در این مطلب، ویدئو تست نرمال بودن در پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:21:09
تصاویر این ویدئو:
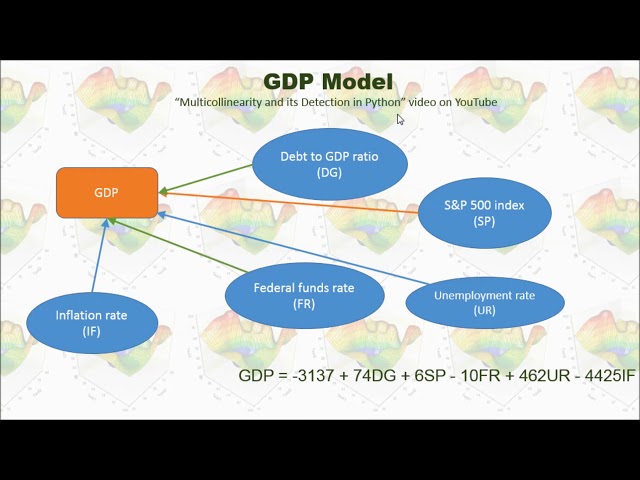

قسمتی از زیرنویس این فیلم:
00:00:01,129 –> 00:00:03,740
این بار می خواهم در مورد
2
00:00:03,740 –> 00:00:08,550
تست های نرمال بودن در paese صحبت کنم، اجازه دهید
3
00:00:08,550 –> 00:00:11,370
ابتدا فرضیات رگرسیون خطی چندگانه را مرور کنیم، فرض
4
00:00:11,370 –> 00:00:15,450
اول
5
00:00:15,450 –> 00:00:19,590
رابطه خطی است اگر
6
00:00:19,590 –> 00:00:22,650
رابطه خطی نیست، ممکن است
7
00:00:22,650 –> 00:00:26,220
بخواهید متغیرها را به یک
8
00:00:26,220 –> 00:00:29,390
رابطه خطی تبدیل کنید یا از
9
00:00:29,390 –> 00:00:33,690
رگرسیون دیگری استفاده کنید. مدل فرض دوم
10
00:00:33,690 –> 00:00:38,190
یکسانی است که
11
00:00:38,190 –> 00:00:41,070
واریانس باقیمانده ها باید در
12
00:00:41,070 –> 00:00:45,260
هر سطح از متغیرهای مستقل یکسان باشد.
13
00:00:45,260 –> 00:00:51,440
فرض سوم خطاهای مستقل است.
14
00:00:53,090 –> 00:00:56,640
15
00:00:56,640 –> 00:00:59,390
16
00:00:59,390 –> 00:01:04,640
17
00:01:04,640 –> 00:01:08,119
مدلی که من
18
00:01:08,119 –> 00:01:12,270
این فرض را در ویدیوی قبلی خود در یوتیوب مورد بحث قرار دادم،
19
00:01:12,270 –> 00:01:16,159
شما خوش آمدید آن را تماشا
20
00:01:16,159 –> 00:01:19,409
کنید. آخرین فرض به طور معمول
21
00:01:19,409 –> 00:01:24,570
توزیع شده است باقیمانده در این ویدئو.
22
00:01:24,570 –> 00:01:29,600
23
00:01:31,850 –> 00:01:36,780
24
00:01:36,780 –> 00:01:39,930
25
00:01:39,930 –> 00:01:44,899
26
00:01:46,700 –> 00:01:51,170
زمانی که نرمال بودن resi را بررسی می کنیم، توسط یک توزیع نرمال بدهی
27
00:01:51,170 –> 00:01:56,039
هایی را که باید به خاطر بسپاریم فقط
28
00:01:56,039 –> 00:01:59,670
باقیمانده را برای نرمال بودن بررسی می کنیم، نیازی نیست که
29
00:01:59,670 –> 00:02:04,520
نرمال بودن داده های خام را بررسی کنیم،
30
00:02:04,520 –> 00:02:08,160
متغیرهای وابسته و مستقل ما
31
00:02:08,160 –> 00:02:11,700
32
00:02:11,700 –> 00:02:15,730
برای برازش مدل رگرسیون خطی نیازی به توزیع نرمال
33
00:02:15,730 –> 00:02:18,590
34
00:02:18,590 –> 00:02:22,110
ندارند. آیا پیامدهای مرتبط
35
00:02:22,110 –> 00:02:24,769
با نقض یک فرض نرمال بودن
36
00:02:24,769 –> 00:02:29,910
دین
37
00:02:29,910 –> 00:02:33,480
به سوگیری کمک نمی کند، همه ناکارآمدی در
38
00:02:33,480 –> 00:02:37,560
مدل های رگرسیون کمک نمی کند، فقط برای
39
00:02:37,560 –> 00:02:40,290
محاسبه p-value برای آزمون معناداری مهم است،
40
00:02:40,290 –> 00:02:45,209
همچنین زمانی که حجم نمونه به اندازه
41
00:02:45,209 –> 00:02:49,140
کافی بزرگ است، می توانیم توزیع را در نظر بگیریم
42
00:02:49,140 –> 00:02:53,220
. این عبارت خطای
43
00:02:53,220 –> 00:02:59,420
نرمال بودن را چگونه بررسی کنیم نرمال بودن را بررسی
44
00:02:59,420 –> 00:03:03,690
کنیم روش های زیادی برای تست Manatee جدید وجود دارد که به آنها
45
00:03:03,690 –> 00:03:08,310
اشاره خواهم کرد که در این ویدیو از چند مورد استفاده شده است.
