در این مطلب، ویدئو خوشه بندی سهام با پایتون | قسمت 4 PCA & Plotting با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:23:25
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,060 –> 00:00:03,179
به همگی به یک آموزش دیگر پایتون خوش آمدید،
2
00:00:03,179 –> 00:00:06,120
ما در حال ادامه سری k-means
3
00:00:06,120 –> 00:00:09,660
خود هستیم آخرین ویدیوی ما که بیشتر
4
00:00:09,660 –> 00:00:12,330
بر حذف نقاط پرت از مجموعه داده هایمان تمرکز می کنیم
5
00:00:12,330 –> 00:00:14,849
و تغییرات اساسی را انجام می دهیم و
6
00:00:14,849 –> 00:00:17,580
فقط داده هایمان را واقعاً
7
00:00:17,580 –> 00:00:19,380
برای ترسیم آماده می کنیم.
8
00:00:19,380 –> 00:00:21,210
ما باید در مورد آن در این
9
00:00:21,210 –> 00:00:23,400
ویدیو فکر کنیم که بیشتر بر روی طرحبندی تمرکز میکنیم،
10
00:00:23,400 –> 00:00:28,740
شاید
11
00:00:28,740 –> 00:00:31,560
اگر احساس کنم که خیلی طولانی نخواهد شد، ممکن است به تجزیه و تحلیل PCA بروم،
12
00:00:31,560 –> 00:00:33,870
اما
13
00:00:33,870 –> 00:00:36,239
در این مرحله این یک نوع برنامه است، بنابراین اولین چیز
14
00:00:36,239 –> 00:00:37,110
ما این کار را انجام می دهیم این است که
15
00:00:37,110 –> 00:00:39,059
داده های خود را رسم می کنیم، بنابراین می گوییم mat نمودار و
16
00:00:39,059 –> 00:00:40,620
سپس در خط انجام می دهیم زیرا می
17
00:00:40,620 –> 00:00:41,910
خواهم مطمئن شوم که می توانم نمودارهای خود را
18
00:00:41,910 –> 00:00:46,200
در دفترچه واقعی ببینم تا بتوانیم
19
00:00:46,200 –> 00:00:49,530
میخواهیم matplotlib را انجام دهیم و سپس از اینجا
20
00:00:49,530 –> 00:00:51,629
باید کتابخانه خود را وارد کنیم،
21
00:00:51,629 –> 00:00:57,199
بنابراین ما میخواهیم نمودار mat plot lib
22
00:00:57,199 –> 00:01:03,390
dot pie را به عنوان نمودار وارد کنیم و سپس از اینجا
23
00:01:03,390 –> 00:01:05,610
کارهای دیگری انجام میدهیم، بنابراین
24
00:01:05,610 –> 00:01:07,380
یک 3 بعدی انجام میدهیم. نمودار و بنابراین مجبور شدیم
25
00:01:07,380 –> 00:01:09,510
چیزهای دیگری را وارد کنیم
26
00:01:09,510 –> 00:01:13,500
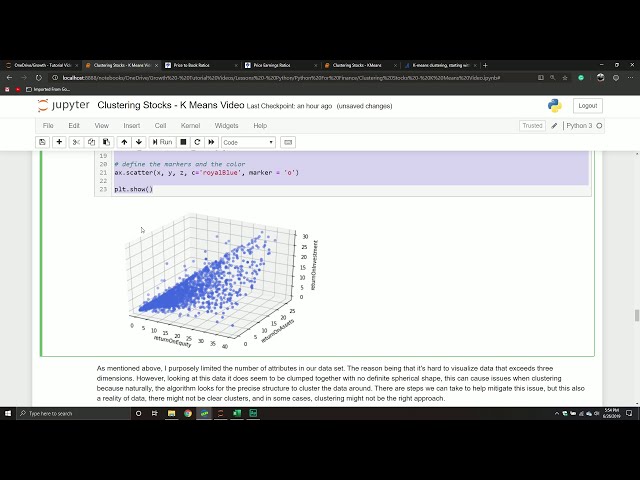
تا تبر سه بعدی را فراهم کنیم es و من میخواهم MPL را انجام دهم،
27
00:01:13,500 –> 00:01:15,799
بنابراین اینجاست، من سعی میکنم دوباره املای جعبه ابزار
28
00:01:15,799 –> 00:01:28,860
M نمودار سه بعدی محورهای وارداتی 3 بعدی بله خوب بعد
29
00:01:28,860 –> 00:01:29,909
از اینجا ما شکل خود را تعریف میکنیم،
30
00:01:29,909 –> 00:01:33,390
بنابراین شکل خود را کاملاً ساده تعریف کنید،
31
00:01:33,390 –> 00:01:34,710
ما فقط ایجاد میکنیم یک
32
00:01:34,710 –> 00:01:37,619
متغیر جدید آن را fig plot می نامیم و سپس
33
00:01:37,619 –> 00:01:40,770
ما شیء شکل خود
34
00:01:40,770 –> 00:01:42,899
را بدون محور صدا می
35
00:01:42,899 –> 00:01:47,790
36
00:01:47,790 –> 00:01:49,680
زنیم.
