در این مطلب، ویدئو پروژه علم داده پایتون 2 | پیشبینی سریهای زمانی در تبدیل دادههای پایتون – آبیشک آگاروال با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:42:13
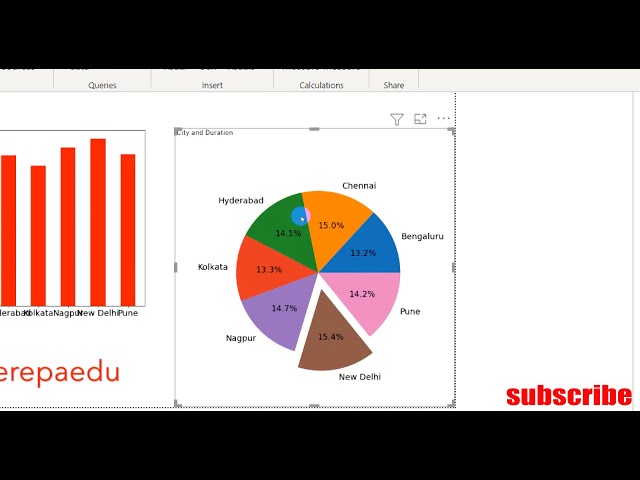
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,120 –> 00:00:02,550
شما در حین کار با پروژه علم داده خود با این مشکل مواجه
2
00:00:02,550 –> 00:00:04,859
می
3
00:00:04,859 –> 00:00:07,529
شوید که حتی پس از
4
00:00:07,529 –> 00:00:09,660
اعمال الگوریتم مناسب و
5
00:00:09,660 –> 00:00:11,759
پارامترهای مناسب در الگوریتم
6
00:00:11,759 –> 00:00:15,210
به نتایج مطلوب نمی رسید، این یک کار روزمره یا یک
7
00:00:15,210 –> 00:00:18,090
سناریوی روزمره دانشمندان داده است
8
00:00:18,090 –> 00:00:19,650
که شما نتیجه را دریافت نمی کنید.
9
00:00:19,650 –> 00:00:21,539
نتایج دلخواه شما الگوریتم درست را به خوبی اعمال نمی کنید
10
00:00:21,539 –> 00:00:24,420
در این ویدیو
11
00:00:24,420 –> 00:00:26,640
چند تکنیک تبدیل داده را به شما نشان می دهم
12
00:00:26,640 –> 00:00:29,580
که می توانید
13
00:00:29,580 –> 00:00:32,040
قبل از ارائه داده ها به
14
00:00:32,040 –> 00:00:34,559
الگوریتم روی الگوریتم های خود اعمال کنید و ببینید که آیا این به
15
00:00:34,559 –> 00:00:37,380
عنوان بخشی از هر علم داده تفاوتی ایجاد می کند یا خیر.
16
00:00:37,380 –> 00:00:40,230
وظیفه یک
17
00:00:40,230 –> 00:00:42,690
دانشمند داده است که به آزمایش
18
00:00:42,690 –> 00:00:44,340
با داده ها و الگوریتم ادامه دهد تا زمانی
19
00:00:44,340 –> 00:00:46,770
که به نتایج مورد نظر یا مورد قبول
20
00:00:46,770 –> 00:00:49,260
دست یابید و این
21
00:00:49,260 –> 00:00:51,120
تکنیک های تبدیل داده که در این ویدیو به شما آموزش خواهم داد
22
00:00:51,120 –> 00:00:54,410
بخشی از آن آزمایش است
23
00:00:54,410 –> 00:00:58,460
زیرا برخی الگوریتمها دادههای تبدیلشده را میگیرند
24
00:00:58,460 –> 00:01:02,460
یا
25
00:01:02,460 –> 00:01:05,040
دادههای تبدیلشده را به روشی بسیار بهتر از
26
00:01:05,040 –> 00:01:08,700
حالت عادی یا اصلی میپذیرند. داده های ملی بنابراین این
27
00:01:08,700 –> 00:01:10,619
تکنیک های تبدیل داده که من
28
00:01:10,619 –> 00:01:13,799
به شما نشان خواهم داد به خوبی به شما کمک می کند تا
29
00:01:13,799 –> 00:01:15,720
با داده های خود آزمایش کنید و
30
00:01:15,720 –> 00:01:18,810
نتایج مورد نظر خود را از
31
00:01:18,810 –> 00:01:21,479
پروژه خود یا از پروژه علم داده خود
32
00:01:21,479 –> 00:01:23,520
که در دست دارید به دست
33
00:01:23,520 –> 00:01:25,590
آورید، پس بیایید جلو برویم و دریافت کنیم خیلی خوب شروع شد،
34
00:01:25,590 –> 00:01:29,070
بنابراین در اینجا ما برای
35
00:01:29,070 –> 00:01:31,920
پروژه پروژه یک چیزی است که
36
00:01:31,920 –> 00:01:35,579
قبلا آن را آپلود کردم تا
37
00:01:35,579 –> 00:01:38,220
در همان نوت بوک وجود داشته باشد، من آن را
38
00:01:38,220 –> 00:01:40,799
در همان نوت بوک نگه می دارم تا نیازی
39
00:01:40,799 –> 00:01:44,579
به درخواست دسترسی و همچنین درخواست دسترسی نداشته باشید.
