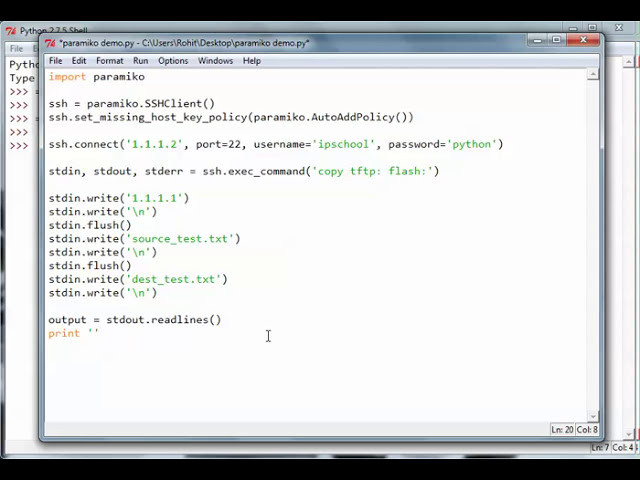
در این مطلب، ویدئو تجزیه و تحلیل داده های بزرگ با استفاده از Spark با پایتون | آموزش PySpark | Intellipaat با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:50:30
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,949 –> 00:00:03,689
با سلام از راه دور به امید
2
00:00:03,689 –> 00:00:05,160
اینکه روز فوق العاده ای داشته باشید
3
00:00:05,160 –> 00:00:07,170
موضوع جلسه امروز
4
00:00:07,170 –> 00:00:10,019
تجزیه و تحلیل داده های بزرگ با استفاده از Spock و Python است، اما
5
00:00:10,019 –> 00:00:11,700
قبل از شروع، حتما
6
00:00:11,700 –> 00:00:13,530
دکمه اشتراک را بزنید و روی نماد اعلان زنگ کلیک کنید
7
00:00:13,530 –> 00:00:15,389
تا این کار را نکنید.
8
00:00:15,389 –> 00:00:17,880
بهروزرسانیهای ما را از دست ندهید، بنابراین بیایید
9
00:00:17,880 –> 00:00:20,189
بدون هیچ مقدمهای شروع کنیم، بنابراین موضوع
10
00:00:20,189 –> 00:00:23,250
امروز تجزیه و تحلیل دادههای بزرگ است و
11
00:00:23,250 –> 00:00:24,449
ما در مورد جنبه بسیار کوچکی
12
00:00:24,449 –> 00:00:27,060
از تجزیه و تحلیل دادههای بزرگ بحث خواهیم کرد که
13
00:00:27,060 –> 00:00:29,670
پردازش دادههای بزرگ با استفاده از اسپارک و پایتون است.
14
00:00:29,670 –> 00:00:32,219
بدون هیچ مقدمه دیگری، اجازه دهید
15
00:00:32,219 –> 00:00:36,079
وارد دستور کار جلسه امروز
16
00:00:36,079 –> 00:00:38,340
شویم، بنابراین ما در مورد داشتن یک
17
00:00:38,340 –> 00:00:40,670
مقدمه مختصر برای تجزیه و تحلیل داده های بزرگ
18
00:00:40,670 –> 00:00:43,980
بحث می کنیم، سپس در مورد اینکه
19
00:00:43,980 –> 00:00:45,899
اسپارک آپاچی چیست و سپس در
20
00:00:45,899 –> 00:00:48,899
مورد نحوه انجام آن بحث خواهیم کرد.
21
00:00:48,899 –> 00:00:51,149
رویههای تجزیه و تحلیل دادههای بزرگ را با استفاده از bi spot
22
00:00:51,149 –> 00:00:53,969
که پایتون و اسپاک است پیادهسازی کنید و ما میخواهیم
23
00:00:53,969 –> 00:00:55,680
در مورد میانگین حقوق یک
24
00:00:55,680 –> 00:00:57,989
توسعهدهنده اسپارک اسکالا و یک توسعهدهنده کلان داده بحث کنیم
25
00:00:57,989 –> 00:01:00,539
و سپس من
26
00:01:00,539 –> 00:01:01,949
برای شما سورپرایز دارم. در پایان
27
00:01:01,949 –> 00:01:03,780
ویدیو در رابطه با دورههایی که ما
28
00:01:03,780 –> 00:01:08,310
یک مسیر دندانپزشکی داریم، بنابراین قبل از اینکه
29
00:01:08,310 –> 00:01:08,869
دادههای بزرگ را شروع
30
00:01:08,869 –> 00:01:12,240
کنیم، باید
31
00:01:12,240 –> 00:01:14,729
قبل از ورود به بخش تجزیه و تحلیل
32
00:01:14,729 –> 00:01:16,740
آن، درک کنیم که دادههای بزرگ چیست، بنابراین اولین موضوع برای امروز
33
00:01:16,740 –> 00:01:18,390
اولین دستور کار است. برای امروز
34
00:01:18,390 –> 00:01:20,220
اساساً برای شما توضیح میدهیم که دادههای بزرگ چیست
35
00:01:20,220 –> 00:01:23,159
، مقدمهای برای
36
00:01:23,159 –> 00:01:27,140
تجزیه و تحلیل دادههای بزرگ، بنابراین Big Data
37
00:01:27,140 –> 00:01:29,549
چیست، اساساً چه احساسی
38
00:01:29,549 –> 00:01:31,170
دارید، وقتی
39
00:01:31,170 –> 00:01:33,060
کلمه ضخیم را میشنوید به معنای بزرگ به معنای
40
00:01:33,060 –> 00:01:35,729
بزرگ است، چه احساسی دارید. بنابراین اساساً Big Data
41
00:01:35,729 –> 00:01:38,189
دقیقاً یکسان است، به معنای واقعی کلمه
42
00:01:38,189 –> 00:01:41,970
مقدار زیادی داده است، بنابراین اساساً هر زمان که
43
00:01:41,970 –> 00:01:45,030
درآمد دادهای از نظر محاسباتی داشته
44
00:01:45,030 –> 00:01:47,220
باشیم، میتوانیم آنها را برای تولید الگوها تجزیه و تحلیل کنیم
45
00:01:47,220 –> 00:01:50,220
و به این ترتیب میتوانیم الگوهایی تولید کنیم، میتوانیم
46
00:01:50,220 –> 00:01:54,060
درک کنیم که چگونه دادهها در شرایطی که
47
00:01:54,060 –> 00:01:57,030
متغیرهای خاص هستند، پیشرفت میکنند. به گونهای تنظیم شده
48
00:01:57,030 –> 00:01:59,430
است که مثالهایی از معنای این دادههای بزرگ را
49
00:01:59,430 –> 00:02:01,710
بفهمیم، میتوانیم به نمونههای خاصی نگاه
50
00:02:01,710 –> 00:02:03,869
کنیم، ابتدا دادههای جعبه سیاه داریم
51
00:02:03,869 –> 00:02:05,850
که به این معنی است که دادههای پرواز اساساً
52
00:02:05,850 –> 00:02:08,139
دادههای ضبطکننده پرواز wh هر زمانی
53
00:02:08,139 –> 00:02:10,660
که پروازی وجود داشته باشد جعبه سیاهی در
54
00:02:10,660 –> 00:02:12,430
آن وجود دارد که صدای
55
00:02:12,430 –> 00:02:14,320
خدمه پرواز و ضبط میکروفون
56
00:02:14,320 –> 00:02:16,240
و گوشی را ضبط می کند و اساساً
57
00:02:16,240 –> 00:02:17,440
عملکرد یا
58
00:02:17,440 –> 00:02:19,930
آمار عملکرد هواپیما همه
59
00:02:19,930 –> 00:02:21,790
آن ضبط شده و در داخل پرواز ذخیره می شود.