37
00:01:49,680 –> 00:01:51,990
اکنون باید
38
00:01:51,990 –> 00:01:57,719
هر محور را تعریف کنیم، بنابراین محورهای X، Y
39
00:01:57,719 –> 00:02:02,460
و z را تعریف کنیم، بنابراین کاری که
40
00:02:02,460 –> 00:02:04,890
میخواهیم انجام دهیم این است که x برابر کمتر است
41
00:02:04,890 –> 00:02:06,780
زیرا باید یک لیست باشد و نمیتواند یک قاب داده باشد.
42
00:02:06,780 –> 00:02:08,250
یا هر چیزی شبیه به آن، هیچ چیز
43
00:02:08,250 –> 00:02:10,378
آنقدر که ما میخواهیم جذاب نیست و
44
00:02:10,378 –> 00:02:13,230
سپس ما این کار را انجام میدهم، قفل میکنم و سپس
45
00:02:13,230 –> 00:02:13,500
به
46
00:02:13,500 –> 00:02:15,030
نوعی رویکرد عمومیتر را انجام
47
00:02:15,030 –> 00:02:16,560
میدهم، فقط میگویم هی که باید باشد
48
00:02:16,560 –> 00:02:18,060
ستون اول شما چون شاید
49
00:02:18,060 –> 00:02:19,380
می خواهید کاوش کنید شاید می خواهید بگویید هی
50
00:02:19,380 –> 00:02:21,540
من می خواهم دفعه بعد یک ویژگی متفاوت انجام دهم
51
00:02:21,540 –> 00:02:24,330
و غیره و غیره سپس
52
00:02:24,330 –> 00:02:25,530
53
00:02:25,530 –> 00:02:27,930
بارها و بارها از این طرح استفاده خواهیم کرد، بنابراین به
54
00:02:27,930 –> 00:02:30,209
هر طریقی مانند کپی و پیست کردن قلب های شما
55
00:02:30,209 –> 00:02:33,270
بسیار خوب است، از اینجا ما
56
00:02:33,270 –> 00:02:35,310
داده هایی را که قرار است به آنجا
57
00:02:35,310 –> 00:02:38,670
بروند تعریف کرده ایم، اکنون برچسب های محور را تعریف می کنیم. بنابراین
58
00:02:38,670 –> 00:02:41,160
ما میخواهیم بگوییم که محورها متأسفم
59
00:02:41,160 –> 00:02:45,060
تصحیح نام ستونهای تعریفشده که
60
00:02:45,060 –> 00:02:48,810
با شاخصهای ما برابری میکنند، ستون نقطهای F،
61
00:02:48,810 –> 00:02:50,160
بنابراین ما آن را
62
00:02:50,160 –> 00:02:52,020
به درستی ستونها نامیده میشویم که فهرستی را برمیگرداند
63
00:02:52,020 –> 00:02:54,750
که سپس میتوانیم آن را بهعنوان محور تنظیم کنیم، بنابراین
64
00:02:54,750 –> 00:02:58,770
میخواهیم برچسب X برابر
65
00:02:58,770 –> 00:03:05,160
با نام ستون ما صفر باشد، بنابراین
66
00:03:05,160 –> 00:03:06,900
ممکن است برخی از افراد مانند الکس بپرسند که چرا این کار را انجام میدهید،
