در این مطلب، ویدئو Naive Bayes در پایتون – یادگیری ماشینی از ابتدا 05 – آموزش پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:20:42
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:02,370
سلام به همه خوش آمدید به یک
2
00:00:02,370 –> 00:00:04,859
آموزش
3
00:00:04,859 –> 00:00:06,690
4
00:00:06,690 –> 00:00:09,360
5
00:00:09,360 –> 00:00:12,200
یادگیری ماشینی
6
00:00:12,200 –> 00:00:15,839
7
00:00:15,839 –> 00:00:19,380
جدید از ابتدا.
8
00:00:19,380 –> 00:00:23,029
و B آنگاه احتمال رویداد a
9
00:00:23,029 –> 00:00:26,599
با توجه به اینکه B قبلاً اتفاق افتاده است
10
00:00:26,599 –> 00:00:30,840
برابر است با احتمال B با توجه به اینکه
11
00:00:30,840 –> 00:00:34,230
a اتفاق افتاده است ضربدر احتمال
12
00:00:34,230 –> 00:00:38,969
a تقسیم بر احتمال B و اگر
13
00:00:38,969 –> 00:00:41,879
این را در مورد خود اعمال کنیم
14
00:00:41,879 –> 00:00:47,489
فرمول ما این است احتمال Y از
15
00:00:47,489 –> 00:00:51,800
کلاس Y ما با توجه به بردار ویژگی X
16
00:00:51,800 –> 00:00:56,180
برابر است با احتمال X داده شده با Y ضرب در
17
00:00:56,180 –> 00:01:03,989
P از Y تقسیم بر P از X و جایی که
18
00:01:03,989 –> 00:01:07,590
X بردار ویژگی ما است که
19
00:01:07,590 –> 00:01:12,180
از چندین ویژگی تشکیل شده است و اکنون به آن
20
00:01:12,180 –> 00:01:15,119
سوگیری ساده لوح گفته می شود زیرا اکنون ما این فرض را میکنیم
21
00:01:15,119 –> 00:01:17,340
که همه ویژگیها از
22
00:01:17,340 –> 00:01:20,939
یکدیگر مستقل هستند، به این معنی که
23
00:01:20,939 –> 00:01:23,369
مثلاً اگر میخواهید
24
00:01:23,369 –> 00:01:26,400
25
00:01:26,400 –> 00:01:27,439
26
00:01:27,439 –> 00:01:30,689
با توجه به این ویژگی که خورشید
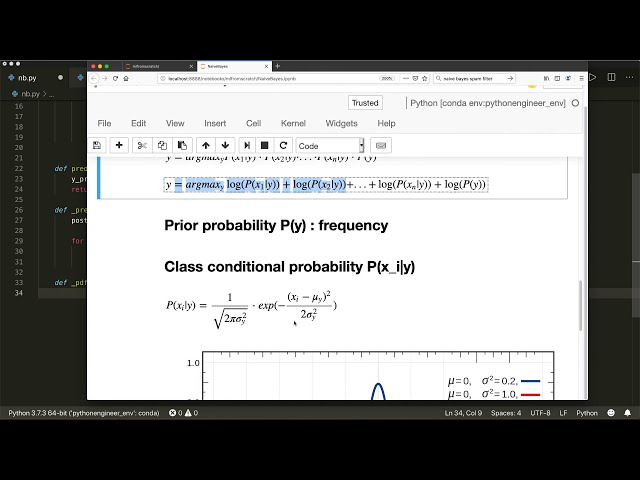
27
00:01:30,689 –> 00:01:33,659
میدرخشد، احتمال اینکه فردی برای دویدن بیرون میرود را پیشبینی کنید. همچنین با توجه به این ویژگی
28
00:01:33,659 –> 00:01:36,960
که فرد سالم است، هر دوی این
29
00:01:36,960 –> 00:01:41,700
ویژگیها ممکن است مستقل باشند، اما هر دو
30
00:01:41,700 –> 00:01:44,369
به این احتمال کمک میکنند که
31
00:01:44,369 –> 00:01:49,100
فرد از بین برود، بنابراین در زندگی واقعی بسیاری از
32
00:01:49,100 –> 00:01:51,659
ویژگیها مستقل از یکدیگر نیستند،
33
00:01:51,659 –> 00:01:54,689
اما این فرض برای بسیاری
34
00:01:54,689 –> 00:01:58,439
از مشکلات خوب عمل میکند. و با این فرض
35
00:01:58,439 –> 00:02:06,060
میتوانیم این احتمال را به
36
00:02:06,060 –> 00:02:09,690
قاعده زنجیره تقسیم کنیم و از قانون زنجیره استفاده کنیم، بنابراین
37
00:02:09,690 –> 00:02:14,240
احتمال هر ویژگی را
38
00:02:14,240 –> 00:02:19,830