60
00:02:21,790 –> 00:02:24,520
بنابراین در صورت بروز هر گونه حادثه یا در
61
00:02:24,520 –> 00:02:25,960
صورت انجام هر گونه بررسی
62
00:02:25,960 –> 00:02:28,150
می توان داده های جعبه سیاه باتای سیاه را مورد
63
00:02:28,150 –> 00:02:31,840
بررسی قرار داد و از آنجایی که تعداد
64
00:02:31,840 –> 00:02:33,880
زیادی پرواز در سراسر جهان در یک
65
00:02:33,880 –> 00:02:36,880
روز انجام می شود، ما حجم زیادی از
66
00:02:36,880 –> 00:02:39,370
داده های جعبه سیاه را در دوره زمانی جمع آوری کردیم. یک روز
67
00:02:39,370 –> 00:02:40,930
به همین دلیل است که داده های جعبه سیاه را می توان
68
00:02:40,930 –> 00:02:43,480
به عنوان داده های بزرگ در نظر گرفت، سپس
69
00:02:43,480 –> 00:02:45,820
مثال بسیار واضح دیگری که داریم
70
00:02:45,820 –> 00:02:48,130
داده های رسانه های اجتماعی است که همه ما از رسانه های اجتماعی استفاده می کنیم
71
00:02:48,130 –> 00:02:49,990
و نوعی دیگر از
72
00:02:49,990 –> 00:02:52,570
سرویس های پیامک استفاده می کنیم که از فیس بوک استفاده می کنیم شما از YouTube استفاده می
73
00:02:52,570 –> 00:02:55,030
کنید. ما از همه اینها استفاده می کنیم و
74
00:02:55,030 –> 00:02:56,740
همه ما حساب داریم و همه ما
75
00:02:56,740 –> 00:03:00,240
داده هایی را تولید می کنیم که الگوی آب
76
00:03:00,240 –> 00:03:03,720
استفاده از رسانه های اجتماعی اساساً این است، بنابراین
77
00:03:03,720 –> 00:03:06,280
گول نخورید هر وب سایت رسانه های اجتماعی
78
00:03:06,280 –> 00:03:09,220
اساساً هر asp را ذخیره می کند. غیر
79
00:03:09,220 –> 00:03:11,140
از دادههایی که در این وبسایتها تولید میکنیم
80
00:03:11,140 –> 00:03:14,980
و برای پردازش و ذخیره این
81
00:03:14,980 –> 00:03:18,130
حجم عظیم دادهها از تجزیه و تحلیل دادههای بزرگ استفاده میکنیم
82
00:03:18,130 –> 00:03:20,769
و این نوع دادهها را میتوان
83
00:03:20,769 –> 00:03:24,220
به عنوان دادههای بزرگ نامید، نمونههای مشابه دیگر
84
00:03:24,220 –> 00:03:26,920
میتواند دادههای شبکه برق یا
85
00:03:26,920 –> 00:03:28,959
تبادل دادههای انتقال باشد. دادههایی که
86
00:03:28,959 –> 00:03:31,720
اسم آنها را میگذارید، همه آنها وجود دارند، بنابراین
87
00:03:31,720 –> 00:03:37,570
برای اینکه هر داده یا مجموعه دادهای به
88
00:03:37,570 –> 00:03:40,630
دادههای بزرگ تبدیل شود، باید به
89
00:03:40,630 –> 00:03:43,180
پنج معیار اساسی که به
90
00:03:43,180 –> 00:03:46,450
آنها پنج V از دادههای بزرگ گفته میشود، برویم، زیرا
91
00:03:46,450 –> 00:03:49,330
هر مجموعه داده بیش از اندازه یک
92
00:03:49,330 –> 00:03:51,370
گیگابایت را نمی توان به سادگی به عنوان داده های بزرگ نامید،
93
00:03:51,370 –> 00:03:54,519
بنابراین پنج
94
00:03:54,519 –> 00:03:57,489
معیار اساسی برای هر مجموعه داده وجود دارد
95
00:03:57,489 –> 00:04:01,300
که داده بزرگ در نظر گرفته شود، بنابراین اولین
96
00:04:01,300 –> 00:04:04,390
معیار سرعت است، بنابراین سرعت به معنای سرعت
97
00:04:04,390 –> 00:04:06,100
است، بدیهی است که اگر فیزیک مطالعه کرده باشید، می
98
00:04:06,100 –> 00:04:08,019
دانید سرعت یعنی چه. این بدان معناست که سرعت
99
00:04:08,019 –> 00:04:11,260
سرعت اساساً به این معنی است که
100
00:04:11,260 –> 00:04:13,510
جریان داده با چه سرعتی سرعت تولید داده می
101
00:04:13,510 –> 00:04:16,000
شود اگر معیاری را برآورده کند
102
00:04:16,000 –> 00:04:18,100
که داده ها واقعاً سریع تولید شده اند،
103
00:04:18,100 –> 00:04:20,260
می توان آن را به عنوان b نامید.
104
00:04:20,260 –> 00:04:22,050
دادههای ig برای مثال ما
105
00:04:22,050 –> 00:04:24,990
جستجوهای گوگل داریم که در روز انجام میشوند، بنابراین
106
00:04:24,990 –> 00:04:27,810
در این مثال ما روزانه 3.5 میلیارد
107
00:04:27,810 –> 00:04:29,820
جستجو انجام میدهیم که میتوانید
108
00:04:29,820 –> 00:04:31,530
میزان دادهای را که تولید میکند تصور کنید،
109
00:04:31,530 –> 00:04:33,900
به این معنی که در
110
00:04:33,900 –> 00:04:36,030
روز مقدار داده واقعاً زیاد است.
111
00:04:36,030 –> 00:04:37,680
که در حال تولید است و
112
00:04:37,680 –> 00:04:39,870
مقوله سرعت را برآورده میکند، به همین دلیل است که
113
00:04:39,870 –> 00:04:41,910
میتوان آن را به عنوان دادههای بزرگ انجام داد و به
114
00:04:41,910 –> 00:04:45,180
V بعدی میرویم، حجم حجم
115
00:04:45,180 –> 00:04:48,290
در اصل از نظر رایانهها اندازه متوسط است و اس
116
00:04:48,290 –> 00:04:50,490
ساً در اینجا مثالی برای آن
117
00:04:50,490 –> 00:04:53,610
.2 اگزابایت داریم که به
118
00:04:53,610 –> 00:04:56,160
119
00:04:56,160 –> 00:04:58,650
این معنی است که ماهانه 6.2 میلیارد گیگابایت داده در ترافیک جهانی موبایل جهانی تولید می شود، به
120
00:04:58,650 –> 00:05:03,690
طوری که حجم داده ها
121
00:05:03,690 –> 00:05:06,180
واقعاً زیاد است و پردازش آن
122
00:05:06,180 –> 00:05:09,330
به ابزارهای غیر استاندارد نیاز دارد و به
123
00:05:09,330 –> 00:05:11,370
همین دلیل است که این نوع داده ها
124
00:05:11,370 –> 00:05:13,770
بزرگ در نظر گرفته می شوند. بنابراین حجم داده ها باید
125
00:05:13,770 –> 00:05:18,570
زیاد باشد – بعد ما تنوع داریم، بنابراین
126
00:05:18,570 –> 00:05:20,280
اساساً سه نوع داده وجود دارد که در
127
00:05:20,280 –> 00:05:21,960
حال حاضر در دنیای امروزی تولید می شود
128
00:05:21,960 –> 00:05:23,790
که به صورت نیمه ساختار یافته
129
00:05:23,790 –> 00:05:26,160
و در s ساختار ساختار یافته اساساً
130
00:05:26,160 –> 00:05:28,260
به این معنی است که همه تاپل ها همه
131
00:05:28,260 –> 00:05:30,270
دسته ها همه متغیرهای داده
132
00:05:30,270 –> 00:05:32,100
به طور کامل تعریف شده اند داده ها در
133
00:05:32,100 –> 00:05:34,710
قالب مرتب هستند و اساساً می توان
134
00:05:34,710 –> 00:05:36,360
آنها را
135
00:05:36,360 –> 00:05:38,510
136
00:05:38,510 –> 00:05:41,910
پردازش کرد.