67
00:03:06,900 –> 00:03:08,540
آیا واقعاً مهم است
68
00:03:08,540 –> 00:03:10,830
که همیشه باید دادههای خود را در
69
00:03:10,830 –> 00:03:13,560
صورت امکان تجسم کنید، هرگز نمیدانید که ممکن
70
00:03:13,560 –> 00:03:15,660
است به او به گونهای نگاه کنید که قطعاً
71
00:03:15,660 –> 00:03:16,890
اینطور است. ابتدا می دانستم که
72
00:03:16,890 –> 00:03:18,090
آب و هوا چشم انداز است، زیرا سعی کردم
73
00:03:18,090 –> 00:03:19,320
نقشه بکشم و مثل اینکه یک دقیقه صبر کنید
74
00:03:19,320 –> 00:03:21,239
جواب نمی
75
00:03:21,239 –> 00:03:23,580
دهد، کاملاً واضح بود که یک پدر و مادر وجود دارد،
76
00:03:23,580 –> 00:03:25,530
بنابراین باید همیشه سعی
77
00:03:25,530 –> 00:03:27,900
کنید داده های خود را تجسم کنید، گاهی اوقات چیزهایی وجود دارد که
78
00:03:27,900 –> 00:03:29,870
در آنجا پنهان هستند. اینها لزوما
79
00:03:29,870 –> 00:03:35,040
درست نیستند، اما این فقط نظر من است، بنابراین
80
00:03:35,040 –> 00:03:36,989
ما یک نمودار پراکندگی انجام می دهیم، بنابراین یک نمودار
81
00:03:36,989 –> 00:03:38,250
پراکندگی سه بعدی خواهد بود،
82
00:03:38,250 –> 00:03:41,940
بنابراین ما x ry و RZ خود را تعریف می کنیم
83
00:03:41,940 –> 00:03:44,519
و سپس ما می خواهیم انجام دهیم. رنگی
84
00:03:44,519 –> 00:03:47,130
که با پارامتر C مشخص می شود من عاشق
85
00:03:47,130 –> 00:03:50,010
این رنگ آبی سلطنتی هستم، من این رنگ من است،
86
00:03:50,010 –> 00:03:52,470
پس آن را دزدی نکن، شوخی
87
00:03:52,470 –> 00:03:55,920
می کنم که می توانی
88
00:03:55,920 –> 00:03:57,780
آن را بدزدی.
89
00:03:57,780 –> 00:03:59,070
آن را نیز نشان دهید،
90
00:03:59,070 –> 00:04:00,600
زیرا در غیر این صورت، چه
91
00:04:00,600 –> 00:04:07,769
فایده ای دارد که آن را پاک کنید، هوم، یوتیوب از آن خوشحال نخواهد شد
92
00:04:07,769 –> 00:04:08,720
93
00:04:08,720 –> 00:04:11,319
[خنده]
94
00:04:11,319 –> 00:04:14,230
که عمدی نبود، خوب چه اتفاقی می
95
00:04:14,230 –> 00:04:18,639
افتد X Y Z نه احساس می کنم دارم عجله می کنم،
96
00:04:18,639 –> 00:04:20,350
بسیار
97
00:04:20,350 –> 00:04:23,050
عالی، پس این سه مورد ماست.
