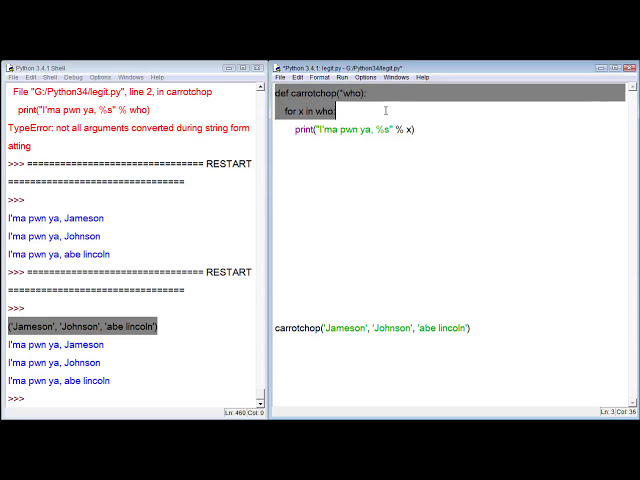
در این مطلب، ویدئو یادگیری ماشینی در پایتون: طبقه بندی عنبیه – قسمت 2 با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:13:53
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:01,500
این ویدیو توسط dev
2
00:00:01,500 –> 00:00:03,179
Mountain یک بوت کمپ برنامه نویسی برای شما آورده شده است که
3
00:00:03,179 –> 00:00:05,069
دوره های حضوری و آنلاین را در
4
00:00:05,069 –> 00:00:06,509
موضوعات مختلف از جمله
5
00:00:06,509 –> 00:00:08,160
توسعه وب توسعه iOS
6
00:00:08,160 –> 00:00:09,960
نرم افزار طراحی تجربه کاربر
7
00:00:09,960 –> 00:00:12,269
تضمین کیفیت و توسعه Salesforce ارائه می دهد برای
8
00:00:12,269 –> 00:00:13,830
اطلاعات بیشتر به پیوند در
9
00:00:13,830 –> 00:00:15,719
توضیحات زیر مراجعه کنید. با اشاره
10
00:00:15,719 –> 00:00:17,670
قبلی که در آن نحوه
11
00:00:17,670 –> 00:00:20,520
نصب ماژول SQL urn را به اشتراک می گذاریم، علاوه
12
00:00:20,520 –> 00:00:22,769
بر بازی با مجموعه داده های عنبیه که
13
00:00:22,769 –> 00:00:25,109
از SK بارگیری کرده ایم، یاد می گیریم، بنابراین
14
00:00:25,109 –> 00:00:26,580
کمی توضیح دادیم که آن
15
00:00:26,580 –> 00:00:28,859
مجموعه داده در مورد چه چیزی است که بررسی کردیم.
16
00:00:28,859 –> 00:00:30,869
کمی با توجه به
17
00:00:30,869 –> 00:00:33,180
نمایش متنی آن داده ها
18
00:00:33,180 –> 00:00:34,350
در بارگذاری آن به عنوان یک
19
00:00:34,350 –> 00:00:36,210
فرهنگ لغت پایتون و در این ویدیو که ما
20
00:00:36,210 –> 00:00:37,410
انجام می دهیم این است که به نوعی آن تحلیل را ادامه می دهیم
21
00:00:37,410 –> 00:00:39,300
اما آن را گرافیکی تر می
22
00:00:39,300 –> 00:00:41,100
کنیم و ما به طور خاص خودمان هستیم میخواهیم
23
00:00:41,100 –> 00:00:42,899
نگاهی به نحوه
24
00:00:42,899 –> 00:00:45,480
ترجمه بسیاری از آنها به نمودارها و نمودارهایی
25
00:00:45,480 –> 00:00:47,100
بیندازیم که ممکن است بتوانیم بینشهایی درباره آنها به دست آوریم
26
00:00:47,100 –> 00:00:49,680
و این خوب است.