46
00:03:08,310 –> 00:03:15,870
47
00:03:15,870 –> 00:03:21,810
48
00:03:21,810 –> 00:03:26,630
49
00:03:26,630 –> 00:03:33,040
آزمون مجذور K کازینوهای ما،
50
00:03:33,040 –> 00:03:39,650
اجازه دهید هر روش را آشکار کنیم، بنابراین QQ چیست،
51
00:03:39,650 –> 00:03:45,640
نمودارهای QQ را به
52
00:03:45,640 –> 00:03:48,970
صورت مخفف کوتاه نمودار چندک نشان می دهد
53
00:03:48,970 –> 00:03:52,910
اگر t گرافیکی به ما کمک می کند تا ارزیابی
54
00:03:52,910 –> 00:03:57,800
کنیم که آیا مجموعه داده ها از
55
00:03:57,800 –> 00:04:00,950
توزیع Cerreta chol مانند
56
00:04:00,950 –> 00:04:05,450
نرمال توزیع نمایی آمده است یا خیر
57
00:04:05,450 –> 00:04:10,510
، عددی به ما نمی دهد اما
58
00:04:10,510 –> 00:04:15,020
به صورت بصری به ما نشان می دهد تا بررسی کنیم که آیا این
59
00:04:15,020 –> 00:04:18,190
فرض درست است،
60
00:04:19,930 –> 00:04:25,310
این یک QQ معمولی است. نمودار روی
61
00:04:25,310 –> 00:04:29,150
محور افقی ما این
62
00:04:29,150 –> 00:04:33,350
کوانتوم نظری و محور عمودی
63
00:04:33,350 –> 00:04:36,370
چندک های نمونه داریم که
64
00:04:36,370 –> 00:04:40,690
می توانید تصور کنید اگر توزیع نظری
65
00:04:40,690 –> 00:04:44,450
با توزیع نمونه یکسان
66
00:04:44,450 –> 00:04:48,740
باشد و سپس این نمودار QQ
67
00:04:48,740 –> 00:04:52,010
یک خط مستقیم را نشان می دهد زیرا
68
00:04:52,010 –> 00:04:55,880
خانه نقطه نظری دقیقاً همان است.
69
00:04:55,880 –> 00:05:00,340
همینطور با چندک های نمونه،
70
00:05:00,830 –> 00:05:08,389
سپس شاپیرو چیست، ابتدا آزمایش می کنیم
71
00:05:08,389 –> 00:05:13,610
، داده های نمونه را از x1 x2 به
72
00:05:13,610 –> 00:05:18,159
xn می گیریم، سپس باید آنها را به ترتیب افزایش حل کنیم
73
00:05:18,159 –> 00:05:23,990
و نمونه سرخ شده
74
00:05:23,990 –> 00:05:33,710
به y1 y2 و 2y تبدیل می شود و سپس
75
00:05:33,710 –> 00:05:38,509
یک عدد می گیریم. اگر این را بر منهای 1 تقسیم کنیم، مجموع کمی
76
00:05:38,509 –> 00:05:43,430
است که ویروس نمونه خواهد بود،
77
00:05:43,430 –> 00:05:50,680
بنابراین این مجموع
78
00:05:50,680 –> 00:05:56,030
تغییرات این داده های نمونه را توصیف می کند و سپس
79
00:05:56,030 –> 00:06:01,060
B را محاسبه می کنیم، پس چگونه B را محاسبه کنیم
80
00:06:01,060 –> 00:06:08,500
B با این فرمول محاسبه
81
00:06:08,500 –> 00:06:13,669
می شود ابتدا تفاوت را از
82
00:06:13,669 –> 00:06:18,729
این داده های نمونه مرتب شده می گیرد و سپس بارهایی
83
00:06:18,729 –> 00:06:25,300
که a از جدول هفته شاپیرو آمده است،
84
00:06:25,300 –> 00:06:29,300
می توانید ببینید که در این جدول ما
85
00:06:29,300 –> 00:06:31,520
اندازه نمونه را در اینجا برای تعداد احساس می کنید
86
00:06:31,520 –> 00:06:35,360
که اندازه نمونه چگونه است. 32 باید
87
00:06:35,360 –> 00:06:41,430
این ستون را بررسی کنید و
88
00:06:41,430 –> 00:06:48,330
a1 این عدد است و در وسط
89
00:06:48,330 –> 00:06:55,169
عدد 16 عدد بعدی است، بنابراین اساساً ما
90
00:06:55,169 –> 00:07:01,259
این جدول Shapiro Wilk را بر
91
00:07:01,259 –> 00:07:07,770
اساس توزیع نظری خود محاسبه می کنیم تا
92
00:07:07,770 –> 00:07:12,720
بتوانیم بگوییم داده های این جدول پس از محاسبه جادو را انجام می دهند.
