در این مطلب، ویدئو فصل نهم: آنالایزر | Elasticsearch در پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:10:21
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:00,060 –> 00:00:02,310
سلام همگی به نهمین ویدیو
2
00:00:02,310 –> 00:00:04,110
از شش شهر آخر زمین خوش آمدید در این
3
00:00:04,110 –> 00:00:05,400
ویدیو قصد داریم در مورد
4
00:00:05,400 –> 00:00:07,770
آنالایزر صحبت کنیم، در نظرات درخواست شده است که در
5
00:00:07,770 –> 00:00:09,150
مورد آن ویدیو بسازید و
6
00:00:09,150 –> 00:00:11,460
به درستی این کار را انجام دهید زیرا
7
00:00:11,460 –> 00:00:13,849
آنالیزورها نقش اساسی در بازیابی های شما
8
00:00:13,849 –> 00:00:16,529
قبل از این دارند. بررسی نحوه عملکرد تحلیلگر
9
00:00:16,529 –> 00:00:18,619
، مهم است که بدانیم آنالیزور چیست،
10
00:00:18,619 –> 00:00:21,449
آنالیزورها مجموعه ای از تنظیمات
11
00:00:21,449 –> 00:00:24,119
هستند که برای تبدیل جریان ورودی
12
00:00:24,119 –> 00:00:27,029
متن استفاده می شوند، بنابراین هر تحلیلگر دارای یک
13
00:00:27,029 –> 00:00:29,670
عملکرد خاص یا
14
00:00:29,670 –> 00:00:31,619
ویژگی های خاصی است که بر اساس آن
15
00:00:31,619 –> 00:00:34,559
متن ورودی اکنون تغییر می کند.
16
00:00:34,559 –> 00:00:36,450
وقتی میگویم متن ورودی
17
00:00:36,450 –> 00:00:39,510
میتواند در زمان نمایهسازی و همچنین
18
00:00:39,510 –> 00:00:42,180
در طول زمان پرس و جو وجود داشته باشد و اگر
19
00:00:42,180 –> 00:00:45,120
نباید تحلیلگرها را با نقشهبرداری اشتباه بگیریم، بنابراین
20
00:00:45,120 –> 00:00:46,680
نگاشتها طرحی هستند، تعریف
21
00:00:46,680 –> 00:00:49,680
