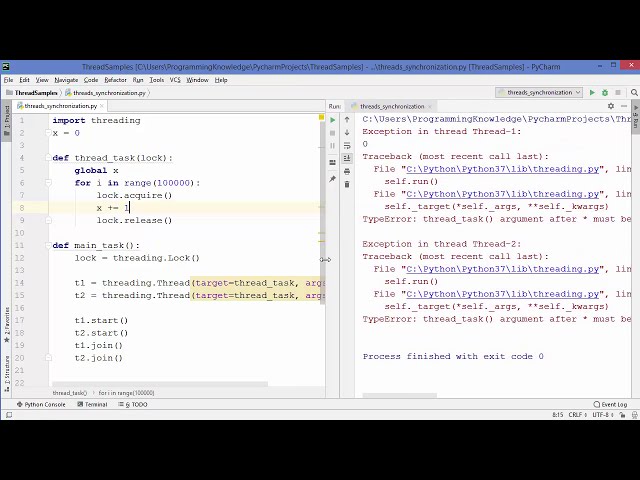
در این مطلب، ویدئو پیش بینی فروش ساده با استفاده از پایتون در Power BI با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:35:23
تصاویر این ویدئو:




قسمتی از زیرنویس این فیلم:
00:00:00,120 –> 00:00:02,399
سلام دوستان نام من چند پائولا است
2
00:00:02,399 –> 00:00:04,170
و من به عنوان مشاور مهندسی کسب و کار
3
00:00:04,170 –> 00:00:06,480
برای غیرفعال
4
00:00:06,480 –> 00:00:09,630
کار می کنم و بله با مایکروسافت bi stack
5
00:00:09,630 –> 00:00:12,120
light SQL Server خدمات یکپارچه سازی و
6
00:00:12,120 –> 00:00:15,260
تجزیه و تحلیل کار می کنم همچنین با
7
00:00:15,260 –> 00:00:18,930
پلت فرم ابری مایکروسافت برای راه حل bi
8
00:00:18,930 –> 00:00:21,779
مانند یک آشنا هستم مطمئناً کارخانه داده باید در
9
00:00:21,779 –> 00:00:22,289
10
00:00:22,289 –> 00:00:24,859
Brix تاریخ خانه و پایگاه داده را نشان
11
00:00:24,859 –> 00:00:28,199
دهم و همچنین امروز روی علم داده و
12
00:00:28,199 –> 00:00:30,689
یادگیری ماشین کار می کنم، می
13
00:00:30,689 –> 00:00:33,329
خواهم تجربیاتم را به خصوص در مورد
14
00:00:33,329 –> 00:00:37,500
مدل یادگیری ماشین با پایتون در
15
00:00:37,500 –> 00:00:39,360
آنجا به شما نشان دهم. چگونه می
16
00:00:39,360 –> 00:00:41,579
توان یادگیری ماشین را مدل یادگیری ماشینی ساده تر
17
00:00:41,579 –> 00:00:44,270
در power bi با استفاده از پایتون پیاده
18
00:00:44,270 –> 00:00:50,809
سازی کرد که امروز این پیش بینی موضوع را انتخاب کردم
19
00:00:51,140 –> 00:00:55,949
وقتی این اصطلاح را در
20
00:00:55,949 –> 00:00:59,280
اینجا در مورد این اصطلاح دیدیم اولین
21
00:00:59,280 –> 00:01:01,590
چیزی که وقتی در مورد پیش بینی صحبت می کنید به ذهن من می
22
00:01:01,590 –> 00:01:05,580
رسد. همیشه روی آینده درست متمرکز شده است،
23
00:01:05,580 –> 00:01:06,840
24
00:01:06,840 –> 00:01:11,369
بنابراین همیشه به آینده به طور معمول اشاره می کنیم
25
00:01:11,369 –> 00:01:15,119
، ما در حال پیش بینی هستیم تا
26
00:01:15,119 –> 00:01:17,070
تصمیمات روزمره زندگی را بگیریم، مانند اینکه آیا می خواهید چیزی بخرید
27
00:01:17,070 –> 00:01:20,580
که ما همیشه تمرکز می کنیم در مورد قیمت ما
28
00:01:20,580 –> 00:01:23,580
اکنون فیض را پیشبینی میکنیم تا این
29
00:01:23,580 –> 00:01:26,549
پیشبینی را انجام دهیم، باید به تجربه خود بستگی
30
00:01:26,549 –> 00:01:28,770
داشته باشیم، اوه باید
31
00:01:28,770 –> 00:01:31,590
اطلاعات را از بازار دریافت کنیم، به عنوان مثال اگر
32
00:01:31,590 –> 00:01:34,740
میخواهید بخرید میخواهید خانه بخرید،
33
00:01:34,740 –> 00:01:36,720
باید مکان خانه نوع خانه را در نظر بگیریم
34
00:01:36,720 –> 00:01:40,259
یا اندازه اتاق و غیره به عنوان مثال
35
00:01:40,259 –> 00:01:43,829
که می گویند مکان یک شهر
36
00:01:43,829 –> 00:01:45,689
یا مکانی خوب است، قطعاً
37
00:01:45,689 –> 00:01:50,700
قیمت خانه در حال حاضر افزایش می یابد، در این
38
00:01:50,700 –> 00:01:52,470
صورت در این سناریو می توانیم تشخیص دهیم
39
00:01:52,470 –> 00:01:56,820
که برای انجام پیش بینی باید
40
00:01:56,820 –> 00:02:00,750
به برخی حقایق دیگر در قبلی وابسته باشیم.