93
00:07:12,720 –> 00:07:13,699
94
00:07:13,699 –> 00:07:19,830
B و سپس میتوانیم
95
00:07:19,830 –> 00:07:24,990
آمار آزمون W را برابر با
96
00:07:24,990 –> 00:07:31,970
B مجذور تقسیم بر s مجذور محاسبه
97
00:07:37,130 –> 00:07:41,210
کنیم، اگر آماره آزمون W کوچکتر از
98
00:07:41,210 –> 00:07:44,330
آستانه بحرانی باشد، فرض
99
00:07:44,330 –> 00:07:47,780
توزیع نرمال باید رد شود،
100
00:07:47,780 –> 00:07:51,980
یعنی توزیع نمونه ما
101
00:07:51,980 –> 00:07:55,520
یک توزیع نرمال نیست. بعداً به شما نشان خواهم داد
102
00:07:55,520 –> 00:07:58,790
که چگونه این تست Shapiro Wilk را در پایتون پیادهسازی کنید،
103
00:07:58,790 –> 00:08:04,610
سپس آنچه را که میدانید،
104
00:08:04,610 –> 00:08:07,880
105
00:08:07,880 –> 00:08:12,370
تست عزیزم، میتوان ابتدا بین هر دو
106
00:08:12,370 –> 00:08:17,470
توزیع استفاده کرد. توزیع نظری خود را
107
00:08:17,470 –> 00:08:21,320
F و سپس
108
00:08:21,320 –> 00:08:24,280
تابع توزیع تجمعی تجربی خود
109
00:08:24,280 –> 00:08:28,840
را داریم f n
110
00:08:28,840 –> 00:08:33,309
، تفاوت بین
111
00:08:33,309 –> 00:08:38,450
توزیع تجربی و توزیع اخلاقی خود را
112
00:08:38,450 –> 00:08:43,849
مربع آن و وزن x
113
00:08:43,849 –> 00:08:48,790
و پسر ماشین حساب
114
00:08:49,660 –> 00:08:55,360
زمانی که تابع وزنی W X 1 است،
115
00:08:55,360 –> 00:08:59,530
آمار را خامهتر مینامیم. یکی آمار را از دست می دهد
116
00:08:59,530 –> 00:09:03,310
و تست عزیزم درک کامل
117
00:09:03,310 –> 00:09:04,060
118
00:09:04,060 –> 00:09:09,520
را از آن به عنوان تابع وزنی خود
119
00:09:09,520 –> 00:09:14,760
استفاده می کنیم، یعنی درک فاصله عزیزم،
120
00:09:14,760 –> 00:09:18,180
وزن بیشتری را روی
121
00:09:18,180 –> 00:09:21,190
مشاهدات در انتهای
122
00:09:21,190 –> 00:09:28,930
توزیع ستایش می کند، زیرا ما در حال
123
00:09:28,930 –> 00:09:32,640
محاسبه تفاوت بین دو توزیع هستیم
124
00:09:32,640 –> 00:09:37,060
که می توانید تصور کنید اگر این دو توزیع
125
00:09:37,060 –> 00:09:40,990
باشند. همان همه به اندازه کافی نزدیک
126
00:09:40,990 –> 00:09:45,430
باید یک مربع بسیار کوچک یا حتی
127
00:09:45,430 –> 00:09:48,310
برابر با صفر به دست آوریم اگر دو
128
00:09:48,310 –> 00:09:56,670
توزیع دقیقاً یکسان هستند.
129
00:09:56,670 –> 00:10:00,370
130
00:10:00,370 –> 00:10:04,690
131
00:10:04,690 –> 00:10:10,030
می ت