27
00:00:49,680 –> 00:00:51,780
هر زمان که
28
00:00:51,780 –> 00:00:53,910
با یک مجموعه داده بازی می کنید و می خواهید
29
00:00:53,910 –> 00:00:55,829
کمی شهود در مورد نحوه
30
00:00:55,829 –> 00:00:58,050
رفتار مجموعه داده ایجاد کنید یک گام ضروری است و به نوعی
31
00:00:58,050 –> 00:01:01,289
دوره را راهنمایی می کند که چگونه می
32
00:01:01,289 –> 00:01:03,059
توان مدل یادگیری ماشین را به طور مؤثر در داده ها اعمال کرد.
33
00:01:03,059 –> 00:01:05,250
تنظیم کنید تا بدانید آن را دریافت کنید – در این مورد
34
00:01:05,250 –> 00:01:07,650
یک نمونه از یک نمونه را به درستی طبقه بندی کنید،
35
00:01:07,650 –> 00:01:09,810
بنابراین این یک
36
00:01:09,810 –> 00:01:12,000
گام میانی است که ممکن است برای
37
00:01:12,000 –> 00:01:13,710
یادگیری کمی بیشتر در مورد
38
00:01:13,710 –> 00:01:15,090
آنچه مجموعه داده به شما می گوید بردارید تا بتوانید
39
00:01:15,090 –> 00:01:17,369
یک نمونه موثر را انتخاب کنید. مدلی که باید از آن استفاده کنیم، بنابراین
40
00:01:17,369 –> 00:01:19,259
کاری که میخواهیم انجام دهیم این است که
41
00:01:19,259 –> 00:01:21,509
اساساً در این ویدیو ترسیم کنیم و ماژولی
42
00:01:21,509 –> 00:01:23,430
که قرار است از آن استفاده کنند،
43
00:01:23,430 –> 00:01:25,770
ماژولی است به نام نقشه نمودار زنده، بنابراین اگر
44
00:01:25,770 –> 00:01:27,540
با طرح زنده من آشنا نیستید، یک
45
00:01:27,540 –> 00:01:29,700
کتابخانه رسم بسیار استاندارد در پایتون
46
00:01:29,700 –> 00:01:31,619
و کاری که میخواهیم انجام دهیم این است
47
00:01:31,619 –> 00:01:33,900
که با گفتن import
48
00:01:33,900 –> 00:01:39,329
matplotlib dot pi نمودار بهعنوان PLT وارد میکنیم، بنابراین
49
00:01:39,329 –> 00:01:40,829
intellisense در اینجا کمی کند است،
50
00:01:40,829 –> 00:01:42,720
گاهی اوقات به هر دلیلی کمی تأخیر میکند.
51
00:01:42,720 –> 00:01:44,040
فقط به خاطر
52
00:01:44,040 –> 00:01:45,960
پلاگین vim که من از آن استفاده می کنم معمولاً
53
00:01:45,960 –> 00:01:47,369
بسیار خوب است، اما به هر دلیلی
54
00:01:47,369 –> 00:01:48,659
به نظر می رسد که در حال حاضر به نوعی چسبیده است،
55
00:01:48,659 –> 00:01:50,970
بنابراین در حال حاضر ما فقط می خواهیم
56
00:01:50,970 –> 00:01:53,460
این مپ pot Lib آن مقدار لوله را به عنوان
57
00:01:53,460 –> 00:01:55,200
PLT وارد کنیم. خلاصه برای
58
00:01:55,200 –> 00:01:57,420
ما به عملکردی
59
00:01:57,420 –> 00:01:59,820
که در بخش نمودار PI از matplotlib یافت
60
00:01:59,820 –> 00:02:02,369
می شود اشاره کنیم تا بتوانیم در این
61
00:02:02,369 –> 00:02:04,049
مورد به عملکرد
62
00:02:04,049 –> 00:02:05,969
نمودار پراکنده دسترسی داشته باشیم که به ما امکان می دهد برخی
63
00:02:05,969 –> 00:02:07,829
از داده هایی را که از مجموعه داده عنبیه داریم پراکنده کنیم.
