در این مطلب، ویدئو یادگیری ماشین با Scikit-learn – تجزیه و تحلیل داده ها با پایتون و پانداها p.6 با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:27:03
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:01,100 –> 00:00:03,210
همه به
2
00:00:03,210 –> 00:00:07,859
قسمت 6 تجزیه و تحلیل داده های پایتون و
3
00:00:07,859 –> 00:00:10,110
علم داده با سری آموزش های پاندا خوش آمدید
4
00:00:10,110 –> 00:00:13,110
در این قسمت آخر ما
5
00:00:13,110 –> 00:00:14,280
قرار بود در مورد استفاده از
6
00:00:14,280 –> 00:00:17,190
یادگیری ماشین در چارچوب داده پاندا صحبت کنیم،
7
00:00:17,190 –> 00:00:18,810
بنابراین اساساً چگونه جریان کاری معمولی در
8
00:00:18,810 –> 00:00:20,580
هنگام انجام دادن چیست؟ یادگیری ماشینی
9
00:00:20,580 –> 00:00:23,789
با مجموعههای داده پانداها، بنابراین به طور کلی،
10
00:00:23,789 –> 00:00:25,380
اگر قرار است ابتدا یادگیری ماشینی انجام دهم، به هر
11
00:00:25,380 –> 00:00:27,019
حال میخواهم
12
00:00:27,019 –> 00:00:31,170
دادههایم را در پانداها پیش پردازش کنند، بنابراین خیلی
13
00:00:31,170 –> 00:00:32,820
راحت
14
00:00:32,820 –> 00:00:33,930
میتوانیم خوب بدانیم که وقتی ویژگیهایمان را دریافت کردیم، مرحله بعدی چیست.
15
00:00:33,930 –> 00:00:35,489
چگونه آن را از طریق یک مدل تغذیه کنیم،
16
00:00:35,489 –> 00:00:37,530
بنابراین این همان کاری است که ما در اینجا
17
00:00:37,530 –> 00:00:39,270
انجام می دهیم، یک مجموعه داده جدید می
18
00:00:39,270 –> 00:00:41,520
گیریم و مجموعه داده های Diamonds را می گیریم،
19
00:00:41,520 –> 00:00:43,290
بنابراین ادامه دهید و دانلود کنید که آن را
20
00:00:43,290 –> 00:00:46,350
در فهرست مجموعه داده های خود قرار دهید، بنابراین
21
00:00:46,350 –> 00:00:48,059
هدف ما خوب خواهد بود، ما می خواهیم
22
00:00:48,059 –> 00:00:52,670
قیمت الماس را پیش بینی کنیم، بنابراین
23
00:00:52,670 –> 00:00:55,739
اساساً این جدول شامل یک سری
24
00:00:55,739 –> 00:00:59,340
مقادیر است در اینجا ما جدول عمق وضوح رنگ برش قیراط را داریم
25
00:00:59,340 –> 00:01:04,619
، نمی دانم
26
00:01:04,619 –> 00:01:07,290
این به چه معناست، اما درصد
27
00:01:07,290 –> 00:01:10,470
توان ما قیمت X Y Z را داریم که
28
00:01:10,470 –> 00:01:16,259
طول آن در عمق آن الماس است،
29
00:01:16,259 –> 00:01:18,689
بنابراین کنجکاوی این است که آیا میتوانیم همه
30
00:01:18,689 –> 00:01:22,320
این مقادیر را به جز برای قیمت تغذیه
31
00:01:22,320 –> 00:01:25,799
از طریق یک مدل رگرسیونی بگیریم و
32
00:01:25,799 –> 00:01:28,560
قیمت آن الماس را پیشبینی کنیم تا در
33
00:01:28,560 –> 00:01:30,090
آینده وقتی الماس دریافت می کنیم و نمی
34
00:01:30,090 –> 00:01:32,790
دانیم برای الماس های خود چقدر باید بپردازیم،
35
00:01:32,790 –> 00:01:35,369
می توانیم آنها را از طریق یک مدل اجرا کنیم، بنابراین یک