41
00:02:00,750 –> 00:02:02,399
به عنوان مثال، ما باید به اندازه بوم مکان بستگی داشته باشیم، اکنون به عنوان مثال،
42
00:02:02,399 –> 00:02:05,040
43
00:02:05,040 –> 00:02:07,619
یک مشکل این است که چگونه
44
00:02:07,619 –> 00:02:11,099
این فرآیند پیشبینی فرآیند را با استفاده از
45
00:02:11,099 –> 00:02:13,770
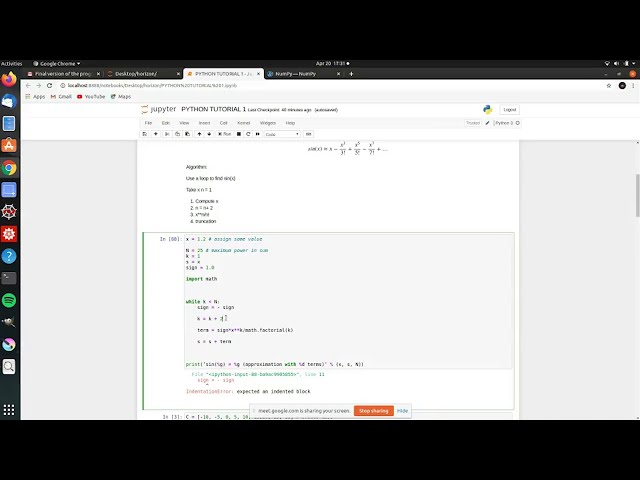
پایتون پیادهسازی کنیم، به سادگی میتوانیم
46
00:02:13,770 –> 00:02:16,530
مدل یادگیری ماشینی را با استفاده از پایتون فراخوانی کنیم تا
47
00:02:16,530 –> 00:02:18,810
توضیح دهیم که چگونه میتوان آن را امروز پیادهسازی کرد.
