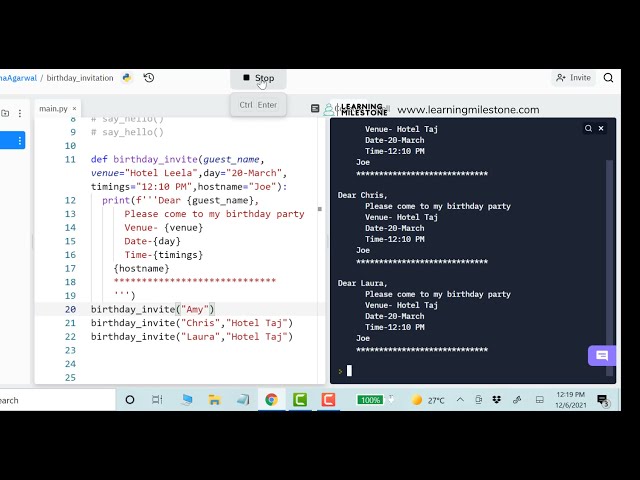
در این مطلب، ویدئو پیش بینی قیمت بیت کوین با استفاده از یادگیری ماشینی و پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:23:32
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,050 –> 00:00:02,190
سلام به همه و به این ویدیو
2
00:00:02,190 –> 00:00:03,899
در مورد زبان برنامه نویسی پایتون و
3
00:00:03,899 –> 00:00:05,970
یادگیری ماشین خوش آمدید، بنابراین در این ویدیو به
4
00:00:05,970 –> 00:00:07,170
همه شما نشان می دهم که چگونه برنامه ای ایجاد کنید
5
00:00:07,170 –> 00:00:08,910
که قیمت
6
00:00:08,910 –> 00:00:10,469
بیت کوین را برای 30 روز آینده پیش بینی کند،
7
00:00:10,469 –> 00:00:13,710
پس بیایید ادامه دهیم و شروع کنیم.
8
00:00:13,710 –> 00:00:15,570
اولین کاری که میخواهم انجام دهم این است که در
9
00:00:15,570 –> 00:00:19,439
نظرات توضیحی درباره برنامه بگذارم، بنابراین
10
00:00:19,439 –> 00:00:23,970
این برنامه قیمت
11
00:00:23,970 –> 00:00:30,029
بیتکوین را برای 30 روز آینده پیشبینی میکند
12
00:00:30,029 –> 00:00:31,920
و حالا بیایید یک سلول جدید با
13
00:00:31,920 –> 00:00:34,620
کلیک کردن روی این دکمه کد در اینجا ایجاد کنیم و در
14
00:00:34,620 –> 00:00:40,670
این سلول ما ‘قرار است کتابخانهها را وارد کنیم،
15
00:00:40,670 –> 00:00:48,930
بنابراین از پانداها یا متأسفیم
16
00:00:48,930 –> 00:00:53,489
که پانداها را SPD وارد میکنیم و سپس
17
00:00:53,489 –> 00:00:57,390
numpy را بهعنوان NP وارد
18
00:00:57,390 –> 00:01:02,280
19
00:01:02,280 –> 00:01:04,409
میکنیم.
20
00:01:04,409 –> 00:01:06,780
یک سلول جدید و سپس ما
21
00:01:06,780 –> 00:01:10,260
اکنون دادهها را بارگیری میکنیم، زیرا من در وبسایت Google هستم که
22
00:01:10,260 –> 00:01:12,330
23
00:01:12,330 –> 00:01:15,810
با تحقیقات سرد لپتاپ در Google، کتابخانه آنها را آرام میکند، بنابراین
24
00:01:15,810 –> 00:01:19,920
از google.com میخواهم
25
00:01:19,920 –> 00:01:22,439
فایلها را وارد کنم و سپس یک فایل ایجاد کنم.