دادهها و تحلیلگر به ما بگویید چگونه
22
00:00:49,680 –> 00:00:51,390
جریان ورودی داده را ذخیره کنیم.
23
00:00:51,390 –> 00:00:55,050
دو چیز متفاوت وجود دارد و elasticsearch
24
00:00:55,050 –> 00:00:56,820
چندین نوع آنالایزر را در اختیار ما قرار می دهد که
25
00:00:56,820 –> 00:00:58,920
تحلیلگر پیش فرض
26
00:00:58,920 –> 00:01:01,050
استاندارد است، بنابراین اگر ما به
27
00:01:01,050 –> 00:01:03,180
جستجوی لاستیک نگویید که از کدام آنالایزر استفاده کند،
28
00:01:03,180 –> 00:01:05,549
سپس به طور پیشفرض آنالایزر استاندارد شما را مورد استفاده قرار میدهد،
29
00:01:05,549 –> 00:01:08,490
بنابراین بیایید به هر کدام از آنها
30
00:01:08,490 –> 00:01:10,590
31
00:01:10,590 –> 00:01:12,780
32
00:01:12,780 –> 00:01:16,140
33
00:01:16,140 –> 00:01:18,270
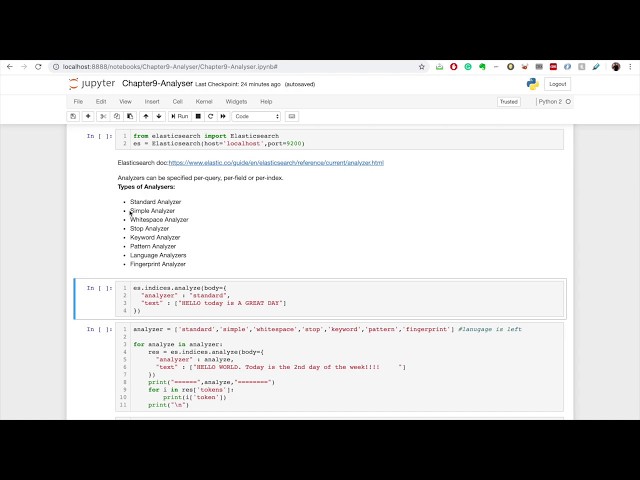
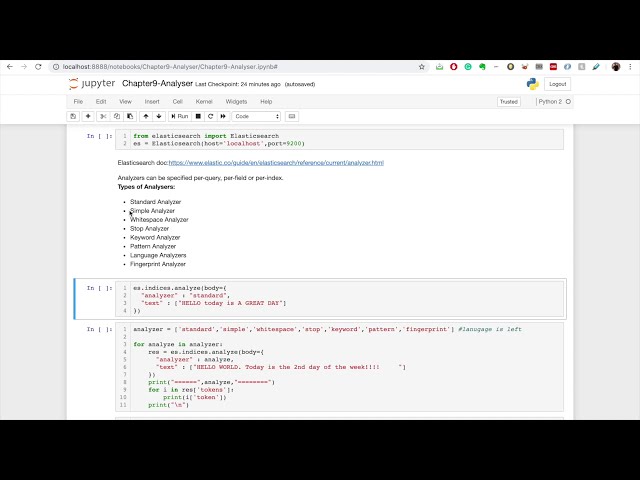
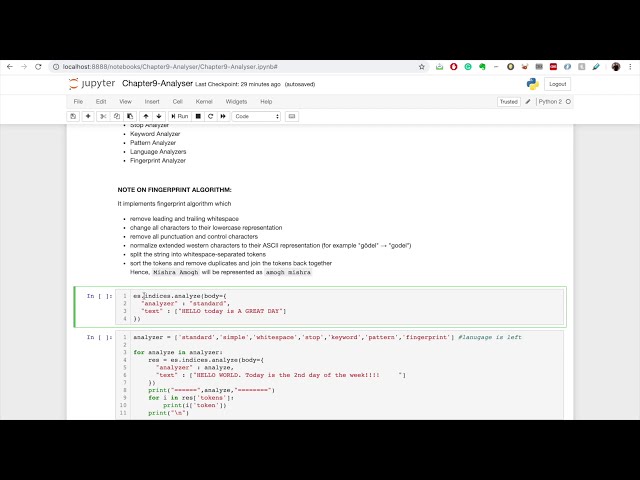
بپردازیم، بنابراین تحلیلگر استاندارد، همانطور که اشاره کردم، یک تحلیلگر پیشفرض است همانطور که اشاره کردم، علامتهای نقطهگذاری را حذف میکند و همچنین کلمات را متوقف میکند و ما نیز میتوانیم ارائه دهیم. آرایه ای
34
00:01:18,270 –> 00:01:20,189
از کلمات توقف که باید حذف شوند به
35
00:01:20,189 –> 00:01:23,640
همراه چهار ویژگی پیش فرض
36
00:01:23,640 –> 00:01:27,299
که دریافت می کنیم، تحلیلگر ساده است،
37
00:01:27,299 –> 00:01:29,820
وقتی
38
00:01:29,820 –> 00:01:31,439
با کاراکتری مواجه می شود که یک حرف نیست، متن را به عبارت تقسیم می کند
39
00:01:31,439 –> 00:01:33,600
و همچنین
40
00:01:33,600 –> 00:01:36,450
تمام عبارت ها را کوچک می کند و سپس تحلیلگر فضای خالی است.
