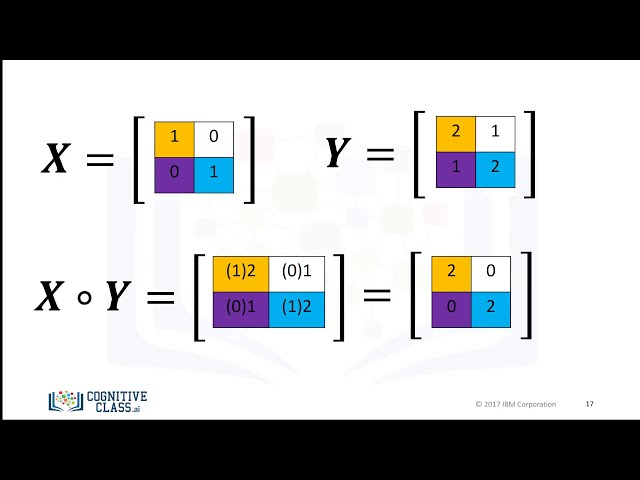
در این مطلب، ویدئو PCA (Principal Component Analysis) در پایتون – یادگیری ماشینی از ابتدا 11 – آموزش پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:17:17
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:02,429
سلام به همگی به یک آموزش یادگیری ماشینی جدید از ابتدا خوش آمدید،
2
00:00:02,429 –> 00:00:04,859
امروز می خواهیم
3
00:00:04,859 –> 00:00:06,600
4
00:00:06,600 –> 00:00:09,750
تجزیه و تحلیل مؤلفه های اصلی یا PCA را فقط با استفاده از
5
00:00:09,750 –> 00:00:14,070
پایتون و numpy پیاده سازی کنیم PCA ابزار خوبی
6
00:00:14,070 –> 00:00:17,070
برای دریافت ویژگی های مستقل خطی و
7
00:00:17,070 –> 00:00:19,949
همچنین کاهش ابعاد
8
00:00:19,949 –> 00:00:24,300
مجموعه داده های ما است. هدف این است که مجموعه جدیدی
9
00:00:24,300 –> 00:00:26,699
از ابعاد را پیدا کنیم به طوری که همه
10
00:00:26,699 –> 00:00:29,609
ابعاد متعامد و از این رو
11
00:00:29,609 –> 00:00:32,399
مستقل خطی باشند و
12
00:00:32,399 –> 00:00:34,950
با توجه به واریانس داده ها در امتداد
13
00:00:34,950 –> 00:00:38,780
آنها رتبه بندی شوند، بنابراین این بدان معناست که ما می خواهیم تبدیلی پیدا کنیم به
14
00:00:38,780 –> 00:00:41,579
طوری که ویژگی های تبدیل شده
15
00:00:41,579 –> 00:00:44,329
به صورت خطی مستقل
16
00:00:44,329 –> 00:00:47,520
و ابعاد هستند. سپس می توان
17
00:00:47,520 –> 00:00:50,129
تنها با گرفتن ابعاد با
18
00:00:50,129 –> 00:00:54,120
بیشترین اهمیت را کاهش داد و آن
19
00:00:54,120 –> 00:00:55,980
ابعاد جدید باید
20
00:00:55,980 –> 00:00:58,590
خطای طرح ریزی را به حداقل برسانند و نقاط پیش بینی شده
21
00:00:58,590 –> 00:01:01,199
باید حداکثر گسترش
22
00:01:01,199 –> 00:01:04,619
یا حداکثر واریانس را داشته باشند، بنابراین
23
00:01:04,619 –> 00:01:07,170
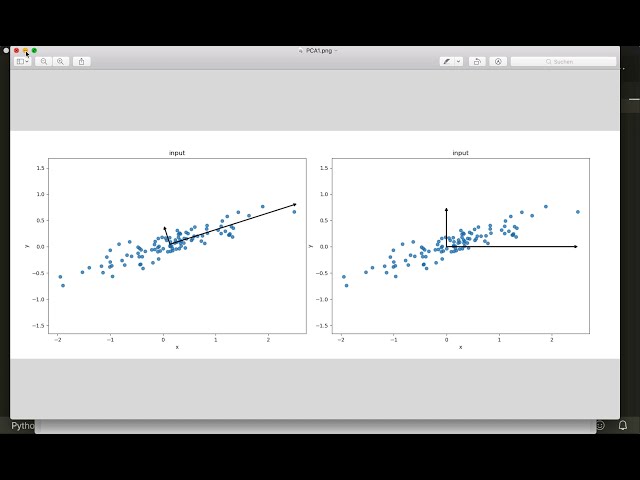
بیایید برای درک بهتر به یک تصویر نگاه
24
00:01:07,170 –> 00:01:11,630
کنیم. می گوییم داده های 2 بعدی ما به این
25
00:01:11,630 –> 00:01:16,049
صورت توزیع شده است و اکنون می خواهیم
26
00:01:16,049 –> 00:01:20,100
آن را به 1d و اکنون ارائه کنیم کاری که
27
00:01:20,100 –> 00:01:24,240
میخواهیم انجام دهیم این است که میخواهیم محورهایی را پیدا کنیم
28
00:01:24,240 –> 00:01:29,159