26
00:01:22,439 –> 00:01:24,600
متغیری به نام upload it به جای
27
00:01:24,600 –> 00:01:28,740
برابر با fi روش آپلود les dot و
28
00:01:28,740 –> 00:01:31,170
اجازه دهید این را اجرا کنیم بسیار خوب،
29
00:01:31,170 –> 00:01:32,970
من روی Choose files here کلیک می کنم و
30
00:01:32,970 –> 00:01:35,250
بیت کوین CSV را انتخاب می
31
00:01:35,250 –> 00:01:38,250
کنیم و اجازه دهید آن را باز کنیم تا بارگذاری شود، من
32
00:01:38,250 –> 00:01:40,619
یک سلول جدید ایجاد می کنم و در
33
00:01:40,619 –> 00:01:45,470
اینجا می خواهیم داده ها را در یک
34
00:01:45,470 –> 00:01:49,799
متغیر ذخیره می کنم، بنابراین من می خواهم
35
00:01:49,799 –> 00:01:51,479
متغیری به نام DF ایجاد کنم که
36
00:01:51,479 –> 00:01:53,430
مخفف یک قاب داده است و می خواهم آن را
37
00:01:53,430 –> 00:01:57,180
برابر با pandas dot read در مدرسه
38
00:01:57,180 –> 00:01:59,820
یا متد CSV تنظیم کنم و سپس باید به
39
00:01:59,820 –> 00:02:02,520
آن بگوییم که چیست. فایلی که میخواهیم آن فایلی را که میخواهیم در آن بخوانیم بخواند
40
00:02:02,520 –> 00:02:03,780
، یعنی
41
00:02:03,780 –> 00:02:08,869
بیت کوین نقطه CSV و سپس
42
00:02:08,869 –> 00:02:11,420
اجازه دهید این را کمی بالا بیاورم،
43
00:02:11,420 –> 00:02:17,280
پس بیایید هفت ردیف
44
00:02:17,280 –> 00:02:20,790
اول داده را نشان دهیم، بنابراین برای انجام این کار فقط سر نقطه D F را تایپ میکنیم
45
00:02:20,790 –> 00:02:24,090
و سپس عدد هفت
46
00:02:24,090 –> 00:02:27,329
را در پارامتر وارد کنید و این را اجرا کنید و
47
00:02:27,329 –> 00:02:28,860
بنابراین اکنون می بینیم که به
48
00:02:28,860 –> 00:02:31,769
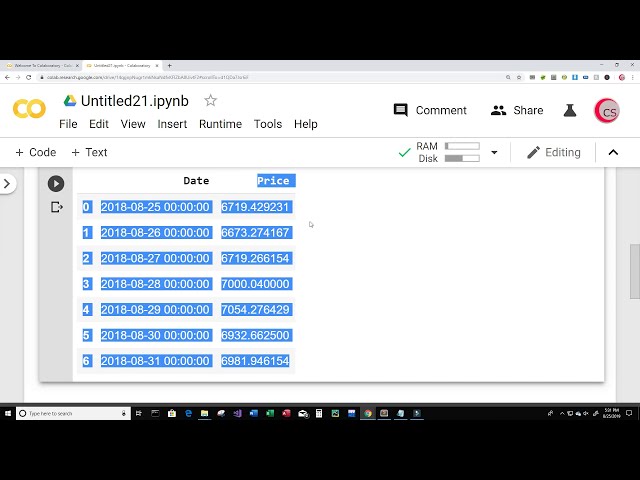
هفت ردیف اول داده ها برمی گردیم و می توانیم
49
00:02:31,769 –> 00:02:36,299
تاریخ ستون ها و قیمت ستون یا
50
00:02:36,299 –> 00:02:38,430
تاریخ ستون و قیمت ستون را کاملاً
51
00:02:38,430 –> 00:02:41,670
خوب ببینیم. یک سلول جدید در اینجا ایجاد کنید
52
00:02:41,670 –> 00:02:45,329
و در این سلول،
53
00:02:45,329 –> 00:02:51,450
ستون تاریخ را حذف می کنیم ستون تاریخ را بردارید
54
00:02:51,450 –> 00:02:54,959
و برای این کار فقط میتوانیم DF dot
55