137
00:05:41,910 –> 00:05:44,130
داده های بدون ساختار ابتدا به تبدیل آن
138
00:05:44,130 –> 00:05:45,660
به ساختار یافته تبدیل می شوند و سپس ما
139
00:05:45,660 –> 00:05:47,610
پردازش می کنیم و نیمه ساختاریافته جایی
140
00:05:47,610 –> 00:05:49,620
در وسط است که به نوعی
141
00:05:49,620 –> 00:05:51,000
ساختارمند است و به نوعی ساختار نیافته است که
142
00:05:51,000 –> 00:05:53,070
برخی از متغیرها ممکن است ساختار یافته باشند برخی
143
00:05:53,070 –> 00:05:55,760
ممکن است اینطور نباشند، بنابراین باید تنوع داشته باشد
144
00:05:55,760 –> 00:05:58,919
اساساً این بدان معناست که بعداً
145
00:05:58,919 –> 00:06:02,460
به سمت تخلخل میرویم، بنابراین دادهها گاهی اوقات
146
00:06:02,460 –> 00:06:04,620
میتوانند متناقض یا نامرتب باشند، اساساً
147
00:06:04,620 –> 00:06:06,900
به این معنی است که دادههای بزرگ
148
00:06:06,900 –> 00:06:08,490
همیشه بینقص نیستند، ممکن است
149
00:06:08,490 –> 00:06:11,940
در آن مجموعه دادهها و در
150
00:06:11,940 –> 00:06:13,950
شرایط دنیای واقعی، وقتی در مورد واقعی صحبت میکنیم، ناسازگاریهای خاصی وجود داشته باشد.
151
00:06:13,950 –> 00:06:15,930
دادههایی که در دنیا تولید میشوند انجام
152
00:06:15,930 –> 00:06:16,590
153
00:06:16,590 –> 00:06:19,500
میدهند، واضح است که صحت در آن وجود دارد
154
00:06:19,500 –> 00:06:21,270
، ساختار مناسبی برای آن وجود ندارد.
155
00:06:21,270 –> 00:06:22,800
فرمت کردن oper به آن پس بدیهی است
156
00:06:22,800 –> 00:06:24,720
که موارد زیادی وجود دارد که شامل
157
00:06:24,720 –> 00:06:26,640
ناهماهنگی در داده های دنیای واقعی است
158
00:06:26,640 –> 00:06:28,350
که در حال حاضر تولید شده است
159
00:06:28,350 –> 00:06:31,320
و به سرعت و
160
00:06:31,320 –> 00:06:34,889
سرعت نیز یک عامل کلیدی در
161
00:06:34,889 –> 00:06:38,789
نامیده شدن داده ها به داده های بزرگ است، بنابراین ما ارزش آن را داریم
162
00:06:38,789 –> 00:06:40,169
ارزش، ضروری ترین
163
00:06:40,169 –> 00:06:42,900
V در پنج V از داده های بزرگ است
164
00:06:42,900 –> 00:06:46,380
ارزش به این معناست که آن داده ها چقدر و چقدر
165
00:06:46,380 –> 00:06:49,020
ارزش دارند که چگونه اساساً می
166
00:06:49,020 –> 00:06:50,970
توانیم حجم زیادی از داده ها را داشته باشیم، اما اگر بی فایده است اگر
167
00:06:50,970 –> 00:06:52,830
به چیزی ترجمه نشود،
168
00:06:52,830 –> 00:06:55,470
همه آن داده های عظیم مقادیر داده دیگر
169
00:06:55,470 –> 00:06:57,539
به هیچ مدل خوبی نمی
170
00:06:57,539 –> 00:06:59,970
رسد. روش تحلیل محاسباتی
171
00:06:59,970 –> 00:07:01,770
خوب دیگر معنی ندارد،
172
00:07:01,770 –> 00:07:03,930
بنابراین اساساً می گویند به عنوان مثال ما
173
00:07:03,930 –> 00:07:08,099
در دانشکده ها اعداد رولی داریم، بنابراین اگر
174
00:07:08,099 –> 00:07:09,990
اعداد رول
175
00:07:09,990 –> 00:07:12,360
کلیدهای اصلی هر جدول را در نظر بگیریم، رول
176
00:07:12,360 –> 00:07:14,159
عدد با هیچ مدلی برابری نمیکند
177
00:07:14,159 –> 00:07:16,530
، نمیتوان پیشبینی کرد که
178
00:07:16,530 –> 00:07:19,050
خوب نیست، زیرا برای محافظت از چیزی خوب نیست، بنابراین
179
00:07:19,050 –> 00:07:21,060
آن دادهها را باید دور بیندازیم
180
00:07:21,060 –> 00:07:23,280
تا دادهها اساساً مقادیر کمتری داشته باشند.
181
00:07:23,280 –> 00:07:25,470
چیز دیگری مانند علامتها به طوری
182
00:07:25,470 –> 00:07:28,080
که اساساً ارزش
183
00:07:28,080 –> 00:07:32,159
آن در پنج درجه مجموعه داده ترجمه میشود، بنابراین با
184
00:07:32,159 –> 00:07:34,710
رفتن به مرحله بعدی، به
185
00:07:34,710 –> 00:07:36,479
تعریف تجزیه و تحلیل دادههای بزرگ
186
00:07:36,479 –> 00:07:38,430
میرویم و با این کار میدانیم که اکنون که میدانیم دادههای بزرگ
187
00:07:38,430 –> 00:07:40,320
چیست، میفهمیم که چه چیزی بزرگ است. تجزیه و تحلیل داده
188
00:07:40,320 –> 00:07:42,719
ها حوزه پیچیده مطالعه
189
00:07:42,719 –> 00:07:44,669
بررسی این مجموعه داده های عظیم و متمایز است
190
00:07:44,669 –> 00:07:47,039
که من در حال حاضر در مورد آن بحث کردم یا
191
00:07:47,039 –> 00:07:49,289
داده های بزرگ را تجزیه و تحلیل داده های بزرگ می نامند، بنابراین چگونه
192
00:07:49,289 –> 00:07:51,210
آن را پردازش کنیم کل مطالعه
193
00:07:51,210 –> 00:07:53,070
کل رشته تحصیلی مرتبط با آن
194
00:07:53,070 –> 00:07:55,889
داده های بزرگ نامیده می شود. تجزیه و تحلیل، پس چرا ما
195
00:07:55,889 –> 00:07:59,030
این تجزیه و تحلیل را انجام می دهیم، این برای
196
00:07:59,030 –> 00:08:02,550
کشف هر نوع الگوی
197
00:08:02,550 –> 00:08:04,530
تمایلات مشتری در روندهای بازار است، اساساً در
198
00:08:04,530 –> 00:08:06,810
تجارت، ما وب سایت های
199
00:08:06,810 –> 00:08:08,969
تجارت الکترونیک زیادی داریم تا آنها
200
00:08:08,969 –> 00:08:11,340
بفهمند چه چیزی را به شما توصیه کنند که چه چیزی را
201
00:08:11,340 –> 00:08:13,949
به شما پیشنهاد دهید و چگونه رفتار می کنید.