40
00:01:44,579 –> 00:01:47,340
یک پیوند جدید را همه با هم دنبال کنید و برای من
41
00:01:47,340 –> 00:01:49,799
نیز حفظ کل کد فقط در یک
42
00:01:49,799 –> 00:01:53,520
کتاب کار بسیار آسان است
43
00:01:53,520 –> 00:01:56,390
و برای شما هم همینطور است، بنابراین کاری که من انجام خواهم داد این است
44
00:01:56,390 –> 00:02:01,280
که پیوند این
45
00:02:01,280 –> 00:02:05,549
دفترچه یادداشت را در توضیحات و شما قرار می دهم.
46
00:02:05,549 –> 00:02:07,469
می توانید آن را از آنجا دانلود کنید در صورتی که
47
00:02:07,469 –> 00:02:09,179
می خواهید از آن برای مرجع خود استفاده کنید
48
00:02:09,179 –> 00:02:12,750
و همچنین این پیوند را دارد، بنابراین اگر
49
00:02:12,750 –> 00:02:13,830
قبلاً به مجموعه داده
50
00:02:13,830 –> 00:02:16,710
دسترسی دارید، مجبور نیستید دوباره آن را درخواست
51
00:02:16,710 –> 00:02:18,570
کنید، بنابراین بیایید ابتدا پیش برویم و شروع کنیم
52
00:02:18,570 –> 00:02:21,030
o همه وارد کردن کتابخانهها
53
00:02:21,030 –> 00:02:23,610
به این دلیل است که ما با هستههای کاملاً جدید شروع میکنیم،
54
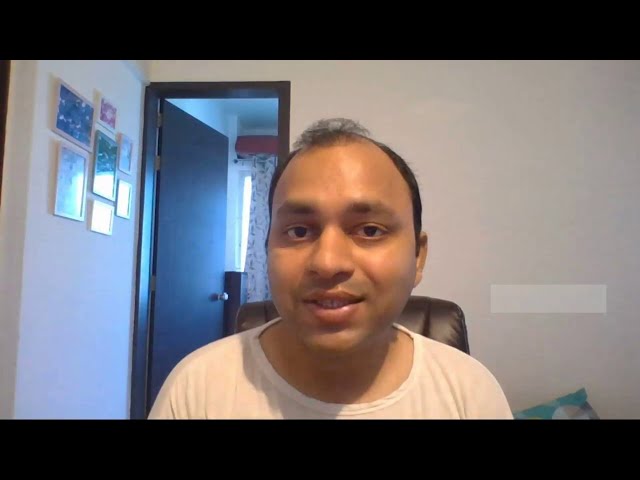
00:02:23,610 –> 00:02:27,290
بنابراین پانداها را SPT
55
00:02:27,290 –> 00:02:35,520
وارد میکنیم و مقدار لوله نقطهای matplotlib را بهعنوان PLT وارد میکنیم
56
00:02:35,520 –> 00:02:41,010
و درصد آزمایشگاه من پلات را در خط فقط
57
00:02:41,010 –> 00:02:44,220
کتابخانههای اولیه برای
58
00:02:44,220 –> 00:02:47,790
دستکاری دادهها تجسم دادهها و برای
59
00:02:47,790 –> 00:02:51,420
چاپ نمودارهای درون خطوط.
60
00:02:51,420 –> 00:02:56,280
همه بعد از سلول خوب است اولین کار
61
00:02:56,280 –> 00:02:59,250
دریافت داده است، بنابراین برای بدست آوردن داده،
62
00:02:59,250 –> 00:03:02,430
من فقط سریع بالا می روم این را کپی می کنم
63
00:03:02,430 –> 00:03:10,200
زیرا این همان چیزی است که من می خواهم و بیایم
64
00:03:10,200 –> 00:03:13,670
اینجا آن را بچسبانیم که می گوییم
65
00:03:13,670 –> 00:03:15,960
طبقه ما در حال ایجاد این شی با
66
00:03:15,960 –> 00:03:18,630
خواندن فایل خواندن نقطه CSV روزانه
67
00:03:18,630 –> 00:03:21,750
کل تولد ایمیل در کالیفرنیا
68
00:03:21,750 –> 00:03:23,880
میخواهیم ستون اول ایندکس شود که
69
00:03:23,880 –> 00:03:27,600
تاریخ است و میخواهیم تاریخ را تجزیه کنیم تا
70
00:03:27,600 –> 00:03:30,930
پایتون بتواند یک بار دادههای
71
00:03:30,930 –> 00:03:33,300
درون این شی را بداند که ستون اول
72
00:03:33,300 –> 00:03:35,880
حاوی تاریخ است بنابراین صفر نشان دهنده
73
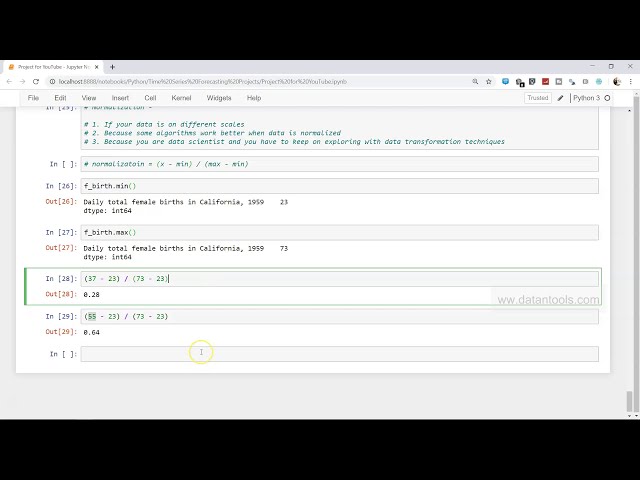
00:03:35,880 –> 00:03:38,670
شماره فهرست یا شماره ستونی که
74
00:03:38,670 –> 00:03:40,380