00:02:54,959 –> 00:02:58,590
drop را تایپ کنیم و در داخل این متد باید
56
00:02:58,590 –> 00:03:00,120
به آن بگوییم که کدام ستون را میخواهیم رها کنیم،
57
00:03:00,120 –> 00:03:02,940
بنابراین ستون تاریخ همان ستونی است که
58
00:03:02,940 –> 00:03:04,769
میخواهیم رها کنیم و باید به آن بگوییم که
59
00:03:04,769 –> 00:03:06,659
میخواهیم روی ستون رها کنیم، بنابراین
60
00:03:06,659 –> 00:03:09,510
یکی را در اینجا قرار میدهیم و سپس میخواهم این
61
00:03:09,510 –> 00:03:13,500
متغیر DF ما را در قاب داده ما منعکس کند،
62
00:03:13,500 –> 00:03:18,359
بنابراین فقط در جای خود معادل true را تایپ کنید و
63
00:03:18,359 –> 00:03:21,419
سپس این را اجرا کنید و حالا اجازه دهید یک سلول جدید ایجاد کنیم
64
00:03:21,419 –> 00:03:26,430
و اجازه دهید اولین سلول را نشان دهیم. هفت ردیف
65
00:03:26,430 –> 00:03:31,049
از داده های جدید یا یک مجموعه داده جدید و برای
66
00:03:31,049 –> 00:03:33,720
انجام این کار فقط DF dot hit را تایپ کنید و سپس
67
00:03:33,720 –> 00:03:36,269
دوباره عدد هفت را وارد کنید و
68
00:03:36,269 –> 00:03:37,980
آن را اجرا کنید و اکنون می بینیم که
69
00:03:37,980 –> 00:03:40,440
فقط ستون قیمت را برای
70
00:03:40,440 –> 00:03:44,069
هفت ردیف اول داده برمی گردیم. یک بیت کوین خوب
71
00:03:44,069 –> 00:03:48,599
حالا بیایید یک سلول جدید ایجاد کنیم و
72
00:03:48,599 –> 00:03:53,629
آن را بالا بیاوریم و بیایید یک متغیر
73
00:03:53,629 –> 00:04:01,169
برای پیش بینی در روزهای
74
00:04:01,169 –> 00:04:04,019
آینده ایجاد کنیم، بنابراین من می خواهم متغیری
75
00:04:04,019 –> 00:04:07,409
به نام پیش بینی underscore در روز
76
00:04:07,409 –> 00:04:10,699
ایجاد کنم و آن را برابر با 30 قرار دهم. موردی
77
00:04:10,699 –> 00:04:15,120
که در آن عدد دلخواه باشد برابر
78
00:04:15,120 –> 00:04:17,700
با پیش بینی است n خط زیر خط روز
79
00:04:17,700 –> 00:04:19,420
که برابر با 30 است،
80
00:04:19,420 –> 00:04:23,550
پس بیایید ستون دیگری ایجاد کنیم
81
00:04:23,550 –> 00:04:27,610
و این ستون هدف یا وابسته ما خواهد بود
82
00:04:27,610 –> 00:04:30,310
. متأسفم که این نظر
83
00:04:30,310 –> 00:04:33,420
شامل هدف یا متغیر وابسته ما خواهد بود.