64
00:02:07,829 –> 00:02:09,780
plot Live نصب شده کاری که می
65
00:02:09,780 –> 00:02:11,700
توانید انجام دهید این است که می توانید یک ترمینال را باز کنید و
66
00:02:11,700 –> 00:02:13,310
می توانید آن را نصب کنید، بنابراین من فقط
67
00:02:13,310 –> 00:02:15,470
یک ترمینال را از طریق vim باز می کنم، فقط می
68
00:02:15,470 –> 00:02:18,380
خواهم بگویم pip install matplotlib بنابراین من
69
00:02:18,380 –> 00:02:19,340
قبلاً این را روی دستگاه خود نصب کرده ام.
70
00:02:19,340 –> 00:02:20,840
بنابراین وقتی این
71
00:02:20,840 –> 00:02:21,980
را میبینم، میبینم که تعدادی از نیازها
72
00:02:21,980 –> 00:02:23,720
قبلاً برآورده شده است، اگر این کار را انجام ندهید،
73
00:02:23,720 –> 00:02:24,920
نصب روی دستگاه خود را مشاهده خواهید کرد و
74
00:02:24,920 –> 00:02:25,819
باید آماده باشید
75
00:02:25,819 –> 00:02:27,680
، درست مانند ویدیوی قبلی
76
00:02:27,680 –> 00:02:29,959
که وارد کردیم. بخش عنبیه بارگذاری
77
00:02:29,959 –> 00:02:32,120
مجموعه داده از urn SQL
78
00:02:32,120 –> 00:02:34,390
که ما Loa کرده ایم آن را برداشت و آن را در
79
00:02:34,390 –> 00:02:37,010
متغیری به نام عنبیه ذخیره کرد که
80
00:02:37,010 –> 00:02:38,330
از آن استفاده می کنیم و چیزی که به
81
00:02:38,330 –> 00:02:40,010
82
00:02:40,010 –> 00:02:42,230
طور خاص ترسیم می کنیم ویژگی های آن هستند، بنابراین دوباره
83
00:02:42,230 –> 00:02:43,940
اینها طول کاسبرگ عرض
84
00:02:43,940 –> 00:02:46,160
کاسبرگ طول و گلبرگ هستند. ویژگیهای عرض
85
00:02:46,160 –> 00:02:47,480
دادههایی که به ما داده میشود اینها
86
00:02:47,480 –> 00:02:49,730
ویژگیها هستند و کاری که میخواهیم انجام دهیم این است
87
00:02:49,730 –> 00:02:51,860
که میخواهیم چند نمودار ایجاد کنیم تا ببینیم چگونه
88
00:02:51,860 –> 00:02:53,870
این ویژگیها بر
89
00:02:53,870 –> 00:02:56,030
اساس گونههایی که اتفاقاً خودشان را محدود
90
00:02:56,030 –> 00:02:58,340
میکنند به هم مرتبط هستند، بنابراین اگر یکی از گونهها
91
00:02:58,340 –> 00:03:00,170
بهطور اتفاقی گلبرگهای بلندتری دارند و
92
00:03:00,170 –> 00:03:01,489
دیگری این یک
93
00:03:01,489 –> 00:03:03,440
ویژگی جالب از آن دادهها است که به
94
00:03:03,440 –> 00:03:06,110
ما کمک میکند تا تشخیص دهیم که
95
00:03:06,110 –> 00:03:08,599
اساساً گونهای با گلبرگهای
96
00:03:08,599 –> 00:03:11,569
بلندتر ممکن است بیشتر
97
00:03:11,569 –> 00:03:12,950
از هر یک از این دسته باشد. به
98
00:03:12,950 –> 00:03:14,900
عنوان مثال، دو کلاس دیگر، بنابراین ما
99
00:03:14,900 –> 00:03:16,340
قصد داریم این روابط متقابل را
100
00:03:16,340 –> 00:03:18,560
با استفاده از چند نمودار پراکنده ترسیم کنیم و کاری
101
00:03:18,560 –> 00:03:19,820
که قرار است انجام دهیم این است که
102
00:03:19,820 –> 00:03:21,829
ابتدا سعی می کنیم بخش ویژگی های آن را استخراج کنیم.