98
00:04:23,050 –> 00:04:26,470
نمودار پراکندگی بعدی که می توانید در اینجا ببینید
99
00:04:26,470 –> 00:04:28,090
خروجی شما خواهد بود که X wack شما خواهد بود
100
00:04:28,090 –> 00:04:33,570
و سپس Y oh بله X Y Z شما پس
101
00:04:33,570 –> 00:04:36,990
X اولین ستونی است که در یک
102
00:04:36,990 –> 00:04:40,030
ثانیه WA T برگردانده می شود و سپس ستون دوم بازگشت
103
00:04:40,030 –> 00:04:42,940
در دارایی ها است، بنابراین این ستون شماست. Y و سپس
104
00:04:42,940 –> 00:04:45,880
بازگشت سرمایه بنابراین در نگاه اول
105
00:04:45,880 –> 00:04:48,160
وجود دارد در واقع به نظر می رسد که
106
00:04:48,160 –> 00:04:50,560
ساختاری در اینجا وجود دارد، اما صادقانه بگویم
107
00:04:50,560 –> 00:04:52,870
، موارد خاصی وجود دارد که
108
00:04:52,870 –> 00:04:54,250
در پایان ویدیو توضیح خواهم داد
109
00:04:54,250 –> 00:04:56,320
که شاید چه کاری می توانستیم متفاوت انجام
110
00:04:56,320 –> 00:04:59,830
دهیم، اما دیدن نوع داده غیر معمول
111
00:04:59,830 –> 00:05:02,740
نیست. از این قبیل و بنابراین
112
00:05:02,740 –> 00:05:04,690
ساختاری در اینجا وجود دارد، اما کاملاً واضح است
113
00:05:04,690 –> 00:05:06,970
که اینجا مانند بلوک متراکم وجود دارد،
114
00:05:06,970 –> 00:05:09,430
منظورم این است که بسیار متراکم است، به نظر می رسد که
115
00:05:09,430 –> 00:05:11,800
اکثر شرکت های ما در بیشتر
116
00:05:11,800 –> 00:05:14,199
موارد در اینجا زندگی می کنند و سپس
117
00:05:14,199 –> 00:05:16,539
شما این نوع را دارید پراکندگی بیرونی و
118
00:05:16,539 –> 00:05:18,070
بنابراین اینها چیزی هستند که من می
119
00:05:18,070 –> 00:05:20,949
نامم. منظورم حداقل در نگاه اول
120
00:05:20,949 –> 00:05:23,320
موارد استثنایی است.
121
00:05:23,320 –> 00:05:25,780
122
00:05:25,780 –> 00:05:27,190
123
00:05:27,190 –> 00:05:28,990
بازگشت سرمایه، بنابراین
124
00:05:28,990 –> 00:05:31,060
اینها به نوعی شبیه ستاره های راک هستند
125
00:05:31,060 –> 00:05:33,610
که این افراد در اینجا آنقدرها
126
00:05:33,610 –> 00:05:35,979
هم عالی نیستند، آنها عملکرد
127
00:05:35,979 –> 00:05:38,800
فوق العاده خوبی ندارند، آنها
128
00:05:38,800 –> 00:05:41,080
تقریباً در هر معیاری ضعیف عمل می کنند و سپس
129
00:05:41,080 –> 00:05:43,210
شما را به دست آوردید. فله دیگری را دقیقاً اینجا می شناسید
130
00:05:43,210 –> 00:05:44,949
که کجاست مثل هی مثل
131
00:05:44,949 –> 00:05:47,590
اینها فقط میدانی که بد یا خوب نیستند، منظورم این است
132
00:05:47,590 –> 00:05:51,099
که بیشتر مردم 7٪ بازده سهام
133
00:05:51,099 –> 00:05:52,840
و چیزی که بسیار بد است، اما من
134
00:05:52,840 –> 00:05:54,430
حدس میزنم با طرح بزرگتری از چیزهایی
135
00:05:54,430 –> 00:05:55,599
که میگویید مثل بله، به نظر من
136
00:05:55,599 –> 00:05:57,310
یعنی تعداد زیادی از شرکتها وجود
137
00:05:57,310 –> 00:05:59,470
دارند که در بیشتر موارد تصور میکنید عملکرد نسبتاً خوبی دارند
138
00:05:59,470 –> 00:06:01,510
، به همین دلیل
139
00:06:01,510 –> 00:06:03,250
مهم است که مطمئن شوید که
140
00:06:03,250 –> 00:06:07,330
شما میدانید
141
00:06:07,330 –> 00:06:09,520
دادههای خود را ترسیم میکنید، در غیر این صورت
142
00:06:09,520 –> 00:06:12,550
گاهی اوقات به هم میریزد، خوب اجازه دهید به
143
00:06:12,550 –> 00:06:13,180
مبحث بعدی بروید،
144
00:06:13,180 –> 00:06:16,449
بنابراین در بالا ذکر کردم که k-means
145
00:06:16,449 –> 00:06:18,970
واقعاً به موارد پرت حساس است و بنابراین
146
00:06:18,970 –> 00:06:20,530
باید مطمئن شویم که
147
00:06:20,530 –> 00:06:23,169
در غیر این صورت می تواند به طور چشمگیری بر
148
00:06:23,169 –> 00:06:24,610
نتایج شما تأثیر بگذارد و
149
00:06:24,610 –> 00:06:26,469
بنابراین آنچه که ما از آن استفاده خواهیم کرد
150
00:06:26,469 –> 00:06:28,479
داخل s Kaler و آنها این اشیا را دارند
151
00:06:28,479 –> 00:06:30,879
که اسکالر نامیده می شوند و اساساً کاری که
152
00:06:30,879 –> 00:06:32,590
اسکالرها انجام می دهند این است که داده های شما را می گیرند و
153
00:06:32,590 –> 00:06:34,539
سعی می کنند آنها را برای شما عادی سازی کنند تا
154
00:06:34,539 –> 00:06:37,840
کمی بیشتر به
155
00:06:37,840 –> 00:06:41,349
شیوه ای سنتی رفتار کند و وقتی این کار به درد نمی خورد.