36
00:01:35,369 –> 00:01:38,670
کار رگرسیون معمولی در اینجا هیچ چیز خیلی
37
00:01:38,670 –> 00:01:40,140
جالبی نیست و سؤال این است که آیا این
38
00:01:40,140 –> 00:01:42,600
ویژگی ها به اندازه کافی توصیفی هستند
39
00:01:42,600 –> 00:01:44,990
که قیمت آن را به ما ارائه دهند. این الماس
40
00:01:44,990 –> 00:01:48,899
احتمالاً متوجه خواهیم شد که اگر میخواهید میتوانید از مجموعه داده دیگری استفاده کنید،
41
00:01:48,899 –> 00:01:50,820
42
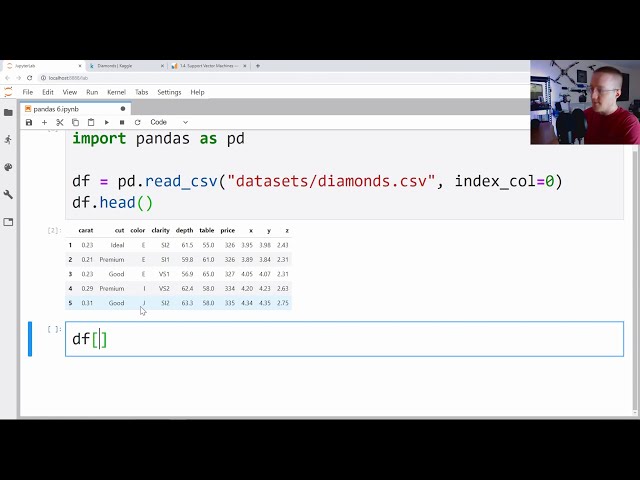
00:01:50,820 –> 00:01:53,220
این یکی تقریباً پنجاه و چهار هزار
43
00:01:53,220 –> 00:01:55,680
ردیف دارد که نمونههای بسیار کمی است که
44
00:01:55,680 –> 00:01:57,060
ما واقعاً میتوانیم در اینجا با آنها کار کنیم
45
00:01:57,060 –> 00:01:59,850
که برای ML سنتی شما بسیار مهم است
46
00:01:59,850 –> 00:02:02,219
. من فکر میکنم احتمالاً بیش از ده
47
00:02:02,219 –> 00:02:05,189
هزار ردیف میخواهم و سپس
48
00:02:05,189 –> 00:02:06,719
اگر میخواهید بیشتر
49
00:02:06,719 –> 00:02:07,950
از صد هزار ردیف به یادگیری عمیق بپردازید، ما
50
00:02:07,950 –> 00:02:10,649
فقط از مدلهای یادگیری ماشینی معمولی استفاده میکنیم،
51
00:02:10,649 –> 00:02:12,090
هیچ چیز خیلی جالبی نیست. ما در
52
00:02:12,090 –> 00:02:13,180
اینجا قصد نداریم یادگیری عمیق را انجام دهیم، اما اگر
53
00:02:13,180 –> 00:02:15,310
در مورد کاری که انجام میدهیم
54
00:02:15,310 –> 00:02:16,359
بیشتر بدانید، میخواهید در مورد
55
00:02:16,359 –> 00:02:19,329
یادگیری ماشینی یا فقط
56
00:02:19,329 –> 00:02:22,090
مدلهای آموزشی ساده یا به طور کلی مدلهای اولیه ml بیاموزید،
57
00:02:22,090 –> 00:02:23,890
میتوانید این آموزش اولیه یادگیری ماشین را بررسی کنید.
58
00:02:23,890 –> 00:02:26,230
در اینجا این یکی اساساً
59
00:02:26,230 –> 00:02:27,609
کاری که ما انجام می دهیم این است که ما با رگرسیون شروع می کنیم
60
00:02:27,609 –> 00:02:28,870
، این همان کاری است که ما در
61
00:02:28,870 –> 00:02:31,299
اینجا انجام می دهیم و در مورد نحوه عملکرد
62
00:02:31,299 –> 00:02:33,250
رگرسیون صحبت می کنیم، یک
63
00:02:33,250 –> 00:02:35,230
مثال کاربردی با استفاده از scikit-learn انجام می دهیم و سپس
64
00:02:35,230 –> 00:02:36,549
در واقع یک مدل رگرسیون
65
00:02:36,549 –> 00:02:39,040
را خودمان می نویسیم و واقعاً ما این کار را با
66
00:02:39,040 –> 00:02:40,930
همه آنها انجام می دهیم تا با رگرسیون K
67
00:02:40,930 –> 00:02:43,510
نزدیکترین همسایه ها ماشین های برداری را پشتیبانی می کنند
68
00:02:43,510 –> 00:02:45,720
و به همین ترتیب ایده این است
69
00:02:45,720 –> 00:02:48,010
که در مورد مدل یاد بگیریم که چگونه
70
00:02:48,010 –> 00:02:49,780
آن را با scikit-learn اعمال کنیم و سپس چگونه
71
00:02:49,780 –> 00:02:52,689
آن را از ابتدا بنویسیم.