41
00:01:36,450 –> 00:01:39,900
هر زمان که
42
00:01:39,900 –> 00:01:42,079
با کاراکتر فضای خالی مواجه شود،
43
00:01:42,079 –> 00:01:44,670
آنالیزگر بسیار ساده و استاندارد، عبارات را تقسیم می کند، هر دوی
44
00:01:44,670 –> 00:01:46,560
آنها عبارت ها را به حروف کوچک تغییر می دهند،
45
00:01:46,560 –> 00:01:49,049
در حالی که تحلیلگر فضای خالی این کار را انجام نمی دهد
46
00:01:49,049 –> 00:01:53,189
، بنابراین حرکت به جلو برای متوقف
47
00:01:53,189 –> 00:01:55,470
کردن تحلیلگر متوقف می شود، کاراکتر کلمات توقف را
48
00:01:55,470 –> 00:01:58,259
که یک حرف نیست حذف می کند و همه
49
00:01:58,259 –> 00:02:02,070
عبارت ها را کوچک می کند. تحلیلگر کلمات کلیدی
50
00:02:02,070 –> 00:02:05,250
تمام متن را همانطور که هست نگه میدارد و
51
00:02:05,250 –> 00:02:07,560
کاملاً روی آن مطابقت دارد، بنابراین هیچ
52
00:02:07,560 –> 00:02:09,419
تغییری در t رخ نخواهد داد. تحلیلگر کلمات کلیدی
53
00:02:09,419 –> 00:02:11,008
که در
54
00:02:11,008 –> 00:02:13,120
مثال زیر نیز مشاهده
55
00:02:13,120 –> 00:02:15,700
خواهیم کرد، تحلیلگر الگوی تحلیلگر الگوی ما
56
00:02:15,700 –> 00:02:17,980
از عبارت منظم برای
57
00:02:17,980 –> 00:02:20,580
تقسیم متن به عبارات استفاده می کند و از
58
00:02:20,580 –> 00:02:24,850
حروف کوچک و کلمات
59
00:02:24,850 –> 00:02:28,420
پایانی پشتیبانی می کند.
60
00:02:28,420 –> 00:02:30,340
61
00:02:30,340 –> 00:02:32,680
پشتیبانی از زبان توسط جستجوی الاستیک ارائه میشود و
62
00:02:32,680 –> 00:02:35,680
میتوانیم حذف stemming و Stoppard را
63
00:02:35,680 –> 00:02:37,930
برای آن زبان خاص انجام دهیم،
64
00:02:37,930 –> 00:02:40,900
آخرین مورد آنالیزگر اثر انگشت است که در اینجا
65
00:02:40,900 –> 00:02:42,819
الگوریتم اثر انگشت را پیادهسازی میکند
66
00:02:42,819 –> 00:02:46,300
که فضاهای سفید پیشرو و انتهایی را حذف میکند و
67
00:02:46,300 –> 00:02:48,880
همه کاراکترها را به
68
00:02:48,880 –> 00:02:51,340
نمایش کوچک تغییر میدهد و تمام علائم نگارشی را حذف میکند.
69
00:02:51,340 –> 00:02:53,140
و Lo و کاراکترهای کنترل،
70
00:02:53,140 –> 00:02:56,860
کاراکترهای غربی گسترش یافته
71
00:02:56,860 –> 00:02:58,300
را به نمایش ASCII عادی می کند، به
72
00:02:58,300 –> 00:03:01,360
عنوان مثال در اینجا نشان داده شده است
73
00:03:01,360 –> 00:03:03,640
که رشته را به فاصله های سفید تقسیم می کند
74
00:03:03,640 –> 00:03:06,100
و شمشیرها نشانه حذف
75
00:03:06,100 –> 00:03:08,590
موارد تکراری هستند و همچنین پس از آن دوباره توکن را
76
00:03:08,590 –> 00:03:12,400
به یکدیگر متصل می کند، بنابراین اگر رشته
77
00:03:12,400 –> 00:03:14,470
میشنا در میان آن باشد، نشان داده می شود.