156
00:06:41,349 –> 00:06:43,210
دوباره وقتی
157
00:06:43,210 –> 00:06:44,979
به مؤلفه واقعی مدلسازی میرسد
158
00:06:44,979 –> 00:06:46,930
، خیلی خوب است که بیش از سه مورد وجود دارد،
159
00:06:46,930 –> 00:06:48,639
اما سه مورد که میخواهم در مورد آنها صحبت کنم
160
00:06:48,639 –> 00:06:52,270
، یک مقیاسکننده استاندارد است که من در مقیاسکننده مک هستم
161
00:06:52,270 –> 00:06:54,490
و سپس یک مقیاسکننده قوی، ما
162
00:06:54,490 –> 00:06:55,479
متوجه میشویم که خواهیم داشت. برای استفاده از یک
163
00:06:55,479 –> 00:06:58,479
مقیاسکننده قوی، بنابراین با یک مقیاسکننده استاندارد،
164
00:06:58,479 –> 00:07:00,279
این مقدار کمی مانند امتیاز z شما است،
165
00:07:00,279 –> 00:07:02,710
بنابراین اساساً هر
166
00:07:02,710 –> 00:07:05,289
نقطه داده را میگیریم، میانگین را کم میکنیم و سپس
167
00:07:05,289 –> 00:07:06,430
آن را بر انحراف استاندارد تقسیم میکنیم
168
00:07:06,430 –> 00:07:09,099
، مشکل این است که این به اعداد پرت حساس است.
169
00:07:09,099 –> 00:07:11,139
با این حال، زیرا اگر
170
00:07:11,139 –> 00:07:12,729
میانگین تمام نقاط داده را در نظر بگیرید،
171
00:07:12,729 –> 00:07:15,460
شامل نقاط پرت نیز می شود و
172
00:07:15,460 –> 00:07:17,229
بنابراین میانگین و
173
00:07:17,229 –> 00:07:19,810
انحراف معیار شما با مقیاس کننده حداقل/حداکثر یکسان تحت تاثیر قرار می گیرد، مقیاس
174
00:07:19,810 –> 00:07:21,669
کننده حداقل/حداکثر
175
00:07:21,669 –> 00:07:23,860
اساساً سعی می کند همه را مطابقت دهد.
176
00:07:23,860 –> 00:07:27,629
از داده های شما بین یک محدوده 0 و 1
177
00:07:27,629 –> 00:07:29,469
ریاضی به خوبی انجام می
178
00:07:29,469 –> 00:07:31,810
دهیم، هر نقطه داده را می گیریم
179
00:07:31,810 –> 00:07:34,389
، حداقل را از آن کم می کنیم و سپس
180
00:07:34,389 –> 00:07:36,219
آن را بر اختلاف حداکثر
181
00:07:36,219 –> 00:07:38,680
مقدار در مقدار حداقل تقسیم می کنیم، دوباره این
182
00:07:38,680 –> 00:07:40,810
واقعاً حساس است. e به مقادیر پرت است زیرا
183
00:07:40,810 –> 00:07:43,180
اگر حداکثر مقدار شما متأسفیم اگر
184
00:07:43,180 –> 00:07:46,150
حداکثر مقدار شما 20% 20000
185
00:07:46,150 –> 00:07:48,430
درصد OE است، می توانید ببینید که چگونه
186
00:07:48,430 –> 00:07:51,370
کارها را خراب می کند، بنابراین بسیار مهم است
187
00:07:51,370 –> 00:07:54,490
که از اسکالر مناسب استفاده کنیم تا
188
00:07:54,490 –> 00:07:56,919
آخرین مورد اسکالر قوی این باشد.