48
00:02:18,810 –> 00:02:22,400
من این سناریو بازاریابی در مقابل فروش را زمانی انتخاب کردم که در مورد این سناریو
49
00:02:22,400 –> 00:02:26,310
شنیدید،
50
00:02:26,310 –> 00:02:29,610
زمانی که ما واقعاً
51
00:02:29,610 –> 00:02:31,740
با آن آشنا شدیم، میدانید که
52
00:02:31,740 –> 00:02:35,400
اگر بتوانیم یک بازاریابی خوب انجام دهیم، قطعاً
53
00:02:35,400 –> 00:02:38,880
فروش را افزایش خواهیم داد. در حال حاضر رشد فروش خوبی داریم،
54
00:02:38,880 –> 00:02:44,220
اما اکنون به آن بستگی دارد، برای
55
00:02:44,220 –> 00:02:46,590
مثال، بیایید فرض کنیم اگر یک
56
00:02:46,590 –> 00:02:49,550
فرآیند بازاریابی خوب انجام دهیم یا
57
00:02:49,550 –> 00:02:51,510
تبلیغات تلویزیونی را تحت شرایط TSP یا
58
00:02:51,510 –> 00:02:55,260
چیزی که میدانید در دوره خارج از فصل انجام دهیم، میتوانیم
59
00:02:55,260 –> 00:02:59,690
60
00:02:59,690 –> 00:03:03,630
رشد فروش داشته باشیم، اما رشد فروش خوبی نیست، اما اگر ما یک کار
61
00:03:03,630 –> 00:03:05,540
بازاریابی خوب در زمان فصلی انجام دهید،
62
00:03:05,540 –> 00:03:08,850
قطعاً ما اراده ای
63
00:03:08,850 –> 00:03:11,850
خواهیم داشت که رشد فروش خوبی داشته باشیم، به همین
64
00:03:11,850 –> 00:03:14,880
ترتیب، اکنون ما این کار را انجام می دهیم در آن
65
00:03:14,880 –> 00:03:17,610
سناریو، ما آن را با استفاده از هوش خود انجام می دهیم
66
00:03:17,610 –> 00:03:21,600
، اما در آن صورت چگونه
67
00:03:21,600 –> 00:03:25,050
این کار را با استفاده از Pfizer پیاده سازی کنیم. این
68
00:03:25,050 –> 00:03:25,620
مشکلی است که
69
00:03:25,620 –> 00:03:27,959
معمولاً شرکتها بودجه را برای بازاریابی اختصاص میدهند،
70
00:03:27,959 –> 00:03:31,260
اما در میانهی امور مالی بله،
71
00:03:31,260 –> 00:03:34,260
اگر تشخیص دهید که ما میتوانیم کارهای بیشتری برای
72
00:03:34,260 –> 00:03:36,750
افزایش فروش تابستانی انجام دهیم، اما نمیدانیم
73
00:03:36,750 –> 00:03:39,660
چقدر به بودجه اختصاص دهیم، بنابراین
74
00:03:39,660 –> 00:03:45,270
بودجه بازاریابی را افزایش دهیم تا بتوانیم این کار را انجام
75
00:03:45,270 –> 00:03:48,209
دهیم. از ماشین یاد بگیرید اکنون
76
00:03:48,209 –> 00:03:50,990
برای انجام آن کمک بگیرید،
77
00:03:50,990 –> 00:03:55,230
الگوریتم های ریاضی برای انجام پیش بینی وجود دارد،
78
00:03:55,230 –> 00:03:57,660
اکنون الگوریتم های زیادی برای انجام این کار وجود دارد، اما
79
00:03:57,660 –> 00:04:02,340
امروز من روش رگرسیون خطی را انتخاب کردم.
80
00:04:02,340 –> 00:04:06,959
o پیاده سازی مدل پیش بینی ساده در
81
00:04:06,959 –> 00:04:10,830
توان با اوکی بیایید در مورد
82
00:04:10,830 –> 00:04:16,350
رگرسیون خطی صحبت کنیم خوب یک رگرسیون خطی
83
00:04:16,350 –> 00:04:18,089
یک مدل ساده
84
00:04:18,089 –> 00:04:20,190
یادگیری ماشینی برای مشکل رگرسیون است
85
00:04:20,190 –> 00:04:23,820
خوب اجازه دهید به تعریف برویم حالا این
86
00:04:23,820 –> 00:04:25,890
یک تعریف ساده در مورد رگرسیون خطی
87
00:04:25,890 –> 00:04:26,669
88
00:04:26,669 –> 00:04:29,870
است اگر این یکی را خلاصه کنم میتوانیم
89
00:04:29,870 –> 00:04:33,240