با توجه به چرایی محاسبه میکنیم و هر کدام را ضرب میکنیم و سپس
39
00:02:19,830 –> 00:02:23,340
آن را با P از Y ضرب میکنیم و بر P
40
00:02:23,340 –> 00:02:30,060
از X تقسیم میکنیم و به هر حال و به این P از Y
41
00:02:30,060 –> 00:02:32,750
X داده شده احتمال عقبی
42
00:02:32,750 –> 00:02:37,350
P از x داده شده Y را
43
00:02:37,350 –> 00:02:41,220
احتمال شرطی کلاس و P از
44
00:02:41,220 –> 00:02:44,730
Y را احتمال قبلی Y و
45
00:02:44,730 –> 00:02:47,610
P از X را احتمال قبلی X می نامند
46
00:02:47,610 –> 00:02:51,260
و اکنون می خواهیم بسازیم یک
47
00:02:51,260 –> 00:02:54,740
طبقه بندی بنابراین با توجه به این
48
00:02:54,740 –> 00:02:58,380
احتمال پسین می خواهیم کلاسی را
49
00:02:58,380 –> 00:03:01,530
با بالاترین احتمال انتخاب کنیم، بنابراین
50
00:03:01,530 –> 00:03:07,040
Y را انتخاب می کنیم که حداکثر قوس Y
51
00:03:07,040 –> 00:03:11,459
این احتمال پسین است و اکنون
52
00:03:11,459 –> 00:03:14,820
می توانیم فرمول خود را اعمال کنیم d از آنجایی که ما
53
00:03:14,820 –> 00:03:18,180
فقط به این علاقه داریم که چرا به
54
00:03:18,180 –> 00:03:21,630
این P از X نیاز نداریم، بنابراین می توانیم آن را خط بزنیم و
55
00:03:21,630 –> 00:03:26,580
سپس فرمول ما این است، پس چرا
56
00:03:26,580 –> 00:03:31,010
حداکثر کمان از است و سپس هر
57
00:03:31,010 –> 00:03:34,470
کلاس احتمال شرطی و
58
00:03:34,470 –> 00:03:38,100
سپس احتمال قبلی را ضرب می کنیم و سپس از یک ترفند کوچک استفاده می کنیم
59
00:03:38,100 –> 00:03:41,670
زیرا همه این مقادیر
60
00:03:41,670 –> 00:03:46,560
احتمالات ما بین 0 و 1 هستند، بنابراین اگر
61
00:03:46,560 –> 00:03:49,050
تعداد زیادی از این مقادیر را ضرب کنیم،
62
00:03:49,050 –> 00:03:52,500
اعداد بسیار کوچکی به دست می آید و ممکن
63
00:03:52,500 –> 00:03:55,769
است با مشکلات سرریز مواجه شویم، بنابراین
64
00:03:55,769 –> 00:03:58,080
برای جلوگیری از این امر تابع قفل را اعمال می
65
00:03:58,080 –> 00:04:01,470
کنیم. بنابراین ما قفل را برای هر یک
66
00:04:01,470 –> 00:04:05,040
از این احتمالات اعمال می کنیم و با قفل
67
00:04:05,040 –> 00:04:07,830
یا قوانین لگاریتم می
68
00:04:07,830 –> 00:04:11,340
توانیم علامت ضرب را به یک علامت مثبت تبدیل
69
00:04:11,340 –> 00:04:14,400
کنیم و اکنون اینجا یک جمع
70
00:04:14,400 –> 00:04:18,358
داریم و اکنون این فرمول را
71
00:04:18,358 –> 00:04:20,970
داریم که نیاز داریم و اکنون نیاز داریم. برای رسیدن به
72
00:04:20,970 –> 00:04:24,690
این احتمال قبلی، بنابراین احتمال قبلی
73
00:04:24,690 –> 00:04:29,010
فقط فرکانس است
74
00:04:29,010 –> 00:04:31,440
که میتوانیم آن را در یک ثانیه ببینیم و
75
00:04:31,440 –> 00:04:34,110
سپس این احتمال شرطی کلاس
76