189
00:07:56,919 –> 00:07:59,169
اگر دادههای شما
190
00:07:59,169 –> 00:08:01,539
دارای نقاط پرت باشد، با این روش، ما
191
00:08:01,539 –> 00:08:04,870
اساساً محدوده بین
192
00:08:04,870 –> 00:08:06,669
چارکی را میگیریم، بنابراین در واقع آخرین
193
00:08:06,669 –> 00:08:09,339
قسمت بالا و پایین را برش میدهیم و از
194
00:08:09,339 –> 00:08:12,339
آن استفاده میکنیم تا به نوعی از مردان و حداکثر خودمان باشیم.
195
00:08:12,339 –> 00:08:14,020
بنابراین بسیار شبیه
196
00:08:14,020 –> 00:08:15,939
مقیاسکننده حداقل حداکثر است، اما ما یک
197
00:08:15,939 –> 00:08:17,589
حداقل بسیار خاص و یک ماکزیمم بسیار خاص را انتخاب
198
00:08:17,589 –> 00:08:20,080
میکنیم و اساساً آن را در جایی قرار
199
00:08:20,080 –> 00:08:21,939
میدهیم که ابتدا
200
00:08:21,939 –> 00:08:24,669
و آخرین قسمت را حذف میکنیم و سپس در حالت ایدهآل
201
00:08:24,669 –> 00:08:26,620
آنچه قرار است انجام شود. انجام دادن کمک به
202
00:08:26,620 –> 00:08:29,439
کنترل نقاط دورافتاده است، بنابراین چگونه به نظر
203
00:08:29,439 –> 00:08:32,140
خوب می رسد، من هر سه مثال را انجام می دهم فقط تا
204
00:08:32,140 –> 00:08:33,399
بتوانید ببینید که تقریباً
205
00:08:33,399 –> 00:08:35,349
یکسان هستند، اما ما فقط از
206
00:08:35,349 –> 00:08:37,260
یک نمونه قوی استفاده می کنیم که به سمت جلو
207
00:08:37,260 –> 00:08:40,260
کاملاً درست است، بنابراین انجام خواهم داد آیا
208
00:08:40,260 –> 00:08:45,090
می خواهیم بگوییم از SK یاد بگیرید که ما
209
00:08:45,090 –> 00:08:48,960
پیش پردازش را انجام می
210
00:08:48,960 –> 00:08:53,490
دهیم و در اینجا وارد می کنیم.