از صفر شروع می شود نشان دهنده
75
00:03:40,380 –> 00:03:42,510
ستون اول یک نشان دهنده ستون دوم است بنابراین
76
00:03:42,510 –> 00:03:45,800
ایندکس سازی از صفر در پایتون شروع می شود
77
00:03:45,800 –> 00:03:50,400
بنابراین اگر این را اجرا کنید quic k
78
00:03:50,400 –> 00:03:53,130
همانطور که قبلا انجام دادیم، اوه
79
00:03:53,130 –> 00:03:56,630
اگر من همیشه این اشتباه را انجام میدهم، بررسی کنید، اما
80
00:03:56,630 –> 00:04:01,170
امیدوارم بتوانید آن را ترک کنید، بنابراین این
81
00:04:01,170 –> 00:04:03,780
دادههایی است که به دست آوردهایم، این اولین
82
00:04:03,780 –> 00:04:07,050
ستون شاخص ستون است، این
83
00:04:07,050 –> 00:04:10,830
تعداد تولد زنان در کالیفرنیا هر
84
00:04:10,830 –> 00:04:15,660
روز است، بنابراین اول ژانویه 1959 35 تولد
85
00:04:15,660 –> 00:04:20,250
در دوم ژانویه 30 برای از بین بردن کودک متولد شده در
86
00:04:20,250 –> 00:04:23,970
30 و 4 و غیره و غیره
87
00:04:23,970 –> 00:04:27,550
بسیار خوب است یک مسئله که قبلاً
88
00:04:27,550 –> 00:04:32,789
با این داده ها دیدیم فکر کنید اگر بگویم
89
00:04:32,789 –> 00:04:35,919
دم این خط را در مجموعه داده شما دارد
90
00:04:35,919 –> 00:04:38,470
که چیزی نیست. اما نشان می دهد که
91
00:04:38,470 –> 00:04:40,360
این یک نام فایل است و امسال است
92
00:04:40,360 –> 00:04:43,810
که باید آن را حذف کنیم زیرا این می
93
00:04:43,810 –> 00:04:48,490
تواند مشکلاتی ایجاد کند و برای انجام این کار ما T
94
00:04:48,490 –> 00:04:56,099
H برابر است با 2f زیرخط اما از 0 تا 365
95
00:04:56,099 –> 00:05:03,490
بنابراین اگر دیدید این داده 365 یا داده 365 است.
96
00:05:03,490 –> 00:05:06,250
تنظیم کنید زیرا از
97
00:05:06,250 –> 00:05:11,889
0 1 ژانویه 1959 شروع می شود و تا 31 دسامبر 1959 شروع می شود
98
00:05:11,889 –> 00:05:16,120
و این ردیف است و همانطور
99
00:05:16,120 –> 00:05:18,250
که می دانید نمایه سازی از 0 شروع می شود
100
00:05:18,250 –> 00:05:21,580
بنابراین اساساً 0 بالا می رود تا
101
00:05:21,580 –> 00:05:26,830
این 364 و این 365 است اما در شاخص
102
00:05:26,830 –> 00:05:30,550
ما ما هستیم گرفتن 0 تا 365 چرا این است
103
00:05:30,550 –> 00:05:33,240
که شاید یک i سوال مصاحبه مبنی بر
104
00:05:33,240 –> 00:05:37,360
اینکه چرا حتی آخرین سطر
105
00:05:37,360 –> 00:05:41,740
را در مجموعه داده انتخاب می کنید و در مستندات پایتون چه کاری به خوبی انجام می دهد
106
00:05:41,740 –> 00:05:46,900
،
107
00:05:46,900 –> 00:05:50,259
آخرین سطر یا آخرین شماره شاخصی
108
00:05:50,259 –> 00:05:54,009
که مشخص می کنید منحصر به فرد است، حساب نمی شود
109
00:05:54,009 –> 00:05:56,710
و به همین دلیل خواهد بود.