72
00:02:52,689 –> 00:02:54,730
از numpy و مواردی از این قبیل استفاده کنید، اما
73
00:02:54,730 –> 00:02:56,169
از نوعی کتابخانه یادگیری ماشین
74
00:02:56,169 –> 00:02:57,790
استفاده نکنید، بنابراین این مجموعه بسیار جالب است و
75
00:02:57,790 –> 00:02:58,719
اگر می خواهید در مورد یادگیری عمیق بیاموزید،
76
00:02:58,719 –> 00:02:59,829
این یکی را بررسی کنید،
77
00:02:59,829 –> 00:03:01,810
بنابراین اگر می خواهید بیشتر
78
00:03:01,810 –> 00:03:03,069
در مورد آن بدانید، این یکی را بررسی کنید. این نوع چیزها در پارامترها،
79
00:03:03,069 –> 00:03:04,480
زیرا پارامترهای زیادی در اینجا وجود دارد
80
00:03:04,480 –> 00:03:07,000
که ما با آنها کار می کنیم و اگر
81
00:03:07,000 –> 00:03:08,530
می خواهید بیشتر بدانید،
82
00:03:08,530 –> 00:03:09,549
احساس نمی کنید که
83
00:03:09,549 –> 00:03:11,169
هنوز در منطقه خاکستری هستید. تا آنجا
84
00:03:11,169 –> 00:03:13,060
که همه این چیزها به چه معناست، می توانید
85
00:03:13,060 –> 00:03:17,199
آن سری را بررسی کنید، بنابراین اکنون آنچه می
86
00:03:17,199 –> 00:03:19,239
خواهیم انجام دهیم این است که فرض کنیم شما یک
87
00:03:19,239 –> 00:03:21,909
آماتور کامل هستید، می توانید
88
00:03:21,909 –> 00:03:24,909
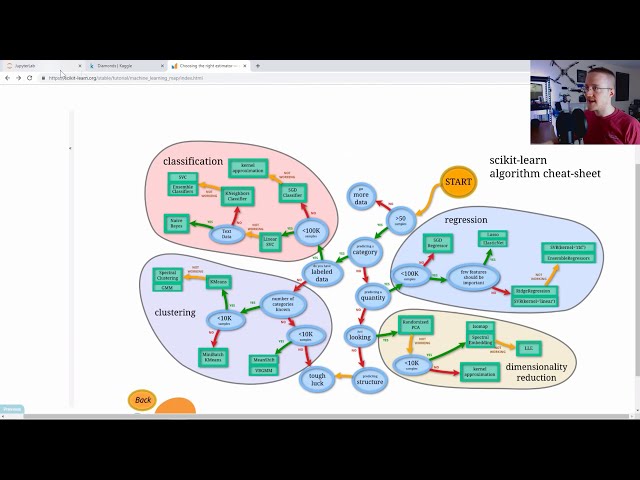
89
00:03:24,909 –> 00:03:26,650
اساساً اگر فقط
90
00:03:26,650 –> 00:03:28,139
تخمینگر مناسب را در گوگل انتخاب کنید، این نمودار برآوردگر مناسب را بررسی کنید. شما متوجه خواهید شد که
91
00:03:28,139 –> 00:03:30,879
این از scikit-learn است و
92
00:03:30,879 –> 00:03:33,459
این دقیقاً روشی است که می توانید یک برآوردگر خاص را
93
00:03:33,459 –> 00:03:36,159
برای آن انتخاب کنید و این یک طبقه بندی کننده
94
00:03:36,159 –> 00:03:39,220
است، مانند مدل شماست که چگونه می توانید برای چیزی که اکنون با آن کار می کنید، یک مورد مناسب را انتخاب کنید.
