در این مطلب، ویدئو خوشه بندی سهام با پایتون | قسمت 1 مقدمه با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:11:59
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,000 –> 00:00:03,360
سلام و خوش آمدید به یکی دیگر از
2
00:00:03,360 –> 00:00:06,000
آموزش های پایتون در ویدیوی امروز، ما
3
00:00:06,000 –> 00:00:08,340
مجموعه ای را شروع می کنیم که چندین
4
00:00:08,340 –> 00:00:11,240
ویدیو طولانی خواهد بود، نحوه
5
00:00:11,240 –> 00:00:15,030
خوشه بندی سهام در پایتون با استفاده از
6
00:00:15,030 –> 00:00:17,670
الگوریتم k-means را مشاهده خواهیم کرد، بنابراین این بخشی از
7
00:00:17,670 –> 00:00:21,390
سری یادگیری ماشین ما است. و
8
00:00:21,390 –> 00:00:23,010
با توجه به موضوع،
9
00:00:23,010 –> 00:00:25,650
دادههای مالی بیشتری را در ویدیوهای قبلی خود انجام میدهیم
10
00:00:25,650 –> 00:00:27,240
که مربوط به یادگیری ماشینی بود،
11
00:00:27,240 –> 00:00:30,510
نحوه انجام رگرسیون خطی را دیدیم، نحوه انجام رگرسیون چندگانه را
12
00:00:30,510 –> 00:00:32,430
دیدیم و اکنون
13
00:00:32,430 –> 00:00:34,260
به سراغ برخی از الگوریتمهای خوشهبندی میرویم.
14
00:00:34,260 –> 00:00:37,680
بیایید به نوعی
15
00:00:37,680 –> 00:00:39,840
پیشزمینه ارائه دهیم و بفهمیم
16
00:00:39,840 –> 00:00:41,520
که شاید چرا میخواهیم این الگوریتم خاص را انجام
17
00:00:41,520 –> 00:00:42,899
دهیم و نوع
18
00:00:42,899 –> 00:00:45,180
مشکلی که برای حل آن طراحی شده است،
19
00:00:45,180 –> 00:00:47,399
تصور کنید شاید در نوعی
20
00:00:47,399 –> 00:00:49,110
شرکت مدیریت ثروت یا نوعی
21
00:00:49,110 –> 00:00:51,660
شرکت مالی کار میکنید و شما فقط
22
00:00:51,660 –> 00:00:54,899
مجموعه عظیمی از داده ها به شما داده شد، این مجموعه داده خاص
23
00:00:54,899 –> 00:00:56,899
شامل یک دسته سهام بود و
24
00:00:56,899 –> 00:01:00,570
همراه با هر سهام، شاید 50
25
00:01:00,570 –> 00:01:03,719
یا 40 ستون از معیارهای مختلف داشتید، بنابراین
26
00:01:03,719 –> 00:01:05,309
شاید چیزهایی مانند بازده داراییها
27
00:01:05,309 –> 00:01:09,600
بازده سرمایهگذاریها میدانید
28
00:01:09,600 –> 00:01:11,939
ارزش بازار چیست EBIT
29
00:01:11,939 –> 00:01:13,680
انواع معیارهای مالی مختلف و
30
00:01:13,680 –> 00:01:15,390
میدانید که شاید مدیر شما بیاید
31
00:01:15,390 –> 00:01:17,670
و بگوید هی میتوانید
32
00:01:17,670 –> 00:01:20,189
با همه این دادهها ساختاری ایجاد کنید، بنابراین ما
33
00:01:20,189 –> 00:01:22,020
واقعاً نمیدانیم ساختاری
34
00:01:22,020 –> 00:01:24,180
که وجود دارد، اما ما باید آن را
35
00:01:24,180 –> 00:01:26,490
به گروههای خاصی تقسیم کنیم و خوب بد باشیم
36