بدون تقسیم دو متغیر وجود داشته باشد، یکی
90
00:04:33,240 –> 00:04:35,849
متغیر پیشبینیکننده و دیگری
91
00:04:35,849 –> 00:04:39,449
متغیر وابسته است، اگر
92
00:04:39,449 –> 00:04:43,169
سناریوی خود را در نظر بگیریم،
93
00:04:43,169 –> 00:04:46,889
اگر
94
00:04:46,889 –> 00:04:48,719
میخواهید رشد فروش خوبی داشته باشید یا اگر
95
00:04:48,719 –> 00:04:51,270
میخواهید فروش را افزایش دهید، همین الان پیشبینی فروش را انجام میدهیم. باید به
96
00:04:51,270 –> 00:04:53,580
هزینه های بازاریابی بستگی داشته باشید او هزینه های بازاریابی را افزایش داد
97
00:04:53,580 –> 00:04:57,330
شما می توانید رشد فروش خوبی داشته باشید
98
00:04:57,330 –> 00:05:00,930
اگر به این نمودار برویم می
99
00:05:00,930 –> 00:05:03,900
توانید بارگذاری های آنها را ببینید و همچنین
100
00:05:03,900 –> 00:05:07,819
اگر هزینه های بازاریابی را
101
00:05:07,819 –> 00:05:12,270
در این خط قرار دهیم و اگر هزینه های بازاریابی را افزایش دهیم تمام فروش ها را در این خط قرار
102
00:05:12,270 –> 00:05:16,409
دهیم. می تواند
103
00:05:16,409 –> 00:05:22,710
جریان فروش خوبی داشته باشد اما برای به دست
104
00:05:22,710 –> 00:05:26,969
آوردن این اطلاعات این پیش بینی را دریافت کنید که
105
00:05:26,969 –> 00:05:29,009
باید اطمینان حاصل کنیم که رابطه مثبتی
106
00:05:29,009 –> 00:05:32,039
بین فروش وجود دارد. s و
107
00:05:32,039 –> 00:05:34,469
هزینه های بازاریابی
108
00:05:34,469 –> 00:05:36,120
109
00:05:36,120 –> 00:05:38,789
ترسیم این نوع نمودار پراکندگی در واقع این یک نمودار پراکنده است که این نوع
110
00:05:38,789 –> 00:05:41,639
نمودار پراکندگی را ترسیم می کند ما می توانیم تشخیص دهیم
111
00:05:41,639 –> 00:05:44,490
که یا هر رابطه احتمالی یا
112
00:05:44,490 –> 00:05:47,219
مثبتی بین این دو
113
00:05:47,219 –> 00:05:52,680
متغیر وجود دارد خوب اجازه دهید وارد
114
00:05:52,680 –> 00:05:56,909
سناریو عملی شویم و ببینیم چگونه این دو
115
00:05:56,909 –> 00:06:01,469
متغیر با مجموعه دادههای نمونه ما رفتار میکند
116
00:06:01,469 –> 00:06:08,099
خوب، این اطلاعات فروش مجموعه دادههای نمونه من است
117
00:06:08,099 –> 00:06:10,650
در اینجا میتوانید
118
00:06:10,650 –> 00:06:15,060
دو سه ستونی
119
00:06:15,060 –> 00:06:17,819
دادههای هزینههای فروش و بازاریابی در ایالت را ببینید که
120
00:06:17,819 –> 00:06:24,900
از سال 2010 تا 30 آوریل 2019 پس از
121
00:06:24,900 –> 00:06:30,300
آن یک ماه می تا دسامبر در دسترس است. اطلاعات فروش
122
00:06:30,300 –> 00:06:34,940
در دسترس نیست، سپس میتوانیم اطلاعات تاریخی واقعی را قبل از
123
00:06:34,940 –> 00:06:38,779
عملاً بعد از سال
124
00:06:38,779 –> 00:06:40,599
2019 دریافت کنیم
125
00:06:40,599 –> 00:06:43,929
و اکنون
126
00:06:43,929 –> 00:06:47,559
پس از آوریل میتوانیم به عنوان د کریک در نظر بگیریم،
127
00:06:47,559 –> 00:06:49,839
زیرا فروش اطلاعات آینده
128
00:06:49,839 –> 00:06:52,719
در دسترس نیست و در سناریوی خود میخواهیم
129
00:06:52,719 –> 00:06:58,089
این
130
00:06:58,089 –> 00:06:59,709
اطلاعات فروش را بر اساس اطلاعات فروش پیشبینی کنیم.