110
00:05:56,710 –> 00:05:59,529
قرار نیست این ردیف خاص را
111
00:05:59,529 –> 00:06:03,099
که ردیف 365 است انتخاب کنم زیرا Rho
112
00:06:03,099 –> 00:06:07,930
از 0 تا 360 شروع می شود زیرا یک
113
00:06:07,930 –> 00:06:09,789
مجموعه داده 365 است و از آنجایی که 0 را شامل
114
00:06:09,789 –> 00:06:13,509
می شود به 365 تبدیل می شود و این 366 است اما
115
00:06:13,509 –> 00:06:16,949
شماره شاخص 365 است بنابراین باید حذف کنیم. که
116
00:06:16,949 –> 00:06:23,009
اگر من این کار را انجام دهم و اکنون قسمت دم را ببینم،
117
00:06:23,009 –> 00:06:26,710
نباید این حق را داشته باشیم، بنابراین امیدوارم
118
00:06:26,710 –> 00:06:28,810
اکنون متوجه شده باشید که چرا این کار را انجام می
119
00:06:28,810 –> 00:06:33,250
دهیم، آخرین عدد در پایتون انحصاری است
120
00:06:33,250 –> 00:06:35,589
در این فهرست، آن را خوب حساب نمی
121
00:06:35,589 –> 00:06:40,710
کند، بنابراین حالا بیایید برویم قبل از
122
00:06:40,710 –> 00:06:43,330
انجام تبدیل داده ها برای انجام
123
00:06:43,330 –> 00:06:45,670
تبدیل داده ها اولین
124
00:06:45,670 –> 00:06:49,180
تکنیکی که ما داریم نرمال سازی است
125
00:06:49,180 –> 00:06:54,640
بنابراین نرمال سازی اساساً در
126
00:06:54,640 –> 00:06:58,150
دو
127
00:06:58,150 –> 00:07:00,340
128
00:07:00,340 –> 00:07:05,380
مورد مفید است. یکی اگر
129
00:07:05,380 –> 00:07:12,130
دادههای شما در مقیاسهای مختلف درست است، به
130
00:07:12,130 –> 00:07:16,480
عنوان مثال شما دادهها را برای
131
00:07:16,480 –> 00:07:18,730
قدهای مختلف افراد دریافت میکنید،
132
00:07:18,730 –> 00:07:20,950
احتمالاً در این مورد فرض کنید زنانه،
133
00:07:20,950 –> 00:07:24,310
بنابراین آنچه ممکن است اتفاق بیفتد این است که برخی از
134
00:07:24,310 –> 00:07:25,990
افراد ممکن است ارتفاع را
135
00:07:25,990 –> 00:07:29,140
در چند سانتیمتر ثبت کنند، ممکن است
136
00:07:29,140 –> 00:07:31,450
افرادی باشند که ممکن است آن را در متر ضبط کند،
137
00:07:31,450 –> 00:07:33,580
بنابراین اگر دادههای شما در
138
00:07:33,580 –> 00:07:35,920
مقیاسهای مختلف هستند، به طور کلی مقدار متفاوتی خواهند داشت،
139
00:07:35,920 –> 00:07:37,900
بنابراین ممکن است بخواهید
140
00:07:37,900 –> 00:07:39,880
هر نقطه داده را در همان مقیاس به
141
00:07:39,880 –> 00:07:43,930
روش دیگری بیاورید یا
142
00:07:43,930 –> 00:07:46,990
دلیل دیگری برای انجام این کار وجود دارد.
143
00:07:46,990 –> 00:07:49,540
برخی از الگوریتمها مانند
144
00:07:49,540 –> 00:07:51,430
رگرسیون لجستیک رگرسیون خطی و
145
00:07:51,430 –> 00:07:54,100
چند الگوریتم دیگر هستند که اساساً
146
00:07:54,100 –> 00:07:58,090
وقتی دادههای شما نرمال میشوند به خوبی کار میکنند، وقتی میگوییم
147
00:07:58,090 –> 00:08:01,240
نرمالسازی شده است، به این
148
00:08:01,240 –> 00:08:04,450
معنی که نوسانات بالایی که به معنی
149
00:08:04,450 –> 00:08:07,510
نقاط پایین و بالا پایینبودن زیاد است و
150
00:08:07,510 –> 00:08:10,000
به نوعی نرمال میشوند، کار میکنند. که
151
00:08:10,000 –> 00:08:12,820
نشان دهنده یک ساختار سازگار مناسب است
152
00:08:12,820 –> 00:08:15,010
و هنگامی که ما نرمال سازی را انجام می دهیم،
153
00:08:15,010 –> 00:08:17,260
داده ها همیشه در محدوده
154
00:08:17,260 –> 00:08:19,630
0 و 1 خواهند بود و شما آن را خواهید دید. در عرض