که متعامد با یکدیگر هستند و
29
00:01:29,159 –> 00:01:32,579
وقتی دادههای خود را روی این محورها پخش
30
00:01:32,579 –> 00:01:35,369
میکنیم، دادههای پیشبینیشده جدید ما باید
31
00:01:35,369 –> 00:01:39,840
حداکثر گسترش را داشته باشند، بنابراین در سمت چپ،
32
00:01:39,840 –> 00:01:43,380
اینها محور اصلی صحیح هستند، بنابراین اگر
33
00:01:43,380 –> 00:01:47,700
ما آنها را به صورت 1d طرح ریزی می کنیم، بنابراین
34
00:01:47,700 –> 00:01:51,000
اگر
35
00:01:51,000 –> 00:01:53,850
داده های خود را روی این محور پرتاب کنیم، آنها
36
00:01:53,850 –> 00:01:58,110
حداکثر گسترش را خواهند داشت و به عنوان مثال اگر
37
00:01:58,110 –> 00:02:01,079
به سمت راست نگاه کنیم، بنابراین اینها در
38
00:02:01,079 –> 00:02:04,950
محور صحیح هستند، بنابراین بیایید ببینیم که
39
00:02:04,950 –> 00:02:08,610
داده های پیش بینی شده چگونه خواهد بود. به نظر می رسد در
40
00:02:08,610 –> 00:02:10,979
سمت راست، ما آن را حتی بدتر کردیم و
41
00:02:10,979 –> 00:02:14,000
آن را در دسترسی y پیش بینی کردیم،
42
00:02:14,000 –> 00:02:16,640
بنابراین اینها به وضوح اشتباه هستند
43
00:02:16,640 –> 00:02:19,190
زیرا در اینجا می توانیم ببینیم که بسیاری از
44
00:02:19,190 –> 00:02:21,800
داده ها در همان نقاط هستند، بنابراین ما
45
00:02:21,800 –> 00:02:25,790
اطلاعات بیشتری در مورد آن نداریم. آنها اما
46
00:02:25,790 –> 00:02:30,350
در اینجا در سمت چپ داده های پیش بینی شده
47
00:02:30,350 –> 00:02:38,860
دارای حداکثر گسترش هستند، بنابراین ما می توانیم
48
00:02:38,860 –> 00:02:41,660
بیشتر اطلاعات مربوط به داده ها
49
00:02:41,660 –> 00:02:45,230
و همچنین خطای طرح ریزی را در خود داشته باشیم،
50
00:02:45,230 –> 00:02:49,550
به این معنی که این خطوط از اینجا
51
00:02:49,550 –> 00:02:53,330
به محور خواهد بود.
52
00:02:53,330 –> 00:02:56,480
در سمت راست، بنابراین در اینجا
53
00:02:56,480 –> 00:02:59,630
باید یک خط طرح ریزی طولانی مدت
54
00:02:59,630 –> 00:03:03,680
برای هر نقطه ایجاد کنیم تا سمت چپ
55
00:03:03,680 –> 00:03:05,180
پاسخ صحیح باشد
56
00:03:05,180 –> 00:03:08,950
و حالا چگونه این اجزای اصلی چاپ را پیدا کنیم،
57
00:03:08,950 –> 00:03:14,630
بنابراین همانطور که
58
00:03:14,630 –> 00:03:17,959
گفتم می خواهیم واریانس را به حداکثر برسانیم.