95
00:03:39,220 –> 00:03:41,139
96
00:03:41,139 –> 00:03:42,939
ما بیش از 50
97
00:03:42,939 –> 00:03:44,949
نمونه داریم که نمیخواهیم دستهای را چاپ
98
00:03:44,949 –> 00:03:46,449
کنیم، میخواهیم مقداری را پیشبینی کنیم،
99
00:03:46,449 –> 00:03:47,799
بنابراین چون در حال انجام
100
00:03:47,799 –> 00:03:49,180
رگرسیون هستیم، میخواهیم قیمت را پیشبینی کنیم
101
00:03:49,180 –> 00:03:51,879
که از آنجایی که یک کار رگرسیونی است،
102
00:03:51,879 –> 00:03:53,259
برخلاف طبقهبندی که در آن
103
00:03:53,259 –> 00:03:55,239
تلاش میکنید. پیش بینی کنید یکی را می شناسید از بین
104
00:03:55,239 –> 00:03:57,009
پنج کلاس در این مورد، بنابراین
105
00:03:57,009 –> 00:03:58,689
طبقه بندی نیست، زیرا مانند هر
106
00:03:58,689 –> 00:04:00,340
قیمتی درست است، ما فقط سعی
107
00:04:00,340 –> 00:04:01,540
می کنیم یک نوع محاسبه
108
00:04:01,540 –> 00:04:05,590
برای قیمت داشته باشیم، آیا کمتر از صد
109
00:04:05,590 –> 00:04:11,259
هزار نمونه داریم اگر نه، پس همینطور است. اگر
110
00:04:11,259 –> 00:04:12,729
نمونههای زیادی داریم، به نوعی
111
00:04:12,729 –> 00:04:13,989
گیجکننده است، اگر بیش از
112
00:04:13,989 –> 00:04:15,549
صد هزار نمونه دارید، با رگرسیون std بروید
113
00:04:15,549 –> 00:04:18,190
یا در غیر این صورت باید
114
00:04:18,190 –> 00:04:20,738
به اینجا بروید یا با رگرسیون بردار پشتیبان
115
00:04:20,738 –> 00:04:23,020
با یک هسته خطی، بنابراین
116
00:04:23,020 –> 00:04:26,110
احتمالاً هسته خطی خود را SV انجام میدهیم.
117
00:04:26,110 –> 00:04:27,639
و دوباره اگر نمیدانید چیست
118
00:04:27,639 –> 00:04:29,259
، فقط روی آن کلیک کنید و این
119
00:04:29,259 –> 00:04:30,669
به شما میگوید خوب است، این چیزی است که باید انجام
120
00:04:30,669 –> 00:04:33,430
دهید، خوب من متوجه شدم درست
121
00:04:33,430 –> 00:04:35,110
122
00:04:35,110 –> 00:04:37,599
است.
123
00:04:37,599 –> 00:04:41,919
آسان است، پس بیایید شروع
124
00:04:41,919 –> 00:04:46,060
کنیم تا پانداها را بهعنوان PD وارد کنیم،
125
00:04:46,060 –> 00:04:49,379
میخواهیم بگوییم DF برابر است با PD
126
00:04:49,379 –> 00:04:52,240
تاریخ CSV را نخوانید، اوه، مجموعههای داده D بزرگ نیست
127
00:04:52,240 –> 00:04:56,439
و الماسها CSV نیستند، سپس
128
00:04:56,439 –> 00:04:59,129
میخواهیم بگوییم فهرست تماس برابر با صفر است زیرا
129
00:04:59,129 –> 00:05:03,190
این مجموعه داده گریس خوش شانس هستیم
130
00:05:03,190 –> 00:05:05,560
که آووکادو با ایندکس دوست داشتنی است نه
131
00:05:05,560 –> 00:05:08,740
تنها بی فایده است، بلکه به
132
00:05:08,740 –> 00:05:16,180
صورت رشته ای نیز بسیار خوب است، بنابراین به
133
00:05:16,180 –> 00:05:17,740
اینجا برگردیم بنابراین می گوییم فراخوانی شاخص
134
00:05:17,740 –> 00:05:19,210
برابر با صفر است زیرا به این ترتیب
135
00:05:19,210 –> 00:05:21,819
شاخص های تکراری در آن تولید نمی کنیم. در این مورد
136
00:05:21,819 –> 00:05:24,509
، ستون ایندکس کاملا بی فایده است،
137
00:05:24,509 –> 00:05:26,889
اما یک چیزی که همیشه می خواهید به
138
00:05:26,889 –> 00:05:28,779
آن توجه داشته باشید این است که اجازه دهید به جلو برویم و
139
00:05:28,779 –> 00:05:33,759
هر زمانی که در حال انجام یادگیری ماشینی هستید، فقط سر نقطه DF را اینجا قرار دهید.