00:01:26,490 –> 00:01:28,680
و میدانی که میدانی کمتر از حد متوسط یا هر
37
00:01:28,680 –> 00:01:30,000
یزی که میدانی، اما با
38
00:01:30,000 –> 00:01:31,380
د بتوانی آن را به گروهها تقسیم کنیم و ب
39
00:01:31,380 –> 00:01:33,479
طور طبیعی. شما کار را شروع
40
00:01:33,479 –> 00:01:35,549
میکنید و خوب پیش میروید، بیایید به گوگل نگاه
41
00:01:35,549 –> 00:01:38,340
کنیم، ببینیم چه اتفاقی میافتد و بنابراین
42
00:01:38,340 –> 00:01:40,409
طبیعتاً شروع به رفتن به Google میکنید و قبل از اینکه
43
00:01:40,409 –> 00:01:41,700
متوجه شوید با مفهومی
44
00:01:41,700 –> 00:01:43,860
به نام خوشهبندی مواجه میشوید و شروع میکنید به
45
00:01:43,860 –> 00:01:45,710
اینکه چندین
46
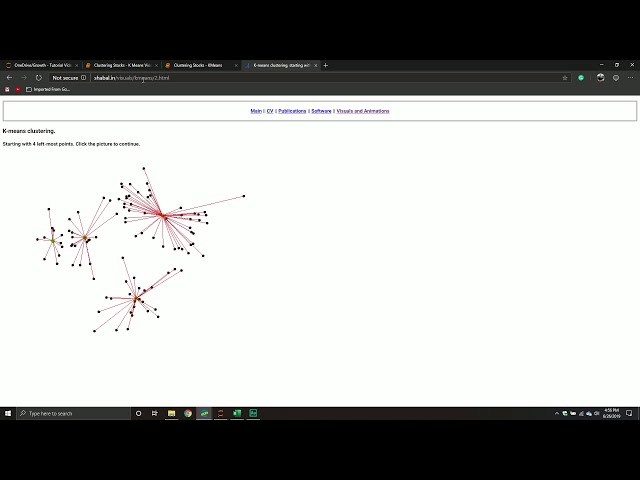
00:01:45,710 –> 00:01:48,659
الگوریتم وجود دارد. که به گونه ای طراحی شده اند
47
00:01:48,659 –> 00:01:51,390
که این مجموعه داده عظیم را جمع آوری کرده و اساساً
48
00:01:51,390 –> 00:01:53,850
آن را به قطعات تقسیم کنند و
49
00:01:53,850 –> 00:01:55,770
مهمتر از آن، این نوع تکه ها
50
00:01:55,770 –> 00:01:57,270
قرار است بهینه سازی شوند تا
51
00:01:57,270 –> 00:01:59,159
تعادل داشته باشند و اساساً اینگونه باشند.
52
00:01:59,159 –> 00:02:01,770
بر اساس شباهت، بنابراین اگر یک
53
00:02:01,770 –> 00:02:04,500
عنصر بخشی از گروه دیگری باشد، آن
54
00:02:04,500 –> 00:02:06,479
عناصر خاص در آن گروه
55
00:02:06,479 –> 00:02:10,489
قرار است به نحوی مشابه باشند و
56
00:02:10,489 –> 00:02:12,660
طبیعتاً کمی عمیقتر
57
00:02:12,660 –> 00:02:13,810
58
00:02:13,810 –> 00:02:15,520
میشوید و بلافاصله با این
59
00:02:15,520 –> 00:02:18,610
الگوریتم به نام k-means مواجه میشوید. k-means یک
60
00:02:18,610 –> 00:02:20,830
الگوریتم یادگیری ماشینی بسیار محبوب است
61
00:02:20,830 –> 00:02:23,410
و با هدف k-means همانطور
62
00:02:23,410 –> 00:02:26,260
که این مجموعه داده بدون برچسب را می گیریم، بنابراین این
63
00:02:26,260 –> 00:02:28,270
مجموعه داده ای است که
64
00:02:28,270 –> 00:02:30,880
دسته بندی ارائه نکرده ایم، ما برای آن گروهی ارائه نکرده
65
00:02:30,880 –> 00:02:33,100
ایم. واقعاً به آن بگویید که
66
00:02:33,100 –> 00:02:35,800
هر گروه به چه نقطه داده ای اشاره می کند که هر داده به چه گروهی
67
00:02:35,800 –> 00:02:38,860
تعلق دارد، بنابراین ما این مجموعه داده های بدون برچسب را به آن تغذیه می کنیم
68
00:02:38,860 –> 00:02:41,470
و اساساً چیزی که
69
00:02:41,470 –> 00:02:43,600
به ما می ریزد این مجموعه داده های ساختار یافته است که
70
00:02:43,600 –> 00:02:47,290
به گروه های مختلف تقسیم شده است و این
71
00:02:47,290 –> 00:02:49,570
نوع مفهوم نامیده می شود.