155
00:08:19,630 –> 00:08:25,380
چند دقیقه خوب است زیرا
156
00:08:25,380 –> 00:08:32,250
الگوریتمها زمانی که دادهها عادی میشوند بهتر کار میکنند
157
00:08:32,250 –> 00:08:35,679
دلیل سوم من فقط به عنوان
158
00:08:35,679 –> 00:08:40,770
بخشی از سرگرمی میگویم زیرا شما
159
00:08:40,770 –> 00:08:47,250
دانشمند داده هستید و باید
160
00:08:47,250 –> 00:08:52,140
با تکنیکهای تبدیل دادهها به کاوش
161
00:08:52,140 –> 00:08:53,860
162
00:08:53,860 –> 00:08:55,510
ادامه دهید، فکر میکنم این
163
00:08:55,510 –> 00:08:58,209
کافی است. دلیل ex برای عادی سازی
164
00:08:58,209 –> 00:09:00,820
داده های ما به عنوان بخشی از تبدیل داده است،
165
00:09:00,820 –> 00:09:04,930
بنابراین فرمول نرمال سازی این است، بنابراین
166
00:09:04,930 –> 00:09:10,050
فرض کنید نرمال سازی برابر است با 2x منهای
167
00:09:10,050 –> 00:09:17,110
حداقل تقسیم بر حداکثر منهای حداقل،
168
00:09:17,110 –> 00:09:20,100
بنابراین این فرمول ما برای عادی سازی است
169
00:09:20,100 –> 00:09:22,839
شما می توانید حتی تابع خود را ایجاد کنید،
170
00:09:22,839 –> 00:09:26,800
اما این I می تواند یاد بگیرد که
171
00:09:26,800 –> 00:09:29,170
روشی برای انجام عادی سازی
172
00:09:29,170 –> 00:09:32,410
بدون ایجاد هیچ فرمی دارد، بنابراین
173
00:09:32,410 –> 00:09:34,029
کاری که انجام می دهد اساساً این است
174
00:09:34,029 –> 00:09:35,829
که مقداری را که شما می دهید انتخاب می کند بنابراین
175
00:09:35,829 –> 00:09:40,029
مقدار مجموعه داده مانند 37 52 48 این
176
00:09:40,029 –> 00:09:42,040
چیزی نیست جز مقدار x به جز از این
177
00:09:42,040 –> 00:09:44,829
مجموعه داده یک مقدار حداقل
178
00:09:44,829 –> 00:09:48,550
و یک مقدار حداکثر خواهد داشت، به عنوان مثال f
179
00:09:48,550 –> 00:09:55,329
زیر خط تولد نقطه حداقل است، بنابراین حداقل
180
00:09:55,329 –> 00:09:59,500
مقدار 23 است که به معنای حداقل یا در یک
181
00:09:59,500 –> 00:10:02,430
معین است. در یک روز معین، 23
182
00:10:02,430 –> 00:10:04,870
فرزند دختر به دنیا میآیند و
183
00:10:04,870 –> 00:10:07,360
این کمترین مقدار در یک روز معین در
184
00:10:07,360 –> 00:10:10,990
مدت 365 روز است، به طور مشابه F
185
00:10:10,990 –> 00:10:15,220
186
00:10:15,220 –> 00:10:19,540
نشان میدهد که شما 73 فرزند داشتهاید به عنوان حداکثر
187
00:10:19,540 –> 00:10:21,910
تعداد تولد نوزاد در
188
00:10:21,910 –> 00:10:24,810
یک زمان معین. یک روز در بازه زمانی 1
189
00:10:24,810 –> 00:10:30,399
ژانویه 1959 تا 31 دسامبر 1959، بنابراین
190
00:10:30,399 –> 00:10:32,190
اکنون میدانید که در حال حاضر عمل میکند و میدانید به
191
00:10:32,190 –> 00:10:35,260
درستی حداکثر حداقل و x تمام این چیزهایی
192
00:10:35,260 –> 00:10:38,440
که میدانید، بنابراین بیایید سعی کنیم 37 را متناسب کنیم و
193
00:10:38,440 –> 00:10:41,740
ببینیم چه خروجی به دست میآوریم تا
194
00:10:41,740 –> 00:10:45,180
در این حالت در یک براکت 37 منهای
195
00:10:45,180 –> 00:10:53,699
حداقل که 23 تقسیم بر 73 منهای
196
00:10:53,699 –> 00:10:57,779
23 است و اگر این را اجرا کنیم 0.28 می شود
197
00:10:57,779 –> 00:11:02,440
بنابراین مقدار 37 شما
198
00:11:02,440 –> 00:11:06,940
از 37 تبدیل می شود تا به آن اشاره کنم همانطور که
199
00:11:06,940 –> 00:11:10,000
گفتم همیشه در محدوده 0 خواهد بود.