140
00:05:33,759 –> 00:05:37,300
141
00:05:37,300 –> 00:05:39,759
142
00:05:39,759 –> 00:05:41,740
شما تمام تلاش خود را می
143
00:05:41,740 –> 00:05:44,770
کنید، آسان است که این کار را نکنید، بنابراین با نگاه کردن به این
144
00:05:44,770 –> 00:05:47,229
مجموعه داده ها، به هر حال
145
00:05:47,229 –> 00:05:50,020
با نگاه کردن به این مجموعه داده ها، کلاهبرداری آسان است، اساساً ما
146
00:05:50,020 –> 00:05:51,729
دوست داریم همه ستون های اینجا ستون های
147
00:05:51,729 –> 00:05:54,699
معنی دار هستند و سپس شما به جز قیمت قیمت، فضولی دارید.
148
00:05:54,699 –> 00:05:56,440
قیمت نفت
149
00:05:56,440 –> 00:05:57,759
نیز معنادار است، اما قیمت همان چیزی است که
150
00:05:57,759 –> 00:05:59,620
ما سعی میکنیم پیشبینی کنیم، بنابراین وقتی میخواهیم
151
00:05:59,620 –> 00:06:01,330
این مدل را بسازیم، در واقع میخواهیم از
152
00:06:01,330 –> 00:06:03,879
همه ستونها استفاده کنیم و قیمت را تعیین
153
00:06:03,879 –> 00:06:05,050
کنیم، اما وقتی به آن نقطه رسیدیم، به چیزی اشاره میکنم.
154
00:06:05,050 –> 00:06:10,960
بیرون و اگر فراموش کنم
155
00:06:10,960 –> 00:06:13,210
یک نفر در زیر نظر دهد
156
00:06:13,210 –> 00:06:16,089
زیرا بسیار مهم است بنابراین مجموعه دادههای ما
157
00:06:16,089 –> 00:06:18,520
اکنون یک چیز در مورد یادگیری ماشینی این است که
158
00:06:18,520 –> 00:06:22,900
تمام دادههایی که
159
00:06:22,900 –> 00:06:25,419
در پایان روز به مدل خود منتقل میکنید، اساساً
160
00:06:25,419 –> 00:06:29,440
تمام یادگیری ماشینی
161
00:06:29,440 –> 00:06:31,930
جبر خطی است، بنابراین همه چیز باید
162
00:06:31,930 –> 00:06:34,120
اعداد باشد. ما باید همه چیز را به اعداد تبدیل کنیم
163
00:06:34,120 –> 00:06:36,430
و در حالت ایده آل آنها اعداد معنی دار هستند
164
00:06:36,430 –> 00:06:37,209
زیرا اگر
165
00:06:37,209 –> 00:06:39,910
معنی دار نباشند بی فایده
166
00:06:39,910 –> 00:06:43,090
هستند بنابراین راه هایی مانند رنگ و وضوح برش وجود دارد که
167
00:06:43,090 –> 00:06:45,700
همه اینها باید
168
00:06:45,700 –> 00:06:48,670
در پانداها به مقادیر عددی تبدیل
169
00:06:48,670 –> 00:06:52,450
شوند. همچنین احتمالاً scikit-learn
170
00:06:52,450 –> 00:06:54,970
و من میدانم که در آشوب و جریان تنسور
171
00:06:54,970 –> 00:06:57,240
است، همیشه مانند دو روش طبقهبندی وجود دارد
172
00:06:57,240 –> 00:06:59,800
که میتوانید آنها را مانند پانداها صدا بزنید، مثلاً
173
00:06:59,800 –> 00:07:04,240
میتوانیم بگوییم DF، بنابراین
174
00:07:04,240 –> 00:07:09,120
اگر فقط بگوییم نقطه برش DF منحصربهفرد است،
175
00:07:09,120 –> 00:07:11,980
خیلی خوب نیست. در اینجا تعداد زیادی وجود دارد، اما می
176
00:07:11,980 –> 00:07:13,300
توانید سناریویی را تصور کنید که در آن تعداد زیادی وجود دارد،
177
00:07:13,300 –> 00:07:17,140
بنابراین این مشکل را ایجاد می کند که باید
178
00:07:17,140 –> 00:07:19,810
آنها را به مقادیر عددی تبدیل کنیم، خوب
179
00:07:19,810 –> 00:07:27,730
یکی از گزینه هایی که شما دارید، قطع DF است به هر حال
180
00:07:27,730 –> 00:07:28,930