202
00:08:13,949 –> 00:08:16,199
آن وبسایت بسیار
203
00:08:16,199 –> 00:08:19,050
ضروری است که دادههایی را
204
00:08:19,050 –> 00:08:22,020
که در طول مدت زمان خود در آن
205
00:08:22,020 –> 00:08:25,650
وبسایت تولید میکنید پردازش کنند، بنابراین اساساً هنری که
206
00:08:25,650 –> 00:08:28,349
مطالعه مربوط به کشف آن است استفاده از این الگو
207
00:08:28,349 –> 00:08:31,289
از دادههای مبهم سرت اساساً
208
00:08:31,289 –> 00:08:33,750
تجزیه و تحلیل دادههای بزرگ است و کل
209
00:08:33,750 –> 00:08:36,208
رشته مورد مطالعه به این موضوع مربوط میشود که در
210
00:08:36,208 –> 00:08:38,578
ادامه به اهمیت
211
00:08:38,578 –> 00:08:41,250
تجزیه و تحلیل دادههای بزرگ خواهیم پرداخت، بنابراین ما در
212
00:08:41,250 –> 00:08:42,719
مورد اهمیت
213
00:08:42,719 –> 00:08:44,730
تجزیه و تحلیل دادههای بزرگ صحبت خواهیم کرد. از دیدگاه تجاری
214
00:08:44,730 –> 00:08:46,180
اساساً
215
00:08:46,180 –> 00:08:47,529
مشاغل می توانند تجارت الکترونیکی
216
00:08:47,529 –> 00:08:50,020
وب سایت های رسانه های اجتماعی باشند، بنابراین وب سایت های رسانه های
217
00:08:50,020 –> 00:08:52,750
اجتماعی نیز از تبلیغات استفاده می کنند و
218
00:08:52,750 –> 00:08:55,900
از تبلیغات هدفمند برای شما استفاده می کنند و هنگامی
219
00:08:55,900 –> 00:08:57,790
که روی آن تبلیغات کلیک می کنید درآمد کسب می کنند
220
00:08:57,790 –> 00:08:59,680
بنابراین اساساً برای آنها بسیار مهم است
221
00:08:59,680 –> 00:09:01,240
که بفهمند شما چه چیزی دارید. در آن
222
00:09:01,240 –> 00:09:04,750
وب سایت برای هدف قرار دادن آن تبلیغات به سمت شما انجام دهید،
223
00:09:04,750 –> 00:09:06,520
بنابراین ما در اینجا در پنج نکته درباره
224
00:09:06,520 –> 00:09:08,680
فرصت هایی برای کسب درآمد بیشتر بحث خواهیم کرد،
225
00:09:08,680 –> 00:09:10,210
بدیهی است که همه می خواهند پول بیشتری به دست
226
00:09:10,210 –> 00:09:12,279
آورند، بنابراین باید بدانند که
227
00:09:12,279 –> 00:09:14,080
پایگاه مصرف کننده آنها چه می خواهد که پایگاه مصرف کننده آنها چگونه
228
00:09:14,080 –> 00:09:17,500
رفتار می کند. چرا
229
00:09:17,500 –> 00:09:18,580
تجزیه و تحلیل داده های بزرگ به آنها
230
00:09:18,580 –> 00:09:20,440
فرصتی برای رضایت مشتری می
231
00:09:20,440 –> 00:09:23,050
دهد اگر یک وب سایت یا
232
00:09:23,050 –> 00:09:24,910
خدماتی که به سمت رضایت مشتری است
233
00:09:24,910 –> 00:09:26,500
. بدیهی است که با
234
00:09:26,500 –> 00:09:29,020
تجزیه و تحلیل دادههای بزرگ میفهمد مشتری چه میخواهد، بنابراین
235
00:09:29,020 –> 00:09:31,960
از نیاز مشتریان خود جلوگیری میکند و از آنجا
236
00:09:31,960 –> 00:09:34,240
که خدمات فوقالعادهای به
237
00:09:34,240 –> 00:09:36,279
مشتری ارائه میکند، به همین دلیل است که مزایای
238
00:09:36,279 –> 00:09:38,279
معیارهای رضایت مشتری را
239
00:09:38,279 –> 00:09:40,900
نسبت به رقبا برآورده میکند، بدیهی است که اگر
240
00:09:40,900 –> 00:09:44,080
یک وبسایت رقابتی
241
00:09:44,080 –> 00:09:45,670
کسبوکار رقابتی نباشد. با استفاده از تجزیه و تحلیل داده های بزرگ،
242
00:09:45,670 –> 00:09:48,450
آنها نسبت به
243
00:09:48,450 –> 00:09:50,620
سازمانی که از تجزیه و تحلیل داده های بزرگ استفاده می کند برتری
244
00:09:50,620 –> 00:09:55,150
ندارند روش های سنتی نمی توانند کاری را
245
00:09:55,150 –> 00:09:57,040
که تجزیه و تحلیل داده انجام می دهد انجام دهند، بنابراین
246
00:09:57,040 –> 00:09:58,750
اساساً به آنها برتری نسبت به
247
00:09:58,750 –> 00:10:01,420
رقبا می دهد بستگی به این دارد که
248
00:10:01,420 –> 00:10:03,220
الگوریتم آنها چقدر خوب است. پردازش مجدد
249
00:10:03,220 –> 00:10:05,380
آن دادههای بزرگ و اینکه چه مقدار ارزشی برای این دادهها
250
00:10:05,380 –> 00:10:08,170
دارد، پس ما
251
00:10:08,170 –> 00:10:09,730
کارایی
252
00:10:09,730 –> 00:10:13,209
بازاریابی را بهبود میبخشیم، بنابراین بدیهی است که بازاریابی
253
00:10:13,209 –> 00:10:15,550
مستلزم هزینههای زیادی است و اگر
254
00:10:15,550 –> 00:10:17,770
بازاریابی را به سمت مجموعه خاصی
255
00:10:17,770 –> 00:10:19,800
از مشتریان هدف قرار دهیم بهجای
256
00:10:19,800 –> 00:10:22,209
قرار دادن بیپرده یک تبلیغ. در همه
257
00:10:22,209 –> 00:10:24,130
جا به وضوح باعث صرفه جویی در
258
00:10:24,130 –> 00:10:26,230
هزینه و افزایش کارایی می شود
259
00:10:26,230 –> 00:10:28,660
بازاریابی این چیزی است که ما میتوانیم
260
00:10:28,660 –> 00:10:30,150
با استفاده از تجزیه و تحلیل دادههای بزرگ تحلیل کنیم که
261
00:10:30,150 –> 00:10:32,020
هزینههای عملیاتی را کاهش میدهد و
262
00:10:32,020 –> 00:10:34,839
توان عملیاتی را افزایش میدهد، بنابراین وقتی از
263
00:10:34,839 –> 00:10:36,490
روشهای محاسباتی برای انجام کارها
264
00:10:36,490 –> 00:10:38,860
به جای روشهای دستی برای انجام آن استفاده میکنیم،
265
00:10:38,860 –> 00:10:41,529
بدیهی است که باید کمتر در مورد
266
00:10:41,529 –> 00:10:43,360
آن کار کنیم، باید تحقیقات کمتری در رایانه انجام دهیم.
267
00:10:43,360 –> 00:10:46,060
همه چیز را به ما می گوید، بنابراین
268
00:10:46,060 –> 00:10:48,279
هزینه های عملیاتی بدیهی است کاهش می یابد، زیرا ما
269
00:10:48,279 –> 00:10:50,380
اطلاعات بیشتری از تجزیه و تحلیل داده های بزرگ داریم،
270
00:10:50,380 –> 00:10:53,070
بنابراین اینها نوعی از
271
00:10:53,070 –> 00:10:56,860
مزایا و اهمیت
272
00:10:56,860 –> 00:10:57,670
تجزیه و تحلیل داده های بزرگ هستند که
273
00:10:57,670 –> 00:11:01,180
اکنون به سراغ بعدی می رویم که چگونه
274
00:11:01,180 –> 00:11:04,240
تجزیه و تحلیل داده های بزرگ در دنیای واقعی چنین کار می
275
00:11:04,240 –> 00:11:07,000
کند. دیدگاه فقط
276
00:11:07,000 –> 00:11:10,990
دو جنبه برای هر نوع پردازش
277
00:11:10,990 –> 00:11:13,390
هر نوع فعالیت محاسباتی
278
00:11:13,390 –> 00:11:15,070
در جهان وجود دارد و رشته علوم کامپیوتر
279
00:11:15,070 –> 00:11:18,370
اولین وجه ذخیره سازی
280
00:11:18,370 –> 00:11:20,170
است و روی دیگر
281
00:11:20,170 –> 00:11:23,110
پردازش و وجه دیگر پردازش این دو وجه تنها
282
00:11:23,110 –> 00:11:25,090
در دپارتمان علوم کامپیوتر هستند.