200
00:11:10,000 –> 00:11:10,810
و 1
201
00:11:10,810 –> 00:11:13,830
به طور مشابه می توانیم 55 را مثال بزنیم و
202
00:11:13,830 –> 00:11:19,890
اتفاقی که می افتد 55 منهای 23 تقسیم بر
203
00:11:19,890 –> 00:11:27,310
73 منهای 23 است و نقطه 6 4 درست است، بنابراین
204
00:11:27,310 –> 00:11:30,520
همانطور که می توانید الگوریتم را ببینید وقتی
205
00:11:30,520 –> 00:11:32,560
پخت می شود،
206
00:11:32,560 –> 00:11:36,460
وقتی به 37 و 55 می رسد، تغییرات زیادی وجود دارد. همانطور که با 28
207
00:11:36,460 –> 00:11:39,460
و 64 مقایسه می شود، همه v شما آلیو در
208
00:11:39,460 –> 00:11:42,940
یک محدوده خوب که میتواند
209
00:11:42,940 –> 00:11:46,450
بسیاری از فراز و نشیبها را حذف کند و بالا و
210
00:11:46,450 –> 00:11:49,300
پایینهای مجموعه داده را میدانید و کار میکند،
211
00:11:49,300 –> 00:11:51,910
ممکن است سعی کند نتایج بهتری به شما بدهد،
212
00:11:51,910 –> 00:11:54,430
بنابراین این همان چیزی است که ما
213
00:11:54,430 –> 00:11:56,980
در پشت سر خواهیم داشت. زمانی که شما این الگوریتم را اعمال می کنید، به پایان
214
00:11:56,980 –> 00:12:00,040
215
00:12:00,040 –> 00:12:04,180
می رسیم، پس بیایید جلوتر برویم و ببینیم چگونه می توانیم این الگوریتم را اعمال کنیم، بنابراین از SK Learn
216
00:12:04,180 –> 00:12:13,000
dot pre-processing import min max
217
00:12:13,000 –> 00:12:16,210
scaler، من فقط tab را فشار می
218
00:12:16,210 –> 00:12:19,870
دهم و خروجی را به من می دهد، بنابراین حداقل اسکالرهای حداکثر
219
00:12:19,870 –> 00:12:23,320
بر روی آرایه کار می کنند. داده ها، بنابراین آنچه که ما نیاز داریم این است که
220
00:12:23,320 –> 00:12:26,770
اساساً یک آرایه تولد در زیر
221
00:12:26,770 –> 00:12:29,650
ARR مدرسه ایجاد کنیم و اگر
222
00:12:29,650 –> 00:12:31,750
ویدیوی دیروز من را دنبال
223
00:12:31,750 –> 00:12:36,370
کرده باشید ساده است، به سادگی مانند قصری برای
224
00:12:36,370 –> 00:12:44,470
مقادیر نقطه پرث پرث است، بنابراین اگر در مورد
225
00:12:44,470 –> 00:12:49,330
خط زیر خط بگویم
226
00:12:49,330 –> 00:12:52,300
ستون ها به این شکل هستند. یا داده ها خوب به نظر می رسند،
227
00:12:52,300 –> 00:12:55,120
بنابراین حالا بیایید جلو برویم و یک
228
00:12:55,120 –> 00:12:59,620
اسکالر برابر با حداکثر اسکالر تعیین کنیم و
229
00:12:59,620 –> 00:13:02,680
باید محدوده ویژگی را مشخص کنیم که
230
00:13:02,680 –> 00:13:05,290
اساساً نشان می دهد که چه تعداد ویژگی می
231
00:13:05,290 –> 00:13:07,240
خواهید در
232
00:13:07,240 –> 00:13:09,400
هنگام تبدیل آن در این مورد در نظر بگیرید.
233
00:13:09,400 –> 00:13:13,270
فقط 0 و 1 فقط یک تاریخ و
234
00:13:13,270 –> 00:13:14,770
تعداد P آرایه ها را داشته باشید، بنابراین ما به جلو می رویم و
235
00:13:14,770 –> 00:13:16,420
این را اجرا می کنیم،
236
00:13:16,420 –> 00:13:19,920
بنابراین اکنون به جلو می رویم و آن
237
00:13:19,920 –> 00:13:27,579
را متناسب می کنیم.
238
00:13:27,579 –> 00:13:28,570
239
00:13:28,570 –> 00:13:31,120
240
00:13:31,120 –> 00:13:38,380
ما
241
00:13:38,380 –> 00:13:42,870
مقادیر درون این شی را داریم، بنابراین برای تشخیص
242
00:13:42,870 –> 00:13:46,860
اینکه آن مقادیر چه هستند، میتوانیم بگوییم
243
00:13:46,860 –> 00:13:50,260
اسکالر یا شاید در اینجا خودش
244
00:13:50,260 –> 00:13:54,940
نقطه اسکالار داده min، بنابراین
245
00:13:54,940 –> 00:13:57,940
حداقل مقدار را مشخص
246
00:13:57,940 –> 00:14:01,990
247
00:14:01,990 –> 00:14:07,180
کرده است. حتی اگر دادهها را
248
00:14:07,180 –> 00:14:09,450
ببینیم مانند بسیاری از روشهای مختلف،
249
00:14:09,450 –> 00:14:12,430
بنابراین روش بعدی که
250
00:14:12,430 –> 00:14:16,740
ما اعمال میکنیم، تبدیل زیرخط مناسب
251
00:14:16,970 –> 00:14:21,540
و ترانسفورماتور ترانسفورماتور است تا
252
00:14:21,540 –> 00:14:25,379
تبدیل نقطهای مقیاسکننده یا شاید کاری که
253
00:14:25,379 –> 00:14:29,370
من انجام خواهم داد این است که فقط این را نگه دارم.