متأسفانه سعی کردم ببینم آیا th at
181
00:07:28,930 –> 00:07:30,550
ترتیب معنیداری داشت، فکر نمیکنم اینطور باشد،
182
00:07:30,550 –> 00:07:33,730
اما به هر حال DF برش داد و سپس میتوانیم بگوییم
183
00:07:33,730 –> 00:07:36,430
نقطه به عنوان نوع و میتوانیم این نوع را به دستهبندی تبدیل کنیم،
184
00:07:36,430 –> 00:07:40,270
در واقع فکر میکنم
185
00:07:40,270 –> 00:07:48,130
رده E است و سپس کد نقطهای نقطه گربه
186
00:07:48,130 –> 00:07:52,300
را اجرا میکنم. خیلی سریع اما کدها
187
00:07:52,300 –> 00:07:53,500
وجود دارد ما خوب میرویم،
188
00:07:53,500 –> 00:07:57,040
بنابراین این کاهش مییابد و میفهمد
189
00:07:57,040 –> 00:07:58,630
خوب چند تا منحصربهفرد
190
00:07:58,630 –> 00:08:01,270
وجود دارد و سپس فقط RS را اختصاص میدهد،
191
00:08:01,270 –> 00:08:02,860
میدانید که اولین موردی که پیدا میکند صفر است
192
00:08:02,860 –> 00:08:06,040
متأسفم صفر دومی یک دو
193
00:08:06,040 –> 00:08:07,450
سه است. این کار را ادامه می دهد تا زمانی
194
00:08:07,450 –> 00:08:09,220
که انجام شود، به حداکثر
195
00:08:09,220 –> 00:08:11,050
تعداد می رسد و بنابراین فقط یک
196
00:08:11,050 –> 00:08:17,200
کد دلخواه به برش ما اختصاص می دهد، مشکل این است
197
00:08:17,200 –> 00:08:19,480
که ما در حال انجام رگرسیون به احتمال زیاد
198
00:08:19,480 –> 00:08:22,870
رگرسیون خطی هستیم و ترجیح می دهیم
199
00:08:22,870 –> 00:08:25,810
مقادیر ما در اینجا معنی پشت آنها
200
00:08:25,810 –> 00:08:29,140
داشته باشند، زیرا برش این است حق خودسرانه نیست
201
00:08:29,140 –> 00:08:32,320
حق بیمه بهتر از منصفانه است و غیره،
202
00:08:32,320 –> 00:08:37,030
بنابراین ما می خواهیم آن نظم را حفظ کنیم، بنابراین می خواهیم این نظم
203
00:08:37,030 –> 00:08:38,979
را حفظ کنیم،
204
00:08:38,979 –> 00:08:41,500
بنابراین اگر بعداً در حال
205
00:08:41,500 –> 00:08:43,270
انجام طبقه بندی هستید، فقط به
206
00:08:43,270 –> 00:08:45,850
کلاس های دلخواه نیاز دارید، بنابراین وقتی در حال انجام
207
00:08:45,850 –> 00:08:48,670
طبقهبندی g میتوانید از این
208
00:08:48,670 –> 00:08:51,130
کاملاً برای تبدیل کلاسهای خود به کد استفاده کنید،
209
00:08:51,130 –> 00:08:53,710
اما در این مورد برای ویژگیها،
210
00:08:53,710 –> 00:08:55,750
ما ویژگیهای ما معنادار است، بنابراین این
211
00:08:55,750 –> 00:08:57,760
کار را انجام نمیدهیم، بنابراین کاری که من انجام میدهم
212
00:08:57,760 –> 00:09:00,940
ایجاد فرهنگ لغت برای همه
213
00:09:00,940 –> 00:09:02,710
این موارد و در در واقع من
214
00:09:02,710 –> 00:09:04,390
اینها را از آموزش مبتنی بر متن کپی و پیست می کنم
215
00:09:04,390 –> 00:09:06,190
زیرا اینجا چیزی برای
216
00:09:06,190 –> 00:09:10,330
تمیز کردن وجود ندارد پس کپی/پیست کنید چرا اجازه می دهیم
217
00:09:10,330 –> 00:09:11,530
کمی بزرگنمایی کنم آنها
218
00:09:11,530 –> 00:09:14,740
کمی دورتر هستند و سپس
219
00:09:14,740 –> 00:09:17,920
این یکی را کپی و جایگذاری کنید بنابراین اینها فقط
220
00:09:17,920 –> 00:09:19,870
فرهنگ لغت هایی هستند که ما نقشه می کشیم از
221