211
00:08:53,490 –> 00:08:58,970
212
00:08:58,970 –> 00:09:03,210
213
00:09:03,210 –> 00:09:04,770
214
00:09:04,770 –> 00:09:10,440
و بنابراین از اینجا
215
00:09:10,440 –> 00:09:13,800
ما حداکثر مقیاسکننده را انجام میدهیم و این
216
00:09:13,800 –> 00:09:17,390
با شیء مقیاسکننده حداکثر ما برابر
217
00:09:17,390 –> 00:09:20,010
میشود و سپس
218
00:09:20,010 –> 00:09:24,420
یک مقیاسکننده STD احتمالاً انتخاب خوبی برای
219
00:09:24,420 –> 00:09:28,260
یک نام نیست، اما هر مقیاسکننده استاندارد
220
00:09:28,260 –> 00:09:31,860
و سپس از اینجا ما مقیاسکننده قوی خود را انجام
221
00:09:31,860 –> 00:09:36,420
میدهیم و این برابر با
222
00:09:36,420 –> 00:09:40,260
تابع خطای مقیاس قوی ما خواهد بود،
223
00:09:40,260 –> 00:09:43,460
بیایید دادهها را
224
00:09:43,460 –> 00:09:46,950
مقیاسبندی کنیم، بنابراین ما آن را
225
00:09:46,950 –> 00:09:49,590
سنتی مانند قطار X بنامیم، خیلی خندهدار این
226
00:09:49,590 –> 00:09:51,450
است که واقعاً شبیه یک
227
00:09:51,450 –> 00:09:54,330
جزء آموزشی از k- نیست. منظورم این است که برخی از افراد به
228
00:09:54,330 –> 00:09:56,730
نوعی استدلال می کنند که وجود دارد زیرا برخی از
229
00:09:56,730 –> 00:09:59,250
افراد می گویند که خوب می توان به
230
00:09:59,250 –> 00:10:01,020
بیش از حد مناسب دسترسی داشت، اما ما نمی خواهیم این موضوع را
231
00:10:01,020 –> 00:10:03,080
پوشش دهیم که در این ویدیوی خاص از نظر
232
00:10:03,080 –> 00:10:04,950
فنی به نوعی سخت است زیرا
233
00:10:04,950 –> 00:10:07,170
مانند اینکه چگونه آن را مقایسه کنید هیچ چیز
234
00:10:07,170 –> 00:10:09,210
واقعی نیست. برچسب گذاری شده است، بنابراین چگونه می توانید بگویید
235
00:10:09,210 –> 00:10:11,100
که خوب یا بد بوده است،
236
00:10:11,100 –> 00:10:12,300
چیزی ندارید که آن را با
237
00:10:12,300 –> 00:10:17,280
خوب مقایسه کنید، بنابراین شاخص DF خوب است، بنابراین
238
00:10:17,280 –> 00:10:19,140
ما حداکثر شیء اسکالر خود را فراخوانی می کنیم و سپس
239
00:10:19,140 –> 00:10:21,330
یک تبدیل مناسب انجام می دهیم و تمام و سپس
240
00:10:21,330 –> 00:10:24,420
ما از چارچوب داده ما عبور کنید خوب است، پس
241
00:10:24,420 –> 00:10:27,840
چطور اوه نه اینطور نیست که ما
242
00:10:27,840 –> 00:10:30,660
این یکی را انجام می دهیم و سپس این یکی
243
00:10:30,660 –> 00:10:34,890
را انجام می دهیم و سپس استاندارد را انجام می دهیم و سپس
244
00:10:34,890 –> 00:10:39,000
قوی عمل می کنیم و در بیشتر موارد خواهید دید
245
00:10:39,000 –> 00:10:41,640
که من یعنی
246
00:10:41,640 –> 00:10:43,680
کمی این را تغییر میدهد اما
247
00:10:43,680 –> 00:10:46,650
نسبتاً یکسان باقی میماند و سپس کاری که میخواهیم
248
00:10:46,650 –> 00:10:49,290
انجام دهیم این است که مقیاس استاندارد
249
00:10:49,290 –> 00:10:50,870
250
00:10:50,870 –> 00:10:54,980
را انجام میدهیم و مقیاسکننده قوی خود را انجام میدهیم
251
00:10:54,980 –> 00:10:58,700
و همچنین واقعاً ایده بدی نیست که به
252
00:10:58,700 –> 00:11:02,360
طور معمول از آنچه که من میگویم مقیاس
253
00:11:02,360 –> 00:11:04,310
دادههای خود را بیشتر کنید، زمانی که مدلهای شما در حالت
254
00:11:04,310 –> 00:11:06,590
ضعیف انجام میدهند، هنگامی که دادههای خود
255
00:11:06,590 –> 00:11:08,990
را بهطور طبیعی مقیاسبندی میکنید، بهبود مییابد، این ایده واقعاً خوبی است
256
00:11:08,990 –> 00:11:12,08





![فیلم آموزشی: دستورات کنترل در پایتون - 17 [ادامه، شکستن، عبور] | پایتون برای مبتدیان | Simplile Learn](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/gkV14SRCD-4image2.jpg)

![فیلم آموزشی: مقدمه ای بر پایتون برای توسعه دهندگان PL/SQL [بخش اول]](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/WoAVY7LQbt4image2.jpg)