59
00:03:17,959 –> 00:03:21,170
ما به مقداری ریاضی نیاز داریم بنابراین به
60
00:03:21,170 –> 00:03:26,049
واریانس یک نمونه X نیاز داریم و این به
61
00:03:26,049 –> 00:03:28,820
صورت 1 بر تعداد نمونه ها محاسبه می شود
62
00:03:28,820 –> 00:03:31,330
و سپس مجموع
63
00:03:31,330 –> 00:03:37,610
هر جزء منهای X میله و X نوار
64
00:03:37,610 –> 00:03:40,970
مقدار میانگین است بنابراین مقدار میانگین را از آن کم می کنیم.
65
00:03:40,970 –> 00:03:46,130
مجموعه داده های ما و اکنون ما نیز
66
00:03:46,130 –> 00:03:50,390
به یک ماتریس کوواریانس نیاز داریم، بنابراین این
67
00:03:50,390 –> 00:03:52,610
نشان دهنده سطحی است که دو
68
00:03:52,610 –> 00:03:56,299
متغیر با هم تغییر می کنند و
69
00:03:56,299 –> 00:03:59,090
ماتریس کوواریانس دو متغیر
70
00:03:59,090 –> 00:04:02,959
به صورت این تا یک روی N و سپس
71
00:04:02,959 –> 00:04:06,650
دوباره مجموع و در اینجا میانگین را کم می کنیم.
72
00:04:06,650 –> 00:04:11,090
و دوباره در اینجا میانگین و
73
00:04:11,090 –> 00:04:14,420
سپس جابجا شده و در مورد ما
74
00:04:14,420 –> 00:04:17,600
می خواهیم ماتریس کوواریانس را با هر دو
75
00:04:17,600 –> 00:04:21,918
XS خود داشته باشیم بنابراین به این
76
00:04:21,918 –> 00:04:27,169
ماتریس کوواریانس خودکار نیز می گویند بنابراین باید
77
00:04:27,169 –> 00:04:27,770
78
00:04:27,770 –> 00:04:32,090
این را محاسبه کنیم و سپس مشکل ما به ei کاهش می یابد.
79
00:04:32,090 –> 00:04:36,080
بردار ژن یا مسئله مقدار ویژه، بنابراین
80
00:04:36,080 –> 00:04:38,990
من در اینجا به جزئیات در مورد بردارهای ویژه نمی پردازم،
81
00:04:38,990 –> 00:04:41,479
اما اگر می خواهید بیشتر بخوانید، چند لینک
82
00:04:41,479 –> 00:04:43,280
در توضیحات قرار خواهم داد،
83
00:04:43,280 –> 00:04:48,560
اما کاری که باید انجام دهیم این است
84
00:04:48,560 –> 00:04:51,289
که باید بردارهای ویژه و مقادیر ویژه
85
00:04:51,289 –> 00:04:55,520
این ماتریس کوواریانس را پیدا کنیم. و
86
00:04:55,520 –> 00:04:58,069
بردارهای ویژه در
87
00:04:58,069 –> 00:05:01,130
جهت حداکثر واریانس و
88
00:05:01,130 –> 00:05:03,919
مقادیر ویژه مربوطه نشان دهنده
89
00:05:03,919 –> 00:05:06,069
اهمیت
90
00:05:06,069 –> 00:05:10,610
بردار ویژه متناظر آن هستند، بنابراین اگر
91
00:05:10,610 –> 00:05:13,550
دوباره به این تصویر در سمت چپ نگاهی بیندازیم، بنابراین
92
00:05:13,550 –> 00:05:17,050
این دو بردار که من در اینجا ترسیم کردهام، در نظر گرفته میشوند.