283
00:11:25,090 –> 00:11:27,820
ما باید پول خرج کنیم، باید
284
00:11:27,820 –> 00:11:30,480
منابع سخت افزاری خوبی داشته باشیم تا
285
00:11:30,480 –> 00:11:34,780
این جنبه ها را کامل کنیم درست است، پس
286
00:11:34,780 –> 00:11:37,840
این چه معنایی دارد، بنابراین اساساً هنگامی
287
00:11:37,840 –> 00:11:40,150
که داده ها آماده هستند و به طور بهینه در دسترس هستند،
288
00:11:40,150 –> 00:11:43,120
زمانی که ما تجزیه و تحلیل داده های بزرگ را روی داده های بزرگ انجام می
289
00:11:43,120 –> 00:11:45,160
دهیم و ما آن را
290
00:11:45,160 –> 00:11:46,930
به شکلی قرار داده ایم که می توانیم آن را
291
00:11:46,930 –> 00:11:48,910
به صورت ساختاریافته یا یک فرم بخوانیم. به شکل نیمه ساختاریافته
292
00:11:48,910 –> 00:11:50,620
میتوانیم فعالیتهای زیر
293
00:11:50,620 –> 00:11:53,200
را با آن انجام دهیم، یعنی جایی که
294
00:11:53,200 –> 00:11:56,170
بخشهای تحلیلی وارد میشوند، بنابراین
295
00:11:56,170 –> 00:11:57,940
ابتدا دادهکاوی دادهکاوی است که
296
00:11:57,940 –> 00:12:00,520
اساساً به معنی دادهکاوی است، گرفتن اطلاعات زیادی
297
00:12:00,520 –> 00:12:03,100
که ممکن است مبهم باشد و
298
00:12:03,100 –> 00:12:04,720
تبدیل آن به چیزی معنادار که
299
00:12:04,720 –> 00:12:07,600
اساسا استخراج میکند. دادههای بدون نویز
300
00:12:07,600 –> 00:12:10,600
یعنی دادهکاوی
301
00:12:10,600 –> 00:12:12,370
تجزیه و تحلیل پیشبینیکننده بعدی، بدیهی است که وقتی
302
00:12:12,370 –> 00:12:14,890
آن دادهها را استخراج میکنیم، میتوانیم آنها را تجزیه و تحلیل
303
00:12:14,890 –> 00:12:16,600
انجام دهیم، میتوانیم انجام دهیم، میتوانیم
304
00:12:16,600 –> 00:12:20,200
نمودارها و نمودارها ایجاد کنیم و پیشبینی کنیم که روند دادهها در کجا
305
00:12:20,200 –> 00:12:23,410
ممکن است وارد شوند، یعنی این
306
00:12:23,410 –> 00:12:24,880
با نکته ای که قبلاً در مورد
307
00:12:24,880 –> 00:12:26,830
آن بحث کردم، درک روندهای پنهان
308
00:12:26,830 –> 00:12:29,410
در داده ها است که با
309
00:12:29,410 –> 00:12:31,870
تجزیه و تحلیل پیشگویانه مرتبط است،
310
00:12:31,870 –> 00:12:34,480
پس از آن حوزه بورس بورس بسیار مهم است.
311
00:12:34,480 –> 00:12:37,510
312
00:12:37,510 –> 00:12:40,390
313
00:12:40,390 –> 00:12:42,130
314
00:12:42,130 –> 00:12:44,380
اگر
315
00:12:44,380 –> 00:12:45,730
شما یادگیری ماشینی را مطالعه کرده باشید
316
00:12:45,730 –> 00:12:47,710
، متوجه خواهید شد که هر چه مجموعه
317
00:12:47,710 –> 00:12:49,690
آموزشی بزرگتر باشد، مجموعه آموزشی بزرگتر، بهتر است، درک اینکه چگونه ممکن است فروش پیش برود وقتی که متغیرهای خاصی را تغییر میدهیم.
318
00:12:49,690 –> 00:12:51,730
تجزیه و تحلیلی که ما می توانیم با آن ارائه دهیم،
319
00:12:51,730 –> 00:12:54,960
سپس یادگیری ماشینی را داریم که به وضوح
320
00:12:54,960 –> 00:12:56,950
در بخش تجزیه و تحلیل پیش بینی کننده چیزها گسترش می یابد،
321
00:12:56,950 –> 00:12:59,710
ما
322
00:12:59,710 –> 00:13:01,690
جنبه بزرگتری برای تجزیه و تحلیل داده های بزرگ داریم که
323
00:13:01,690 –> 00:13:04,270
یادگیری ماشینی دوباره امتیاز
324
00:13:04,270 –> 00:13:06,070
به نقطه ای مربوط می شود که اگر مجموعه داده های آموزشی
325
00:13:06,070 –> 00:13:08,620
در این مورد بزرگ باشد. در مورد
326
00:13:08,620 –> 00:13:11,460
تجزیه و تحلیل دادههای بزرگ، بسیار بزرگ است، پس
327
00:13:11,460 –> 00:13:13,200
الگوریتمهای
328
00:13:13,200 –> 00:13:15,270
یادگیری ماشینی، مدلهای یادگیری ماشینی که
329
00:13:15,270 –> 00:13:17,490
از آن الگوریتمها ایجاد میکنیم،
330
00:13:17,490 –> 00:13:21,540
با افزایش اندازه دادهها دقیقتر و دقیقتر میشوند
331
00:13:21,540 –> 00:13:24,420
و سپس با گسترش
332
00:13:24,420 –> 00:13:26,250
یادگیری ماشینی، یادگیری عمیق داریم،
333
00:13:26,250 –> 00:13:27,930
بنابراین یادگیری ماشینی اساساً
334
00:13:27,930 –> 00:13:29,700
مدلهای ساده و یادگیری عمیق در
335
00:13:29,700 –> 00:13:32,880
شبکههای نودل پیچیده است و
336
00:13:32,880 –> 00:13:33,990
اگر میدانید که آیا با استفاده از یادگیری ماشینی
337
00:13:33,990 –> 00:13:35,130
متوجه خواهید شد
338
00:13:35,130 –> 00:13:37,550
که ایجاد
339
00:13:37,550 –> 00:13:39,780
مدلهای پیچیدهتر با شبکه با
340
00:13:39,780 –> 00:13:42,480
تعداد محدودیتها و متغیرهای بالاتر یعنی چه یادگیری عمیق.
341
00:13:42,480 –> 00:13:44,880
342
00:13:44,880 –> 00:13:47,670
343
00:13:47,670 –> 00:13:50,790
344
00:13:50,790 –> 00:13:53,730
ارزش این دادهها با مدلهای بهتر هم مطابقت دارد،
345
00:13:53,730 –> 00:13:56,670
بنابراین به
346
00:13:56,670 –> 00:14:00,090
سراغ چیز بعدی بروید
347
00:14:00,090 –> 00:14:02,400
که ما ابزارهای کلان داده را داریم که اگر
348
00:14:02,400 –> 00:14:05,880
دورههای کلان دادههای بزرگ را انجام دادهاید یا اگر
349
00:14:05,880 –> 00:14:07,200
به دنبال آموزشهایی بودهاید
350
00:14:07,200 –> 00:14:08,760
، در اختیار داریم. همه این ابزارها را بشناسید یا
351
00:14:08,760 –> 00:14:10,170
شاید در مورد آنها شنیده باشید
352
00:14:10,170 –> 00:14:12,360
اولین مورد این است که do yarn بدیهی است که
353
00:14:12,360 –> 00:14:14,580
مدیر منابع Hadoop Hadoop همه
354
00:14:14,580 –> 00:14:16,190
نرم افزاری است که ما برای کلان داده ها استفاده می کنیم،
355
00:14:16,190 –> 00:14:19,020
بنابراین نخ منابعی را مدیریت می کند
356
00:14:19,020 –> 00:14:20,820
که ما مشاغل را تخصیص می دهیم و
357
00:14:20,820 –> 00:14:22,620
مانند MapReduce که داریم.