00:04:34,110 –> 00:04:39,390
P از X با توجه به Y چقدر است و در اینجا
77
00:04:39,390 –> 00:04:42,260
این را با یک توزیع گاوسی مدل میکنیم
78
00:04:42,260 –> 00:04:46,320
تا h قبل از اینکه بتوانیم فرمول را ببینیم پس
79
00:04:46,320 –> 00:04:49,650
این 1 است و سپس جذر 2
80
00:04:49,650 –> 00:04:54,960
پی ضربدر واریانس Y
81
00:04:54,960 –> 00:04:59,190
ضربدر تابع نمایی منهای X
82
00:04:59,190 –> 00:05:02,580
منهای میانگین مقدار مجذور تقسیم بر 2
83
00:05:02,580 –> 00:05:05,610
برابر واریانس و در اینجا
84
00:05:05,610 –> 00:05:08,580
نموداری از تابع گاوسی برای
85
00:05:08,580 –> 00:05:11,850
86
00:05:11,850 –> 00:05:15,390
87
00:05:15,390 –> 00:05:20,730
میانگین ها و تغییرات مختلف بدون واریانس است، بنابراین این یک احتمال است که همیشه بین 0 و 1 است و بله با
88
00:05:20,730 –> 00:05:23,760
این فرمول ها این تمام چیزی است که برای شروع نیاز داریم،
89
00:05:23,760 –> 00:05:27,720
بنابراین اکنون می توانیم آن را شروع و
90
00:05:27,720 –> 00:05:29,760
پیاده سازی کنیم و اول از همه
91
00:05:29,760 –> 00:05:34,800
البته وارد می کنیم. numpy به عنوان NP و سپس
92
00:05:34,800 –> 00:05:40,530
کلاسی به نام naive bias ایجاد می کنیم
93
00:05:40,530 –> 00:05:43,140
که نیازی به متد init ندارد بنابراین می توانیم
94
00:05:43,140 –> 00:05:46,080
ابتدا متد fit را پیاده سازی کنیم بنابراین می
95
00:05:46,080 –> 00:05:49,980
خواهیم داده های آموزشی و برچسب های آموزشی را برازش کنیم
96
00:05:49,980 –> 00:05:52,950
و سپس می خواهیم
97
00:05:52,950 –> 00:05:58,350
یک متد پیش بینی را نیز پیاده سازی کنیم. بنابراین در اینجا ما
98
00:05:58,350 –> 00:06:02,960
برچسبهای تست را بدون نمونه آزمایشی پیشبینی میکنیم
99
00:06:02,960 –> 00:06:06,330
و حالا بیایید شروع کنیم، بنابراین بیایید با
100
00:06:06,330 –> 00:06:11,330
روش برازش شروع کنیم، بنابراین کاری که میتوانیم در اینجا انجام دهیم این است
101
00:06:11,330 –> 00:06:15,630
که به موارد اولیه نیاز داریم و میتوانیم
102
00:06:15,630 –> 00:06:18,840
آنها را در این روش برازش محاسبه کنیم و
103
00:06:18,840 –> 00:06:22,050
به کلاس شرطی نیاز داریم بنابراین او e ما
104
00:06:22,050 –> 00:06:25,770
به میانگین برای هر کلاس و
105
00:06:25,770 –> 00:06:28,080
واریانس برای هر کلاس نیاز داریم تا بتوانیم اینها را نیز
106
00:06:28,080 –> 00:06:32,340
محاسبه کنیم، بنابراین بیایید این کار را انجام دهیم، بنابراین
107
00:06:32,340 –> 00:06:36,180
بیایید ابتدا تعداد نمونه ها و
108
00:06:36,180 –> 00:06:40,440
تعداد ویژگی ها را بدست
109
00:06:40,440 –> 00:06:41,060
آوریم
110
00:06:41,060 –> 00:06:45,410
و به هر حال X یک داور است. آرایهای
111
00:06:45,410 –> 00:06:48,139
که بعد اول
112
00:06:48,139 –> 00:06:51,260