254
00:14:29,370 –> 00:14:31,709
که شما می توانید آن را زودتر ارجاع دهید اجازه دهید بعداً
255
00:14:31,709 –> 00:14:36,300
و این را خواهید دید، بنابراین
256
00:14:36,300 –> 00:14:41,310
زیرخط تولد عادی برابر است با
257
00:14:41,310 –> 00:14:50,009
تبدیل دو نقطه اسکالر و آماده است، بنابراین اکنون
258
00:14:50,009 –> 00:14:53,160
تبدیل داده
259
00:14:53,160 –> 00:14:55,079
ترانس مقدار تبدیل شده تبدیل شده است.
260
00:14:55,079 –> 00:14:57,000
مقدار orm در
261
00:14:57,000 –> 00:14:59,490
زیر خط تولد نرمال سازی وجود دارد، بنابراین اگر
262
00:14:59,490 –> 00:15:02,069
می خواهید مقدار perc underscore
263
00:15:02,069 –> 00:15:06,379
non lies 0 را ببینید، این مقدار
264
00:15:06,379 –> 00:15:16,620
0.24 برای t35 سمت راست است و زیرخط تولد
265
00:15:16,620 –> 00:15:21,839
عادی سازی یک این را بنویسید و به همین ترتیب
266
00:15:21,839 –> 00:15:23,939
اگر می خواهید بیشتر چاپ کنید می توانید
267
00:15:23,939 –> 00:15:26,759
ذکر کنید. یک حلقه for برای I در فرض کنید
268
00:15:26,759 –> 00:15:32,790
پنج مقدار چاپ تولد پنج زیرخط
269
00:15:32,790 –> 00:15:35,899
من
270
00:15:37,080 –> 00:15:40,830
و مجری ها را عادی کنید و شما پنج مقدار اول را دریافت خواهید کرد
271
00:15:40,830 –> 00:15:44,550
بنابراین به این ترتیب می توانید
272
00:15:44,550 –> 00:15:47,910
مقادیر تبدیل شده را چاپ کنید و این
273
00:15:47,910 –> 00:15:50,550
داده ها پس
274
00:15:50,550 –> 00:15:52,769
از اتمام عادی سازی آن را چاپ کنید. آماده است تا
275
00:15:52,769 –> 00:15:55,500
همه موارد آماده را برای درج در
276
00:15:55,500 –> 00:15:59,570
الگوریتم انتخاب کند، بنابراین الگوریتمی که قبلاً به آن
277
00:15:59,570 –> 00:16:03,570
اشاره کردیم، الگوریتم ARIMA بود، بنابراین اگر
278
00:16:03,570 –> 00:16:07,079
من کمی
279
00:16:07,079 –> 00:16:11,070
از مدل آمار یا TSA به اینجا بروم، بله، این و
280
00:16:11,070 –> 00:16:13,200
این دو عبارت واردات هستند
281
00:16:13,200 –> 00:16:16,290
که باید انجام دهیم. از مدل اول
282
00:16:16,290 –> 00:16:19,230
بنابراین مدل stat را ذخیره کنید TSA را imam
283
00:16:19,230 –> 00:16:22,320
otto نقطهگذاری کنید و سپس مدل ARIMA را مشخص کنید
284
00:16:22,320 –> 00:16:25,560
و قبل از آن خوب است
285
00:16:25,560 –> 00:16:29,160
که دادهها را آموزش و تست کنید بنابراین ctrl a ctrl
286
00:16:29,160 –> 00:16:32,670
C فقط s را کپی و پیست میکنم. o که مجبور نیستم
287
00:16:32,670 –> 00:16:36,839
آن را ایجاد کنم، بنابراین F هر دو در اینجا
288
00:16:36,839 –> 00:16:40,589
و آنچه باید در این مورد انجام دهم این است که
289
00:16:40,589 –> 00:16:46,670
باید به درستی زیرخط تولد را ذکر
290
00:16:46,670 –> 00:16:50,490
کنم زیرا می خواهیم
291
00:16:50,490 –> 00:16:56,730
مقدار نرمال شده را بگیریم و اجرای
292
00:16:56,730 –> 00:17:00,149
سیستم به این صورت است. هر دو خط پایین خط قطار
293
00:17:00,149 –> 00:17:06,230
اندازه نقطه تولد زیر خط تست نقطه نقطه
294
00:17:06,230 –> 00:17:10,230
330 به اضافه 35 365 است، بنابراین ما کل
295
00:17:10,230 –> 00:17:15,030
داده ها را داریم و حالا من ادامه می دهم و از
296
00:17:15,030 –> 00:17:20,220
مدل های آماری، نقطه T دارای یک است و فکر می کنم این
297
00:17:20,220 –> 00:17:25,349
بود که من اشتباه نمی کنم این توپ ARIMA
298
00:17:25,349 –> 00:17:30,320
من فقط میخواستم از آن نقطه،
299
00:17:30,320 –> 00:17:38,429
مدل ARIMA را وارد کنید، ARIMA خوب است و
300
00:17:38,429 –> 00:17:41,100
سپس باید قرار دهیم که باید
301
00:17:41,100 –> 00:17:44,970