358
00:14:22,620 –> 00:14:26,040
اصلی ترین چیزی است که Hadoop
359
00:14:26,040 –> 00:14:29,460
داده های نقشه ها را دارد و سپس آن را کاهش می
360
00:14:29,460 –> 00:14:33,600
دهد داده های نقشه را به قسمت های خاصی کاهش می دهد و سپس
361
00:14:33,600 –> 00:14:35,460
به caboose ارسال می شود و کاهش
362
00:14:35,460 –> 00:14:37,830
دهنده داده ها را جمع می کند. t مدلی
363
00:14:37,830 –> 00:14:40,950
است که اساساً از تمام دادههای بزرگ پیروی میکند
364
00:14:40,950 –> 00:14:44,250
امروز به شکلهای خوشهای پردازش میشود
365
00:14:44,250 –> 00:14:47,250
، ما تعداد زیادی گره داریم
366
00:14:47,250 –> 00:14:50,000
که در سختافزار سطح کالا پخش شدهاند
367
00:14:50,000 –> 00:14:52,940
که تهیه آن آسانتر است، سپس میگوییم
368
00:14:52,940 –> 00:14:54,900
سختافزار سطح پیشرفتهای که
369
00:14:54,900 –> 00:14:57,120
قبلاً برای پردازش استفاده میشد، امروز آن را انتخاب کردیم.
370
00:14:57,120 –> 00:14:59,400
ما از سختافزار سطح کالا با
371
00:14:59,400 –> 00:15:02,040
استفاده از مدیریت کلاستر و Hadoop و
372
00:15:02,040 –> 00:15:04,410
Spark استفاده میکنیم و همه این نرمافزارهایی
373
00:15:04,410 –> 00:15:06,960
که امروزه برای دادههای بزرگ استفاده میشوند
374
00:15:06,960 –> 00:15:09,450
، از گره خوشهای از نوعی منطق استفاده میکنند، بنابراین
375
00:15:09,450 –> 00:15:12,000
واضح است که Spark Apache را داریم که در مورد
376
00:15:12,000 –> 00:15:13,050
چه چیزی بحث خواهیم کرد.
377
00:15:13,050 –> 00:15:16,250
امروزه اسپارک آپاچی همچنین به
378
00:15:16,250 –> 00:15:19,410
پردازش دادهها کمک میکند و به روشی بسیار سریعتر
379
00:15:19,410 –> 00:15:21,450
از Hadoop، اگرچه از
380
00:15:21,450 –> 00:15:22,520
Hadoop
381
00:15:22,520 –> 00:15:24,770
بهعنوان پایهای برای چیزها به عنوان
382
00:15:24,770 –> 00:15:27,680
معیاری برای ذخیرهسازی چیزها استفاده میکند، اما جرقه
383
00:15:27,680 –> 00:15:29,360
با انجام روشهای بسیار سریعتر
384
00:15:29,360 –> 00:15:31,279
برای اجرای عملیات MapReduce
385
00:15:31,279 –> 00:15:34,190
یا اجرای عملیات MapReduce گسترش مییابد. عملیات Hadoop Big Data
386
00:15:34,190 –> 00:15:36,920
اساساً ما HBase داریم که
387
00:15:36,920 –> 00:15:40,790
کندو داریم اساساً به این معنی است
388
00:15:40,790 –> 00:15:43,040
که دادههای واقعی را تغییر نمیدهیم، بلکه به ما دیدی
389
00:15:43,040 –> 00:15:44,959
از این دادهها و پردازش آنها از موارد
390
00:15:44,959 –> 00:15:47,540
بالا بدون تغییر واقعی چیزی
391
00:15:47,540 –> 00:15:49,610
در دادههای اصلی،
392
00:15:49,610 –> 00:15:51,770
اساساً مشاهده دادهها را میگیرد که برخی از
393
00:15:51,770 –> 00:15:53,540
عملیاتها روی آن انجام میشود، خروجی را به شما میدهد،
394
00:15:53,540 –> 00:15:55,550
اما در واقع
395
00:15:55,550 –> 00:15:57,620
دادههای واقعی را که ما برای مقادیر زیادی انتخاب کردهایم تغییر نمیدهد.
396
00:15:57,620 –> 00:15:59,270
وبلاگهای وب که
397
00:15:59,270 –> 00:16:01,640
هر روز از وبسایتها ایجاد میشوند تا
398
00:16:01,640 –> 00:16:04,220
حجم زیادی از گزارشهای وب را پردازش کنیم که ما از یک جلوه شیک استفاده میکنیم،
399
00:16:04,220 –> 00:16:06,589
اینها برخی از ابزارهایی هستند که
400
00:16:06,589 –> 00:16:08,810
معمولاً برای دادههای بزرگ و
401
00:16:08,810 –> 00:16:12,110
صنایع بزرگ استفاده میکنیم، بنابراین در
402
00:16:12,110 –> 00:16:14,510
مورد یک جرقه غیرفعال صحبت خواهیم کرد. امروز و نحوه
403
00:16:14,510 –> 00:16:16,700
اجرای یک جرقه غیرفعال با یک عمل
404
00:16:16,700 –> 00:16:19,190
دستی، بنابراین ما به موضوع بعدی می رویم
405
00:16:19,190 –> 00:16:22,330
که یک جرقه بودجه است، بنابراین
406
00:16:22,330 –> 00:16:24,890
صحبت در مورد اسپارک آپاچی یک
407
00:16:24,890 –> 00:16:29,270
چارچوب ارائه شده برای انجام آن است، بنابراین آنچه که
408
00:16:29,270 –> 00:16:32,420
اساسا انجام می دهد فراهم می کند همانطور که می
409
00:16:32,420 –> 00:16:34,310
بینیم موتور تجزیه و تحلیل یکپارچه برای
410
00:16:34,310 –> 00:16:36,980
پردازش داده در مقیاس بزرگ،
411
00:16:36,980 –> 00:16:38,870
بنابراین فایلها را از فرآیند ذخیرهسازی که
412
00:16:38,870 –> 00:16:41,420
آن را پردازش میکند، میگیرد و نتایج را به ما میدهد
413
00:16:41,420 –> 00:16:44,540
تا آن را بهصورت منبع باز باز کند
414
00:16:44,540 –> 00:16:46,730
تا زیر آن آسانتر شود.
415
00:16:46,730 –> 00:16:48,890
تغییر آن بر اساس نیاز شما آسان تر است
416
00:16:48,890 –> 00:16:50,660
زیرا در یک محیط متن باز وجود
417
00:16:50,660 –> 00:16:55,520
دارد، بنابراین مزیت
418
00:16:55,520 –> 00:16:57,829
سوپ مزیت اسپارک در اصل این است که
419
00:16:57,829 –> 00:16:59,870
یک رابط برنامه ریزی کل
420
00:16:59,870 –> 00:17:01,790
خوشه ها با موازی سازی ضمنی داده ها
421
00:17:01,790 –> 00:17:04,400
و تحمل خطا فراهم می کند، به این معنی که
422
00:17:04,400 –> 00:17:07,250
حتی اگر داده ها را از دست بدهید. در یک گره حتی اگر
423
00:17:07,250 –> 00:17:10,670
داده ها را پردازش کنید و به نحوی دچار
424
00:17:10,670 –> 00:17:12,230
خطا شود، می توانید سه نفر به داده ها دسترسی داشته باشید
425
00:17:12,230 –> 00:17:13,699
زیرا این یک سیستم مدیریت مبتنی بر خوشه
426
00:17:13,699 –> 00:17:16,550
است بنابراین اساساً
427
00:17:16,550 –> 00:17:18,439
خودش را بر اساس همه
428
00:17:18,439 –> 00:17:20,270
گره ها تکرار می کند و در واقع می توانید از گره دیگری به آن دسترسی داشته باشید.