84
00:04:33,420 –> 00:04:41,020
85
00:04:41,020 –> 00:04:44,520
فقط DF را تایپ کنید و سپس
86
00:04:44,520 –> 00:04:49,200
پیش بینی کنید که آیا آن را P بزرگ کنم و
87
00:04:49,200 –> 00:04:55,530
سپس وقتی این را برابر با قیمت DF قرار دادم، به
88
00:04:56,490 –> 00:05:01,510
آنجا می رویم و از shift برای
89
00:05:01,510 –> 00:05:05,260
تغییر آن به سمت بالا استفاده می کنیم، بنابراین برای جابجایی آن به بالا،
90
00:05:05,260 –> 00:05:07,330
علامت منفی را در اینجا قرار می دهیم و می خواهیم برای اینکه آن
91
00:05:07,330 –> 00:05:10,090
را 30 روز به بالا تغییر دهیم، اما یک متغیر خوب
92
00:05:10,090 –> 00:05:11,130
برای آن روزهایی که قبلاً
93
00:05:11,130 –> 00:05:16,360
کاپری دیکشنری نشان میدهد داریم، بنابراین اکنون
94
00:05:16,360 –> 00:05:18,400
میتوانم این متغیر را در اینجا
95
00:05:18,400 –> 00:05:21,420
تغییر دهم و هر چه این عدد
96
00:05:21,420 –> 00:05:25,450
مشکلی ندارد، چند روز خوب است، بنابراین خوب به
97
00:05:25,450 –> 00:05:27,640
نظر میرسد، اجازه دهید سلول را اجرا کنیم و بیایید
98
00:05:27,640 –> 00:05:30,940
یک سلول جدید ایجاد کنیم و این را می خواهم
99
00:05:30,940 –> 00:05:34,980
هفت ردیف اول مجموعه داده جدید را نشان دهم،
100
00:05:34,980 –> 00:05:38,970
بنابراین دوباره فقط DF dot
101
00:05:38,970 –> 00:05:42,010
hit و ورودی در پارامتر
102
00:05:42,010 –> 00:05:44,860
عدد هفت را تایپ می کنیم و این را اجرا می کنیم و اکنون
103
00:05:44,860 –> 00:05:47,140
هفت رول اول را برمی گردانیم. داده ها اما
104
00:05:47,140 –> 00:05:49,120
اکنون می بینیم که ما h نه تنها
105
00:05:49,120 –> 00:05:51,270
ستون قیمت، بلکه
106
00:05:51,270 –> 00:05:55,870
ستون پیشبینی را هم داریم، بنابراین بیایید یک
107
00:05:55,870 –> 00:05:59,440
سلول جدید در اینجا ایجاد کنیم و با جابجایی مقادیر به
108
00:05:59,440 –> 00:06:04,630
بالا سی روز،
109
00:06:04,630 –> 00:06:08,590
انتهای مجموعه دادههای ما دارای
110
00:06:08,590 –> 00:06:11,340
مقادیر گم شده است، بنابراین نشان میدهیم که در اینجا
111
00:06:11,340 –> 00:06:15,700
هفت ردیف آخر مجموعه داده جدید را نشان خواهیم داد
112
00:06:15,700 –> 00:06:19,120
و برای انجام این کار فقط
113
00:06:19,120 –> 00:06:22,210
DF tail را تایپ می کنیم و سپس عدد
114
00:06:22,210 –> 00:06:25,240
هفت را وارد می کنیم، بنابراین بیایید این را اجرا کنیم و اکنون
115
00:06:25,240 –> 00:06:30,010
می توانیم یک ساده از هفت
116
00:06:30,010 –> 00:06:33,260
ردیف آخر داده را درست برای مشاهده کنیم. مجموعه دادههای من
117
00:06:33,260 –> 00:06:36,560
و در ستون پیشبینی na
118
00:06:36,560 –> 00:06:39,800
n داریم که به این معنی است که این مقادیر خالی هستند،
119
00:06:39,800 –> 00:06:42,920
اما این مشکلی
120
00:06:42,920 –> 00:06:44,600
نیست زیرا ما از
121
00:06:44,600 –> 00:06:50,300