131
00:06:59,709 –> 00:07:03,279
تخصیص هزینه های بازاریابی خوب است،
132
00:07:03,279 –> 00:07:06,610
اجازه دهید ابتدا فکر کنیم که باید
133
00:07:06,610 –> 00:07:11,129
این اطلاعات را به نوت بوک های مشتری وارد کنیم
134
00:07:11,129 –> 00:07:14,740
من قصد دارم از نرمافزار نوتبوک Jupiter
135
00:07:14,740 –> 00:07:20,229
برای انجام این آزمایش استفاده کنم،
136
00:07:20,229 –> 00:07:23,580
در این مورد ما به این کتابخانهها نیاز داریم که
137
00:07:23,580 –> 00:07:27,039
در واقع به پانداها numpy برای
138
00:07:27,039 –> 00:07:29,800
محاسبات madflip برای تجسم دادهها نیاز داریم
139
00:07:29,800 –> 00:07:32,139
و در اینجا میتوانید
140
00:07:32,139 –> 00:07:35,369
یادگیری روانی را که در واقع مربوط
141
00:07:35,369 –> 00:07:38,469
به خطی است، مقیاسگذاری کنید تا خطی پیادهسازی شود.
142
00:07:38,469 –> 00:07:40,689
مدل رگرسیون و اولین کاری که
143
00:07:40,689 –> 00:07:43,330
باید انجام دهیم این است که باید
144
00:07:43,330 –> 00:07:45,339
اطلاعات را از این مکان وارد کنیم
145
00:07:45,339 –> 00:07:47,680
در حال حاضر در منبع من موجود در
146
00:07:47,680 –> 00:07:51,399
دسکتاپ در این پوشه است.
147
00:07:51,399 –> 00:07:55,569
148
00:07:55,569 –> 00:07:58,059
149
00:07:58,059 –> 00:08:02,469
بعد از 30 آوریل ما اطلاعات فروش نداریم
150
00:08:02,469 –> 00:08:08,319
و قبل از مه 2018 می
151
00:08:08,319 –> 00:08:11,229
توانیم آن را به عنوان اطلاعات تاریخی در نظر بگیریم و
152
00:08:11,229 –> 00:08:14,589
در اینجا من این منطق را پیاده سازی می کنم تا
153
00:08:14,589 –> 00:08:17,709
اطلاعات تاریخی را با استفاده از آن
154
00:08:17,709 –> 00:08:21,490
فروش که برابر 0 نیست جدا کنیم و اجازه دهید
155
00:08:21,490 –> 00:08:24,459
آن یکی را اجرا کنیم و بعد از آن زمان به
156
00:08:24,459 –> 00:08:27,099
درج کنید که در واقع من آن
157
00:08:27,099 –> 00:08:29,889
اطلاعات را در چارچوب داده DF واقعی وارد کردم
158
00:08:29,889 –> 00:08:35,769
و پس از آن باید این دو
159
00:08:35,769 –> 00:08:38,019
متغیر فروش و بازاریابی را تقسیم کنم زیرا
160
00:08:38,019 –> 00:08:41,259
این دو متغیر متغیرهای
161
00:08:41,259 –> 00:08:43,419
فروش رگرسیون خطی ما،
162
00:08:43,419 –> 00:08:45,069
متغیر پیشبینیکننده بازاریابی است، بنابراین این
163
00:08:45,069 –> 00:08:49,329
متغیر وابسته است و مانند متغیر غیرمستقیم محور X Y است
164
00:08:49,329 –> 00:08:53,399
165
00:08:53,769 –> 00:08:57,249
و پس از آن باید
166
00:08:57,249 –> 00:09:01,809
تقسیم دادهها را برای انجام آزمایش انجام دهیم زیرا
167
00:09:01,809 –> 00:09:03,639
باید دریابیم که آیا وجود دارد یا خیر.
168
00:09:03,639 –> 00:09:05,529
رابطه بین این X و متغیر Y ما
169
00:09:05,529 –> 00:09:08,410
فروش و بازاریابی برای انجام این کار می
170
00:09:08,410 –> 00:09:10,239
توانیم از اطلاعات تاریخی برای
171
00:09:10,239 –> 00:09:12,489
آموزش مدل رگرسیون خطی استفاده کنیم و
172
00:09:12,489 –> 00:09:15,569
سپس می توانیم از اطلاعات تاریخی
173
00:09:15,569 –> 00:09:19,149
برای آزمایش آن استفاده کنیم تا دقت
174
00:09:19,149 –> 00:09:23,139
مدل را بدست آوریم.