429
00:17:20,270 –> 00:17:22,520
موازی سازی داده ها
430
00:17:22,520 –> 00:17:25,040
به این معنی است که وقتی داده ها را پردازش
431
00:17:25,040 –> 00:17:27,859
می کنید به طور موازی در گره های مختلف اتفاق می
432
00:17:27,859 –> 00:17:31,960
افتد بنابراین سریعتر انجام می شود و
433
00:17:32,440 –> 00:17:34,549
کمی سابقه پس زمینه در
434
00:17:34,549 –> 00:17:36,710
اسپارک در ابتدا در
435
00:17:36,710 –> 00:17:39,200
436
00:17:39,200 –> 00:17:41,990
پایگاه قدیمی spark spark دانشگاه کالیفرنیا برکلی توسعه داده شد و بعداً
437
00:17:41,990 –> 00:17:43,730
به نرم افزار آپاچی اهدا شد.
438
00:17:43,730 –> 00:17:45,500
به همین دلیل است که امروزه به عنوان اسپارک آپاچی شناخته می
439
00:17:45,500 –> 00:17:47,240
شود و به عنوان یک نرم افزار منبع باز توسعه یافته است
440
00:17:47,240 –> 00:17:49,580
ابزار در
441
00:17:49,580 –> 00:17:52,460
دانشگاه کالیفرنیا و سپس به
442
00:17:52,460 –> 00:17:55,279
بنیاد نرمافزار آپاچی اهدا شد، بنابراین
443
00:17:55,279 –> 00:17:59,419
ما به بخش بعدی میرویم،
444
00:17:59,419 –> 00:18:02,539
هسته جرقه، اولین جزء اصلی
445
00:18:02,539 –> 00:18:04,520
که اسپارک دارد، که اساساً
446
00:18:04,520 –> 00:18:07,399
ارتباط 2 بعدی با rdd دارد،
447
00:18:07,399 –> 00:18:09,559
اما نکته اصلی است. در مورد جرقه مزیت اصلی
448
00:18:09,559 –> 00:18:11,149
در مورد نقطه،
449
00:18:11,149 –> 00:18:14,590
بنابراین Dedes ما چیست، بنابراین Dedes ما
450
00:18:14,590 –> 00:18:18,320
مجموعه داده های توزیع شده انعطاف پذیر هستند مجموعه ای چندگانه
451
00:18:18,320 –> 00:18:20,120
از اقلام داده فقط خواندنی توزیع شده بر روی
452
00:18:20,120 –> 00:18:21,649
دسته ای از ماشین ها که به
453
00:18:21,649 –> 00:18:24,620
روشی مقاوم در برابر خطا نگهداری می شوند، دوباره
454
00:18:24,620 –> 00:18:27,169
جنبه جرقه عبارت است از تحمل خطا که به معنای
455
00:18:27,169 –> 00:18:30,470
تکرار داده است، اگر
456
00:18:30,470 –> 00:18:33,289
در هر زمان از پردازش
457
00:18:33,289 –> 00:18:36,140
یا اجرای یک عملیات جرقه خطا رخ دهد،
458
00:18:36,140 –> 00:18:38,179
داده ها تکرار می شوند و ما می توانیم دوباره به آن دسترسی داشته باشیم
459
00:18:38,179 –> 00:18:41,510
و RDD اساساً به این معنی است که
460
00:18:41,510 –> 00:18:43,549
وقتی شما یک چیز عجیب و غریب ایجاد می کنید ممکن است یک خطا باشد.
461
00:18:43,549 –> 00:18:46,010
RDD بزرگ با توجه به مقدار
462
00:18:46,010 –> 00:18:49,059
دادهای که در آن RTD وارد کردهاید،
463
00:18:49,059 –> 00:18:52,220
بنابراین برای مدیریت آن مقدار زیاد
464
00:18:52,220 –> 00:18:56,059
فضای ذخیرهسازی، یک RDD میتواند خود را در گرههای مختلف پخش کند.
465
00:18:56,059 –> 00:18:58,669
s و این همان چیزی است که
466
00:18:58,669 –> 00:19:00,440
مدیریت مبتنی بر خوشه و جرقه این است که
467
00:19:00,440 –> 00:19:03,669
اساساً به این معنی است که یک RDD دقیقاً همین است، بنابراین
468
00:19:03,669 –> 00:19:07,130
یک RDD را می توان به روش های مختلفی پیاده سازی کرد،
469
00:19:07,130 –> 00:19:10,100
همانطور که می بینید، آبجکت های Python Java یا Scala
470
00:19:10,100 –> 00:19:13,190
و سپس ما Spock SQL را داریم
471
00:19:13,190 –> 00:19:16,520
البته جنبه ای از جرقهای که به ما امکان میدهد
472
00:19:16,520 –> 00:19:19,340
با سیستم مدیریت پایگاهداده رابطهای که پیادهسازی میکند مقابله کنیم،
473
00:19:19,340 –> 00:19:24,919
بنابراین Spock is
474
00:19:24,919 –> 00:19:27,110
QL با ارائه فریمهای داده به ما، TDهای ما را گسترش میدهد،
475
00:19:27,110 –> 00:19:29,240
بنابراین قاب داده
476
00:19:29,240 –> 00:19:31,760
اساساً توسعهای از یک RDD است که در آن
477
00:19:31,760 –> 00:19:34,370
میتوانیم از منابعی مانند
478
00:19:34,370 –> 00:19:37,630
فایلهای دادههای ساختار یافته جدول hive فایلهای csv یا فایلهای csv استفاده کنیم.
479
00:19:37,630 –> 00:19:40,399
پایگاه داده های خارجی یا rdd های موجود ما
480
00:19:40,399 –> 00:19:42,980
همچنین می توانیم فریم های داده را از موارد
481
00:19:42,980 –> 00:19:44,600
عجیب و غریب موجود بسازیم، شما می دانید که
482
00:19:44,600 –> 00:19:45,180
483
00:19:45,180 –> 00:19:48,720
اگر یادگیری ماشین پایتون
484
00:19:48,720 –> 00:19:50,370
یا یادگیری ماشینی را با ما انجام داده
485
00:19:50,370 –> 00:19:52,770
باشید، بر اساس همان منطق و
486
00:19:52,770 –> 00:19:56,100
مانند شما است که تاریخ نام آن ها را ندارند. می توانید ببینید که الهام گرفته شده
487
00:19:56,100 –> 00:19:59,340
است، بنابراین اکنون که در مورد
488
00:19:59,340 –> 00:20:01,530
اجزای SPARC بحث کردیم، اکنون در
489
00:20:01,530 –> 00:20:03,480
مورد مزایای SPARC نسبت به
490
00:20:03,480 –> 00:20:07,650
عملیات سنتی Hadoop عملیات پردازش Hadoop صحبت خواهیم
491
00:20:07,650 –> 00:20:10,410
کرد.
492
00:20:10,410 –> 00:20:13,080
بدیهی است که دلیل اینکه ما
493
00:20:13,080 –> 00:20:15,780
یک روش از قبل موجود را با هر چیزی جدید جایگزین می کنیم، به دلیل متدولوژی ها هستند، بدیهی است که دلیل اینکه ما یک روش از قبل موجود را
494
00:20:15,780 –> 00:20:17,730
با هر چیزی جدید جایگزین می کنیم این است که
495
00:20:17,730 –> 00:20:20,730
کارآمدتر است، بنابراین سرعت اول پس از آن
496
00:20:20,730 –> 00:20:21,810
ما سهولت استفاده را داریم،
497
00:20:21,810 –> 00:20:23,430
بدیهی است که استفاده از SPARC بسیار آسان تر
498
00:20:23,430 –> 00:20:26,940
است Hadoop به ما کمک می کند. از چیزهایی
499
00:20:26,940 –> 00:20:29,100
با پیادهسازیهای سطح قدیمی و
500
00:20:29,100 –> 00:20:30,890
درک آن برای تازهواردها سختتر و
501
00:20:30,890 –> 00:20:32,700
درک آن سختتر زمانی
502
00:20:32,700 –> 00:20:34,260
است که از ابتدا چیزی را یاد میگیرید،
503
00:20:34,260 –> 00:20:37,590
بدیهی است که SPARC یک
504
00:20:37,590 –> 00:20:39,480
انتزاع بر روی Hadoop به ما ارائه میدهد، بنابراین
505
00:20:39,480 –> 00:20:41,600
استفاده از آن آسانتر است، سپس ما مسئولیت کلی
506
00:20:41,600 –> 00:20:44,850
داریم و سپس هر جایی اجرا میکنیم.