یک مدل ایجاد کنیم، اول از همه، ده
302
00:17:44,970 –> 00:17:50,200
مدل زیرخط Berghe برابر با هر EEMA است
303
00:17:50,200 –> 00:17:53,429
و با آن شما باید هر دو
304
00:17:53,429 –> 00:17:58,840
خط زیر خط، ترتیب کاما قطار برابر با
305
00:17:58,840 –> 00:18:02,860
اگر باشد. من اشتباه نمی کنم این برای یکی بود که دوست داشت
306
00:18:02,860 –> 00:18:07,389
بله
307
00:18:07,389 –> 00:18:11,409
2 1 3 را بررسی کند، بنابراین ما فکر می کنم 2 1 3 چیزی است
308
00:18:11,409 –> 00:18:13,600
که می توانیم بگیریم و سپس می توانیم
309
00:18:13,600 –> 00:18:17,200
با مقدار AIC مقایسه کنیم، بنابراین در آخرین ویدیو
310
00:18:17,200 –> 00:18:19,600
به مقدار کمتر اشاره کردم. از یک من می
311
00:18:19,600 –> 00:18:22,630
بینم مدل نبرد است بنابراین مدل تولد
312
00:18:22,630 –> 00:18:24,250
undersco re fate دستور بعدی است و
313
00:18:24,250 –> 00:18:26,919
سپس هوش مصنوعی ببیند ما به چه چیزی نیاز داریم، بنابراین اگر
314
00:18:26,919 –> 00:18:32,080
پایین بروید و این مدل زیرخط نوار را اجرا کنید
315
00:18:32,080 –> 00:18:36,010
و امتیاز واکشی برابر با
316
00:18:36,010 –> 00:18:41,380
مدل زیرخط تولد باشد خدا که
317
00:18:41,380 –> 00:18:43,530
318
00:18:44,810 –> 00:18:46,580
و فعلاً من فقط این هشدار
319
00:18:46,580 –> 00:18:49,330
تولد و مدرسه را نادیده خواهم گرفت. مدل dot fit dot
320
00:18:49,330 –> 00:18:53,060
AIC بنابراین بسیار پایین آمده است اگر می بینید
321
00:18:53,060 –> 00:18:57,890
به منفی 344 رفته است بنابراین
322
00:18:57,890 –> 00:19:03,620
قبلاً AIC داشتیم من بالا رفتم
323
00:19:03,620 –> 00:19:07,070
دو تا سه صفر بود اما بعد از
324
00:19:07,070 –> 00:19:09,800
تبدیل مقدار یک مقدار جدید گرفتیم.
325
00:19:09,800 –> 00:19:13,010
مقداری که منفی است، بنابراین ما باید
326
00:19:13,010 –> 00:19:15,830
واقعاً ببینیم که چگونه پیشبینیها
327
00:19:15,830 –> 00:19:17,900
به محض اعمال این مورد انجام میشوند، بنابراین
328
00:19:17,900 –> 00:19:19,820
این نیز در جهتی کاملاً متفاوت پیش میرود،
329
00:19:19,820 –> 00:19:23,660
اما ما هنوز باید ببینیم که چگونه
330
00:19:23,660 –> 00:19:24,710
331
00:19:24,710 –> 00:19:26,690
یک بازیگر وارد میشود تا این کار را انجام دهد.
332
00:19:26,690 –> 00:19:28,340
پیشبینی قبلاً در
333
00:19:28,340 –> 00:19:30,680
ویدیوی قبلی ذکر کردم ارزش شما
334
00:19:30,680 –> 00:19:32,600
باید چقدر باشد، بنابراین من فقط این قطعه را کپی میکنم
335
00:19:32,600 –> 00:19:38,150
و به اینجا میآیم تا واتان برویم
336
00:19:38,150 –> 00:19:40,430
پیشبینی مدل زیرخط تولد است که
337
00:19:40,430 –> 00:19:44,330
دیسکو بر روی شی یکسان است و
338
00:19:44,330 –> 00:19:47,630
مراحل هزینه آموزش داده میشود. 35 چون میدونی
339
00:19:47,630 –> 00:19:50,180
اندازه آزمون 35 است، بنابراین ما میتوانیم
340
00:19:50,180 –> 00:19:53,000
میانگین مربعات خطا را در آن حالت شناسایی کنیم، بنابراین
341
00:19:53,000 –> 00:19:56,720
این را اجرا میکنیم و زیرخط برای هزینه
342
00:19:56,720 –> 00:20:01,880
آن این است و اما تست زیرخط این است،
343
00:20:01,880 –> 00:20:05,480
بنابراین خواهید دید که این مقادیر بسیار
344
00:20:05,480 –> 00:20:08,000
بسیار سازگار هستند، مانند چهل شش
345
00:20:08,000 –> 00:20:10,550
نقطه چهار شش نقطه چهار شش
346
00:20:10,550 –> 00:20:13,310
تغییرات بعد از زمانی که
347
00:20:13,310 –> 00:20:17,450
نقطه اعشار سوم شروع می شود و
348
00:20:17,450 –> 00:20:21,710
اینجا بالاست کمی تغییر است
349
00:20:21,710 –> 00:20:25,700
مانند 0.2 0.4 بنابراین نگاه کردن با
350