103
00:03:21,829 –> 00:03:24,410
t دادهها را در چیزی قرار
104
00:03:24,410 –> 00:03:26,420
میدهیم که میتوانیم واقعاً با آن بازی کنیم، بنابراین
105
00:03:26,420 –> 00:03:27,950
اگر از ویدیوی قبلی به خاطر بیاورید، کاری که من میخواهم انجام دهم این
106
00:03:27,950 –> 00:03:30,859
است که
107
00:03:30,859 –> 00:03:33,500
کلید داده مجموعه داده عنبیه با تمام دادهها مطابقت دارد،
108
00:03:33,500 –> 00:03:35,480
به عنوان مثال اگر بگویم
109
00:03:35,480 –> 00:03:38,840
عنبیه چاپی داده این
110
00:03:38,840 –> 00:03:41,510
مربوط به آرایهای است که دارای ردیفهایی است
111
00:03:41,510 –> 00:03:43,489
که در آن هر یک از ردیفها
112
00:03:43,489 –> 00:03:45,590
با اطلاعات دادههای ویژگی برای یک
113
00:03:45,590 –> 00:03:47,389
نمونه مشخص مطابقت دارد، بنابراین من فقط میروم
114
00:03:47,389 –> 00:03:49,819
و آن را مینویسم و سپس آن را اجرا می
115
00:03:49,819 –> 00:03:51,319
کنم، بنابراین من فقط میروم. برای گفتن یک پایتون قسمت دو
116
00:03:51,319 –> 00:03:52,760
نقطه pi که نام این فایل است
117
00:03:52,760 –> 00:03:55,400
و دوباره این فقط لیستی از ردیفهایی است
118
00:03:55,400 –> 00:03:56,870
که مربوط به هر یک از
119
00:03:56,870 –> 00:03:58,609
نمونههایی است که بخشی از این مجموعه داده است،
120
00:03:58,609 –> 00:04:00,920
بنابراین کاری که میخواهم انجام دهم این است که در
121
00:04:00,920 –> 00:04:02,450
در این مورد، آن دادهها را جابهجا میکنیم
122
00:04:02,450 –> 00:04:04,489
و در انجام این کار، کاری که
123
00:04:04,489 –> 00:04:05,989
به من اجازه میدهد انجام دهم،
124
00:04:05,989 –> 00:04:09,049
مجموعه دادهها را به چهار شعاع مجزا تقسیم میکنیم
125
00:04:09,049 –> 00:04:10,819
و بهطور خاص هر یک از این چهار
126
00:04:10,819 –> 00:04:13,760
آرایه مجزا، آرایهای خواهند بود
127
00:04:13,760 –> 00:04:15,739
که کاملاً اختصاصی است. به تمام
128
00:04:15,739 –> 00:04:18,019
طول کاسبرگ تمام این کاسبرگ w idth
129
00:04:18,019 –> 00:04:19,608
تمام طول گلبرگ و تمام عرض گلبرگ،
130
00:04:19,608 –> 00:04:21,709
بنابراین اجازه دهید من ادامه دهم و به
131
00:04:21,709 –> 00:04:23,930
شما نشان دهم که چه چیزی قرار است به ما بدهد،
132
00:04:23,930 –> 00:04:24,919
زیرا فکر می کنم نشان دادن آن کمی ساده
133
00:04:24,919 –> 00:04:26,730
تر است به جای اینکه دو
134
00:04:26,730 –> 00:04:28,440