507
00:20:44,850 –> 00:20:47,760
این پارک تقریباً یک
508
00:20:47,760 –> 00:20:49,290
وصله است، این پارک تقریباً مستقل از پلتفرم است،
509
00:20:49,290 –> 00:20:52,500
بنابراین بارهای کاری را صد
510
00:20:52,500 –> 00:20:54,150
برابر سریعتر صد برابر سریعتر اجرا میکند و در
511
00:20:54,150 –> 00:20:56,130
این مورد به این معنی است که
512
00:20:56,130 –> 00:20:58,020
در مقایسه با Hadoop
513
00:20:58,020 –> 00:21:01,680
legacy hadoo 100 برابر سریعتر اجرا میشود، پس ما میتوانیم استفاده از آن را آسان کنیم.
514
00:21:01,680 –> 00:21:04,260
برنامه های کاربردی با
515
00:21:04,260 –> 00:21:06,870
نرفتن به روش های کدنویسی قدیمی می توانیم از آن استفاده کنیم از
516
00:21:06,870 –> 00:21:09,840
Park با استفاده از spur Java Scala Python یا و
517
00:21:09,840 –> 00:21:13,590
SQL سپس کلی داریم ترکیبی از
518
00:21:13,590 –> 00:21:15,240
جریان SQL و تجزیه و تحلیل پیچیده،
519
00:21:15,240 –> 00:21:17,190
اساساً به ما این امکان را می دهد که
520
00:21:17,190 –> 00:21:19,290
همه اینها را ترکیب کنیم به جای اینکه سه
521
00:21:19,290 –> 00:21:22,440
پایانه جداگانه برای هر
522
00:21:22,440 –> 00:21:25,080
سه C از API داشته باشیم، برای همه این
523
00:21:25,080 –> 00:21:27,510
سه اجرا در هر جایی که جرقه در Hadoop Apache اجرا شود
524
00:21:27,510 –> 00:21:29,820
منبع من kubernetes مستقل است.
525
00:21:29,820 –> 00:21:31,770
یا در فضای ابری می تواند به منابع داده های متنوعی دسترسی داشته
526
00:21:31,770 –> 00:21:33,360
باشد، به طوری که
527
00:21:33,360 –> 00:21:37,530
پیاده سازی Spock
528
00:21:37,530 –> 00:21:39,300
با استفاده از PI Spock کاملاً واضح است، بنابراین اکنون که ما در
529
00:21:39,300 –> 00:21:41,970
مورد چیستی اسپارک آپاچی بحث کرده
530
00:21:41,970 –> 00:21:44,460
ایم و می توانیم با کمی دستی به پیاده سازی آن بپردازیم.
531
00:21:44,460 –> 00:21:46,590
بنابراین ابتدا
532
00:21:46,590 –> 00:21:48,810
قبل از اینکه به سراغ hams دستی برویم، بحث خواهیم کرد که اسپارک PI چیست،
533
00:21:48,810 –> 00:21:51,390
زیرا
534
00:21:51,390 –> 00:21:54,120
اسپارک من API پایتون است، بنابراین
535
00:21:54,120 –> 00:21:56,790
اساساً به این دلیل است که پیسون به
536
00:21:56,790 –> 00:21:59,520
ما یک API برای نوشتن
537
00:21:59,520 –> 00:22:01,980
کد جرقه به جای نوشتن اسپارک در
538
00:22:01,980 –> 00:22:04,260
اسپارک می دهد. ترمینال میتوانیم در پایتون بنویسیم
539
00:22:04,260 –> 00:22:06,360
و دقیقاً همین کار را انجام میدهد در
540
00:22:06,360 –> 00:22:08,250
واقع فرصتهای بهتر و متدولوژیهای بهتری به ما میدهد،
541
00:22:08,250 –> 00:22:09,870
زیرا Python
542
00:22:09,870 –> 00:22:11,430
بدیهی است که از یادگیری ماشینی پشتیبانی میکند و
543
00:22:11,430 –> 00:22:14,370
اگر بخواهیم پیادهسازی و یکپارچه سازی کنیم
544
00:22:14,370 –> 00:22:16,770
هر دوی اینها را به مزایای
545
00:22:16,770 –> 00:22:19,500
پایتون و اسپارک رتبه بندی کنید و آن را در یک
546
00:22:19,500 –> 00:22:22,560
پلتفرم قرار دهید به جای اینکه خودمان را
547
00:22:22,560 –> 00:22:25,230
با اجرای آن روی دو
548
00:22:25,230 –> 00:22:28,440
پلتفرم دیوانه کنیم، می توانیم از PI spark API
549
00:22:28,440 –> 00:22:29,940
که توسط پایتون ارائه شده است استفاده کنیم،
550
00:22:29,940 –> 00:22:33,360
بنابراین اساساً spark یک
551
00:22:33,360 –> 00:22:37,500
موتور محاسباتی است که چیزها را در آن پردازش می کند. اگر
552
00:22:37,500 –> 00:22:39,510
از اسپارک PI استفاده می کنیم، کاری که می بینیم اسپارک
553
00:22:39,510 –> 00:22:41,910
انجام می دهد این است که اسپارک قسمت پردازش
554
00:22:41,910 –> 00:22:43,860
آن و قسمت ذخیره سازی آن را انجام می دهد در حالی که
555
00:22:43,860 –> 00:22:46,560
پایتون دستورات
556
00:22:46,560 –> 00:22:50,010
قسمت اجرایی آن را انجام می دهد، بنابراین اجرا و ذخیره
557
00:22:50,010 –> 00:22:52,260
چیزها در یک سیستم مدیریت خوشه
558
00:22:52,260 –> 00:22:54,990
توسط جرقه انجام می شود. Python just
559
00:22:54,990 –> 00:22:58,410
برای نوشتن دستورات استفاده میشود، بنابراین به سراغ دستورات
560
00:22:58,410 –> 00:23:02,700
بعدی میرویم، بنابراین
561
00:23:02,700 –> 00:23:07,590
یک نقطه همکاری بررسی شده است یا
562
00:23:07,590 –> 00:23:09,840
ترمینال google.com در اینجا باز است،
563
00:23:09,840 –> 00:23:11,640
این اساساً یک دفترچه یادداشت مشتری است
564
00:23:11,640 –> 00:23:14,100
که ما از آن استفاده میکنیم. راهاندازی یک
565
00:23:14,100 –> 00:23:16,410
ماشین مجازی یا راهاندازی یک
566
00:23:16,410 –> 00:23:18,930
نمونه AWS که به
567
00:23:18,930 –> 00:23:22,440
پول و یا قدرت پردازش زیادی روی رایانه شخصی شما نیاز دارد،
568
00:23:22,440 –> 00:23:24,720
ما فقط میتوانیم از تور تحقیقاتی نقطهای همکاری
569
00:23:24,720 –> 00:23:27,000
به نام google.com استفاده کنیم.
570
00:23:27,000 –> 00:23:29,130
نوتبوک مشتری که گوگل
571
00:23:29,130 –> 00:23:32,340
ارائه میکند، بنابراین ما میتوانیم آن ر