72
00:02:49,570 –> 00:02:52,090
یادگیری ماشین بدون نظارت بدون نظارت است
73
00:02:52,090 –> 00:02:55,840
زیرا من برچسب یا
74
00:02:55,840 –> 00:02:57,760
گروه را به الگوریتم ارائه
75
00:02:57,760 –> 00:03:00,459
نمیکنم، به این ترتیب بر آن نظارت نمیکنم، من
76
00:03:00,459 –> 00:03:02,650
فقط به این مجموعه داده Algar نظارت نشده تغذیه میکنم
77
00:03:02,650 –> 00:03:06,250
و بیرون میرود و آن
78
00:03:06,250 –> 00:03:09,430
را به مجموعهها تقسیم میکند. از گروههایی که
79
00:03:09,430 –> 00:03:11,950
میخواهیم انجام دهد، واقعاً ایده پشت
80
00:03:11,950 –> 00:03:14,530
آن این است که ما این مجموعه داده بدون برچسب را داریم که
81
00:03:14,530 –> 00:03:16,900
میخواهیم اساساً ساختاری
82
00:03:16,900 –> 00:03:18,910
در پشت آن پیدا کنیم یا شاید
83
00:03:18,910 –> 00:03:21,640
معتقدیم ساختاری در پشت آن وجود دارد و بنابراین از
84
00:03:21,640 –> 00:03:25,239
الگوریتم k-means استفاده میکنیم. به منظور ایجاد
85
00:03:25,239 –> 00:03:27,940
ساختار از آن، بنابراین چگونه این
86
00:03:27,940 –> 00:03:30,489
الگوریتم خاص به خوبی کار می کند، من می
87
00:03:30,489 –> 00:03:32,170
توانم به نوعی وارد مسائل ریاضی شوم،
88
00:03:32,170 –> 00:03:34,690
اما اجازه دهید آن را به مراحل تقسیم کنیم و
89
00:03:34,690 –> 00:03:36,459
سپس از آن مراحل، یک مثال تصویری را مشاهده خواهیم کرد،
90
00:03:36,459 –> 00:03:40,590
بنابراین برای k-means.
91
00:03:40,590 –> 00:03:42,880
دوباره فقط تکرار می کنم و این یک
92
00:03:42,880 –> 00:03:45,100
الگوریتم یادگیری ماشینی بدون نظارت است
93
00:03:45,100 –> 00:03:48,700
و هدف K میانگین تقسیم n
94
00:03:48,700 –> 00:03:50,980
نقطه داده است، بنابراین اساساً هر ردیف
95
00:03:50,980 –> 00:03:53,859
در مجموعه داده های شما به K پارتیشن می شود،
96
00:03:53,859 –> 00:03:58,090
جایی که K به صورت k آمده است – یعنی K شما باید
97
00:03:58,090 –> 00:04:00,549
آن را در آن بگویید. احساس شما باید
98
00:04:00,549 –> 00:04:02,859
به یک معنا بدانید که چه تعداد k که
99
00:04:02,859 –> 00:04:04,480
فکر میکنید اعداد بهینه هستند، اکنون خواهیم
100
00:04:04,480 –> 00:04:06,640
دید که راههایی وجود دارد که به ما در انتخاب K کمک میکند،
101
00:04:06,640 –> 00:04:09,310
اما واقعاً این
102
00:04:09,310 –> 00:04:11,650
راه مطمئن وجود ندارد که هر بار کار کند و
103
00:04:11,650 –> 00:04:14,350
این کار را انجام میدهد. عالی باش همیشه
104
00:04:14,350 –> 00:04:17,140
n نقطه داده را می گیریم و آن را به K پارتیشن تقسیم می کنیم
105
00:04:17,140 –> 00:04:20,019
که در آن مجموع
106
00:04:20,019 –> 00:04:23,169
فواصل به حداقل می رسد، این بخش کلیدی
107
00:04:23,169 –> 00:04:25,990
در مورد این الگوریتم است که در تلاش برای
108
00:04:25,990 –> 00:04:27,150
یافتن
109
00:04:27,150 –> 00:04:29,520
کل گروه است که مجموع
110
00:04:29,520 –> 00:04:31,650
فواصل از این چیزی است که ما به آن می گوییم.