00:09:19,870 –> 00:09:21,850
کجا من این را در دوستدار الماس خود می دانستم
222
00:09:21,850 –> 00:09:25,270
نه من اینها را از
223
00:09:25,270 –> 00:09:27,400
توضیحات اینجا پیدا کردم مجموعه داده هایی است که آنها آنها را
224
00:09:27,400 –> 00:09:33,940
سفارش می دهند و چیزهایی برای ما دارند، بنابراین بله،
225
00:09:33,940 –> 00:09:38,110
اکنون مشتریان جالبی شروع کردم این
226
00:09:38,110 –> 00:09:40,660
یکی در 0 که نباید مهم باشد،
227
00:09:40,660 –> 00:09:43,540
اما خندهدار است، من میخواهم آن را درست کنم،
228
00:09:43,540 –> 00:09:46,870
بیایید درستش کنیم، نمیدانم چطور
229
00:09:46,870 –> 00:09:49,210
الان متوجه آن شدم، اما به هر حال اجازه دهید
230
00:09:49,210 –> 00:09:56,110
سریع آن را درست کنم یا 5 6 و 7 را درست
231
00:09:56,110 –> 00:09:58,480
نمیکنم اگر بتوانم از i اجتناب کنم، می خواهم مقدار 0 را
232
00:09:58,480 –> 00:10:00,790
به مدل رگرسیونی خود منتقل
233
00:10:00,790 –> 00:10:02,680
کنم اجازه ندهید آن را در یک نسخه مبتنی بر متن حل کنم،
234
00:10:02,680 –> 00:10:06,820
خوب است، بنابراین حالا که ما اینها را
235
00:10:06,820 –> 00:10:11,110
داریم، فقط می خواهیم آنها را نقشه برداری کنیم، بنابراین من فقط
236
00:10:11,110 –> 00:10:12,460
می خواهم اینجا بیایم و می گویم
237
00:10:12,460 –> 00:10:23,980
برش DF برابر است با DF cut da map و سپس ما
238
00:10:23,980 –> 00:10:26,830
فقط نقشه برش کلاس دیکت درست است
239
00:10:26,830 –> 00:10:28,390
و سپس ما دقیقاً همان
240
00:10:28,390 –> 00:10:30,370
کار را برای وضوح و رنگ انجام می دهیم، بنابراین من فقط
241
00:10:30,370 –> 00:10:32,770
کپی پیست می کنم کپی پیست این کپی پیست را انجام می دهم
242
00:10:32,770 –> 00:10:35,590
و سپس فقط شفافیت
243
00:10:35,590 –> 00:10:39,160
دیکت و سپس دیکت رنگی است. نه
244
00:10:39,160 –> 00:10:44,130
فقط رنگها همه رنگها و رنگها عالی میخواهم،
245
00:10:44,130 –> 00:10:46,230
246
00:10:46,230 –> 00:10:48,940
بنابراین همه آنها را نقشهبرداری میکنیم، اجازه دهید فقط آن را
247
00:10:48,940 –> 00:10:50,680
با سر DF در انتهای
248
00:10:50,680 –> 00:10:55,660
آن بررسی کنیم، عالی است ما اکنون مجموعه دادههایمان را داریم،
249
00:10:55,660 –> 00:10:57,430
اساساً آماده است، تبدیل شده است
250
00:10:57,430 –> 00:11:00,130
، آماده هستیم تا آن را از طریق یک
251
00:11:00,130 –> 00:11:02,590
ما به نوعی در مورد مدل واقعی صحبت خواهیم کرد
252
00:11:02,590 –> 00:11:04,780
که چرا در ابتدا نیاز
253
00:11:04,780 –> 00:11:06,880
به یادگیری scikit نداریم، بنابراین بیایید به خط فرمان مورد علاقه خود برویم
254
00:11:06,880 –> 00:11:07,630
255
00:11:07,630 –> 00:11:11,590
و کیت Sai را نصب
256
00:11:11,590 –> 00:11:15,070
کنیم – یاد بگیریم که scikit-learn را دریافت خواهیم کرد و
257
00:11:15,070 –> 00:11:16,600
در حین انجام آن فکر می کنم تازه
258
00:11:16,600 –> 00:11:18,490
برمی گردم و تازه شروع به تایپ کردن می کنم که
259
00:11:18,490 –> 00:11:22,300
خیلی جالب است، بنابراین ما می خواهیم تحمیل کنیم rt
260
00:11:22,300 –> 00:11:25,540
SK یاد بگیرید و سپس از SK می رویم