30 روز گذشته در مجموعه دادههای خود استفاده نمیکنیم،
122
00:06:50,300 –> 00:06:52,670
کاری که در اینجا میخواهیم انجام دهیم قیمت فعلی را بگیرید
123
00:06:52,670 –> 00:06:55,610
و سپس
124
00:06:55,610 –> 00:06:58,010
قیمت آینده را در 30 روز
125
00:06:58,010 –> 00:07:01,430
پیش بینی کنید که در پیش بینی ستون باشد بنابراین با توجه به
126
00:07:01,430 –> 00:07:02,480
قیمت شش هزار و هفتصد و
127
00:07:02,480 –> 00:07:04,970
نوزده امتیاز چهار دو نه دو سه
128
00:07:04,970 –> 00:07:10,610
یک قیمت و سی
129
00:07:10,610 –> 00:07:12,410
روز آینده در آینده شش هزار ثانیه خواهد بود
130
00:07:12,410 –> 00:07:13,640
نهصد و سی و نه نقطه سه صفر
131
00:07:13,640 –> 00:07:16,970
چهار یک شش هفت خوب پس این کاری است که
132
00:07:16,970 –> 00:07:18,110
ما اینجا انجام خواهیم داد، بیایید ادامه دهیم
133
00:07:18,110 –> 00:07:21,560
و یک سلول جدید ایجاد کنیم و در
134
00:07:21,560 –> 00:07:24,620
نهایت شروع کنیم اوه باید این را
135
00:07:24,620 –> 00:07:26,630
پایین بیاورم، یک سلول جدید ایجاد می کنم و
136
00:07:26,630 –> 00:07:27,860
ما شروع به تقسیم
137
00:07:27,860 –> 00:07:30,410
کردن داده های خود خواهیم کرد، بنابراین
138
00:07:30,410 –> 00:07:37,730
مجموعه داده های مستقل را ایجاد می کنیم و برای
139
00:07:37,730 –> 00:07:39,410
این کار، یک فراخوانی متغیر
140
00:07:39,410 –> 00:07:46,390
X ایجاد می کنم، آن را برابر با آرایه نقطه NP تنظیم می کنم و
141
00:07:46,390 –> 00:07:48,410
ادامه می دهم و در نظرات اینجا بنویسید که
142
00:07:48,410 –> 00:07:51,440
من چه کار میکنم. میخواهم چارچوب دادهای
143
00:07:51,440 –> 00:07:56,890
متغیر DF خود را به یک آرایه numpy تبدیل کنم
144
00:07:56,890 –> 00:08:01,280
و سپس میخواهم ستون پیشبینی را رها کنم،
145
00:08:01,280 –> 00:08:04,100
146
00:08:04,100 –> 00:08:07,550
بنابراین در حال حاضر از این
147
00:08:07,550 –> 00:08:11,750
روش آرایه نقطهای NP برای تبدیل دادههایمان استفاده میکنیم. فریم
148
00:08:11,750 –> 00:08:15,710
به نام EF در یک آرایه NP اما قبل از
149
00:08:15,710 –> 00:08:18,080
آن باید ستونی به نام
150
00:08:18,080 –> 00:08:22,340
پیشبینی خوب پیشبینی شامل همه
151
00:08:22,340 –> 00:08:24,830
متغیرهای هدف
152
00:08:24,830 –> 00:08:27,380
را رها کنیم، به همین دلیل است که آن را رها میکنیم و میخواهیم
153
00:08:27,380 –> 00:08:30,740
آن ستون را کاملاً رها کنیم تا
154
00:08:30,740 –> 00:08:35,450
در مرحله بعد خوب باشد. من می خواهم
155
00:08:35,450 –> 00:08:39,349
n ردیف آخر را در این مورد 3 ردیف آخر را حذف کنم 0
156
00:08:39,349 –> 00:08:42,919
سطر و به یاد داشته باشید که n
157
00:08:42,919 –> 00:08:49,220
متغیر پیش بینی روزهای است، بنابراین برای
158
00:08:49,220 –> 00:08:55,190
انجام این کار فقط x برابر x را تایپ کنید و
159
00:08:55,190 –> 00:09:00,140
سپس آخرین را برگردانیم، بنابراین
160
00:09:00,140 –> 00:09:02,890