توضیح بدهم، بنابراین من می خواهم چه کار کنم. آیا
135
00:04:28,440 –> 00:04:30,090
همانطور که گفتم می خواهم
136
00:04:30,090 –> 00:04:32,820
این داده را جابجا کنم و اگر این کار را با این عملگر نقطه T انجام دهم،
137
00:04:32,820 –> 00:04:34,740
138
00:04:34,740 –> 00:04:37,560
مجموعه داده ها را بر روی آن چیزی
139
00:04:37,560 –> 00:04:39,780
که یک عملیات ماتریسی است جابجا می کند و سپس این
140
00:04:39,780 –> 00:04:41,910
کار انجام می شود. یک نوع لیست متمایز ما از
141
00:04:41,910 –> 00:04:43,910
لیستها که شامل
142
00:04:43,910 –> 00:04:46,380
ویژگیهای مختلف میشود، بنابراین ما باید
143
00:04:46,380 –> 00:04:47,520
این را بنویسیم، من آن را اجرا
144
00:04:47,520 –> 00:04:48,360
میکنم دقیقاً منظورم را
145
00:04:48,360 –> 00:04:50,460
به شما نشان میدهد، بنابراین اگر نتیجه این را چاپ کند
146
00:04:50,460 –> 00:04:52,380
آنچه من دارم این است که من دارم لیستی از لیست ها
147
00:04:52,380 –> 00:04:53,910
که در آن هر یک از فهرست های فرعی هر یک از
148
00:04:53,910 –> 00:04:56,880
این چهار لیست فرعی اساساً یک
149
00:04:56,880 –> 00:04:58,770
لیست برجسته هستند یا لیست هایی که با
150
00:04:58,770 –> 00:05:01,080
هر کدام
151
00:05:01,080 –> 00:05:02,640
از طول کاسبرگ مطابقت دارند.
152
00:05:02,640 –> 00:05:04,980
153
00:05:04,980 –> 00:05:07,710
این یکی
154
00:05:07,710 –> 00:05:09,060
با تمام گلبرگ مطابقت دارد
155
00:05:09,060 –> 00:05:10,800
طول ورودیها و این یکی
156
00:05:10,800 –> 00:05:11,730
فقط با ورودیهای عرض پانل مطابقت دارد،
157
00:05:11,730 –> 00:05:13,650
بنابراین من اساساً فهرستی از
158
00:05:13,650 –> 00:05:15,540
فهرستها دارم که در آن هر یک از این فهرستها مربوط به
159
00:05:15,540 –> 00:05:17,400
یکی از ویژگیهای منحصربهفرد است که بخشی
160
00:05:17,400 –> 00:05:18,990
از مجموعه دادههای ما هستند و کاری که میخواهیم
161
00:05:18,990 –> 00:05:20,460
انجام دهیم نوعی ذخیرهسازی است. اینها در
162
00:05:20,460 –> 00:05:23,610
متغیرها و سپس ترسیم این مجموعه
163
00:05:23,610 –> 00:05:25,170
از داده ها در برابر یکدیگر تا
164
00:05:25,170 –> 00:05:26,580
به نوعی حس ارتباط بین این چیزها را به دست آوریم،
165
00:05:26,580 –> 00:05:29,160
بنابراین من ادامه می دهم
166
00:05:29,160 –> 00:05:30,660
و این را
167
00:05:30,660 –> 00:05:32,280
روی صفحه چاپ می کنم و این را در یک صفحه ذخیره می کنم.