261
00:11:25,540 –> 00:11:32,860
یاد بگیریم SV em را بیاموزیم، بنابراین من می خواهم
262
00:11:32,860 –> 00:11:34,450
فضایی ایجاد کنم اما نمی توانم زیرا
263
00:11:34,450 –> 00:11:36,760
احتمالاً نصب می شود، اما ما خیلی خوب هستیم،
264
00:11:36,760 –> 00:11:43,420
پس چه نوع عالی است،
265
00:11:43,420 –> 00:11:46,090
خب میخواهید اول انجام دهید، هر زمان
266
00:11:46,090 –> 00:11:48,640
که دادهای دارید، احتمالاً میخواهید آن دادهها را با هم مخلوط کنید،
267
00:11:48,640 –> 00:11:52,960
زیرا آخرین چیزی که اغلب
268
00:11:52,960 –> 00:11:55,570
ما آموزش میدهیم و نظم را دوست داریم و
269
00:11:55,570 –> 00:11:57,820
آخرین چیز بیشتر
270
00:11:57,820 –> 00:11:59,950
از اولین چیزی که مدل
271
00:11:59,950 –> 00:12:01,690
دیده است، مغرضانهتر است. معمولاً ایده خوبی است
272
00:12:01,690 –> 00:12:04,180
که مدل را به هم بزنیم، به خصوص اگر آنها مرتب شوند
273
00:12:04,180 –> 00:12:07,930
اگر مجموعه داده به هر نحوی مرتب شده باشد و آیا
274
00:12:07,930 –> 00:12:11,110
این مجموعه داده به هر نحوی مرتب شده است، به
275
00:12:11,110 –> 00:12:14,770
اینجا می آییم و اگر به
276
00:12:14,770 –> 00:12:18,760
بالای صفحه بروید، می بینیم که قیمت ظاهر می شود.
277
00:12:18,760 –> 00:12:22,840
به نظر می رسد که این مجموعه داده
278
00:12:22,840 –> 00:12:27,820
اکنون بر اساس قیمت سفارش داده شده است، بنابراین این یک مشکل است
279
00:12:27,820 –> 00:12:30,340
و سپس ممکن است بعداً به یک مشکل تبدیل شود،
280
00:12:30,340 –> 00:12:33,850
بنابراین ابتدا این مجموعه داده را به هم می زنم تا آن را به پایان برسانم،
281
00:12:33,850 –> 00:12:35,950
بنابراین
282
00:12:35,950 –> 00:12:38,230
راه های زیادی برای به هم زدن یک داده وجود دارد.
283
00:12:38,230 –> 00:12:41,050
در پانداها راهی برای انجام این کار
284
00:12:41,050 –> 00:12:43,600
با ایندکس وجود دارد، اما من d من نمی خواهم
285
00:12:43,600 –> 00:12:46,240
این کار را انجام دهم زیرا روشی که
286
00:12:46,240 –> 00:12:47,890
پانداها شما انجام
287
00:12:47,890 –> 00:12:50,710
288
00:12:50,710 –> 00:12:52,000
289
00:12:52,000 –> 00:12:55,150
می دهند زشت است. SK
290
00:12:55,150 –> 00:12:59,860
شما را یاد گرفت تا زمانی که z’ dot shuffle DF انجام داد
291
00:12:59,860 –> 00:13:03,970
که قاب داده به هم ریخته است اکنون می خواهیم
292
00:13:03,970 –> 00:13:06,370
مقادیر x و y را اختصاص دهیم بنابراین در
293
00:13:06,370 –> 00:13:08,320
یادگیری ماشینی به طور کلی بزرگ X
294
00:13:08,320 –> 00:13:10,810
مجموعه ویژگی شماست با حروف کوچک Y گاهی اوقات
295
00:13:10,810 –> 00:13:13,150
می بینید که افراد از حروف بزرگ Y استفاده می کنند.
296
00:13:13,150 –> 00:13:17,560
آیا برچسب های شما هستند بنابراین X چیست X X
297
00:13:17,560 –> 00:13:20,579
مجموعه ویژگی است، بنابراین این
298
00:13:20,579 –> 00:13:22,739
لیست ویژگی هایی است که به
299
00:13:22,739 –> 00:13:25,110
آن برچسب نشان می دهد که قیمت برچسب چقدر است، بنابراین
300
00:13:25,110 –> 00:13:26,850
لیست ویژگی ها اساساً همه چیز است
301
00:13:26,850 –> 00:13:29,579
به جز قی