من هر سطر
161
00:09:02,890 –> 00:09:07,550
به جز 30 سطر آخر را برمی گردانیم. بنابراین
162
00:09:07,550 –> 00:09:10,010
این طول قاب داده ما است
163
00:09:10,010 –> 00:09:16,100
– پیش بینی روزها را زیر خط می زند و
164
00:09:16,100 –> 00:09:19,310
ما فقط با دادن سوگیری برای گرفتن
165
00:09:19,310 –> 00:09:21,649
همه ردیف ها به جز 30 ردیف آخر،
166
00:09:21,649 –> 00:09:24,850
اساساً آن 30 رول آخر را حذف
167
00:09:24,850 –> 00:09:28,279
می کنیم و سپس بیایید ادامه دهیم و X را چاپ کنیم
168
00:09:28,279 –> 00:09:31,720
و نگاهی بیندازیم. در کاری که اینجا انجام دادهایم
169
00:09:31,720 –> 00:09:35,290
خیلی خوب است، بنابراین من آن را اجرا میکنم، فقط به بالا نگاه کنید،
170
00:09:35,290 –> 00:09:38,029
بنابراین اینجا میخواهم در واقع به پایین اسکرول کنم
171
00:09:38,029 –> 00:09:45,820
و این را تا آخر بالا بیاورم، بسیار خوب است،
172
00:09:45,820 –> 00:09:47,750
بنابراین ما میرویم،
173
00:09:47,750 –> 00:09:50,720
بنابراین اکنون همه دادهها را
174
00:09:50,720 –> 00:09:53,779
به جز برای آن 30 ردیف آخر، بنابراین اگر
175
00:09:53,779 –> 00:09:56,630
بخواهم تا آخر اینجا
176
00:09:56,630 –> 00:10:00,769
را ادامه دهم، هیچ مقدار گمشده ای را نخواهیم دید، بنابراین
177
00:10:00,769 –> 00:10:01,610
همه چیز در آنجا خوب به نظر می رسد،
178
00:10:01,610 –> 00:10:05,089
بیایید یک سلول جدید ایجاد کنیم و و این ما
179
00:10:05,089 –> 00:10:08,720
اساساً می خواهیم مجموعه داده های وابسته خود را ایجاد کنیم
180
00:10:08,720 –> 00:10:11,329
، پس بیایید قرار دهید که در نظرات
181
00:10:11,329 –> 00:10:17,149
اینجا مجموعه داده های وابسته را ایجاد کنید و
182
00:10:17,149 –> 00:10:20,660
بنابراین اجازه دهید این کار را انجام دهید، ما فریم داده را تبدیل می کنیم،
183
00:10:20,660 –> 00:10:22,970
اما شما آن متغیر DF جانبی را
184
00:10:22,970 –> 00:10:29,660
به یک آرایه numpy می گیریم و
185
00:10:29,660 –> 00:10:33,050
ما همه مقادیر موجود در مجموعه داده
186
00:10:33,050 –> 00:10:35,870
را دریافت می کنیم، بنابراین من متغیری
187
00:10:35,870 –> 00:10:38,720
به نام Y ایجاد می کنم و آن را برابر با MP dot قرار می دهیم.
188
00:10:38,720 –> 00:10:43,100
آرایه و در داخل این متد ما
189
00:10:43,100 –> 00:10:48,190
DF را میخواهیم و ستون پیشبینی را به
190
00:10:48,190 –> 00:10:50,010
طور خاص
191
00:10:50,010 –> 00:10:52,290
خوب میخواهیم، بنابراین همه آن
192
00:10:52,290 –> 00:10:56,340
ادهها از جمله Nance و NA ی
193
00:10:56,340 –> 00:11:00,810
مقادیر خالی را به ما باز میگرداند، بنابراین باید از شر
194
00:11:00,810 –> 00:11:03,390
ن مقادیر خالی خلاص شویم و غیره ما
195
00:11:03,390 –> 00:11:09,080
همه مقادیر را به
196
00:11:09,080 –> 00:11:17,450
جز آخرین سطرها دریافت می کنیم، بنابراین فقط y را برابر با
197
00:11:17,450 –> 00:11:22,950
Y