78
00:03:14,470 –> 00:03:18,250
در میان اندازه گیری خوب بنابراین الگوریتم اثر انگشت
79
00:03:18,250 –> 00:03:22,720
w یک نمایش منحصر به فرد
80
00:03:22,720 –> 00:03:25,360
از متن ارسال شده به آن ایجاد خواهد کرد و
81
00:03:25,360 –> 00:03:27,790
به همین دلیل نام آن اثر انگشت است، بنابراین
82
00:03:27,790 –> 00:03:31,239
اگر می خواهید نحوه عملکرد آنالیزور
83
00:03:31,239 –> 00:03:34,269
را آزمایش کنید، باید یک تابع را با شاخص های
84
00:03:34,269 –> 00:03:36,850
نقطه ای فراخوانی کنیم و در بدنه
85
00:03:36,850 –> 00:03:38,860
نوع تحلیلگر مورد نظر خود را ارائه دهیم. برای استفاده و
86
00:03:38,860 –> 00:03:41,920
ما متن را بهعنوان آرایهای از تمام فنرها ارائه میکنیم،
87
00:03:41,920 –> 00:03:44,109
بنابراین این یک تحلیلگر استاندارد است
88
00:03:44,109 –> 00:03:47,859
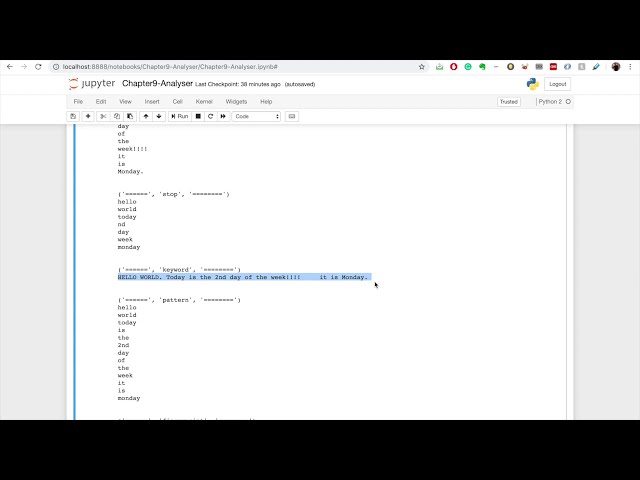
و بیایید ببینیم چگونه جستجوی کلاسیک
89
00:03:47,859 –> 00:03:51,299
تجزیه و تحلیل انجام شده را روی یک جریان متن ذخیره میکند،
90
00:03:51,299 –> 00:03:58,680
بنابراین پاسخ JSON را نگه میدارد که
91
00:03:58,680 –> 00:04:01,870
حاوی مقدار آفست شروع
92
00:04:01,870 –> 00:04:04,690
آفست است. در پایان آفست پس
93
00:04:04,690 –> 00:04:07,329
موقعیت
94
00:04:07,329 –> 00:04:11,170
کلمه چیست که موقعیت کلمه چیست این آفست شروع
95
00:04:11,170 –> 00:04:13,209
به عنوان موقعیت کاراکتر شروع و
96
00:04:13,209 –> 00:04:14,410
موقعیت کاراکتر پایانی
97
00:04:14,410 –> 00:04:17,769
نشانه چیست و نوع نشانه چیست
98
00:04:17,769 –> 00:04:19,690
بنابراین در حال حاضر همه آنها
99
00:04:19,690 –> 00:04:22,479
به صورت آلفا نگه داشته شده اند و اگر
100
00:04:22,479 –> 00:04:25,150
استاندارد تبدیل را مشاهده کردید، آنالیزور استاندارد می تواند
101
00:04:25,150 –> 00:04:26,800
102
00:04:26,800 –> 00:04:28,720
کاراکترهای حروف کوچک ما را به حروف کوچک تبدیل کند، بنابراین
103
00:04:28,720 –> 00:04:32,789
hello ما به hello کوچک تبدیل می شود و
104
00:04:32,789 –> 00:04:37,810
به طور مشابه اگر آن da را ببینید y من ایجاد کردم
105
00:04:37,810 –> 00:04:43,000
و همه آنها با حروف کوچک گرفتند، بنابراین
106
00:04:43,000 –> 00:04:45,539
این یک نمایش Bose از نحوه
107
00:04:45,539 –> 00:04:49,060
تجزیه و تحلیل تحلیلگر است، بنابراین در اینجا می بینیم که
108
00:04:49,060 –> 00:04:50,860
تجزی