تعداد نمونهها و بعد دوم
113
00:06:51,260 –> 00:06:53,690
یا تعداد ردیفها تعداد
114
00:06:53,690 –> 00:06:56,300
نمونهها و تعداد ستونها
115
00:06:56,300 –> 00:06:59,419
تعداد ویژگیها است، بنابراین میتوانیم این را باز کنیم
116
00:06:59,419 –> 00:07:07,130
و بگوییم این شکل نقطه X است و Y ما
117
00:07:07,130 –> 00:07:11,660
یک بردار ردیف 1 بعدی نیز با اندازه
118
00:07:11,660 –> 00:07:15,260
تعداد نمونه ها، بنابراین این ورودی ما است و
119
00:07:15,260 –> 00:07:19,580
حالا بیایید کلاس های منحصر به فرد را دریافت کنیم، فرض کنید
120
00:07:19,580 –> 00:07:26,810
کلاس های خود برابر numpy منحصر به فرد Y هستند،
121
00:07:26,810 –> 00:07:29,570
بنابراین عناصر منحصر به فرد یک
122
00:07:29,570 –> 00:07:32,570
آرایه را پیدا می کند، بنابراین اگر دو کلاس 0 و دارید 1
123
00:07:32,570 –> 00:07:37,639
سپس این یک آرایه خواهد بود که فقط 1 0
124
00:07:37,639 –> 00:07:43,430
و 1 Y در آن و 1 1 در آن وجود دارد، پس فرض
125
00:07:43,430 –> 00:07:47,750
کنید تعداد کلاس ها برابر است با
126
00:07:47,750 –> 00:07:54,200
طول این کلاس های خود و حالا اجازه دهید در آن
127
00:07:54,200 –> 00:08:01,780
یا در آن به معنای واریانس و پیشین
128
00:08:01,780 –> 00:08:07,340
ها باشد. self dot به معنای برابر است و ما
129
00:08:07,340 –> 00:08:10,280
می خواهیم آنها را با وی شروع کنیم در ابتدا صفرهای اول
130
00:08:10,280 –> 00:08:16,250
را به دست می آورد و به اندازه ای می رسد که تعداد
131
00:08:16,250 –> 00:08:20,479
کلاس ها و تعداد ویژگی ها را به صورت تاپلی
132
00:08:20,479 –> 00:08:29,110
در اینجا دارد، بنابراین برای هر کلاس نیز
133
00:08:29,110 –> 00:08:37,789
به همان تعداد برای هر کلاس است که
134
00:08:37,789 –> 00:08:44,120
برای هر ویژگی نیاز داریم و می خواهیم
135
00:08:44,120 –> 00:08:46,610
این را دریافت کنیم. به این یک نوع داده
136
00:08:46,610 –> 00:08:53,660
از float numpy dot float64 می دهیم و
137
00:08:53,660 –> 00:08:54,830
می خواهیم این کار را با
138
00:08:54,830 –> 00:08:58,520
همان واریانس ها انجام دهیم، بنابراین فرض کنید خود
139
00:08:58,520 –> 00:09:05,600
نقطه VAR برابر با این است و سپس می
140
00:09:05,600 –> 00:09:11,210
خواهیم خود نقطه های قبلی برابر و پیت
141
00:09:11,210 –> 00:09:15,110
صفرها را انجام دهیم و در اینجا برای هر کلاس ما
142
00:09:15,110 –> 00:09:20,150
یک پیش از آن می خواهید پس این فقط یک بردار 1 بعدی از
143
00:09:20,150 –> 00:09:23,980
اندازه تعداد کلاس ها با نوع داده
144
00:09:23,980 –> 00:09:31,520
خاموش و P نقطه float64 اس




![فیلم آموزشی: [عربی] حل مسائل با پایتون - حرف گم شده را پیدا کنید](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/CnFaB06cHH0image2.jpg)