175
00:09:23,139 –> 00:09:28,420
بخش بیایید آن یکی را اجرا کنیم و این
176
00:09:28,420 –> 00:09:30,730
قسمت برای پیاده سازی
177
00:09:30,730 –> 00:09:32,290
مدل رگرسیون خطی است، اکنون می توانید
178
00:09:32,290 –> 00:09:34,299
معادله خطی رگرسیون را با استفاده از
179
00:09:34,299 –> 00:09:40,589
کتابخانه های یادگیری cycad ببینید و سپس اضافی را پاس می کنیم
180
00:09:40,589 –> 00:09:43,660
و چرا در اینجا آموزش می دهیم
181
00:09:43,660 –> 00:09:46,689
مجموعه داده ای متغیر X 1 یا Y را به تقسیم می کنیم.
182
00:09:46,689 –> 00:09:50,410
train and test و قطار
183
00:09:50,410 –> 00:09:54,850
و ain خارجی را با استفاده از اندازه تست 0 2 پیاده سازی می کنیم
184
00:09:54,850 –> 00:09:59,559
و در اینجا بعد از آموزش
185
00:09:59,559 –> 00:10:04,540
مدل از آن مدل استفاده می کنیم تا دقت مدل خود را بررسی
186
00:10:04,540 –> 00:10:11,220
کنیم ok اجازه دهید این قسمت را اجرا کنید
187
00:10:11,610 –> 00:10:15,040
خوب بیایید دقت این
188
00:10:15,040 –> 00:10:21,699
مدل را بررسی کنیم اکنون می توانید ببینید 20,000 931
189
00:10:21,699 –> 00:10:25,439
برای این رهگیری است و
190
00:10:25,439 –> 00:10:32,709
مقدار ضریب رگرسیون 20 1.25 است،
191
00:10:32,709 –> 00:10:34,420
حالا معنی این
192
00:10:34,420 –> 00:10:36,939
رهگیری ها و ضریب چیست.
193
00:10:36,939 –> 00:10:40,179
می توانید فروش ما را ببینید
194
00:10:40,179 –> 00:10:47,860
در واقع بین 100000 وجود دارد
195
00:10:47,860 –> 00:10:53,069
و بله می توانید مقداری لیست را نیز مشاهده کنید
196
00:10:53,069 –> 00:10:58,689
88000 چیزی در حال حاضر این وقفه است
197
00:10:58,689 –> 00:11:02,769
که میانگین واقعی مورد انتظار
198
00:11:02,769 –> 00:11:06,160
y را نشان می دهد زمانی که x است 0 با معادله رگرسیون شروع کنید
199
00:11:06,160 –> 00:11:07,839
ما
200
00:11:07,839 –> 00:11:11,889
یک پیش بینی X است اگر X گاهی اوقات برابر است
201
00:11:11,889 –> 00:11:13,959
با صفر وقفه صرفاً
202
00:11:13,959 –> 00:11:17,019
مقدار میانگین مورد انتظار y است در اینجا می
203
00:11:17,019 –> 00:11:20,620
توانیم دوقلو 2020 هزار و نهصد
204
00:11:20,620 –> 00:11:24,519
و سی و یک برای آن یکی داشته باشیم و همچنین
205
00:11:24,519 –> 00:11:26,620
آن متغیر دیگر را داریم یا خروجی دیگر
206
00:11:26,620 –> 00:11:29,680
ضریب است که در
207
00:11:29,680 –> 00:11:31,720
واقع جهت رابطه
208
00:11:31,720 –> 00:11:34,569
بین متغیر پیش بینی کننده را نشان می دهد. و
209
00:11:34,569 –> 00:11:36,670
متغیر پاسخ یک علامت مثبت
210
00:11:36,670 –> 00:11:39,670
نشان می دهد که با افزایش متغیر پیش بینی کننده،
211
00:11:39,670 –> 00:11:42,550
متغیر پاسخ نیز
212
00:11:42,550 –> 00:11:44,050
افزایش می یابد. یک مقدار مثبت
213
00:11:44,050 –> 00:11:47,259
که به این معنی است که ما میتوانیم بیش از شما بگوییم که
214
00:11:47,259 –> 00:11:51,850