111
00:04:31,650 –> 00:04:33,350
نقطه خاصی که مرکز اوی نامیده می شود در
112
00:04:33,350 –> 00:04:35,850
مقایسه با تمام نقاط داده دیگر
113
00:04:35,850 –> 00:04:38,669
و به این ترتیب به مراحل تقسیم می شود، ما اساساً به
114
00:04:38,669 –> 00:04:42,090
طور تصادفی این مرکزها را انتخاب می کنیم، منظورم این است
115
00:04:42,090 –> 00:04:43,320
که آنها می توانند هر جایی باشند که می توانند یک
116
00:04:43,320 –> 00:04:44,699
نقطه داده باشند و لازم نیست یک نقطه داده باشند،
117
00:04:44,699 –> 00:04:47,070
اما ما اساساً به طور تصادفی
118
00:04:47,070 –> 00:04:49,949
این مراکز خوشه را انتخاب کنید،
119
00:04:49,949 –> 00:04:53,460
فاصله هر نقطه را محاسبه می کنیم، بنابراین هر
120
00:04:53,460 –> 00:04:56,490
نقطه داده به یک خوشه و یک برچسب خوشه ای اختصاص می دهیم
121
00:04:56,490 –> 00:04:59,100
که در آن
122
00:04:59,100 –> 00:05:03,150
فاصله اقلیدسی کوچکترین است و خواهیم دید
123
00:05:03,150 –> 00:05:05,460
که از نظر فنی می توانید از
124
00:05:05,460 –> 00:05:07,740
اندازه گیری های دیگر فاصله استفاده
125
00:05:07,740 –> 00:05:09,210
کنید. برای حفظ اقلیدسی در این
126
00:05:09,210 –> 00:05:11,010
ویدئو، اما از نظر فنی راههای دیگری
127
00:05:11,010 –> 00:05:12,419
برای انجام آن وجود دارد، وقتی به
128
00:05:12,419 –> 00:05:15,330
موتورهای پیشنهادی رسیدیم، آن را خواهیم دید و
129
00:05:15,330 –> 00:05:18,150
بعد از اینکه آن را اختصاص دادیم، c را دوباره محاسبه میکنیم.
130
00:05:18,150 –> 00:05:20,970
انترویدها را با در نظر گرفتن میانگین تمام
131
00:05:20,970 –> 00:05:23,010
نقاط داده اختصاص داده شده به آن خوشه و
132
00:05:23,010 –> 00:05:26,160
ما اساساً فقط آن مرکز را تکان می دهیم
133
00:05:26,160 –> 00:05:28,650
، مرحله را تکرار می کنیم تا زمانی که یکی از این
134
00:05:28,650 –> 00:05:30,840
دو شرط زیر برآورده شود،
135
00:05:30,840 –> 00:05:34,349
مجموع فاصله به حداقل برسد یا
136
00:05:34,349 –> 00:05:36,690
حداکثر تعداد تکرارهای انجام شده باشد.
137
00:05:36,690 –> 00:05:38,310
رسیده است، بنابراین دو شرط وجود دارد که
138
00:05:38,310 –> 00:05:42,090
می توانیم این الگوریتم را کاملاً متوقف کنیم، بنابراین
139
00:05:42,090 –> 00:05:45,780
من این تصویر کوچک زیبا را دارم،
140
00:05:45,780 –> 00:05:48,419
پیوندی را در ویدیوی زیر قرار می دهم، اما
141
00:05:48,419 –> 00:05:50,010
فکر کردم این عالی بود، منظورم این است که این فقط
142
00:05:50,010 –> 00:05:51,930
چیزی را به خانه هدایت می کند که من می خواهم
143
00:05:51,930 –> 00:05:55,860
تازه کردن صفحه ای که در اینجا می بینید
144
00:05:55,860 –> 00:05:57,840
اساساً انجام می داد، این است که سانتروئیدها را اختصاص می دهد
145
00:05:57,840 –> 00:05:59,639
و در حال محاسبه است، بنابراین
146
00:05:59,639 –> 00:06:01,979
اساساً فاصله تا هر
147
00:06:01,979 –> 00:06:05,159
نقطه داد







![فیلم آموزشی: Web Scraping آمار NBA با پایتون: پروژه داده [بخش 1 از 3] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/JGQGd-oa0l4image2.jpg)