,230 –> 00:19:11,040
میکنم و گفتم مقصد
430
00:19:11,040 –> 00:19:13,260
0 باشد، زیرا اینطور است. مقصد متغیری است
431
00:19:13,260 –> 00:19:15,780
که در آن ما این فرآیند است که
432
00:19:15,780 –> 00:19:18,210
در پایان دادهها را دریافت میکند تا
433
00:19:18,210 –> 00:19:20,250
جمع شود و این پردازش 0 خواهد بود و
434
00:19:20,250 –> 00:19:23,280
در نهایت من کل را تعریف میکنم که در حال حاضر
435
00:19:23,280 –> 00:19:26,340
منهای 1 را ایجاد کردهایم و این همان جایی است که
436
00:19:26,340 –> 00:19:27,900
ما انجام خواهیم داد. انباشته انباشته شدن
437
00:19:27,900 –> 00:19:31,830
پاسخ بنابراین در حال حاضر در thi قسمتی از کد I
438
00:19:31,830 –> 00:19:35,390
have هر فرآیند بخش خود را از انتگرال محاسبه می کند
439
00:19:35,390 –> 00:19:39,120
و انتگرال جزئی را محاسبه می کند
440
00:19:39,120 –> 00:19:42,360
بنابراین در اینجا هر فرآیند باید
441
00:19:42,360 –> 00:19:45,240
حد ادغام محلی خود را مشخص کند
442
00:19:45,240 –> 00:19:48,600
بنابراین محلی a و محلی B این
443
00:19:48,600 –> 00:19:50,400
محدوده ادغام است که هر
444
00:19:50,400 –> 00:19:54,390
فرآیند باید انجام دهد. و هر فرآیند از رتبه من
445
00:19:54,390 –> 00:19:57,390
برای تعیین اینکه کدام قسمت از
446
00:19:57,390 –> 00:19:59,760
انتگرال مسئول است استفاده می کند، به عنوان مثال اگر من
447
00:19:59,760 –> 00:20:01,450
در مثبت 0
448
00:20:01,450 –> 00:20:03,580
باشد، این صفر خواهد بود، به این معنی
449
00:20:03,580 –> 00:20:05,590
که حد ادغام من در سمت چپ
450
00:20:05,590 –> 00:20:08,860
a است و حد انتگرال من در سمت راست
451
00:20:08,860 –> 00:20:12,730
است. هر چه حد باقی مانده بود به اضافه
452
00:20:12,730 –> 00:20:16,539
n محلی ضربدر H بنابراین محلی n تعداد
453
00:20:16,539 –> 00:20:19,210
کل نقاط ادغام تقسیم بر
454
00:20:19,210 –> 00:20:20,889
P است که P تعداد پردازنده ها است
455
00:20:20,889 –> 00:20:26,169
و سپس H محدوده کل
456
00:20:26,169 –> 00:20:28,450
انتگرال تقسیم بر n است که
457
00:20:28,450 –> 00:20:30,909
تعداد نقاط و در اینجا من روش ذوزنقه را صدا می زنم،
458
00:20:30,909 –> 00:20:32,889
بنابراین این