دقت تست ما تقریباً خوب است،
215
00:11:51,850 –> 00:11:55,329
اما بیایید آن را تجسم کنیم تا درک خوبی داشته
216
00:11:55,329 –> 00:11:57,970
باشیم – خوشحالم که میتوانیم از
217
00:11:57,970 –> 00:12:01,810
این روش با استفاده از تجسم دادههای کتابخانه matplotlib استفاده
218
00:12:01,810 –> 00:12:03,759
219
00:12:03,759 –> 00:12:09,519
کنیم، خوب اجازه دهید آن را اجرا کنیم، بله، ما میتوانیم
220
00:12:09,519 –> 00:12:11,829
ببینیم که دو متغیر ما در اینجا
221
00:12:11,829 –> 00:12:16,839
هزینه های بازاریابی را به درستی خرج می کنند و سپس
222
00:12:16,839 –> 00:12:19,990
محور y فروش را اکنون به محض اینکه
223
00:12:19,990 –> 00:12:22,420
محور x را افزایش دهید این هزینه های بازاریابی می
224
00:12:22,420 –> 00:12:25,779
توانید ببینید که این خط در حال بالا رفتن است به
225
00:12:25,779 –> 00:12:28,720
این معنی که در دو متغیر ما با
226
00:12:28,720 –> 00:12:31,170
مجموعه داده می توانید بگویید رابطه مثبتی
227
00:12:31,170 –> 00:12:34,509
بین دو متغیر x و
228
00:12:34,509 –> 00:12:39,490
y وجود دارد، هزینههای فروش و بازاریابی خوب است،
229
00:12:39,490 –> 00:12:45,509
اکنون میتوانیم نشان دهیم که مدل ما
230
00:12:45,509 –> 00:12:48,569
مجموعه دادهها و مدلها تقریباً
231
00:12:48,569 –> 00:12:52,120
در واقع بازیگر خوبی است و
232
00:12:52,120 –> 00:12:57,550
اکنون با پایگاه داده نمونه ما دقت خوبی
233
00:12:57,550 –> 00:13:02,439
دارد. من گفتم که بعد از آوریل 2019
234
00:13:02,439 –> 00:13:04,630
اکنون فروش نداریم، باید
235
00:13:04,630 –> 00:13:09,490
فروش را بر اساس هزینه های بازاریابی پیش بینی
236
00:13:09,490 –> 00:13:12,130
کنیم، اکنون تمام
237
00:13:12,130 –> 00:13:16,510
هزینه های بازاریابی بودجه بندی شده را مشخص کرده ایم و بعد از
238
00:13:16,510 –> 00:13:22,740
آوریل آینده آن را مشخص کرده ایم. و ما باید تصمیم
239
00:13:23,050 –> 00:13:26,830
بگیریم که بهترین هزینه بازاریابی
240
00:13:26,830 –> 00:13:31,450
یا ارزشی که می تواند تام را به ارمغان بیاورد یا
241
00:13:31,450 –> 00:13:34,030
بازدهی رشد فروش گروهی
242
00:13:34,030 –> 00:13:35,860
چیست، به این معنی که اکنون می توانیم به عنوان
243
00:13:35,860 –> 00:13:39,730
مثال این یکی را همین الان در 31 مه بگیریم
244
00:13:39,730 –> 00:13:45,160
تا فروش خوبی داشته باشیم. رشد الان
245
00:13:45,160 –> 00:13:47,290
قبلاً 800 هزار یا
246
00:13:47,290 –> 00:13:47,860
چیزی
247
00:13:47,860 –> 00:13:52,450
هشتصد و هشتاد هزار داریم الان
248
00:13:52,450 –> 00:13:54,490
تا دویست هزار چیزی داشته باشیم الان
249
00:13:54,490 –> 00:13:56,350
چهارصد و نه
250
00:13:56,350 –> 00:13:59,320
هفت و نهصد و هفتاد و پنج مقدار
251
00:13:59,320 –> 00:14:02,830
تخصیص داده ایم اگر هزار دیگر را اختصاص دهیم
252
00:14:02,830 –> 00:14:08,020
یعنی 5575 برای این مقدار می توانیم آن را بدست آوریم.