93
00:05:17,050 –> 00:05:21,139
با بردارهای ویژه
94
00:05:21,139 –> 00:05:26,300
ماتریس کوواریانس مجموعه داده ما مطابقت دارد، بنابراین
95
00:05:26,300 –> 00:05:29,449
این کاری است که باید انجام دهیم و در اینجا
96
00:05:29,449 –> 00:05:33,080
روش را نوشته ام، بنابراین ابتدا
97
00:05:33,080 –> 00:05:36,590
مقدار میانگین را از X یا
98
00:05:36,590 –> 00:05:39,530
از مجموعه داده خود کم می کنیم سپس ماتریس کوواریانس را محاسبه می
99
00:05:39,530 –> 00:05:42,199
کنیم. سپس باید
100
00:05:42,199 –> 00:05:44,419
بردارهای ویژه و
101
00:05:44,419 –> 00:05:48,770
مقادیر ویژه را محاسبه کنیم سپس بردارهای ویژه را به
102
00:05:48,770 –> 00:05:51,409
ترتیب کاهش با توجه به
103
00:05:51,409 –> 00:05:54,919
مقادیر ویژه آنها مرتب کنیم و سپس می توانیم مشخص کنیم که
104
00:05:54,919 –> 00:05:59,120
چند بعد می خواهیم t. o نگه دارید و
105
00:05:59,120 –> 00:06:04,120
سپس فقط اولین بردارهای K eigen را انتخاب می
106
00:06:04,120 –> 00:06:07,460
کنیم که بعد K جدید خواهند بود
107
00:06:07,460 –> 00:06:12,699
و سپس داده های اصلی
108
00:06:12,699 –> 00:06:17,509
را با نمایش دادن آنها به این ابعاد جدید تبدیل می
109
00:06:17,509 –> 00:06:21,050
کنیم فقط این فقط یک محصول نقطه ای
110
00:06:21,050 –> 00:06:26,330
از داده های ما با جدید با ویژه است.
111
00:06:26,330 –> 00:06:30,020
بردارها و سپس کار ما تمام شد، بنابراین این تنها کاری
112
00:06:30,020 –> 00:06:37,430
است که باید انجام دهیم و یکی از چیزهایی
113
00:06:37,430 –> 00:06:40,670
که در مورد
114
00:06:40,670 –> 00:06:41,980
115
00:06:41,980 –> 00:06:44,900
تجزیه و تحلیل مؤلفه های اصلی [موسیقی] بسیار خوب است و
116
00:06:44,900 –> 00:06:47,860
بردارهای ویژه این است که همه آنها
117
00:06:47,860 –> 00:06:51,950
متعامد یکدیگر هستند، این بدان معنی است که
118
00:06:51,950 –> 00:06:54,680
داده های جدید ما پس از آن هستند. همچنین به صورت خطی
119
00:06:54,680 –> 00:06:58,630
مستقل است، بنابراین این یک
120
00:06:58,630 –> 00:07:00,830
امتیاز کوچک خوب برای PCA است
121
00:07:00,830 –> 00:07:05,740
و اکنون میتوانیم شروع کنیم، بنابراین بیایید
122
00:07:05,740 –> 00:07:10,750
numpy s و p را وارد کنیم و سپس یک کلاس
123
00:07:10,750 –> 00:07:17,180
PCA ایجاد میکنیم که یک init با self دریافت میکند و
124
00:07:17,180 –> 00:07:20,410
سپس در اینجا تعداد
125
00:07:20,410 –> 00:07:26,930
مؤلفههایی را که میخواهیم مشخص میکنیم. برای نگه داشتن و سپس
126
00:07:26,930 –> 00:07:30,280
آنها را در اینجا ذخیره می کنیم، بنابراین می گوییم خود نقطه و
127
00:07:30,280 –> 00:07:39,310
مؤلفه ها برابر است و مؤلفه ها و می
128
00:07:39,310 –> 00:07:42,800
خواهیم بردارهای ویژه را پیدا
129
00:07:42,800 –> 00:07:46,240
کنیم، بنابراین بیایید آنها را در اینجا مؤلفه های خود بنامیم و
130
00:07:46,240 –> 00:07:49,580
این در ابتدا هیچکدام نیست و
131
00:07:49,580 –> 00:07:52,190
همچنین می خواهیم ذخیره کنیم e میانگین بعداً پس
132
00:07:52,190 –> 00:07:55,040
بیایید خود را بگوییم که میانگین برابر است با هیچ
133
00:07:55,040 –> 00:08:00,590
و سپس روش برازش