168
00:05:32,280 –> 00:05:33,150
متغیری که من می خواهم
169
00:05:33,150 –> 00:05:34,890
ویژگی ها را صدا کنم، بنابراین این فقط یک شی
170
00:05:34,890 –> 00:05:36,720
است که لیست لیست ها را ذخیره می کند
171
00:05:36,720 –> 00:05:38,730
و به عنوان مثال، اگر بگویم
172
00:05:38,730 –> 00:05:41,640
ویژگی های چاپ 0
173
00:05:41,640 –> 00:05:43,350
، اولین جزء از آن لیست
174
00:05:43,350 –> 00:05:44,850
لیست ها را به من می دهد. در این مورد، این فقط
175
00:05:44,850 –> 00:05:47,520
فهرستی از تمام داده های طول کاسبرگ است
176
00:05:47,520 –> 00:05:49,620
که ما در مجموعه داده های خود داریم، بنابراین فقط برای
177
00:05:49,620 –> 00:05:50,940
اینکه این کار زمانی که در
178
00:05:50,940 –> 00:05:52,500
واقع در حال تولید نمودارهای خود هستیم، کمی آسان تر شود، کاری که من می
179
00:05:52,500 –> 00:05:53,700
خواهم انجام دهم این است که یک متغیر ایجاد کنید
180
00:05:53,700 –> 00:05:55,980
که به آن کاسبرگ طول می گویند
181
00:05:55,980 –> 00:05:57,660
یا اجازه دهید آن را فوقپیوندی بنامیم و
182
00:05:57,660 –> 00:05:58,950
این فقط با ویژگیهای 0 برابری میکند،
183
00:05:58,950 –> 00:06:01,500
بنابراین من فقط میروم
184
00:06:01,500 –> 00:06:02,310
و از شر آن پرانتزهای اضافی خلاص میشوم
185
00:06:02,310 –> 00:06:03,780
و سه پرانتز
186
00:06:03,780 –> 00:06:04,890
دیگر خواهیم داشت که نسبتاً خواهند بود.
187
00:06:04,890 –> 00:06:07,080
مشابه، بنابراین ما همچنین می
188
00:06:07,080 –> 00:06:09,240
خواهیم یکی برای عرض کاسبرگ داشته باشیم، می خواهیم
189
00:06:09,240 –> 00:06:11,820
یکی برای طول گلبرگ و همچنین طول گلبرگ داشته
190
00:06:11,820 –> 00:06:13,620
باشیم و می خواهیم یکی برای
191
00:06:13,620 –> 00:06:15,840
عرض گلبرگ داشته باشیم، بنابراین اینها چهار
192
00:06:15,840 –> 00:06:18,120
لیست متمایز هستند که
193
00:06:18,120 –> 00:06:20,460
شامل ویژگی های مجموعه داده های ما این است
194
00:06:20,460 –> 00:06:23,010
1 این 2 و سپس این 3 است، بنابراین
195
00:06:23,010 –> 00:06:25,170
این چهار لیست متمایز هستند که شامل
196
00:06:25,170 –> 00:06:27,300
تمام اجزای منحصر به فرد هر یک از
197
00:06:27,300 –> 00:06:29,490
این ویژگی ها هستند، بنابراین آنچه من نیز
198
00:06:29,490 –> 00:06:31,500
می خواهم انجام دهم این است که می خواهم برچسب
199
00:06:31,500 –> 00:06:34,290
یا نام ویژگی یک مجموعه داده معین
200
00:06:34,290 –> 00:06:36,030
و این بیشتر به این دلیل است که صرفاً
201
00:06:36,030 –> 00:06:37,380
یک مختصر است که به
202
00:06:37,380 –> 00:06:39,660
ما امکان می دهد به راحتی به آن اشاره کنیم وقتی که
203
00:06:39,660 –> 00:06:41,010
واقعاً رسم می کنیم، بنابراین اگر
204
00:06:41,010 –> 00:06:42,720
چیزی را رسم کنیم و بخواهیم
205
00:06:42,720 –> 00:06:44,970
محور x و محور y را برچسب گذاری کنیم. می تواند به سرعت
206
00:06:44,970 –> 00:06:46,560
به این موارد بر اساس
207
00:06:46,560 –> 00:06:49,680
متغیرهایی را که میخواهیم بر اساس
208
00:06:49,680 –> 00:06:51,840
نامهای آینده ایجاد کنیم، بهعنوان مثال به یاد بیاورید
209
00:06:51,840 –> 00:06:53,910
که ساختار فرهنگ لغت مجموعه داده عنبیه
210
00:06:53,910 –> 00:06:55,950
نیز دارای یک کلید به نام ویژگیهای
211






![فیلم آموزشی: شروع به کار | پایتون برای مبتدیان [3 از 44] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/CXZYvNRIAKMimage2.jpg)