253
00:14:08,020 –> 00:14:10,360
این همان کاری است که ما در اینجا می خواهیم انجام
254
00:14:10,360 –> 00:14:13,060
دهیم، ما قبلاً یک مدل آموزش
255
00:14:13,060 –> 00:14:16,840
256
00:14:16,840 –> 00:14:19,590
257
00:14:19,590 –> 00:14:21,940
258
00:14:21,940 –> 00:14:27,390
259
00:14:27,600 –> 00:14:31,660
داده ایم. در واقع در
260
00:14:31,660 –> 00:14:34,140
این مرحله باید این مرحله را اجرا کنیم من این مرحله را اجرا می کنم
261
00:14:34,140 –> 00:14:37,330
اکنون می توانیم
262
00:14:37,330 –> 00:14:39,670
هزینه های بازاریابی را ببینیم محدوده ای وجود دارد که اکنون
263
00:14:39,670 –> 00:14:41,920
از صفر شروع می کنیم و سپس
264
00:14:41,920 –> 00:14:43,720
هزار و دو هزار و سه شما
265
00:14:43,720 –> 00:14:46,000
حالا اگر این مجموعه داده را
266
00:14:46,000 –> 00:14:49,060
انتخاب کنید و ما آن را امتحان کنیم، چه کاری انجام خواهیم
267
00:14:49,060 –> 00:14:53,560
داد تا این جیب تخصیص یافته را
268
00:14:53,560 –> 00:14:55,990
که با هزار و دو هزار به این شکل بیان می شود افزایش
269
00:14:55,990 –> 00:14:58,510
دهیم و می توانیم
270
00:14:58,510 –> 00:15:01,780
پیش بینی فروش پیش بینی برای آن
271
00:15:01,780 –> 00:15:06,580
افزایش را بدست آوریم. اکنون
272
00:15:06,580 –> 00:15:09,070
مجموعه دادههای محدوده هزینههای بازاریابی را داریم
273
00:15:09,070 –> 00:15:12,550
و برای آن باید بودجه یا مجموعه دادههای آینده را از هم جدا کنیم، به
274
00:15:12,550 –> 00:15:19,020
275
00:15:19,020 –> 00:15:24,250
این معنی که این بخش اکنون در اینجا من از فروش برابر
276
00:15:24,250 –> 00:15:26,800
با صفر اطلاعات آینده در این
277
00:15:26,800 –> 00:15:29,950
چارچوب دادهای بودجهبندی شده DF استفاده میکنم و همچنین تولید میکنم.
278
00:15:29,950 –> 00:15:32,830
چهارچوب داده در اینجا و برای
279
00:15:32,830 –> 00:15:34,339
ادغام آن دو
280
00:15:34,339 –> 00:15:38,629
محصول cutscene که به معنای هر
281
00:15:38,629 –> 00:15:42,290
رکورد برای هر رکورد است، باید
282
00:15:42,290 –> 00:15:44,720
هزار و پنج هزار تا پانزده
283
00:15:44,720 –> 00:15:55,730
هزار ردیف را در تجربیات بازاریابی تخصیص یافته جدید
284
00:15:55,730 –> 00:15:58,550
برای هر ردیف تنظیم کنم تا این کار را انجام دهم که
285
00:15:58,550 –> 00:16:00,110
باید از این متقاطع استفاده کنم.
286
00:16:00,110 –> 00:16:01,519
تابع محصول دکارتی را بدانید
287
00:16:01,519 –> 00:16:04,339
این یک حق بیمه پیاده سازی شده در حال اجرا است،
288
00:16:04,339 –> 00:16:08,180
حالا بیایید آن یکی را اجرا کنیم و سپس
289
00:16:08,180 –> 00:16:14,600
می توانیم پیوستن به دوره را انجام دهیم،
290
00:16:14,600 –> 00:16:16,490
DF بودجه بندی شده را تعیین می کنم که تعریف
291
00:16:16,490 –> 00:16:18,319
نشده است. xecute این قسمت
292
00:16:18,319 –> 00:16:21,230
باشه بیایید این یکی را اجرا کنیم خب حالا ما
293
00:16:21,230 –> 00:16:25,809
می توانیم فروش برابر با صفر را ببینیم تمام
294
00:16:25,809 –> 00:16:28,779
اطلاعات مربوط به آینده
295
00:16:28,779 –> 00:16:34,610
در حال حاضر اجازه دهید اولین عضویت را طی
296
00:16:34,610 –> 00:16:36,170
کنیم در اولین باری که این نوع
297
00:16:36,170 –> 00:16:39,050
پیام هشدار دریافت می کنید و بیایید این قسمت را
298
00:16:39,050 –> 00:16:41,959
اجرا کنیم چارچوب داده جدید اکنون در اینجا می
299
00:16:41,959 –> 00:16:44,629
توانید ببینید که هزینه های بازاری